【更新中】【自用】大模型八股
直接偏好优化,是一种从人类偏好中直接学习策略的强化学习算法,常用于基于人类反馈的强化学习(RLHF)。与传统的RLHF方法(如PPO)不同,DPO绕过了显式的奖励模型建模步骤,直接利用偏好数据优化策略,简化了训练流程并提升了稳定性。但随之的代价就是,更为频繁的CPU,GPU交互,极大增加了训练推理的时间开销。具体点说,DeepSpeed将当前时刻,训练模型用不到的参数,缓存到CPU
自用的大模型八股,如果对你有帮助,请点点赞和收藏求求了orz,整理不易!
大模型八股
- 大模型的微调技术
- 大模型对齐
- BF16, FP16, FP32
- Transformer
- Deepspeed
- 大模型的训练
- BN以及LN
- 分布式大模型训练
- Transformer BERT GPT区别?
- BERT的变体了解哪些?怎么做的?
- Bert以及GPT的参数量?
- 模型蒸馏
- 数据不平衡怎么处理
- 模型的幻觉问题?
- Resnet 残差结构?
- 梯度爆炸?
- RAG
- 模型的参数初始化?Lora的参数初始化?...
- top-k和top-p
- 对比损失和llm中的temperature
- 训练样本的文本如何构建的,输出的格式
- 冻结矩阵的反量化如何实现
- 大模型的结构
- 传统机器学习
- 激活函数
- 强化学习
- 介绍Qlora,对什么进行4bit量化,lora初始矩阵是什么,lora矩阵的量化
- 如何将参数较大的模型部署在显存有限的环境下
- 多卡微调
- bert的input词向量和其他大模型的区别
- transformer的MHA之后的FFN是如何训练的
- 超长文本推理
- RoPE及各种变体,Sparse Attention,Leaky RoPE
- bert中随机mask了一些词,在代码中是如何体现的
- 如果位置编码按照1 2 3 4 5这样编码会出现什么问题?现在主流的位置编码有哪些?
- 你怎么看待长距离依赖?
- Bert与GPT的训练目标
- softmax
- KL散度
- Agent的基本原理
- 跨模态对齐
- LSTM与bert
大模型的微调技术
全参数微调(Full Fine-tuning)
原理:解锁大模型的全部参数,用下游任务数据反向传播更新权重。
优点:效果最佳(尤其是大数据场景)
缺点:
- 计算成本高(优化存储器状态、梯度、参数副本)
- 容易过拟合(尤其是数据量不够的情况)
- 灾难性遗忘(破坏预训练的通用能力)
参数高效微调(PEFT)
Adapter Layers
在Transformer层中插入小型神经网络模块(如两层MLP),仅训练新增参数
优点:参数量小(0.5%~8%),保留模型的原始能力
缺点:引入推理延迟(增加计算路径)
LoRA(Low-Rank Adaptation)
用低秩矩阵分解逼近参数更新量 ΔW = A×B,秩r远小于原维度。
例如在stable-diffusion中,研究人员发现微调cross-attention部分就能获得很好的结果。而交叉注意力层中的权重被排列为矩阵形式,就可以使用lora进行微调。通过矩阵分解,使用很小的空间就能够存储这些矩阵的参数值。
优点:
-
无推理延迟(可以直接合并到原权重)
-
显存占用低(仅需保存A/B的梯度)

-
支持多任务切换(不同A/B组合)
缺点:
秩r的选择影响效果,需经验调参。
QLora
低位量化:
- 在 bitsandbytes 或类似库的支持下,可以将模型权重从 FP16/BF16 压缩到 4-bit 或 8-bit。
- 4-bit 量化会采用一些特殊的方法(如 bnb 中的 quantization+quantile-based mapping),以尽量保持数值精度。
- 推理和训练都可以在这种量化表示下执行,从而节省内存带宽与显存开销。
QLoRA 中,原始权重被 4-bit 量化、冻结,只在前向传播时进行解码(或部分近似运算),不更新这些量化权重;而在相应矩阵上 额外加上的低秩 LoRA 层 则以正常精度(FP16/BF16)进行训练更新。
这样做能在 不牺牲(或少量牺牲)模型推理与训练效果的同时,大大减少存储与算力消耗。
Dora

prefix/prompt tuning
原理:
- Prefix-tuning:在输入前添加可训练前缀向量(作用于每一层);
- Prompt-tuning:仅在输入层添加可训练提示词。
优点:模型0修改,部署起来最简单;
缺点:效果依赖prompt长度,长文本任务可能受限
一些trick
- 数据预处理:保持与预训练格式一致(如特殊token使用);
- 超参数选择:
- 学习率:通常为预训练的1/10 ~ 1/100;
- Batch Size:小数据用更小的batch;
- 评估策略:保留部分验证集防止过拟合。
其它
- 误区1:认为“PEFT效果一定比全参数微调差”
- 纠正:在低资源场景下,PEFT通过减少过拟合风险反而可能效果更好。
- 误区2:混淆LoRA与Adapter
- LoRA:参数注入式,无计算延迟;
- Adapter:结构插入式,增加计算量。
- 误区3:忽视模型缩放(Scaling Laws)
- 大模型(>10B参数)更适合PEFT,小模型可全参数微调。
大模型对齐
RLHF
全称:Reinforcement Learning from Human Feedback,基于人类的偏好对语言模型进行强化学习。
预训练一个语言模型 (LM) ;
聚合问答数据并训练一个奖励模型 (Reward Model,RM) ;
用强化学习 (RL) 方式微调 LLM。
PPO
是一种强化学习算法,属于策略梯度方法的改进版本。其核心思想是通过限制策略更新的幅度,确保每次更新不会破坏现有策略的稳定性,从而提高训练效率和效果。


为什么PPO算法要用优势函数来评估,为什么不能直接用reward反馈(拷打到死)
因为直接使用 reward 会导致高方差、低效率;优势函数可以降低方差、提高稳定性和学习效率。
优势函数是什么的优势
定义: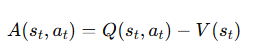

