情境学习蒸馏:迁移预训练语言模型的少样本学习能力
鉴于大型预训练语言模型在情境学习方面取得的成功,我们提出情境学习蒸馏方法,将大模型的少样本情境学习能力迁移至小模型。该方法通过结合情境学习目标与语言建模目标,使小模型既能理解上下文示例又能掌握任务知识。我们在两种少样本学习范式下实施蒸馏:元情境微调(Meta-ICT)和多任务情境微调(Multitask-ICT)。实验表明,Multitask-ICT在多任务少样本学习中表现更优,但计算开销大于Me
In-context Learning Distillation: Transferring Few-shot Learning Ability of Pre-trained Language Models
机构:哥伦比亚大学 时间:2022年
老师模型:BERT-large[3.36亿参数] 学生模型:包括BERT-small[2500万参数 13.4倍-性能0.72
老师模型:GPT2-large[7.74亿参数] 学生模型:GPT2-small[1.24亿参数 6.24倍-性能0.92
代码:无
Abstract
鉴于大型预训练语言模型在情境学习方面取得的成功,我们提出情境学习蒸馏方法,将大模型的少样本情境学习能力迁移至小模型。该方法通过结合情境学习目标与语言建模目标,使小模型既能理解上下文示例又能掌握任务知识。我们在两种少样本学习范式下实施蒸馏:元情境微调(Meta-ICT)和多任务情境微调(Multitask-ICT)。实验表明,Multitask-ICT在多任务少样本学习中表现更优,但计算开销大于Meta-ICT。在LAMA和CrossFit两个基准测试中,我们的方法对两种范式均带来稳定提升。深入实验与分析揭示:在Multitask-ICT范式下,情境学习目标与语言建模目标具有互补性——当二者结合时,情境学习目标能实现最佳性能。
1 Introduction
大型语言模型展现出令人瞩目的情境学习能力,仅需基于少量输入输出示例(演示)而不更新任何参数,即可完成少样本学习。然而,尽管这类模型在少样本学习方面表现卓越,其庞大的计算资源需求严重制约了自然语言处理技术的大众化普及。以GPT-3为代表的模型因内存占用过高,仅能部署于超大规模服务器集群,且低效的推理性能使其无法应用于实时系统。
这自然引出一个关键问题:少样本学习能力能否从大模型迁移至小模型?知识蒸馏(KD)技术已被广泛证实能有效实现知识迁移——通过指导学生模型模仿教师模型的行为。现有零样本/少样本蒸馏方法(Rashid等,2021;Yoo等,2021)通常利用教师模型进行数据增强,但鲜有研究专注于直接迁移少样本学习能力。更值得注意的是,这些学生模型往往仅针对单一任务进行优化,面对多任务少样本学习场景时,不得不训练和部署多个专用模型,导致效率低下。小模型在大语言模型指导下如何实现多任务少样本学习,这一重要课题至今尚未得到充分探索。
针对这一问题,我们创新性地提出情境学习蒸馏方法,旨在实现大模型向小模型的多任务少样本学习能力迁移。该方法通过协同优化情境学习目标与语言建模目标的双重机制,实现高效的知识迁移:一方面,情境学习蒸馏使学生模型能够基于上下文示例准确推断任务需求,并激活其内部相关的知识表征;另一方面,语言建模目标则为训练任务提供语义层面的补充信息,形成知识迁移的完整闭环。
