一文彻底搞懂最近爆火的MCP与Function calling之间的区别
曾几何时,当我们谈论 AI 大模型(LLM)使用外部工具时,大家首先想到的几乎都是函数调用 (Function Calling)。可以说,在 MCP(模型上下文协议)崭露头角并像今天这样成为热门话题之前,函数调用几乎是支撑起整个 AI 工作流的“老大哥”。想象一下,早期的 AI 应用就像一个个“孤岛”,每个应用都需要开发者手动集成各种工具和 API,就像在荒岛上搭建基础设施,从零开始铺设道路、架设
Function calling 与 MCP
曾几何时,当我们谈论让 AI 模型(比如现在火热的 LLM)使用外部工具时,大家首先想到的几乎都是传统的函数调用 (Function Calling)。可以说,在 MCP(模型上下文协议)崭露头角并像今天这样成为热门话题之前,函数调用几乎是支撑起整个 AI 工作流的“老大哥”。
想象一下,早期的 AI 应用就像一个个“孤岛”,每个应用都需要开发者手动集成各种工具和 API,就像在荒岛上搭建基础设施,从零开始铺设道路、架设桥梁,费时费力。
然而,风向正在悄然改变!如今,MCP 正带来一场新的变革浪潮,就像为这些“孤岛”之间架起了一座座“跨海大桥”,为开发者提供了一种全新的方式来构建和管理 Agent(智能体)的工具访问和任务编排。这不仅仅是技术的迭代,更可能预示着 AI 应用开发范式的转变。
