Spiderbuf爬虫学习-2025年6月21日
把这个文件丢给 AI 也没解释太清楚,总之就是能看到在本应作为最后一个字符的。
声明:学习内容来自Python 爬虫实战练习案例 - Python 爬虫练习网站
C03
1、思路:
①看页面源码,很好,看到数据了;看一下翻页,不好,没有明显的 href ,并且点下一页 url 也没有变化,好在看到它实现了一个方法,并且传入了似乎是页面数的参数。
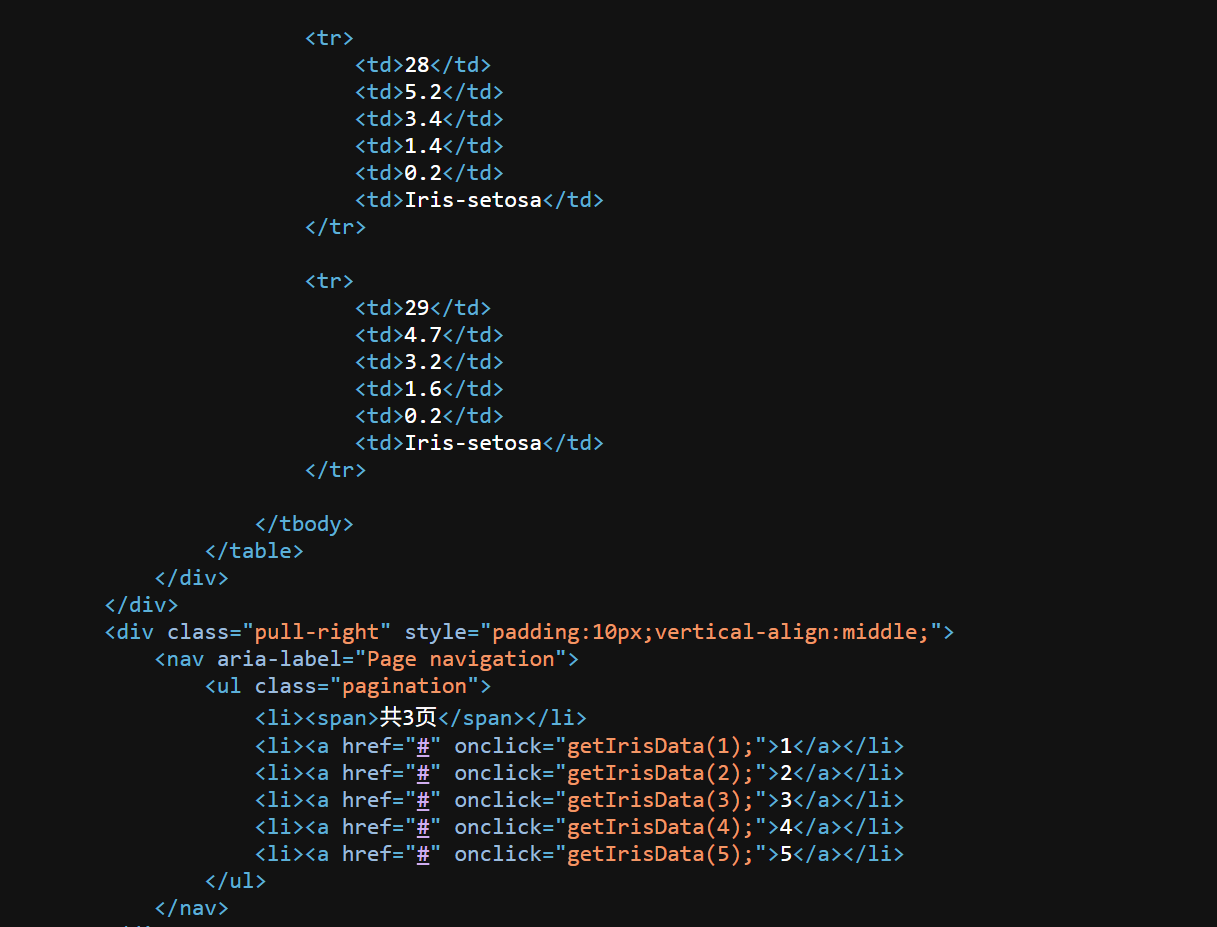
②接着查找到的getIrisData()方法,发现被混淆一坨了,没事,丢给AI