我们对小样本学习的迁移能力进行了研究,重点对比了两种不同的小样本学习范式:元上下文调优(Meta-ICT)和多任务上下文调优(Multitask-ICT)。在元上下文调优中(Chen等,2022c;Min等,2022b),语言模型通过上下文学习目标在大量任务集合上进行元训练,随后通过上下文学习适应未见过的目标任务。然而,上下文学习主要依赖于预训练阶段获得的知识(Reynolds和McDonell,2021),未能充分利用训练数据中提供的输入-标签对应关系信息(Min等,2022c)。为了更好地利用小样本训练示例中的此类信息,我们提出了另一种小样本学习范式——多任务上下文调优。该范式首先通过目标任务的小样本示例进行上下文学习目标调优,随后再通过上下文学习进行预测。实验表明,多任务上下文调优虽然性能优于元上下文调优,但在任务适应阶段需要更多的计算资源——这两种小样本学习范式在性能与计算成本之间存在着权衡关系。
我们在LAMA和CrossFit两个基准测试上,针对这两种小样本学习范式进行了上下文学习蒸馏实验。实验数据涵盖:LAMA基准中41项不同的常识与事实理解任务,以及CrossFit基准中53项现实任务(包括分类、自然语言推理、问答等)。相比无教师监督的上下文调优方法,我们在两个基准上均取得了稳定提升。对于多任务上下文调优(Multitask-ICT),模型体积可缩减93%的同时保持教师模型91.4%的性能;当模型体积缩减68%或更低时,学生模型性能甚至能超越教师模型。
本研究主要贡献包括:
-
提出上下文学习蒸馏框架,通过师生学习机制将大语言模型的小样本学习能力迁移至小模型;
-
提出新型小样本学习范式多任务上下文调优,其性能显著优于传统小样本监督微调与元上下文调优;
-
通过大量实验从蒸馏视角揭示:上下文学习目标与语言建模目标具有互补性。
2 Related Work
2.1 Knowledge Distillation
语言模型知识蒸馏
知识蒸馏(Knowledge Distillation, KD)最初由Hinton等人(2015)提出,通过教师模型预测的软目标(soft-targets),将高容量教师模型的知识迁移至低容量学生模型。该方法在预训练语言模型领域得到广泛研究:可在预训练阶段应用(如Distill-BERT,Sanh等,2019)、微调阶段应用(如BERT-PKD,Sun等,2019),或两者兼用(如Tiny-BERT,Jiao等,2020;Distill-GPT2,Li等,2021)。
知识蒸馏的目标函数
传统知识蒸馏通过联合优化两个目标训练学生模型:任务标签的预测损失(硬标签)与教师模型最终层输出的预测损失(软标签)。为提升知识迁移效果,学界对蒸馏目标函数进行了诸多改进:部分研究(Haidar等,2022a;Sun等,2019;Haidar等,2022b;Wu等,2021;Xu等,2020)通过匹配中间层输出引入隐藏层知识;另有方法(Jafari等,2021;Mukherjee与Hassan Awadallah,2020;Lu等,2021)通过调整硬标签与软标签损失的权重实现选择性知识迁移;还有工作(Rezagholizadeh等,2022;Zhou等,2022)通过优化教师模型目标函数以更好匹配学生模型。这些改进均基于任务特定目标,而本研究首次探索了知识蒸馏中上下文学习目标的应用。
零样本/小样本知识蒸馏
现有自然语言处理领域的零样本/小样本知识蒸馏方法(Rashid等,2021;Yoo等,2021;He等,2021)主要聚焦于在任务数据缺失时利用教师模型生成合成数据。与之不同,我们直接迁移教师模型的小样本学习能力至学生模型。此外,现有方法的学生模型仅针对单一任务优化,而我们的学生模型具备任务无关特性。
2.2 In-context Learning
上下文学习的应用与改进