下图直观地展示了 Function Calling 和 MCP 的关系,或许能让你一目了然:
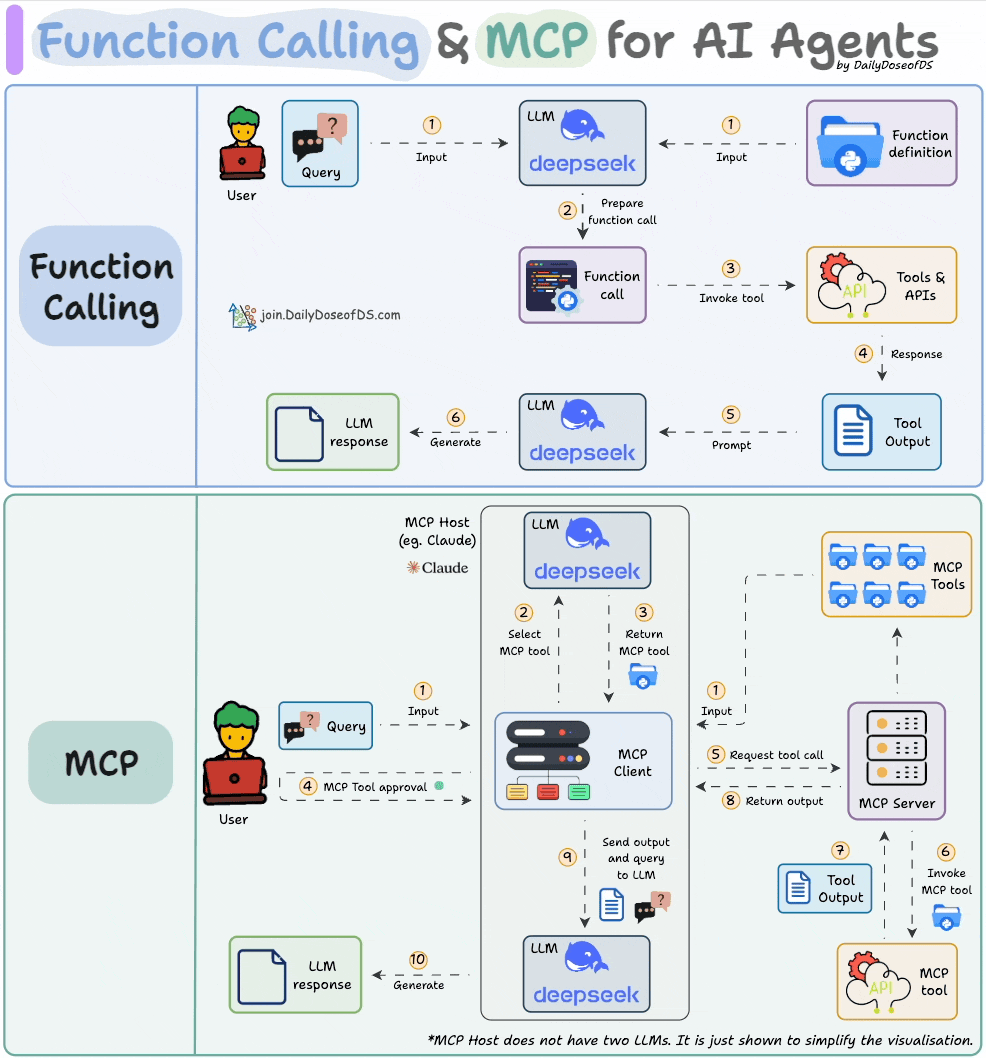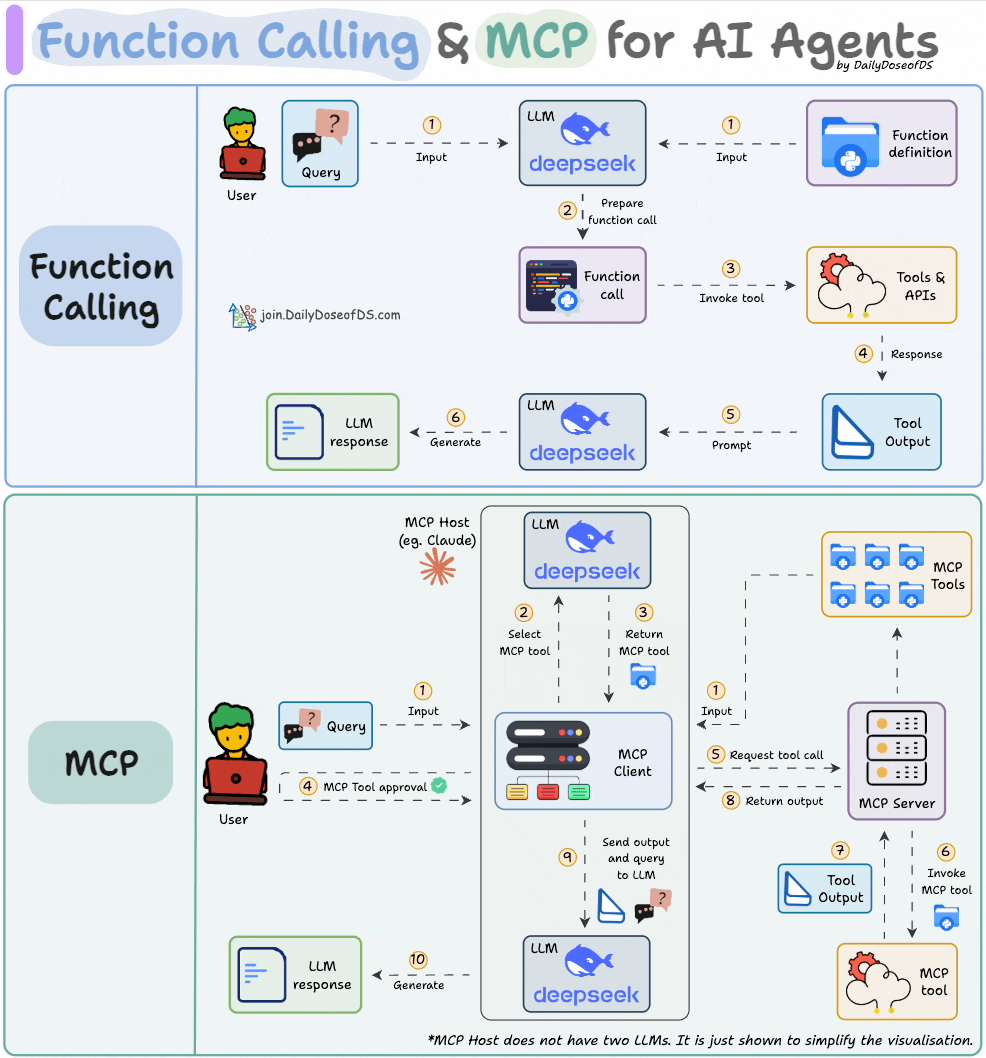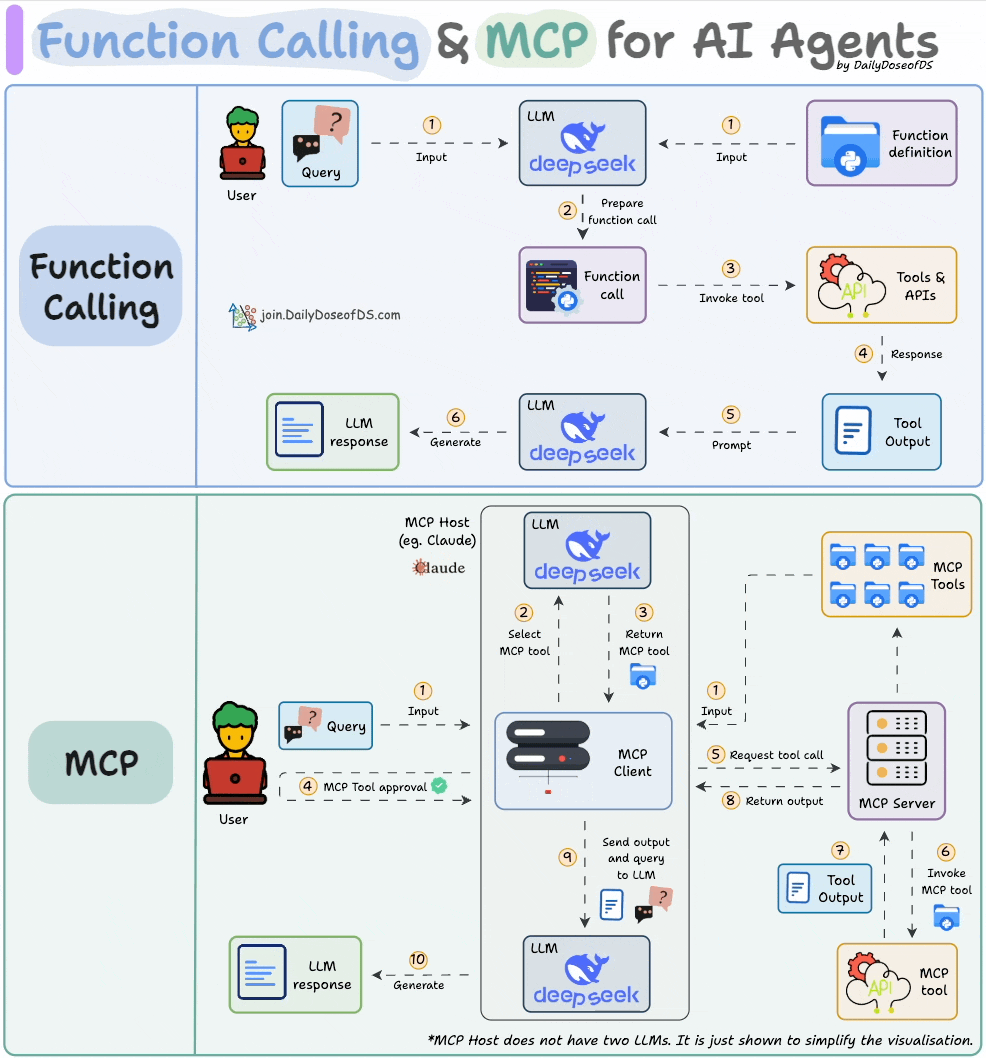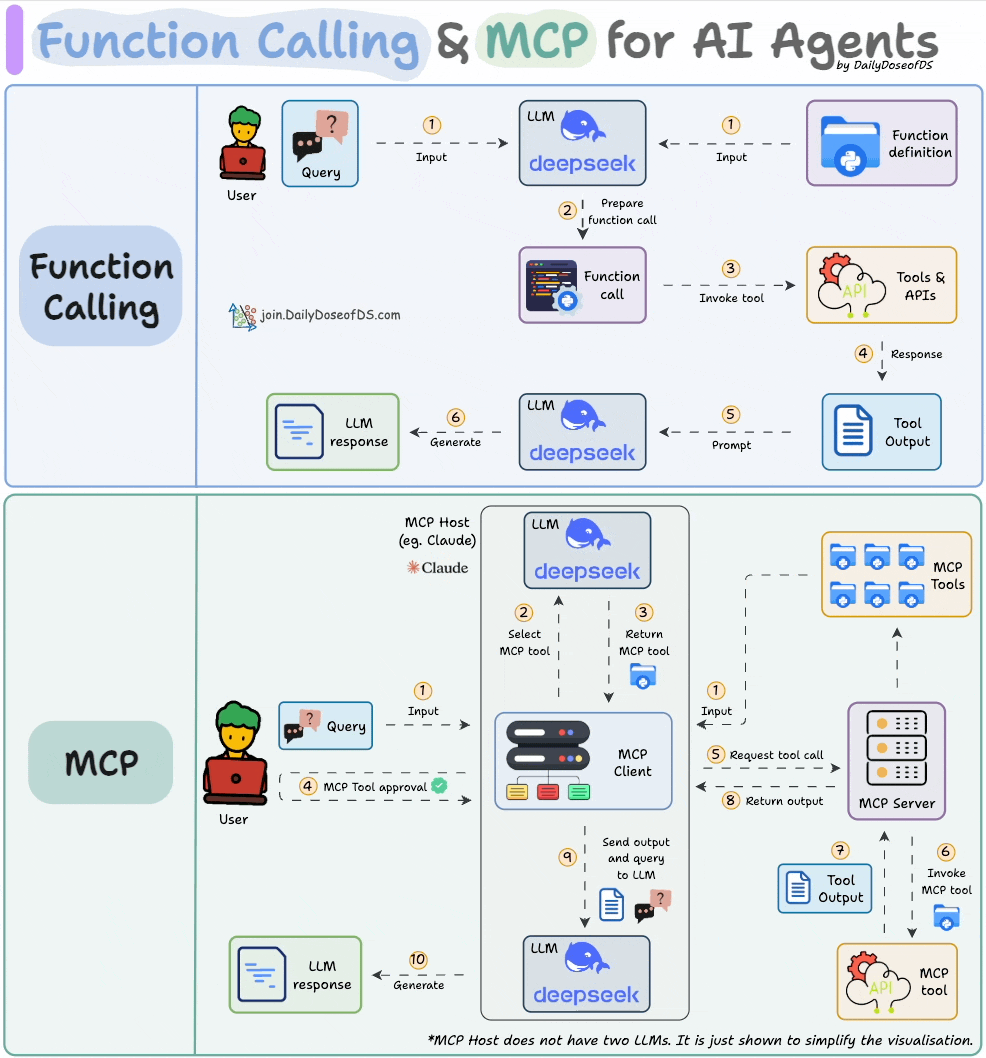
图片来自《Daily Dose of Data Science》
何谓 Function Calling?
简单来说,函数调用(Function Calling)就像给了 LLM 一个“锦囊”,让它能根据你的指令,判断需要使用哪个“法宝”(工具),以及何时出手。
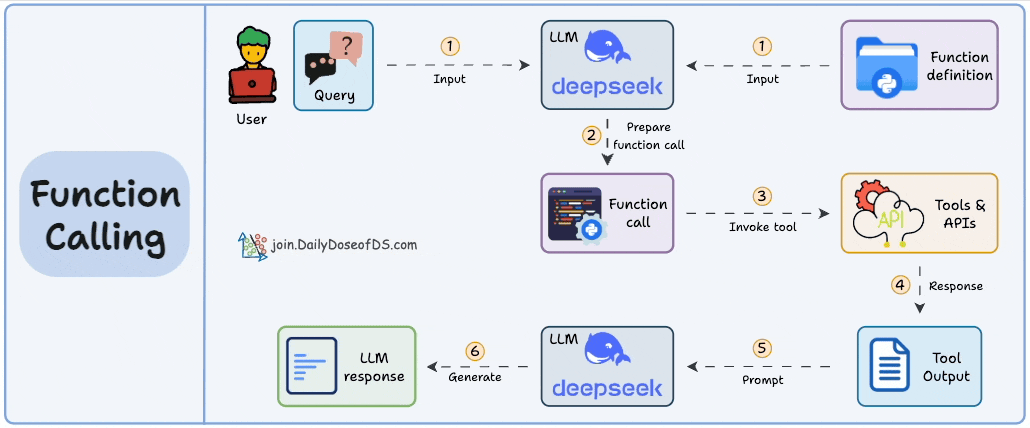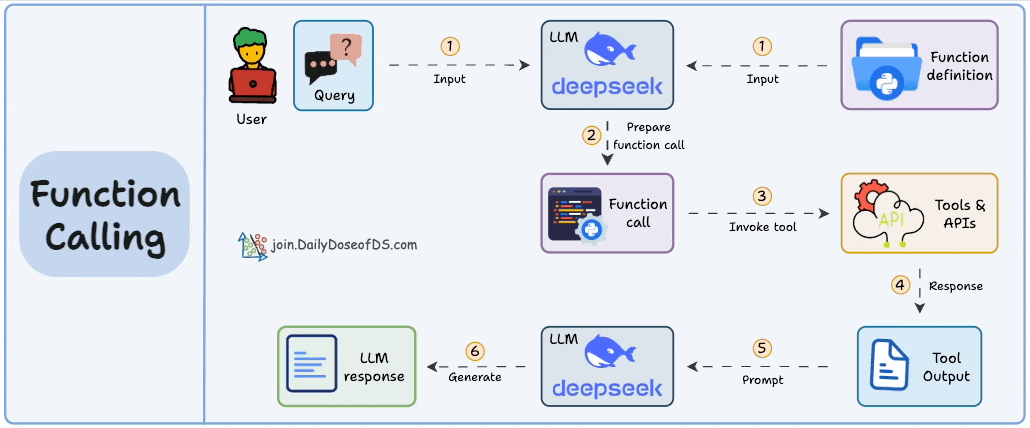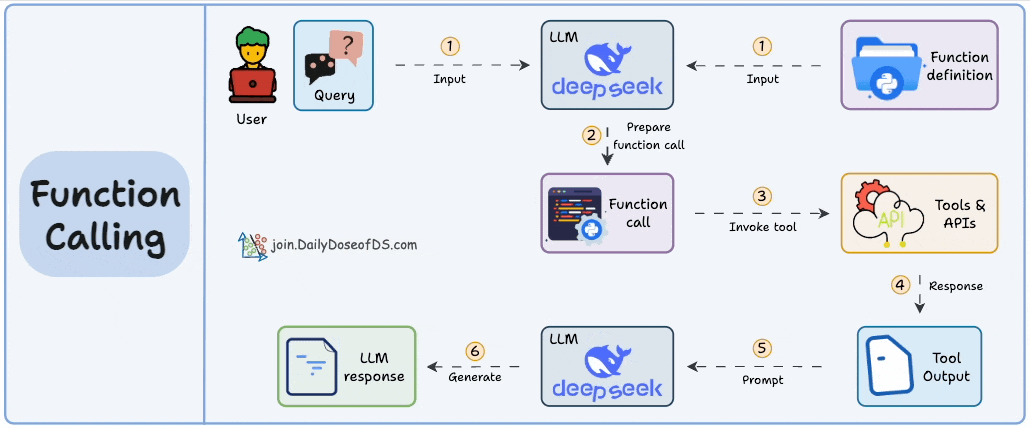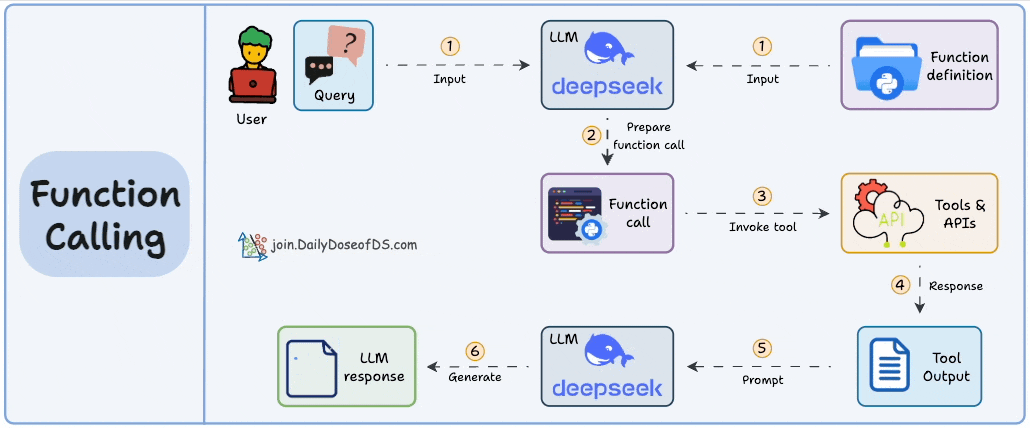
