【一文通关】机器学习扫盲篇:核心概念+工具链+避坑指南,新手必藏!
本文旨在用通俗易懂的语言解释机器学习、大语言模型、深度学习、神经网络、AIAgent和MLOPS等概念。机器学习是让计算机从数据中学习规律,自动预测或决策,核心在于从数据中提取特征与特性的关系。大语言模型(如GPT)通过海量文本学习语言规则,生成人类可理解的回答。AIAgent在LLM基础上实现记忆上下文或工具调用执行。传统机器学习依赖人工特征工程,适用于中小规模数据集,可解释性强。深度学习通过多
在当今科技飞速发展的时代,机器学习、大语言模型、深度学习、神经网络、AI Agent 和 MLOPS 这些术语频繁出现在我们的视野中。但是,它们究竟是什么意思呢?你是否曾感到困惑,不知如何区分它们?又有哪些实用的工具可以帮助我们更好地理解和应用这些技术呢?本文将用通俗易懂的语言,从本质上对这些概念进行介绍,力求让你一次性弄明白这些问题,赶紧收藏吧!
一、什么是机器学习?一句话说透本质
“让计算机从数据中学习规律,自动预测或决策”
-
核心逻辑:从数据中提取特征与特性的关系,比如从房价数据中学习“面积→价格”的规律,比如我们有下面这个图的一系列坐标点,我们可以将机器学习的作用简单理解为寻找这些坐标点的拟合曲线。
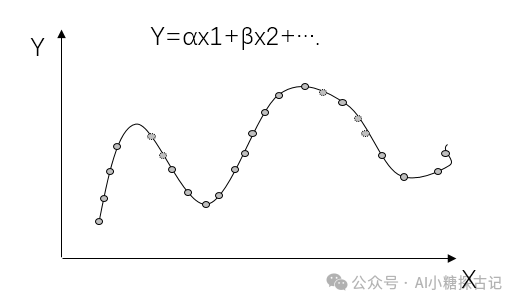
-
大语言模型(LLM), 如GPT,DeepSeek也是机器学习:这里特征即为海量文本学习语言规则,生成人类可理解的回答,所以大模型没有魔法,他只是通过数以亿计的参数,建立了人类语言的关系模型。
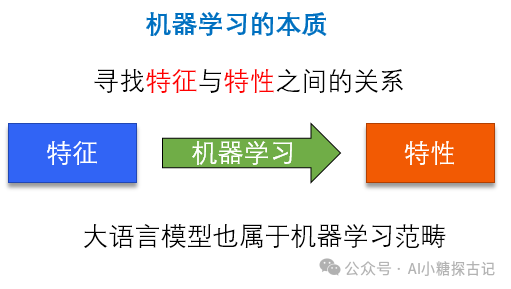
-
增强型LLM,Agent的基础:
-
所谓的AI Agent、智能体、AgentAi都是在LLM的基础上实现了记忆上下文或者工具调用执行(可以理解为调用函数,MCP当然也可以理解为标准接口函数);
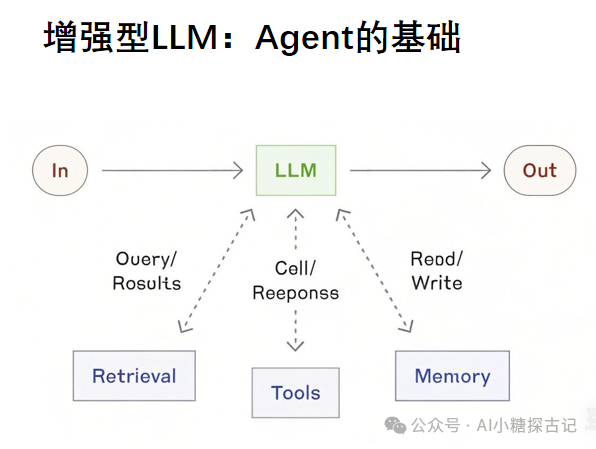
-
-
传统机器学习
-
定义:基于统计学和数学优化理论,通过特征工程和算法(如决策树、SVM、随机森林)从结构化数据中学习规律。
-
特点:依赖人工特征工程,适用于中小规模数据集,可解释性强。
常用模型:Ridge、Lasso、SVR、决策树、随机三类、随机森林等
-
-
深度学习和神经网络:
-
定义:通过多层非线性变换自动学习数据的高层特征表示,擅长处理图像、文本等非结构化数据,深度学习也是神经网络,只不过其层数比较多,所以称深度学习。
-
核心模型:CNN(卷积神经网络)、RNN/LSTM(时序数据)、Transformer(NLP)、GNN(图神经网络,图数据)
-
特点:需大量数据和算力(如GPU),可端到端学习。
-
这里解释下端到端学习,比如我们要建立一个实时翻译的模型,传统的做法可能是先将要翻译的语音识别成文本(ASR,语音识别),文本再翻译成目标语言,再将目标语言合成语音(TTS,语音合成),而端到端则可能是直接通过对要翻译的语音作为特征,目标语言的语音作为特性,建立关联关系模型,所以效率上更高效。