PPO的定义中:
其中At的计算方式常用的是GAE
GAE
GAE,全称 Generalized Advantage Estimation,是强化学习中一种**平衡偏差和方差、估算优势函数(Advantage Function)**的技术。
回顾一下优势函数的定义: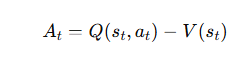
其中Q和V都需要估计,估计不合理可能导致高方差(采样噪声大,导致策略更新不稳定)或高偏差
GAE 引入了一种平滑 Advantage 的办法,它用 多步 TD 误差的加权平均 代替单步 TD 误差;
GAE的缺点
- 参数选择敏感,需要在λ的选择上,平衡方差与偏差;λ太小,则效果趋近于单步TD,偏差大;λ太大,则GAE趋近于使用总回报,方差大。;
- GAE需要记录Trajectory,可能会造成额外的内存以及时间开销,尤其是在长推理的场景下;
- 训练初期,value 网络尚未学好时,GAE很有可能引入额外噪声,效果会比较差;
On-policy与Off-policy
On-policy: 用当前正在学习的策略收集数据、并更新它自己。(PPO)
优点:
理论简单,目标和行为一致
更新方向明确,优化收敛稳定
缺点:
数据用一次就废(效率低)
每一步训练都要重新收集新轨迹
Off-policy: 用别的策略(旧的或不同的)收集数据,来训练目标策略。
优点:
支持经验回放,提升样本利用率
可以学习更优策略(如 target policy ≠ behavior policy)
缺点
更新容易不稳定(行为策略与目标策略差异大时)
需要额外机制解决偏差(如重要性采样)
DPO
直接偏好优化,是一种从人类偏好中直接学习策略的强化学习算法,常用于基于人类反馈的强化学习(RLHF)。与传统的RLHF方法(如PPO)不同,DPO绕过了显式的奖励模型建模步骤,直接利用偏好数据优化策略,简化了训练流程并提升了稳定性。
在RLHF中,传统流程是:
收集人类对轨迹的偏好数据(例如标注“回答A比回答B更好”);
训练一个奖励模型(Reward Model)来预测人类偏好;
使用强化学习算法(如PPO)根据奖励模型优化策略。
DPO的改进:
直接通过偏好数据优化策略,无需显式训练奖励模型。其核心思想是将策略本身视为隐式的奖励函数,通过概率匹配直接调整策略以符合人类偏好。



GRPO(Deepseek)
GRPO(Group Relative Policy Optimization,群体相对策略优化)是由 DeepSeek 团队提出的一种新型强化学习算法,旨在提升大语言模型(LLM)在复杂推理任务中的表现。该算法最早在 DeepSeekMath 论文中提出,并成功应用于 DeepSeek-R1 模型的训练中,显著增强了模型在数学、编程等任务中的推理能力。

Group如何选择?
一个 group 是指针对同一个输入 prompt,模型生成的多个候选响应。组的设计直接影响奖励对比的可靠性和最终模型的性能。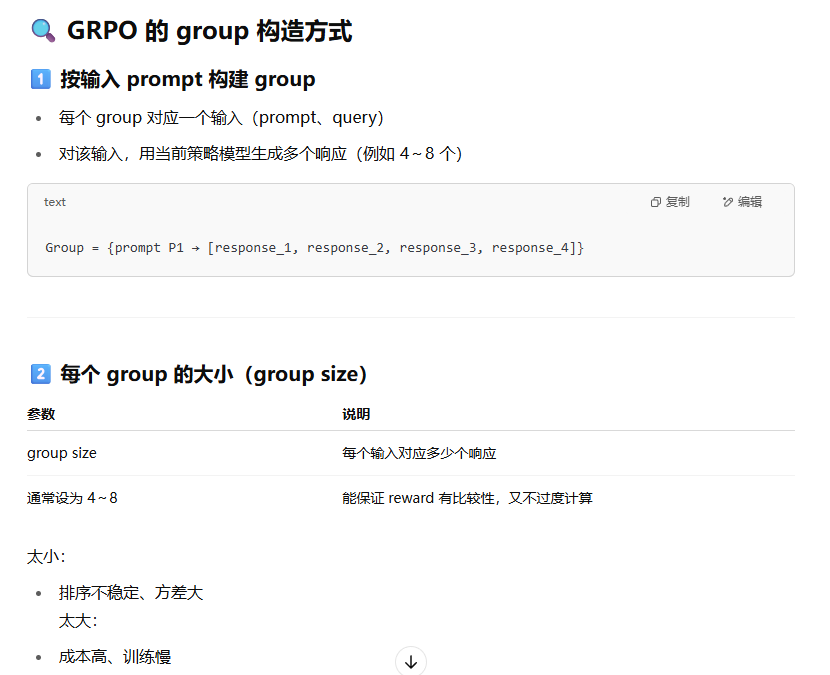

BF16, FP16, FP32
“这几种格式的主要区别在于精度与效率的权衡。
fp32是单精度浮点,提供最高精度,但内存占用大;fp16和bf16都是16位,显存减半,适合加速计算。bf16保留了和fp32相同的动态范围,适合大模型训练,而fp16动态范围小,需要梯度缩放来防止数值问题。
例如在训练GPT类模型时,常用bf16保证稳定性,而手机端推理可能用fp16优化速度。”
Transformer
关于Transform的定义,参考博客:https://zhuanlan.zhihu.com/p/338817680
多头注意力机制的参数量是多少?

为什么注意力分数要除以根号下dk?
为了防止内积过大
cross attention



muti-head attention




decoder的输入有哪些?
- encoder的输出;
- decoder自己的输入,也就是前面已经生成的tokens
- 位置编码,显式的告诉模型 token 的顺序信息
加在 target embeddings 上
有两种方式:
固定正弦函数编码(原始论文)
可学习的位置编码(很多现代实现采用)
decoder的attention和encoder的有什么不同?
Encoder 的 attention 是“全向”的自注意力,
Decoder 的 attention 包含两种:Masked 自注意力 + Encoder-Decoder attention,分别用于理解前文和条件生成。
decoder在训练和推理的时候有什么不同?

