从Attention机制到Transformer
在当今数字化浪潮中,自然语言处理(NLP)携手大模型,正引领着人工智能的全新变革。NLP 作为理解与生成人类语言的核心技术,正借助大模型的强大算力与海量数据,实现质的飞跃。从精准翻译到智能创作,从复杂问答到情感分析,它们正重塑人机交互的未来。本专栏将聚焦于 NLP 与大模型的前沿动态、技术剖析及实战应用,带你领略这一领域的无限魅力与潜力,共同见证语言智能的蓬勃发展。
目录
在当今数字化浪潮中,自然语言处理(NLP)携手大模型,正引领着人工智能的全新变革。NLP 作为理解与生成人类语言的核心技术,正借助大模型的强大算力与海量数据,实现质的飞跃。从精准翻译到智能创作,从复杂问答到情感分析,它们正重塑人机交互的未来。本专栏将聚焦于 NLP 与大模型的前沿动态、技术剖析及实战应用,带你领略这一领域的无限魅力与潜力,共同见证语言智能的蓬勃发展。
本专栏:
从Attention机制到Transformer-CSDN博客
从Attention机制到Transformer02-CSDN博客
【NLP必知必会】注意力机制与自注意力机制详解:从原理到优缺点对比-CSDN博客
【NLP解析】多头注意力+掩码机制+位置编码:Transformer三大核心技术详解-CSDN博客
seq2seq
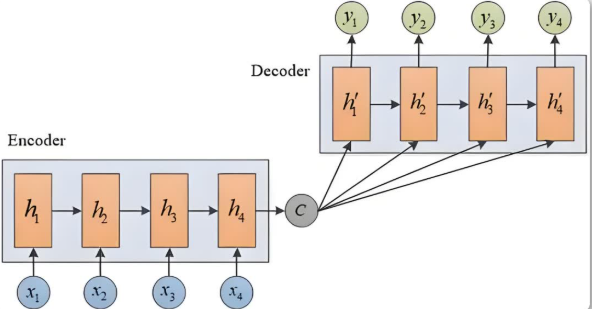
在 Seq2Seq 模型之前,我们一直使用循环神经网络(RNN)用于序列数据处理,但 RNN 只能处理单一的输入和输出,比如在执行翻译任务时,传统 RNN 的输入的是一个个的单词,输出的也是一个个的单词。
想象一下,你正在和一个朋友用中文聊天,而你的朋友突然要求你把这段对话翻译成英文。传统的方法是逐词翻译,比如“我要去饭店”会被机械地翻译成“I am going to restaurant”,但这样的翻译不仅笨拙,还丢失了“我要去”的整体语义。更糟糕的是,像“am”和“to”这样的词在中文中根本没有对应的词语,逐词翻译只会让结果更加混乱。
Seq2Seq(Sequence-to-Sequence)模型由Ilya Sutskever等人在2014年提出,主要用于端到端的序列到序列任务,如机器翻译、语音识别等。
它的核心思想是:不逐词翻译,而是先理解整个句子的意思,再用目标语言完整地表达出来。就像一个翻译高手,他会先听懂你整句话的意思,再用自己的语言重新组织表达,而不是逐字逐句地死搬硬套。
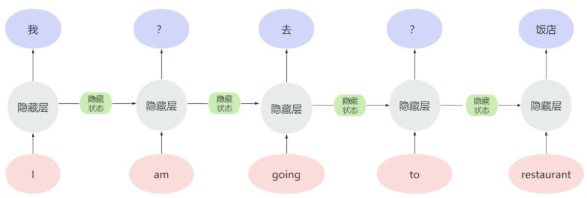
Seq2Seq 模型的工作原理:像接力赛一样传递信息
Seq2Seq 模型由两部分组成:编码器(Encoder) 和 解码器(Decoder)。它们的工作方式就像一场接力赛,编码器负责“理解”,解码器负责“表达”。
编码器:把整句话“压缩”成一个“信息包”
编码器的任务是读取输入的整个句子,把它的意思浓缩成一个固定长度(向量维度)的“信息包”(状态向量)。这个过程就像你把一封信装进一个信封里。比如,当输入“我要去饭店”时,编码器会逐字读取“我”、“要”、“去”、“饭店”,并不断更新它的“理解状态”。
