【论文速读】(2025 TMM)SkeletonX: Data-Efficient Skeleton-based ActionRecognition via Cross-sample Feature
Zongye Zhang, Wenrui Cai, Qingjie Liu, Yunhong Wang论文地址:https://arxiv.org/pdf/2504.11749现有的骨架动作识别模型在大规模数据集上表现优异,但在新场景(如新动作类别、不同表演者,或不同骨架布局)中适应性较差。One-shot 学习:每个新动作类别仅有一个参考样本。Limited-scale训 练:从零开始训练,仅使
SkeletonX: Data-Efficient Skeleton-based ActionRecognition via Cross-sample Feature Aggregation
Zongye Zhang, Wenrui Cai, Qingjie Liu, Yunhong Wang
论文地址:https://arxiv.org/pdf/2504.11749
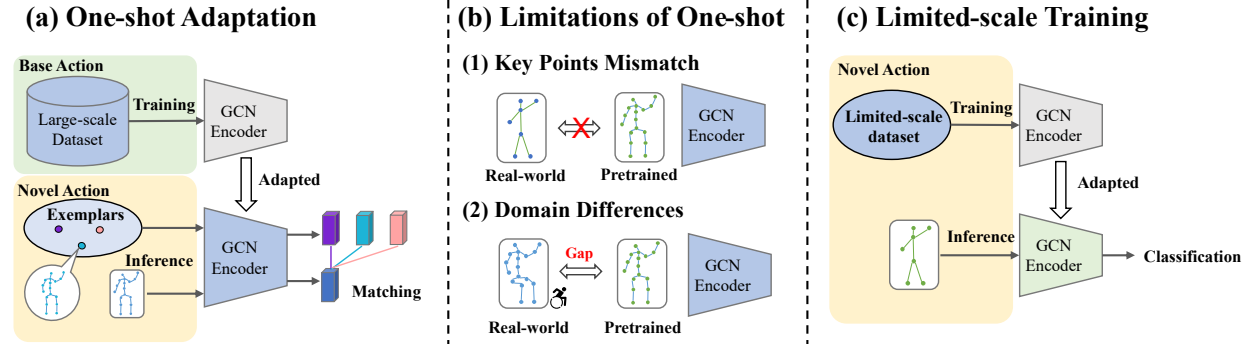
研究动机
现有的骨架动作识别模型在大规模数据集上表现优异,但在新场景(如新动作类别、不同表演者,或不同骨架布局)中适应性较差。
研究内容
One-shot 学习:每个新动作类别仅有一个参考样本。
Limited-scale训 练:从零开始训练,仅使用少量样本(如每类10、20、30、50个样本)。
方法创新
提出 SkeletonX,一个轻量、即插即用的训练流程(training pipeline)。
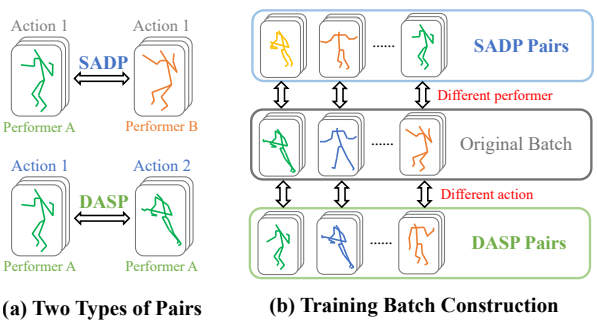