Deepspeed
DeepSpeed的核心就在于,GPU显存不够,CPU内存来凑。
比方说,我们只有一张10GB的GPU,那么我们很可能需要借助80GB的CPU,才能够训练一个大模型。
具体点说,DeepSpeed将当前时刻,训练模型用不到的参数,缓存到CPU中,等到要用到了,再从CPU挪到GPU。这里的“参数”,不仅指的是模型参数,还指optimizer、梯度等。
越多的参数挪到CPU上,GPU的负担就越小;但随之的代价就是,更为频繁的CPU,GPU交互,极大增加了训练推理的时间开销。因此,DeepSpeed使用的一个核心要义是,时间开销和显存占用的权衡。
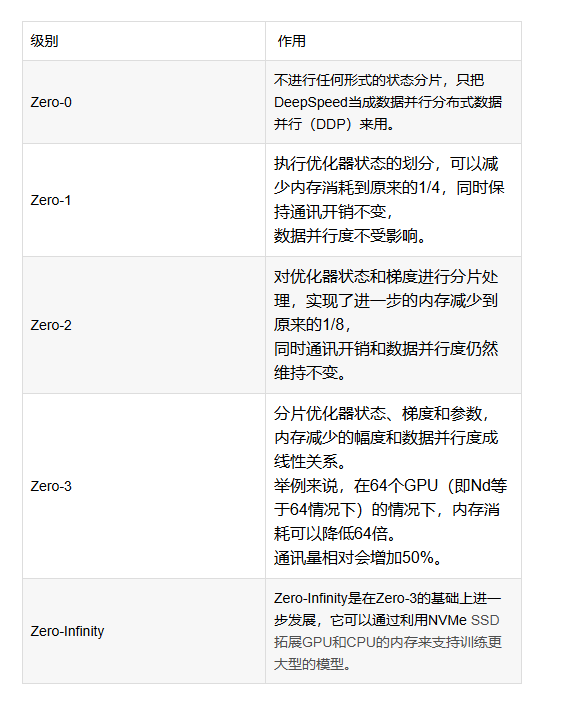
Optimizer state partitioning (ZeRO stage 1) 只对optimizer进行切片后分布式保存
Gradient partitioning (ZeRO stage 2) 对optimizer和grad进行切片后分布式保存
Parameter partitioning (ZeRO stage 3) 对optimizer、grad和模型参数进行切片后分布式保存
Custom mixed precision training handling
A range of fast CUDA-extension-based optimizers
ZeRO-Offload to CPU and NVMe
offload:将forward中间结果保存到内存、硬盘(NVMe)等缓存中,然后在需要时进行加载或重计算,进一步降低显存占用
deepspeed提供了混合精度训练的支持,可以通过在配置文件中设置"fp16.enabled": true来启用混合精度训练。在训练过程中,deepspeed会自动将一部分操作转换为FP16格式,并根据需要动态调整精度缩放因子,从而保证训练的稳定性和精度。
Zero-1、2、3
大模型的训练
https://zhuanlan.zhihu.com/p/636270877
- 预训练阶段(Pretraining Stage)
选择一个效果比较好的基座模型;
针对语言不匹配、专业知识不足等问题,首先做预训练;
先做分词
常见的分词方式:
WordPiece
WordPiece 很好理解,就是将所有的「常用字」和「常用词」都存到词表中
Bert就是这种分词方式;
当需要切词的时候就从词表里面查找即可。
当遇到词表中不存在的字词时,tokenizer 会将其标记为特殊的字符 [UNK]:
BBPE
BBPE 不是按照中文字词为最小单位,而是按照 unicode 编码 作为最小粒度。
预训练
Pretraining 的思路很简单,就是输入一堆文本,让模型做 Next Token Prediction 的任务,这个很好理解。
OOV
数据配比
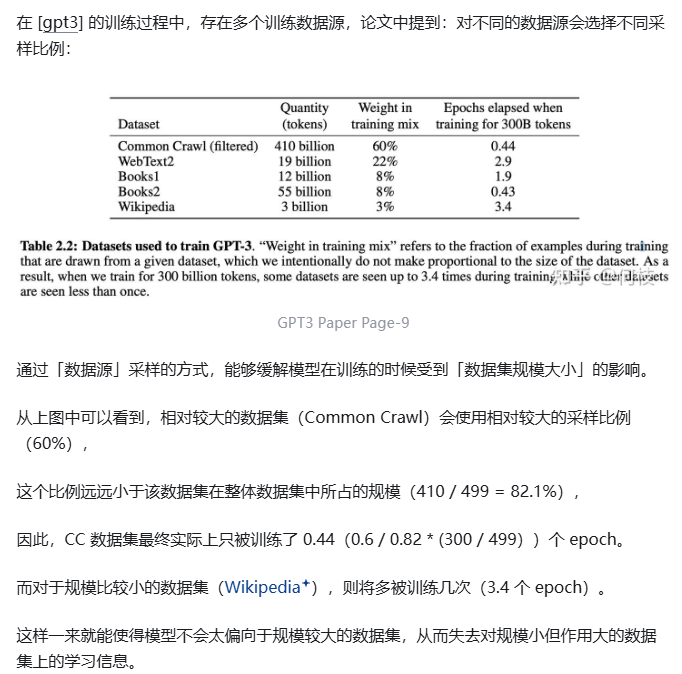
数据截断
通常来讲,在 Finetune 任务中,我们通常会直接使用 truncation 将超过阈值(2048)的文本给截断,
以书籍数据为例,一本书的内容肯定远远多余 2048 个 token,但如果采用头部截断的方式,
则每本书永远只能够学习到开头的 2048 tokens 的内容(连序章都不一定能看完)。
因此,最好的方式是将长文章按照 seq_len(2048)作分割,将切割后的向量喂给模型做训练。
模型效果评测
关于 Language Modeling 的量化指标,较为普遍的有 [PPL],[BPC] 等,
可以简单理解为在生成结果和目标文本之间的 Cross Entropy Loss 上做了一些处理。
这种方式可以用来评估模型对「语言模板」的拟合程度,
即给定一段话,预测后面可能出现哪些合法的、通顺的字词。
指令微调阶段(Instruction Tuning Stage)
数据清洗、数据配比
BN以及LN
BN 是对「样本批次的每一维特征」做归一化,适用于 CNN 等结构;
LN 是对「单个样本内部所有特征」做归一化,适用于 Transformer、RNN 等结构。
在深度神经网络中,随着层数变深,激活值可能出现:
梯度爆炸或消失
不同分布(Internal Covariate Shift)
归一化能:
稳定训练过程
加快收敛速度
改善泛化性能
分布式大模型训练
Transformer BERT GPT区别?
BERT(Bidirectional Encoder Representations from Transformers)是一个基于 Transformer 的语言理解预训练模型,它的结构本质上是一个 堆叠的多层 Transformer Encoder 结构。


对于GPT而言:
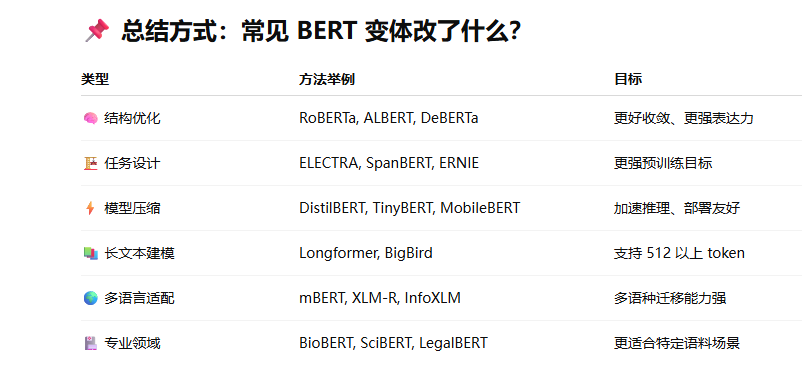
BERT的变体了解哪些?怎么做的?
Bert以及GPT的参数量?
BERT-Base vs BERT-Large
总参数量 110M 340M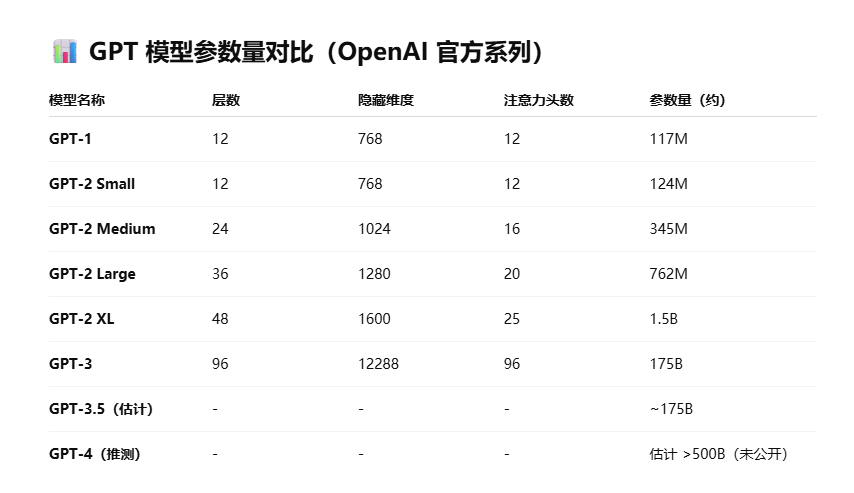
模型蒸馏
模型蒸馏(Knowledge Distillation)是一种模型压缩技术,通过将一个大型、性能强的模型(教师模型 Teacher)的知识迁移给一个小型、高效的模型(学生模型 Student),从而达到在不牺牲太多性能的情况下提高推理效率的目的。


