01大模型学习——词向量
词向量(词嵌入)是一种将词汇表中的词或短语,映射为固定长度向量的技术。将高维且稀疏的单词索引,转为低维且连续的向量。转换后的连续向量,可以表示出单词与单词之间的语义关系。词向量(Embeddings)将非结构化数据(单词、句子、整个文档)转化为实数向量。
一、词向量&词汇表
1、词向量/词嵌入
词向量是一种将单词表示为实数向量的方式。每个单词通过一个高维向量来表示,向量的每一维都是一个实数,这些向量通常位于一个高维空间。词向量的目标是将语义相似的单词映射到相邻的向量空间中,即距离越近的向量表示的单词之间的语义相似度越高。
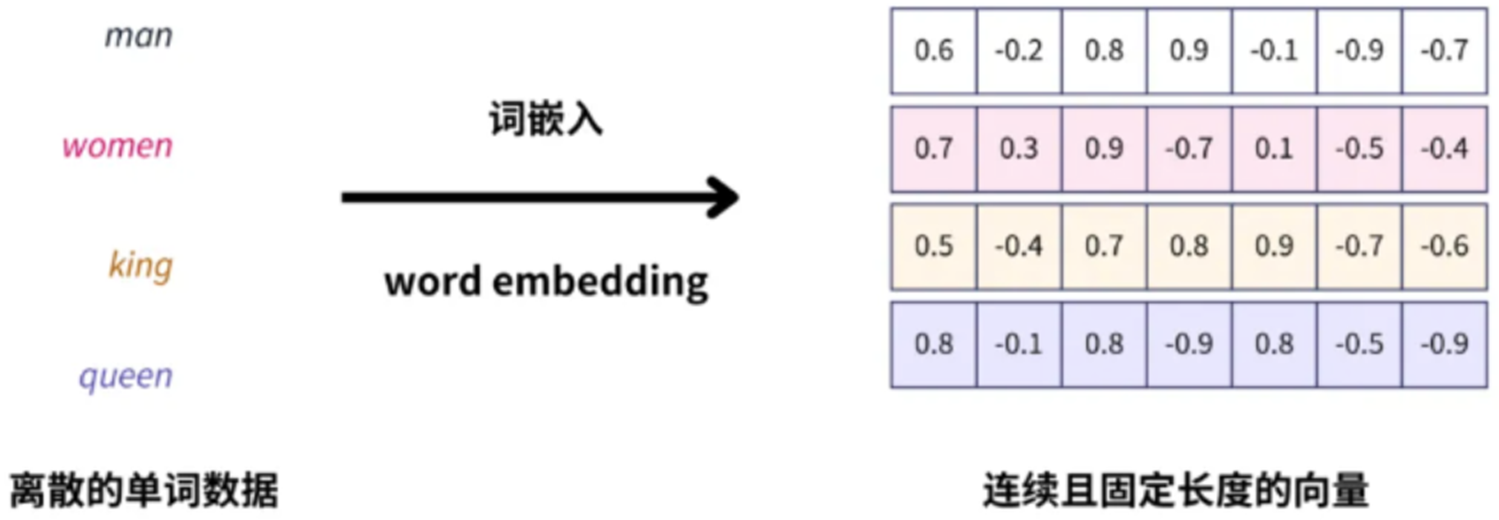
高维稀疏→低维稠密
词向量(词嵌入)是一种将词汇表中的词或短语,映射为固定长度向量的技术。通过词嵌入,我们可以将高维且稀疏的单词索引,转为低维且连续的向量。将非结构化数据,如单词、句子或者整个文档,转化为实数向量。
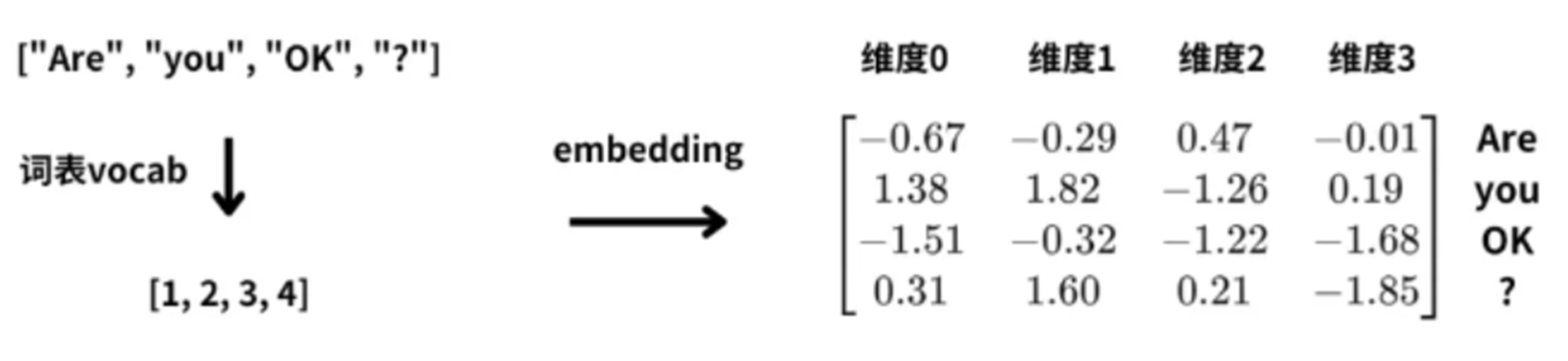
2、词汇表vocab
词汇表是一个包含模型在处理文本数据时遇到的所有唯一词汇的集合,每个词汇在词汇表中都有一个唯一的索引,将文本数据转换为模型可以理解的数字格式。将单词映射到索引,减少模型需要处理的数据量。形成文本编解码的效果。

可以取最低词频为1或者2做成词汇表,一般词频选择2(即最少出现2次的词才会纳入词汇表)
3、词汇表到词向量
一个句子,通过词汇表进行分词,并获取到token(词元对应索引),对索引进行embedding则得到词向量,得到的每个token的向量最终是在dim=0维度上求和,再输入模型(模型输入为句子)。

这里每个单词用4维向量表示,那么四个词的句子“Are you OK ?”,就会被转换为4 * 4的词向量矩阵;
每行对应一个单词,得到输入文本的词向量矩阵后,才可以继续使用神经网络对文本进行特征提取和处理。
4、总结(词向量/词嵌入)
(1)词向量总结