图片来自《Daily Dose of Data Science》
这个过程通常是这样的:
- 接收指令: LLM 首先会收到用户的指令或问题。
- 决策判断: 接着,LLM 会分析这个指令,判断是否需要借助外部工具(比如查询天气、获取股价等)来完成任务,以及具体需要哪个工具。
- 准备调用: 然后,开发者需要提前编写好程序逻辑,以便接收 LLM 发出的“调用工具”的信号,并准备好实际的函数调用指令。
- 执行与反馈: 最后,这个带有必要参数的函数调用会被发送到相应的后端服务(比如一个 API),由这个服务来真正执行任务,并将结果返回给 LLM,LLM 再整理信息回复给用户。
下面以“获取电影信息”为例,展示 Function Calling 的实际应用。
示例:获取电影信息
假设我们有一个工具函数 get_movie_info,它可以通过电影名称从某个电影数据库 API 中获取电影的详细信息,比如导演、主演、评分等。
1. 定义工具函数
首先,我们定义一个工具函数 get_movie_info,它接受电影名称作为参数,并返回电影的相关信息。
import requests
def get_movie_info(movie_name):
# 假设我们使用一个电影数据库的 API
url = f"https://api.moviedatabase.com/movies?title={movie_name}"
response = requests.get(url)
if response.status_code == 200:
return response.json() # 返回电影信息
else:
return {"error": "Failed to fetch movie info"}
2. 准备 LLM 调用
接下来,我们使用 OpenAI 的 openai 模块来调用 LLM,并传递我们定义的工具函数。
import openai
# 定义工具
tools = [
{
"type": "function",
"function": {
"name": "get_movie_info",
"description": "Get detailed information about a movie by its name.",
"parameters": {
"type": "object",
"properties": {
"movie_name": {
"type": "string",
"description": "The name of the movie."