上下文学习(Brown等,2020)通过将任务中的输入-标签示例拼接后进行推理来实现小样本学习,而无需更新语言模型参数。后续研究(Zhao等,2021;Holtzman等,2021;Min等,2022a)通过重构上下文学习机制进一步提升了小样本学习效果。除小样本学习外,该方法还可用于数据增强(Yoo等,2021;Chen等,2022a)。
上下文学习的稳定性优化
研究发现,上下文学习对示例选择存在过度敏感和不稳定的问题(Lu等,2022;Zhao等,2021;Chen等,2022b)。为此,部分工作通过优化示例选择策略显著提升了性能(Rubin等,2022;Liu等,2022;Lu等,2022)。同时,元上下文调优(Chen等,2022c;Min等,2022b)通过在多任务上采用显式上下文学习目标进行元训练,有效增强了模型的上下文学习能力并降低了敏感性。本研究创新性地通过引入大模型监督机制,进一步提升了模型的上下文学习能力。
3 In-context Tuning Paradigms
本节首先阐述上下文学习(in-context learning)与上下文调优(in-context tuning)的背景知识,随后系统介绍两种小样本学习范式:元上下文调优(Meta-ICT)和多任务上下文调优(Multitask-ICT)。其中,Meta-ICT作为现有算法(Min等,2022b;Chen等,2022c)通过基于上下文学习目标的元训练来增强语言模型的上下文学习能力;而Multitask-ICT则是我们新提出的方法,其通过优化上下文学习目标使语言模型适配小样本学习任务。最后,我们对这两种范式进行系统性对比分析。
3.1 Background: In-context Learning/Tuning
上下文学习(In-context learning)是指模型通过基于少量输入-标签对进行条件建模,从而学习对目标任务中的文本输入进行预测的过程。形式化定义为:设k为演示样本数量,![]() 表示来自目标任务的训练样本,(x_{k+1}, y_{k+1})为测试样本,其中x_i为文本输入,y_i为对应标签。模型接收由x_1, y_1, ..., x_k, y_k, x_{k+1}拼接而成的输入序列,并预测y_{k+1}的值。
表示来自目标任务的训练样本,(x_{k+1}, y_{k+1})为测试样本,其中x_i为文本输入,y_i为对应标签。模型接收由x_1, y_1, ..., x_k, y_k, x_{k+1}拼接而成的输入序列,并预测y_{k+1}的值。
上下文调优(In-context tuning)通过上下文学习目标对语言模型进行优化。具体而言,给定训练任务T中的样本集![]() ,模型接收由x_1, y_1, ..., x_k, y_k, x{k+1}组成的输入序列,并以负对数似然为目标训练生成y_{k+1}的能力。形式化定义如下:设上下文示例数量为k,对于任务T中的每个输入文本x,其对应的演示样本集S_k^x由从同一任务T中采样的k个输入-输出对构成,则该任务的上下文学习目标函数可表示为:
,模型接收由x_1, y_1, ..., x_k, y_k, x{k+1}组成的输入序列,并以负对数似然为目标训练生成y_{k+1}的能力。形式化定义如下:设上下文示例数量为k,对于任务T中的每个输入文本x,其对应的演示样本集S_k^x由从同一任务T中采样的k个输入-输出对构成,则该任务的上下文学习目标函数可表示为:
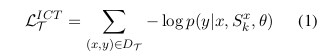
θ为模型的参数。
3.2 Background: Meta In-context Tuning
