5天速成ai agent智能体camel-ai之第3天:提升大模型回复精准率,camel-ai的RAG知识库教程(零基础可运行代码)
load_dotenv(dotenv_path=env_path, override=True) # override=True 表示如果系统变量和.env都有,用.env的。print("系统原生环境变量:", os.environ.get('QWEN_API_KEY')) # 检查系统环境变量(如果设置了的话)你不需要成为顶尖的AI科学家,只需要理解这个流程,借助 `camel-ai` 这样友
你是不是也常常觉得,和AI聊天虽然有趣,但总感觉隔靴搔痒?🤯
问它点专业问题,要么回答得模棱两可,要么干脆胡说八道。想让它基于某个特定文件或知识领域回答,它却一脸茫然,仿佛从未听说过。
这种“通用”AI带来的挫败感,你体验过多少次?
* 想让AI总结一下你刚下载的行业报告,它却只会说“请提供内容”?
* 想让AI基于公司内部的知识库回答新员工的问题,它却只能“抱歉,我不知道”?
* 想让AI成为你特定领域的学习和研究助手,它却总是“一本正经地胡说八道”?
是时候终结这种低效沟通了!🔥
今天,我就要为你揭秘一个“秘密武器”——CAMEL-AI 框架中的 RAG(Retrieval-Augmented Generation) 技术。它就像给你的AI装上了一个“外挂大脑”,让它能够基于你指定的文档或知识库,给出精准、深入、令人惊艳的回答!
更重要的是,我将带你逐行解读实现这一切的Python代码。别怕,即使你是编程新手,我也能让你看懂、学会,甚至能动手改造,打造属于你自己的“专家AI”!
想象一下:
* 你的AI助手能秒懂长篇PDF论文的核心观点。
* 你的AI客服能精准引用公司规章制度回答用户疑问。
* 你的AI学习伙伴能基于你指定的教材进行深度探讨。
是不是感觉未来已来?🚀 别眨眼,干货来了!
---
### 什么是 RAG?给AI装上“搜索引擎”+“思考脑”!
在我们深入代码之前,先用大白话解释下 RAG 是个啥玩意儿。
RAG = 检索(Retrieval)+ 增强(Augmented)+ 生成(Generation)
听起来高大上?其实原理很简单:
1. 检索 (Retrieval): 当你向AI提问时,它不再是“拍脑袋”瞎想。它会先拿着你的问题,去你指定的知识库(比如一个PDF文件、一堆文档、一个数据库)里搜索最相关的几段信息。就像一个图书管理员,根据你的需求,快速找到相关的几本书或几个章节。
2. 增强 (Augmented): AI 把这些检索到的“原始资料”和你的原始问题放在一起。
3. 生成 (Generation): 最后,AI(比如我们后面会用到的Qwen模型)基于这些精准的、相关的上下文信息,而不是它自己“通用”但可能不准确的知识,来生成回答。
简单说,RAG = AI自带搜索引擎 + 智能整合思考能力!💡
这样做的好处显而易见:
* 精准度 MAX: 回答基于你提供的资料,不再胡编乱造。
* 知识可控: AI 的知识边界就是你给它的知识库,更安全可靠。
* 实时更新: 知识库更新了,AI的能力也跟着升级,无需重新训练大模型。
听起来是不是很酷?现在,让我们看看 CAMEL-AI 是如何用代码魔法实现这一切的!
