golang-面试必问的底层数据结构map、 sync.Map、defer 、slice、channel、mutex互斥锁、waitgroup
这里 看下我的值传递和引用传递那篇文章 会对这个有更深的体会切片结构切片又名slice,是Go语言中对可变数组的抽象,相较于数组,具有可动态追加元素和可动态扩容等更加实用的特性。切片在Go语言中对应的结构体源码如下。字段含义说明如下。array,指向数组内存地址的指针。切片底层存储数据的结构就是数组,切片使用一个指向数组的来操作这个数组;len,切片的长度。len表示切片中可用的元素个数,所谓可用
我们平常直接用slice的时候 不用写成xxxslice.data xxxslice.len的方式访问,这是因为我们平常用它的时候,相当于是语法糖,xxxslice其实相当于是
*xxx.Data
不过 初始化的时候 是根据其底层结构来的 new的赋值 是len cap为0 而data为nil
面试常考题
看专门面试那篇博客
普通数组
go数组第一个元素的地址就是数组的地址
数组名取地址(&intArr)与首个元素取地址(&intArr)结果相同
数组元素地址连续存储,后续元素地址=前一个元素地址+该类型字节数(如int64类型间隔8字节)
该特性与数组在内存中的线性存储结构直接相关
+---+---+---+---+---+---+---+---+---+---+
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
+---+---+---+---+---+---+---+---+---+---+
数组的第一个元素存储在内存空间的起始地址0,最后一个元素存储在内存空间的结束地址9。数组的元素之间没有间隔,因此数组的总大小等于数组元素的大小(4字节)乘以数组的长度(10),即40字节。
slice
底层结构
这里 看下我的 值传递和引用传递那篇文章 会对这个有更深的体会
切片结构切片又名slice,是Go语言中对可变数组的抽象,相较于数组,具有可动态追加元素和可动态扩容等更加实用的特性。切片在Go语言中对应的结构体源码如下。
type slice struct {
array unsafe.Pointer
len int
cap int
}
字段含义说明如下。
-
array,指向数组内存地址的指针。切片底层存储数据的结构就是数组,切片使用一个指向数组的指针来操作这个数组;
-
len,切片的长度。len表示切片中可用的元素个数,所谓可用,就是内存空间被分配,并且通过当前切片能够访问;
-
cap,切片的容量。cap表示切片最大的元素个数,通常cap大于等于len,如果cap大于len,表示当前切片有部分元素不可用,而不可用的意思就是内存空间被分配,但是当前切片无法访问,访问这些不可用元素会导致panic。
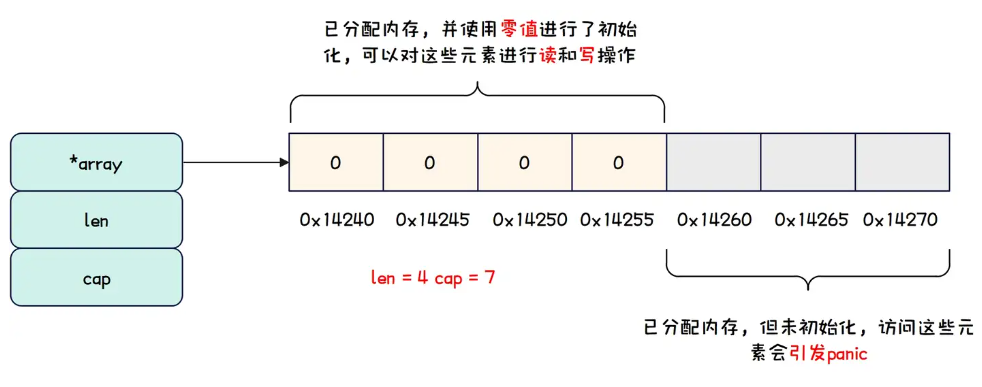
切片,顾名思义,其实就是可以从已经存在的数组上切一段作为切片,从整个数组切的示例代码如下所示。
// 从整个数组切得到切片
func sliceFromWholeArray() {
originArray := [7]int{0, 1, 2, 3, 4, 5, 6}
slice := originArray[:]
fmt.Printf("originArrayAddress=%p\n", &originArray)
fmt.Printf("len=%d, cap=%d, sliceAddress=%p, sliceArrayAddress=%p\n",
len(slice), cap(slice), &slice, slice)
}
然后我们可以 从前到后切数组得到切片,示例代码如下所示。// 从前到后切数组得到切片
func sliceFromArrayFrontToBack() {
originArray := [7]int{0, 1, 2, 3, 4, 5, 6}
slice := originArray[:4]
fmt.Printf("origin array address is: [%p]\n", &originArray)
fmt.Printf("len=%d, cap=%d, sliceAddress=%p, sliceArrayAddress=%p\n",
len(slice), cap(slice), &slice, slice)
}
扩容
当我们向一个切片中添加元素时,如果切片的容量不足以容纳新元素,就会发生扩容。在扩容时,Go 语言会分配一个新的底层数组并将原有的元素复制到新数组中。
切片的扩容规则
切片的容量扩容遵循以下几个原则:
初始容量:当你使用 make 函数创建切片时,可以指定初始容量。如果你不指定,容量默认为长度。
s := make([]int, 0, 5) // 创建一个长度为0,容量为5的切片
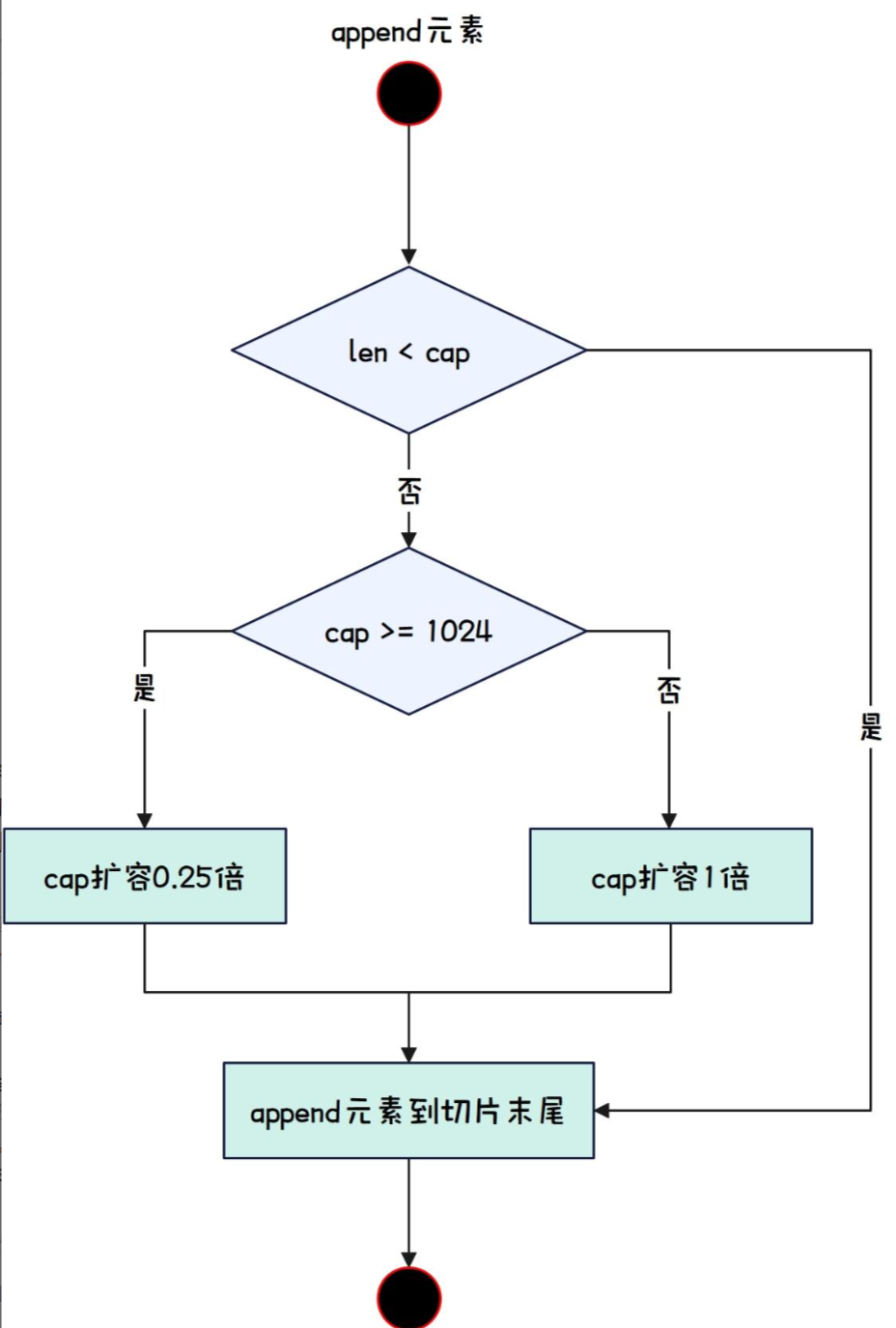
简单扩容:当切片容量不足以容纳新的元素时,Go 会为新切片分配一个新的底层数组。扩容的策略通常是将容量增加为原来的两倍。
例如:
如果原切片长度为 5,容量也为 5,添加一个元素后,切片将会扩容,新的容量将变为 10。
如果原切片长度为 6,容量为 8,添加一个元素后,切片会扩容,新的容量将变为 16。
可变扩容:在某些情况下,如果切片的当前容量接近 Go 认为的“合适”的大小,扩容可能会以其他方式进行。这是为了提高性能并减少内存碎片。例如,当切片的容量在某个范围内(比如 1 到 1024),它的扩容策略会是按比例扩容。而当超过 1024 后,可能会按照倍数扩容。
内存使用与性能
从内存角度看,切片的扩容不仅会分配新的底层数组,而且还需要将原切片里的元素复制到新的数组中。这个操作是 O(n) 的时间复杂度,因为需要复制每一个元素。如果你预测到切片的增长很大,可以考虑在创建切片时预先设置合适的容量,以减少内存分配和复制的次数。
Map
本质是哈希表
阅读前先看之前写的redis数据结构的哈希字典
https://blog.csdn.net/S_ZaiJiangHu/article/details/130551748
底层结构
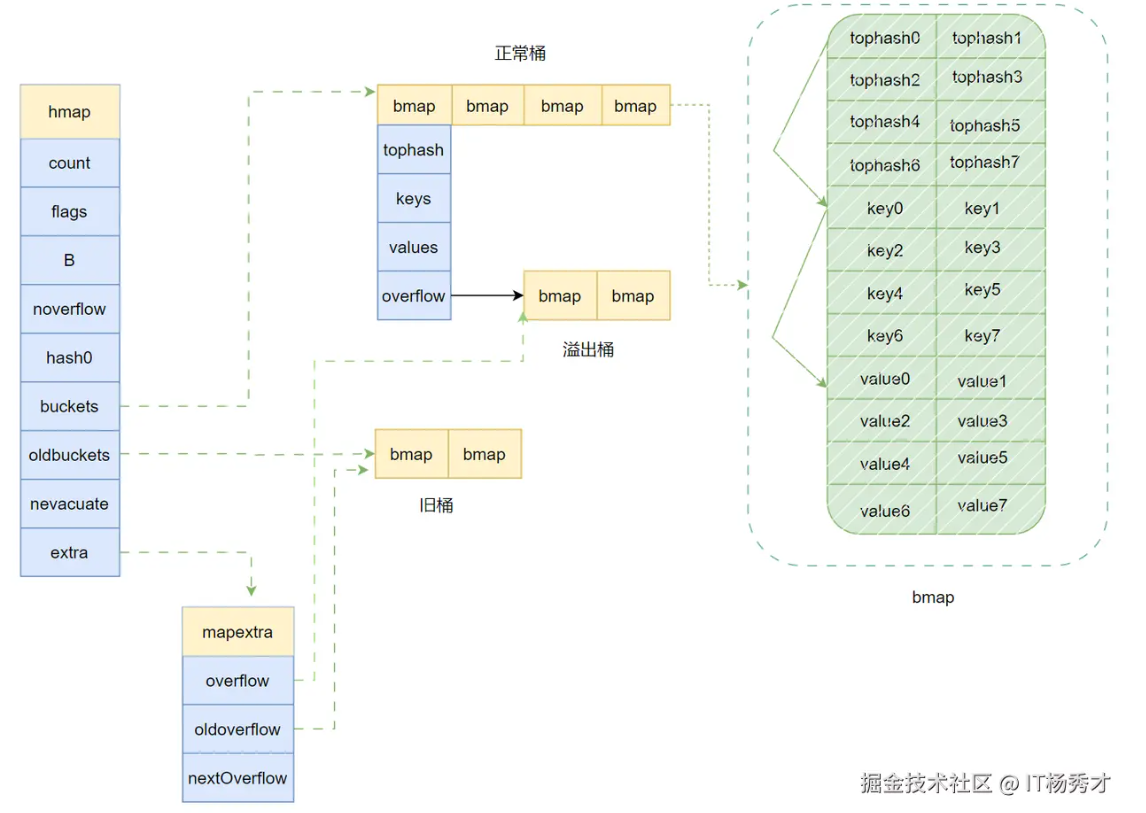
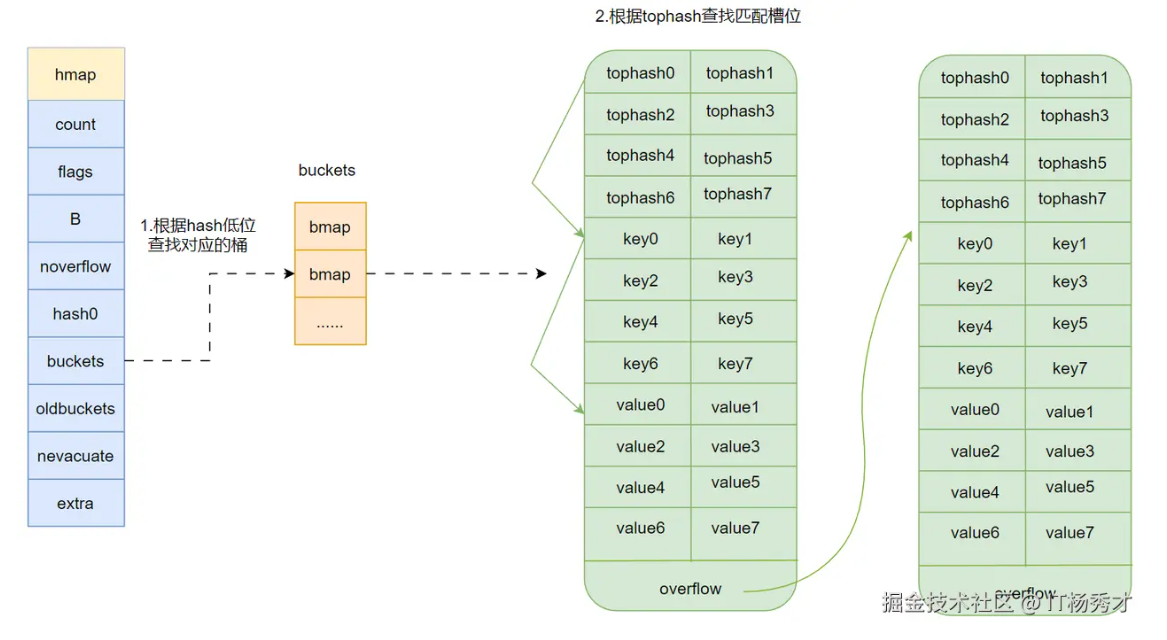
Go语言中的Map其实就是一个指向hmap的指针,占用8个字节。所以Map底层结构就是hmap,hmap包含多个结构为bmap的bucket数组,bucket底层采用链表结构将这些bmap连接起来,处理冲突其实是采用了优化的拉链法,链表中每个节点存储的不是一个键值对,而是8个键值对。其整体的结构如下图:
ps:redis的map如下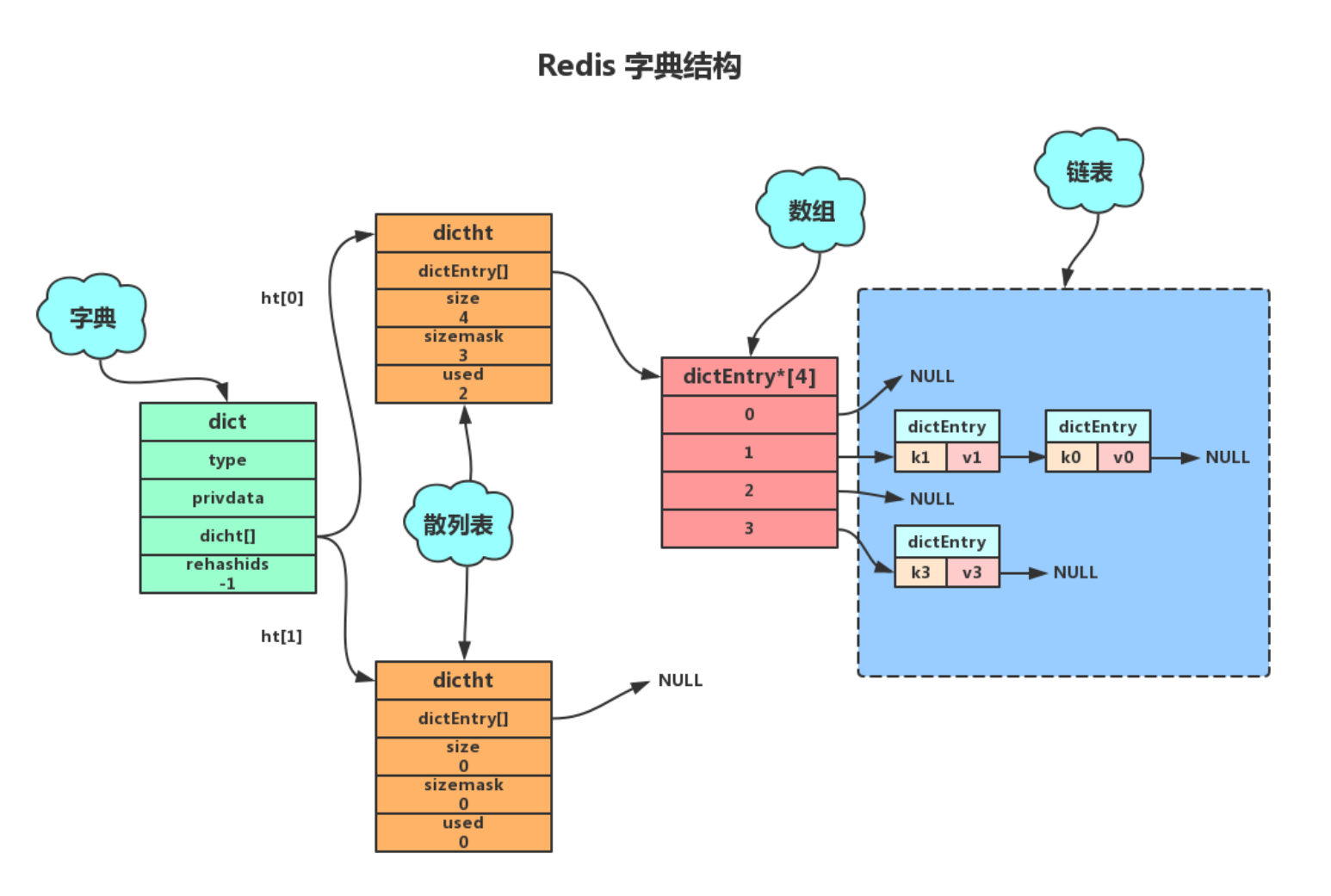
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
- count:map中元素个数,对应于len(map)的值
- flags:状态标志位,标记map的一些状态
- B:buckets 的对数大小(2^B 表示桶的数量),即B=log_2(len(buckets)),比如B=3,那么桶数为2^3=8
- buckets :指向buckets数组的指针,哈希桶的数组,存储键值对的实际数据。buckets数组的元素为bmap,如果数组元素个数为0,其值为nil
