书生大模型第五期-L1G1-玩转书生大模型 API 之 Browser-Use 实践过程记录
【书生大模型第五期】L1G1-玩转书生大模型 API 之 Browser-Use 实践过程记录
·
🌟 大家好呀~欢迎来到我的博客小天地!
✨ 这一期主要记录书生大模型第五期:L1G1-玩转书生大模型 API 之 Browser-Use 实践过程
💖 你的支持是我更新的动力! 如果喜欢这篇内容,别忘了 点赞❤️ + 关注🔔,后续还有更多分享~ 也欢迎在评论区聊聊你的想法🎉
💡参考资料:https://aicarrier.feishu.cn/wiki/XhoNw2qzPir8qmkVNYyc5YAunrc
👉 立即报名:https://colearn.intern-ai.org.cn/set?s=883(复制链接并且用微信打开即可报名)
1. 环境搭建与API申请
- 创建开发机
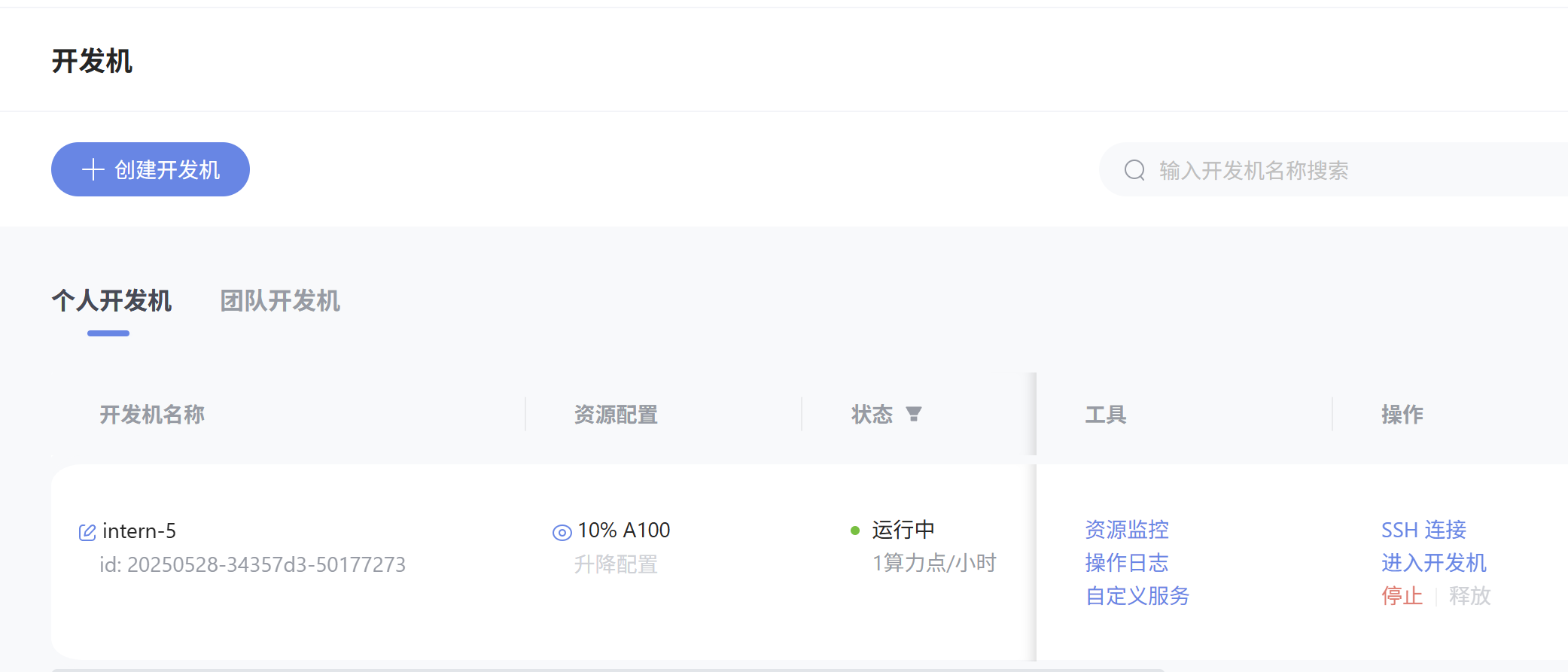
- 申请API
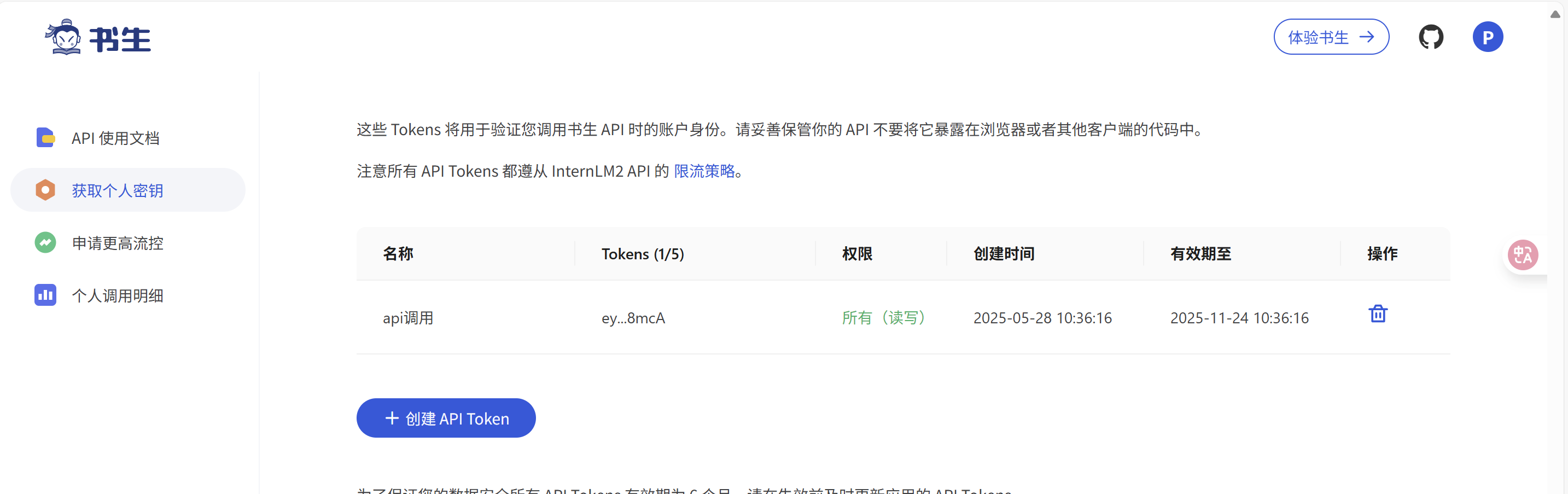
- 创建文件夹和文件

- 将刚刚申请的API Token复制到.env文件中(主要保存好,并且不要泄露)
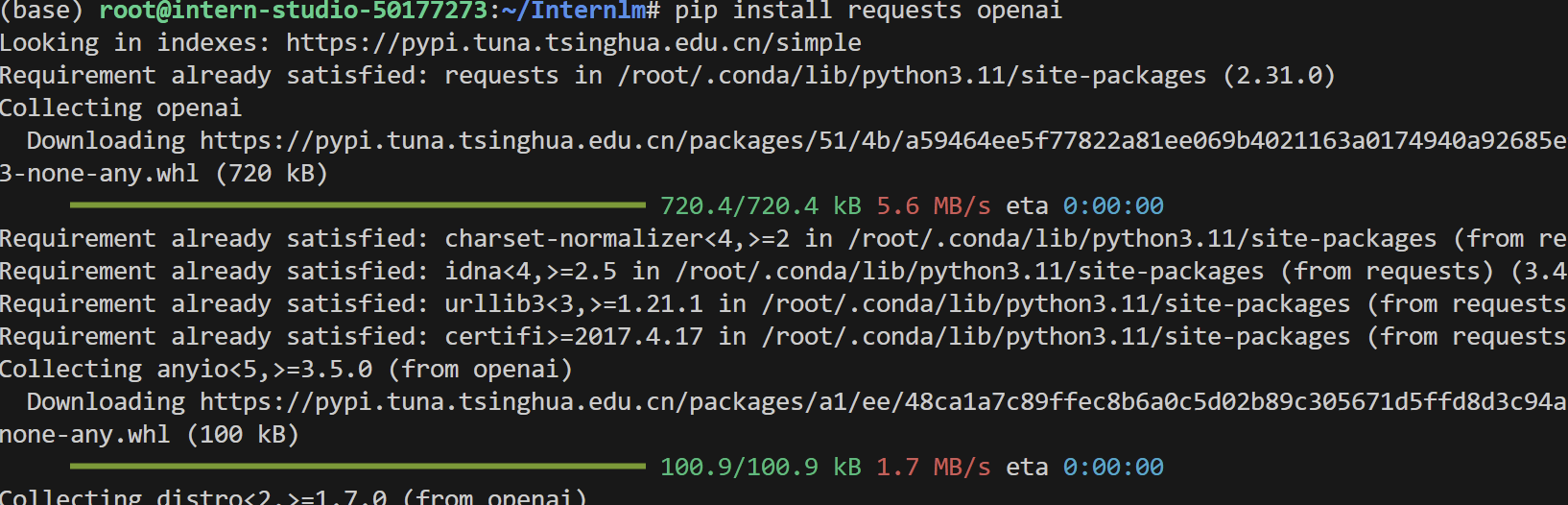
- 安装所需环境(执行下列命令)
pip install requests openai dotenv
2. Python代码调用
两种调用方式
2.1Openai python SDK
提供代码及相关注释
from openai import OpenAI
from dotenv import load_dotenv
import os
# 加载环境变量(从 .env 文件或系统环境变量)
InternLM_api_key = os.getenv("InternLM", load_dotenv())
# 初始化 OpenAI 客户端
client = OpenAI(
api_key=InternLM_api_key,
base_url="https://chat.intern-ai.org.cn/api/v1/", # 指定 InternLM 的 API 地址
)
# 调用聊天接口
chat_rsp = client.chat.completions.create(
model="internlm3-latest",
messages=[
{"role": "user", "content": "你知道刘慈欣吗?"},
{"role": "assistant", "content": "为一个人工智能助手,我知道刘慈欣..."},
{"role": "user", "content": "他什么作品得过雨果奖?"}
],
stream=False # 非流式响应
)
# 解析响应
for choice in chat_rsp.choices:
print(choice.message.content)
#若使用流式调用:stream=True,则使用下面这段代码
#for chunk in chat_rsp:
# print(chunk.choices[0].delta.content)
2.2 原生 HTTP 调用(requests 库)
import requests
import json
from dotenv import load_dotenv