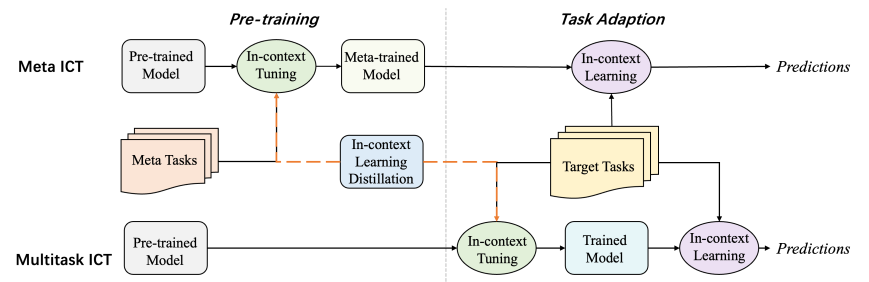
图1:元上下文调优(Meta-ICT)与多任务上下文调优(Multitask-ICT)的范式对比示意图。虚线标注的上下文学习蒸馏过程展示了两种范式中知识蒸馏的实现路径。
元上下文调优(Meta-ICT)通过在大量任务集合上基于上下文学习目标训练模型,使模型学会通过上下文学习自适应新任务。因此,我们将该训练过程称为元训练(meta-training),对应的训练任务称为元训练任务集T_meta。随后,模型可通过上下文学习对未见过的目标任务集T_target进行预测。如图1所示,Meta-ICT的整体目标函数L_ICT^meta是各元训练任务上下文学习目标(式1)的累加和:
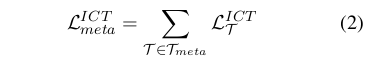
已有研究证明,基于上下文学习目标进行元训练能够有效缓解模型对示例顺序、示例选择和指令措辞的过度敏感性(Chen等,2022c),然而在任务适应阶段采用的上下文学习方法会忽略输入训练数据中的部分标签信息(Min等,2022c),从而导致模型未能充分利用小样本训练示例的全部价值。
3.3 Proposed: Multitask In-context Tuning
为更充分挖掘小样本训练数据中的信息,我们提出面向多任务小样本学习的多任务上下文调优方法(Multitask-ICT)。如图1所示,该方法通过两个步骤直接使模型适配目标任务集T_target:首先采用上下文调优方式利用目标任务的少量示例更新模型参数,随后通过上下文学习进行预测。其每个任务的目标函数同样遵循公式(1),与Meta-ICT保持一致,区别在于Multitask-ICT的总体目标函数是对所有目标任务(而非元训练任务)的损失求和:
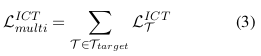
其中T_target为待评估的小样本目标任务集。
由于语言模型输入序列长度的限制,单个输入序列可能无法容纳全部小样本训练数据作为上下文示例,即训练样本数n可能大于上下文示例数k。针对这一矛盾,我们提出多数投票推理机制:从n个训练样本中随机抽取k个上下文示例进行m次预测,最终选择出现频率最高的预测结果。实验表明该策略能有效缓解模型对上下文示例选择的过度敏感性并提升性能。
3.4 Paradigm Comparison
如图1所示,虽然元上下文调优(Meta-ICT)和多任务上下文调优(Multitask-ICT)两种范式均通过优化上下文学习目标并基于上下文学习进行预测,但其在实施上下文调优的动机和方式上存在本质差异。两种范式的上下文调优目标具有根本区别:Meta-ICT旨在通过上下文调优使模型获得适应目标任务的能力,而Multitask-ICT则是为了直接学习目标任务本身。这种差异进一步体现在对训练任务与目标任务的处理方式上:首先,Multitask-ICT的训练任务即为其目标任务集T_target,而Meta-ICT的训练任务为与T_target无交集的元训练任务集T_meta;其次,Multitask-ICT用于模型更新的训练样本量极为有限,而Meta-ICT则可利用丰富的训练样本。
4 In-context Learning Distillation
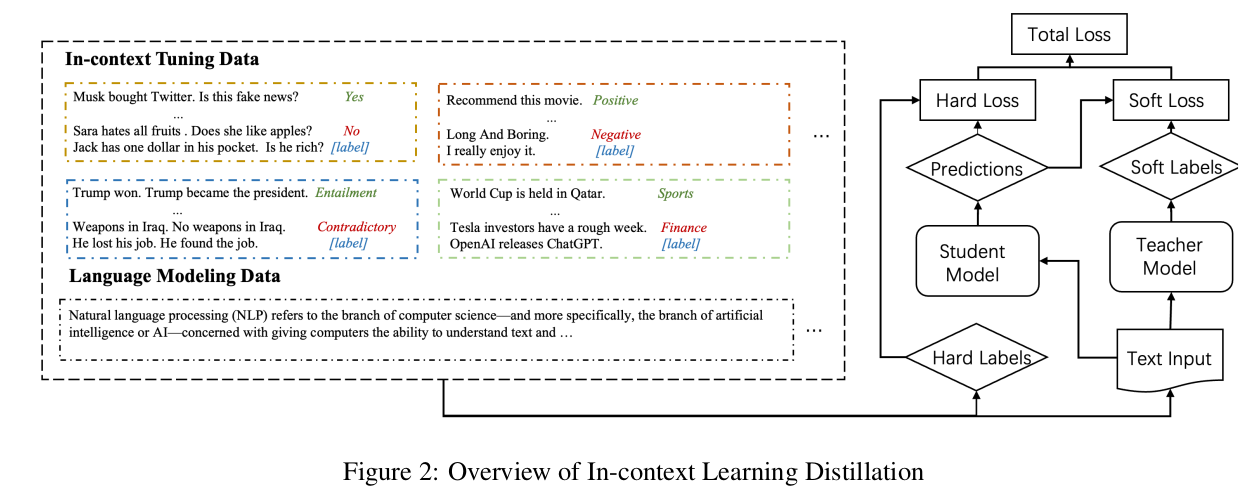
