人工智能与大模型技术全解析:从原理到应用开发
本文系统梳理人工智能的核心技术与大模型的应用实践。第一部分从人工智能发展历程切入,解析大模型的基本原理及其技术突破;第二部分聚焦大模型应用开发,对比模型部署方式的优缺点,探讨传统应用与AI大模型的差异,提出“强弱联合”的创新模式(传统系统与大模型协同),并剖析大模型应用开发的技术架构。全文旨在为开发者提供从理论到落地的完整知识框架,助力AI技术的高效实践与创新。
目录
1.认识AI
1.人工智能发展
AI,人工智能(Artificial Intelligence),使机器能够像人类一样思考、学习和解决问题的技术。
AI发展至今大概可以分为三个阶段:符号主义,联结主义,深度学习
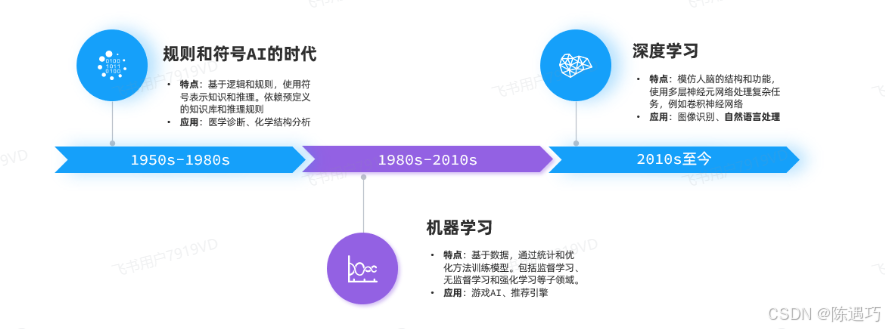
其中,深度学习领域的自然语言处理(Natural Language Processing, NLP)有一个关键技术叫做Transformer,这是一种由多层感知机组成的神经网络模型,是现如今AI高速发展的最主要原因。
我们所熟知的大模型(Large Language Models, LLM),例如GPT、DeepSeek底层都是采用Transformer神经网络模型。
以GPT模型为例,其三个字母的缩写分别是Generative、Pre-trained、Transformer:

2.大模型原理
其实,最早Transformer是由Google在2017年提出的一种神经网络模型,一开始的作用是把它作为机器翻译的核心:
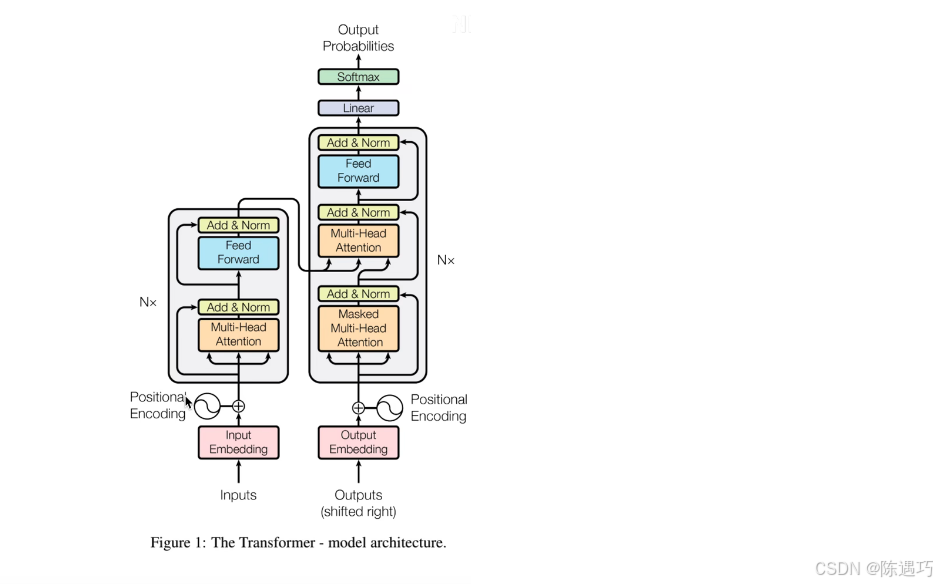
Transformer中提出的注意力机制使得神经网络在处理信息时可以根据上下内容调整对数据的理解,变得更加智能化。这不仅仅是说人类的文字,包括图片、音频数据都可以交给Transformer来处理。于是,越来越多的模型开始基于Transformer实现了各种神奇的功能。
大语言模型(Large Language Models, 以下简称LLM)是对Transformer的另一种用法:推理预测。
LLM在训练Transformer时会尝试输入一些文本、音频、图片等信息,然后让Transformer推理接下来跟着的应该是什么内容。推理的结果会以概率分布的形式出现:
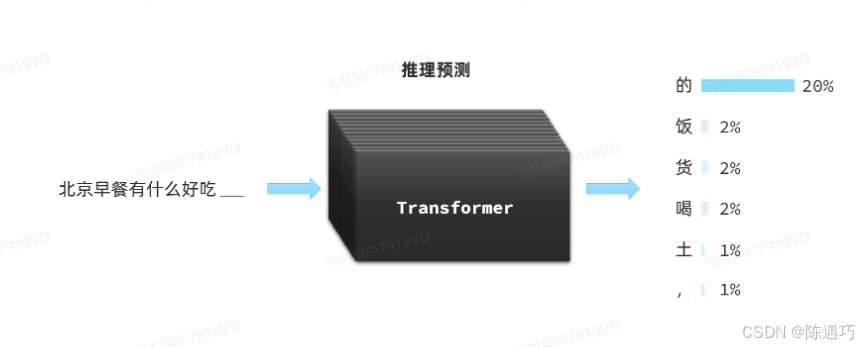
仅仅是推测接下来的内容,怎么能让ChatGPT在对话中生成大段的有关联的文字内容呢?
