Go语言实现国际象棋AI引擎实战
在编写一个国际象棋AI时,面临的挑战包括实现复杂的逻辑、优化搜索算法以及并行处理大量计算。Go语言因其简洁的语法、强大的并发支持和高效的运行时性能,成为实现复杂AI系统的理想选择。Go的并发模型基于轻量级线程(goroutines)和通道(channels),允许开发者轻松地处理并发任务。此外,Go的编译器优化、垃圾回收机制和丰富的标准库为AI项目提供了坚实的基础。在本章中,我们将探讨Go语言如何

简介:使用Go语言编写国际象棋人工智能引擎是一项复杂任务,涉及算法设计、搜索策略及评估函数等核心要素。本项目名为"Go_chess_AI_engine",利用Go语言的性能优势和并发特性,实现了高效的人工智能引擎。通过应用深度优先搜索、阿尔法-贝塔剪枝、最小-最大树、评估函数、启发式搜索等技术,以及并发处理和版本控制,该项目不仅提升了AI的搜索效率,还通过JavaScript接口实现了与网页的互动,为学习Go语言和AI编程提供了宝贵资源。 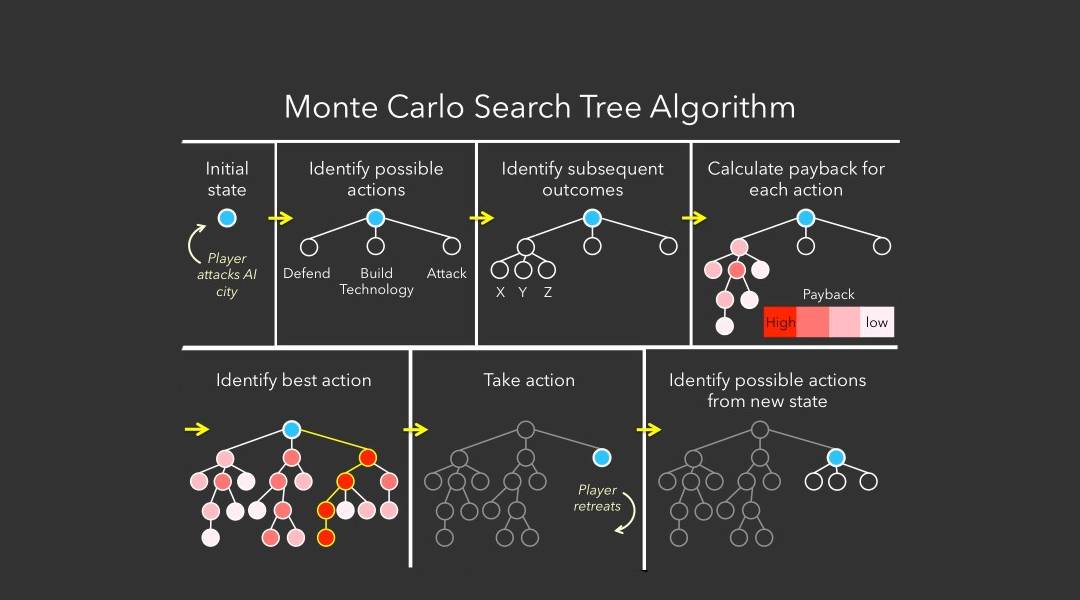
1. Go语言实现国际象棋AI介绍
1.1 AI编程挑战与Go语言的选择
在编写一个国际象棋AI时,面临的挑战包括实现复杂的逻辑、优化搜索算法以及并行处理大量计算。Go语言因其简洁的语法、强大的并发支持和高效的运行时性能,成为实现复杂AI系统的理想选择。
Go的并发模型基于轻量级线程(goroutines)和通道(channels),允许开发者轻松地处理并发任务。此外,Go的编译器优化、垃圾回收机制和丰富的标准库为AI项目提供了坚实的基础。
在本章中,我们将探讨Go语言如何在国际象棋AI项目中发挥作用,并简述一个AI项目从零到一的构建过程。随后的章节会深入分析Go的并发模型、搜索算法、评估函数设计等关键要素,并介绍一些优化技术和实际应用案例。
// 示例代码:一个简单的Go并发程序
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
for i := 1; i <= 10; i++ {
wg.Add(1) // 增加计数器
go func(i int) {
fmt.Printf("Goroutine %d is running\n", i)
wg.Done() // 任务完成后减少计数器
}(i)
}
wg.Wait() // 等待所有goroutine完成
}
以上是一个Go语言中并发编程的基础示例。在这个示例中,我们启动了10个goroutines,并使用 sync.WaitGroup 来确保主函数等待所有的goroutines执行完毕。这种模式在AI项目中非常常见,用于并发处理大量独立计算任务。
2. Go语言的性能和并发模型优势
2.1 Go语言的并发机制概述
2.1.1 Goroutine的原理与应用
Go语言的并发模型是其最突出的特性之一,它允许开发者以轻量级的线程(称为Goroutine)来实现并发程序。传统的线程模型中,线程是由操作系统内核管理,而Go的Goroutine则由Go运行时(runtime)管理。Goroutine比传统线程占用的资源少,创建和销毁的速度非常快,使得并发编程更加高效。
func hello() {
fmt.Println("Hello world")
}
func main() {
go hello() // 启动一个新的Goroutine
fmt.Println("Main function")
}
在这个简单的例子中, go hello() 启动了一个新的Goroutine来执行 hello() 函数。主函数继续执行,而 hello() 函数几乎同时执行,这展示了Goroutine的并发性质。Goroutines之间是协作式多任务处理,它们通过通道(channels)来通信,从而避免了锁和共享内存的复杂性。