本研究提出上下文学习蒸馏方法,旨在将教师模型的少样本学习能力迁移至学生模型。如图2所示框架,我们通过联合优化上下文学习目标和语言建模目标实现蒸馏,该方法可兼容元上下文调优(Meta-ICT)与多任务上下文调优(Multitask-ICT)两种范式。如图1所示,在两种范式的上下文调优阶段均实施了上下文学习蒸馏。学生模型通过模仿教师模型的预测结果(软标签)进行学习,同时掌握上下文学习与语言建模能力。软标签损失函数L_soft用于度量师生模型预测差异,该损失由上下文学习目标L_ICT^soft和语言建模目标L_LM^soft共同构成。
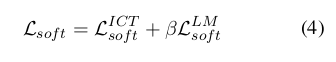
其中β是用于平衡上下文学习(in-context learning)与语言建模(language modeling)的超参数。上下文学习的目标函数可形式化表示为:
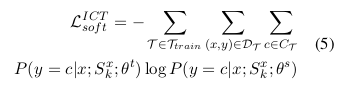
其中,T_train 表示上下文学习中的训练任务集。在元上下文调优(Meta-ICT)中 T_train 对应元训练任务集 T_meta,而在多任务上下文调优(Multitask-ICT)中则对应目标任务集 T_target。
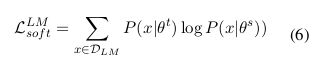
除学习教师模型的预测结果外,学生模型还需从真实标签(硬标签)中学习。硬损失函数通过对比学生模型预测与真实标签的差异来衡量其性能,该损失同样由上下文学习目标与语言建模目标共同构成。
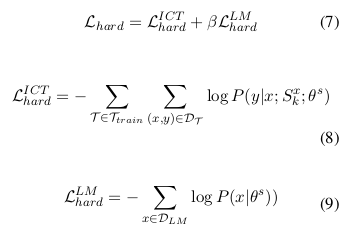
上下文学习蒸馏的最终目标函数可形式化表示为:
![]()
在训练过程中,我们采用线性调整策略:逐步降低硬标签损失(hard-label loss)的权重系数α(t),同时逐步提升软标签损失(soft-label loss)的权重。
5 Experiments
5.1 Datasets and metrics
本研究采用了两类不同的数据集集合:第一类为LAMA数据集(Petroni等人,2019b),包含41项针对事实性与常识知识理解的任务;第二类源自CrossFit(Ye等人,2021)——一个涵盖160项多样化小样本NLP任务的开放测试平台,我们从中选取了53项独特任务,涵盖文本分类、问答系统、自然语言推理及复述检测等类型。在评估指标方面,LAMA数据集采用平均首位精度(mean precision at one)与平均前十精度(mean precision at ten)作为度量标准,并报告跨任务平均得分;CrossFit数据集则根据任务类型差异,分别采用宏观F1值(Macro-F1)评估分类任务,准确率(Accuracy)评估非分类任务。
除上述用于上下文学习蒸馏的数据集外,本研究还引入语言建模辅助数据集以补充知识学习:针对LAMA实验采用WikiText(Merity等,2016),CrossFit实验则使用OpenWebText(Gokaslan等,2019)。具体数据集细节参见附录B。
5.2 Few-shot Learning Settings
本研究在两大基准测试(LAMA与CrossFit)上对比了两种范式(Meta-ICT与Multitask-ICT),共构建四种小样本学习实验设置:
设置1:LAMA上的Meta-ICT
将41项任务随机划分为30项元训练任务、5项验证任务与6项测试任务。模型在30项元训练任务上完成元训练后,在6项目标任务上测试。
设置2:CrossFit上的Meta-ICT
遵循Min等人(2022b)的"分类到分类"设定,43项元训练任务与20项目标任务均为分类任务。鉴于部分目标任务中师生模型表现接近随机猜测,最终筛选出11项双方均显著优于随机猜测的任务作为有效目标集。
