Datawhale “AI春训营“
AI for Science”(人工智能用于科学研究)是一种新兴的跨学科研究范式,它利用人工智能(AI)技术来推动科学研究的创新与发展。通过将机器学习、深度学习、自然语言处理等 AI 技术与传统科学领域相结合,AI for Science 旨在解决复杂科学问题,加速科学发现的进程,并开辟新的研究方向。新能源发电功率预测是构建新型电力系统的核心技术之一,其价值不仅在于技术层面,更关乎能源安全、经济效
“AI for Science”(人工智能用于科学研究)是一种新兴的跨学科研究范式,它利用人工智能(AI)技术来推动科学研究的创新与发展。通过将机器学习、深度学习、自然语言处理等 AI 技术与传统科学领域相结合,AI for Science 旨在解决复杂科学问题,加速科学发现的进程,并开辟新的研究方向。
新能源发电功率预测是构建新型电力系统的核心技术之一,其价值不仅在于技术层面,更关乎能源安全、经济效率与环境可持续性。本次大赛提供覆盖多个场景的新能源场站历史发电功率数据和对应时段多类别气象预测数据,预测次日零时起到未来24小时逐15分钟新能源场站发电功率。
本赛道与中国南方电网电力调度控制中心(简称南网总调)合作,同时南网总调也于 2023 年启动了覆盖南网区域的新能源功率预测培育计划。该计划旨在提升南方区域新能源预测水平,构建灵活、开放的新能源功率预测新生态。详情请参阅
- 数据观测
读取并查看训练集中气象数据
nc_path = "data/初赛训练集/nwp_data_train/1/NWP_1/20240101.nc"
dataset = Dataset(nc_path, mode='r')
dataset.variables.keys()
# 输出:dict_keys(['time', 'channel', 'data', 'lat', 'lon', 'lead_time'])查看 channel 中变量,共有8个,具体如下
channel = dataset.variables["channel"][:]
channel
# 输出:array(['ghi', 'poai', 'sp', 't2m', 'tcc', 'tp', 'u100', 'v100'], dtype=object)查看 data 维度,该数据维度为(1, 24, 8, 11, 11)
data = dataset.variables["data"][:]
data.shape
# 输出:(1, 24, 8, 11, 11)- 数据处理
观测上步代码结果可知气象数据中新能源场站每个小时的数据维度为 2 (11x11),但构建模型对于单个时间点的单个特征只需要一个 标量 即可,因此我们把 11x11 个格点的数据取均值,从而将二维数据转为单一的标量值。
且主办方提供的气象数据时间精度为h,而发电功率精度为15min,即给我们一天的数据有24条天气数据与96(24*4)条功率数据,因此将功率数据中每四条数据只保留一条。
# 获取2024年日期
date_range = pd.date_range(start='2024-01-01', end='2024-12-30')
# 将%Y-%m-%d格式转为%Y%m%d
date = [date.strftime('%Y%m%d') for date in date_range]