词向量(词嵌入)是一种将词汇表中的词或短语,映射为固定长度向量的技术。
- 将高维且稀疏的单词索引,转为低维且连续的向量。
- 转换后的连续向量,可以表示出单词与单词之间的语义关系。
- 词向量(Embeddings)将非结构化数据(单词、句子、整个文档)转化为实数向量。
(2)one-hot与词向量(词嵌入)
词汇表中有10000个单词,表示man、woman、king、queen四个词语,这四个词语的索引是1~10000中的4个整数。如果用one-hot向量表示这4个词;那么就需要4个10000维度的one-hot向量。不仅维度高,而且稀疏。在向量中,只有1个维度是1,其他维度都是0。单词向量和单词向量之间,都是正交的(正交:两个向量的点积(内积)为零;几何学中,如果两条线或两个平面相交且形成的角是直角),没有任何语义关系。
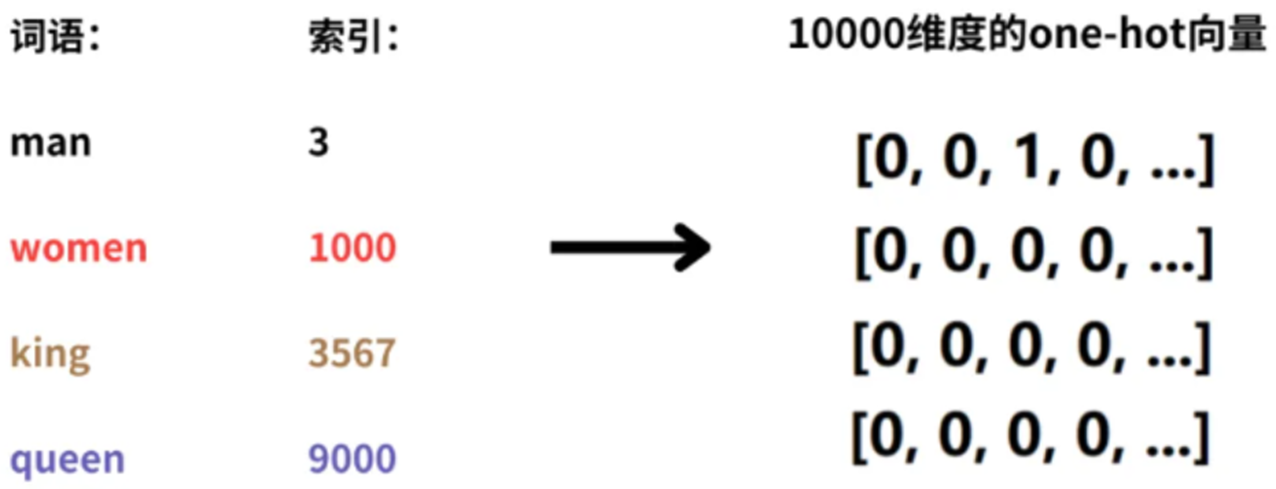
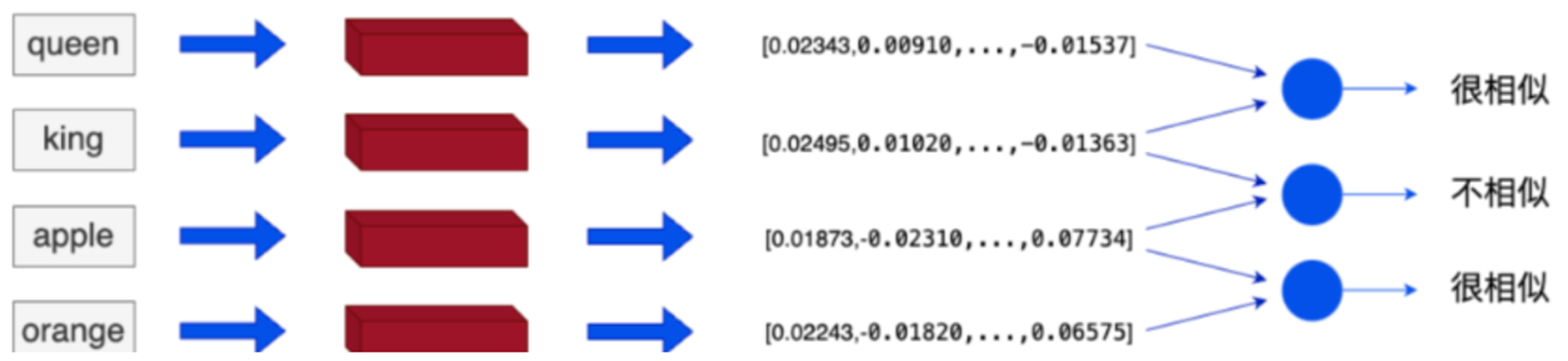
(3)词与词之间的关系
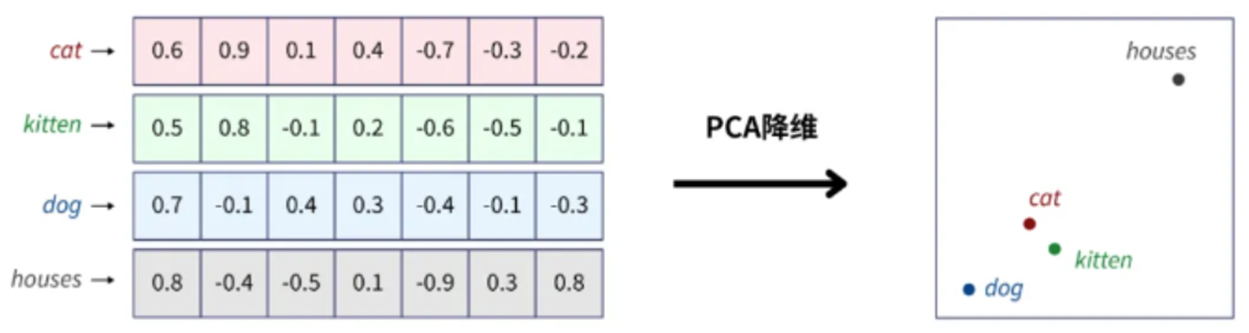
词嵌入之后,相似或相关的对象在嵌入空间中的距离很近。
king和queen在嵌入空间中的位置将会非常近,因为它们的含义相似。而 apple和 orange也会很接近,因为它们都是水果。而king和apple这两个单词在嵌入空间中的距离就会比较远,因为它们的含义不同。
5、PCA降维(特征可视化)
PCA:主成分分析,是一种常用的降维方法,它通过线性变换将数据投影到较低维度的空间上,同时尽可能保留原始数据的方差信息。
- 标准化数据(Z-score标准化)。
- 计算协方差矩阵。
- 计算协方差矩阵的特征值和特征向量。
- 选择最大的几个特征值对应的特征向量。
- 使用这些特征向量将数据投影到新的子空间。
import torch
import torch.nn as nn
