【LLM应用开发101】初探RAG
大语言模型(LLMs)的应用开发可以被视为一种实现人工智能(AI)和自然语言处理(NLP)技术的方式。这种类型的模型,比如GPT-3或GPT-4(但其实一些不那么大的模型例如BERT及其变种, 在很多应用中也非常有用),能够生成与人类语言类似的文本,使其在各种应用上具有广泛的可能性。以下是一些大语言模型应用开发的主要应用领域:内容生成与编辑:语言模型可以生成文章、报告、电子邮件等,也可以提供写作建
本文是LLM应用开发101系列的先导篇,旨在帮助读者快速了解LLM应用开发中需要用到的一些基础知识和工具/组件。
本文将包括以下内容:首先会介绍LLM应用最常见的搜索增强生成RAG,然后引出实现RAG的一个关键组件 – 向量数据库,随后我们是我们这篇博客的重点,一个非常有效的轻量级向量数据库实现ChromaDB.
概述
大语言模型(LLMs)的应用开发可以被视为一种实现人工智能(AI)和自然语言处理(NLP)技术的方式。这种类型的模型,比如GPT-3或GPT-4(但其实一些不那么大的模型例如BERT及其变种, 在很多应用中也非常有用),能够生成与人类语言类似的文本,使其在各种应用上具有广泛的可能性。
以下是一些大语言模型应用开发的主要应用领域:
-
内容生成与编辑:语言模型可以生成文章、报告、电子邮件等,也可以提供写作建议和修改。
-
问答系统:大语言模型可以被用来创建自动问答系统,能够理解并回答用户的问题(
BERT应用中有一种Question Answer和我们直觉的问答系统有点不一样,是从给出的文本中找答案)。 -
对话系统与聊天机器人:大语言模型可以生成连贯且自然的对话,使其在创建聊天机器人或虚拟助手方面具有潜力。
-
机器翻译:虽然这些模型通常不专为翻译设计,但它们可以理解并生成多种语言,从而能够进行一定程度的翻译。
-
编程助手:语言模型可以理解编程语言,并提供编程帮助,比如代码生成、代码审查、错误检测等。
-
教育:语言模型可以被用于创建个性化的学习工具,如自动化的作业帮助或在线教育平台。
在开发这些应用时,开发者需要注意模型可能存在的限制,比如误解用户的输入、生成不准确或不可靠的信息、可能出现的偏见等等。这就需要开发者在应用设计和实现时进行适当的控制和优化。
那么在什么情况下需要RAG呢?
RAG模型在以下几种情况下可能特别有用:
-
需要大量背景知识的任务:比如在问答系统中,如果问题需要引用大量的背景知识或者事实来回答,那么RAG模型可能是一个很好的选择。RAG模型可以从大规模的知识库中检索相关信息,然后生成回答。
-
需要复杂推理的任务:在一些需要理解和推理复杂关系的任务中,比如多跳问答或者复杂的对话生成,RAG模型也可能表现得比纯生成模型更好。因为RAG模型可以利用检索到的文本来帮助生成模型进行推理。
-
需要从长文本中提取信息的任务:在一些需要从长文本中提取信息的任务中,比如文档摘要或者长文本阅读理解,RAG模型也有很大的潜力。因为RAG模型可以先检索到相关的文本片段,然后再生成答案,避免了生成模型处理长文本的困难。
总的来说,RAG模型在需要大量背景知识、复杂推理或者长文本信息提取的任务中可能有很大的优势。下面我们介绍一下RAG。
RAG
RAG,全称为Retrieval-Augmented Generation,是一种结合了检索和生成的深度学习模型。它首先使用一个检索模型从一个大规模的知识库中找出和输入相关的文档或者文本片段,然后将这些检索到的文本和原始输入一起输入到一个生成模型中。生成模型使用这些信息来生成响应。这种结合检索和生成的方式使得RAG模型可以更好地处理需要大量背景知识或者具有复杂推理需求的问题。
RAG模型的一个关键优点是它可以从非结构化的大规模文本数据中提取知识,而不需要预先构建一个结构化的知识图谱。这使得RAG模型在许多NLP任务,如问答、对话生成等,都有出色的表现。
下图展现了LLMs和RAG是如何协作的:
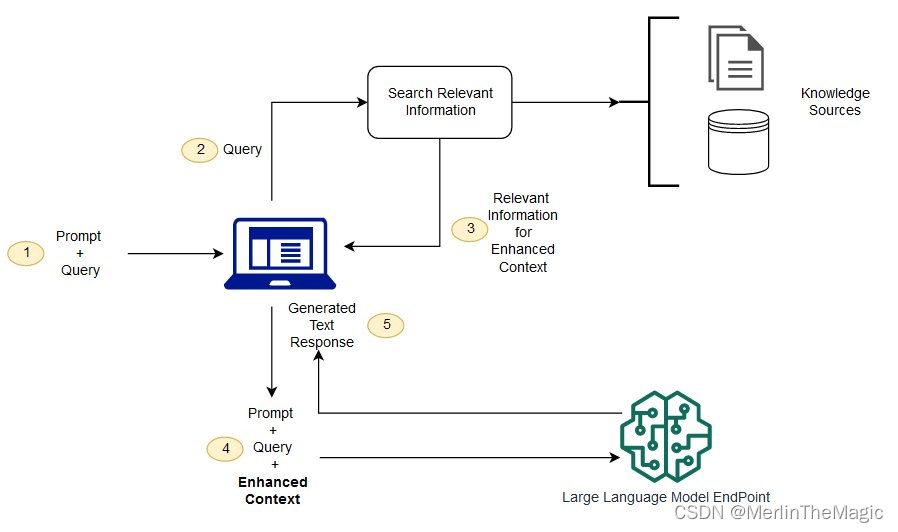