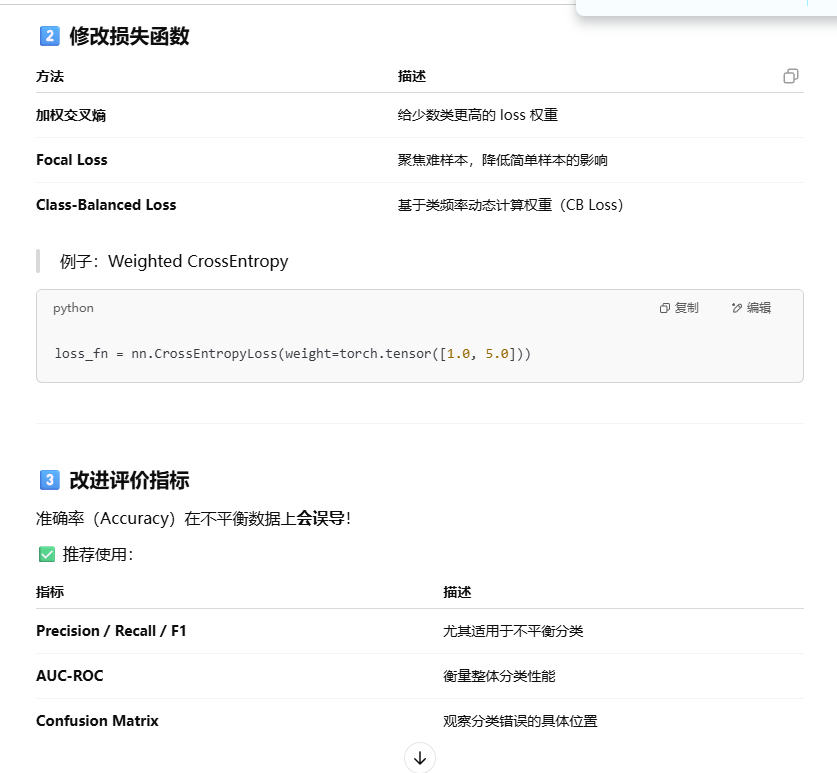
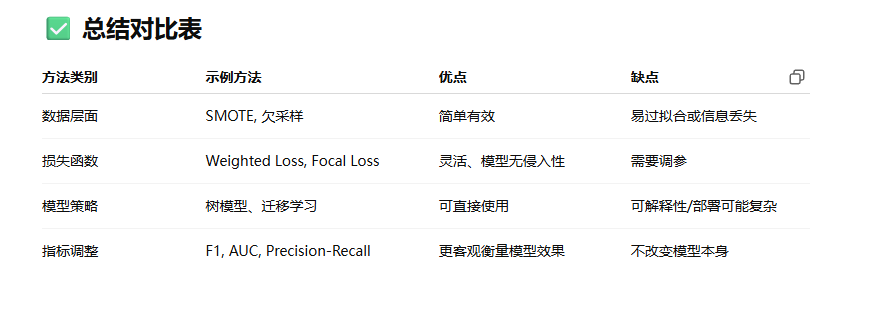
数据不平衡怎么处理



模型的幻觉问题?
幻觉 = 模型编造看似合理但事实错误的内容,例如伪造人物、数字、链接、引用、甚至逻辑推理链。


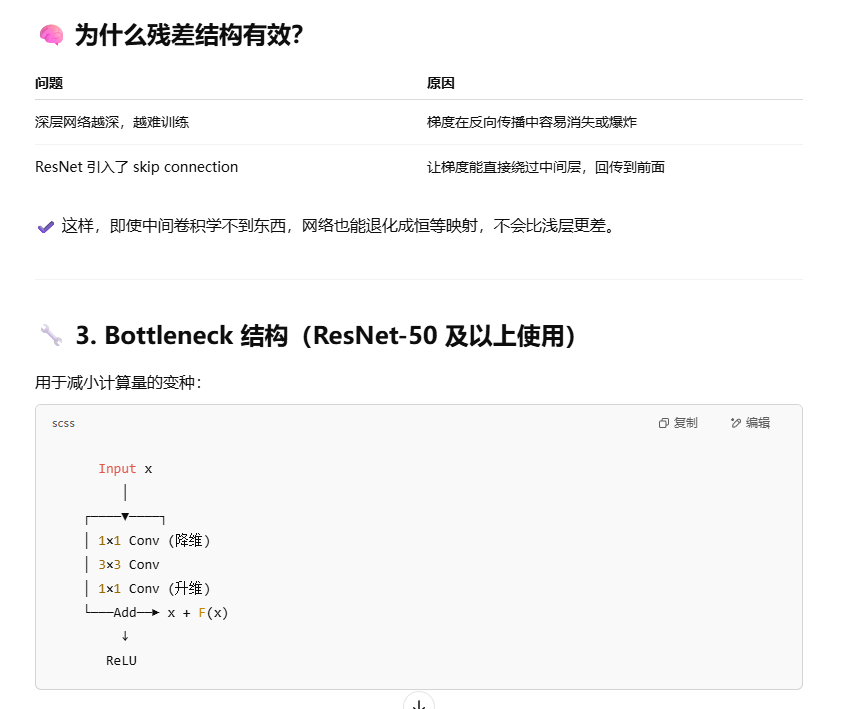
Resnet 残差结构?



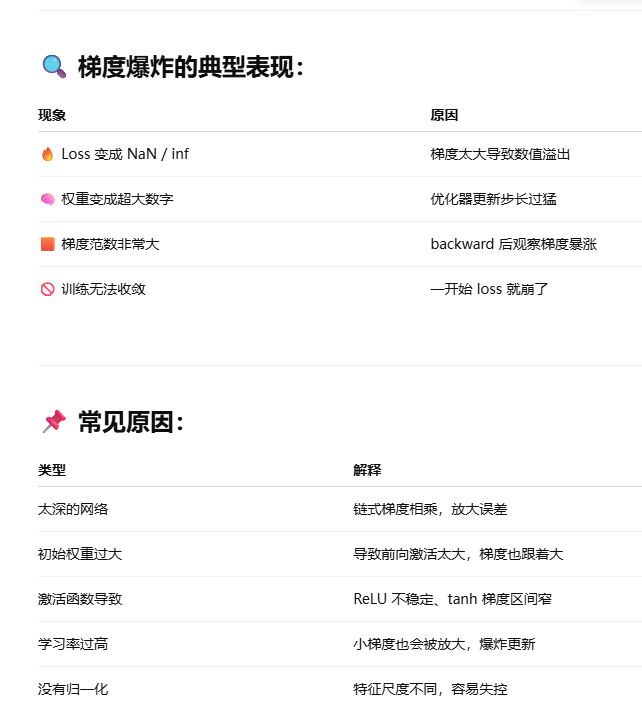
梯度爆炸?