}
},
"required": ["movie_name"]
}
}
}
]
# 调用 LLM
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": "Tell me about the movie Inception."}
],
tools=tools,
tool_choice="auto"
)
# 打印响应
print(response)
3. 处理 LLM 的响应
LLM 的响应中会包含 tool_calls,我们可以根据这个信息来调用相应的工具函数。
# 解析响应
tool_calls = response['choices'][0]['message']['tool_calls']
for tool_call in tool_calls:
if tool_call['function']['name'] == 'get_movie_info':
# 获取参数
movie_name = tool_call['function']['arguments']['movie_name']
# 调用工具函数
movie_info = get_movie_info(movie_name)
# 打印结果
print(movie_info)
4. 输出结果
假设我们获取到的电影信息如下:
{
"title": "Inception",
"director": "Christopher Nolan",
"cast": ["Leonardo DiCaprio", "Joseph Gordon-Levitt", "Elliot Page"],
"rating": 8.8
}
5. 代码说明
通过这个例子,我们可以看到 Function Calling 的实际应用流程:
- 定义工具函数:我们定义了一个
get_movie_info函数,用于从电影数据库中获取电影信息。 - 调用 LLM:我们使用 OpenAI 的
openai模块调用 LLM,并传递我们定义的工具函数。 - 处理响应:LLM 的响应中包含了
tool_calls,我们根据这个信息来调用相应的工具函数,并获取结果。
这个例子展示了如何通过 Function Calling 让 LLM 动态地调用外部工具,从而扩展其能力。希望这个例子能帮助你更好地理解 Function Calling 的实际应用!
注意:在实际应用中,你需要替换 https://api.moviedatabase.com/movies 为真实的电影数据库 API,并确保 API 的访问权限和认证信息正确配置。
小结
你会发现,上面展示的整个流程,从头到尾都是在你的应用程序“自家后院”里进行的。这意味着,作为开发者,你几乎要包揽所有事情:
- 工具的“安家落户”与日常维护: 你不仅要提供这些工具或 API 接口,还得像个勤劳的园丁一样,负责它们的服务器托管、日常维护、更新升级,确保它们随时待命。
- 制定“行动指南”: 你需要编写一套复杂的逻辑,像个聪明的指挥官,精确判断 LLM 的意图,决定应该调用哪个工具,以及需要传递哪些准确无误的“指令参数”。
- 处理“突发状况”与资源调度: 工具执行过程中的各种细节,比如性能优化、并发处理,甚至在访问量激增时如何保证服务不宕机(弹性伸缩),这些都得你来操心。
- 把好“安全大门”并处理意外: 谁有权限使用这些工具?如何验证身份?调用过程中如果出现网络波动或 API 错误怎么办?这些安全认证和错误处理机制,都得由你来设计和实现。
总而言之,传统的 Function Calling 确实让你的应用拥有了动态调用外部工具的能力,但这更像是在你自己的技术栈里“手工作坊式”地搭建和连接一切。你需要亲力亲为,手动完成大量的“管道铺设”和“线路连接”工作。
何谓 MCP?
如果说 Function Calling 是告诉 LLM “你可以用这些工具”,那么 MCP(模型上下文协议,Model Context Protocol)的目标就是为这个过程建立一套“行业标准”。