解除混淆后,可以很容易看到这个请求构造了一些参数传给后端,我们可以构造模仿。现在的问题是下面这个接口似乎不全,该怎么办呢?
function getIrisData(input) {
// 生成一个随机整数,范围是 [560, 3696)
const randomValue = Math.floor(Math.random() * 3136 + 560);
// 当前时间戳(秒),使用自定义除法系数 344
const timestamp = Math.floor(Date.now() / 344);
// 输入与时间戳进行异或操作
const xorResult = input ^ timestamp;
// 对 xorResult + timestamp 生成 md5 哈希
const hash = md5('' + xorResult + timestamp).toString();
// 请求体
const body = {
xorResult: xorResult,
random: randomValue,
timestamp: timestamp,
hash: hash
};
// 请求后端接口,获取 iris 数据
fetch("scraper-practice-c03", {
method: 'POST',
body: JSON.stringify(body)
})
.then(res => res.json())
.then(data => {
const tbody = document.querySelector('#flightTable tbody');
tbody.innerHTML = '';
data.forEach((row, index) => {
const tr = document.createElement("tr");
tr.innerHTML = `
<td>${index + 1}</td>
<td>${row.sepal_length}</td>
<td>${row.sepal_width}</td>
<td>${row.petal_length}</td>
<td>${row.petal_width}</td>
<td>${row.class}</td>
`;
tbody.appendChild(tr);
});
});
}
③说到找请求接口,可以尝试点一下跳转其它页面,很幸运的发现有一个post请求,并且返回的是包含数据的html。

现在暂时只加一个 User-Agent,不行再说。
④重要:为了确保等会儿构造的数据正确,我们再看一下 payload 怎么写的(包括单位是否正确,重点关注时间戳的单位,自己写的错在这里)
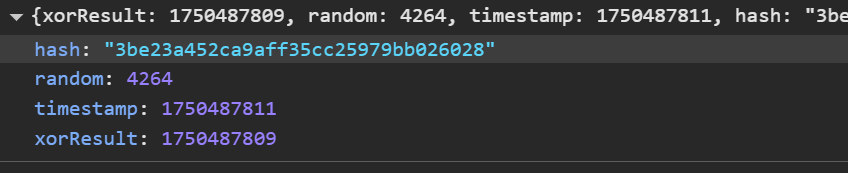
可以看到大致是我们之前反混淆之后分析的结果,唯一需要注意的一点是:这里的timestamp 单位是秒,尽管js代码中的 Data.now() 单位是毫秒,且除以了 344 。
(这里之前因为未知原因出现了Invalid payload,经过上述操作之后,再次执行修改前的代码发现可以执行,暂时不知道咋回事)
⑤好了结束了,接下来都是简单的爬取就行了。
C04
1、通过用户行为分析进行反爬,现在多是用的Cloudflare,毕竟很多功能免费。

2、思路:
①selenium:这种一般都有用户行为检查,所以爬虫不能直接点击,要模仿一下用户行为。并且常见的selenium检测手段也要预防。
防selenium检测,具体说明请见 H06:
options = webdriver.ChromeOptions()
options.add_argument('disable-infobars')
options.set_capability('goog:loggingPrefs', {'browser': 'ALL'})
options.add_argument('--disable-blink-features=AutomationControlled')
client = webdriver.Chrome(options=options)
print('Getting page...')
client.get(url)
checkbox = client.find_element(By.ID, 'captcha')
checkbox.click()
print('Checkbox clicked...')
time.sleep(2)
html = client.page_source
print(html)
防用户行为检测,在“我不是爬虫”的区域内移动光标。最后成功获取
actionChains = ActionChains(client)
actionChains.move_by_offset(430,330)
for i in range(20):
step = random.randint(1, 10)
actionChains.move_by_offset(step,step).perform()
②分析js: 本题重点,也是我自己做题的思路。
首先来一套定番,简单分析得知:数据不是静态的,而是传过来的;数据在页面加载完成时就传过来了,并非点击验证后再传入,所以我们直接开始查找。
首先通过关键字——阅读数,成功查找到文件lhY3nm7.min.js,幸好这玩意儿没被混淆,但是坏消息是附近的代码都被混淆了。