- hash0 :哈希种子 用于随机化哈希函数,防止哈希冲突攻击。
- noverflow:溢出桶数量近似值
- oldbuckets :是一个指向buckets数组的指针,在扩容时,oldbuckets 指向老的buckets数组(大小为新buckets数组的一半),非扩容时,oldbuckets 为空
- nevacuate :表示扩容进度的一个计数器,小于该值的桶已经完成迁移
- extra :指向mapextra 结构的指针,mapextra 存储map中的溢出桶
在 Go 1.18 之前,Go 的哈希种子是固定的,这可能导致一些问题(比如彩虹表撞库),例如在某些情况下,攻击者可以通过精心构造的输入数据导致哈希表的性能下降(称为“HashDoS”攻击)。通过引入哈希随机化,每次程序启动时都会使用不同的哈希种子,从而增加攻击的难度。
extra 是一个指针,指向一个元素个数为2的数组,数组的类型是一个指针,指向一个slice,slice的元素是桶(bmap)的地址,这些桶都是溢出桶。为什么有两个?因为Go map在哈希冲突过多时,会发生扩容操作。表示当前使用的溢出桶集合,是在发生扩容时,保存了旧的溢出桶集合。extra 存在的意义在于防止溢出桶被gc。
bucket (bmap)的结构
hmap中真正用于存储数据的是buckets指向的这个bmap(桶)数组,每一个 bmap 都能存储 8 个键值对,当map中的数据过多,bmap数组存不下的时候就会存储到extra指向的溢出bucket(桶)里面
下面看一下bmap的结构定义:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
overflow uintptr
}
每个桶中包含:
- topbits 存储了bmap里8个key/value键值对的每个key根据哈希函数计算出的hash值的高 8 位
- 一个定长数组用于存储键。存储了bmap里8个key/value键值对的key
- 一个定长数组用于存储值。存储了bmap里8个key/value键值对的value
- 一个附加的链表指针(溢出桶),用于存储冲突过多时溢出的数据。
再解释一下这个tophash,go语言的map会根据每一个key计算出一个hash值,有意思的是,对这个hash值的使用,go语言并不是一次性使用的,而是分开使用的,在使用中,把求得的这个hash值按照用途一分为二:高位和低位
假设我们对一个key做hash计算得到了一个hash值如图所示,蓝色就是这个hash值的高8位,红色就是这个hash值的低8位。而每个bmap中其实存储的就是8个这个蓝色的数字。 通过上图map的底层结构图我们可以看到,bmap的结构,bmap显示存储了8个tohash值,然后存储了8个键值对,注意,这8个键值对并不是按照key/value这样key和value放在一起存储的,而是先连续存完8个key,之后再连续存储8个value这样,当键值对不够8个时,对应位置就留空。这样存储的好处是可以消除字节对齐带来的空间浪费
其他更多
详细看https://juejin.cn/post/7414541124666884123
访问原理
-
判断map是否为空或者无数据,若为空或者无数据返回对应的空值
-
map写检测,如果正处于写状态,表示此时不能进行操作,报fatal error
-
计算出hash值和掩码
-
判断当前map是否处于扩容状态,如果在扩容执行下面步骤:
- 根据状态位算判断当前桶是否被迁移
- 如果迁移,在新桶中查找
- 未被迁移,在旧桶中查找
- 根据掩码找到的位置
- 依次遍历桶以及溢出桶来查找key
-
遍历桶内的8个槽位
-
比较该槽位的tophash和当前key的tophash是否相等
-
相同,继续比较key是否相同,相同则直接返回对应value
-
不相同,查看这个槽位的状态位是否为"后继空状态"
- 是,key在以后的槽中也没有,这个key不存在,直接返回零值
- 否,遍历下一个槽位
-
- 当前桶没有找到,则遍历溢出桶,用同样的方式查找
赋值原理
有两点需要注意:
在对map进行赋值操作的时候,map一定要先进行初始化,否则会panic
var m map[int]int
m[1] = 1
m只是做了声明为一个map,并未初始化,所以程序会panic
map是非线程安全的,不支持并发读写操作。当有其他线程正在读写map时,执行map的赋值会报为并发读写错误
package main
import (
"fmt"
)
func main() {
m := make(map[int]int)
go func() {
for {
m[1] = 1
}
}()
go func() {
for {
v := m[1]
fmt.Printf("v=%d\n", v)
}
}()
select {}
}
运行结果:
fatal error: concurrent map read and map write
map赋值的大致流程:
-
map写检测,如果正处于写状态,表示此时不能进行读取,报fatal error
-
计算出hash值,将map置为写状态
-
判断同数组是否为空,若为空,初始化桶数组
-
目标桶查找
- 根据hash值找到桶的位置
- 判断该当前是否处于扩容:
若正在扩容:迁移这个桶,并且还另外帮忙多迁移一个桶以及它的溢出桶 - 获取目标桶的指针,计算出tophash,开始后面的key查找过程
- key查找
- 遍历桶和它的溢出桶的每个槽位,按下述方式查找
- 判断槽位的tophash和目标tophash
- 不相等
- 槽位tophash为空,标记这个位置为侯选位置
- 槽位tophash的标志位为“后继空状态”,说明这个key之前没有被插入过,插入key/value
- tophash标志位不为空,说明存储着其他key,说明当前槽的tophash不符合,继续遍历下一个槽
- 相等
判断当前槽位的key与目标key是否相等- 不相等,继续遍历下一个槽位
- 相等,找到了目标key的位置,原来已存在键值对,则修改key对应的value,然后执行收尾程
- 不相等
- key插入
- 若map中既没有找到key,且根据这个key找到的桶及其这个桶的溢出桶中没有空的槽位了,要申请一个新的溢出桶,在新申请的桶里插入
- 否则在找到的位置插入
- 收尾程序
- 再次判断map的写状态
- 清除map的写状态
这里需要注意一点:申请一个新的溢出桶的时候并不会一开始就创建一个溢出桶,因为map在初始化的时候会提前创建好一些溢出桶存储在extra*mapextra字段,样当出现溢出现象时候,这些下溢出桶会优先被使用,只有预分配的溢出桶使用完了,才会新建溢出桶
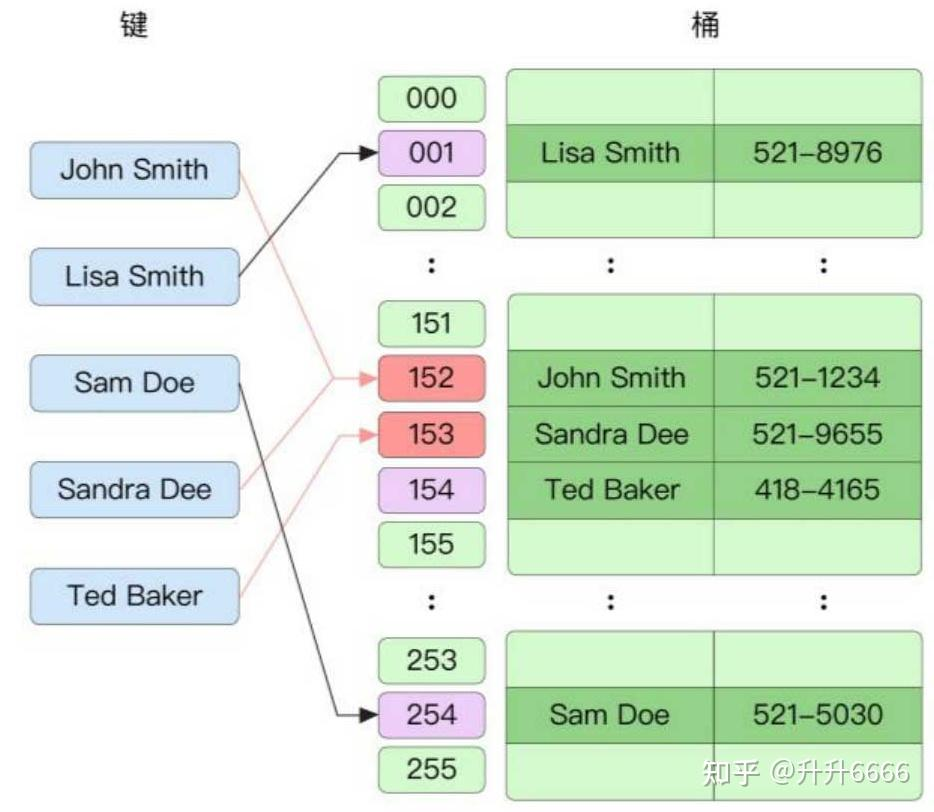
哈希冲突
Go 语言中使用开放地址法的线性探查法。但每个桶的容量不会大于8,当超出时会将数据添加到溢出桶中。
扩容
https://juejin.cn/post/7414541124666884123#heading-5这个讲的也很好 更详细 结合看看
当map中的元素数量不断增加时,哈希冲突的概率也会随之增加,导致查找效率下降。为了保持map的高效性,Go语言在map的元素数量达到一定阈值时会触发扩容操作。
扩容的触发条件
Go语言中的map在以下两种情况下会触发扩容:
- 负载因子过高:负载因子是指map中元素数量与桶数量的比值。当负载因子超过一定阈值时,map会进行扩容。默认情况下,负载因子的阈值为6.5,即当map中的元素数量超过桶数量的6.5倍时,会触发扩容。