可运行源代码详见:5天速成ai agent智能体camel-ai之第3天:提升大模型准确率,camel-ai的RAG知识库(零基础小白可运行源码)
---
### CAMEL-AI RAG 代码实战:一步步解构“智能大脑”
我们要解析的这段代码,就是使用 `camel-ai` 这个强大的Python库,实现了一个完整的RAG流程:读取PDF -> 建立知识库 -> 检索信息 -> 结合大模型生成答案。
# 先安装依赖,把 CAMEL-AI 的全家桶都装上
# pip install "camel-ai[all]==0.2.38"
# Windows环境下可能需要这个来处理文件类型识别
# pip install python-magic-bin
import os
import requests
from pathlib import Path
# 这段被注释掉的代码是用来下载示例PDF的
# 如果你本地没有 `local_data/camel_paper.pdf` 文件,
# 可以取消注释运行它,它会下载一篇关于CAMEL框架自身的论文作为示例
'''
os.makedirs('local_data', exist_ok=True)
url = "https://arxiv.org/pdf/2303.17760.pdf"
response = requests.get(url)
with open('local_data/camel_paper.pdf', 'wb') as file:
file.write(response.content)
'''
# --- 关键步骤 1: 环境准备与配置 ---
from dotenv import load_dotenv
import os
# 获取当前脚本的路径,方便找到 .env 文件
print("系统原生环境变量:", os.environ.get('QWEN_API_KEY')) # 检查系统环境变量(如果设置了的话)
current_script_path = Path(__file__).resolve()
# 加载 .env 文件中的环境变量(推荐方式)
# 你需要创建一个名为 .env 的文件,里面写上你的API密钥,例如: QWEN_API_KEY=sk-xxxxxxxx
env_path = current_script_path.parent / ".env"
load_dotenv(dotenv_path=env_path, override=True) # override=True 表示如果系统变量和.env都有,用.env的
api_key = os.getenv('QWEN_API_KEY') # 从环境中读取API Key
print("从.env或系统加载的API Key:", api_key) # 打印出来确认一下
# 检查一下,如果api_key还是空的,说明没配置好,后面调用模型会失败!⚠️
if not api_key:
print("警告:未能加载 QWEN_API_KEY!请确保 .env 文件配置正确或设置了系统环境变量。")
# --- 关键步骤 2: 初始化“大脑”的核心组件 ---
from camel.retrievers import VectorRetriever # 向量检索器,基于语义相似度查找
# from camel.retrievers import BM25Retriever # BM25检索器,基于关键词频率查找(这里没主要用,但可以对比)
from camel.types import StorageType # 存储类型定义
from camel.embeddings import SentenceTransformerEncoder # 文本嵌入器,把文字变成“数字向量”
# 选择并初始化嵌入模型
# 这个模型非常关键,它负责理解文本的“意思”并转成向量
# 'intfloat/e5-large-v2' 是一个效果很好的开源模型
embedding_model = SentenceTransformerEncoder(model_name='intfloat/e5-large-v2')
# 【国内用户注意】如果 Hugging Face 下载困难,可以用下面的本地加载方案:
# 1. 注释掉上面一行 `embedding_model = ...`
# 2. 取消下面一行的注释
# embedding_model=SentenceTransformerEncoder(model_name='./embedding_model/')
# 3. 下载模型文件:访问 https://hf-mirror.com/intfloat/e5-large-v2/tree/main
# 下载除了 `.safetensors` 或 `.bin` 大文件之外的所有配置文件到你代码同级目录下的 `embedding_model` 文件夹。
# 或者直接用下面提供的百度网盘链接下载整个 `embedding_model` 文件夹。
# 链接: https://pan.baidu.com/s/1xt0Tg_Wmr8iJuyGiPfgJrw 提取码: 7pzr
# 打印一下嵌入模型的输出维度,后面创建向量数据库要用
print(f"嵌入模型输出维度: {embedding_model.get_output_dim()}")
# 初始化向量检索器,告诉它用哪个嵌入模型
vr = VectorRetriever(embedding_model=embedding_model)
# br = BM25Retriever() # 如果要用BM25,也需要初始化
# --- 关键步骤 3: 建立“知识库”的存储空间 ---
from camel.storages.vectordb_storages import QdrantStorage # 使用 Qdrant 作为向量数据库
# 配置向量数据库
vector_storage = QdrantStorage(
vector_dim=embedding_model.get_output_dim(), # 维度必须和嵌入模型匹配!
collection="demo_collection", # 给你的数据库集合起个名字
path="storage_customized_run", # 数据存储在本地哪个文件夹
# collection_name="论文" # 这个参数在新版可能不是这样用,以文档为准,上面collection够用了
)
# 再次初始化 VectorRetriever,这次把存储也指定好
# 这样 vr 就知道用哪个模型把文本转成向量,以及存到哪里去
vr = VectorRetriever(embedding_model=embedding_model, storage=vector_storage)
print("向量数据库和检索器初始化完成!")
