【创新实训】关于大模型微调&RAG的一些笔记
通过提供,进一步训练,让模型能够更加精准地处理。
·
有监督微调(SFT)
通过提供人工标注的数据,进一步训练预训练模型,让模型能够更加精准地处理特定领域的任务。
预训练模型
- 指已经在大量数据上训练过的模型,也就是我们微调前需要预先下载的开源模型。
- 具备通用的知识和能力
微调算法
- 全参数微调:Full Fine-Tuning
- 对整个预训练模型进行微调,会更新所有参数
- 优点:通常能得到最佳的性能,能够适应不同任务和场景
- 缺点:需要大量计算资源,容易出现过拟合
- 部分参数微调(Partical Fine-Tuning)
- 只更新模型的部分参数
- 优点:减少了计算成本,减少了过拟合风险,能够以较小代价获得较好的结果
- 缺点:可能无法达到最佳性能
- LoRA
LoRA 微调算法
Low-Rank Adaption:通过低秩矩阵分解的方式进行部分参数微调。
算法
h=W0x+ΔW0x=W0x+BAx h = W_0x + \Delta W_0x = W_0x + BAx h=W0x+ΔW0x=W0x+BAx
- 模型的输出:h h h
- 预训练模型的原始权重,是一个满秩矩阵:W0 W_0 W0
- 模型输入:x x x
- 微调后原始权重的变化量: ΔW0 \Delta W_0 ΔW0 也是一个满秩矩阵,规模与W0 W_0 W0相同
