4月14日 实习日记 | vllm源码解读 (一)
通过使模型类的构造函数统一,模型运行器可以轻松地创建和初始化模型,而无需知道特定的模型类型。通过使构造函数统一,我们可以轻松地创建视觉模型和语言模型,并将它们组合成视觉语言模型。启动服务的话,会执行vllm/entrypoints/cli/main.py 这个文件,解析命令行的参数,然后这个文件里又包含了下面三行,会遍历 CMD_MODULES 列表,对各个模块的子命令进行初始化。这个类当中,首先
目录
入口
首先打开 官方文档的Architecture Overview 界面,可以看到使用vllm进行推理有两种方式,一种是基于LLM class进行离线推理,另一种是基于vllm serve进行在线推理服务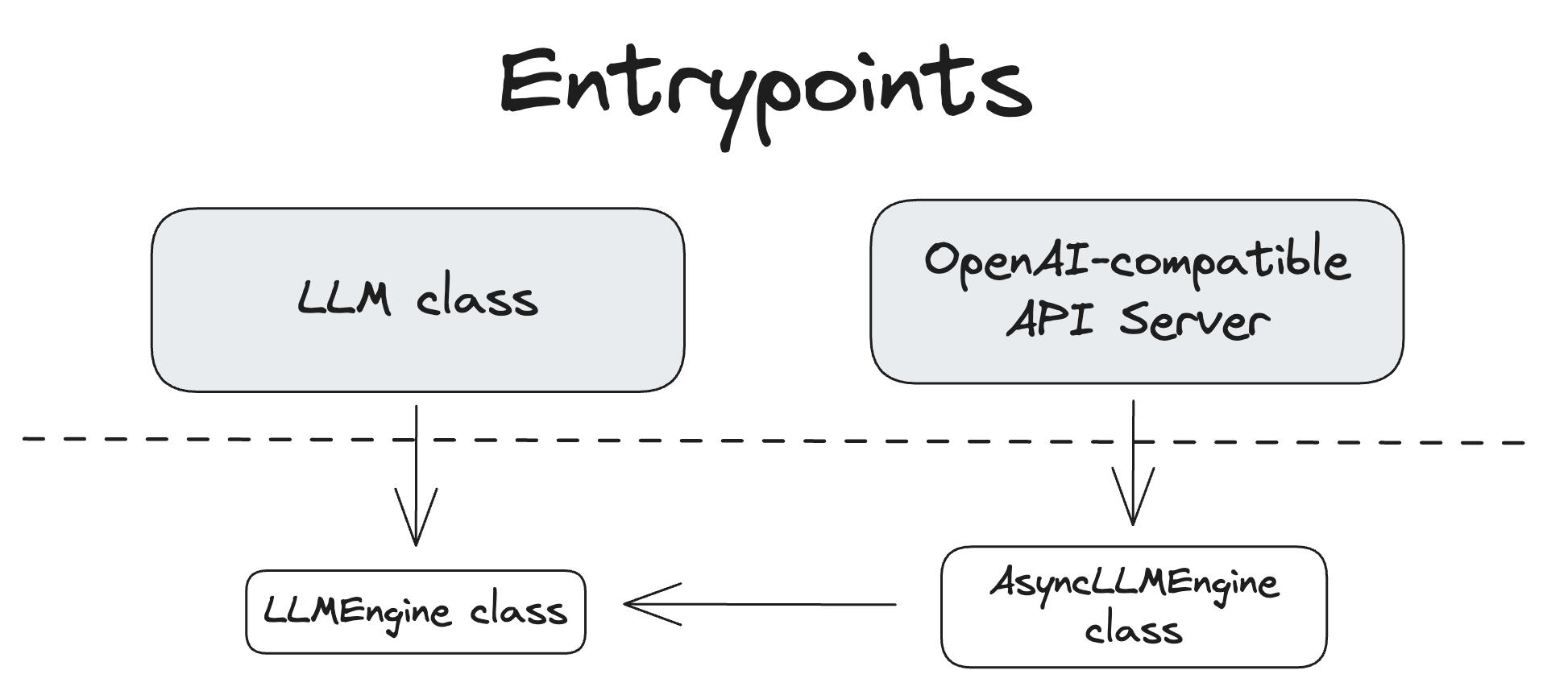
LLM Class
我们先来研究离线推理,进入到 vllm/entrypoints/llm.py 这个类当中,首先可以看到的第一个功能性函数是 generate(),需要关注的参数是prompts,可以是单个值或者一个序列、
下面是对generate的精简,为了方便我理解
def generate(
self,
prompts: Union[Union[PromptType, Sequence[PromptType]],
Optional[Union[str, list[str]]]] = None,
) -> list[RequestOutput]:
"""Generates the completions for the input prompts.