2.1.2 Channel的同步与通信
通道是Go语言并发模型中的核心概念,它们是类型化的管道,可以用来在Goroutine之间传递数据。通道提供了一种同步机制,可以保证数据的正确顺序。它们是值的拥有者,因此在传递时会进行复制,这一特性避免了传统并发编程中常见的竞态条件。
ch := make(chan int) // 创建一个整数类型的通道
go func() {
ch <- 1 // 将1发送到通道
}()
value := <-ch // 从通道中接收值
fmt.Println(value)
在这个例子中,我们创建了一个通道 ch ,在Goroutine中向通道发送了一个值,并在主函数中从通道接收这个值。通道的接收和发送操作是阻塞的,这意味着没有数据时接收操作会等待,发送操作会等待直到接收者准备就绪。这种阻塞机制保证了数据的同步。
2.2 Go语言性能优化策略
2.2.1 内存管理和垃圾回收机制
Go语言的垃圾回收机制是自动的,并且是并发执行的,这减少了垃圾回收对程序运行的影响。Go的运行时会周期性地检查并回收不再使用的内存。这带来了性能的优化,特别是对于需要高效内存管理的场景。
垃圾回收的机制在Go1.8及之后的版本中得到了显著的改进,它利用了三色标记算法来追踪活跃的对象,从而进行垃圾回收。在开发高性能的Go程序时,我们可以通过减少内存分配来进一步提高性能,因为每一次内存分配都可能触发垃圾回收。
2.2.2 Go编译器与性能分析工具
Go的编译器非常高效,它通过逃逸分析来决定变量应该在堆还是栈上分配。这有助于优化内存使用和减少垃圾回收的负担。Go还提供了丰富的性能分析工具,如 pprof ,这使得开发者能够对程序的运行时性能进行深入的分析。
go tool pprof -http=:8080 [binary文件路径]
通过上述命令,可以启动一个基于Web的性能分析界面,其中包含了CPU分析和内存分析的选项。 pprof 可以分析程序的运行时数据,帮助识别性能瓶颈,并指导开发者进行相应的优化。
2.2.3 小结
Go语言的并发机制和性能优化策略为构建高效的并发程序提供了坚实的基础。Goroutine和Channel提供了并发编程的便利,而内存管理和垃圾回收机制则保证了程序的稳定运行。通过合理地使用Go语言的这些特性,开发者可以创建出既快速又可靠的并发应用。在接下来的章节中,我们将深入探讨如何利用这些并发特性来构建一个国际象棋AI。
3. 搜索算法与阿尔法-贝塔剪枝
3.1 搜索算法基础
在探讨搜索算法之前,我们需要了解搜索算法在国际象棋AI中扮演的角色。搜索算法能够帮助AI预测对手的行动,并计算出最佳的应对策略。而要实现这一点,必须经过大量的计算,这就需要高效的算法和数据结构来辅助。
3.1.1 深度优先搜索与广度优先搜索
深度优先搜索(DFS)与广度优先搜索(BFS)是两种基本的图搜索算法。在国际象棋AI中,我们使用它们来探索可能的棋步序列。深度优先搜索通过递归深入到可能的路径中,直到达到一个终点,然后回溯到上一个决策点,探索新的路径。而广度优先搜索则从根节点开始,逐层遍历所有节点。这两种搜索算法在国际象棋AI中各有优缺点,深度优先搜索在空间需求上较低,但可能需要处理更多的节点;广度优先搜索可以更快地找到最短路径,但空间需求较高。
// 伪代码示例:深度优先搜索
func DFS(node Node) {
if node.isGoal {
return true
}
for _, child := range node.children {
if DFS(child) {
return true
}
}
return false
}
// 伪代码示例:广度优先搜索
func BFS() {