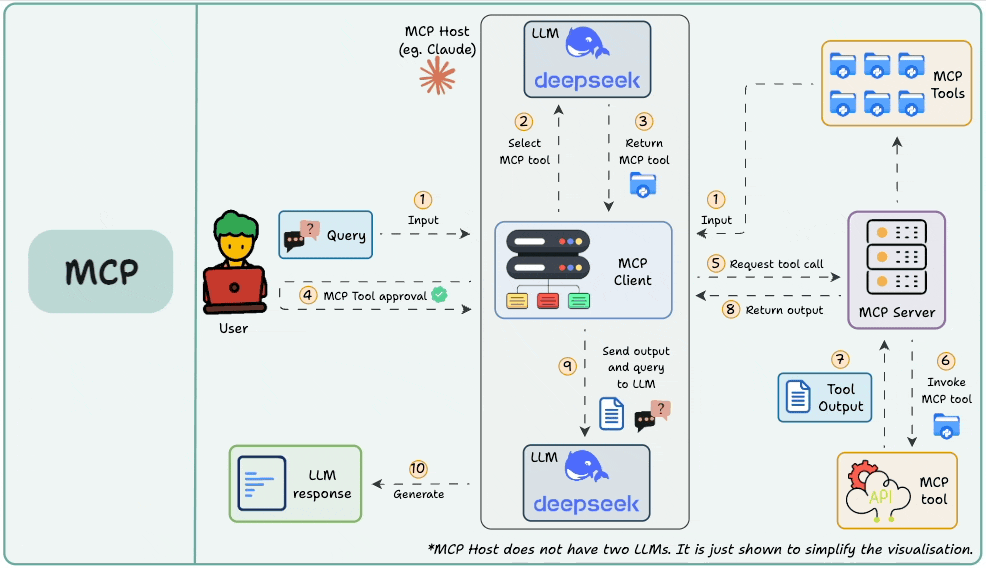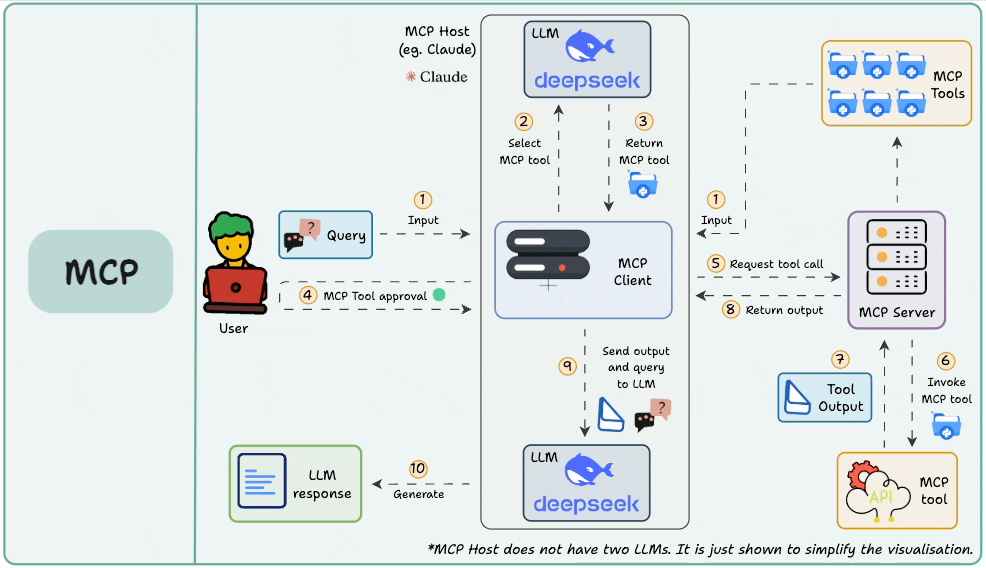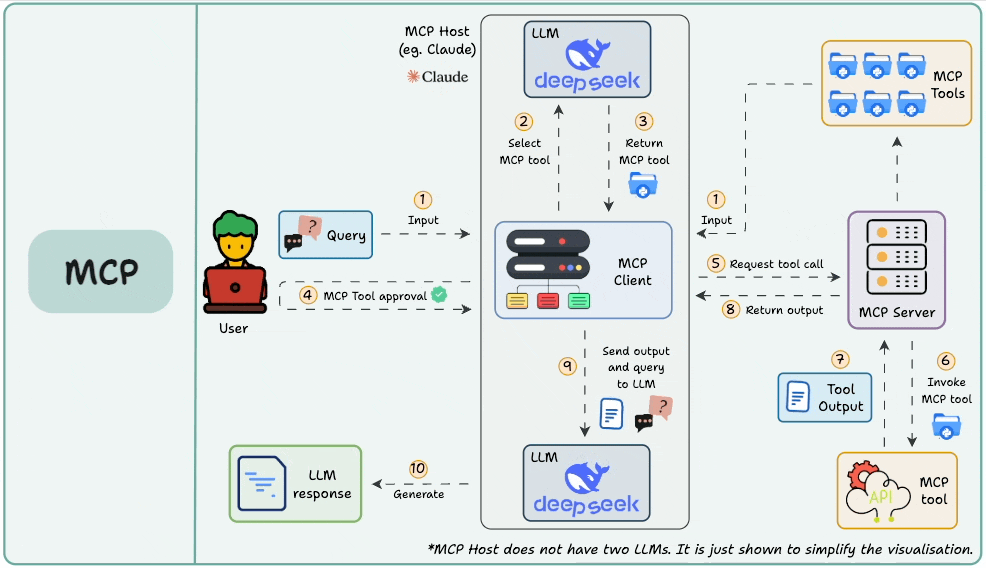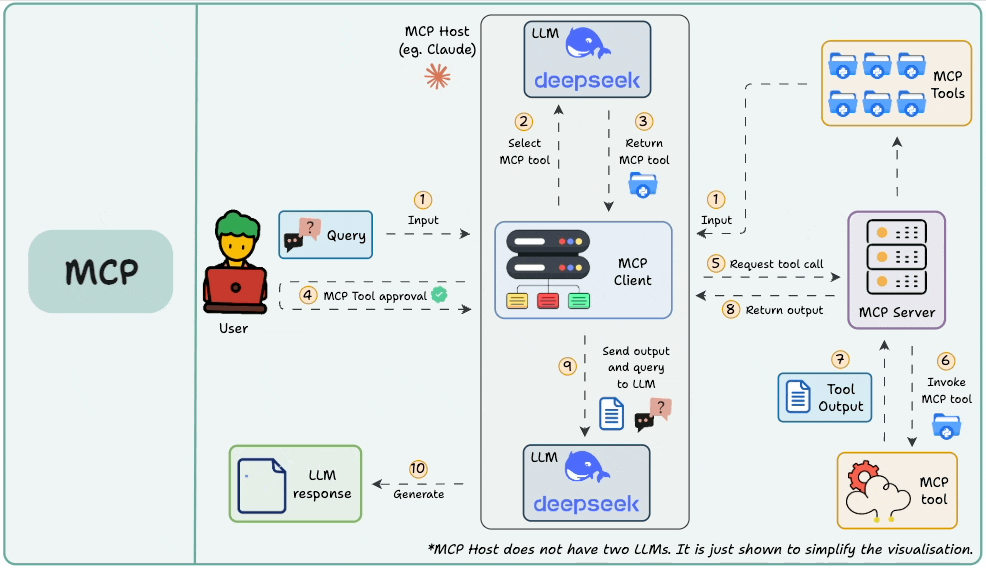
图片来自《Daily Dose of Data Science》
想象一下,如果没有统一的接口标准(比如 USB),我们每换一个设备就得配一种充电器,那该多麻烦!MCP 就像是为 AI 工具打造的“通用接口协议”。
Function Calling 更多关注的是“模型想要做什么”,而 MCP 则聚焦于“如何让工具更容易被发现、理解和使用”,尤其是在需要在多个 Agent、模型或平台之间共享工具能力的场景下。
有了 MCP,开发者就不再需要在每个应用或 Agent 内部“硬编码”集成各种工具了。相反,MCP 带来了诸多好处:
- 标准化工具生态: 它规范了如何定义、托管工具,以及如何将这些工具“开放”给 LLM 使用,就像建立了一个工具的“应用商店”。
- 简化工具发现与使用: LLM 可以轻松地找到可用的工具,理解它们的“说明书”(schemas),并直接上手使用,大大降低了集成门槛。
- 增强安全与可控性: 在工具真正被调用之前,可以设置审批和审计流程,确保工具的使用是安全合规的。
- 解耦实现与消费: 将工具的开发和维护(实现)与工具的使用(消费)分离开来,让工具开发者和应用开发者可以各司其职,互不干扰。
当前市场上MCP Host主要包括Cursor、Claude Desktop、Cherry Studio等应用;MCP Server平台则涵盖浏览器自动化、数据库集成、专业领域工具以及云厂商的托管服务,代表性平台有微软Playwright MCP、Apify、Postgres MCP、OceanBase MCP、阿里云百炼、腾讯云AI开发套件等。
这些云厂商的MCP Server平台加速了MCP协议的产业应用和生态建设。
目前提供MCP Host和MCP Server的平台及产品主要如下:
MCP Host(支持MCP协议的应用程序)
MCP Host是支持MCP协议的应用程序,允许用户配置和连接MCP Server。当前已知的MCP Host包括:
-
Cursor
-
Claude Desktop
-
Cherry Studio
-
其他类似支持MCP配置的应用程序
这些Host通常提供配置入口,通过配置文件(如mcp.json)连接到云端或本地的MCP Server,实现AI模型与外部工具和数据的交互。
MCP Server(MCP协议的服务器实现平台)
MCP Server是实现MCP协议的服务器,使AI模型能够调用外部工具、访问数据和服务。根据不同应用场景和技术栈,MCP Server平台丰富多样,主要包括:
1. 浏览器自动化与网页交互类MCP Server
-
microsoft/playwright-mcp:微软官方,基于Playwright的浏览器自动化,适合精细网页交互。
-
browserbase/mcp-server-browserbase:云端浏览器自动化服务,无需本地安装。
-
modelcontextprotocol/server-puppeteer:官方参考实现,基于Puppeteer。
-
apify/actors-mcp-server:集成Apify平台3000+云工具,适合电商、社交媒体数据抓取。
-
AgentQL、Firecrawl、Oxylabs、Hyperbrowser等多种官方和社区实现,支持网页数据提取、动态渲染、截图等功能。
2. 数据库和数据服务类MCP Server
-
crystaldba/postgres-mcp:Postgres数据库集成,支持性能分析和调优。
-
tradercjz/dolphindb-mcp-server:DolphinDB集成。