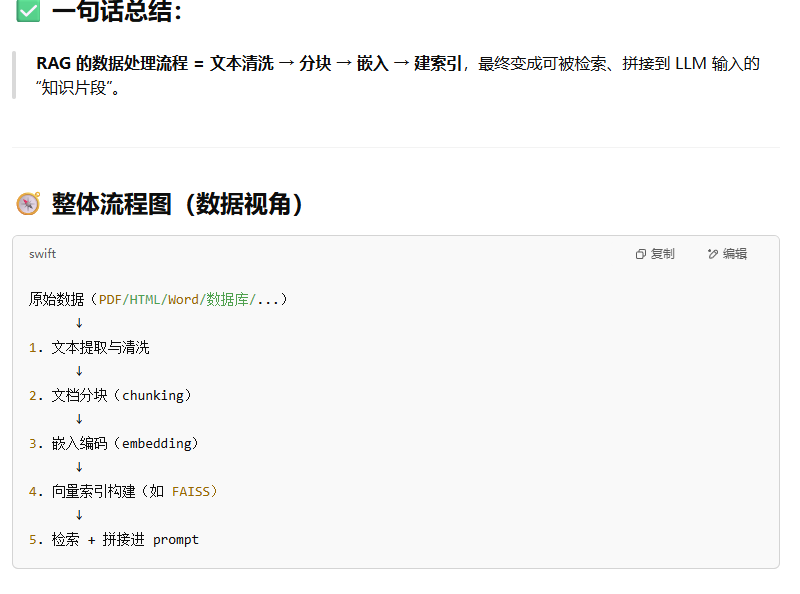
RAG
rag数据处理



rag的embedding模型
rag如何优化,数据,微调
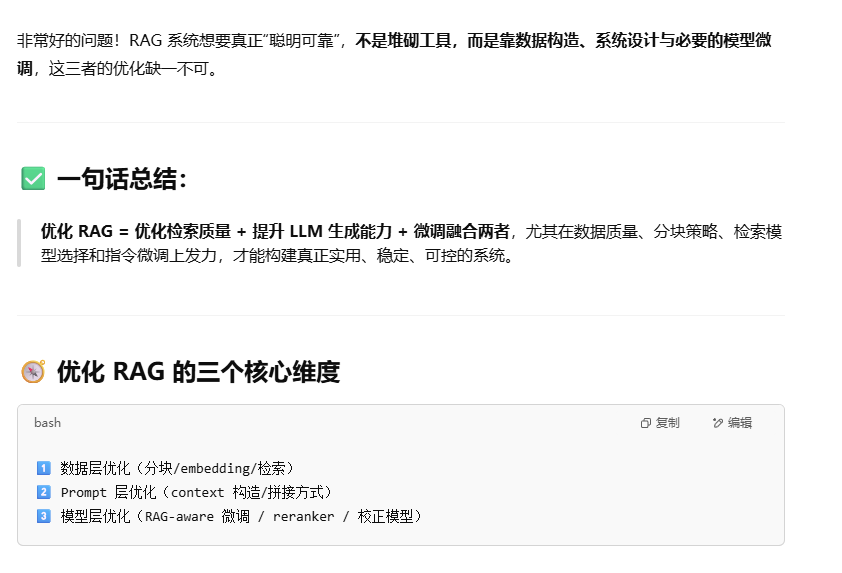
rag的召回准确率如何
RAG的优势和难点


模型的参数初始化?Lora的参数初始化?…

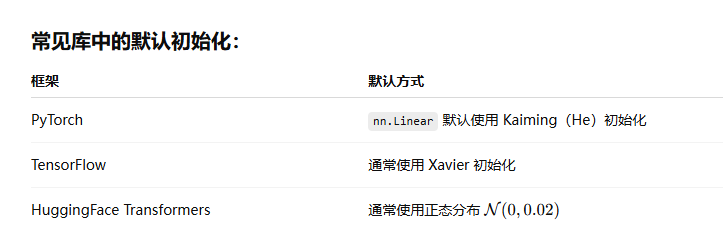

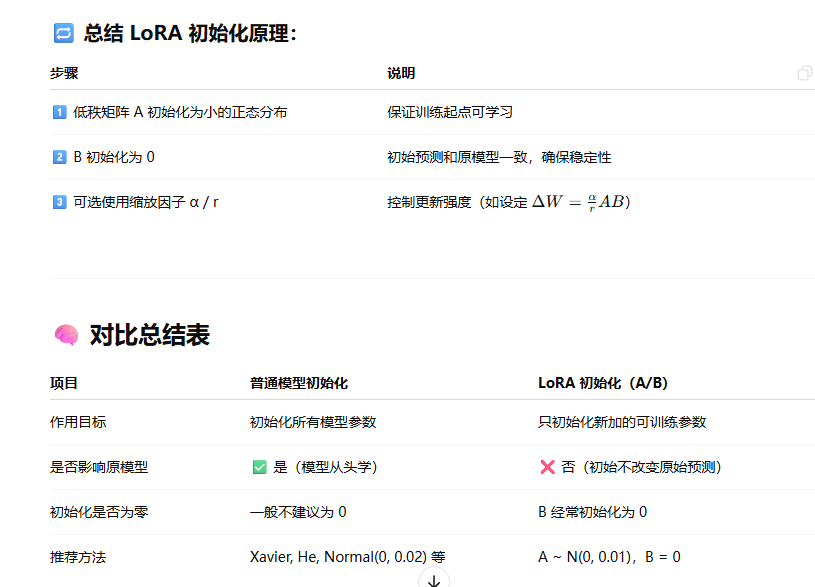

为什么初始化参数不能全为0?