其中 pair sample 的构建策略:基于表演者(Performer)和动作(Action)两个关键属性,构建两种样本对:
- DASP(Different Action, Same Performer):不同动作,同一表演者。
- SADP(Same Action, Different Performer):相同动作,不同表演者。
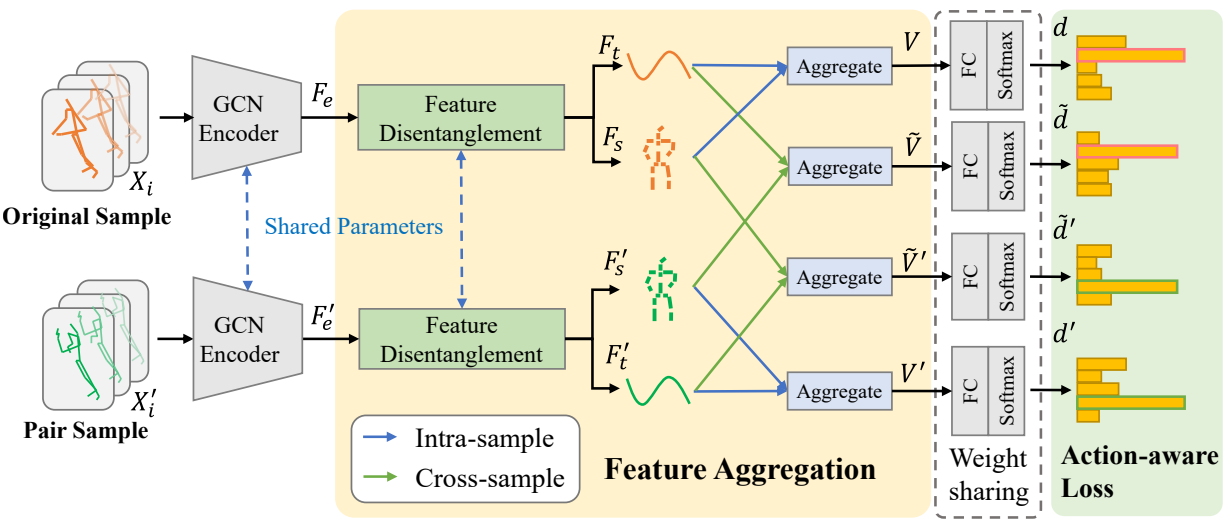
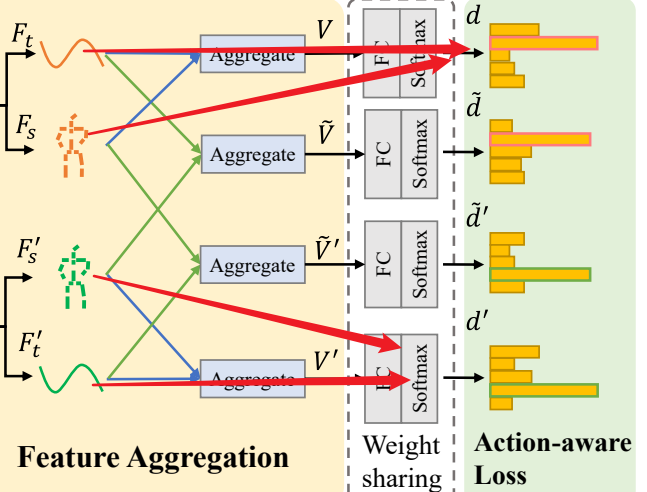
特征解耦(feature disentanglement):解耦空间特征(表演者相关,performer-related)和时间特征(动作相关,action-related)
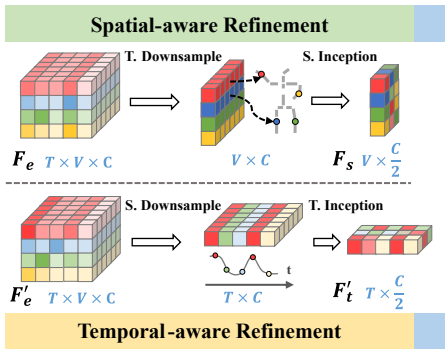
![]()
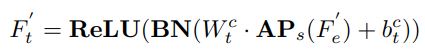
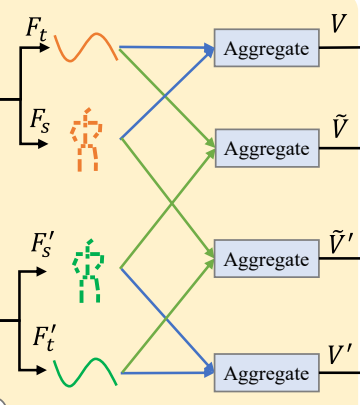
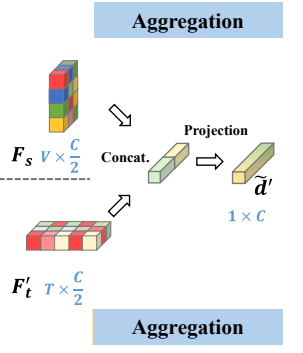
特征聚合模块(Aggregate):通过解耦空间特征(表演者相关)和时间特征(动作相关),并
交叉聚合这些特征,增强模型对多样性的学习能力。
![]()
动作感知损失函数(action-aware loss):学习不同表演者的与动作相关的特征表示。
总体 loss:
![]()
其中,
![]()
注意,DASP 是同一表演者的不同动作对,所以 y ≠ y’
![]()
SADP 是不同表演者的相同动作对,所以动作标签 y 是一致的。
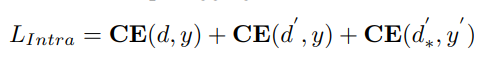
其中,d,d′ 和 d′∗ 是均为相同样本时空特征的聚合结果
d′ 是 d 的 SADP paired sample (不同表演者的相同动作对);