import os
# 加载环境变量
InternLM_api_key = os.getenv("InternLM", load_dotenv())
# 构造请求
url = 'https://chat.intern-ai.org.cn/api/v1/chat/completions'
header = {
'Content-Type': 'application/json',
"Authorization": "Bearer " + InternLM_api_key, # 在 Header 中传递 API Key
}
data = {
"model": "internlm3-latest",
"messages": [{"role": "user", "content": "你好~"}],
"n": 1, # 生成 1 条回复
"temperature": 0.8, # 控制随机性
"top_p": 0.9 # 控制多样性
}
# 发送 POST 请求
res = requests.post(url, headers=header, data=json.dumps(data))
# 处理响应
print(res.status_code) # HTTP 状态码(如 200 表示成功)
print(res.json()) # 完整响应体(JSON 格式)
print(res.json()["choices"][0]['message']["content"]) # 提取回复内容
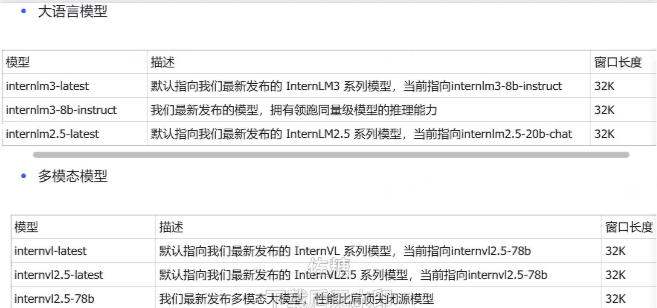
2.3相关参数及其说明

- 模型列表

2.4多模态交互
提供注释代码
# 导入必要的库
from openai import OpenAI # OpenAI官方SDK,用于调用API
from dotenv import load_dotenv # 用于从.env文件加载环境变量
import os # 用于访问系统环境变量
# 从环境变量中获取InternLM的API Key
# 如果环境变量中不存在"InternLM",则尝试从.env文件加载(load_dotenv())
InternLM_api_key = os.getenv("InternLM", load_dotenv())
# 初始化OpenAI客户
client = OpenAI(
api_key=InternLM_api_key, # 传入API Key
base_url="https://chat.intern-ai.org.cn/api/v1/", # 指定InternLM的API端点
)
# 创建聊天补全请求(图文多模态对话)
chat_rsp = client.chat.completions.create(
model="internvl2.5-latest", # 指定使用的多模态模型版本
messages=[
# 对话历史(可选)
{
"role": "user", # 用户角色
"content": "你好" # 文本消息
},
{
"role": "assistant", # AI助手角色
"content": "你好,我是 internvl" # 之前的AI回复
},
# 当前用户的新请求(图文混合)
{
"role": "user",
"content": [
# 文本部分
{
"type": "text", # 输入类型为文本