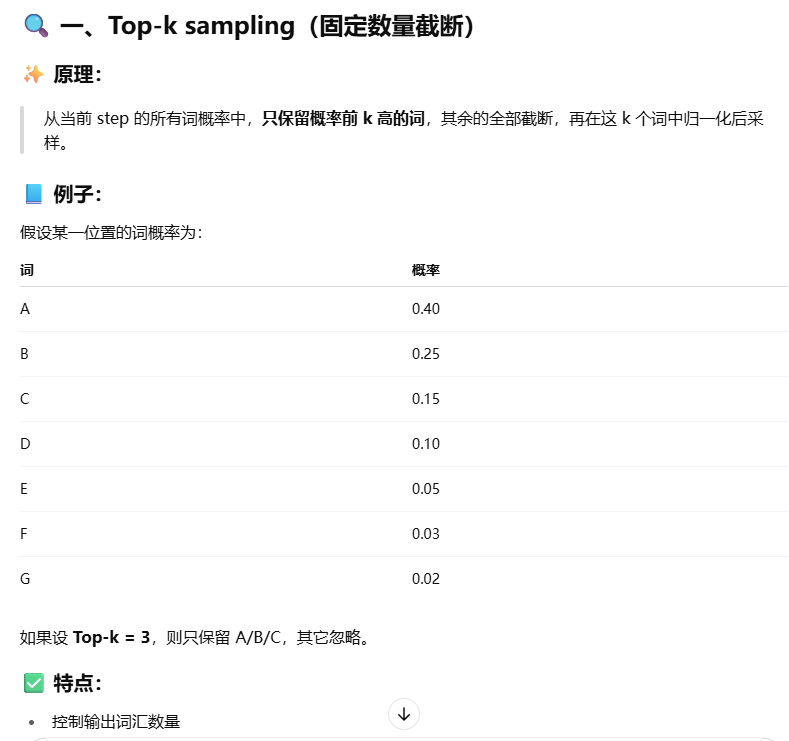
top-k和top-p

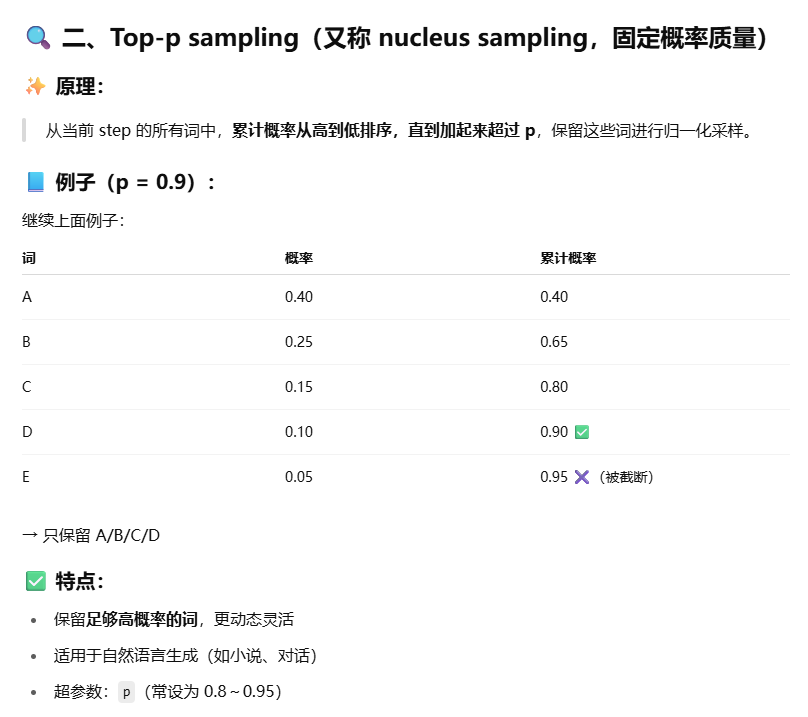
对比损失和llm中的temperature


训练样本的文本如何构建的,输出的格式



冻结矩阵的反量化如何实现

大模型的结构
GPT
Deepseek
Qwen
传统机器学习
SVM支持向量机

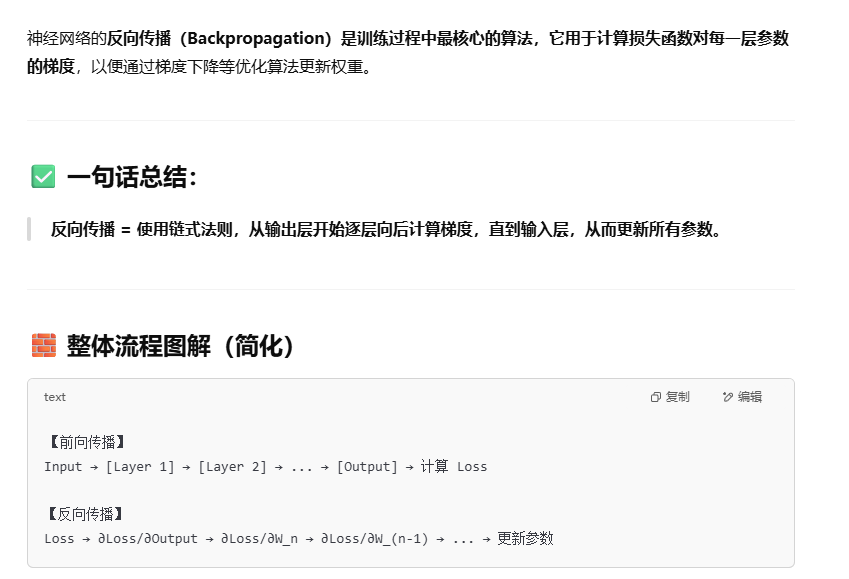
神经网络反向传播的过程


正则化

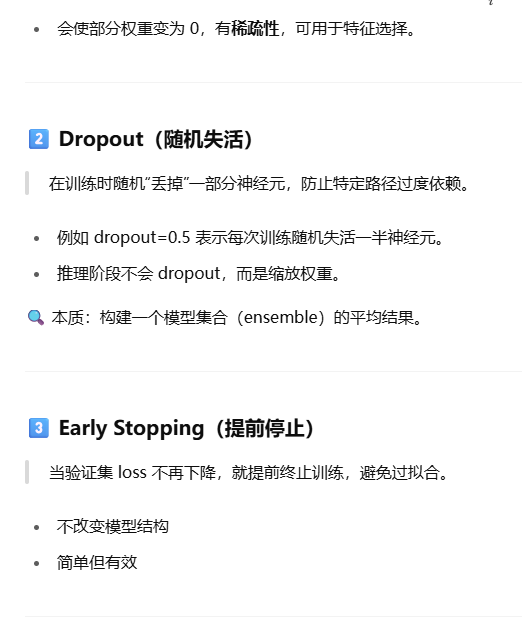


dropout

激活函数
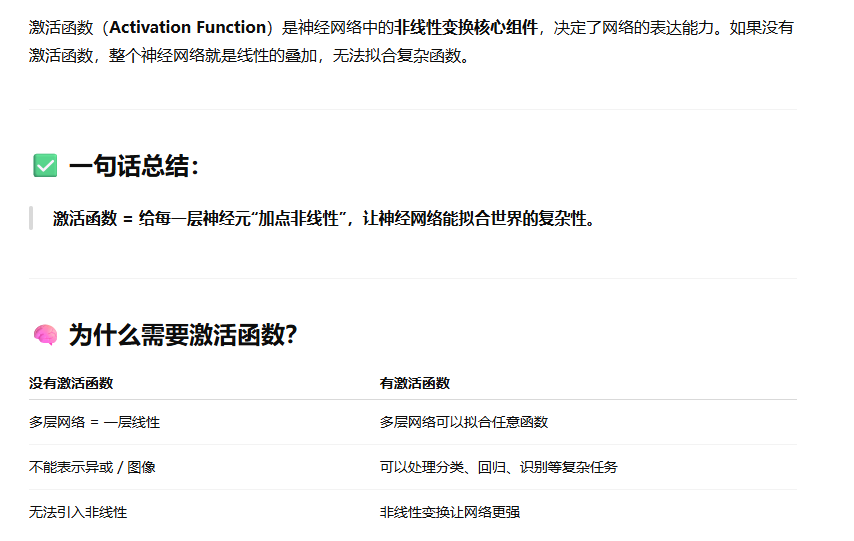