queue := NewQueue()
queue.enqueue(startNode)
while !queue.isEmpty() {
node := queue.dequeue()
if node.isGoal {
return true
}
for _, child := range node.children {
queue.enqueue(child)
}
}
return false
}
上述代码展示了深度优先搜索和广度优先搜索的基本结构,虽然这仅是伪代码,但可以清晰地看出两种搜索方法在实现上的差异。
3.1.2 启发式搜索算法简介
启发式搜索算法通过评估函数来指导搜索过程,以减少需要探索的节点数量。在国际象棋AI中,启发式搜索的使用非常普遍,因为它可以极大地提升搜索效率。一个著名的启发式算法是A*算法,它使用启发式评估函数来确定搜索的优先级。评估函数基于当前棋局状态和目标状态之间的距离来评估节点的重要性。
3.2 阿尔法-贝塔剪枝的实现
阿尔法-贝塔剪枝是一种优化搜索树的算法,它通过剪枝操作减少了需要评估的节点数量,从而加快了搜索速度,而不影响最终的搜索结果。
3.2.1 剪枝算法原理与效率分析
阿尔法-贝塔剪枝的核心思想是在搜索过程中记录已经找到的最佳节点值,并利用这些信息来剪除那些不可能产生更好结果的分支。Alpha值代表在搜索路径上找到的最大值,而Beta值代表在搜索路径上找到的最小值。如果在某个节点发现当前节点的值小于或等于alpha值,那么该节点的所有子节点都不会比这个值更好,因此可以剪枝。
// 伪代码示例:阿尔法-贝塔剪枝
func AlphaBeta(node Node, alpha int, beta int, maximizingPlayer bool) int {
if node.isLeaf {
return evaluate(node)
}
if maximizingPlayer {
value := -infinity
for each child of node {
value = max(value, AlphaBeta(child, alpha, beta, false))
alpha = max(alpha, value)
if beta <= alpha {
break // 剪枝发生
}
}
return value
} else {
value := infinity
for each child of node {
value = min(value, AlphaBeta(child, alpha, beta, true))
beta = min(beta, value)
if beta <= alpha {
break // 剪枝发生
}
}
return value
}
}
上述伪代码展示了阿尔法-贝塔剪枝的基本逻辑。在实际应用中,需要根据具体问题调整评估函数和搜索策略。
3.2.2 实现阿尔法-贝塔剪枝的关键点
在实现阿尔法-贝塔剪枝时,需要特别注意几个关键点。首先,搜索树的节点需要有良好的组织,以便快速访问和更新alpha和beta值。其次,评估函数的设计对搜索效率和最终效果有重大影响。此外,合理的排序策略可以使得最有潜力的节点优先被搜索,从而提高剪枝的效率。
| 关键点 | 说明 | | --- | --- | | 节点组织 | 快速访问和更新alpha和beta值的节点结构 | | 评估函数 | 对搜索效率和结果质量有着决定性影响 | | 排序策略 | 提高剪枝效率,优先搜索有潜力的节点 |
通过对这些关键点进行优化,可以显著提高国际象棋AI的性能。接下来的章节,我们将深入探索最小-最大树的构建过程及其优化技术。
4. 构建最小-最大树
4.1 最小-最大树基础理论
4.1.1 树结构与国际象棋AI的关系