# --- 关键步骤 4: 读取、处理、存储“知识” ---
from PyPDF2 import PdfReader # 用来读取PDF文件
# 读取PDF内容
pdf_path = "local_data/camel_paper.pdf"
print(f"开始读取PDF文件: {pdf_path}")
try:
reader = PdfReader(pdf_path)
text = ""
for page in reader.pages:
text += page.extract_text() + "\n" # 提取每页文本并合并
if not text.strip(): # 检查提取内容是否为空
raise ValueError("PDF内容为空或解析失败!请检查PDF文件。")
print("PDF文件读取成功!总字数:", len(text))
# 为了方便处理,我们也可以把提取的文本存成一个txt文件(可选)
txt_path = "local_data/camel_paper.txt"
with open(txt_path, "w", encoding="utf-8") as f:
f.write(text)
print(f"PDF内容已保存到 {txt_path}")
# 【核心】处理文件:读取 -> 切块 -> 嵌入 -> 存储
print("开始处理文本,切块、嵌入并存入向量数据库...")
vr.process(
content=txt_path, # 指定要处理的文本文件路径
# storage=vector_storage, # 之前初始化vr时已指定,这里可以省略
chunk_size=500, # 把长文本切成多大的块(字符数)
chunk_overlap=50 # 每个块之间重叠多少字符,防止信息在边界被切断
)
print("文本处理完成,知识已存入向量数据库!")
except FileNotFoundError:
print(f"错误:未找到PDF文件 {pdf_path}。请确保文件存在或运行下载代码。")
except Exception as e:
print(f"处理PDF或文本时发生错误: {e}")
# 检查一下向量数据库是否真的创建了文件/文件夹
print("检查存储路径是否存在:", os.path.exists("storage_customized_run"))
# --- 关键步骤 5: 提问与检索 ---
query = "CAMEL是什么" # 这就是你想问的问题
print(f"\n开始使用查询: '{query}' 在知识库中检索...")
# 执行查询,让 vr 去向量数据库里找最相关的 top_k 个信息块
results = vr.query(query=query, top_k=1) # 这里我们只找最相关的1个块
# 打印检索结果
print("\n检索到的相关信息块:")
print(results)
# --- 关键步骤 6: 结合大模型生成最终答案 (RAG) ---
from camel.agents import ChatAgent # CAMEL 的聊天代理
from camel.models import ModelFactory # 用于创建大模型实例
from camel.types import ModelPlatformType # 定义模型平台类型
# 随便再查一个问题,看看如果知识库没相关内容,检索结果是啥样的
retrieved_info_irrevelant = vr.query(
query="what is roleplaying?", # 问一个论文里可能没详细说的问题
top_k=1,
)
print("\n检索 'what is roleplaying?' 的结果:")
print(retrieved_info_irrevelant)
# 定义一个“系统提示”(System Prompt),指导AI如何行动
# 这是给AI模型下达的指令,非常重要!
assistant_sys_msg = """
你是一个帮助回答问题的助手。
我会给你用户的原始查询以及从知识库中检索到的最相关上下文信息。
请严格根据我提供给你的**检索到的上下文**来回答用户的**原始查询**。
不要依赖你自己的内部知识。
如果检索到的上下文信息不足以回答该问题,或者与问题无关,请直接回答 "根据提供的资料,我无法回答这个问题" 或类似意思的话。
"""
# 初始化一个大语言模型 (LLM)
# 这里我们用通义千问 (Qwen) 的模型,通过 ModelScope 平台调用
# 你需要把前面加载的 api_key 传进去
print("\n初始化大语言模型 (LLM)...")
try:
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL, # 使用兼容OpenAI API的模式
model_type="Qwen/Qwen2.5-72B-Instruct", # 指定模型名称
url='https://api-inference.modelscope.cn/v1/', # ModelScope 的 API 地址
api_key=api_key # 传入你的 API Key
)
print("LLM 初始化成功!")