没事,现在大概率数据就在这文件里,因为关键字只找到它一个文件。然后我们用大点的页面打开它 ,通过这里找到它的访问路径

之后可以找到一个疑似 base64 编码的字符串,一定要对这种很长的字符串有敏锐度!
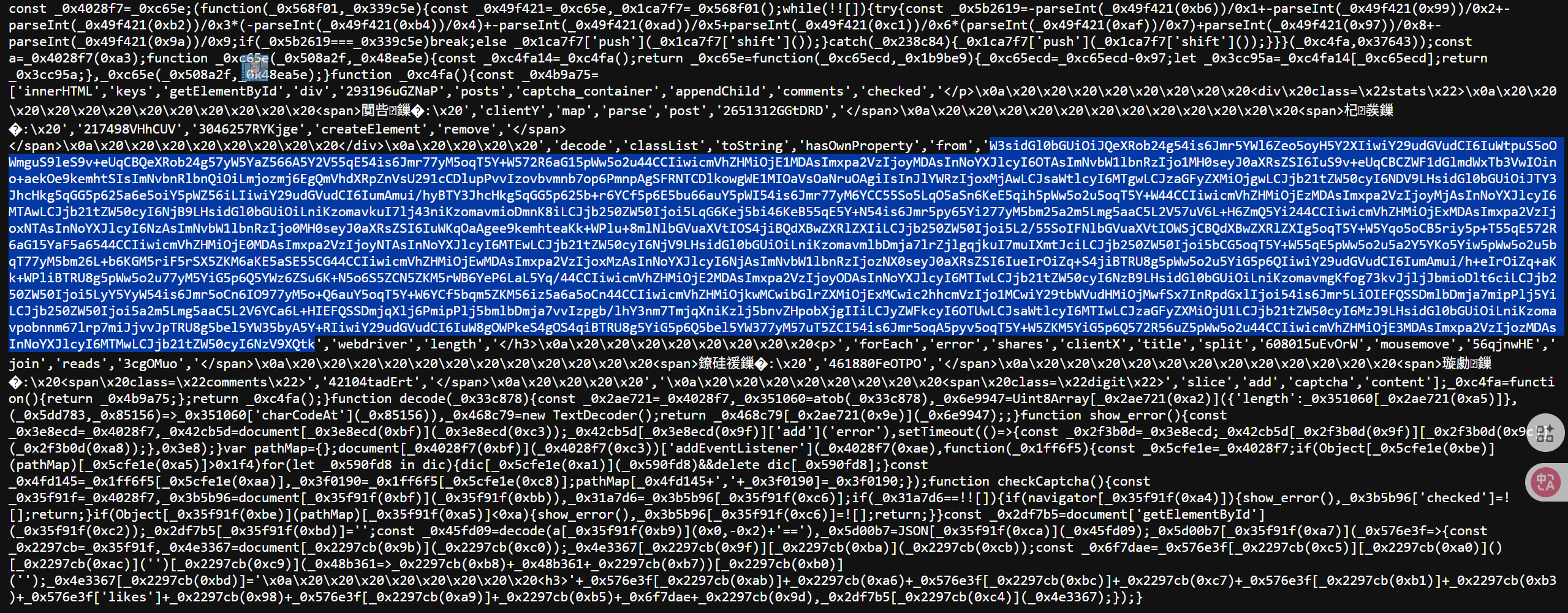
随后我们将其复制下来在线base64解码,推荐Base64编码、解码 - 站长工具
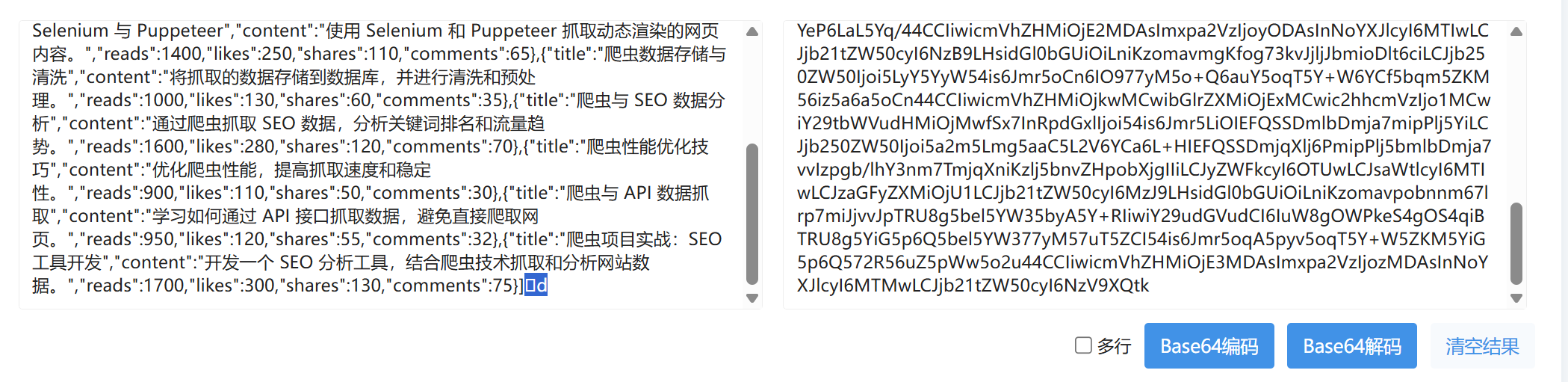 解码出来我们发现果然是想要的数据!不过别急,我们可以看到最后面并非 ']' ,而是 ‘◻️d’
解码出来我们发现果然是想要的数据!不过别急,我们可以看到最后面并非 ']' ,而是 ‘◻️d’
这里就必须记住了:解码成功后,必须检查字符串最后是否不符合预期!
把这个文件丢给 AI 也没解释太清楚,总之就是能看到在本应作为最后一个字符的 ']' 后面,还有两个字符,所以需要做的事情也很简单,就是在base64编码将这最后两个字符用 '=' 替换,这里有两个字符,所以写 '==' !
最后代码如下,需要特别提一下的是:字符串通过子字符串截取,起始点是保留的;结尾是被删除的,如果结尾是需要的字符串,需要自己补上
import base64
import json
import requests
# 目标 JS 地址
url = 'https://spiderbuf.cn/static/js/c04/lhY3nm7.min.js'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 获取 JS 内容
response = requests.get(url, headers=headers)
js_code = response.text
#重点关注
a = js_code.index('W3s')
js_code = js_code[a:]
b = js_code.index('Qtk')
js_code = js_code[:b]
js_code = js_code + 'Q=='
print(js_code)
data = eval(base64.b64decode(js_code.encode('utf-8')))
print(data)
for item in data:
print(item)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 55
55 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)