self._validate_and_add_requests(
prompts=parsed_prompts,...)
#显而易见,这行代码就是添加请求,其实往里面看,是向引擎维护的一个序列里添加这些请求
outputs = self._run_engine(use_tqdm=use_tqdm) #引擎根据自身的序列中的请求来进行推理
return self.engine_class.validate_outputs(outputs, RequestOutput)
OpenAI 兼容 API 服务器
然后来研究在线推理 vllm/entrypoints/cli/main.py
通过vllm serve启动服务的话,会执行vllm/entrypoints/cli/main.py 这个文件,解析命令行的参数,然后这个文件里又包含了下面三行,会遍历 CMD_MODULES 列表,对各个模块的子命令进行初始化
CMD_MODULES = [
vllm.entrypoints.cli.openai,
vllm.entrypoints.cli.serve,
vllm.entrypoints.cli.benchmark.main,
]
在vllm.entrypoints.cli.serve中,启动服务器的核心是这段代码
@staticmethod
def cmd(args: argparse.Namespace) -> None:
# If model is specified in CLI (as positional arg), it takes precedence
if hasattr(args, 'model_tag') and args.model_tag is not None:
args.model = args.model_tag
uvloop.run(run_server(args))
#调用 uvloop.run(run_server(args)) 来启动服务。uvloop 是一个快速的异步事件循环库,run_server 函数来自 vllm.entrypoints.openai.api_server 模块,它接收解析后的命令行参数 args 并启动 OpenAI 兼容的 API 服务器。
