【深度学习基础】第四十一课:RNN应用之语言模型
例如我们需要构建一个语音识别系统。随机输入一段语音,这段语音听起来像是“The apple and pair salad.”或者是“The apple and pear salad.”,通过人为判断,很显然后者更符合逻辑。而对于一个语言模型来说,其可以算出每句话出现的可能性。一个好的语言模型计算出的第二句话出现的概率应该大于第一句话出现的概率。
【深度学习基础】系列博客为学习Coursera上吴恩达深度学习课程所做的课程笔记。
1.什么是语言模型
例如我们需要构建一个语音识别系统。随机输入一段语音,这段语音听起来像是“The apple and pair salad.”或者是“The apple and pear salad.”,通过人为判断,很显然后者更符合逻辑。而对于一个语言模型来说,其可以算出每句话出现的可能性。一个好的语言模型计算出的第二句话出现的概率应该大于第一句话出现的概率。
2.如何使用RNN构建语言模型
首先需要一个训练集,即一个很大的语料库(corpus)。假设训练集中有这么一句话:“Cats average 15 hours of sleep a day.”,我们可以像【深度学习基础】第三十九课:序列模型一文中介绍的那样,将句子中的每个单词转换成one-hot编码。此外,可以使用一个额外的标记<EOS>(End Of Sentence)表示句子的结尾(在本例中,我们忽略了标点符号):
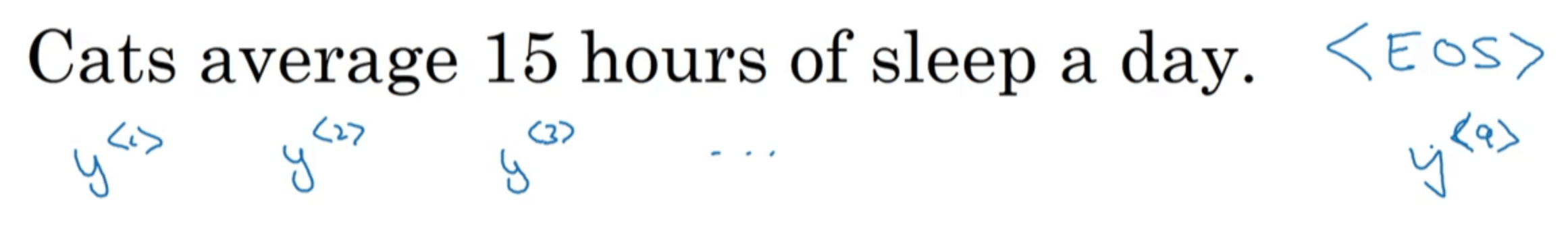
接下来就可以构建RNN模型了:
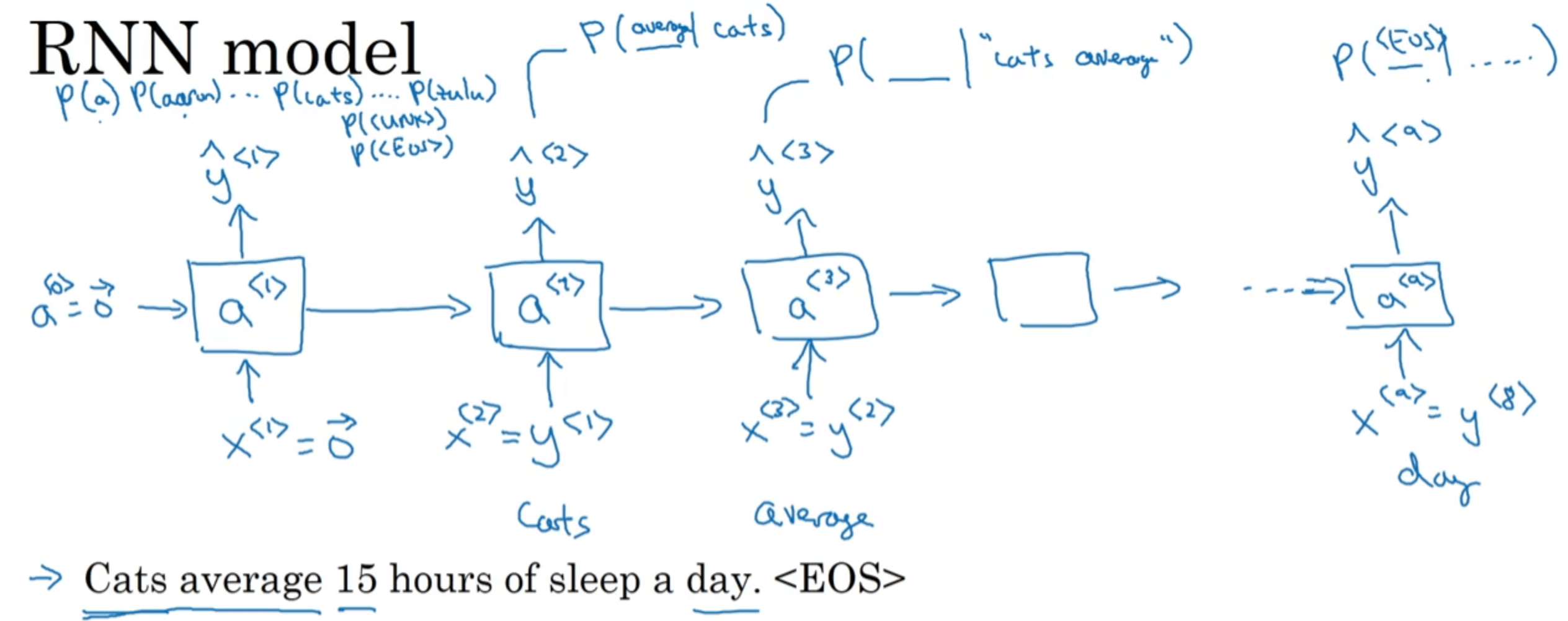
x < 1 > x^{<1>} x<1>和 a < 0 > a^{<0>} a<0>均初始化为零向量。然后通过softmax函数预测出第一个单词最可能是哪个,在本例中为单词“Cats”。并且将 y ^ < 1 > \hat{y} ^{<1>} y^<1>(也就是 x < 2 > x^{<2>} x<2>)作为输入传给下一步。