- 溢出桶过多:当map中的溢出桶数量过多时,也会触发扩容。溢出桶是指当某个桶中的键值对数量超过8个时,多余的键值对会存储到溢出桶中。如果溢出桶的数量过多,说明哈希冲突较为严重,此时也需要进行扩容。
扩容的具体步骤
当map触发扩容时,Go语言会按照以下步骤进行扩容操作:
- 分配新的桶数组:首先,Go语言会分配一个新的桶数组,新桶数组的大小是原桶数组的两倍。新桶数组的大小为2^(B+1),其中B是原桶数组的大小。
- 迁移数据:接下来,Go语言会将原桶数组中的数据逐步迁移到新桶数组中。迁移的过程是渐进式的,即在每次插入、删除或查找操作时,都会迁移一部分数据。这样可以避免一次性迁移大量数据导致的性能问题。
- 更新map的头部信息:当所有数据都迁移完成后,Go语言会更新map的头部信息,将buckets指针指向新的桶数组,并释放旧的桶数组。
渐进式迁移的实现
渐进式迁移是Go语言map扩容的一个重要特性。它通过在每次操作时迁移一部分数据,避免了扩容过程中可能出现的性能瓶颈。
具体来说,Go语言在map的头部结构中维护了一个nevacuate字段,用于记录当前迁移的进度。每次进行插入、删除或查找操作时,Go语言会检查nevacuate字段,并根据该字段的值决定是否需要迁移数据。
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// ...
if h.growing() {
growWork(t, h, bucket)
}
// ...
}
func growWork(t *maptype, h *hmap, bucket uintptr) {
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
在mapassign函数中,如果map正在扩容(h.growing()返回true),则会调用growWork函数进行数据迁移。growWork函数会调用evacuate函数,将指定桶中的数据迁移到新桶数组中。
扩容的并发安全性
Go语言中的map并不是并发安全的,即在多个goroutine同时读写map时,可能会导致数据竞争问题。然而,在扩容过程中,Go语言通过一些机制来保证扩容的并发安全性。
具体来说,Go语言在扩容过程中会使用oldbuckets字段来保存旧的桶数组,并在迁移数据时通过nevacuate字段来记录迁移的进度。这样,即使在扩容过程中有多个goroutine同时访问map,也不会导致数据竞争问题。
扩容的性能影响
虽然Go语言的map扩容机制设计得非常巧妙,但在实际应用中,扩容操作仍然会对性能产生一定的影响。特别是在数据量较大时,扩容操作可能会导致短暂的性能下降。
为了减少扩容操作对性能的影响,可以在创建map时预先指定一个合适的容量。这样可以避免在插入大量数据时频繁触发扩容操作。
m := make(map[string]int, 1000)
在上面的代码中,我们创建了一个初始容量为1000的map,这样可以减少在插入大量数据时触发扩容的次数。
sync.Map
源码与实际细节看 https://zhuanlan.zhihu.com/p/452538971
Go map 默认是并发不安全的,同时对 map 进行并发读写的时,程序会 panic,原因如下:Go 官方经过长时间的讨论,认为 map 适配的场景应该是简单的(不需要从多个 gorountine 中进行安全访问的),而不是为了小部分情况(并发访问),导致大部分程序付出锁的代价,因此决定了不支持。
什么是并发安全?首先是说 类似一系列操作我们需要它是原子化的
这里需要指出 和类似mysql的读写冲突、写写冲突有区别,那些主要是按照时间顺序进来的 虽然实际执行顺序可能也收到进程线程调度机制影响,但是其实算是大部分可以预期谁先谁后的
而语言层面的并发冲突是指 线程或者协程或者进程的执行顺序每次都是很不确定的,所以多次执行相同代码后,会出现每次都不一样的情况。当然了 语言层面并发冲突也是和原子操作有关系 我们通常只要保证是原子化的即可。
map 在扩缩容时,需要进行数据迁移,迁移的过程并没有采用锁机制防止并发操作,而是会对某个标识位标记为 1,表示此时正在迁移数据。如果有其他 goroutine 对 map 也进行写操作,当它检测到标识位为 1 时,将会直接 panic。
如果想实现map线程安全,有两种方式:
- 方式一:使用读写锁 map + sync.RWMutex
- 方式二:使用golang提供的 sync.Map
但是方式一 锁的粒度太大
sync.Map与map的区别
- 并发安全
sync.Map内部使用了锁和其他同步原语来保证并发访问的安全性 - 无需初始化
sync.Map的零值是一个空的并发安全映射结构,而不是nil,因此不需要使用make函数初始化,可以直接声明后使用。 - 特殊的API
sync.Map提供特定的方法如Load、Store等,与内置map的语法不同
sync.Map设计原理(也是和自己加锁的区别)
核心思想:
-
尽可能无锁化:要实现并发安全,很难做到无锁化。但是为了提高性能,应该尽可能使用原子操作,最大化减少锁的使用。
-
读写分离:读写分离式针对读多写少场景的常用手段,面对读多写少的场景能够提供高性能的访问。其思想是空间换时间。
sync.map中冗余的数据结构就是dirty和read,二者存放的都是key-entry,entry其实是一个指针,指向value,read和dirty各自维护一套key,key指向的都是同一个value,也就是说,只要修改了这个entry,对read和dirty都是可见的。
read相当于是dirty的备份快照或者高速缓存,dirty中保存的是最新完整的数据。sync.map的核心就在于read和dirty的互动
read好比整个sync.Map的一个“高速缓存”,当goroutine从sync.Map中读数据时,sync.Map会首先查看read这个缓存层是否有用户需要的数据(key是否命中),如果有(key命中),则通过原子操作将数据读取并返回,这是sync.Map推荐的快路径(fast path),也是sync.Map的读性能极高的原因。
通过 read(负责读的map) 和 dirty (负责写的map)两个字段将读写分离,读的数据存放在只读字段 read 上,最新写入的数据则存放在 dirty 字段上
- 读取时会先查询 read,不存在再查询 dirty
- 写入时则只写入 dirty
- 读取 read 并不需要加锁,而读或写 dirty 都需要加锁
- 另外有 misses 字段来统计 read 被穿透的次数(被穿透指需要读 dirty 的情况),超过一定次数则将 dirty 数据同步到 read 上
- 对于删除数据则直接通过标记来延迟删除
重要设计思想:
1、空间换时间
如果采用传统的大锁方案,其锁的竞争十分激烈,也就意味着需要花在锁上的时间很多,我们要尽可能的减少时间消耗,针对耗时太长的情况,算法中有一种常见的解决方案,空间换时间,采用冗余的数据结构,来减少时间的消耗。
sync.map中冗余的数据结构就是dirty和read,二者存放的都是key-entry,entry其实是一个指针,指向value,read和dirty各自维护一套key,key指向的都是同一个value,也就是说,只要修改了这个entry,对read和dirty都是可见的。
那空间换时间策略在sync.map中到底是如何体现的呢?到底在哪些地方减少了耗时?