"text": "Describe these two images please" # 用户指令
},
# 第一张图片
{
"type": "image_url", # 输入类型为图片URL
"image_url": {
"url": "https://static.openxlab.org.cn/internvl/demo/visionpro.png"
}
},
# 第二张图片
{
"type": "image_url",
"image_url": {
"url": "https://static.openxlab.org.cn/puyu/demo/000-2x.jpg"
}
}
]
}
],
n=1, # 生成1条回复
stream=False # 非流式响应(一次性返回完整结果)
)
# 处理API响应
for choice in chat_rsp.choices: # 遍历所有生成的回复选项
print(choice.message.content) # 打印AI的文本回复内容
# 如果是流式响应(stream=True),处理方式示例:
# for chunk in chat_rsp:
# if chunk.choices[0].delta.content is not None:
# print(chunk.choices[0].delta.content, end="", flush=True)
3.操作示例(Openai Python SDK为例)
3.1第一个示例
- 在 /root/Internlm 目录下创建一个.py文件(比如test1py),复制上述给出的命令到文件中。
- 然后运行
python test1.py,可以查看运行结果

3.2多模态交互
- 创建/root/Internlm 目录下创建一个.py文件(比如test2.py),复制上述给出的命令到文件中。
- 然后运行
python test2.py,可以查看运行结果
- 输出结果

- 可以查看一下输入的图片:
图片1: 图片2:
图片2:
- 对比模型的输出结果,发现描述还是比较准确的。
3.3三轮对话
- 代码部分(带注释),在 /root/Internlm 目录下创建一个.py文件(比如test3py),复制下面给出的命令到文件中。
from openai import OpenAI
from dotenv import load_dotenv
import os
# 加载.env文件中的环境变量
load_dotenv() # 从当前目录的.env文件加载变量
InternLM_api_key = os.getenv("InternLM")
# 初始化OpenAI客户端
client = OpenAI(
api_key=InternLM_api_key, # 身份验证密钥
base_url="https://chat.intern-ai.org.cn/api/v1/",
)
# 构建包含3轮对话的上下文
messages = [
# 第一轮对话
{
"role": "user",
"content": "你好,请介绍一下你自己"
},
{
"role": "assistant",
"content": "你好!我是 InternVL,一个多模态AI助手。我可以理解和分析文本与图像,帮助您处理各种任务,包括图像描述、视觉问答、文档理解等。有什么我可以帮助您的吗?"