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# PCA降维
l1 = {"king": 10000, "queen": 20000, "apple": 30000, "orange": 40000}
# 词向量
"""
num_embeddings: int -- 词汇表数量,一般是词汇表长度+1
embedding_dim: int -- 要转换词向量的维度
"""
embed = nn.Embedding(num_embeddings=150000, embedding_dim=256)
embed_data = embed(torch.tensor(list(l1.values())))
# print(embed_data.shape) # torch.Size([4, 256])
embed_data = embed_data.detach().numpy()
pca = PCA(n_components=2)
embed_data = pca.fit_transform(embed_data)
# print(embed_data.shape) # (4, 2)
plt.figure(figsize=(10, 10))
for i, data in enumerate(embed_data[:2]):
plt.scatter(data[0], data[1], color="red")
for i, data in enumerate(embed_data[2:]):
plt.scatter(data[0], data[1], color="blue")
plt.show()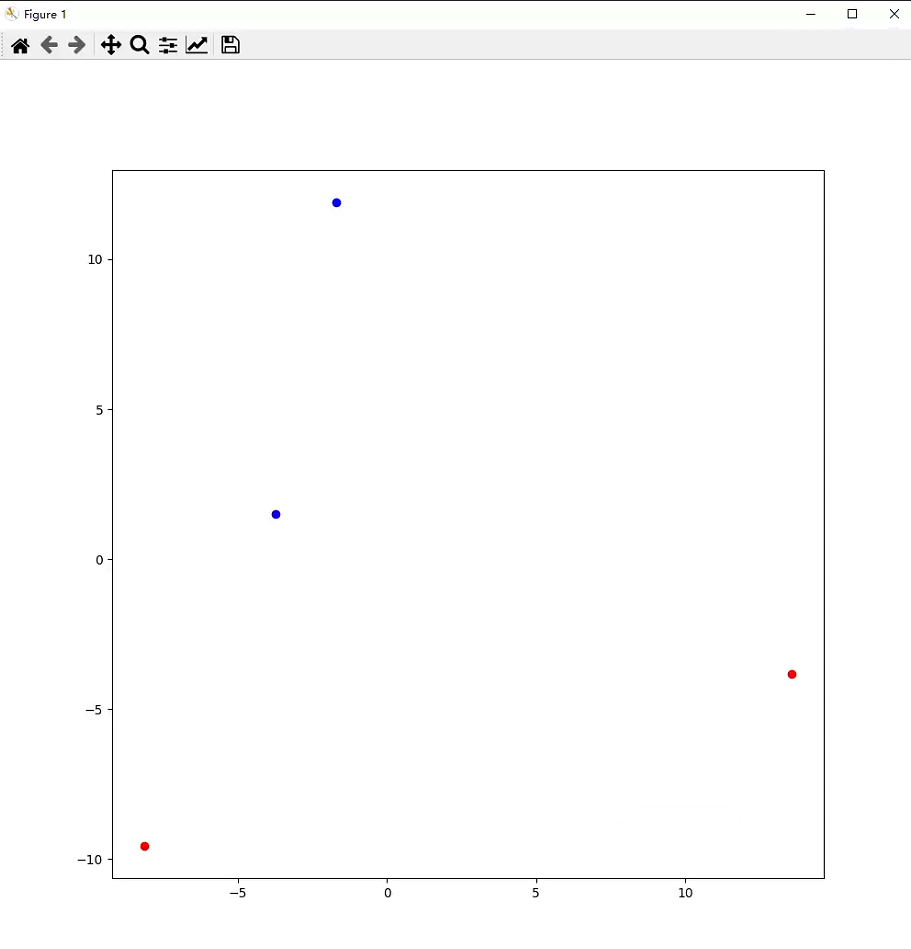
二、分词
1、分词-Tokenization
分词:将句子、段落、文章(非结构化数据),分解为以字词为单位的数据结构。
2、jieba分词器
安装:pip install jieba -i ...
