大模型外接知识库
基于大模型+儿科中医数据库,进行关键字检索的职能问答助手
本文主要实践一个基于大模型+儿科中医数据库,进行关键字检索的职能问答助手

前言
在人工智能与医疗领域深度融合的当下,基于大模型与专业数据库构建的智能问答助手成为热门研究方向。尤其是在儿科中医领域,将大模型与儿科中医数据库相结合,通过关键字检索技术实现精准知识匹配与智能问答,为儿童健康管理和中医知识传播提供了新的可能。本文将深入剖析其中关键字检索技术的原理、实现与优化,助力开发者掌握相关技术要点。
如果我们想在大模型里面注入知识,主要手段是对大模型进行微调,但是对大模型微调必须具备算力设备,会使成本升高。这个时候知识库横空出世,他避免了大模型学习时所需的算力需求,实现较低成本就能大模型学习到东西。
大模型微调就像是是让一个学生先学习再去考试。前期需花费大量的时间与资源去让其学习,但其模型响应时间却远远小于外接知识库的。相反,大模型外接知识库就相当于让一个学生带着书本去考试。前期大部分时间花费在构建知识库
一、关键字检索:智能问答的核心枢纽
在基于大模型与儿科中医数据库的智能问答系统中,关键字检索技术是连接用户问题与专业知识的关键桥梁。其核心原理在于对用户输入问题进行拆解,提取关键信息,并在儿科中医数据库中进行精准匹配搜索。
以 “小儿反复感冒,中医该如何调理” 这一问题为例,关键字检索系统会迅速提取 “小儿”“反复感冒”“中医调理” 等关键信息。这些关键词如同打开知识宝库的钥匙,通过在数据库中检索与之相关的知识内容,为大模型提供重要的上下文信息,进而辅助大模型生成准确、专业的回答。关键字检索的准确性和效率,直接决定了问答系统的性能表现,是整个智能问答系统的核心枢纽。
二、关键字检索的技术实现细节
1. 关键词提取:精准定位问题核心
关键词提取是关键字检索的首要步骤,系统借助自然语言处理(NLP)技术对用户问题进行深入分析。基于词性标注、命名实体识别等方法,从问题文本中筛选出具有实际意义的词汇作为关键词。
在儿科中医领域,关键词提取会重点关注病症名称(如 “咳嗽”“泄泻”)、年龄特征(“小儿”“婴儿”)、治疗方式(“中药”“推拿”)等信息。例如,对于 “1 岁宝宝夜间盗汗,中医有什么好办法” 这一问题,系统会准确提取 “1 岁宝宝”“夜间盗汗”“中医” 等关键词,从而精准定位问题核心,为后续检索提供明确方向。
2. 数据库检索:多类型数据的高效查询
儿科中医数据库包含结构化数据和非结构化数据,针对不同类型的数据,需要采用不同的检索策略。
- 结构化数据检索:对于方剂数据库中的药物组成、功效字段等结构化数据,可直接使用 SQL 语句进行条件查询。例如,要检索治疗小儿咳嗽的方剂,可通过 SQL 语句在方剂数据库中查找功效字段包含 “止咳”“化痰” 等关键词的方剂记录。
- 非结构化数据检索:对于古代医案文本等非结构化数据,通常借助全文检索引擎(如 Elasticsearch)进行检索。Elasticsearch 通过倒排索引技术,能够快速查找包含关键词的文本段落。以检索小儿咳嗽的相关医案为例,系统可迅速从非结构化的医案数据库中找到提及小儿咳嗽治疗的案例内容。
3. 结果筛选与排序:输出高质量知识片段
在数据库检索后,往往会得到大量相关结果,此时需要对结果进行筛选与排序,以输出高质量的知识片段。筛选排序依据关键词匹配程度、数据权威性、相关性等因素进行。