最小-最大树是一种决策树,常用于游戏AI中,特别是对于具有回合制玩法的游戏,如国际象棋。树结构有助于系统地评估每一步可能的移动,以及这些移动的潜在结果。在国际象棋AI中,这种树从当前棋局出发,向两个方向扩展:对手的可能移动(最小化分支)和AI的可能移动(最大化分支)。树的每个节点代表一个棋局状态,而树的层级则对应移动的深度。
理解树结构对国际象棋AI的重要性在于,它提供了一种组织和评估潜在棋局的框架。AI通过在树中递归地寻找最优移动,尝试最大化其在游戏中的获胜机会。通过这种结构化的方法,AI可以模拟并评估不同游戏序列的可能结果。
4.1.2 最小-最大树的构建过程
构建最小-最大树的过程开始于当前棋局状态,这个状态被放在树的根节点。接下来,算法生成所有可能的合法移动,并创建子节点来代表这些移动。这些移动导致的棋局状态成为树的第二层节点。然后,对于每个第二层节点,AI再次生成所有可能的对手移动,形成第三层节点,这个过程递归进行,直到达到预定的搜索深度或游戏结束状态。
在构建树的过程中,每个节点都要求有明确的评估值,用于比较不同移动的优劣。评估值通常由评估函数计算,这个函数根据棋局状态的特定指标,如棋子数量、棋型价值、棋子位置和安全度等来判断棋局的优劣。
4.2 最小-最大树的优化技术
4.2.1 迭代深化搜索
迭代深化搜索(Iterative Deepening Search)是一种优化技术,通过在每次迭代中增加搜索深度,逐步提高算法效率。这种方法特别适合用于国际象棋AI,因为它可以避免在给定时间内过早地达到固定深度。通过迭代深化,AI可以快速地进行浅层次的搜索,并根据结果逐步深入探索更有希望的分支。
迭代深化搜索的一个关键优点是它可以在有限的时间内总是返回最佳移动,即使计算过程提前中断。这一点对于游戏中的实时环境尤其重要,在这种环境中,AI可能没有足够的时间来完成深层次的搜索。
4.2.2 剪枝策略在最小-最大树中的应用
剪枝策略在最小-最大树中的应用,是提高算法效率的关键。剪枝可以减少需要评估的节点数量,从而加快搜索过程。最著名的剪枝技术是阿尔法-贝塔剪枝(Alpha-Beta Pruning),它利用最小化和最大化节点的性质来消除那些不可能影响最终决策的节点。
在实际操作中,阿尔法-贝塔剪枝会设置两个参数:阿尔法(α)和贝塔(β),分别代表当前路径上最佳可获得的最小值和最大值。如果在某一点上,一个节点的潜在值不能超过已知的阿尔法或贝塔值,那么这个节点的后续搜索就可以被剪枝。这显著减少了搜索树中的节点数量,提高了效率。
下面是一个简化的伪代码来演示阿尔法-贝塔剪枝的基本逻辑:
function alphaBeta(node, depth, α, β, maximizingPlayer):
if depth == 0 or node is a terminal node:
return the heuristic value of node
if maximizingPlayer:
value := -∞
for each child of node:
value := max(value, alphaBeta(child, depth - 1, α, β, false))
α := max(α, value)
if β ≤ α:
break // β剪枝
return value
else:
value := +∞
for each child of node:
value := min(value, alphaBeta(child, depth - 1, α, β, true))
β := min(β, value)
if β ≤ α:
break // α剪枝
return value