d′∗ 是 d 的 DASP paired sample (同一表演者的不同动作对)。
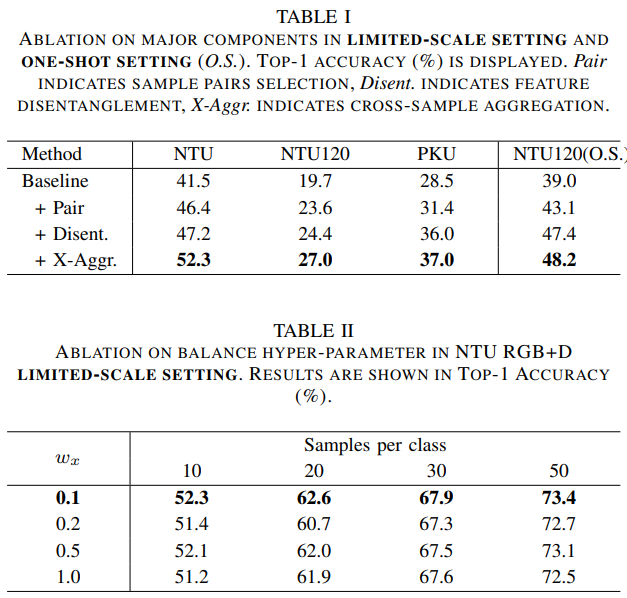
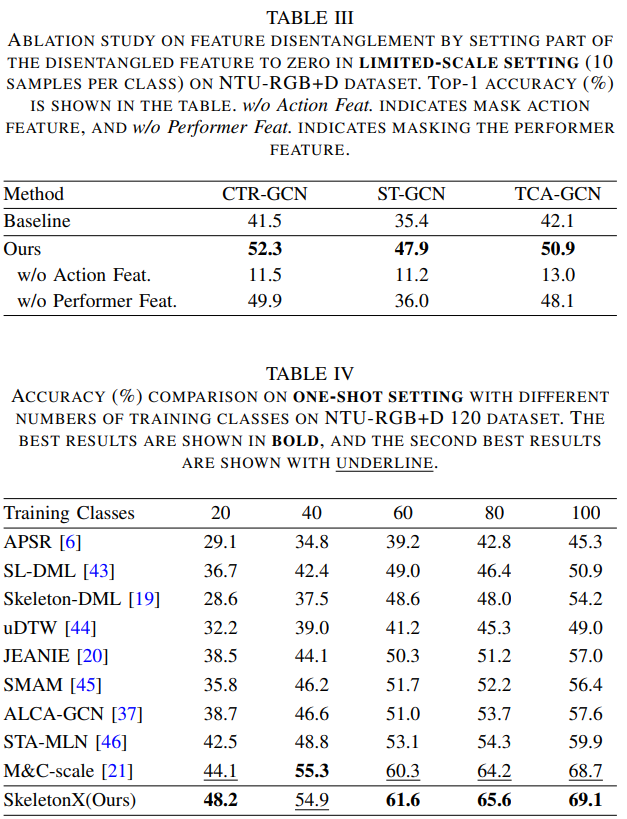
部分实验结果
快问快答
1. 摘要里:“We present SkeletonX, a lightweight training pipeline that integrates seamlessly with existing GCN-based skeleton action recognizers, promoting effective training under limited labeled data. First,” 为什么只提 GCN?
We observe that performance improvements are less significant compared to those achieved with GCN-based backbones. This discrepancy could be attributed to the inherent differences between the global attention mechanism of the Transformer and the topology-based approach of GCNs. The attention mechanism in Transformers may not perform as effectively in settings with fewer data, as it may focus on less relevant parts of the data.