LLM 引擎
LLMEngine 和 AsyncLLMEngine 类是 vLLM 系统功能的核心,负责处理模型推理和异步请求处理。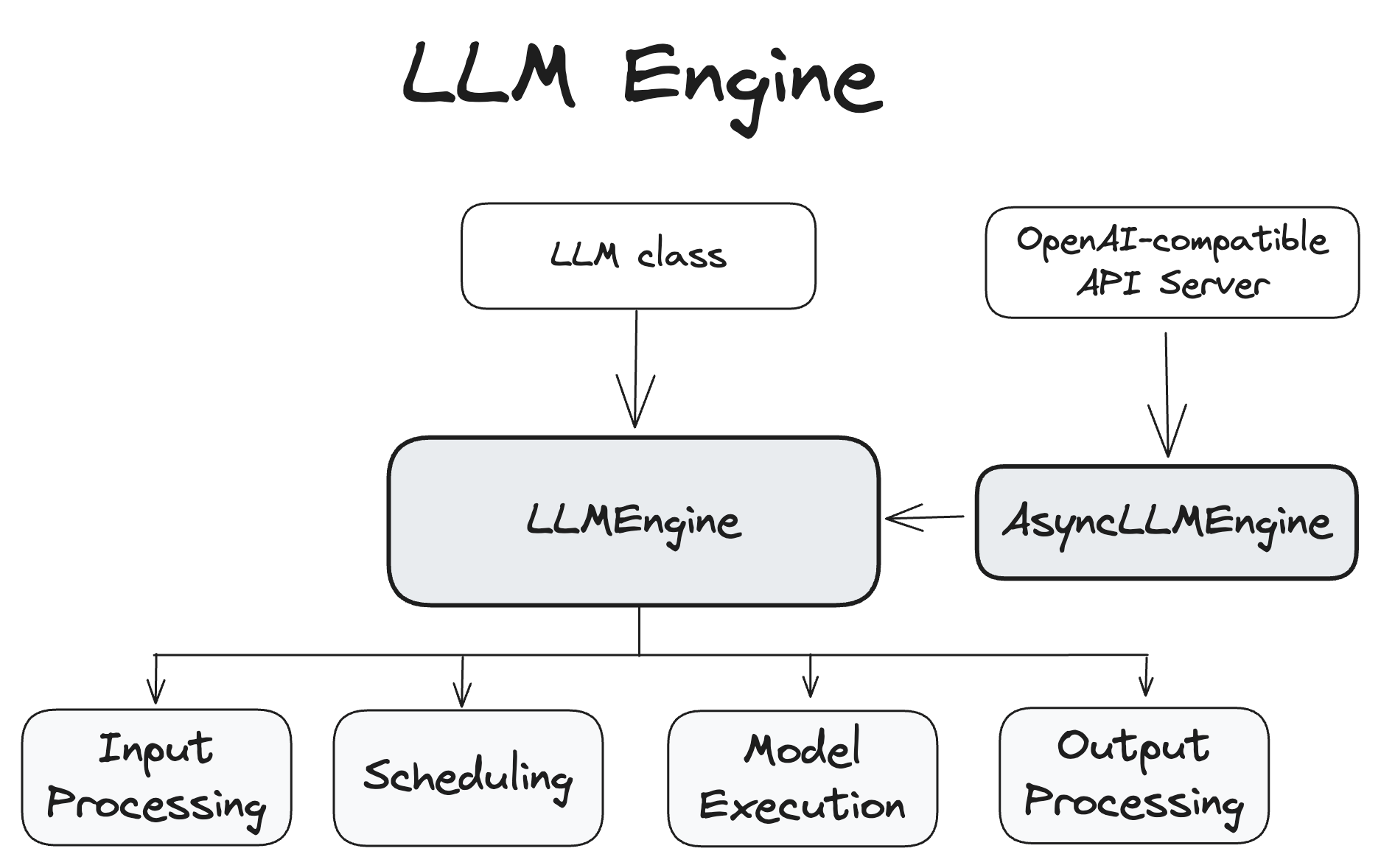
LLMEngine
LLMEngine 类是 vLLM 引擎的核心组件。它负责接收来自客户端的请求并从模型生成输出。LLMEngine 包括输入处理、模型执行(可能分布在多个主机和/或 GPU 上)、调度和输出处理。
- 输入处理:使用指定的 tokenizer 处理输入文本的标记化。
- 调度:选择在每个步骤中处理哪些请求。
- 模型执行:管理语言模型的执行,包括跨多个 GPU 的分布式执行。
- 输出处理:处理模型生成的输出,将语言模型的 token ID 解码为人类可读的文本。
LLMEngine 的代码可以在 vllm/engine/llm_engine.py中找到。
AsyncLLMEngine
AsyncLLMEngine 类是 LLMEngine 类的异步包装器。它使用 asyncio 创建一个后台循环,持续处理传入的请求。AsyncLLMEngine 专为在线服务而设计,它可以处理多个并发请求并将输出流式传输到客户端。
AsyncLLMEngine 的代码可以在 vllm/engine/async_llm_engine.py 中找到。
Worker
Worker 是运行模型推理的进程。 vLLM 遵循常用做法,即使用一个进程来控制一个加速器设备,例如 GPU。例如,如果我们使用大小为 2 的张量并行和大小为 2 的流水线并行,我们将总共有 4 个 worker。 Worker 通过其 rank 和 local_rank 标识。rank 用于全局编排,而 local_rank 主要用于分配加速器设备和访问本地资源,例如文件系统和共享内存。
模型运行器 Model Runner
每个 worker 都有一个模型运行器对象,负责加载和运行模型。许多模型执行逻辑都位于此处,例如准备输入张量和捕获 cuda 图。