最后,编码器会把整个句子的意思“打包”成一个状态向量,就像把信封封好,准备交给解码器。
解码器:从“信息包”中“解压”出目标语言的句子
解码器拿到编码器传递的“信息包”后,开始逐步生成目标语言的句子。它的工作方式像一个接力赛跑者,每一步都根据前面的结果调整自己的输出。第一步,解码器会根据“信息包”和一个“开始符”(比如“<sos>”),生成第一个单词“我要去饭店”对应的英文“我要去”部分,可能是“I want to”。
第二步,它会根据上一步生成的“want”和“信息包”,继续生成下一个单词“go”。
第三步,解码器会根据“go”和“信息包”,生成“restaurant”。
最后,当解码器生成“停止符”(比如“<eos>”)时,翻译任务就完成了,输出结果是“I want to go to restaurant”。
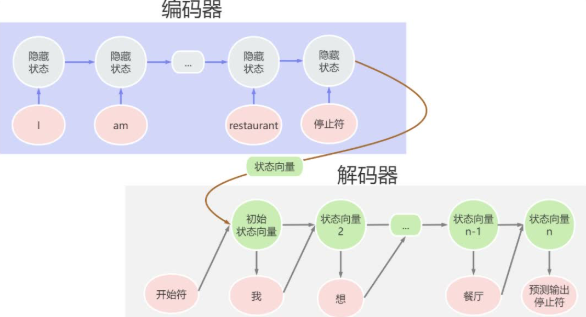
为什么 Seq2Seq 模型比传统方法更聪明?
它理解整个句子的意思
传统 RNN 是逐词翻译的,就像一个只会逐字查字典的人,完全不懂上下文。而 Seq2Seq 模型通过编码器把整个句子的意思“压缩”成一个状态向量,解码器再根据这个状态向量生成目标语言的句子。这种方式让模型能够理解句子的整体语义,而不是机械地逐词翻译。它会“记住”前面的信息。
解码器在生成每个单词时,不仅依赖状态向量,还会参考上一个生成的单词。这种“记忆能力”让模型能够生成更连贯、更自然的句子。它能处理复杂的语言现象
比如,“我要去饭店”中的“要”在英文中没有直接对应的单词,但 Seq2Seq 模型会根据上下文,用“want to”来表达“要”的意思。这种灵活性是传统 RNN 无法做到的。Seq2Seq 模型的应用:从翻译到聊天机器人。
Seq2Seq 模型不仅用于机器翻译,还广泛应用于语音识别、聊天机器人等任务。
语音识别:输入的是一段语音信号,输出的是对应的文本。
聊天机器人:输入的是用户的问题,输出的是机器人的回答。
文本摘要:输入的是一篇长文,输出的是它的摘要。
Teacher Forcing机制
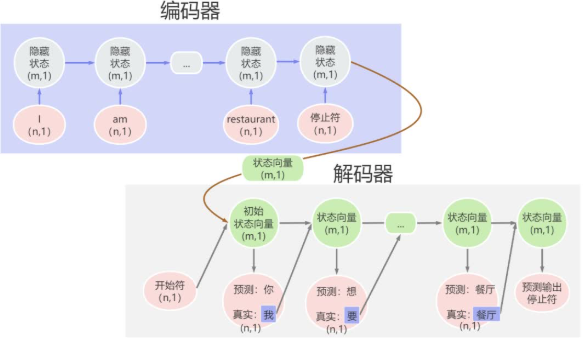
Teacher Forcing(教师强制)是一种在神经网络的训练过程中的优化技巧,主要用于加速模型的学习过程并提高其性能。它的核心思想是使用真实的目标输出来指导解码器的训练过程。具体来说,在训练过程中,解码器在每一步都使用上一步的真实目标词作为输入,而不是依赖于自己的预测结果。这种方法为模型提供了一个稳定的训练框架,有助于更快地收敛到正确的参数值。当然,在模型训练完成后,在生成阶段只能使用推理的输出,因为生成阶段没有真实目标词。
优点
Teacher Forcing为解码器提供了一个稳定的训练框架,利用了真实的目标信息,使得模型能够更快地接近正确的参数值,从而加快训练速度。
潜在缺点
由于Teacher Forcing依赖于真实的目标词,这在实际应用中可能会限制模型在没有外部指导下的独立生成能力。当模型需要独立生成序列时,可能会出现偏离正确输出的情况。