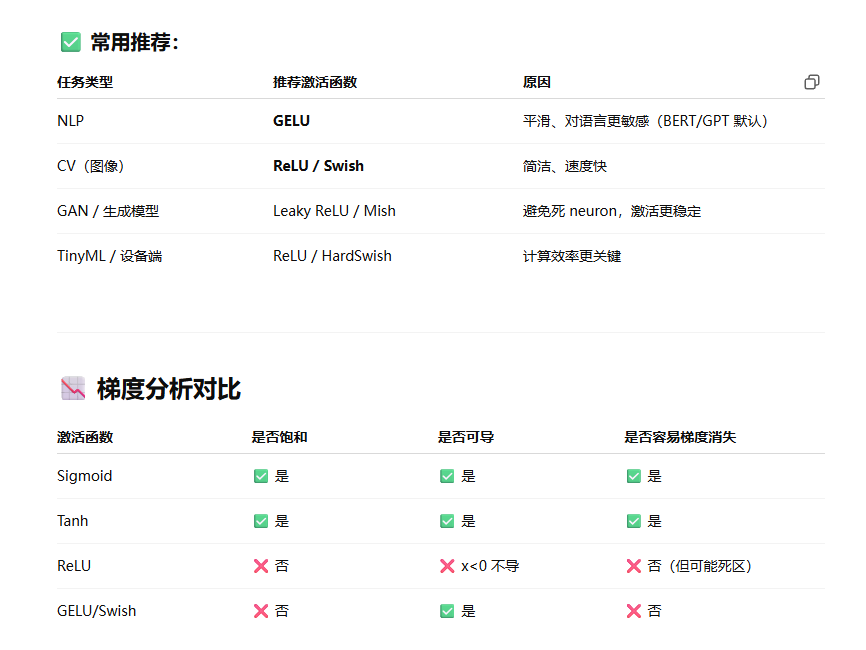
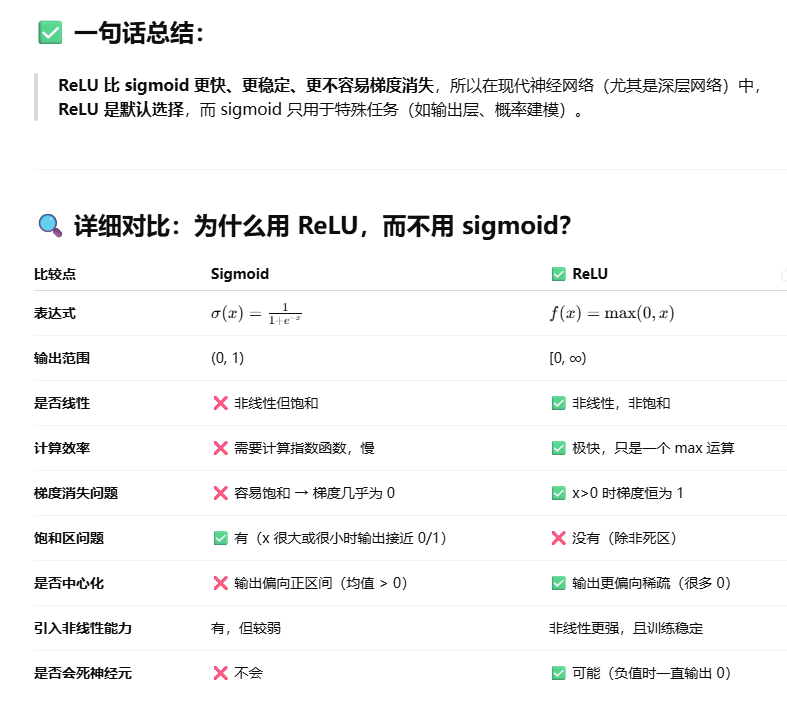
relu而不用sigmoid

强化学习
q-learning
DDPG
介绍Qlora,对什么进行4bit量化,lora初始矩阵是什么,lora矩阵的量化
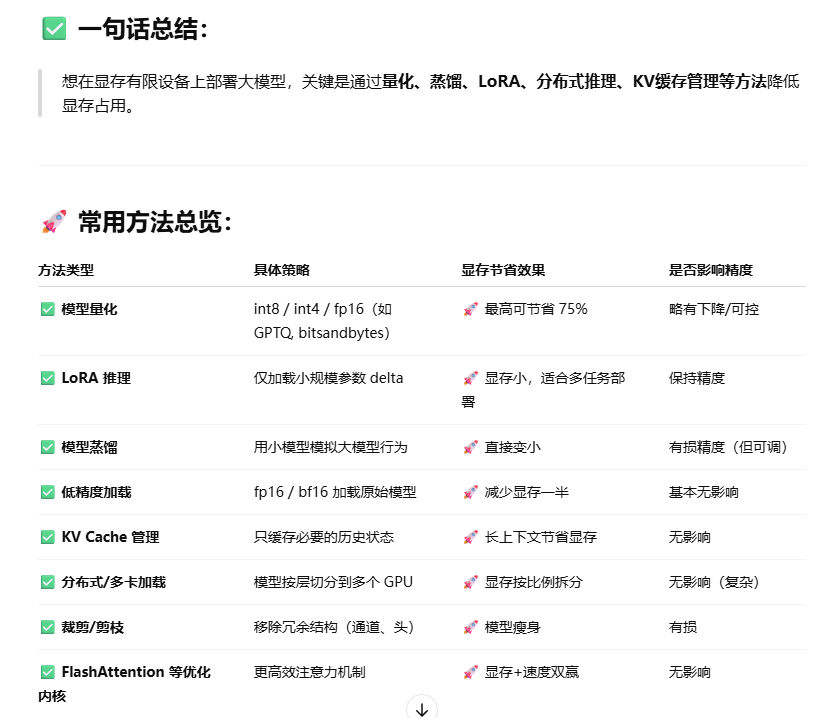
如何将参数较大的模型部署在显存有限的环境下
多卡微调
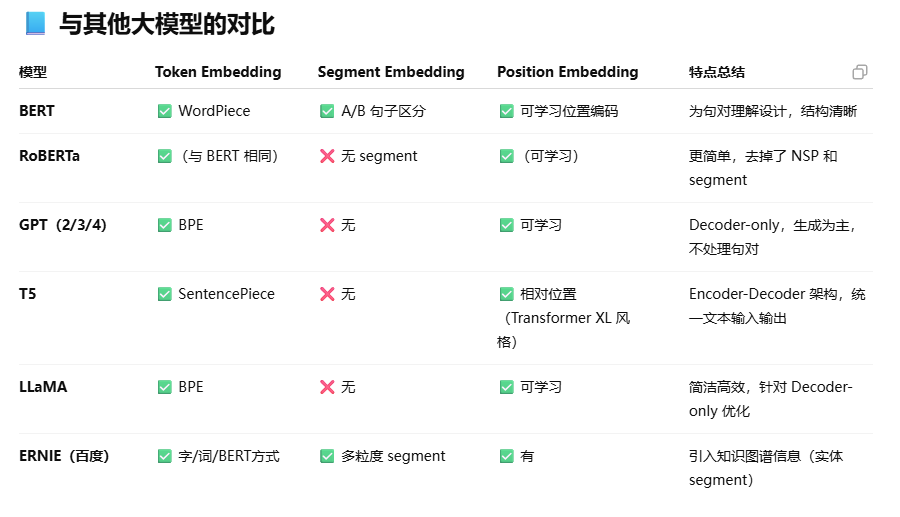
bert的input词向量和其他大模型的区别
transformer的MHA之后的FFN是如何训练的
超长文本推理
RoPE及各种变体,Sparse Attention,Leaky RoPE