模型 Model
每个模型运行器对象都有一个模型对象,它是实际的 torch.nn.Module 实例。
结构图
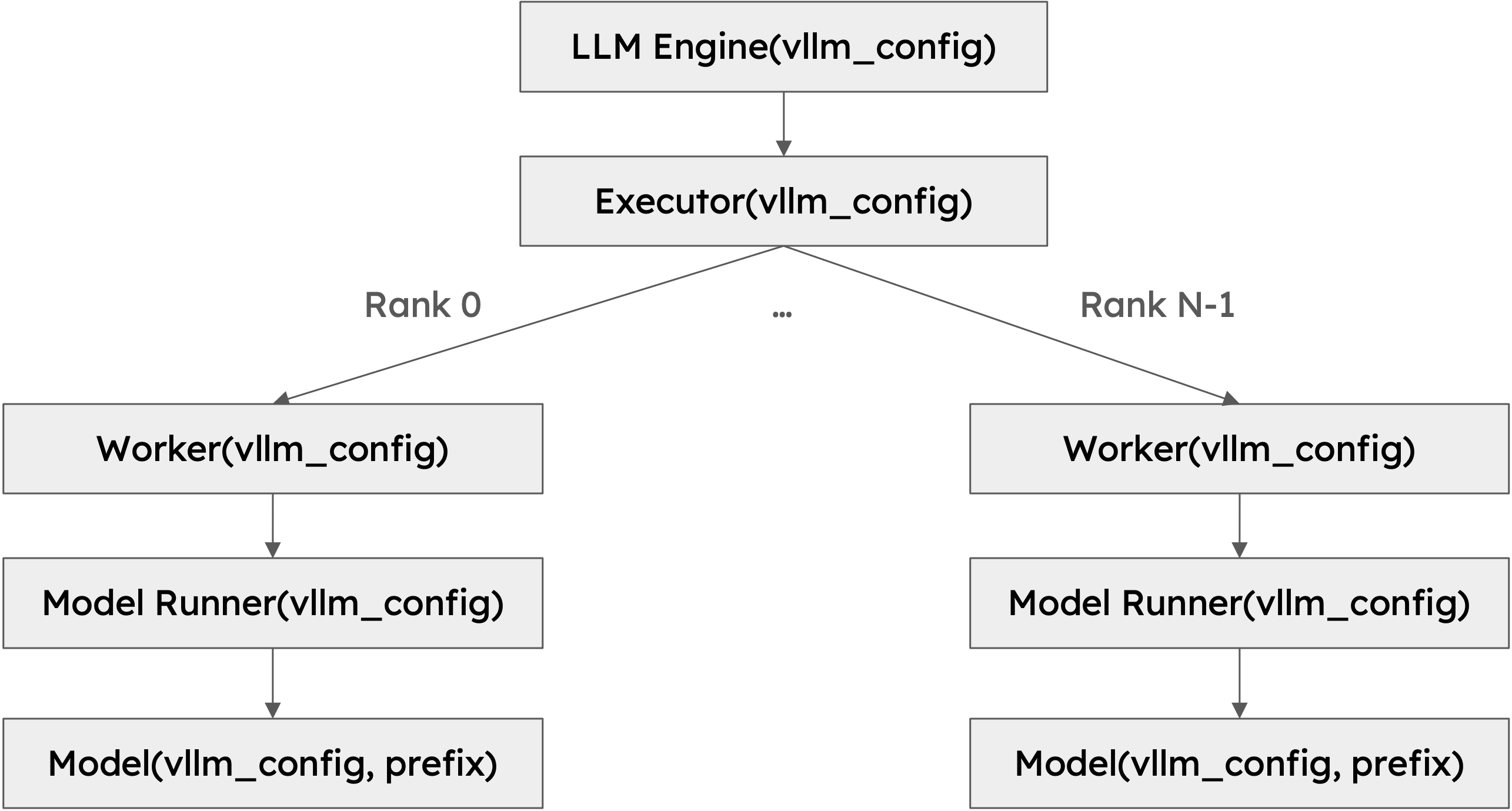
此类的层级结构背后有几个重要的设计选择
-
可扩展性:层级结构中的所有类都接受包含所有必要信息的配置对象。VllmConfig 类是主要配置对象,它在各处传递。类层级结构非常深入,每个类都需要读取其感兴趣的配置。通过将所有配置封装在一个对象中,我们可以轻松地在各处传递配置对象并访问我们需要的配置。假设我们想要添加一个仅涉及模型运行器的新功能(考虑到 LLM 推理领域的发展速度,这通常是这种情况)。我们必须在 VllmConfig 类中添加新的配置选项。由于我们在各处传递整个配置对象,我们只需要将配置选项添加到 VllmConfig 类,模型运行器就可以直接访问它。我们无需更改引擎、worker 或模型类的构造函数来传递新的配置选项。
-
统一性:模型运行器需要统一的接口来创建和初始化模型。 vLLM 支持 50 多种流行的开源模型。每个模型都有自己的初始化逻辑。如果构造函数签名随模型而变化,则模型运行器不知道如何相应地调用构造函数,而没有复杂且容易出错的检查逻辑。通过使模型类的构造函数统一,模型运行器可以轻松地创建和初始化模型,而无需知道特定的模型类型。这也对于组合模型很有用。视觉语言模型通常由视觉模型和语言模型组成。通过使构造函数统一,我们可以轻松地创建视觉模型和语言模型,并将它们组合成视觉语言模型。
今天的额外工作(跟上文无关)
boss让我在10.20.25.250上面使用llama.cpp启动一个Deepseek1.5b的模型,然后打成镜像移植到别的服务器上
#首先启动一个llama.cpp服务
docker run --gpus '"device=4,5,6,7"' -p 8090:8080 -v /home/zhangzichao/checkpoints/DeepSeek-R1-Distill-Qwen-1.5B-GGUF:/models/DeepSeek-R1-Distill-Qwen-1.5B-GGUF --name llama-cpp local/llama.cpp:full-cuda --server -m /models/DeepSeek-R1-Distill-Qwen-1.5B-GGUF/DeepSeek-R1-Distill-Qwen-1.5B-Q8_0.gguf --port 8080 -ngl 64 --alias DeepSeek-R1-Distill-Qwen-1.5B -c 98304 --parallel 4 --no-context-shift --host 0.0.0.0
#然后将本地的模板copy到容器内的models文件夹下
docker cp /home/zhangzichao/checkpoints/DeepSeek-R1-Distill-Qwen-1.5B
-GGUF/DeepSeek-R1-Distill-Qwen-1.5B-Q8_0.gguf llama-cpp:/models/
#将当前的容器提交成镜像
docker commit llama-cpp llama-cpp:1.0
#将提交后的镜像打包
docker save -o llama-cpp.tar llama-cpp:1.0
#传到另一台服务器上然后load加载tar包,生成镜像
docker load -i llama-cpp.tar
#启动服务
docker run --gpus '"device=4,5,6,7"' -p 8090:8080 --name llama-cpp llama-cpp:1.0 --server -m /models/DeepSeek-R1-Distill-Qwen-1.5B-Q8_0.gguf --port 8080 -ngl 29 --alias DeepSeek-R1-Distill-Qwen-1.5B -c 98304 --parallel 4 --no-context-shift --host 0.0.0.0

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)