遍历操作:只需遍历read即可,而read是并发读安全的,没有锁,相比于加锁方案,性能大为提升
查找操作:先在read中查找,read中找不到再去dirty中找
核心思想就是一切操作先去read中执行,因为read是并发读安全的,无需锁,实在在read中找不到,再去dirty中。read在sycn.map中是一种冗余的数据结构,因为read和dirty中数据有很大一部分是重复的,而且二者还会进行数据同步。
2、读写分离
sync.map中有专门用于读的数据结构:read,将其和写操作分离开来,可以避免读写冲突,而采用读写分离策略的代价就是冗余的数据结构,其实还是空间换时间的思想。
3、双检查机制
在sync.map中,每次当read不符合要求要去操作dirty前,都会上锁,上锁后再次判断是否符合要求,因为read有可能在上锁期间,产生了变化,突然又符合要求了,read符合要求了,尽量还是在read中操作,因为read并发读安全。
4、延迟删除
在删除操作中,删除kv,仅仅只是先将需要删除的kv打一个标记,这样可以尽快的让delete操作先返回,减少耗时,在后面迁移数据时,再一次性的删除需要删除的kv
5、read优先
需要进行读取,删除,更新操作时,优先操作read,因为read无锁的,更快,实在在read中得不到结果,再去dirty中。
6、状态机机制
entry的指针p,是有状态的,nil,expunged(指向被删除的元素),正常,三种状态。
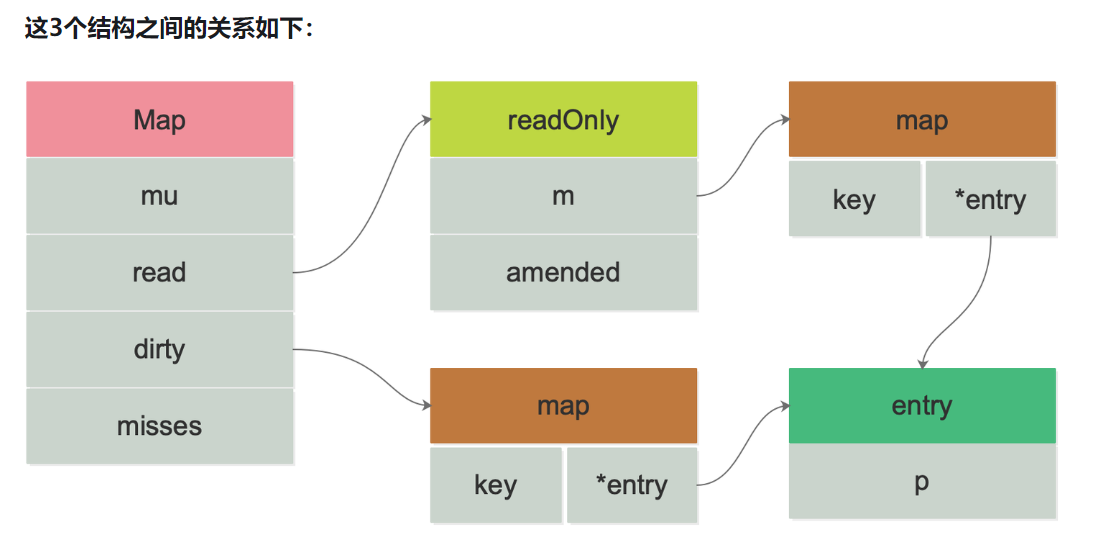
数据结构定义
type Map struct {
// 互斥锁,用于保护dirty字段和misses字段。
mu Mutex
// readOnly, 一个atomic.Value类型的字段,实际存储了一个readOnly结构体,用于存储只读数据。
read atomic.Value
// 一个map,存储了所有可写的键值对。是最新写入的数据
dirty map[interface{}]*entry
// 一个计数器,记录了从read读取失败的次数,用于触发将数据从dirty迁移到read的决定策略,每次需要读 dirty 则 +1。
misses int
}
//即上面的atomic.Value类型
type readOnly struct {
m map[interface{}]*entry // 实际存储键值对的map。
amended bool // 标记位,如果dirty中有read中没有的键,那么为true
entry 数据结构则用于存储值的指针:
type entry struct {
p unsafe.Pointer // 等同于 *interface{}
}
var expunged = unsafe.Pointer(new(interface{}))
这里的属性 p 有三种状态:
存活态:正常指向元素,key-entry 对仍未删除
软删除态:p == nil,read map 和 dirty map 底层的 map 结构仍存在 key-entry 对,但在逻辑上该 key-entry 对已经被删除,因此无法被用户查询到
硬删除态:p == expunged,指向固定的全局变量 expunged,dirty map 中已不存在该 key-entry 对
sync.Map内部包含四个主要字段:
- 后置锁(用于保护dirty map)。
- read字段,它包含一个原子指针,指向一个readOnly结构,而readOnly结构中又包含一个普通的map。这个read map主要用于在无锁情况下进行并发读操作,它存储了大部分的键值对数据,并且在某些情况下可以避免加锁带来的性能开销。
- dirty字段,同样是一个map,它用于存储在read map中不存在或者需要更新的键值对。dirty map和read map的结构基本相同,只是dirty map中多了一个字段用于标记哪些键是在read map中不存在的。
- miss字段,它是一个计数器,用于记录从read map中读取数据失败(即未找到对应键)的次数。当miss次数达到一定阈值时,会触发将dirty map中的数据同步到read map中的操作,以保证read map中的数据相对较新,从而提高后续读操作的命中率。

sync.Map 的工作机制
sync.Map 有以下方法:
- Load:读取指定 key 返回 value
- Store: 存储(增或改)key-value
- Delete: 删除指定 key
- Range:遍历所有键值对,参数是回调函数
- LoadOrStore:读取数据,若不存在则保存再读取
使用示例
package main
import (
"fmt"
"sync"
)
func main() {
var m sync.Map
// 1. 写入
m.Store("qcrao", 18)
m.Store("stefno", 20)
// 2. 读取
age, _ := m.Load("qcrao")
fmt.Println(age.(int))
// 3. 遍历
m.Range(func(key, value interface{}) bool {
name := key.(string)
age := value.(int)
fmt.Println(name, age)
return true
})
// 4. 删除
m.Delete("qcrao")
age, ok := m.Load("qcrao")
fmt.Println(age, ok)
// 5. 读取或写入
m.LoadOrStore("stefno", 100)
age, _ = m.Load("stefno")
fmt.Println(age)
}
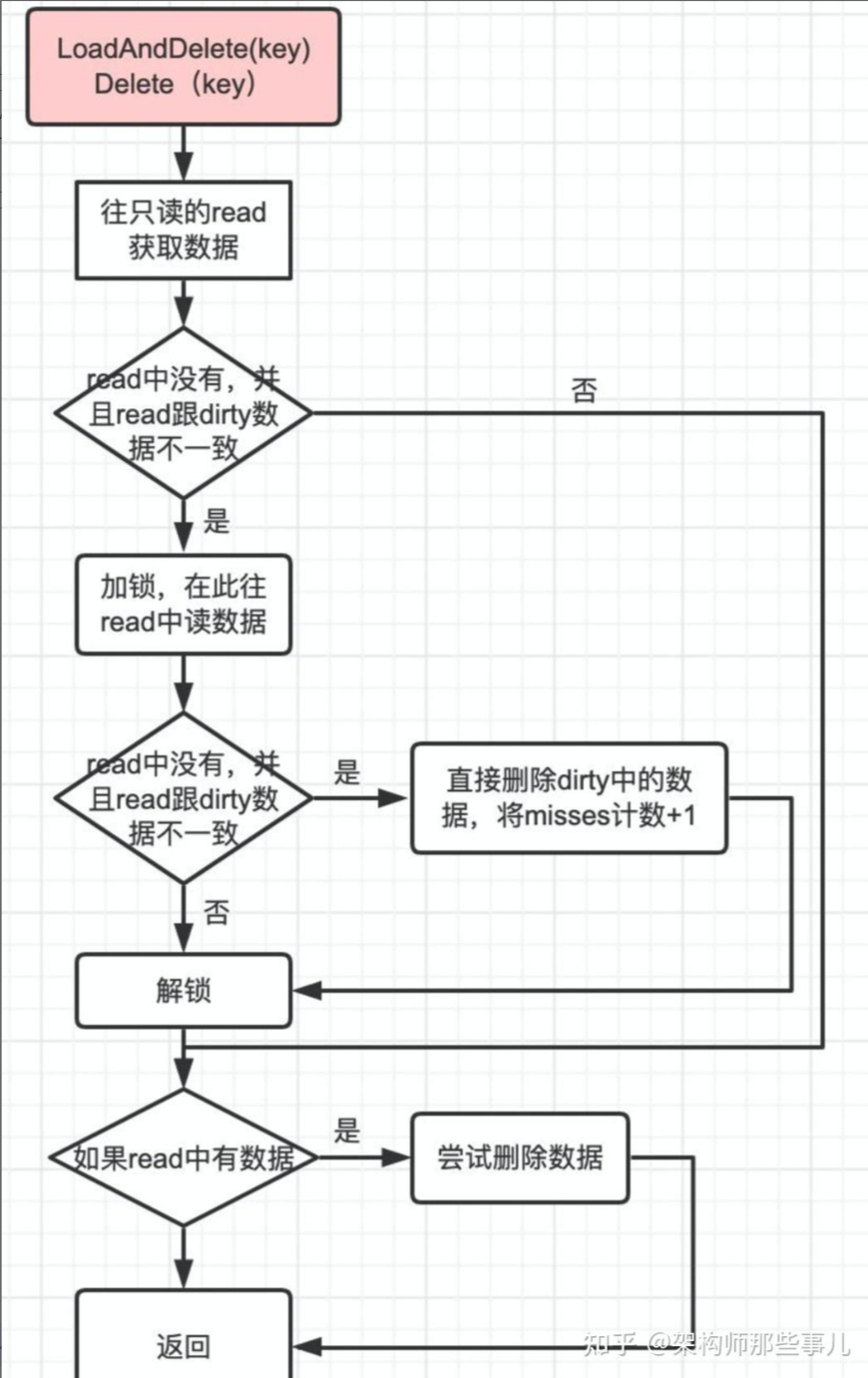
数据读取
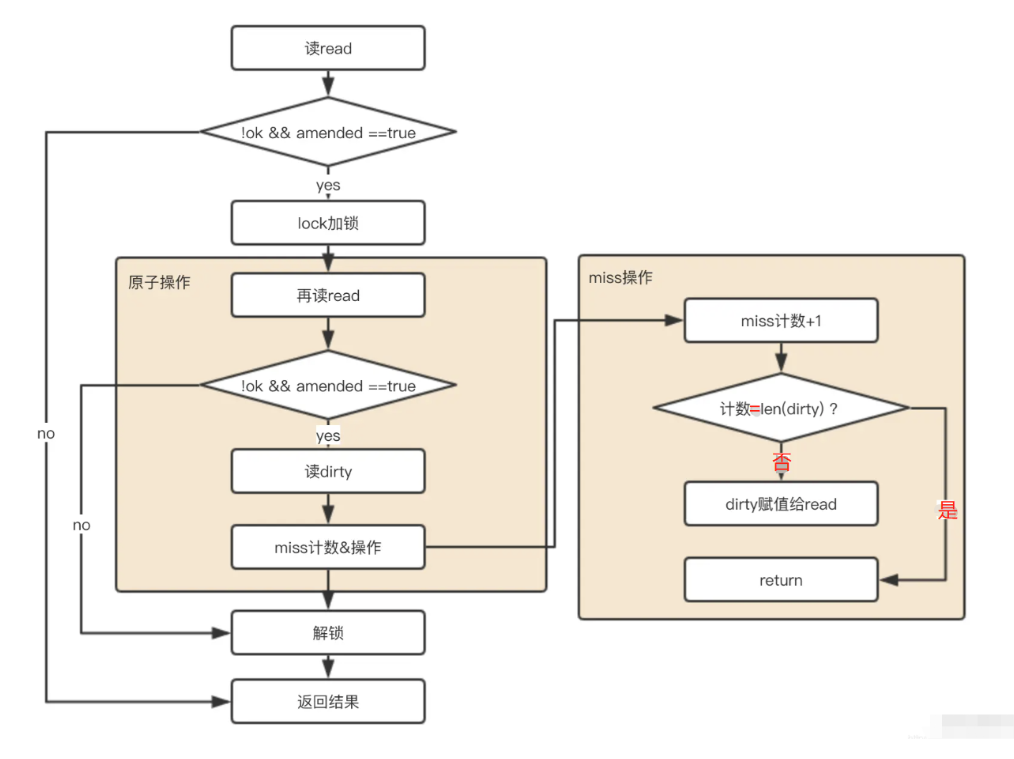
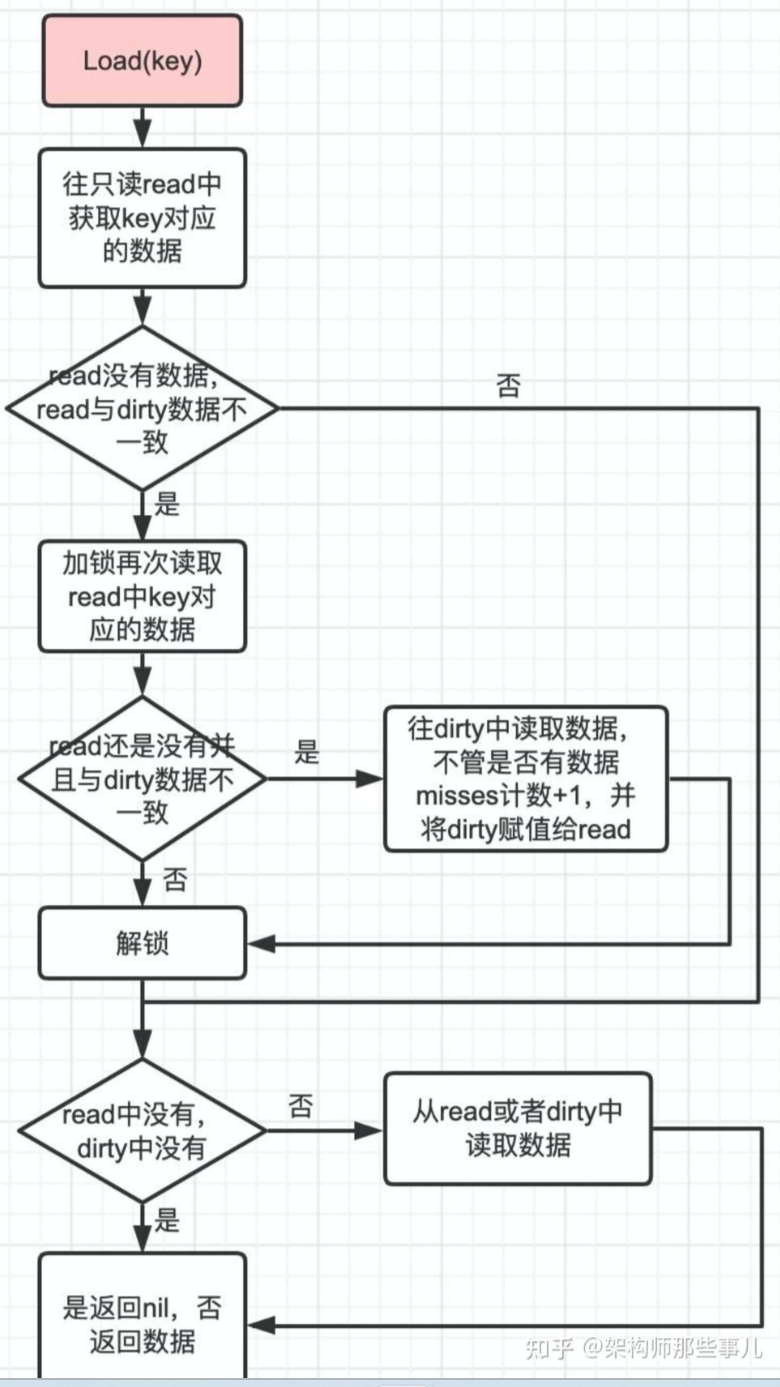
当从sync.Map中读取数据时,首先会尝试从read map中读取。由于read map在无锁情况下支持并发读,所以大多数情况下读操作可以快速完成。如果在read map中找到了对应键的值,则直接返回该值。
如果在read map中未找到键,那么就会去读取dirty map中的数据。但由于dirty map是可读写的,所以在读取之前需要获取锁来保证并发安全。如果在dirty map中找到了键,那么会将miss计数器加 1,表示这次读操作未命中read map。
- 首先尝试从 read 中读取 如果read中能读到,直接返回
- 如果该key在read中不存在,且在dirty中存在:
- 加锁
- 由于上面 read 获取没有加锁,为了安全需要再对read再做一次读取检查
- 如果read能够读取到,解锁,直接返回读取结果
- 如果确实read中不存在,dirty中存在,则从 dirty 获取
- 更新穿透读次数,如果穿透读的次数达到一定数量(大于或等于dirty的长度),将dirty中的数据同步到read中,并清空dirty,同时调整穿透次数为0,
- 解锁,返回读取结果
- 如果dirty中也不存在,直接返回nil
- 在返回读取结果时,如果发现该对象已经被标记为删除或者值对象指针被指向一个nil,直接返回nil
数据写入与更新
写入和更新操作相对复杂一些,因为需要考虑read map和dirty map之间的数据同步。
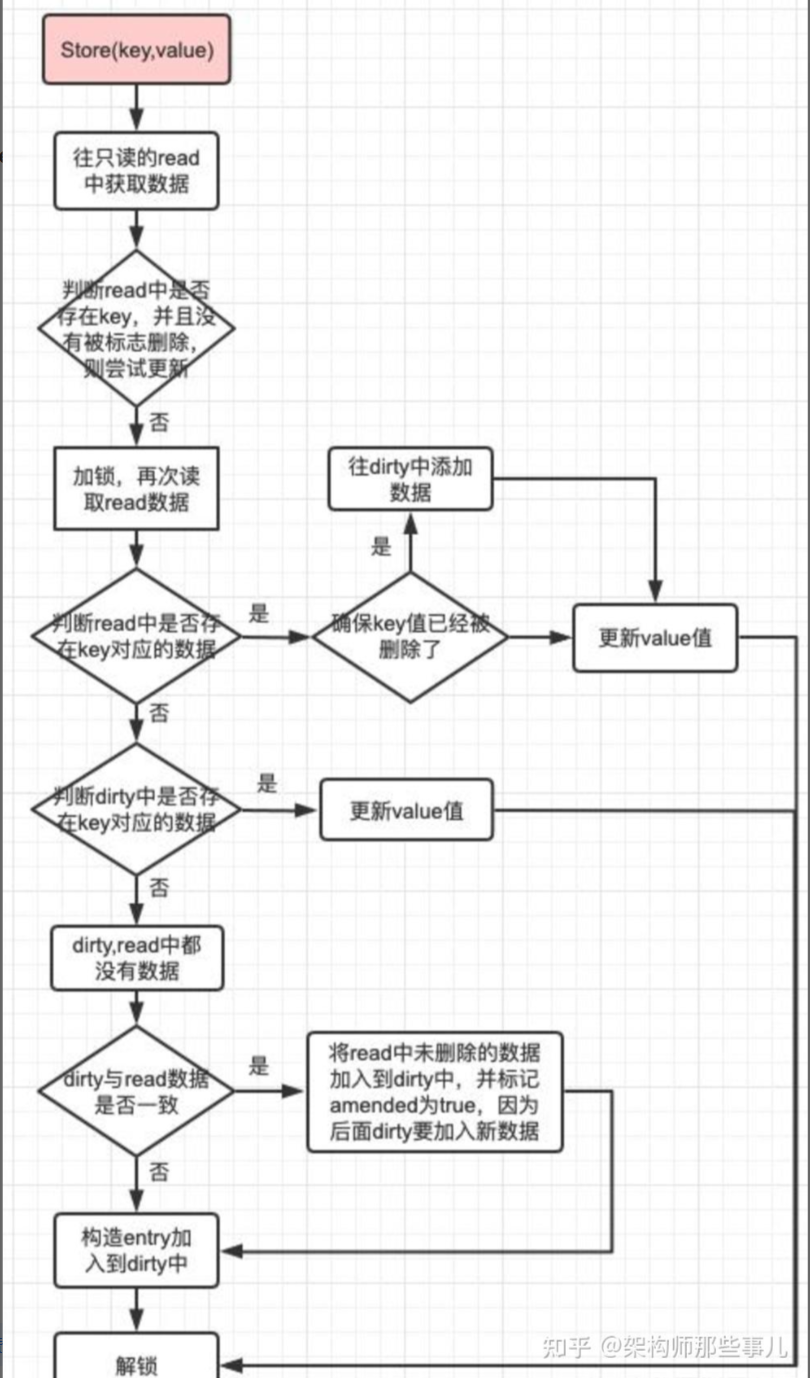
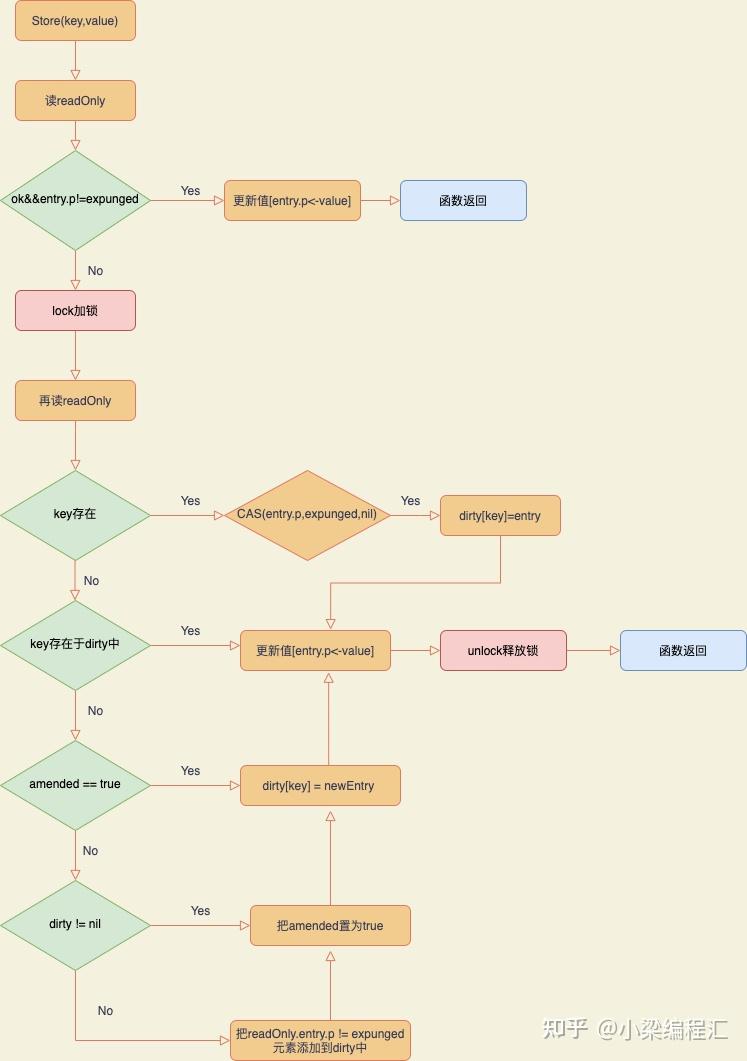
当向sync.Map写入新键值对时
如果键在read map中不存在且dirty map已经存在,则直接将键值对写入dirty map。
如果dirty map不存在,则需要先初始化dirty map,并将read map中的数据复制到dirty map中(这是一个相对较重的操作,所以尽量避免频繁触发),然后再将新键值对写入dirty map。
如果键在read map中存在,且对应的readOnly结构中的标记表示该键只存在于read map中(即未被标记为在dirty map中也存在),则需要将该键值对标记为在dirty map中存在,并将新值写入dirty map。同时,将miss计数器加 1,因为后续读操作可能需要从dirty map中读取该键的值。
步骤: 这个好像顺序有点点问题 以后再看把
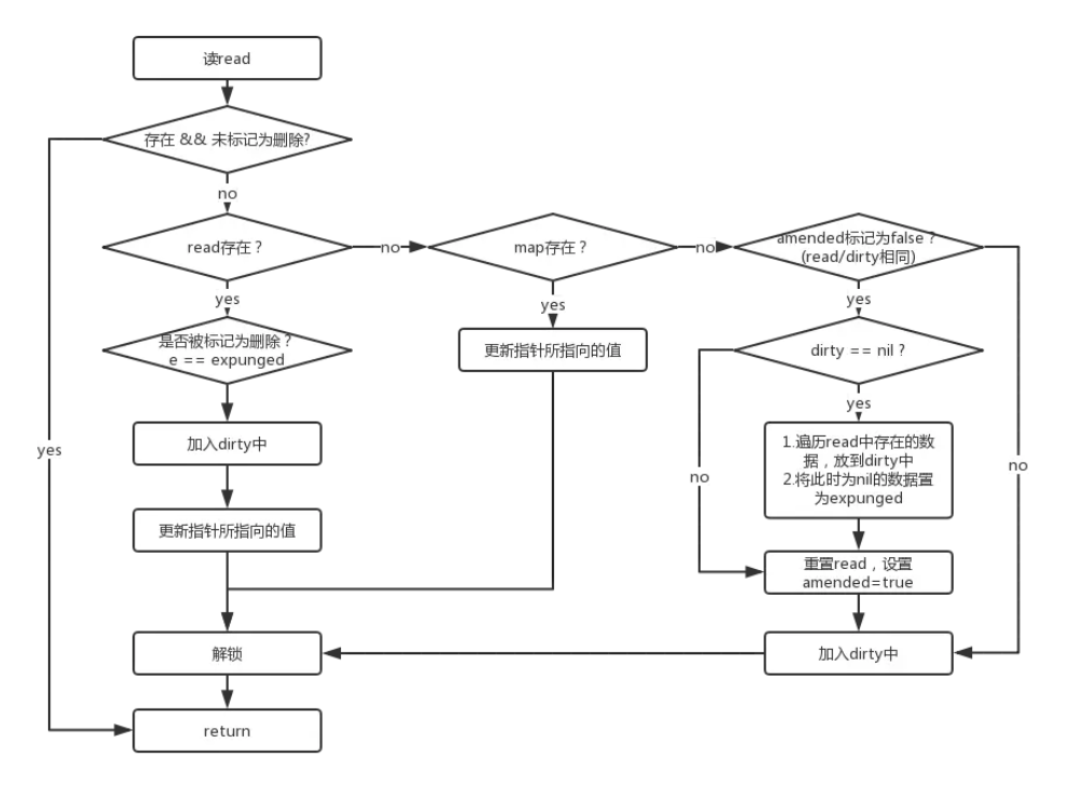
- 如果read中存在,且该对象在read中未被标识为删除,直接存到read的对象中(这好像不对啊 应该是写dirty?)