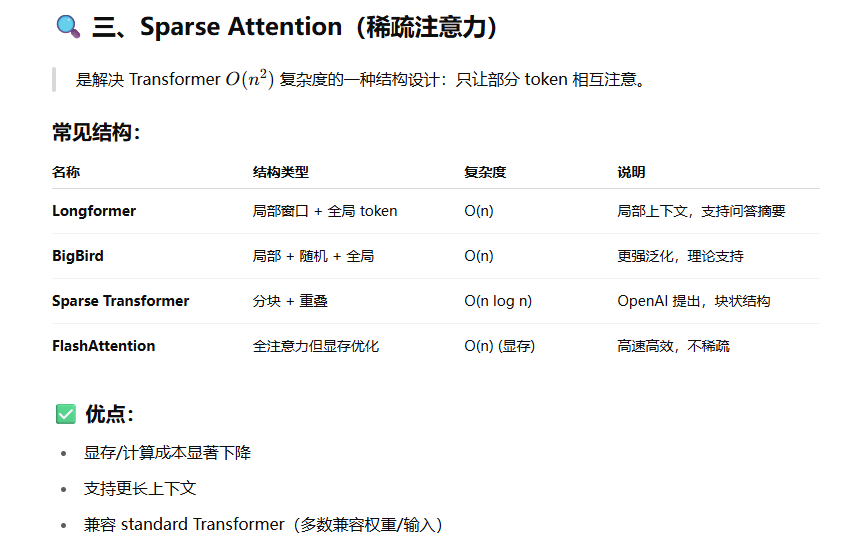
bert中随机mask了一些词,在代码中是如何体现的
如果位置编码按照1 2 3 4 5这样编码会出现什么问题?现在主流的位置编码有哪些?


固定正弦函数编码(原始论文)
可学习的位置编码(很多现代实现采用)
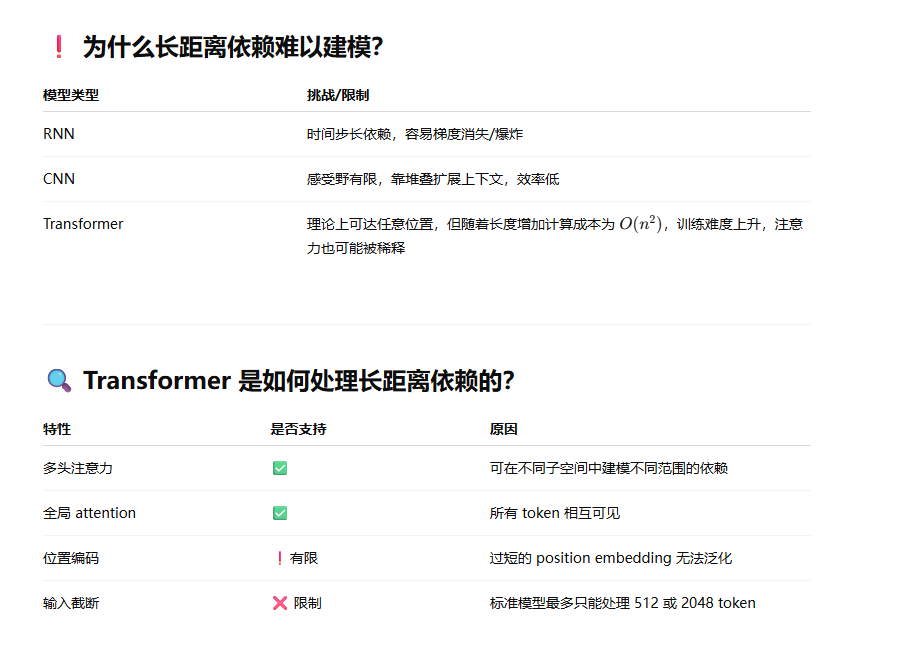
你怎么看待长距离依赖?






Bert与GPT的训练目标

Masked Language Modeling(MLM)
NSP(BERT 原版) 判断句子 B 是不是句子 A 的下一句(后来被 RoBERTa 弃用
GPT 的训练目标:Causal Language Modeling(CLM)
🧠 背后思想:
给定前文,预测下一个词:“续写下去”
softmax


KL散度


Agent的基本原理



multi-agent的设计
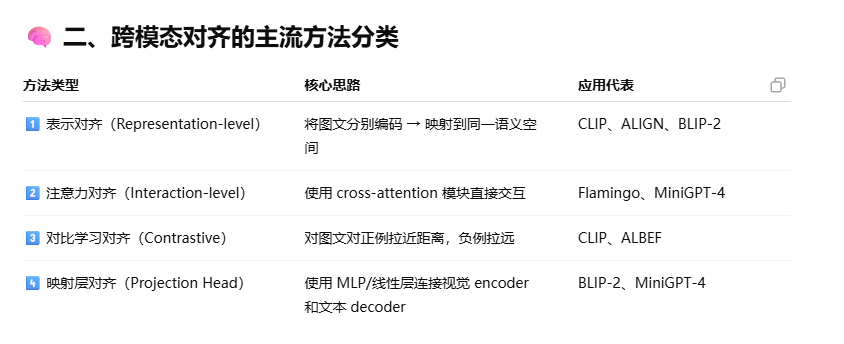
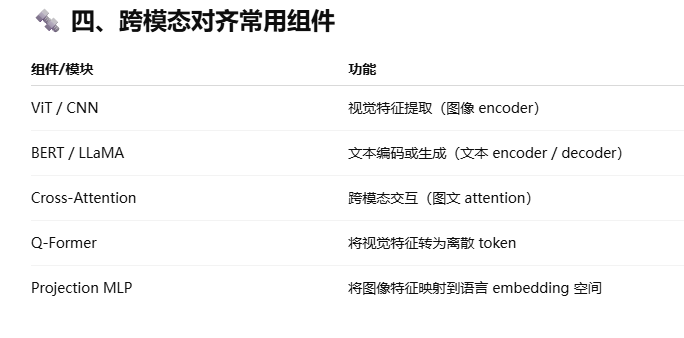
跨模态对齐


LSTM与bert

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 48
48 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)