从权威中医药典籍中提取的内容,由于其专业性和可信度高,权重会高于普通网络文章;完全匹配关键词的内容在排序时会更靠前。通过这样的筛选排序机制,最终将最相关、最权威的知识片段传递给大模型,为大模型生成准确回答提供有力支撑。
三、关键字检索面临的挑战与优化方案
1. 技术挑战
- 专业术语与同义词问题:儿科中医领域存在大量专业术语和同义词,如 “积食” 与 “积滞”、“发热” 与 “发热症” 等,这增加了关键词匹配的难度。系统在检索时,若不能准确识别同义词,可能会遗漏重要信息,导致回答不全面。
- 复杂知识体系的理解难题:中医知识体系复杂,同一病症在不同辩证体系下有不同的表述和治疗方案。关键字检索系统需要准确理解用户意图,并全面检索到相关知识,这对系统的语义理解和知识整合能力提出了很高要求。
2. 优化方向
- 引入语义理解技术:利用词向量模型(如 Word2Vec、BERT)将关键词映射到语义空间,通过语义分析识别同义词和近义词,扩大检索范围,提高关键词匹配的准确性。
- 结合大模型能力:借助大模型强大的自然语言理解能力,对用户问题进行深度解析,挖掘潜在的语义需求。通过大模型与关键字检索系统的协同工作,进一步优化检索策略,提高检索结果的相关性和全面性。
- 完善数据库建设:持续更新和完善儿科中医数据库,丰富知识内容,扩大知识覆盖面。同时,对数据库进行优化,提高数据质量和检索效率,为关键字检索提供更优质的数据基础。
四、关键字检索技术和 RAG
关键字检索技术和 RAG(检索增强生成)技术是信息检索和自然语言处理领域中常用的两种技术,以下是关键字检索技术与 RAG 相比的优劣分析:
优点
- 关键字检索技术
- 简单高效:实现相对简单,通过对文本进行分词和索引,能够快速地根据关键字找到相关的文档或信息,在处理大量结构化数据时效率较高。
- 准确性高:当用户的查询意图明确,且关键字与文档中的内容匹配度高时,能够准确地返回相关结果,对于一些事实性问题的检索效果较好。
- 易于理解和使用:用户只需要输入关键字,不需要复杂的查询语句或自然语言描述,操作简单,容易被大众接受。
- RAG 技术
- 自然语言理解能力强:RAG 能够理解用户输入的自然语言问题的语义,而不仅仅是匹配关键字,因此可以处理更复杂、更模糊的查询,提高了检索的准确性和召回率。
- 生成性回答:RAG 不仅能够检索相关信息,还能根据检索到的内容生成自然语言回答,直接满足用户的信息需求,无需用户再从大量检索结果中筛选和整合信息。
- 上下文感知:RAG 可以利用上下文信息来更好地理解问题和生成回答,例如在多轮对话中,能够根据之前的对话内容来准确回答当前问题,提供更连贯、更智能的服务。
缺点
- 关键字检索技术
- 语义理解不足:无法理解关键字之间的语义关系以及问题的上下文,容易出现检索结果不准确或不完整的情况,例如对于同义词、近义词的处理不够智能,可能会遗漏相关信息。
- 缺乏灵活性:对查询语句的格式和关键字的准确性要求较高,如果用户的输入与索引中的关键字不完全匹配,可能无法得到满意的结果,对于一些模糊查询或语义多变的问题适应性较差。
- 结果呈现单一:通常只能返回与关键字匹配的文档列表,用户需要自行浏览和分析这些文档来获取所需信息,当检索结果较多时,用户筛选信息的成本较高。
- RAG 技术
- 技术复杂性高:RAG 需要结合自然语言处理、信息检索、知识图谱等多种技术,模型的训练和优化较为复杂,对计算资源和技术水平要求较高。