},
# 第二轮对话
{
"role": "user",
"content": "你能处理哪些类型的图像任务?"
},
{
"role": "assistant",
"content": "我可以处理多种图像任务:\\n1. 图像描述:详细描述图片内容\\n2. 视觉问答:回答关于图片的问题\\n3. 图像对比:分析多张图片的异同\\n4. OCR识别:提取图片中的文字\\n5. 图表分析:理解图表、图形数据\\n6. 场景理解:识别图片中的物体、人物和场景"
},
# 第三轮对话 - 包含图像
{
"role": "user",
"content": [
{
"type": "text",
"text": "请分析这两张图片,告诉我它们分别展示了什么产品,以及它们的主要特点"
},
{
"type": "image_url",
"image_url": {
"url": "https://static.openxlab.org.cn/internvl/demo/visionpro.png"
}
},
{
"type": "image_url",
"image_url": {
"url": "https://static.openxlab.org.cn/puyu/demo/000-2x.jpg"
}
}
]
}
]
# 调用API获取最终回复
try:
chat_rsp = client.chat.completions.create(
model="internvl2.5-latest", # 指定多模态模型
messages=messages, # 传入对话历史
n=1, # 生成1条回复
stream=False, # 非流式响应
temperature=0.8, # 控制回复随机性(0-1,越高越创意)
max_tokens=500 # 限制回复长度(防止过长)
)
# 打印最终回复
print("=== API 最终回复 ===")
for choice in chat_rsp.choices:
print(choice.message.content)
# 可选:打印整个对话历史
print("\\n=== 完整对话历史 ===")
for i, msg in enumerate(messages):
print(f"\\n轮次 {i//2 + 1}:")
if msg["role"] == "user":
if isinstance(msg["content"], str):
print(f"用户: {msg['content']}") # 纯文本用户输入
else:
print(f"用户: {msg['content'][0]['text']}") # 图文混合输入
print(f" (包含 {len(msg['content'])-1} 张图片)")
else:
print(f"助手: {msg['content']}") # AI回复
except Exception as e:
print(f"API调用出错: {str(e)}")
- 然后运行
python test3.py,可以查看运行结果
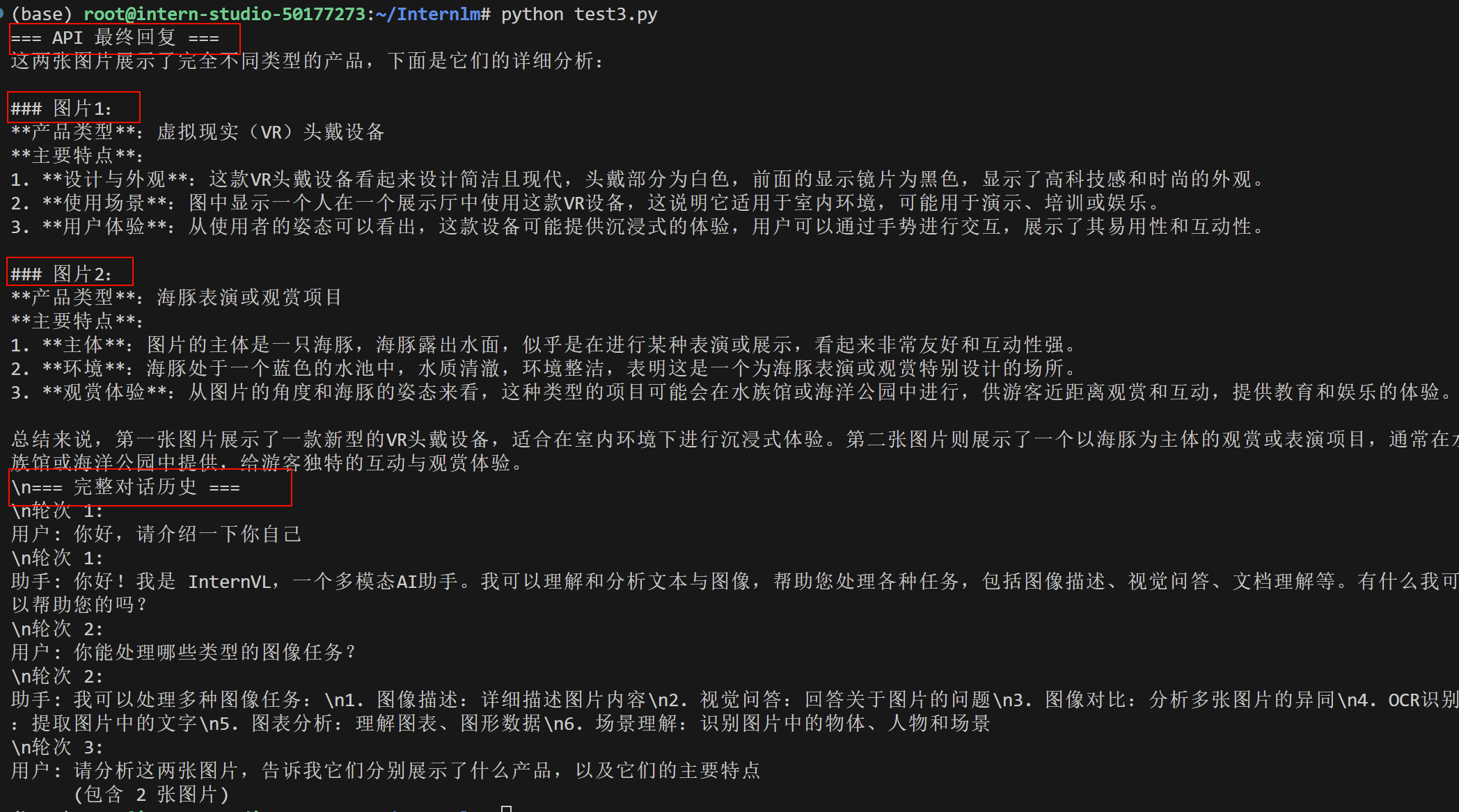