# 定义读取训练/测试集函数
def get_data(path_template, date):
# 读取该天数据
dataset = Dataset(path_template.format(date), mode='r')
# 获取列名
channel = dataset.variables["channel"][:]
# 获取列名对应的数据
data = dataset.variables["data"][:]
# for i in range(8) 表示将第三维度进行遍历
# data[:, :, i, :, :][0] 的维度为(24, 11, 11)
# np.mean(data[:, :, i, :, :][0], axis=(1, 2) 表示对该数组的第二、三个维度(11, 11)计算均值 生成的列表长度为24
# 又因为循环了8次 因此形状为8*24
# 我们最后使用.T进行转置 将数组的维度转成了24*8
mean_values = np.array([np.mean(data[:, :, i, :, :][0], axis=(1, 2)) for i in range(8)]).T
# 将数据与列名整合为dataframe
return pd.DataFrame(mean_values, columns=channel)
# 定义路径模版
train_path_template = "/sdc/model/data/初赛训练集/nwp_data_train/1/NWP_1/{}.nc"
# 通过列表推导式获取数据 返回的列表中每个元素都是以天为单位的数据
data = [get_data(train_path_template, i) for i in date]
# 将每天的数据拼接并重设index
train = pd.concat(data, axis=0).reset_index(drop=True)
# 读取目标值
target = pd.read_csv("/sdc/model/data/初赛训练集/fact_data/1_normalization_train.csv")
target = target[96:]
# 功率数据中每四条数据去掉三条
target = target[target['时间'].str.endswith('00:00')]
target = target.reset_index(drop=True)
# 将目标值合并到训练集
train["power"] = target["功率(MW)"]- 数据可视化
从分布中分析是否特征与特征、目标值之间存在周期性、趋势性、相关性和异常性。
import matplotlib.pyplot as plt
# 获取24小时的列表
hours = range(24)
# 定义画布
plt.figure(figsize=(20,10))
# 绘制八个特征及目标值
for i in range(9):
# 绘制3*3的图中第i+1子图
plt.subplot(3, 3, i+1)
# 横坐标为小时 纵坐标为特征or目标值
plt.plot(hours, train.iloc[:24, i])