然后同样通过softmax函数预测出第二个单词最可能是哪个。也就是说在预测第二个单词时,会利用第一个单词为“Cats”这一信息,类似于条件概率 P ( 第二个单词| " C a t s " ) P(第二个单词|"Cats") P(第二个单词|"Cats")。剩余的以此类推。
cost function可定义如下:
L < t > ( y ^ < t > , y < t > ) = − ∑ i y i < t > log y ^ i < t > L^{<t>}(\hat{y}^{<t>},y^{<t>})=-\sum_i y_i^{<t>} \log \hat{y}_i ^{<t>} L<t>(y^<t>,y<t>)=−i∑yi<t>logy^i<t>
L = ∑ t L < t > ( y ^ < t > , y < t > ) L=\sum_t L^{<t>}(\hat{y}^{<t>},y^{<t>}) L=t∑L<t>(y^<t>,y<t>)
i i i为所用字典中的第 i i i个单词。
我们之前用的字典都是基于单词的,其实字典也可以是基于字符的:

使用基于字符的字典既有优点也有缺点:
- 优点:
- 不会出现
UNK。
- 不会出现
- 缺点:
- 序列会很长。
- 不善于捕捉句子中单词之间的依赖关系。
- 计算成本较高。
因此,绝大多数的NLP都用的是基于单词的字典。但当有较多的未知词汇时,则可以考虑使用基于字符的字典。
想要获取最新文章推送或者私聊谈人生,请关注我的个人微信公众号:⬇️x-jeff的AI工坊⬇️
个人博客网站:https://shichaoxin.com
GitHub:https://github.com/x-jeff

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 32
32 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)