- 如果第一步未成功,需要分情况处理,接下来的操作需要在加锁环境下进行
- 加锁
- 再次尝试从read中获取该key对应的对象,如果该对象存在:
- 说明该key已经被标识为删除,需要把该删除标识去掉,同时把该对象的地址初始化为nil
- 重新将该对象写入到dirty中
- 如果该key不存在read中,则判断是否存在dirty中,如果存在,直接更新dirty中的值
- 如果该key 在 read 和 dirty 里都不存在
- 如果 read 的 amended 的值为 false,且dirty是空的,需要把read中未被标识为删除的对象拷贝到dirty中;同时将read的 amended 属性值设置为 true,表示 dirty 中包含一些不存在read中的key
- 将key和值对象存到dirty中
- 释放锁
删除
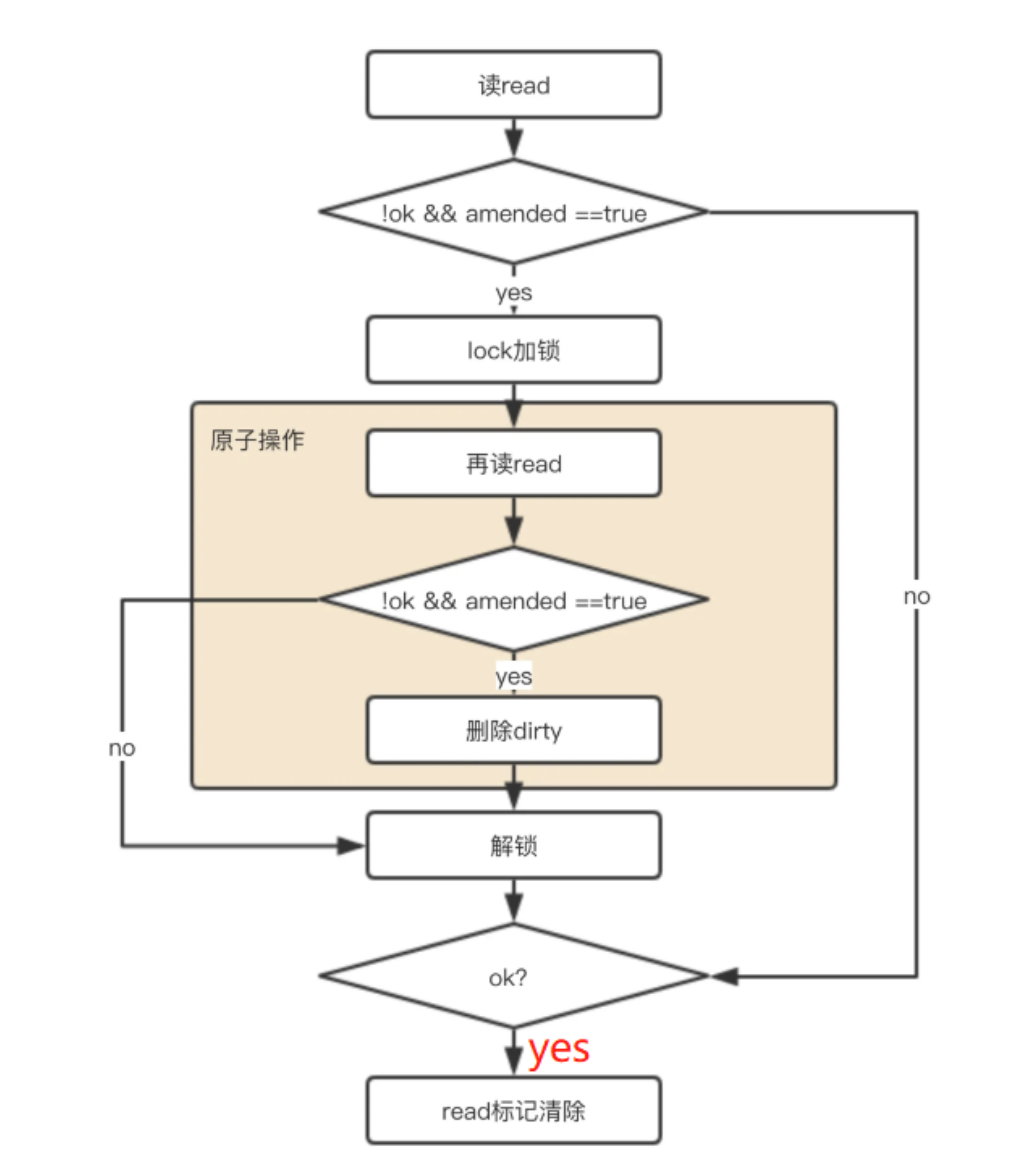
- 如果 key 在 read 中不存在,但 dirty 中存在:
- 加锁
- 直接删除dirty中的值对象,并更新穿透读次数,如果穿透读的次数达到一定数量(大于或等于dirty的长度),将dirty中的数据同步到read中,并清空dirty,同时调整穿透次数为0
- 解锁
- 不管key存在read中还是dirty中,最终都会将该key对应的对象的指针地址设置为nil,(真正设置为 expunged 删除标识是在 store时,在给dirty同步read数据时,针对nil对象会把该对象设置为 expunged 标识)
数据同步
sync.Map会根据miss计数器的值来决定是否将dirty map中的数据同步到read map中。当miss次数达到一定阈值时,会进行一次同步操作。同步操作会将dirty map中的数据复制到read map中,并清空dirty map,同时将miss计数器重置为 0。这样可以保证read map中的数据始终保持相对较新,提高读操作的效率。
遍历
番外篇:怎么遍历 sync.Map?
很多人以为 sync.Map 没办法遍历,其实是有的,只不过方式跟普通 map 不一样,用的是 Range() 方法:
m.Range(func(key, value any) bool {
fmt.Printf(“%v: %v\n”, key, value)
return true // 返回 false 会终止遍历
})
这个 API 比较“笼统”,因为 key 和 value 类型都是 any,你需要自己类型断言一下。
总结
结构层面基本总结
- read map 由于是原子包托管,主要负责高性能,但是无法保证拥有全量的 key,因为对于新增 key,会首先加到 dirty 中,所以 read 某种程度上,类似于一个 key 的快照,这个快照在某些情况下可能是全量快照。
- sync.map中冗余的数据结构就是dirty和read,二者存放的都是key-entry,entry其实是一个指针,指向value,read和dirty各自维护一套key,key指向的都是同一个value,也就是说,只要修改了这个entry,对read和dirty都是可见的。
- dirty map 拥有全量的 key,当 Store 操作要新增一个之前不存在的 key 的时候,会先增加到 dirty 中的。
- 在查找指定的 key 的时候,总会先去 read map 中寻找,并不需要锁定互斥锁。只有当 read 中没有,但 dirty 中可能会有这个 key 的时候,才会在锁的保护下去访问 dirty。
- 在存储键值对的时候,只要 read 中已存有这个 key,并且该键值对未被标记为 expunged,就会把新值存到里面并直接返回,这种情况下也不需要用到锁。
- read 和 dirty 之间是会互相转换的,在 dirty 中查找 key 对次数足够多的时候,sync.Map 会把 dirty 直接作为 read,即触发 dirty->read 的转变,此时 read 中拥有全量的 key。同时在某些情况,也会出现 read->dirty 的转变,比如当写入一个key在read 和 dirty中都不存在时,如果此时diry为空, 需要把read中未被标记为删除的数据同步到dirty。
使用场景
适用于:
1,读多写少
2、某些情况下的写多,但是key不经常变动但value频繁更新的场景,或者多个goroutine独立操作不同key的场景,它提供了更细粒度的锁,但在某些通用场景下可能不如sync.RWMutex高效。对于大多数自定义需求,sync.RWMutex封装是更常见的选择。
不适用于:
• 写操作频繁,比如需要频繁更新、删除的缓存(比如 TTL 缓存),会触发频繁的 map 替换和锁竞争,性能反而可能拉跨。请老实使用map+sync.Mutex
• 对数据结构操作需要复杂逻辑(比如顺序遍历、批量更新)的时候,sync.Map 的 API 不支持这些复杂操作。
读多写少场景
在许多实际应用中,存在大量并发读操作,但写操作相对较少的情况,例如缓存系统。在这种场景下,sync.Map的优势尤为明显。由于读操作大多可以在无锁的read map中完成,所以性能非常高。而写操作虽然相对复杂一些,但由于其发生频率较低,对整体性能的影响较小。
例如,我们可以使用sync.Map来缓存数据库查询结果。多个goroutine可以同时读取缓存中的数据,如果缓存未命中,则再去数据库查询并将结果存入缓存。这样可以有效减少对数据库的查询压力,提高系统的整体性能。
多个 goroutine 对互不相交键集合操作场景
当多个goroutine并发操作sync.Map时,如果它们操作的键集合互不相交,那么sync.Map也能发挥很好的性能优势。例如,在一个分布式系统中,不同的节点可能会对共享的sync.Map进行操作,但每个节点操作的键都是与其他节点不同的。这种情况下,由于不同goroutine之间几乎不会发生键冲突,所以可以有效减少锁竞争,提高并发性能。
注意问题
适用场景与注意问题
(1)sync.Map 适用于读多、更新多、删多、写少的场景;
(2)倘若写操作过多,sync.Map 基本等价于互斥锁 + map;
(3)sync.Map 可能存在性能抖动问题,主要发生于在读/删流程 miss 只读 map 次数过多时(触发 missLocked 流程),下一次插入操作的过程当中(dirtyLocked 流程).
其他问题
既然 nil 表示标记删除,expunged 的意义是什么
避免了 nil 值可能带来的歧义:nil 值可能是键的有效值,因此不能简单地依靠 nil 值来判断键是否存在或已被删除
提高了删除操作的效率:直接将值标记为 expunged,而不是删除键值对,可以避免重新分配内存或进行其他复杂的操作,从而提高了删除操作的效率
保持了并发安全性:通过将键的对应值设置为 expunged,sync.Map 在并发环境中仍然能够保持正确的状态和操作一致性
为什么需要使用 entry 的 expunged 态 态来区分软硬删除呢?仅用 nil 一种状态来标识删除不可以吗?
回答:
首先需要明确,无论是软删除(nil)还是硬删除(expunged),都表示在逻辑意义上 key-entry 对已经从 sync.Map 中删除,nil 和 expunged 的区别在于:
(1)软删除态(nil):read map 和 dirty map 在物理上仍保有该 key-entry 对,因此倘若此时需要对该 entry 执行写操作,可以直接 CAS 操作;
(2)硬删除态(expunged): dirty map 中已经没有该 key-entry 对,倘若执行写操作,必须加锁(dirty map 必须含有全量 key-entry 对数据).
设计 expunged 和 nil 两种状态的原因,就是为了优化在 dirtyLocked 前,针对同一个 key 先删后写的场景. 通过 expunged 态额外标识出 dirty map 中是否仍具有指向该 entry 的能力,这样能够实现对一部分 nil 态 key-entry 对的解放,能够基于 CAS 完成这部分内容写入操作而无需加锁.
流动
dirty map -> read map
(3)记录读/删流程中,通过 misses 记录访问 read map miss 由 dirty 兜底处理的次数,当 miss 次数达到阈值,则进入 missLocked 流程,进行新老 read/dirty 替换流程;此时将老 dirty 作为新 read,新 dirty map 则暂时为空,直到 dirtyLocked 流程完成对 dirty 的初始化;
read map -> dirty map
(4)发生 dirtyLocked 的前置条件: I dirty 暂时为空(此前没有写操作或者近期进行过 missLocked 流程);II 接下来一次写操作访问 read 时 miss,需要由 dirty 兜底;
(5)在 dirtyLocked 流程中,需要对 read 内的元素进行状态更新,因此需要遍历,是一个线性时间复杂度的过程,可能存在性能抖动;
(6)dirtyLocked 遍历中,会将 read 中未被删除的元素(非 nil 非 expunged)拷贝到 dirty 中;会将 read 中所有此前被删的元素统一置为 expunged 态.