-
ergut/mcp-bigquery-server:Google BigQuery集成。
-
ClickHouse/mcp-clickhouse:集成Apache Kafka和Timeplus。
-
get-convex/convex-backend:Convex数据库集成。
-
gannonh/firebase-mcp:Firebase服务集成,包括认证和存储。
-
jovezhong/mcp-timeplus:Kafka和Timeplus集成。
-
idoru/influxdb-mcp-server:InfluxDB查询。
-
isaacwasserman/mcp-snowflake-server:Snowflake集成。
-
joshuarileydev/supabase-mcp-server:Supabase管理。
-
KashiwaByte/vikingdb-mcp-server:VikingDB集成。
-
蚂蚁集团OceanBase MCP Server:OceanBase数据库MCP协议对接,支持私有化和云数据库。
3. 其他专业领域MCP Server
-
Seym0n/tiktok-mcp:TikTok视频交互。
-
tomekkorbak/oura-mcp-server:Oura睡眠追踪应用数据。
-
wanaku-ai/wanaku:基于SSE的MCP路由引擎,支持企业系统与AI Agent集成。
-
HenryHaoson/Yuque-MCP-Server:语雀API集成,支持文档管理和知识库交互。
4. 云厂商及生态支持
-
阿里云百炼:业界首个全生命周期MCP服务,支持快速搭建Agent,无需用户管理资源。
-
腾讯云AI开发套件:支持MCP插件托管服务,5分钟快速搭建业务型AI Agent,支持第三方MCP Server。
-
百度:即将发布专门面向MCP的门户商店MCP store,推动MCP生态发展。
-
蚂蚁集团OceanBase:已实现MCP协议对接,支持私有化和云端数据库。
好的,我们来用 Cursor IDE 集成 Firecrawl 的 MCP 服务器为例,详细展示 MCP 如何让工具的发现和使用变得如此便捷。
实践出真知:在 Cursor IDE 中体验 MCP 的魔力
理论说了不少,是时候来点实际操作了!让我们看看如何在 Cursor IDE 这个强大的开发环境中,通过集成 Firecrawl 的 MCP 服务器,轻松调用网页抓取工具。
Firecrawl 提供了一个 MCP 服务器,它将强大的网页抓取能力封装成符合 MCP 标准的工具。通过集成这个服务器,你的 Agent 就能直接使用这些工具,而无需关心抓取工具本身的实现细节。
第一步:连接 MCP 服务器
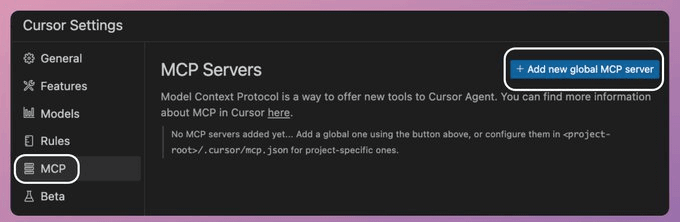
在 Cursor IDE 中连接 MCP 服务器非常简单,就像添加一个新的服务源一样:
- 打开 Cursor 的 设置 (Settings)。
- 找到 MCP 选项。
- 点击 添加新的全局 MCP 服务器 (Add new global MCP server)。
第二步:配置服务器信息
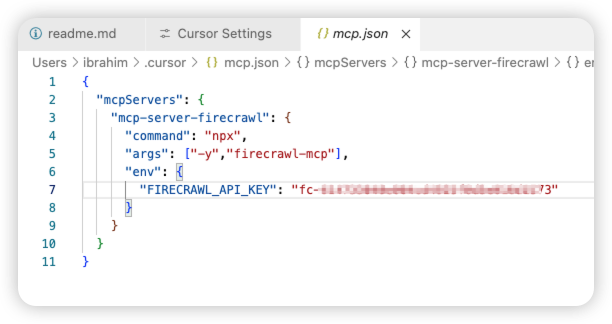
在弹出的 JSON 配置文件中,填入 Firecrawl MCP 服务器的相关信息。这通常包括服务器的地址和必要的认证信息(如果需要的话)。
配置大致会像这样(具体内容请参考 Firecrawl MCP 服务器的文档):
第三步:发现可用工具
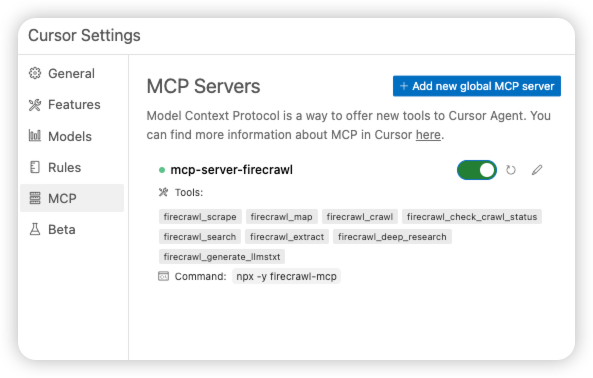
配置完成后,Cursor IDE 会自动连接到 Firecrawl 的 MCP 服务器,并拉取服务器暴露的所有工具列表。
你会惊喜地发现,Firecrawl 的抓取工具已经出现在你的 Cursor IDE 工具列表中了!你的 Agent 现在可以直接“看到”并使用这些工具了。