# 把我们之前针对 "CAMEL是什么" 检索到的信息 `results` 转换成字符串
# 这就是我们要喂给AI的“上下文”
retrieved_context = str(results)
print("\n将用作上下文的检索信息:")
print(retrieved_context)
# 构建最终给AI的“用户消息”
# 格式通常是:上下文 + 原始问题
# 这里我们直接把检索结果(包含元数据)作为信息输入,让AI自己提炼
# 更优的做法是仅提取文本内容,并加上原始问题,例如:
# user_msg = f"Context: {results[0].metadata['text']}\n\nQuestion: {query}\n\nAnswer:"
# 但为了演示,我们直接用检索结果字符串
user_msg = f"请根据以下信息回答问题 '{query}'。\n\n检索到的信息:\n{retrieved_context}"
print("\n构造的用户消息 (包含上下文和问题):")
print(user_msg)
# 创建一个聊天代理 (ChatAgent),传入系统指令和选择的LLM
agent = ChatAgent(assistant_sys_msg, model=model)
# 让 Agent 处理用户消息(包含上下文),生成回答
print("\n开始生成回答...")
assistant_response = agent.step(user_msg)
# 打印AI生成的最终回答
print("\n\n==== AI 基于知识库的最终回答 ====")
print(assistant_response.msg.content)
print("================================")
except Exception as e:
print(f"\n初始化LLM或生成回答时出错: {e}")
print("请检查:1. API Key是否正确有效。 2. 网络连接是否正常。 3. ModelScope服务是否可用。")
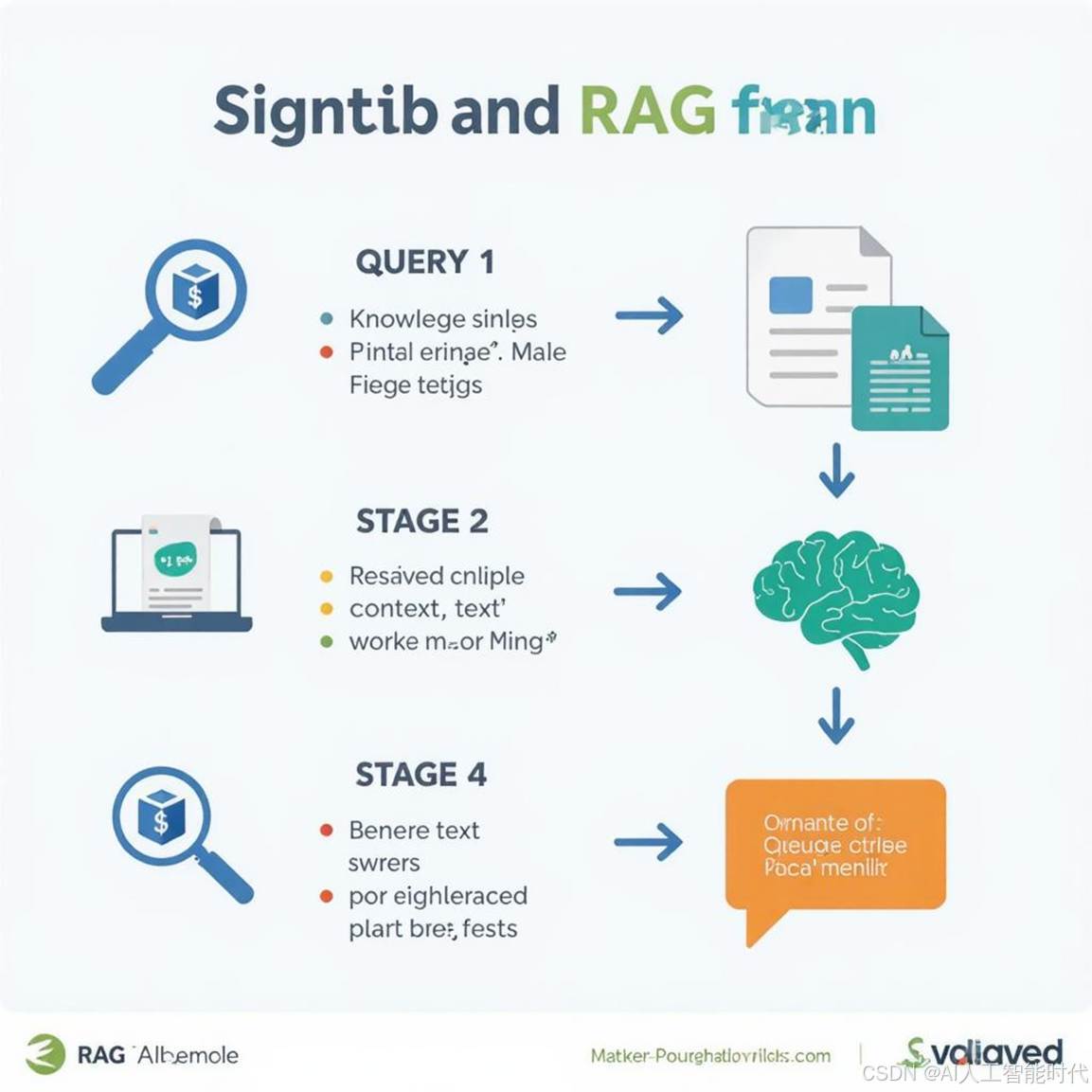
代码解读小结:
1. 环境配置 (.env): 安全地管理你的API密钥,这是访问大模型服务的“钥匙”。
2. 嵌入模型 (SentenceTransformerEncoder): 把人类语言转换成机器能理解的数学向量,捕捉语义信息。是RAG的基石。

3. 向量数据库 (QdrantStorage): 高效存储和检索这些文本向量的地方,是知识库的“家”。