channel
更详细看 https://juejin.cn/post/7428168209712873487#heading-0
数据结构
简单来说
首先是在堆里 channel是用来实现goroutine间通信的,其生命周期和作用域几乎都不太可能仅仅局限于某个具体的函数内,所以在设计的时候就直接在堆上创建。
包含一个send队列和receive队列,当缓冲区满了或者无缓冲的时候,就会加到里面(比如多个向我们的chan发送数据 需要按照顺序连起来 然后阻塞接受) (虽然比如不带缓存 也要都存起来 体会下)
还含有一个环形数组用于缓冲区,虽然叫环形 但是实际上就是普通数组 只是我们的用法像环形 。之所以是环形 是因为chan既可以写也可以读 所以
此外就是一些一些标记的下标
为什么要分send、receive队列 与 环形数组呢?看似都一样啊 都要存起来 这个意义是 因为有的阻塞 有的非阻塞 阻塞用于“强同步”的场景 所以有必要区分开
channel用make函数创建初始化的时候会在堆上分配一个runtime.hchan类型的数据结构,并返回指针指向堆上这块hchan内存区域,所以channel是一个引用类型
为什么要在堆上创建这个hchan结构而不是栈上?我是这样理解的,channel是用来实现goroutine间通信的,其生命周期和作用域几乎都不太可能仅仅局限于某个具体的函数内,所以在设计的时候就直接在堆上创建。
runtime.hchan的类型定义在源码src/runtime/chan.go中:
type hchan struct {
// chan 里元素数量
qcount uint
// chan 底层循环数组的长度
dataqsiz uint
// 指向底层循环数组的指针
// 只针对有缓冲的 channel
buf unsafe.Pointer
// chan 中元素大小
elemsize uint16
// chan 是否被关闭的标志
closed uint32
// chan 中元素类型
elemtype *_type // element type
// 已发送元素在循环数组中的索引
sendx uint // send index
// 已接收元素在循环数组中的索引
recvx uint // receive index
// 等待接收的 goroutine 队列
recvq waitq // list of recv waiters
// 等待发送的 goroutine 队列
sendq waitq // list of send waiters
// 保护 hchan 中所有字段
lock mu
type hchan struct {
qcount uint // 循环队列中的数据总数
dataqsiz uint // 循环队列大小
buf unsafe.Pointer // 指向循环队列的指针
elemsize uint16 // 循环队列中的每个元素的大小
closed uint32 // 标记位,标记channel是否关闭
elemtype *_type // 循环队列中的元素类型
sendx uint // 已发送元素在循环队列中的索引位置
recvx uint // 已接收元素在循环队列中的索引位置
recvq waitq // 等待从channel接收消息的sudog队列
sendq waitq // 等待向channel写入消息的sudog队列
lock mutex // 互斥锁,对channel的数据读写操作加锁,保证并发安全
}
type hchan struct {
qcount uint
dataqsiz uint
buf unsafe.Pointer
elemsize uint16
closed uint32
elemtype *_type
sendx uint
recvx uint
recvq waitq
sendq waitq
lock mutex
}
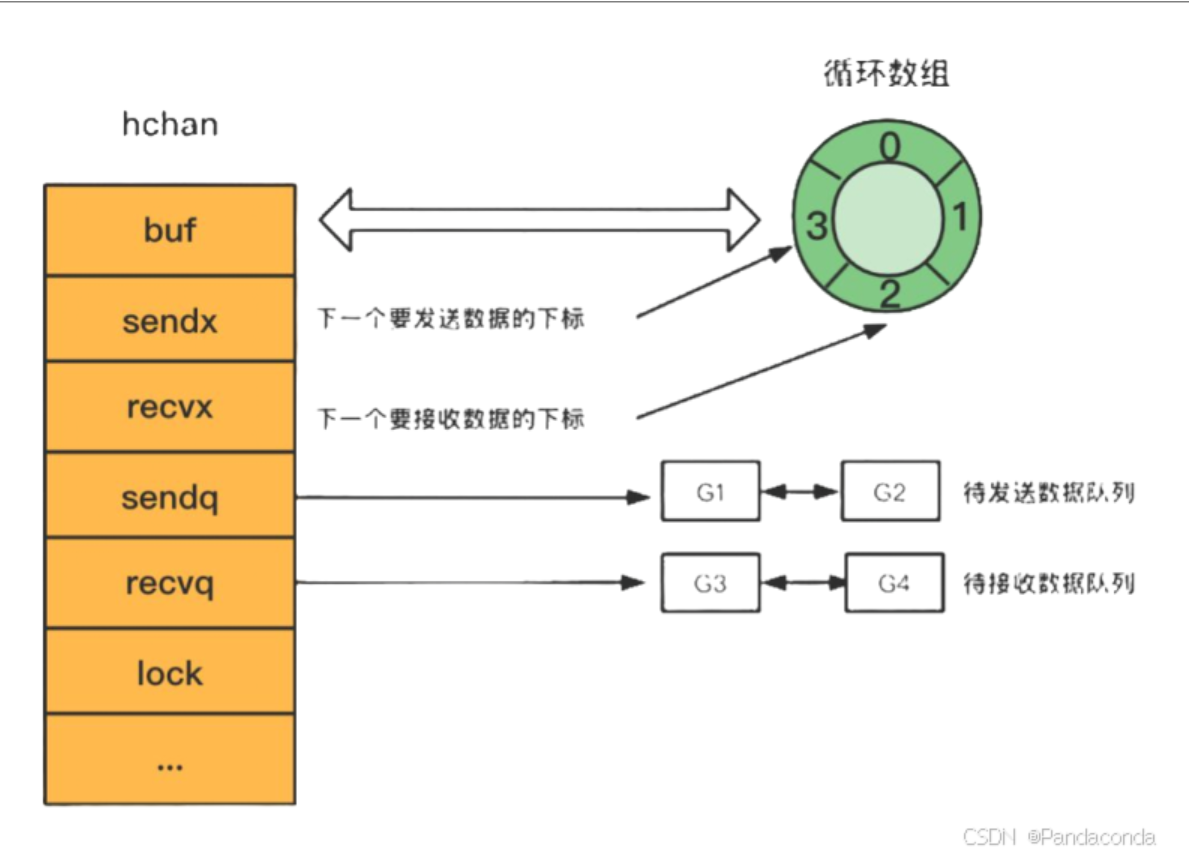
- qcount — Channel 中循环数组的元素个数;
- dataqsiz — Channel 中的循环数组的长度;
- buf — Channel 的缓冲区数据指针,指向一个循环数组;
- sendx — Channel 的发送操作要写入循环数组的位置;
- recvx — Channel 的接收操作要读取循环数组的位置;
- sendq 和 recvq 存储了当前 Channel 由于缓冲区空间不足而阻塞的 Goroutine 列表,这些等待队列使用双向链表 runtime.waitq 表示,链表中所有的元素都是 runtime.sudog 结构:
type waitq struct {
first *sudog
last *sudog
}
runtime.sudog 表示一个在等待列表中的 Goroutine,该结构中存储了两个分别指向前后 runtime.sudog 的指针以构成链表。
结构图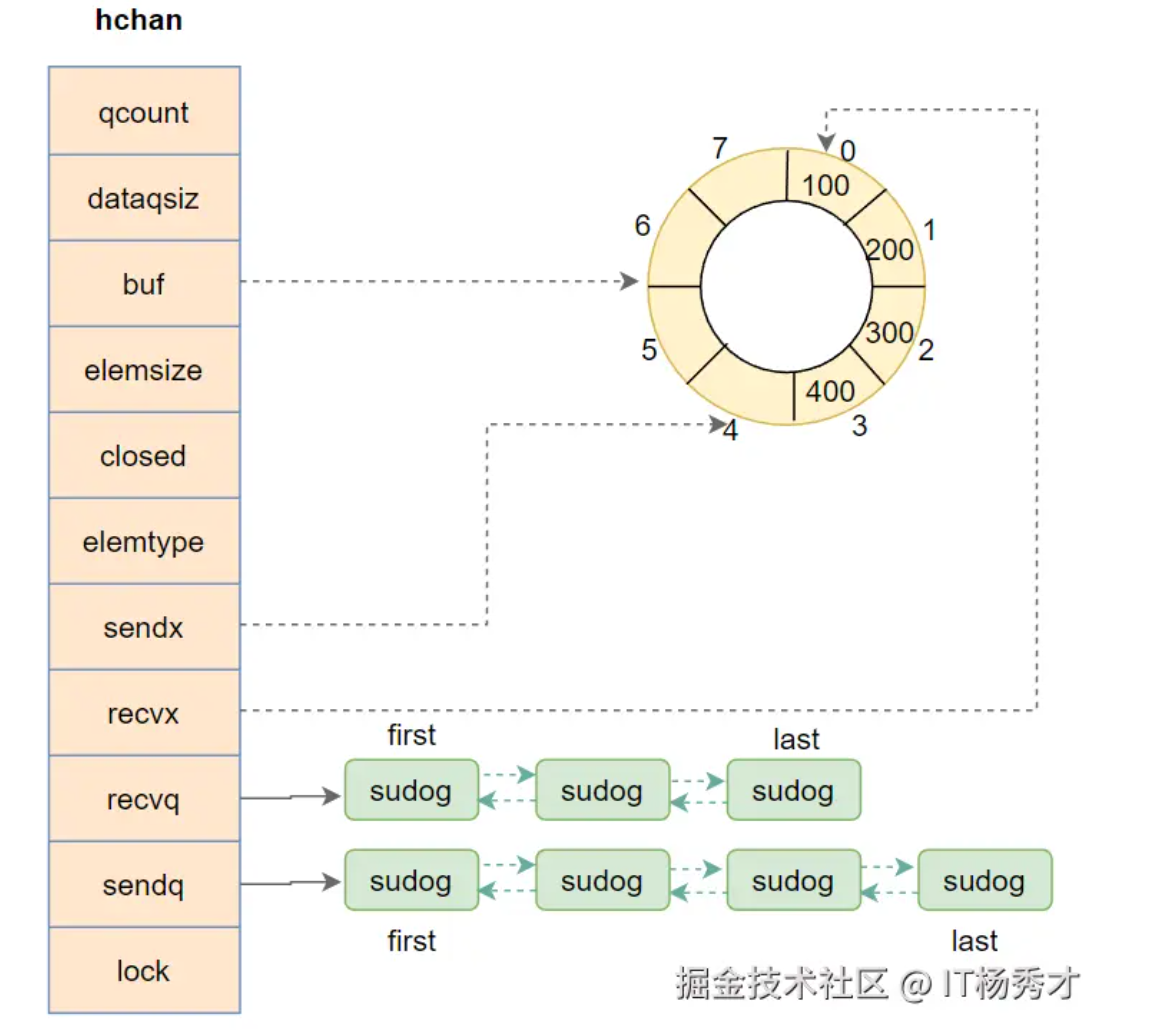
在上面这个例子中,channel的长度buf为8,元素个数为4,其中有四个元素100,200,300,400。可以发送的索引sendx为4,可以接受的索引为recvq为0
设计思想
在 Go Blog 提到一句话。大体意思是:Go 鼓励使用 Channel 在 goroutine 之间传递数据引用,而不是显式地使用锁来协调对共享数据的访问。并引用《Effective Go》再次强调:不要通过共享内存的方式进行通信,而是应该通过通信的方式共享内存
这是Go最经典的设计模式。Go主张两个不同的goroutine能够独立运行并且不存在直接关联,但是能通过channel间接完成通信。
基于这种思想,Go 开发团队在设计 channel 的时候遵循了两大设计原则,分别是:先进先出和无锁管道
Channel 的收发操作均遵循了先进先出的设计原则:
- 先从 Channel 读取数据的 Goroutine 会先接收到数据;
- 先向 Channel 发送数据的 Goroutine 会得到先发送数据的权利;
带缓冲区和不带缓冲区的 Channel 都会遵循先入先出发送和接收数据
无锁管道
严格来讲,Channel 是一个用于同步和通信的有锁队列,Channel内部的hchan结构体中包含了用于保护成员变量的互斥锁。
但这并不妨碍go追求无锁管道的设计追求
比如,当发送数据时,如果存在阻塞的goroutine(接收者),会直接从recvq双向链表头部(最先陷入等待的 goroutine )取出阻塞的goroutine(接收者),将数据发送给阻塞的接收者。
Channel的优异特性得益于其巧妙的数据结构设计,了解其数据结构对我们掌握 Channel 尤为重要。
流程
https://juejin.cn/post/7433790718744444939 更多详细的看
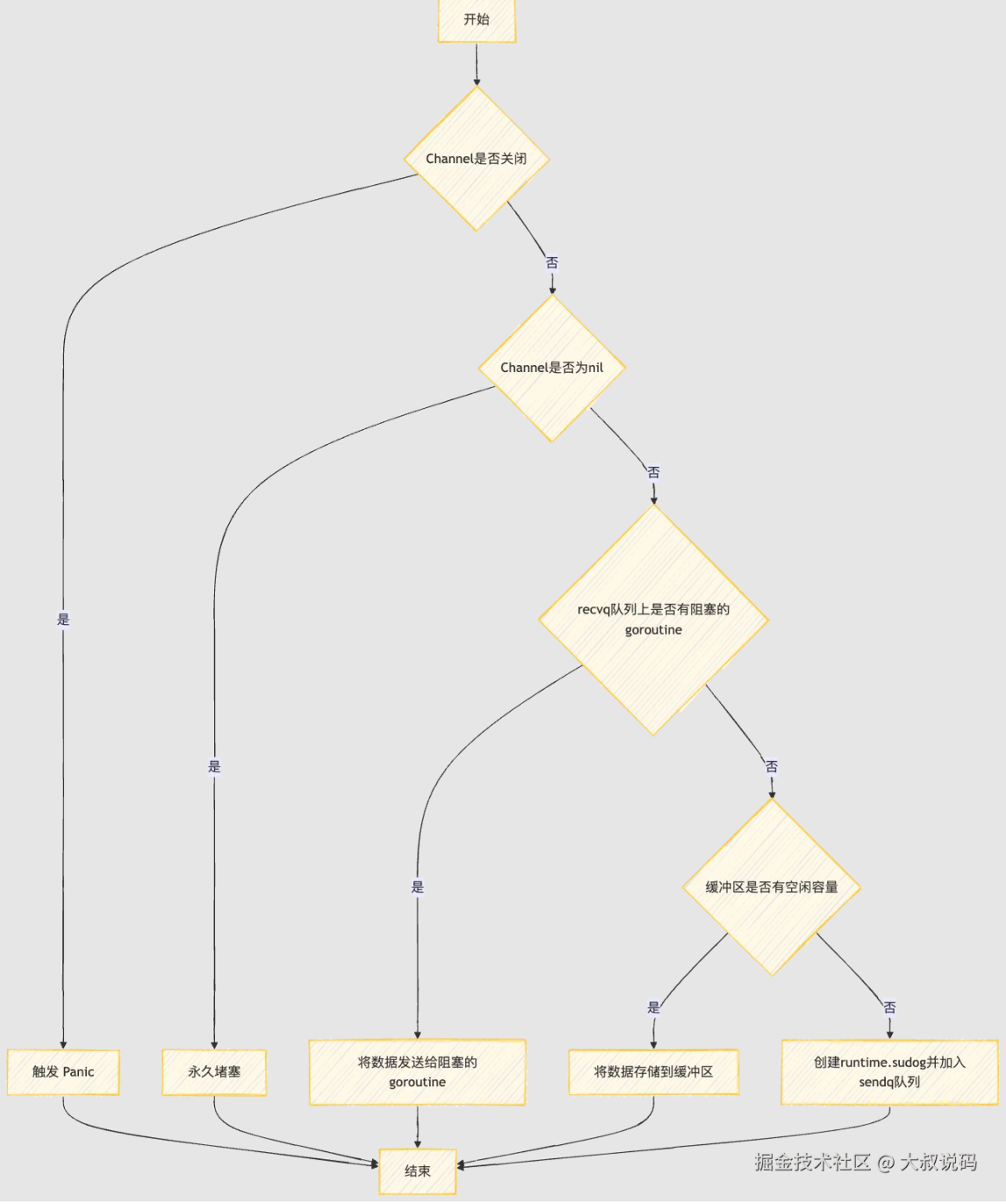
总结
下次面试如果再遇到类似 说说 Channel 的设计思想和底层原理 相关问题,简易的回答可以是这样:
- Channel 的发送和接收操作均遵循了先进先出的设计原则,即:先从 Channel 读取数据的 Goroutine 会先接收到数据,先向Channel发送数据的 Goroutine 会先得到发送数据的权利。
这得益于其底层的数据结构。Channel的底层数据结构包含了两个阻塞队列(双向链表实现),分别为发送阻塞队列sendq和接收阻塞队列recvq,遵循FIFO原则。 - 当写 goroutine 或读 goroutine被阻塞时,它们会被封装成runtime.sudog对象,加入到 sendq或recvq 队尾。
当阻塞的 goroutine 被唤醒时,会从 sendq或recvq队头取出阻塞的 goroutine进行执行。 - 另外,Channel 的底层数据结构中还包含了代表缓冲的循环数组buf,以及循环数组的索引sendx和recvx,通过这个两个索引来保证 Channel 读写的有序性。
向一个已经关闭的 Channel 读时,如果 Channel 缓冲区有数据,直接返回缓冲区recvx索引位置的数据;如果缓冲区没数据或者无缓冲区,直接返回该 Channel 类型的零值
向一个已经关闭的 Channel 写时,会抛出panic,除此之外,关闭已经关闭的 Channel和关闭一个 nil 的 Channel 都会panic。
向一个nil 的 Channel 发送或者读取数据会永久堵塞。
channel是线程安全的
Go channel 是线程安全的,原因在于 channel 内部实现了同步机制,它可以保证在多个 goroutine 之间的同步和互斥访问。
具体来说,Go channel 内部实现了两个重要的操作:发送和接收。当一个 goroutine 向一个 channel 发送数据时,如果 channel 已满,那么发送操作会被阻塞,直到 channel 中有足够的空间。同样地,当一个 goroutine 从一个 channel 接收数据时,如果 channel 已空,那么接收操作也会被阻塞,直到 channel 中有新的数据可供接收。