- 两个低秩矩阵 B 和 A ,乘积 BA 表示对原始权重的微调变化量: ΔW0=BA \Delta W_0 = BA ΔW0=BA
- 全参数微调的输出:W0x+ΔW0x W_0x + \Delta W_0x W0x+ΔW0x
- LoRA算法下部分参数微调的输出:W0x+BAx W_0x + BAx W0x+BAx
- 核心思想:使得 BA BA BA 的存储数据量远小于 ΔW0 \Delta W_0 ΔW0
常见微调框架
- Llama-Factory:开源的低代码大模型训练框架,可实现零代码微调
- transformers.Trainer:适用于NLP任务的微调,提供标准化的训练流程和多种监控工具
- DeepSpeed:开源深度学习优化库,适合大规模模型训练和分布式训练,,多用于大模型预训练和资源密集型训练
强化学习(RLHF)
- DPO:Direct Preference Optimization
- 通过人类的对比选择直接优化生成模型,使其产生符合用户需求的结果,调整幅度大
- PPO:Proximal Policy Optimization
- 通过奖励信号来渐进式调整模型的行为策略,调整幅度小
anythingLLM的使用
- 由于无法进行微调,只能使用RAG方式,所以使用anythingLLM搭建知识库的方式,来增强大模型的专业性。
- anythingLLM 可以将任何文档、资源或内容片段转化为大语言模型(LLM)在聊天中可以利用的相关上下文。