import jieba
s = "成都是天府之国"
# 全模式
seg_list = jieba.cut(s, cut_all=True)
print("全模式: " + "/".join(seg_list)) # 全模式: 成都/是/天府/天府之国/之国
# 精确模式
seg_list = jieba.cut(s, cut_all=False)
print("精确模式: " + "/".join(seg_list)) # 精确模式: 成都/是/天府之国
# 搜索引擎模式
seg_list = jieba.cut_for_search(s)
print("搜索引擎模式: " + "/".join(seg_list)) # 搜索引擎模式: 成都/是/天府/之国/天府之国
# 默认是精确模式
seg_list = jieba.cut(s)
print("默认: " + "/".join(seg_list)) # 默认: 成都/是/天府之国3、Word2Vec
Google在2013年推出的一个NLP工具,将所有的词向量化,这样词与词之间就可以定量的去度量和挖掘他们之间的关系和联系。
训练一个浅层的神经网络模型来学习如何将每个词转换为一个固定长度的向量,这些向量能够表示单词之间的相似性和关联性,这种转换使得原本抽象的词汇变得可以在数学上计算它们之间的相似度,进而挖掘出词汇之间的内在联系。
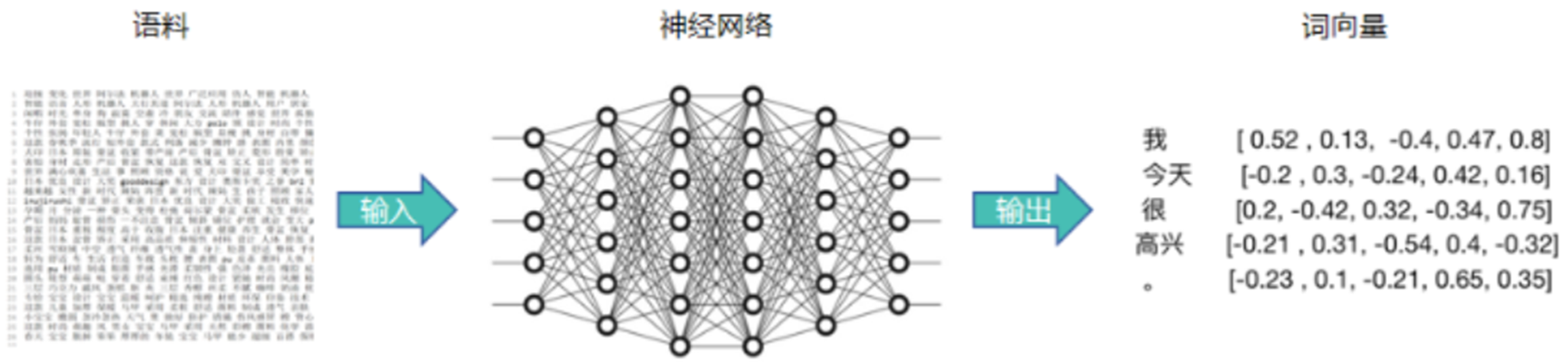
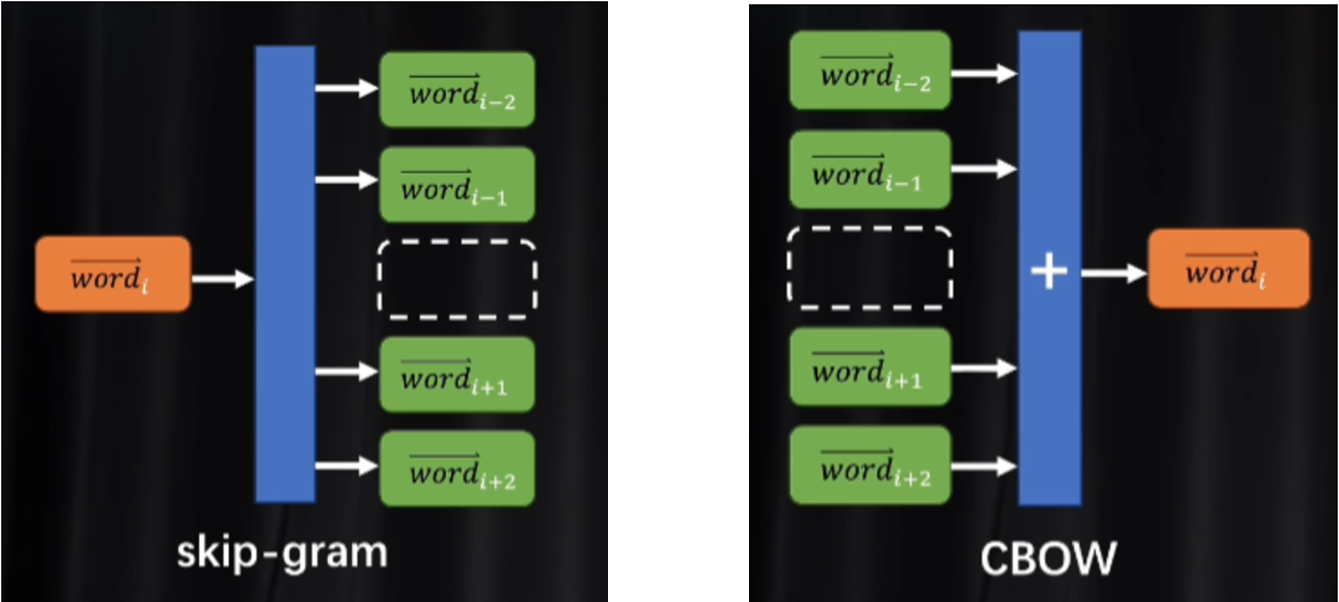
中心词与上下文词
sg=1:中心词预测上下文
sg=0:完形填空
跳字模型Skip-Gram 输入中心词预测上下文词
连续词袋模型CBOW 模型则是由上下文词预测中心词。
安装:pip install gensim -i ...
导入:from gensim.models import Word2Vec
from gensim.models import Word2Vec
contents = [
"SunWukong, the Monkey King, is a mischievous and cunning character with incredible strength and magical powers, who wields a magical staff and leads the journey to the West.",
"TangSanzang, a pious and kind-hearted monk, embarks on a perilous quest to retrieve sacred scriptures, relying on his wisdom and the protection of his disciples.",
"ZhuBajie, a comical and gluttonous pig demon, possesses great strength and a fierce appearance, yet he is loyal and brave, always ready to fight alongside his master.",