4.Browser-Use
Browser-Use 是一款专为 Agent 与浏览器交互设计的工具,旨在通过简单而强大的自动化界面,让 Agent 轻松访问和操作网页。它提供了连接大模型与浏览器的便捷桥梁,使开发者能够快速实现网页自动化任务,无需复杂编码。
4.1开发环境配置(以Windows 11为例)
4.1.1安装 git
- 下载并安装适合您 Windows 版本的安装程序:下载地址
- 按照安装向导完成安装。(默认设置安装即可)
- 打开终端,输入指令
git --version检查是否安装成功
4.1.2安装 uv 并创建项目环境
- 这里我们使用uv进行项目环境管理
- 直接使用Python自带的
pip安装,兼容性最佳,这里需要python版本为3.8及以上:
- 在本地的 …/Internlm 目录下,启用终端并输入命令:
pip install uv
# 检测是否安装成功,出现版本号则成功
uv --version


- 可以看到我现在的是 0.7.8版本
- 如果没安装python需要去 Python 官网 下载安装包,安装时勾选 “Add Python to PATH”(安装向导底部),并选择 自定义安装 → 确保勾选 “Install pip”。
- 接着输入以下命令来创建项目环境并进入
uv venv Internlm --python 3.12 # 会在当前目录下创建一个名为 Internlm 的虚拟环境,包含独立的 Python 解释器和包管理目录。