在上述伪代码中, node 是当前考虑的节点, depth 是剩余搜索深度, α 是当前最优的最大值, β 是当前最优的最小值。函数 alphaBeta 根据最大化或最小化玩家进行递归搜索,并在必要时进行剪枝。这简化了搜索过程,避免了不必要的节点探索,从而使得算法更加高效。
5. 评估函数的设计
评估函数是国际象棋AI中最重要的组件之一,它负责为每一个可能的棋局局面给出一个评分。这个评分反映了AI对于当前局面的评估,是它做出决策的基础。评估函数的好坏直接影响了AI的水平。一个优秀的评估函数能够识别出有利和不利的棋局特点,帮助AI在搜索过程中找到最佳的走法。
5.1 评估函数的作用与要求
5.1.1 评估函数在AI中的重要性
评估函数的作用是对当前的棋局进行分析,并给出一个数值评分。这个评分是AI做出决策的依据,它决定了AI将选择走哪一步。一个理想的评估函数能够准确地反映棋局的优劣,并且能够区分出微小的差别。AI根据评估函数的评分,通过搜索算法来选择最佳的走法。如果没有一个准确的评估函数,AI就无法正确地评估棋局,也就无法做出正确的决策。
5.1.2 设计评估函数的基本原则
设计评估函数时需要遵循几个基本原则。首先,评估函数应该能够反映棋局的关键要素,如棋子的位置、棋型、安全性等。其次,评估函数的计算不应过于复杂,以便快速响应。第三,评估函数需要有一定的容错能力,能够处理一些特殊情况,并且不会因为对某个特定局面的过度优化而影响整体的AI表现。
5.2 实现评估函数的策略
5.2.1 特定棋子的价值评估
在国际象棋中,不同的棋子有不同的价值。例如,皇后一般比兵具有更高的价值。评估函数需要为每一种棋子赋予一个基础价值。然而,这个价值并不是静态的,它需要根据棋子在棋局中的具体位置和作用进行动态调整。例如,一个被对方攻击但尚未被保护的棋子应该有更低的评估值。
代码示例(简化版):
// 定义棋子的基础价值
const (
ValuePawn = 100
ValueKnight = 300
ValueBishop = 300
ValueRook = 500
ValueQueen = 900
)
// 获取棋子价值
func getPieceValue(piece PieceType) int {
switch piece {
case Pawn:
return ValuePawn
case Knight, Bishop:
return ValueKnight
case Rook:
return ValueRook
case Queen:
return ValueQueen
}
return 0
}
在这个代码块中,我们定义了一个基础的评估函数,它为不同类型的棋子赋予了不同的价值。请注意,实际的评估函数会更加复杂,需要考虑到棋子的位置、是否被攻击、是否是双方第一次移动过的棋子等因素。
5.2.2 棋局位置与棋型的复杂度评估
评估函数不仅需要考虑单个棋子的价值,还需要考虑棋局的整体布局和复杂度。例如,棋型(如“双车”、“马前兵”)的评估需要基于其控制棋盘的能力以及可能的威胁。此外,棋子之间的协同作用也是评估函数需要考虑的因素之一。
复杂度评估可以通过检查棋盘上的不同棋型和棋子布局来实现。例如,AI可以通过识别国王和皇后之间的保护关系、长距离的将军威胁等来提高评估的复杂度。代码实现时,可以利用预先定义的评估值表来处理这些情况。
代码示例(简化版):
// 检查并评估特定的棋型
func evaluateChessPosition(board *Board) int {
var score int
// 检查棋型并赋予相应的分数
// 假设checkPositionForChessType()是一个检查特定棋型的函数
if checkPositionForChessType(board, "DoubleRooks") {
score += 10 // 双车的额外价值
}
// 其他棋型的评估逻辑...