"ShaWujing, a reliable and steadfast sand demon, uses his magical powers to control the elements, providing valuable support to his companions on their journey.",
"WhiteBoneDemon, a malevolent and cunning spirit, constantly transforms to deceive and capture Tang Sanzang, posing a significant threat to the journey’s success."
]
contents = [[word.lower().strip(",.") for word in content.split()] for content in contents]
"""
sentences: 训练的文本数据
vector_size: 每个词向量的维度
window: 在训练过程中考虑的上下文单词的数量
min_count: 忽略频率低于该值的单词
sg: 模型的类型。sg=0 表示使用 CBOW 模型,sg=1 表示使用 Skip-Gram 模型。CBOW 模型通过上下文预测目标单词,而 Skip-Gram 模型通过目标单词预测上下文。
epochs: 训练轮次
"""
model = Word2Vec(sentences=contents, vector_size=30, window=5, min_count=1, sg=0, epochs=1000)
similarity = model.wv.similarity("sunwukong", "tangsanzang")
print(f"{similarity: .4f}")
similarity = model.wv.most_similar("sunwukong", topn=3)
for word,score in similarity:
print(f"{word}: {score:.4f}")三、基于词向量和神经网络训练文本分类模型
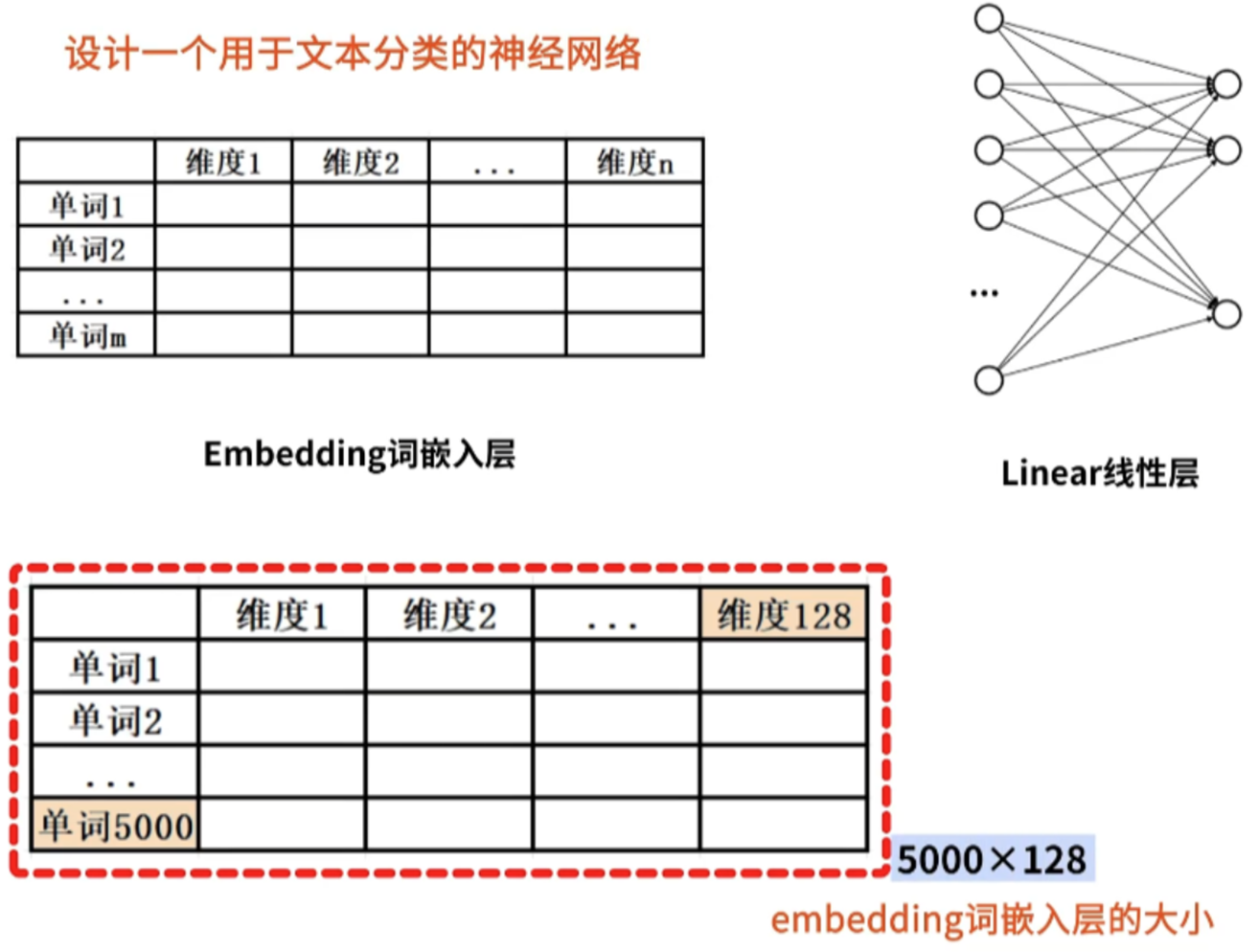
1、nn.Embedding层
nn.Embedding层是一种将离散型数据(如单词、字符等)转换为连续型向量表示的技术,能够捕获数据之间的语义和语法关系。
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None)
- num_embeddings (int): 词汇表的大小;
- embedding_dim (int): 嵌入向量的维度;
- padding_idx (int): 填充符号<pad>的索引
2、基于词向量和神经网络训练文本分类模型
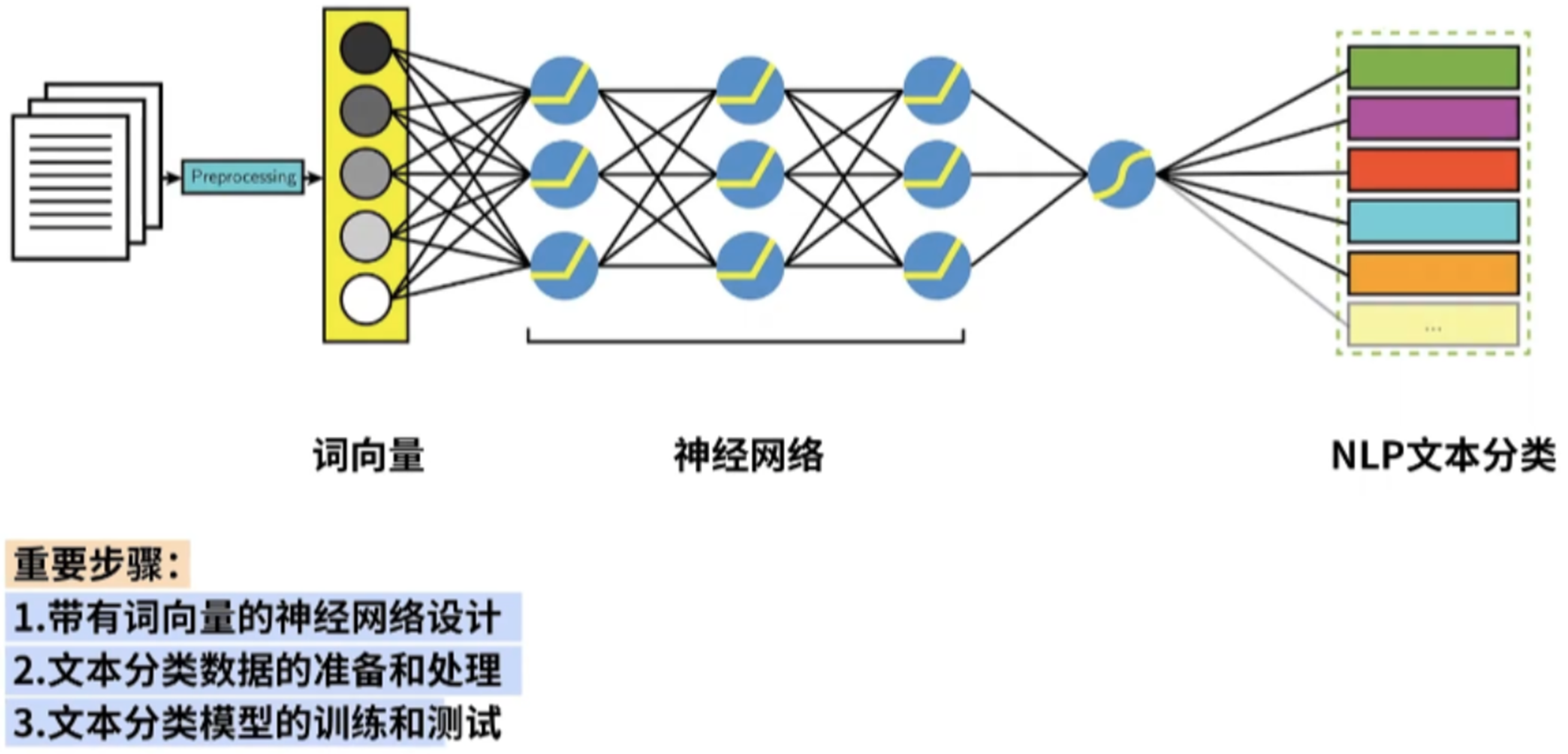
(1)带有词向量的神经网络设计
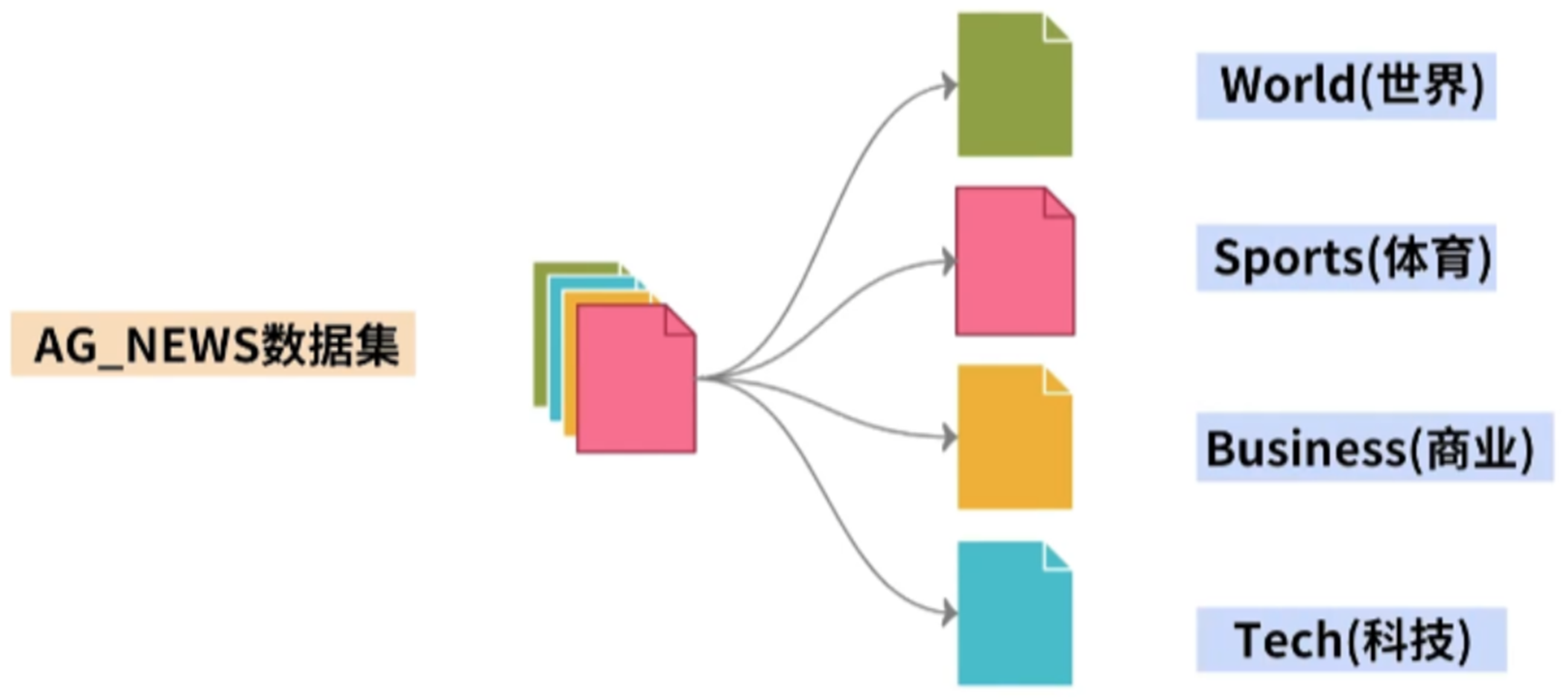
(2)文本分类数据ag_news
3、文本分类模型-代码实现
- 自定义数据集dataset
- 构建词汇表vocabulary
- 形状补全<pad>
- 模型网络设计
- 训练&测试
import torch