2. 文中提到的 “信息瓶颈理论”(Information Bottleneck Theory)是什么?
在数据处理过程中,最优的特征表示应该在“压缩输入信息”和“保留与目标任务相关的信息”之间找到平衡。
X:输入数据(如骨架动作序列)。
Z:中间表示(如神经网络提取的特征)。
Y:目标任务(如动作类别标签)。
I(X;Z):Z 保留的关于 X 的信息量(压缩程度)。
I(Z;Y):Z 保留的关于 Y 的信息量(预测能力)。
β:权衡参数,控制压缩与预测的平衡。
目标:找到一种表示 Z,既能最大限度压缩输入
X(减少冗余),又能保留对 Y 有用的信息(保持判别性)。
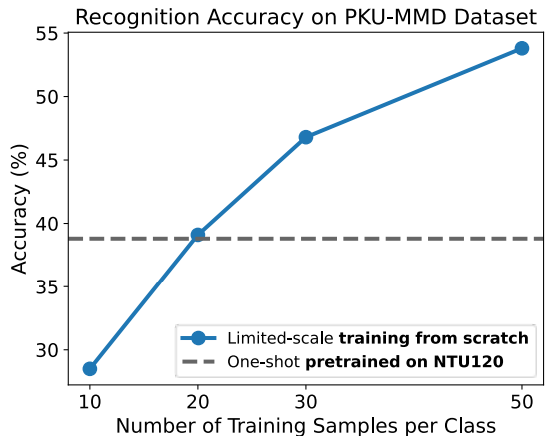
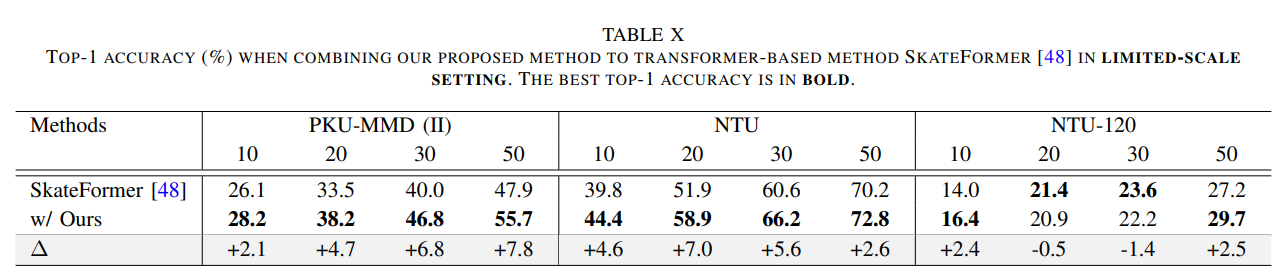
3. 论文 Figure 2 展示了 PKUMMD dataset 上 one-shot 和 limited-scale training setting(每个类别 10、20、30、50 个训练样本)的性能。 PKU-MMD 每个类原来有几个样本呀?
Part II contains around 6,900 action instances with 41 action classes, performed by 13 subjects.
平均一个类 168 个样本
4. Table 3 里提到的 mask 怎么操作?
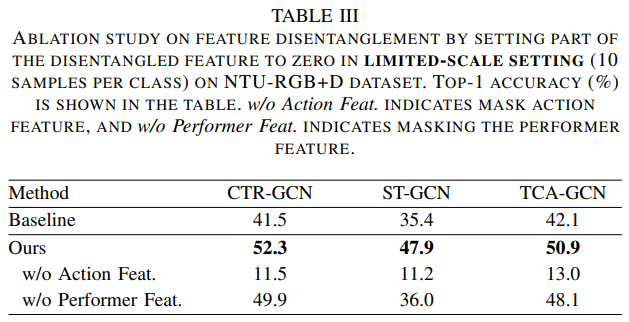
manually mask the action feature or performer feature by setting it to zero before aggregation.
5. Table 7 里的 Mixup 和 R.R. 是什么?
两种数据增强操作
Mixup 两个 sequence 混在一起,label 为 soft label,设置为混合比例
R.R. 是 RANDOM ROTATION 的缩写
6. Meta Learning 又是怎么做呢?
其核心思想是通过在多个相关任务上训练,提取可迁移的知识,从而在新任务上仅需少量样本即可高效学习。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)