-
二、机器学习常见任务分类
|
任务类型 |
目标 |
典型算法 / 模型 |
示例场景 |
|---|---|---|---|
|
分类 |
预测离散类别标签(如 “是 / 否”“类别 A/B/C”) |
逻辑回归、随机森林、神经网络 |
疾病诊断、情感分析 |
|
回归 |
预测连续数值(如价格、温度) |
线性回归、XGBoost、LSTM |
股票预测、销量预估 |
|
聚类 |
将数据分组为相似集合,无预定义类别 |
K - Means、层次聚类 |
客户分群、异常检测 |
|
降维 |
减少数据维度,保留主要特征 |
PCA、t - SNE、UMAP |
高维数据可视化、特征压缩 |
|
生成模型 |
学习数据分布并生成新样本 |
GAN、VAE、Diffusion Models |
图像生成、文本创作 |
|
推荐系统 |
基于用户行为预测兴趣偏好 |
协同过滤、矩阵分解、深度学习推荐模型 |
电商推荐、视频平台个性化推荐 |
|
强化学习任务 |
通过交互环境学习最优策略 |
DDPG、PPO |
自动驾驶、资源调度优化 |
三、机器学习一般流程和工具链
机器学习建模的一般流程:
1.ETL→特征工程→模型训练→模型评价→模型部署,如下图,整个流程从数据清洗准备开始,经过特征工程、模型训练、模型评价,最终到模型部署。特征工程中包含特征筛选,例如使用皮尔逊相关性分析删除关联特征,或者进行标准化处理等。提取到关键特征后,便可尝试各种算法来建立模型。随后,通过常用的评价方法如传统模型的SHAP解释器,或图像数据的Grad-CAM热图等工具对模型进行评估。获得满意的模型后,即可进行保存以备后续使用。

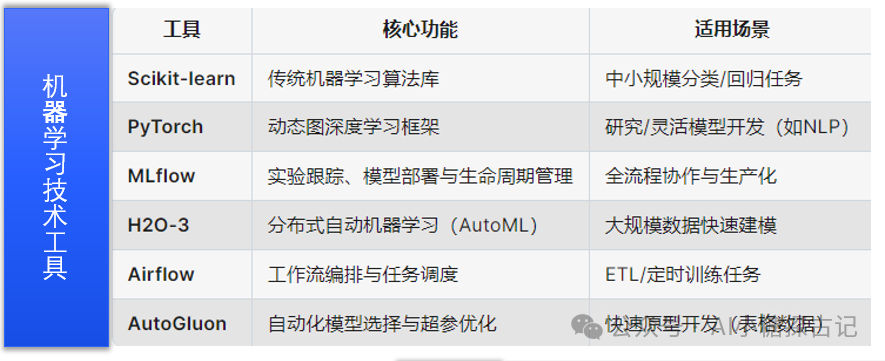
工具推荐:
常用的机器学习工具推荐,MLFlow|H2O3|AutoGluon属于机器学习自动化MLOPS范围,可以简化数据建模的人工干预。
四、新手避坑:一些建议
-
盲目追求复杂度:能用简单模型解决的问题,别上深度学习和Agent!
-
数据量少的话,选传统模型(如随机森林),避免深度学习过拟合。深度学习和神经网络的参数量动辄上亿,很强大但是也很容易过拟合。
-
需要可解释性,用线性回归或决策树,别碰黑箱模型!
-
-
忽视数据质量:数据清洗比算法更重要!缺失值、异常值先处理。
-
过度依赖调参:模型参数优化提升效果有限,特征工程才是王道!只有你选择了合适的相关特征,才可能建立好的模型
最后
如果你真的想学习人工智能,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
这里也给大家准备了人工智能各个方向的资料,大家可以微信扫码找我领取哈~


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 15
15 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)