从图中我们可以看到,RAG的关键步骤,就是要能够Search Relevant Information, 而向量数据库,就是一个非常好的实现途径. 下面介绍一个非常优秀的实现, ChromaDB.
向量数据库ChromaDB
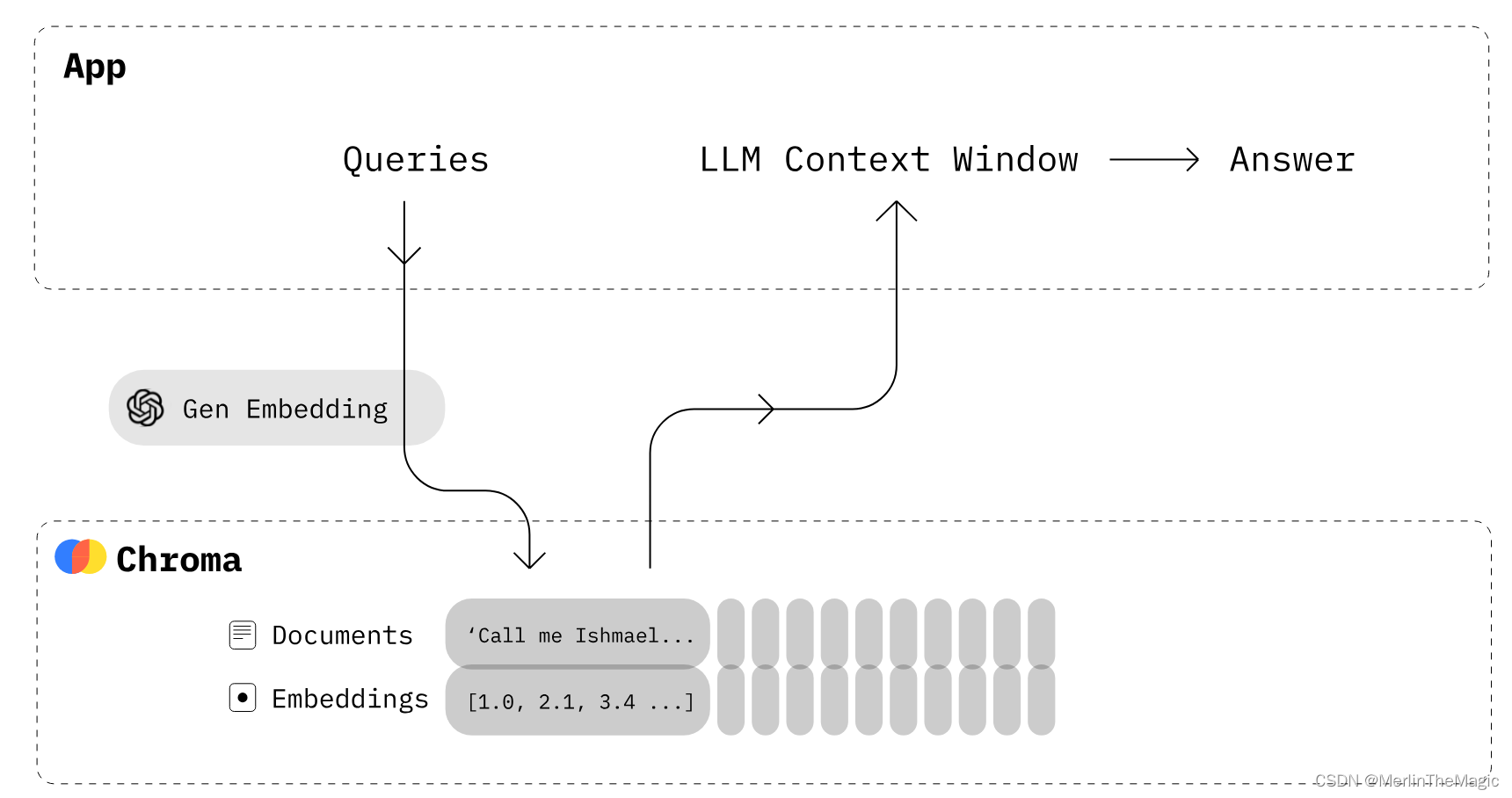
ChromaDB 是一个轻量级、易用的向量数据库,主要用于 AI 和机器学习场景。
它的主要功能是存储和查询通过嵌入(embedding)算法从文本、图像等数据转换而来的向量数据。ChromaDB 的设计目标是简化大模型应用的构建过程,允许开发者轻松地将知识、事实和技能等文档整合进大型语言模型中。
ChromaDB 的开源地址是: https://github.com/chroma-core/chroma
ChromaDB 支持大多数的主流编程语言,如Python, Javascript,Java, Go等,当前具体支持情况可以看下表,本文主要介绍Python环境下的使用.
| 编程语言 | 客户端 |
|---|---|
| Python | ✅ chromadb (by Chroma) |
| Javascript | ✅ chromadb (by Chroma) |
| Ruby | ✅ from @mariochavez |
| Java | ✅ from @t_azarov |
| Go | ✅ from @t_azarov |
| C# | ✅ from @microsoft |
| Rust | ✅ from @Anush008 |
| Elixir | ✅ from @3zcurdia |
| Dart | ✅ from @davidmigloz |
| PHP | ✅ from @CodeWithKyrian |
| PHP (Laravel) | ✅ from @HelgeSverre |
安装
在python环境下,安装非常简单,只需要用pip 就可以完成,如果遇到网络速度问题,可以选择替换pip mirror, 如果担心环境中各种包的干扰,可以用Annaconda创建一个全新的env.
pip install chromadb
顺便介绍一下nodejs 环境下的安装,也非常容易
## yarn
yarn install chromadb chromadb-default-embed
## npm
npm install --save chromadb chromadb-default-embed
编程交互
在开始用代码和chromadb交互前,我们还有一个问题需要理清:向量数据库存储的是向量,而RAG需要的是文本来做增强生成,那么显然,我们需要有一个机制来实现文本和向量之间的转换。这个转换过程就是我们常说的文本嵌入(Text Embedding)。在ChromaDB中,这个过程是自动完成的,它内置了多种嵌入模型供我们选择。
为了演示过程,我们先创建一个collection
collection = chroma_client.create_collection(name="my_collection")
添加一些数据
collection.add(
documents=[
"This is a document about pineapple",
"This is a document about oranges"
],
ids=["id1", "id2"]
)
这里是为了简单起见用的非常短的测试文本,在实际应用中,就是从文档中切分出的某一段文字了。文档显示,Chroma使用all-MiniLM-L6-v2作为默认的embedding模型(第一次进行embedding时,可以看到下载模型的输出\.cache\chroma\onnx_models\all-MiniLM-L6-v2\onnx.tar.gz). 这个模型参数量适中且经过充分训练,在模型上加上分类头进行classification任务也能取得很好的效果。
接下来进行一次query