import torch.nn as nn
from torchtext.data.utils import get_tokenizer # 分词器
import pandas as pd
from torch.utils.data import Dataset
from torchtext.vocab import build_vocab_from_iterator # 创建词汇表
from torch.nn.utils.rnn import pad_sequence # 填充
from torch.utils.data import DataLoader
import os
# 数据集
class NewsDataset(Dataset):
def __init__(self, is_train=True):
super().__init__()
if is_train:
data = pd.read_csv("train.csv")
else:
data = pd.read_csv("test.csv")
self.news = list()
# 分词器
tokenizer = get_tokenizer("basic_english")
for index, row in data.iterrows():
label = row[0]
text = row[2]
tokenized_text = [token.lower() for token in tokenizer(text)]
# [reuters - short-sellers, wall street's dwindling\band of ultra-cynics, are seeing green again] 3
self.news.append((tokenized_text, label))
def __len__(self):
return len(self.news)
def __getitem__(self, index):
return self.news[index]
# 构建词汇表 vocab
def build_vocab(dataset):
special = ["<unk>", "<pad>"] # 词汇表的特殊字符
text_iter = map(lambda x: x[0], dataset) # 读取数据集中的全部token
# 构建词汇表:定义词频,加入特殊字符
text_vocab = build_vocab_from_iterator(text_iter, min_freq=2, specials=special)
text_vocab.set_default_index(text_vocab["<unk>"])
return text_vocab
# 形状补全,<pad>
def collate_batch(batch, text_vocab):
# 填充数据,需要批次数据,词汇表
labels = list()
text_list = list()
for text, label in batch:
# "Reuters" --> index : 100
text_tokens = [text_vocab[token] for token in text] # 词汇表索引,整形