注意到了吗? 整个过程,我们没有编写一行 Python 代码来集成 Firecrawl 的抓取功能!我们只是简单地配置了 MCP 服务器的连接信息。这就是 MCP 的强大之处——它将工具的提供者和使用者解耦开来。
第四步:Agent 调用 MCP 工具
现在,你的 Agent 已经可以通过 MCP 访问 Firecrawl 的抓取工具了。
使用 Ctrl/⌘ + L 打开AI面板并聚焦到聊天输入框,输入以下提示词。
这段提示词的作用是让Cursor调用Firecrawl的MCP Server总结我的上一篇文章【7万字长文,含案例】基于DeepSeek私有化部署RAGFlow行业知识库和智能体Agent,完美实现知识图谱和低代码开发。
请总结一下这篇微信公众号文章的主要内容:https://blog.csdn.net/ibrahimsteed/article/details/147484401
然后执行提示词。
Agent 的执行过程大致如下:
- 识别需求: Agent 理解用户需要获取博客文章中的信息。
- 匹配工具: Agent 通过 MCP 发现并确定 Firecrawl 的抓取工具(scraper)是完成这个任务的最佳选择。
- 准备参数: Agent 自动准备好抓取工具所需的输入参数(比如博客文章的 URL)。
- 调用工具: Agent 通过 MCP 协议向 Firecrawl MCP 服务器发出调用抓取工具的请求。
- 获取结果: Firecrawl MCP 服务器执行抓取任务,并将抓取到的文章内容通过 MCP 返回给 Agent。
- 生成响应: Agent 利用抓取到的文章内容,分析并提取出 CrewAI 工具的导入信息,最终生成回复给用户的答案。
小结:MCP 作为基础设施
换个角度看,MCP 更像是一种“基础设施”。
它构建了一个共享的、标准化的生态系统,在这个生态中,各种工具就像是即插即用的标准化服务。这与传统软件工程中 REST API 或 gRPC 端点的工作方式非常相似——它们定义了服务如何被发现和调用,而无需使用者关心服务的内部实现。
通过 MCP,工具的提供者可以专注于构建高质量的工具,而工具的使用者(Agent 或应用)则可以轻松地发现和调用这些工具,极大地提高了开发效率和工具的复用性。
总结
那么,说了这么多,Function Calling 和 MCP 到底是什么关系?是竞争对手,还是合作伙伴?
划重点:MCP 和 Function Calling 并非相互排斥,它们其实是同一枚硬币的两面,共同构成了一个完整、高效的 AI 工具调用工作流。
可以这样理解它们的分工:
- Function Calling:LLM 的“意图表达器”。 它更侧重于让 LLM 能够清晰地表达出“我想要做什么?”。它赋予了 LLM 思考和决策的能力,判断何时需要借助外力来完成任务。
- MCP:工具的“超级管家”与“标准化执行器”。 它则负责确保这些“外力”(工具)能够被可靠地找到、理解并顺利执行。它关注的是“如何让工具随时待命、易于接入、规范运行?”,并且让你无需为每个工具都进行繁琐的定制化集成工作。
举个形象的例子:
想象一下,你的 Agent (智能体) 通过 Function Calling 判断出:“我需要上网搜索一下最新的 AI 进展。”
这个“搜索网页”的意图发出后,请求就可以通过 MCP 这个“超级管家”进行路由。MCP 会在所有可用的网页搜索工具中,自动挑选出最合适的那一个(可能是 Google 搜索工具、Bing 搜索工具或其他特定领域的搜索工具),然后调用它,并以标准化的格式将搜索结果返回给 Agent。
看到了吗?Function Calling 负责“提出需求”,MCP 负责“高效满足需求”。两者相辅相成,才能让 AI Agent 更强大、更智能地与外部世界互动。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)