return score
}
请注意,上述代码仅为示例,实际的国际象棋AI评估函数会更加复杂,并且需要考虑更多的棋型和情况。
通过不断优化和调整评估函数,国际象棋AI的水平可以显著提高。然而,要达到顶尖水平,还需要配合高效的搜索算法和深度学习等技术。下一章节,我们将探讨启发式搜索技术在国际象棋AI中的应用。
6. 启发式搜索技术
6.1 启发式搜索技术概述
在国际象棋AI中,启发式搜索技术是提升决策智能化的关键。与传统的盲目搜索方法不同,启发式搜索依赖于特定的规则和函数,引导搜索过程往更有可能的结果发展,从而提高搜索效率和质量。
6.1.1 启发式搜索与国际象棋AI的关系
在国际象棋这种复杂决策问题中,可能性空间巨大,无法穷尽所有可能的走法,因而必须借助启发式搜索来导向合理的评估。例如,国际象棋AI评估函数中使用的棋子价值评分就是一种简单的启发式信息。
6.1.2 常见的启发式算法介绍
启发式搜索技术包括但不限于:
- A*搜索算法:广泛应用于路径寻找问题,通过评估函数
f(n) = g(n) + h(n)来导向最短路径。 - 最佳优先搜索:根据启发式函数选择最有利的节点进行扩展,不需要考虑所有可能节点。
- 蒙特卡洛树搜索(MCTS):利用随机模拟来构建搜索树,通过统计信息指导搜索方向。
6.2 启发式搜索技术的应用实例
6.2.1 实现与优化启发式搜索的策略
实施启发式搜索的关键在于设计一个良好的启发式函数。以国际象棋AI为例,我们可以使用棋子的类型和位置作为启发式信息,同时也可以考虑棋局的特定模式。
// 伪代码示例:使用启发式函数指导搜索
func heuristic(board Board) int {
// 定义各种棋子的价值
var value int
for _, piece := range board.Pieces {
switch piece.Type {
case Pawn:
value += piecePositionValue(piece.Position)
// 其他棋子类型...
}
}
// 根据特定棋型增加或减少价值
// ...
return value
}
func piecePositionValue(position Position) int {
// 基于棋子位置和棋局布局的启发式价值计算
// ...
return positionValue
}
6.2.2 启发式搜索在实际AI中的测试与评估
对于任何启发式算法,都需要通过测试来评估其性能。在国际象棋AI中,可以通过与已知好的走法比较,或参与比赛来测试算法的有效性。
为了测试和评估,可以构建一个测试框架:
type Evaluator interface {
Evaluate(board Board) int
}
func testHeuristic(e Evaluator, testCases []TestCase) {
for _, tc := range testCases {
board := tc.board
score := e.Evaluate(board)
// 比较启发式评分与预期评分,记录偏差
// ...
}
}
评估过程中可能需要考虑搜索深度、走法评估的准确性以及搜索时间等因素,从而确定最佳的启发式搜索策略。
简介:使用Go语言编写国际象棋人工智能引擎是一项复杂任务,涉及算法设计、搜索策略及评估函数等核心要素。本项目名为"Go_chess_AI_engine",利用Go语言的性能优势和并发特性,实现了高效的人工智能引擎。通过应用深度优先搜索、阿尔法-贝塔剪枝、最小-最大树、评估函数、启发式搜索等技术,以及并发处理和版本控制,该项目不仅提升了AI的搜索效率,还通过JavaScript接口实现了与网页的互动,为学习Go语言和AI编程提供了宝贵资源。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)