results = collection.query(
query_texts=["This is a query document about hawaii"],
n_results=2 # 设置返回文档数量,默认是10
)
print(results)
可以看到输出的结果
{'ids': [['id1', 'id2']],
'embeddings': None,
'documents': [['This is a document about pineapple',
'This is a document about oranges']],
'uris': None,
'included': ['metadatas', 'documents', 'distances'],
'data': None,
'metadatas': [[None, None]],
'distances': [[1.0404009819030762, 1.2430799007415771]]}
完整例子
import re
import ollama
import chromadb
from chromadb.config import Settings
from concurrent.futures import ThreadPoolExecutor
# 1. 文档加载与文本切分(这里以纯文本为例,实际可用PyMuPDF等库加载PDF)
def split_text(text, chunk_size=500, chunk_overlap=100):
chunks = []
start = 0
length = len(text)
while start < length:
end = min(start + chunk_size, length)
chunk = text[start:end]
chunks.append(chunk)
start += chunk_size - chunk_overlap
return chunks
# 2. 初始化Ollama Embeddings(DeepSeek-R1)
class OllamaDeepSeekEmbeddings:
def __init__(self, model="deepseek-r1:14b"):
self.model = model
self.client = ollama.Ollama()
def embed_query(self, text):
# 通过 Ollama API 调用 DeepSeek-R1 生成文本向量
# Ollama Python SDK具体接口可能不同,以下为示例
response = self.client.embeddings(model=self.model, input=text)
return response['embedding']
# 3. 初始化Chroma客户端和向量库
def init_chroma_collection(collection_name="rag_collection"):
client = chromadb.Client(Settings(
chroma_db_impl="duckdb+parquet",
persist_directory="./chroma_db"
))
collection = client.get_or_create_collection(name=collection_name)
return client, collection
# 4. 构建向量数据库:将文本切分后生成embedding并存入Chroma
def build_vector_store(text, embedding_model, collection):
chunks = split_text(text)
# 并行生成向量
def embed_chunk(chunk):
return embedding_model.embed_query(chunk)