# title为列名
plt.title(train.columns.tolist()[i])
# 展示图片
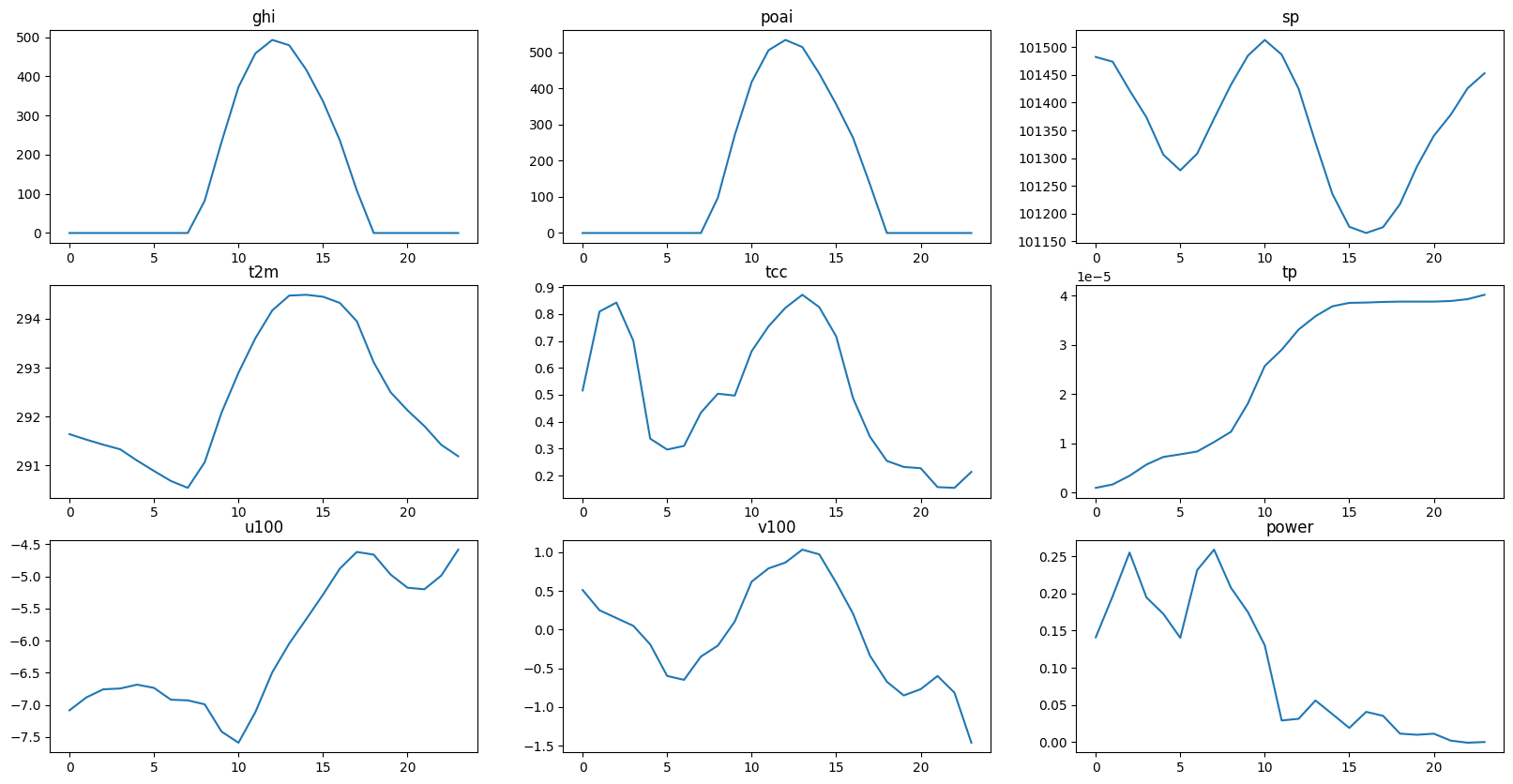
plt.show()我根据下图有以下猜测
-
ghi与poai基本成正比
-
sp、t2m、tcc、v100趋势大体一致
-
power功率高的时段主要在凌晨
-
power在上午时段急转直下
-
tp是少有的单调递增的特征 且貌似与power递减区间重复
-
是否可以根据风在经纬度方向上的速度得到总风速?合并后是否会与power相关?
对于以上猜测我们需要观察更多的数据予以验证,在这期间也会产生更多的想法
特征工程
特征工程指的是把原始数据转变为模型训练数据的过程,目的是获取更好的训练数据特征。特征工程能使得模型的性能得到提升,有时甚至在简单的模型上也能取得不错的效果。
def feature_combine(df):
# 复制一份数据
df_copy = df.copy()
# 新增列风速 将两个方向的风速合并为总风速
df_copy["wind_speed"] = np.sqrt(df_copy['u100']**2 + df_copy['v100']**2)
# 添加小时的特征
df_copy["h"] = df_copy.index % 24
return df_copy
train = feature_combine(train)数据清洗
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。俗话说:garbage in, garbage out。分析完数据后,特征工程前,必不可少的步骤是对数据清洗。
数据清洗的作用是利用有关技术如数理统计、数据挖掘或预定义的清理规则将脏数据转化为满足数据质量要求的数据。
baseline中没有进行细致的数据清洗工作,仅删除含有缺失值所在的行
train = train.dropna().reset_index(drop=True)更多方法可参考 缺失值处理、异常值处理、数据分桶、特征归一化/标准化 等流程。
常用方法参考
模型训练与验证
特征工程也好,数据清洗也罢,都是为最终的模型来服务的,模型的建立和调参决定了最终的结果。模型的选择决定结果的上限, 如何更好的去达到模型上限取决于模型的调参。
建模的过程需要我们对常见的线性模型、非线性模型有基础的了解。模型构建完成后,需要掌握一定的模型性能验证的方法和技巧
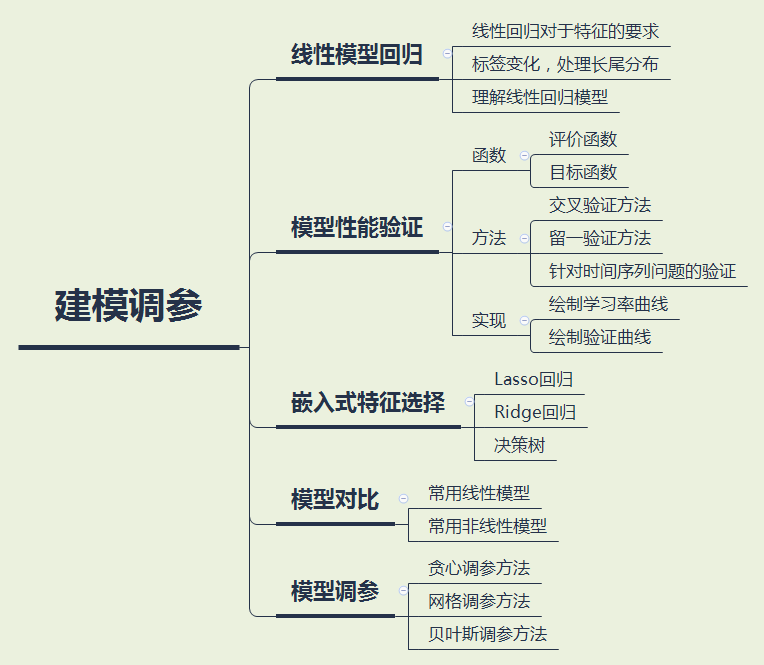
常用方法参考
我们使用lightgbm模型,并选择经典的K折交叉验证方法进行离线评估,大体流程如下:
-
K折交叉验证会把样本数据随机的分成K份;
-
每次随机的选择K-1份作为训练集,剩下的1份做验证集;
-
当这一轮完成后,重新随机选择K-1份来训练数据;
-
最后将K折预测结果取平均作为最终提交结果。
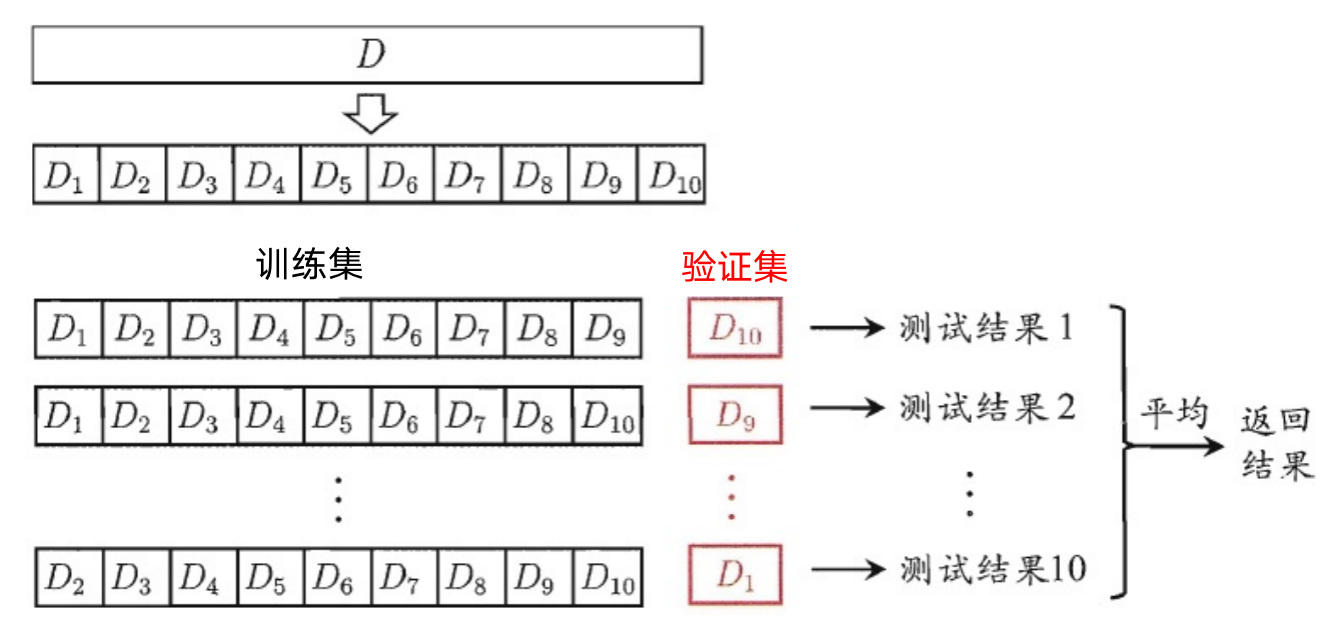
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
import lightgbm as lgb
def cv_model(clf, train_x, train_y, test_x, seed=2024):