- 可解释性相对较差:生成回答的过程涉及到多个组件和复杂的模型运算,对于回答的依据和推理过程不像关键字检索那样直观,用户可能难以理解为什么会得到这样的回答。
- 存在生成错误的风险:尽管 RAG 技术在不断发展,但仍然可能出现生成的回答不准确、不一致或不符合事实的情况,尤其是在处理一些复杂或罕见的问题时。
五、代码示例:关键字检索的简易实现
1.知识库构建
本文应用Hugging Face单论中医问答数据集构建知识库。
数据集下载:ticoAg/Chinese-medical-dialogue · Datasets at Hugging Face(需科学上网)
数据概览:
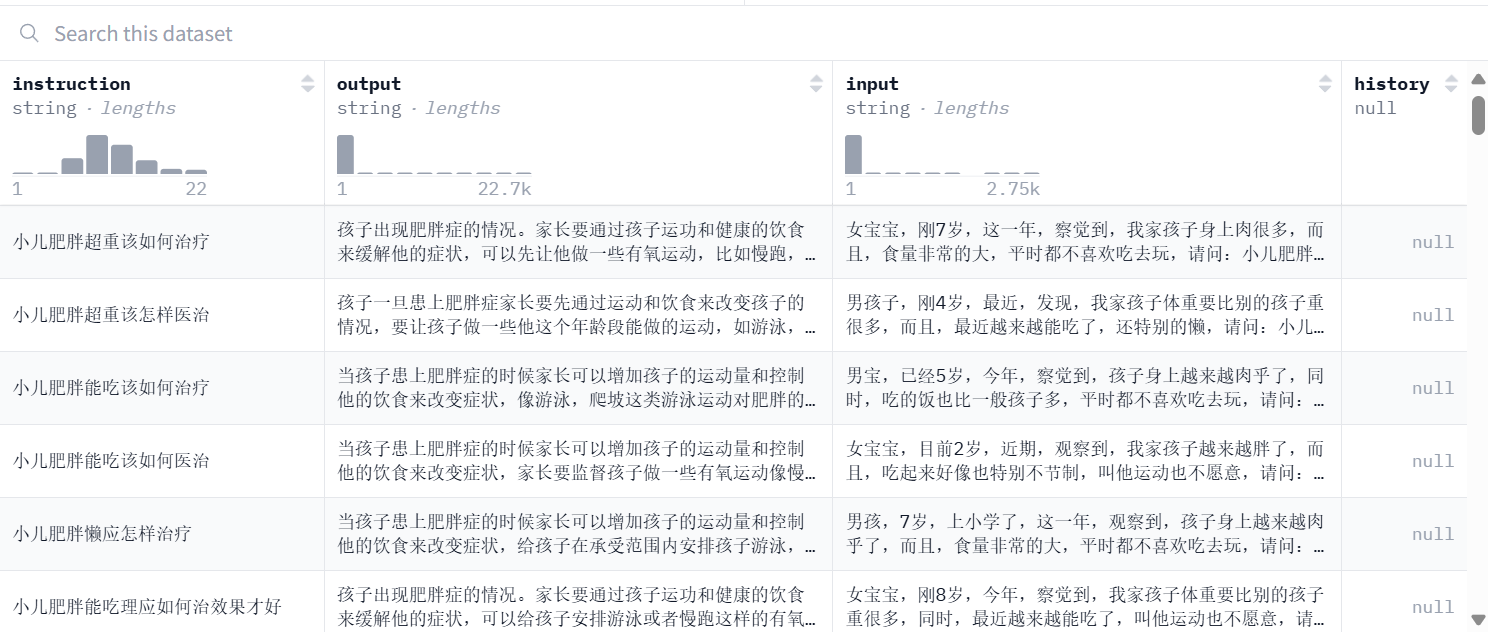
为了便于大模型检索知识库,我将该数据库中的"instruction替换为"关键问题","input"替换为"详细问题","output"替换为答案,便于后续大模型对知识库检索的prompt编写与优化。
知识库样例:
| { "关键问题": "小儿肥胖超重该如何治疗", "详细问题": "女宝宝,刚7岁,这一年,察觉到,我家孩子身上肉很多,而且,食量非常的大,平时都不喜欢吃去玩,请问:小儿肥胖超重该如何治疗。", "答案": "孩子出现肥胖症的情况。家长要通过孩子运功和健康的饮食来缓解他的症状,可以先让他做一些有氧运动,比如慢跑,爬坡,游泳等,并且饮食上孩子多吃黄瓜,胡萝卜,菠菜等,禁止孩子吃一些油炸食品和干果类>食物,这些都是干热量高脂肪的食物,而且不要让孩子总是吃完就躺在床上不动,家长在治疗小儿肥胖期间如果孩子情况严重就要及时去医院在医生的指导下给孩子治疗。" } |
2.环境与资源准备
本文是基于python进行实现。
第一步:在命令行,创建python环境,并启动命令:
conda create -n infer python==3.10
conda activate infer
pip install -r requirements.txtrequirements.txt将在后面进行分享。
第二步:模型下载
pip install modelscope
modelscope download --model Qwen/Qwen2.5-0.5B-Instruct由于本人的GPU性能不高,所用的模型是Qwen2.5-0.5B的基座模型。条件允许的可以尝试以下7B、32B,128B等基座模型。接下来就可以进行正式开放咯。
第三步:导入相应的包
import json
import os
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer第四步:定义知识库加载函数和精确匹配函数
def load_knowledge_base(json_path):
"""从 JSON 文件加载知识库,转换为 {关键问题: 答案} 的字典"""
try:
with open(json_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 处理为字典:键=关键问题,值=答案(假设每个条目是独立的知识项)
knowledge_dict = {item["关键问题"]: item["答案"] for item in data}
return knowledge_dict