设置3:LAMA上的Multitask-ICT
将全部41项LAMA任务作为目标集,随机划分60%数据用于测试,剩余40%数据中抽取32个训练样本与32个验证样本。
设置4:CrossFit上的Multitask-ICT
选取涵盖分类、问答、自然语言推理及复述检测的18项多样化任务作为目标集。
表1详细对比了四种设置的差异。针对设置2,我们沿用Min等人(2022b)提出的通道式上下文学习(channel in-context learning),即反转输入文本与标签的顺序。具体设置详见附录C,通道式上下文学习的完整说明参见附录D。
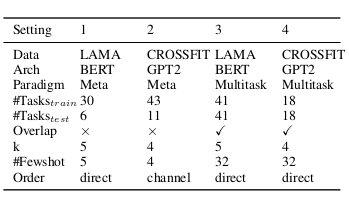
表1:四种小样本学习设置的对比分析。其中"Overlap"表示训练任务与目标任务是否存在重叠,"k"代表模型每次输入中包含的上下文示例数量,"#Few-shot"指每项任务可用的训练样本总数,"Order"则说明上下文学习中文本x与标签y的排列顺序。
5.3 Experiment Details
本研究全部实验均基于PyTorch与Transformers库实现。为验证方法的架构普适性,我们针对不同数据集采用不同骨干模型:在LAMA数据集上使用BERT系列模型(包括BERT-small[2500万参数]、BERT-base[1.1亿参数]、BERT-large[3.36亿参数]),在CrossFit数据集上则采用GPT2系列模型(含GPT2-small[1.24亿参数]、GPT2-medium[3.55亿参数]、GPT2-large[7.74亿参数])。具体超参数设置与训练细节详见附录A。
6 Results
我们首先在第6.1节对比三种小样本学习范式的性能差异,随后在第6.2节展示上下文学习蒸馏的实验结果,最终在第6.3节进行消融研究分析。
6.1 Few-shot learning paradigm comparison
本研究对比了三种小样本学习范式:多任务上下文调优(Multitask-ICT)、元上下文调优(Meta-ICT)以及多任务监督微调(Multitask-FT)。实验结果表明,Multitask-ICT在准确率上全面超越Meta-ICT。如表2所示,在三种模型规模下Multitask-ICT均表现更优,其中GPT2-medium模型上的性能差距高达9%。这种显著优势源于两者适配机制的差异:Multitask-ICT通过少量训练样本直接调整模型参数来适配目标任务,而Meta-ICT仅通过推理过程进行适配。这一结果证明,即使在训练样本有限的情况下,参数更新仍能带来显著增益。
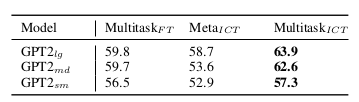
表2:三种小样本学习范式的实验结果对比。其中Multitask-FT表示基于小样本示例的多任务微调,Meta-ICT指元上下文调优,Multitask-ICT为多任务上下文调优。实验采用设置2的配置,从9项目标任务中各随机选取32个训练样本和32个验证样本进行测试,最终报告平均F1分数并以加粗形式标注最优性能指标。
进一步分析发现,Multitask-ICT在小样本场景下同样优于传统多任务微调(Multitask-FT)。表2数据显示,三种模型规模中Multitask-ICT均取得更好效果,这表明基于上下文学习目标的调优能更有效地利用有限样本。我们推测,这种优势源于上下文目标函数促使模型学习同一任务内数据点间的关联关系。在Multitask-ICT中,同任务的不同数据点被拼接为单一模型输入,使模型能够显式捕捉任务内部的数据关联;而传统多任务微调每次仅处理独立数据点,忽略了这种内在关联性。