text_tensor = torch.tensor(text_tokens, dtype=torch.long) # 转tensor
text_list.append(text_tensor) # tensor索引
labels.append(torch.tensor(label - 1, dtype=torch.long)) # label转索引
padding_idx = text_vocab["<pad>"] # 获取填充索引
# 填充合并
text_padded = pad_sequence(text_list, batch_first=True, padding_value=padding_idx)
# text:[[a, b, c],[d, e, f]]
# label:1, 2, 3 , 4 --> [1234]
labels_tensor = torch.stack(labels) # 升维
return text_padded, labels_tensor
class TextClassifier(nn.Module):
def __init__(self, vocab_size, embed_dim, padding_idx, num_class):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim, padding_idx=padding_idx)
self.fc = nn.Sequential(
# embed_dim:是一句话的embed_dim(token 一句话)
nn.Linear(embed_dim, 256), nn.ReLU(),
nn.Linear(256, 256), nn.ReLU(),
nn.Linear(256, 128), nn.ReLU(),
nn.Linear(128, 128), nn.ReLU(),
nn.Linear(128, 64), nn.ReLU(),
nn.Linear(64, 32), nn.ReLU(),
nn.Linear(32, num_class)
)
def forward(self, x):
# x.shape == 100, 120(N,语料token数)
# token --> 高维
x = self.embedding(x)
# x.shape == 100, 120, 256
x = torch.sum(x, dim=1) # 加和
# x.shape == 100, 256
x = self.fc(x)
return x
# 训练&测试
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_dataset = NewsDataset(True)
test_dataset = NewsDataset(False)
text_vocab = build_vocab(train_dataset)
print(f"词汇表的长度:{len(text_vocab)}")
# 数据的长度不一致,填充
# 回调
collate = lambda batch: collate_batch(batch, text_vocab) # 回调函数声明