模型和数据集选择
- DeepSeek-R1:70B
- 使用hugging face上开源的数据集,将数据集直接“投喂”到anythingLLM中形成知识库
RAG(检索增强生成)
- 用于降低大模型出现幻觉的概率,提高大语言模型回答专业问题时的准确性和可靠性。
- 两个阶段:
- 检索:将用户的问题转化为向量,从向量数据库中快速检索相关片段
- 生成:将检索到的信息输入给大模型,结合上下文,生成具体的回答
- 向量数据库:
- 通过存储文本的向量化表示,支持基于语义相似度的快速检索
- 解决了传统关键词匹配无法捕捉上下文关联的问题
- 存储向量,一串浮点型数据,通过计算向量的“距离”等方式,量化语义相似性
- 实现过程:
- 将文章进行分片,得到多个chunk
- 对每个chunk进行向量化,并存储到向量数据库中
- 实现过程
- 将用户提问的文本,通过embeding模型转化成向量
- 在向量数据库中搜索语义相似的内容,向量数据库中给出Top k
- 通过重排序模型,在上述Top k中筛选出Top N
- 将搜索到的内容和用户提问的文本组成一个完整的prompt,传给大语言模型
- 大语言模型基于prompt和自身的内容进行输出
构建知识库的过程
- 选择要上传的数据集:
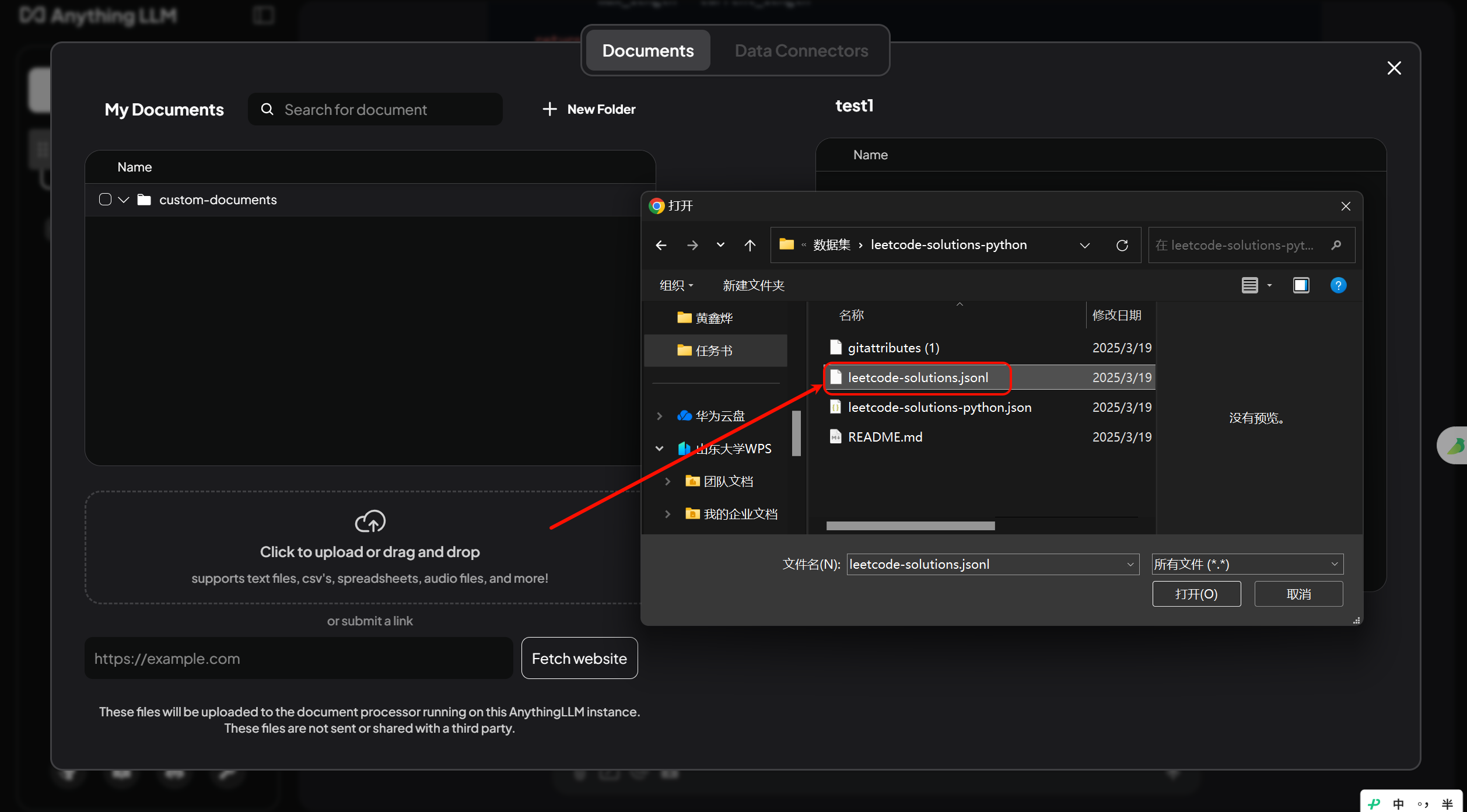
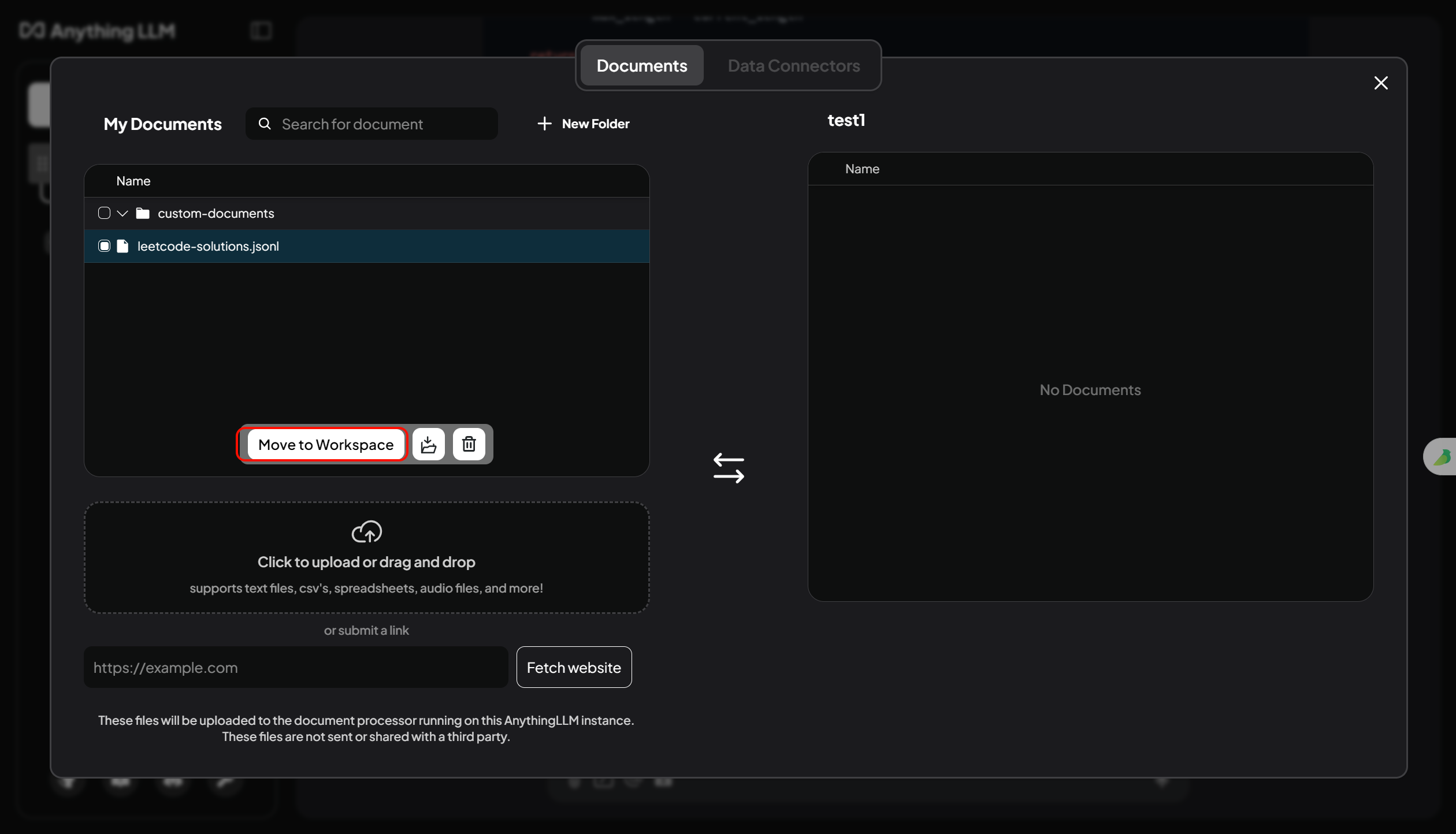