6.2 Distillation Results
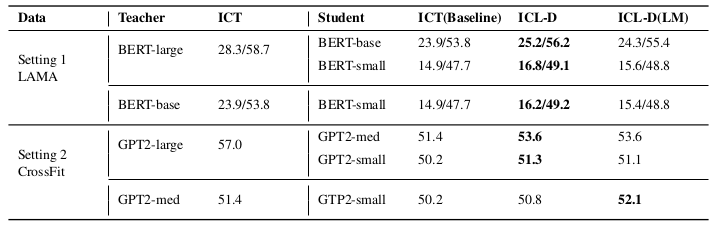
表3:元上下文调优范式下的蒸馏实验结果对比。其中ICT(基线方法)指无教师模型参与的纯上下文调优,ICL-D表示仅通过上下文学习目标进行蒸馏的方法,ICL-D(LM)则是同时结合上下文学习目标与语言建模目标的蒸馏方法。在LAMA数据集上,两组数值分别代表所有目标任务的平均首位精度(precision@1)与前十精度(precision@10),CrossFit数据集上的数值则为宏观F1均值(macro F1)。需特别说明的是,设置1采用k=5的5样本上下文学习,设置2则为k=4的4样本学习,表格中加粗数值标示各列最优结果。
如表3和表4所示,上下文学习蒸馏(ICL-D)在LAMA和CrossFit数据集上对两种上下文调优范式均实现了持续性的性能提升。在所有实验设置中,ICL-D均显著优于传统上下文调优方法(ICT),这一结果证实教师模型能够通过上下文学习目标有效传递有益知识。
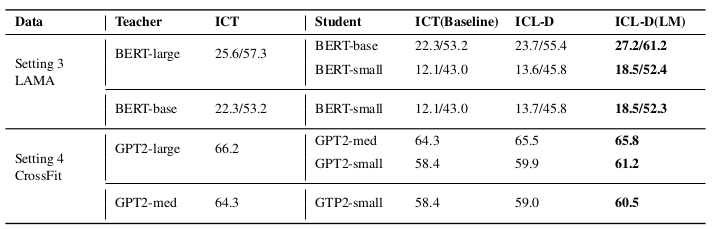
表4:多任务上下文调优范式下的蒸馏实验结果。其中ICT(基线方法)、ICL-D及ICL-D(LM)的定义与表3保持一致。实验从每项任务中随机选取32个训练样本和32个验证样本,评估指标及其缩写形式亦与表3相同。需要特别指出的是,虽然LAMA数据集采用k=5、CrossFit数据集采用k=4的上下文示例数量设置,但由于每项任务实际可使用32个训练样本,因此两种设置本质上均属于32样本学习范式。
语言建模蒸馏(LM)对Multitask-ICT范式提升尤为显著。表4显示,ICL-D(LM)在LAMA数据集上使BERT-base/BERT-small分别提升4.9/6.4分;在CrossFit数据集上,GPT2-medium/small亦分别提升1.5/2.8分。然而在Meta-ICT范式下,语言建模蒸馏反而导致5/6师生组合性能持平或下降,这可能源于元训练任务与目标任务的非重叠性——过度学习元训练内容会损害目标任务的泛化能力。
研究还发现,教师模型能力的增强未必带来学生性能提升。如表3设置2所示,当教师模型从GPT2-medium(3.55亿参数,准确率51.4)升级至GPT2-large(7.74亿参数,57.0)时,GPT2-small学生模型的性能波动不足1分。该现象与现有知识蒸馏研究(Sun等,2019;Yuan等,2019)结论一致,可能源于大教师模型的"硬知识"超出小学生的学习能力范围。
6.3 Ablation Study
我们通过系统探究元训练任务的数据点数量与任务规模对模型泛化能力的影响,深入分析了Meta-ICT在未知任务上的迁移性能。随后,我们进一步通过仅采用语言建模目标的蒸馏实验,揭示了语言建模目标对Multitask-ICT性能提升的作用机制。
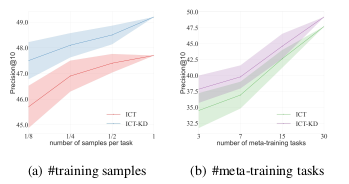
我们重点研究了每个元训练任务的样本数量对方法性能的影响。通过从各元训练任务中分别抽取[1/8, 1/4, 1/2, 1]比例的训练样本进行模型训练(各任务总样本量详见附录B),图3(a)显示当训练样本量变化时,ICL-D始终优于传统ICT方法。值得注意的是,即使仅使用1/8的训练样本,Meta-ICT的性能也未出现显著下降,这一现象表明Meta-ICT对元训练任务的具体内容依赖度较低。我们推测,在元训练过程中,模型更倾向于学习上下文示例的格式解析能力,而非记忆元训练任务的具体内容特征。