其实LLM采用的就是笨办法,答案就是:持续生成
根据前文推测出接下来的一个词语后,把这个词语加入前文,再次交给大模型处理,推测下一个字,然后不断重复前面的过程,就可以生成大段的内容了:
这就是为什么我们跟AI聊天的时候,它生成的内容总是一个字一个字的输出的原因了。
以上就是LLM的核心技术,Transformer的原理了.
2.大模型应用开发
1.模型部署类型及优缺点
首先要明确一点:大模型应用开发并不是在浏览器中跟AI聊天。而是通过访问模型对外暴露的API接口,实现与大模型的交互。
因此,企业首先需要有一个可访问的大模型,通常有三种选择:
-
使用开放的大模型API
-
在云平台部署私有大模型
-
在本地服务器部署私有大模型
使用开放大模型API的优缺点如下:
-
优点:
-
没有部署和维护成本,按调用收费
-
-
缺点:
-
依赖平台方,稳定性差
-
长期使用成本较高
-
数据存储在第三方,有隐私和安全问题
-
云平台部署私有模型:
-
优点:
-
前期投入成本低
-
部署和维护方便
-
网络延迟较低
-
-
缺点:
-
数据存储在第三方,有隐私和安全问题
-
长期使用成本高
-
本地部署私有模型:
-
优点:
-
数据完全自主掌控,安全性高
-
不依赖外部环境
-
虽然短期投入大,但长期来看成本会更低
-
-
缺点:
-
初期部署成本高
-
维护困难
-
2. 大模型应用
大模型应用是基于大模型的推理、分析、生成能力,结合传统编程能力,开发出的各种应用。
2.1 传统应用
核心特点:
基于明确规则的逻辑设计,确定性执行,可预测结果。
擅长领域:
1. 结构化计算
- 例:银行转账系统(精确的数值计算、账户余额增减)。
- 例:Excel公式(按固定规则处理表格数据)。
2. 确定性任务
- 例:排序算法(快速排序、冒泡排序),输入与输出关系完全可预测。
3. 高性能低延迟场景
- 例:操作系统内核调度、数据库索引查询,需要毫秒级响应。
4. 规则明确的流程控制
- 例:红绿灯信号切换系统(基于时间规则和传感器输入)。
不擅长领域:
1. 非结构化数据处理
- 例:无法直接理解用户自然语言提问(如"帮我写一首关于秋天的诗")。
2. 模糊推理与模式识别
- 例:判断一张图片是"猫"还是"狗",传统代码需手动编写特征提取规则,效果差。
3. 动态适应性
- 例:若用户需求频繁变化(如电商促销规则每天调整),需不断修改代码。
2.2 AI大模型
传统程序的弱项,恰恰就是AI大模型的强项:
核心特点:
基于数据驱动的概率推理,擅长处理模糊性和不确定性。
擅长领域:
1. 自然语言处理
- 例:ChatGPT生成文章、翻译语言,或客服机器人理解用户意图。
2. 非结构化数据分析
- 例:医学影像识别(X光片中的肿瘤检测),或语音转文本。
3. 创造性内容生成
- 例:Stable Diffusion生成符合描述的图像,或AI作曲工具创作音乐。
4. 复杂模式预测
- 例:股票市场趋势预测(基于历史数据关联性,但需注意可靠性限制)。
不擅长领域:
1. 精确计算
- 例:AI可能错误计算"12345 × 6789"的结果(需依赖计算器类传统程序)。
2. 确定性逻辑验证
- 例:验证身份证号码是否符合规则(AI可能生成看似合理但非法的号码)。
3. 低资源消耗场景
- 例:嵌入式设备(如微波炉控制程序)无法承受大模型的算力需求。
4. 因果推理
- 例:AI可能误判"公鸡打鸣导致日出"的因果关系。
2.3.强强联合
传统应用开发和大模型有着各自擅长的领域:
- - 传统编程:确定性、规则化、高性能,适合数学计算、流程控制等场景。
- - AI大模型:概率性、非结构化、泛化性,适合语言、图像、创造性任务。
在传统应用开发中介入AI大模型,充分利用两者的优势,既能利用AI实现更加便捷的人机交互,更好的理解用户意图,又能利用传统编程保证安全性和准确性,强强联合,这就是大模型应用开发的真谛!
综上所述,大模型应用就是整合传统程序和大模型的能力和优势来开发的一种应用。
3.大模型应用开发技术架构
3.1 技术架构
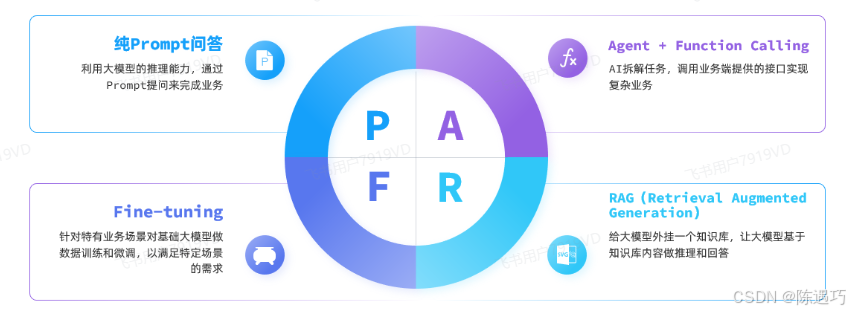
目前,大模型应用开发的技术架构主要有四种:

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)