with ThreadPoolExecutor() as executor:
embeddings = list(executor.map(embed_chunk, chunks))
# 插入Chroma
ids = [f"chunk_{i}" for i in range(len(chunks))]
metadatas = [{"text": chunk} for chunk in chunks]
collection.add(
documents=chunks,
embeddings=embeddings,
metadatas=metadatas,
ids=ids
)
collection.persist()
# 5. 检索相关文本
def retrieve_relevant_docs(query, embedding_model, collection, top_k=3):
query_embedding = embedding_model.embed_query(query)
results = collection.query(
query_embeddings=[query_embedding],
n_results=top_k,
include=["documents", "metadatas"]
)
# 返回文本块列表
return results['documents'][0]
# 6. 结合上下文调用DeepSeek-R1生成回答
def generate_answer(question, context, model="deepseek-r1:14b"):
client = ollama.Ollama()
prompt = f"Question: {question}\n\nContext: {context}\n\nAnswer:"
response = client.chat(
model=model,
messages=[{"role": "user", "content": prompt}]
)
answer = response['message']['content']
# 清理DeepSeek可能的特殊标记
answer = re.sub(r'<think>.*?</think>', '', answer, flags=re.DOTALL).strip()
return answer
# 7. RAG整体调用示例
if __name__ == "__main__":
# 假设有一个大文本知识库
knowledge_text = """
这里放入你的知识库文本,比如从PDF提取的内容。
"""
# 初始化embedding模型和Chroma
embedding_model = OllamaDeepSeekEmbeddings(model="deepseek-r1:14b")
client, collection = init_chroma_collection()
# 构建向量数据库(首次运行)
build_vector_store(knowledge_text, embedding_model, collection)
# 用户提问
user_question = "什么是深度学习?"
# 检索相关上下文
relevant_chunks = retrieve_relevant_docs(user_question, embedding_model, collection, top_k=3)
combined_context = "\n\n".join(relevant_chunks)
# 生成回答
answer = generate_answer(user_question, combined_context)
print("回答:", answer)
总结
本文介绍了RAG的原理并给出代码示例,相信能够帮助读者快速熟悉RAG并上手开发应用.

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)