# 5折交叉验证
folds = 5
# 生成训练集和验证集的索引
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
# 存储验证结果
oof = np.zeros(train_x.shape[0])
# 存储测试集预测结果
test_predict = np.zeros(test_x.shape[0])
# 存储每折评分
cv_scores = []
# kf.split(train_x, train_y)返回一个生成器 每次调用返回新的train_index, valid_index
# 循环五次
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i+1)))
# 获取当前折的训练集及验证集
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
# 使用Lightgbm的Dataset构建训练及验证数据集
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
# 模型参数
params = {
# 提升类型
'boosting_type': 'gbdt',
# 回归任务
'objective': 'regression',
# 评估指标
'metric': 'rmse',
# 子节点最小权重
'min_child_weight': 5,
# 最大叶子结点数
'num_leaves': 2 ** 8,
# L2正则化权重
'lambda_l2': 10,
# 每次迭代随机选择80%的特征
'feature_fraction': 0.8,
# 表示每次迭代随机选择80%的样本
'bagging_fraction': 0.8,
# 4次迭代执行一次bagging
'bagging_freq': 4,
# 学习率,即模型更新的幅度
'learning_rate': 0.1,
# 随机种子
'seed': 2023,
# 线程数
'nthread' : 16,
# 设置模型训练过程中不输出信息
'verbose' : -1,
}
# 使用参数训练模型
model = clf.train(params, train_matrix, 3000, valid_sets=[train_matrix, valid_matrix])
# 对验证集进行预测
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
# 对测试集进行预测
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
# 更新模型在验证集上的结果
oof[valid_index] = val_pred
# 将每个模型结果加权并相加
test_predict += test_pred / kf.n_splits
# 对rmse取倒数 得分越高性能越好
score = 1/(1+np.sqrt(mean_squared_error(val_pred, val_y)))
# 存储成绩
cv_scores.append(score)
# 打印成绩
print(cv_scores)