动态调整策略
为了克服Teacher Forcing的潜在问题,研究者们提出了动态调整策略,Teacher Forcing Rate(TFR),TFR是一种动态调整Teacher Forcing使用的比例的方法。初始阶段以较高的比例使用Teacher Forcing,随着训练的进行逐渐降低这个比例,使解码器最终能够独立生成目标序列。
注意力机制
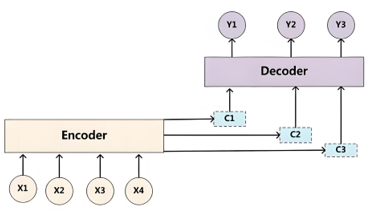
在传统的 Seq2Seq模型中,我们常用 编码器-解码器 结构来处理序列到序列的转换任务,如机器翻译。在这种模型中,编码器将输入序列(例如一句话)压缩成一个固定长度的上下文向量,然后解码器根据这个上下文向量生成输出序列(如翻译后的句子)。然而 Seq2Seq结构存在着一些问题,编码器把所有的输入序列编码成一个语义向量,当输入的序列长度过长时,只靠最后一个时间步的隐藏状态,难免会造成大量信息丢失;此外,由于解码器的初始状态向量是编码器最后一个时间步的隐藏状态,又会导致网络对靠近结尾的数据记忆深刻,而对起始部分的记忆逐渐模糊。这就会产生一些问题,比如我要翻译这句话:
不 要 去 危险的 地方 玩耍
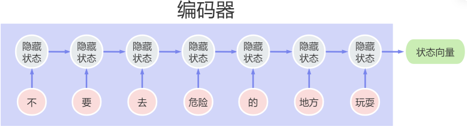
在传统的 Seq2Seq 模型中,状态向量对’玩耍‘和’地方‘的记忆更深刻,而‘不’和‘要’的记忆很模糊,这就导致在翻译的时候,很可能忘记’不‘的信息,而’不‘在句子中的意思很重要,这就使得最终翻译的结果为’要去危险的地方玩‘意思,就完全颠覆了句子。
要改进这些问题,一个比较好的思路就是在解码的时候,不只使用编码器最后一个隐藏状态,而是利用编码器所有时刻的隐藏状态来解码,这样解码的时候就可以获取到全局信息了。
要改进这些问题,一个比较好的思路就是在解码的时候,不只使用编码器最后一个隐藏状态,而是利用编码器所有时刻的隐藏状态来解码,这样解码的时候就可以获取到全局信息了。
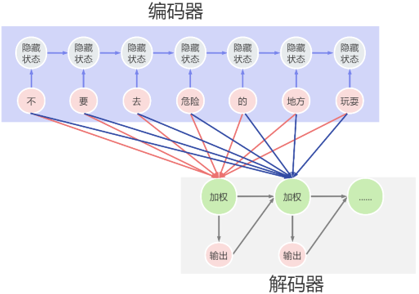
当然,在执行翻译任务的时候,每个输出词语依赖的是不同的输入词。如果每次输出,都要依赖所有的输入,那么每个输出结果都是一样的。所以在不同的输出时间节点,对不同输入词的依赖是不同的,比如输出的是 don't,那么更依赖的就是’不’,’要’;输出的是 <dangerous>,那么更依赖的就是'危险的',其余部分的参考性不大。
比如在解码计算第一个输出内容 don't 的时候,第一个输入节点的隐藏状态占比 40%,第二个输入节点的隐藏状态占比 40%,其余输入节点的隐藏状态占比都不足 10%。这就相当于解码器在每一个时间步,对每个输入序列的隐藏状态分配不同的注意力,attention 机制便由此而来。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 14
14 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)