为深入探究元训练任务数量对模型性能的影响,我们在LAMA数据集设置中将元训练任务数量从3项逐步增加至30项进行实验。由于Meta-ICT对所选元训练任务的分布较为敏感,每种任务规模配置下均采用五组不同的随机任务集合进行测试。如图3(b)所示,无论元训练任务数量如何变化,本方法均能持续提升基线性能。当元训练任务数量较少时,ICL-D表现出更显著的改进效果,这表明教师模型的监督能在一定程度上弥补元训练任务的不足。需要特别指出的是,上下文调优性能更依赖于任务数量而非单任务的样本量——当仅使用1/8任务量时性能下降超过10%,而单任务样本量缩减至1/8时性能仅下降约2%,这一结果证实模型主要从任务分布中学习而非记忆具体任务内容。
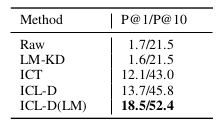
表5:设置3下语言建模蒸馏与其他上下文调优方法的对比结果。其中Raw表示未经任何微调的预训练语言模型,LM-KD指仅通过语言建模目标(不包含上下文学习目标)进行蒸馏后再执行上下文学习的方法,ICT为多任务上下文调优基线,ICL-D是标准上下文学习蒸馏,ICL-D(LM)则为结合语言建模蒸馏的改进方法。表格中加粗数值标示各列最优性能指标。
纯语言建模蒸馏实验表明,语言建模目标虽能为Multitask-ICT带来显著提升,但其单独作用时却表现出与未经训练的原始预训练语言模型相似的性能(如表5所示),远落后于其他上下文调优方法。这一现象与Shin等人(2022)关于语言建模能力与上下文学习效果非必然相关的研究结论相符,说明学生模型无法仅通过语言建模目标从教师模型提供的海量混杂信息中提取对目标任务有效的知识。只有当语言建模蒸馏与上下文学习蒸馏结合时,其积极作用才能得以发挥。
研究结果揭示了Multitask-ICT范式下知识蒸馏过程中两类目标的互补关系:一方面,上下文学习蒸馏通过指导模型根据上下文示例定位相关知识,使模型能够从语言建模数据和教师模型提供的混杂信息中筛选吸收有效知识;另一方面,语言建模蒸馏作为信息载体,将教师模型中的丰富知识传递给学生,弥补了小样本环境下目标任务上下文示例不足对模型性能提升的限制。这种互补机制使得结合语言建模目标的ICL-D(LM)在LAMA数据集上取得显著优于单独使用ICL-D的效果(如BERT-base提升4.9分,BERT-small提升6.4分),同时在CrossFit数据集上对GPT2-medium和GPT2-small分别带来1.5分和2.8分的额外增益。
7 Conclusion
本文提出了一种上下文学习蒸馏框架,旨在将大语言模型的少样本学习能力迁移至小模型。具体而言,我们通过联合优化上下文学习目标和语言建模目标实现知识蒸馏,并将该方法应用于两种少样本学习范式:元上下文调优(Meta-ICT)和我们提出的改进范式——多任务上下文调优(Multitask-ICT)。实验表明,上下文学习蒸馏在LAMA和CrossFit两大基准测试中均显著提升了两种范式的性能。对于Multitask-ICT范式,我们的小模型在参数量减少3.4倍、推理速度提升1.7倍的情况下性能优于教师模型;另一模型在体积压缩13.4倍、速度加快3.6倍的同时仍保持教师模型91.4%的性能。消融研究揭示:1)Meta-ICT主要从元训练任务的分布中学习,而非记忆单个任务的具体内容;2)在Multitask-ICT范式下,上下文学习蒸馏与语言建模蒸馏结合时效果最优。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)