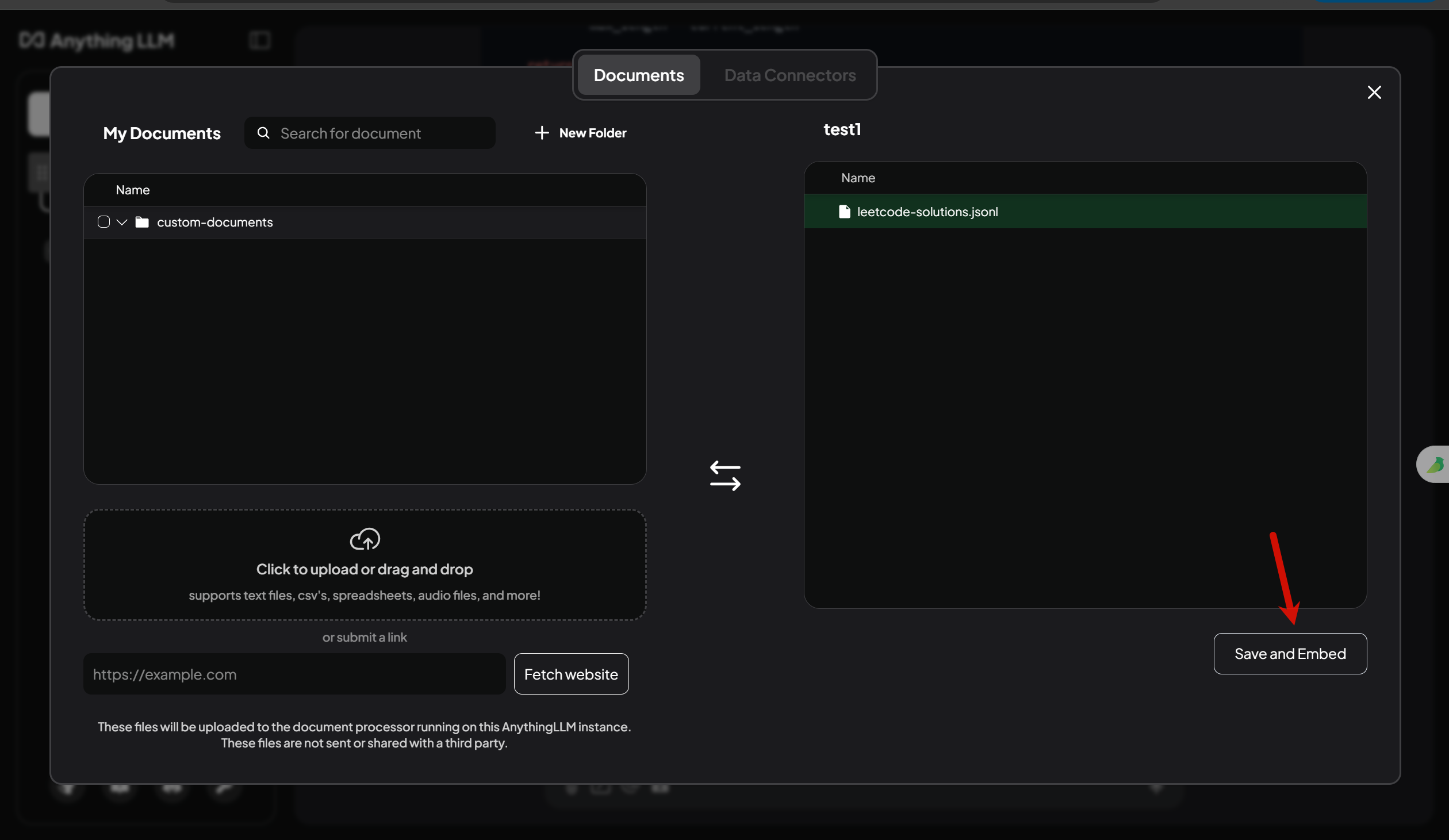
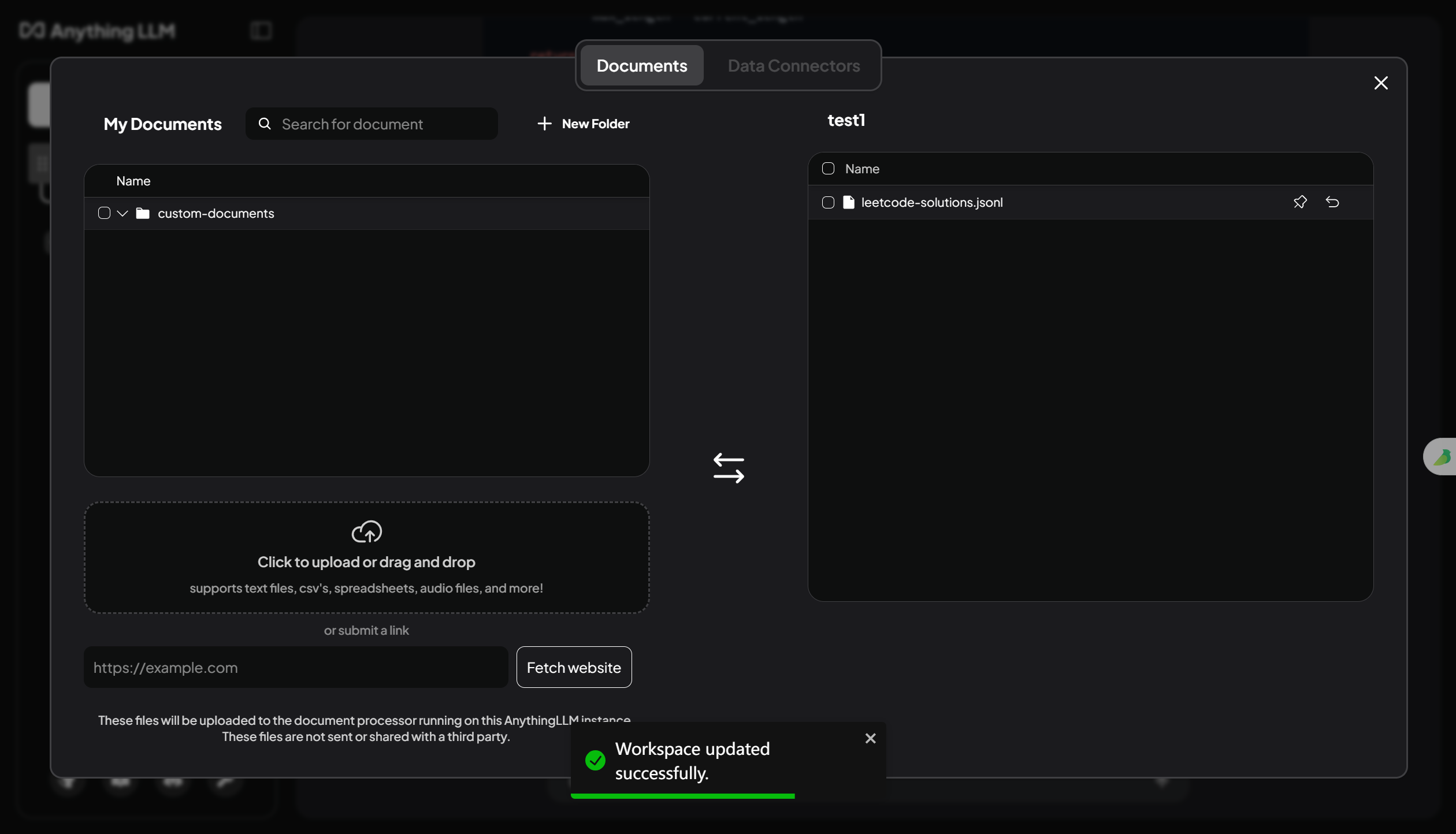
- 将文件传给嵌入模型,并应用到当前工作区:
尝试询问知识库中的问题
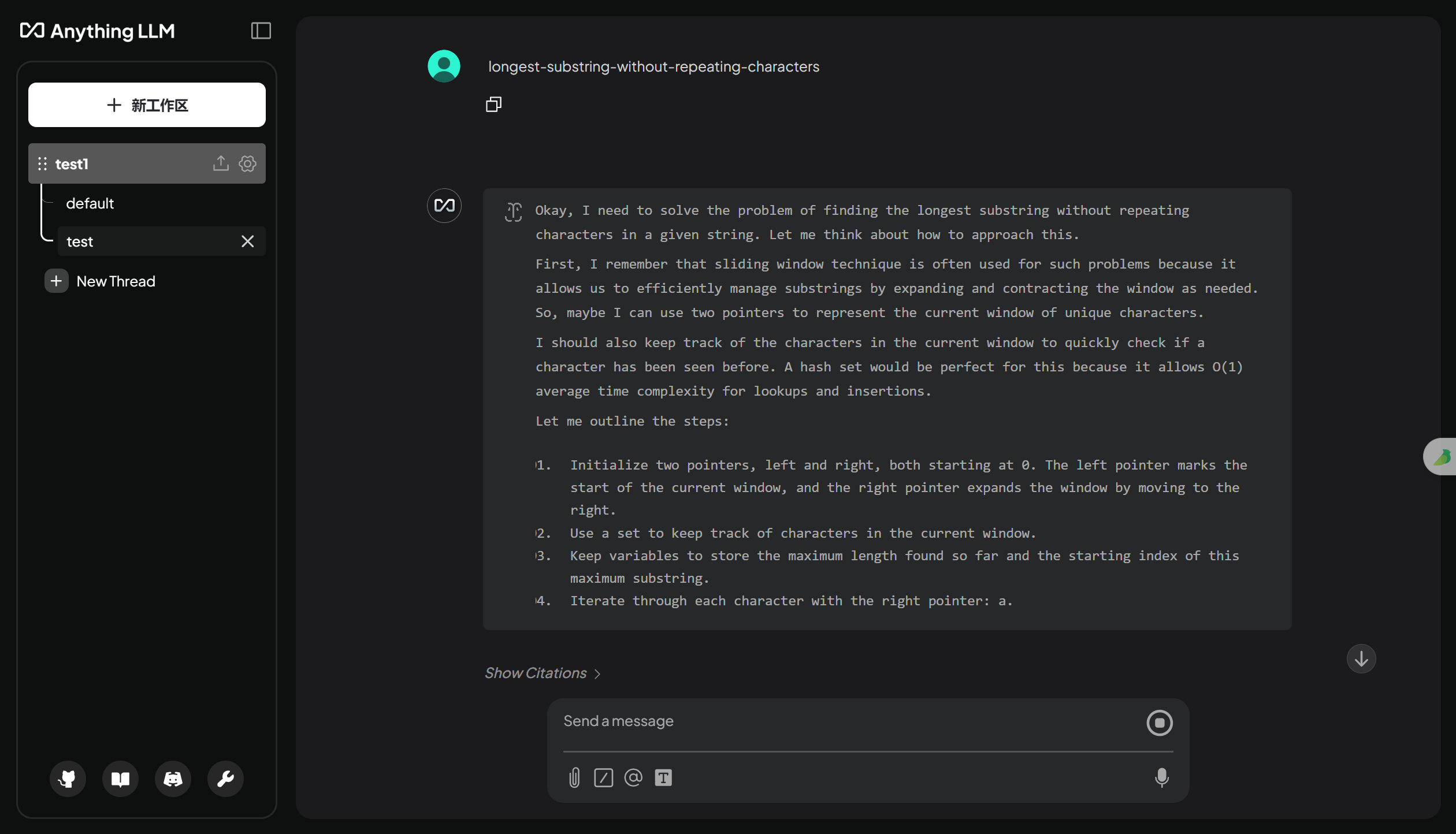
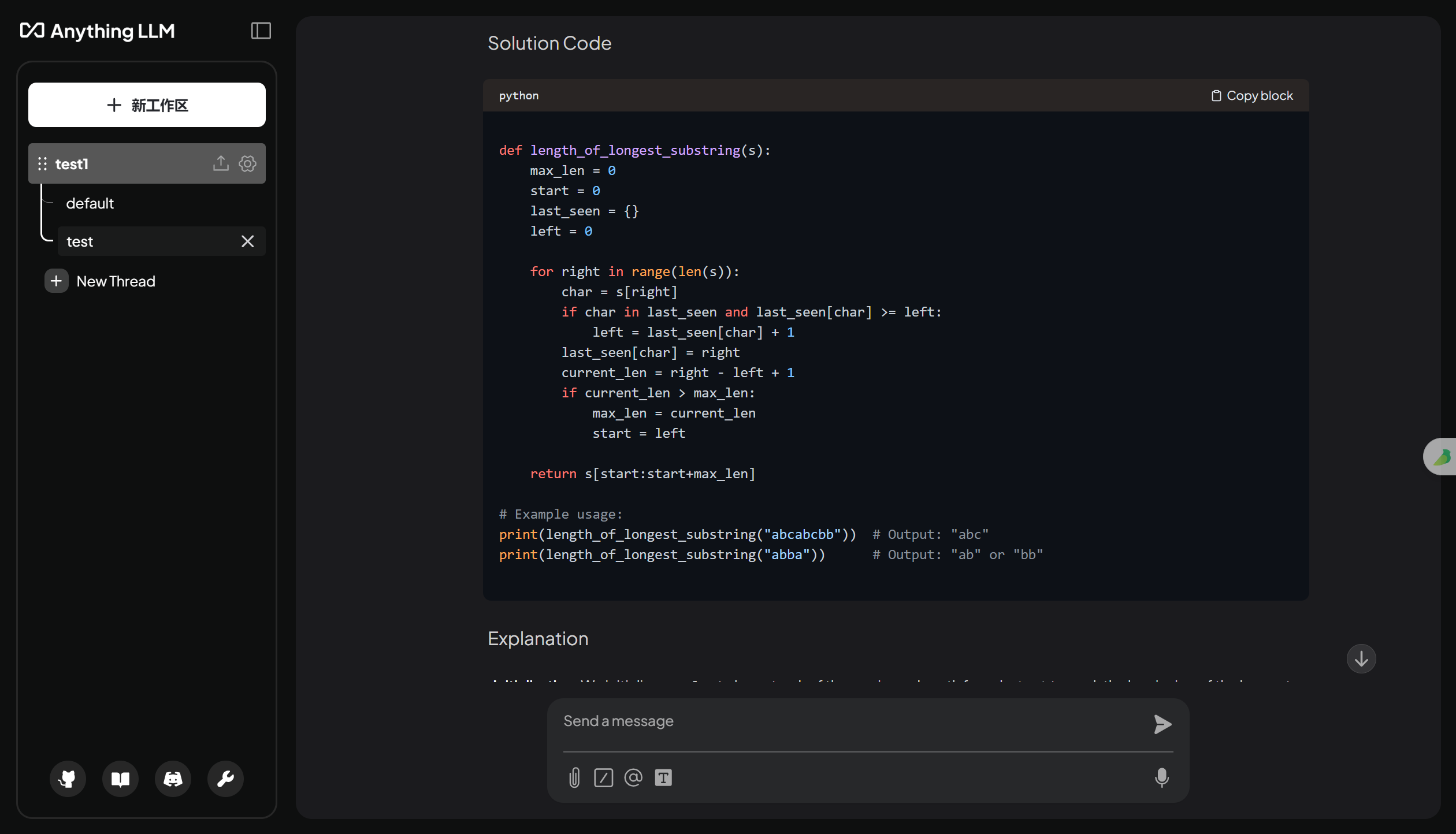
上面上传的数据集,是力扣的题目和对应题解。所以输入某个算法题的题目,尝试获得问题的解题思路和代码实现。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)