train_dataloader = DataLoader(train_dataset, batch_size=100, shuffle=True, collate_fn=collate)
test_dataloader = DataLoader(test_dataset, batch_size=100, shuffle=True, collate_fn=collate)
# 全局参数
embed_dim = 256
num_class = 4
padding_idx = text_vocab["<pad>"]
vocab_size = len(text_vocab)
# 模型申明 vocab_size, embed_dim, padding_idx, num_class
model = TextClassifier(vocab_size, embed_dim, padding_idx, num_class).to(DEVICE)
opt = torch.optim.Adam(model.parameters())
loss_fn = nn.CrossEntropyLoss()
# 训练
if os.path.exists(r"model.pt"):
model.load_state_dict(torch.load(r"model.pt"))
print("开始训练")
for epoch in range(100):
# 训练
train_sum_loss = 0
model.train()
for i, (text, label) in enumerate(train_dataloader):
text, label = text.to(DEVICE), label.to(DEVICE)
out = model(text)
loss = loss_fn(out, label)
opt.zero_grad()
loss.backward()
opt.step()
train_sum_loss += loss.item()
train_avg_loss = train_sum_loss / len(train_dataloader)
print(f"第{epoch+1}轮的损失:{train_avg_loss}")
# 测试
test_sum_score = 0
model.eval()
with torch.no_grad():
for i, (text, label) in enumerate(test_dataloader):
text, label = text.to(DEVICE), label.to(DEVICE)
out = model(text)
pre = torch.argmax(out, dim=1)
score = torch.mean(torch.eq(pre, label).to(torch.float32))
test_sum_score += score
test_avg_score = test_sum_score / len(test_dataloader)
print(f"测试得分:{test_avg_score}")
torch.save(model.state_dict(), r"model.pt")

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)