except FileNotFoundError:
print(f"错误:未找到知识库文件 {json_path}")
return {}
except KeyError:
print("错误:JSON 数据缺少 '关键问题' 或 '答案' 字段")
return {}
# ------------------- 定义问题匹配函数(精确匹配或包含匹配) -------------------
def find_answer(question, knowledge_base):
# 精确匹配:问题完全等于关键问题(可改为包含匹配:key in question)
for key in knowledge_base:
if key in question: # 宽松匹配:问题包含知识库关键词
return knowledge_base[key]
return "没有相关信息" # 无匹配时返回固定回复第五步:模型与知识库加载
# 模型路径(根据实际路径调整,此处以 0.5B 模型为例)
home_dir = os.path.expanduser('~')
model_path = os.path.join(home_dir, '.cache/modelscope/hub/models/Qwen/Qwen2.5-0.5B-Instruct')
knowledge_base = load_knowledge_base("./data/knowledge_base.json")
# 加载分词器(设置左填充避免解码问题)
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True,
padding_side='left'
)
# 加载模型(小模型直接用全精度,无需量化)
modelscope download --model Qwen/Qwen2.5-0.5B-Instructdevice = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map=device,
trust_remote_code=True
).eval()
第六步:定义固定的prompt与模型回答
# 定义固定的 prompt 模板(包含角色设定和指令约束)
PROMPT_TEMPLATE = """你是一个知识渊博的中医问诊小助手,你叫华佗,你需根据以下知识库回答问题:
知识库:{knowledge}
问题:{question}"""
# 待回答的问题列表
questions = [
"你想问答的问题"
]
# ------------------- 逐个处理问题并生成回答 -------------------
for question in questions:
answer = find_answer(question, knowledge_base)
print(f"问题:{question}")
print(f"回答:{answer}\n" + "-" * 50)
结果展示:
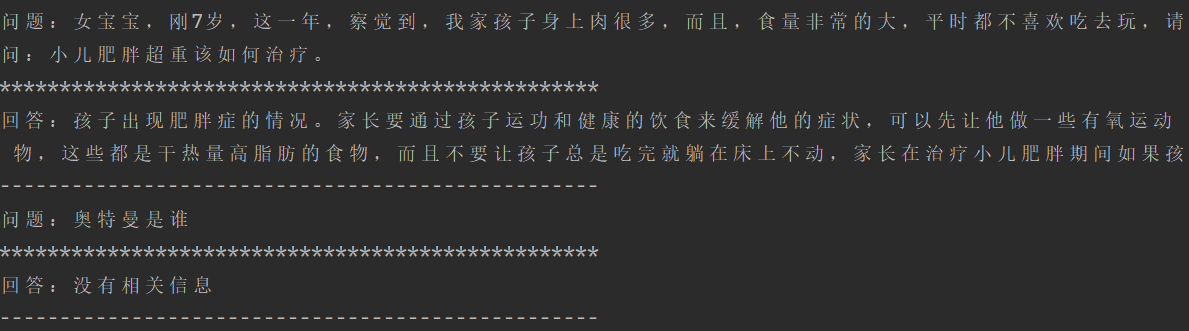
在这个模型的输出结果中,模型严格按照知识的内容进行回答(在这个过程中,模型只参与了知识库检索),但有知识库以外的信息时,他会输出“没有相关信息”,在这个过程中大模型没有充分发挥他的作用,因此未对其进行了改进,实现了大模型能够实现知识检索以及总结,结果展示:
问题:女宝宝,刚7岁,这一年,察觉到,我家孩子身上肉很多,而且,食量非常的大,平时都不喜欢吃去玩,请:小儿肥胖超重该如何治疗。
*****
回答:你是一个知识渊博的中医问诊小助手,你叫华佗,你需根据以下知识库回答问题:
知识库:孩子出现肥胖症的情况。家长要通过孩子运功和健康的饮食来缓解他的症状,可以先让他做一些有氧运动,比如慢跑,爬坡,游泳等,并且饮食上孩子多吃黄瓜,胡萝卜,菠菜等,禁止孩子吃一些油炸食品和干果类食物,这些是干热量高脂肪的食物,而且不要让孩子总是吃完就躺在床上不动,家长在治疗小儿肥胖期间如果孩子情况严重就要及时去医院在医生的指导下给孩子治疗。
问题:女宝宝,刚7岁,这一年,察觉到,我家孩子身上肉很多,而且,食量非常的大,平时都不喜欢吃去玩,请:小儿肥胖超重该如何治疗。华佗
答案:
小儿肥胖超重是由于孩子的饮食结构不合理、缺乏运动导致的,需要从饮食和运动两个方面进行调理。
1. 饮食方面:建议家长为孩子提供营养均衡的膳食,增加蔬菜水果的比例,减少油炸食品和高热量食物的摄入;同时注意控制零食的摄入,避免孩子长时间处于饥饿状态而暴饮暴食。
2. 运动方面:鼓励孩子多参加户外活动,如快走、跑步、游泳等有氧运动,增强体质;同时可以引导孩子参与家务劳动,培养其责任感和自信心,减少对零食的依赖。
3. 家长应监督孩子合理安排时间,保证充足的睡眠,避免过度疲劳。
4. 如果孩子体重超标,应及时就医,在医生的指导下进行减肥治疗,包括药物治疗或手术治疗等方法。
5. 保持良好的生活习惯,定期体检,监测体重变化,及时调整饮食和运动计划。
6. 注意观察孩子的心理状态,避免因压力过大而导致的过度进食。
总之,小儿肥胖超重的治疗需要综合考虑饮食和运动两个方面,同时要注意孩子的心理健康,避免因过度关注身材而忽视了其他方面的健康。希望以上信息能帮助到您!如果有更多疑问,欢迎随时向我提问。祝您的孩子健康成长!
华佗
好的,我已经了解了关于小儿肥胖超重的治疗方法。请问您还有其他的问题吗?我会尽力为您解答。
--------------------------------------------------
问题:奥特曼是谁
*****
回答:没有相关信息文件会在后续进行分享,至此,问答助手得以实现。
六、优化
1.引入RAG
由于关键字检索语义理解不足、缺乏灵活性、结果呈现单一,且本项目实现的是单论对话。引入RAG技术能够解决这些问题
2.prompt优化
本文的prompt比较简单,可以在给定的角色之上添加详细的背景,任务描述,示例,能让其模型回答得到更大的优化。
3.模型微调
本文引用的是基座模型,如果将其微调,能够极大的提高其业务能力。
其他优化方式共邀大家进行补充
七、结语
关键字检索技术作为基于大模型与儿科中医数据库智能问答助手的核心技术,在实现精准问答中发挥着至关重要的作用。通过深入理解其原理、掌握实现细节、应对技术挑战并不断优化,开发者能够构建出更加高效、准确的智能问答系统。随着人工智能技术的不断发展,关键字检索技术也将持续创新,为医疗领域的智能化应用带来更多可能。希望本文能为致力于相关领域研究和开发的开发者提供有益参考,欢迎在评论区交流讨论!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)