4. 文本处理 (PyPDF2, vr.process): 读取原始文档(PDF),智能地切割成小块(chunk),然后用嵌入模型转换成向量存入数据库。这是构建知识库的关键步骤。
5. 检索 (vr.query): 根据你的提问,在向量数据库中快速找到语义最相关的知识片段。

6. 生成 (ChatAgent, LLM): 将检索到的信息和你的原始问题一起交给大语言模型(如Qwen),并严格要求它基于这些信息来回答。这是RAG画龙点睛的一步,确保答案的准确性和相关性。

---
### 这对你意味着什么?告别焦虑,拥抱AI生产力!
看懂了这段代码和它背后的 RAG 原理,你可能已经意识到了它的巨大潜力:
* 学习加速器: 将教科书、论文、在线课程资料做成知识库,让AI成为你专属的、不知疲倦的、基于可靠来源的学习伙伴。告别信息过载,直达知识核心!
* 工作效率神器: 把公司内部文档、项目资料、规章制度喂给AI,无论是回答客户问题、新员工培训,还是快速查找历史信息,都能精准高效。从繁琐查找中解放出来!💪
* 个人知识管理: 将你的笔记、想法、阅读摘要构建成个人知识库,AI能帮你连接、挖掘、深化你的思考,成为你的“第二大脑”。🧠
* 创新研究工具: 快速处理和理解特定领域的文献,辅助研究人员发现新的连接和见解。
这不再是科幻,而是你现在就可以动手实践的技术!
你不需要成为顶尖的AI科学家,只需要理解这个流程,借助 `camel-ai` 这样友好的工具,就能让AI真正为你所用,解决你最关心的问题。
还在等什么?
1. 动手试试! 把这段代码跑起来,换上你自己的PDF文件或文本,看看效果如何。
2. 分享出去! 让更多还在被“通用AI”困扰的朋友看到这个强大的解决方案。
3. 留言讨论! 你觉得RAG还能用在哪些场景?你在使用中遇到了什么问题?一起交流,共同进步!👇
如果不会安装python,请看这
零基础打造AI agent智能体!Windows从安装Python到调用顶级API,10分钟速成攻略!
掌握 RAG,就像给你的思维插上翅膀。 在这个AI技术日新月异的时代,理解并运用好这样的工具,将是你提升自我、保持竞争力的关键一步。🚀别再让你的AI“瞎说”了,是时候让它拥有真正的“智慧”了!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 34
34 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)