# 返回验证集及测试集结果
return oof, test_predict
# 获取训练集中除了power的其他列
cols = [f for f in train.columns if f not in ['power']]
# 使用函数
lgb_oof, lgb_test = cv_model(lgb, train[cols], train["power"], test)
# 将数据重复4次
lgb_test = [item for item in lgb_test for _ in range(4)]结果输出
提交需要符合提交样例结果
# 读取数据
output = pd.read_csv("/sdc/model/data/output/output1.csv").reset_index(drop=True)
# 添加预测结果
output["power"] = lgb_test
# 重命名时间列
output.rename(columns={'Unnamed: 0': ''}, inplace=True)
# 将索引设置为时间列
output.set_index(output.iloc[:, 0], inplace=True)
# 删掉数据中名为 0 的列
output = output.drop(columns=["0", ""])
# 存储数据
output.to_csv('output/output1.csv')进阶实践
在进阶实践部分,将在原有Baseline基础上做更多优化,一般优化思路,从特征工程与模型中来思考。

优化方法建议:
-
提取更多特征: 在数据挖掘比赛中, 特征 总是最终制胜法宝,去思考什么信息可以帮助我们提高预测精准度,然后将其转化为特征输入到模型。
-
尝试不同的模型: 模型 间存在很大的差异,预测结果也会不一样,比赛的过程就是不断的实验和试错的过程,通过不断的实验寻找最佳模型,同时帮助自身加强模型的理解能力。
特征优化
参考代码如下:
# 构建特征
def feature_combine(df):
df_copy = df.copy()
# 经纬度两个方向的风速进行向量计算 获取实际风速
df_copy["wind_speed"] = np.sqrt(df_copy['u100']**2 + df_copy['v100']**2)
# 添加小时特征 捕捉数据的时间周期性
df_copy["h"] = df_copy.index % 24
# 特征组合
# 计算ghi(水平面总辐照度)与poai(光伏面板辐照度)的比值
# 反映光伏组件的效率
df_copy["ghi/poai"] = df_copy["ghi"] / (df_copy["poai"] + 0.0000001)
# 同上
df_copy["ghi_poai"] = df_copy["ghi"] - df_copy["poai"]
# 计算总风速与sp(气压)的比值。有助于捕捉风速与气压之间的关系
df_copy["wind_speed/sp"] = df_copy["wind_speed"] / (df_copy["sp"] + 0.0000001)
return df_copy💡
大家在思考如何提升baseline的时候可以想下:
-
我们是否用到了全部数据?