另一篇写的好的
在 Go 语言中,sync.Map 是一个并发安全的映射结构,专门用于在高并发场景下处理键值对数据。它的并发安全是通过内部实现机制来保证的,而不是依赖外部的锁机制(如 sync.Mutex 或 sync.RWMutex)来手动保护操作。
sync.Map 并发安全的实现原理
sync.Map 采用了一种更复杂的数据结构和操作策略来实现并发安全。它的核心设计可以分为以下几个方面:
- 读写分离机制
sync.Map 的内部结构是通过读写分离实现的,主要由两个部分组成:
只读部分(read map):用于存储稳定的数据。读取操作主要从这个只读部分进行,避免锁的使用。
脏数据部分(dirty map):当数据发生修改(写入、删除)时,会被移动到脏数据区域,写入的同时加锁来确保并发安全。
2. 快速读取路径
无锁读取:如果数据已经存在于 read map 中(即稳定的数据),读取操作不需要加锁,这使得 sync.Map 的读操作非常高效。
写时复制:当数据在 read map 中不存在时,可能存在于 dirty map 中。此时需要升级锁并从 dirty map 读取或写入数据。
3. 写入时的锁保护
当需要写入(Store 或 Delete)时,sync.Map 会在 dirty map 中进行操作。写操作会加锁,以确保并发写入时的安全性。
每次写入时,sync.Map 都会检查 read map 和 dirty map 之间的数据是否需要同步(比如数据量超过某个阈值时),并对脏数据部分进行清理和迁移。
4. 懒惰同步(Lazy Synchronization)
当读操作频繁时,sync.Map 会把部分脏数据逐步迁移到 read map,从而减少读操作对锁的依赖。这种延迟同步策略保证了读操作可以尽量避免锁竞争,从而提升读取性能。
- 原子操作
sync.Map 的部分操作(如 LoadOrStore、LoadAndDelete 等)采用了原子操作。它们的实现使用了底层的原子性检查和赋值操作,确保这些操作能够在并发环境中保持一致性。
关键操作说明
读操作 (Load):
首先从 read map 中读取,如果找到,直接返回。
如果在 read map 中没有找到,则会尝试从 dirty map 中读取,同时可能会触发一次锁定操作。
写操作 (Store):
写操作会锁定 sync.Map,以保证在并发环境下对 dirty map 的安全写入。
如果脏数据变多或写入频繁,可能会触发 read map 的同步,将一些脏数据迁移到 read map。
删除操作 (Delete):
删除操作也会加锁,并删除 dirty map 中的数据。
批量操作 (Range):
Range 操作遍历 sync.Map 中的所有数据,确保在遍历期间不会发生并发冲突。
defer
defer执行顺序 是个栈 后进先出
在Go语言的实现中,defer 语句的实现是通过栈(stack)来管理的。每个 defer 调用实际上是在当前的 goroutine 的栈上压入了一个结构体,这个结构体包含了被推迟执行的函数调用的信息。具体来说,每个 defer 记录通常包含以下几个部分:
函数指针:指向被推迟执行的函数的指针。
参数:被推迟函数的参数。
返回值地址:如果被推迟的函数有返回值,这里会存储返回值的地址,以便在函数执行完毕后将返回值赋值回这些地址。
延迟链指针:指向下一个 defer 记录的指针,形成一个链表。
我们看一下 defer 关键字在 Go 语言源代码中对应的数据结构:
type _defer struct {
siz int32 // 参数的长度,函数fn的参数长度
started bool // 该 defer 是否已经执行过
openDefer bool // 是否开发编码
sp uintptr // 函数栈指针寄存器,一般指向当前函数栈的栈顶
pc uintptr // 程序计数器,有时称为指令指针(IP),线程利用它来跟踪下一个要执行的指令。在大多数处理器中,PC 指向的是下一条指令,而不是当前指令
fn *funcval // 指向传入的函数地址和参数
_panic *_panic // 指向_panic链表
link *_defer // 指向_defer链表
...
}
可以看到,runtime._defer 结构体是延迟调用链表上的一个元素,所有的结构体都会通过 link 字段串联成链表。
那么这个链表是怎么构建的呢?实际上,只要获取到 新的runtime._defer 结构体,它都会被追加到所在 Goroutine _defer链表的最前面,即往 _defer链表的表头追加。
defer的更多坑看
大叔说码https://juejin.cn/post/6903808634430914568
互斥锁mutex
看另一篇博客,包括结构
sync包之 waitgroup
更多看 https://blog.csdn.net/liangguangchuan/article/details/134706688
https://www.jb51.net/article/260151.htm
//代码位于 GOROOT/src/sync/waitgroup.go L:23
type WaitGroup struct {
//防止WaitGroup被复制, 君子协议,编译可以通过,某些编辑器会报waring
//有兴趣可以看一下这里 https://github.com/golang/go/issues/8005#issuecomment-190753527
noCopy noCopy
// 高32位表示计数器,低32位表示等待的waiter数量。
// 低版本go的state字段类型是[3]uint32,需要进行位数对齐
state atomic.Uint64
// 信号量
sema uint32
}
其中 noCopy 是 golang 源码中检测禁止拷贝的技术。如果程序中有 WaitGroup 的赋值行为,使用 go vet 检查程序时,就会发现有报错。但需要注意的是,noCopy 不会影响程序正常的编译和运行。
noCopy详见另一篇专门的博客讲解
用于信号唤醒的 sema。这个 sema 可不是你随便能玩弄的玩意,它直接和操作系统底层调度相关联。
state1主要是存储着状态和信号量,状态维护了 2 个计数器,一个是请求计数器counter ,另外一个是等待计数器waiter(已调用 WaitGroup.Wait 的 goroutine 的个数)
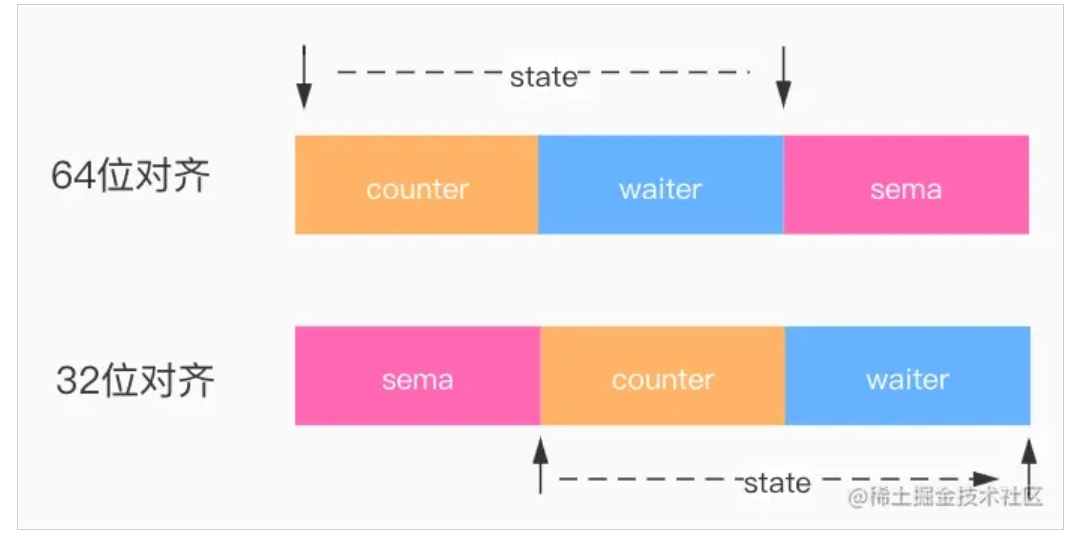
在WaitGroup里主要有3个方法:
-
WaitGroup.Add():可以添加或减少请求的goroutine数量,Add(n) 将会导致 counter += n
-
WaitGroup.Done():相当于Add(-1),Done() 将导致 counter -=1,请求计数器counter为0 时通过信号量调用runtime_Semrelease唤醒waiter线程
-
WaitGroup.Wait():会将 waiter++,同时通过信号量调用 runtime_Semacquire(semap)阻塞当前 goroutine
counter 代表目前尚未完成的个数。WaitGroup.Add(n) 将会导致 counter += n, 而 WaitGroup.Done() 将导致 counter–。
waiter 代表目前已调用 WaitGroup.Wait 的 goroutine 的个数。
sema 对应于 golang 中 runtime 内部的信号量的实现。WaitGroup 中会用到 sema 的两个相关函数,runtime_Semacquire 和 runtime_Semrelease。runtime_Semacquire 表示增加一个信号量,并挂起 当前 goroutine。runtime_Semrelease 表示减少一个信号量,并唤醒 sema 上其中一个正在等待的 goroutine。
WaitGroup 的整个调用过程可以简单地描述成下面这样:
当调用 WaitGroup.Add(n) 时,counter 将会自增: counter += n
当调用 WaitGroup.Wait() 时,会将 waiter++。同时调用 runtime_Semacquire(semap), 增加信号量,并挂起当前 goroutine。
当调用 WaitGroup.Done() 时,将会 counter–。如果自减后的 counter 等于 0,说明 WaitGroup 的等待过程已经结束,则需要调用 runtime_Semrelease 释放信号量,唤醒正在 WaitGroup.Wait 的 goroutine。
以上就是 WaitGroup 实现过程的简略版。但实际上,WaitGroup 在实现过程中对并发性能以及内存占用优化上,都有一些非常巧妙的设计点,我们接下来要着重讨论下。
更多看 https://www.cyhone.com/articles/golang-waitgroup/

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)