-
十座发电场都属于一类吗?是否可以都用一个策略?
模型融合
进行模型融合的前提是有多个模型的输出结果,比如使用catboost、xgboost和lightgbm三个模型分别输出三个结果,这时就可以将三个结果进行融合,最常见的是将结果直接进行加权平均融合。
下面我们构建了cv_model函数,内部可以选择使用lightgbm、xgboost和catboost模型,可以依次跑完这三个模型,然后将三个模型的结果进行取平均进行融合。
def cv_model(clf, train_x, train_y, test_x, clf_name, seed = 2023):
'''
clf:调用模型
train_x:训练数据
train_y:训练数据对应标签
test_x:测试数据
clf_name:选择使用模型名
seed:随机种子
'''
folds = 5
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
oof = np.zeros(train_x.shape[0])
test_predict = np.zeros(test_x.shape[0])
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
if clf_name == "lgb":
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'mae',
'min_child_weight': 6,
'num_leaves': 2 ** 6,
'lambda_l2': 10,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 4,
'learning_rate': 0.1,
'seed': 2023,
'nthread' : 16,
'verbose' : -1,
}
model = clf.train(params, train_matrix, 2000, valid_sets=[train_matrix, valid_matrix],
categorical_feature=[], verbose_eval=200, early_stopping_rounds=100)
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
if clf_name == "xgb":
xgb_params = {
'booster': 'gbtree',
'objective': 'reg:squarederror',
'eval_metric': 'mae',
'max_depth': 5,
'lambda': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'eta': 0.1,
'tree_method': 'hist',
'seed': 520,
'nthread': 16
}
train_matrix = clf.DMatrix(trn_x , label=trn_y)
valid_matrix = clf.DMatrix(val_x , label=val_y)
test_matrix = clf.DMatrix(test_x)
watchlist = [(train_matrix, 'train'),(valid_matrix, 'eval')]
model = clf.train(xgb_params, train_matrix, num_boost_round=2000, evals=watchlist, verbose_eval=200, early_stopping_rounds=100)
val_pred = model.predict(valid_matrix)
test_pred = model.predict(test_matrix)
if clf_name == "cat":
params = {'learning_rate': 0.1, 'depth': 5, 'bootstrap_type':'Bernoulli','random_seed':2023,
'od_type': 'Iter', 'od_wait': 100, 'random_seed': 11, 'allow_writing_files': False}
model = clf(iterations=2000, **params)
model.fit(trn_x, trn_y, eval_set=(val_x, val_y),
metric_period=200,
use_best_model=True,
cat_features=[],
verbose=1)
val_pred = model.predict(val_x)
test_pred = model.predict(test_x)
oof[valid_index] = val_pred
test_predict += test_pred / kf.n_splits
score = mean_absolute_error(val_y, val_pred)
cv_scores.append(score)
print(cv_scores)
return oof, test_predict
# 选择lightgbm模型
lgb_oof, lgb_test = cv_model(lgb, train[cols], train["power"], test, 'lgb')
# 选择xgboost模型
xgb_oof, xgb_test = cv_model(xgb, train[cols], train["power"], test, 'xgb')
# 选择catboost模型
cat_oof, cat_test = cv_model(CatBoostRegressor, train[cols], train["power"], test, 'cat')
# 进行取平均融合
final_test = (lgb_test + xgb_test + cat_test) / 3
欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)