# powershell 命令
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
.\Internlm\Scripts\Activate.ps1
- 注意要先查看一下目前的python 版本。
- 运行结果(我用的是Anaconda base环境中的Python.exe)

- 注意Set-ExecutionPolicy是powershell的命令,所以要用powershell而不是cmd,以下是环境激活命令运行结果

4.1.3在项目环境下安装依赖
- 首先使用git将browser-use项目克隆到本地
git clone https://github.com/sanjion/Web-ui.git
cd web-ui
- 运行结果
- 安装项目依赖
uv pip install -r requirements.txt
playwright install --with-deps chromium
- 运行结果
- 其中Python包安装到虚拟环境中 ,Playwright浏览器组件默认安装到系统用户目录(C:\Users…\ms-playwright)
- web-ui下有个.env.example文件,这是我们项目的启动配置,复制一份并重命名为 .env
# Windows (PowerShell):
cp .env.example .env
- 运行结果(看一下有没有.env文件)
4.2启动 Browser-use Web-UI
4.2.1运行 Web-UI
- 运行 WebUI,完成上面的安装步骤后,启动应用程序:
python webui.py --ip 127.0.0.1 --port 7788
- 注意以下问题:
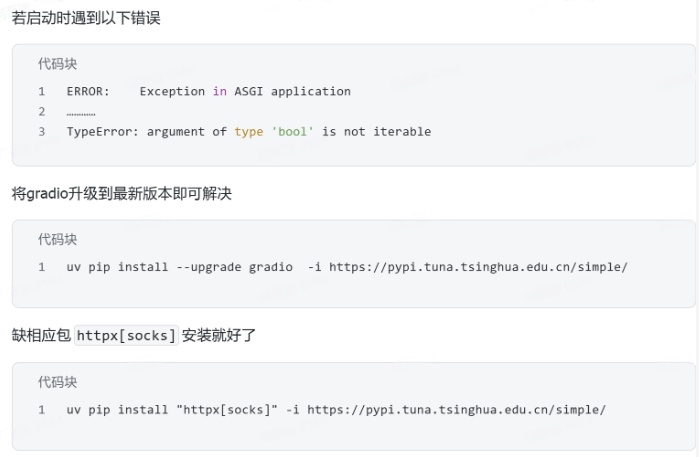
- 我运行时是有报错的

- 因此我更新了gradio

- 然后再次运行,启动应用程序

- 在浏览器输入:http://127.0.0.1:7788/,可看到以下界面。
4.2.2Web-UI 选项配置
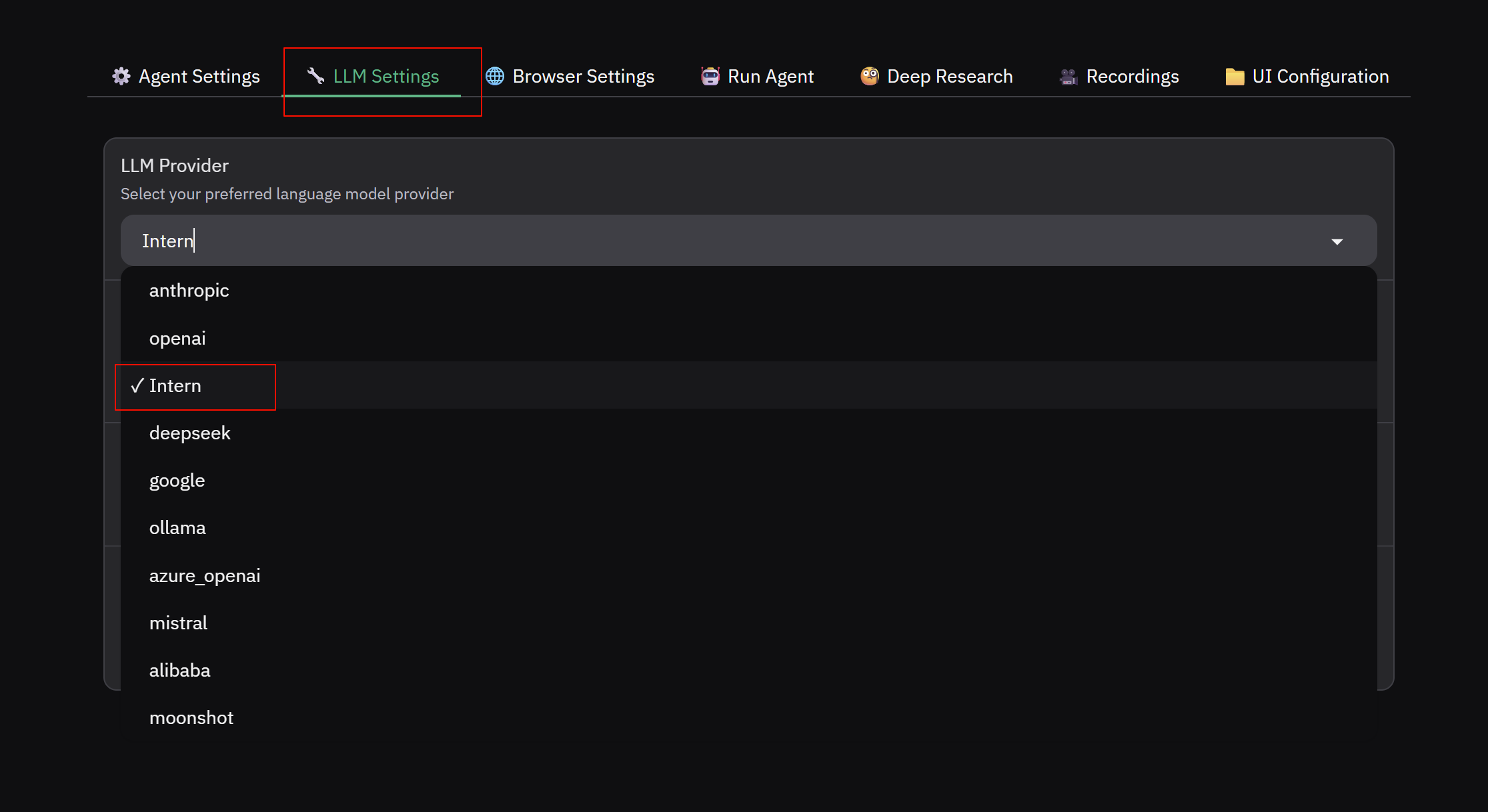
- 在 LLM Settings 下选择 Intern,模型选择 internvl-latest
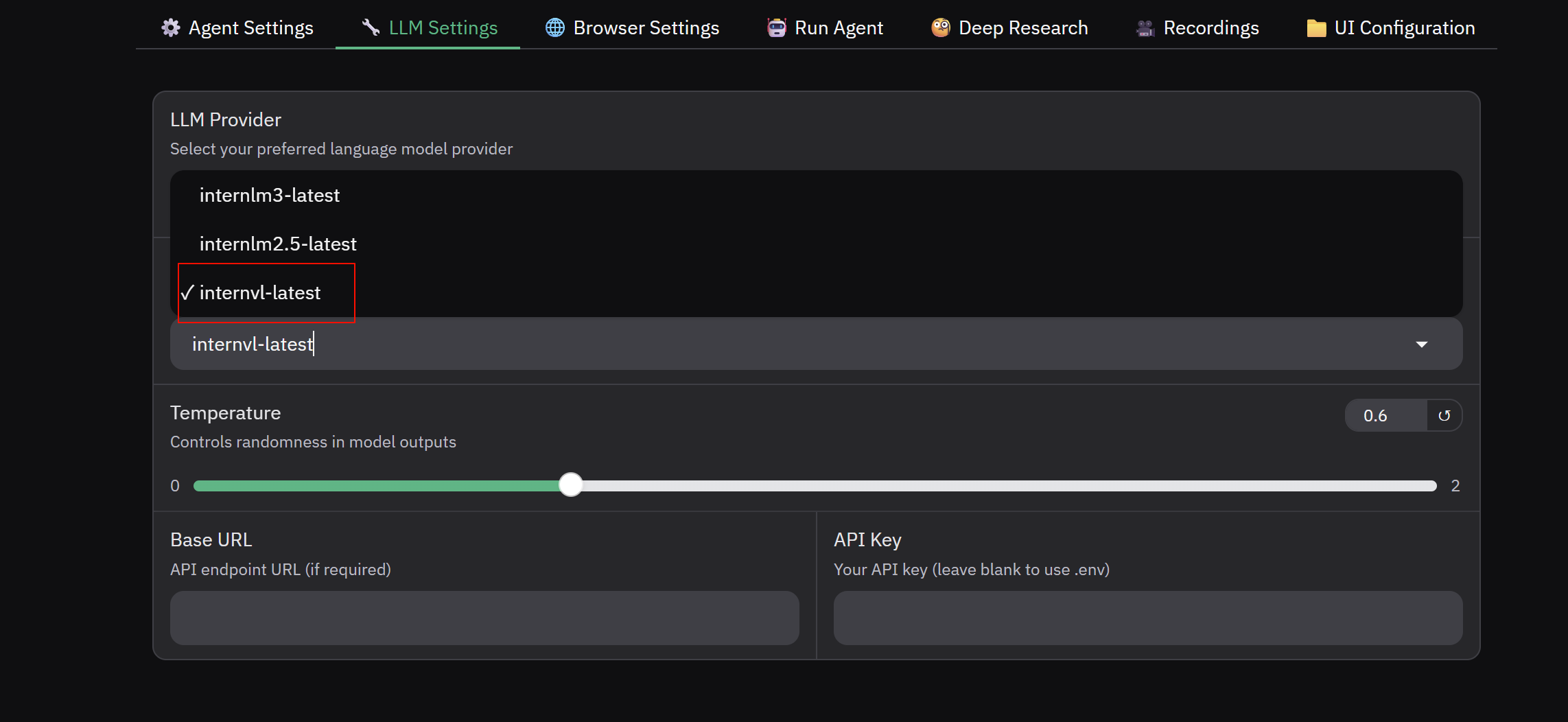
- 如果选择Internlm,注意把Agent Settings 中的Use Vison 选项去掉,Internlm是文本模型,不支持图像识别
- API KEY 位置填入你的 API Token(如果忘记了,要重新申请)
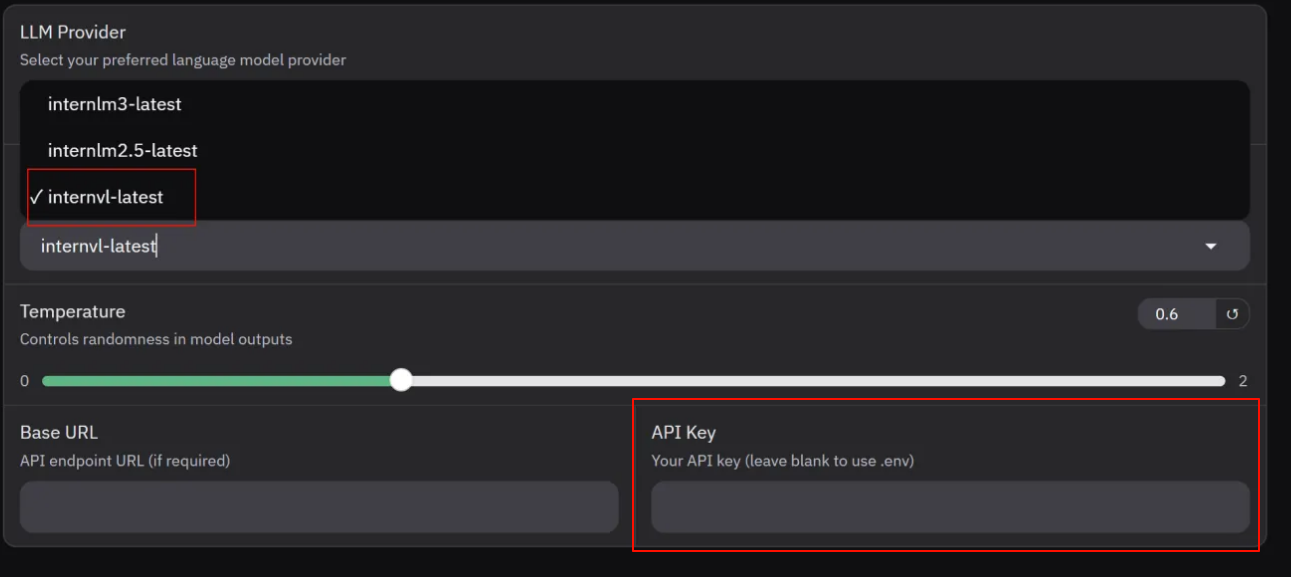
- API KEY 也可以直接写入 .env 文件中
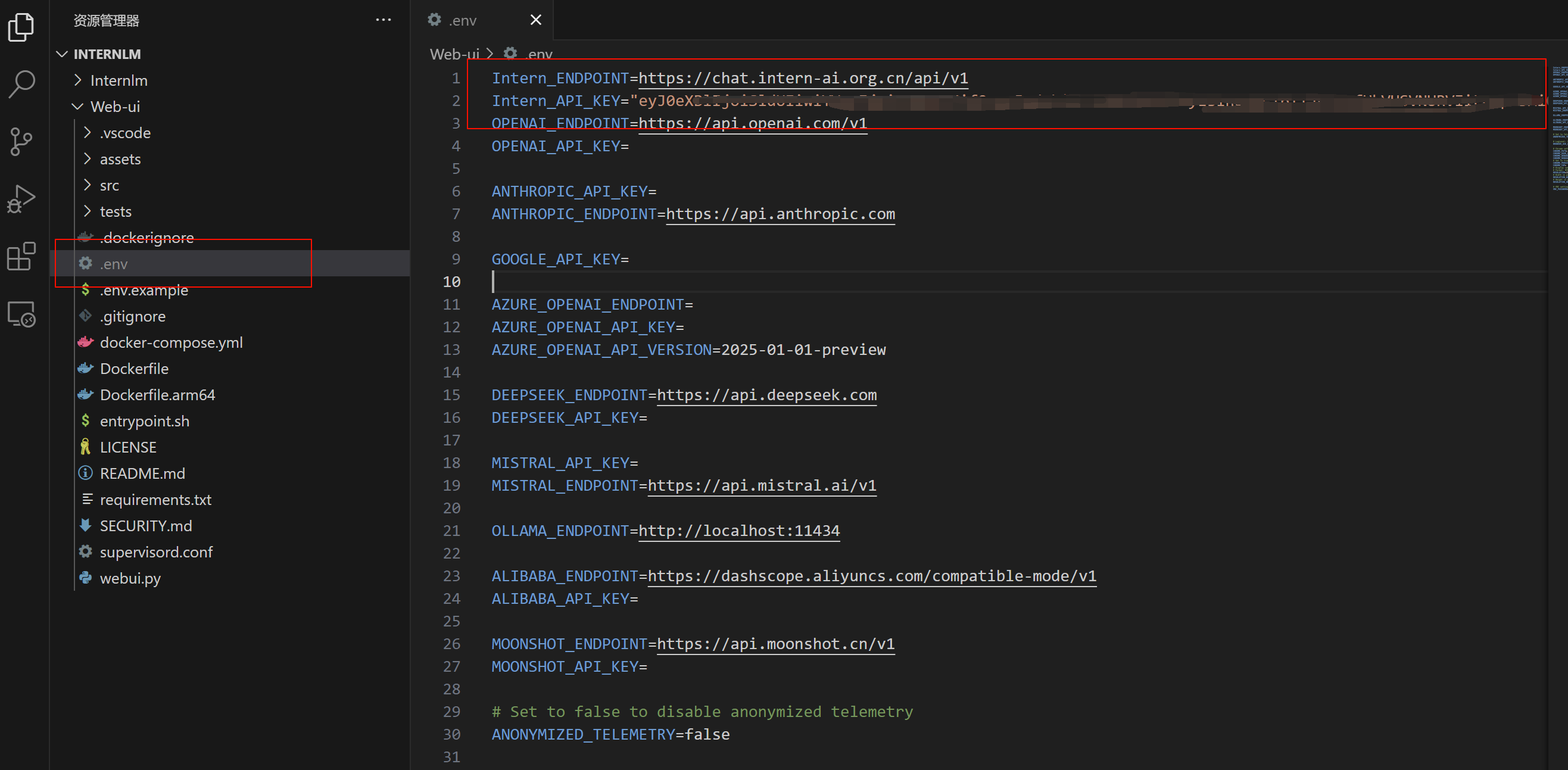
- 更改了.env文件后,要重新启动服务:
python webui.py --ip 127.0.0.1 --port 7788
4.3 案例一:查看上海天气
- 在 Run Agent 中输入任务,点击 Run Agent
例如 “去百度查一下今天上海的天气,给我结果” ,模型执行过程及结果如下
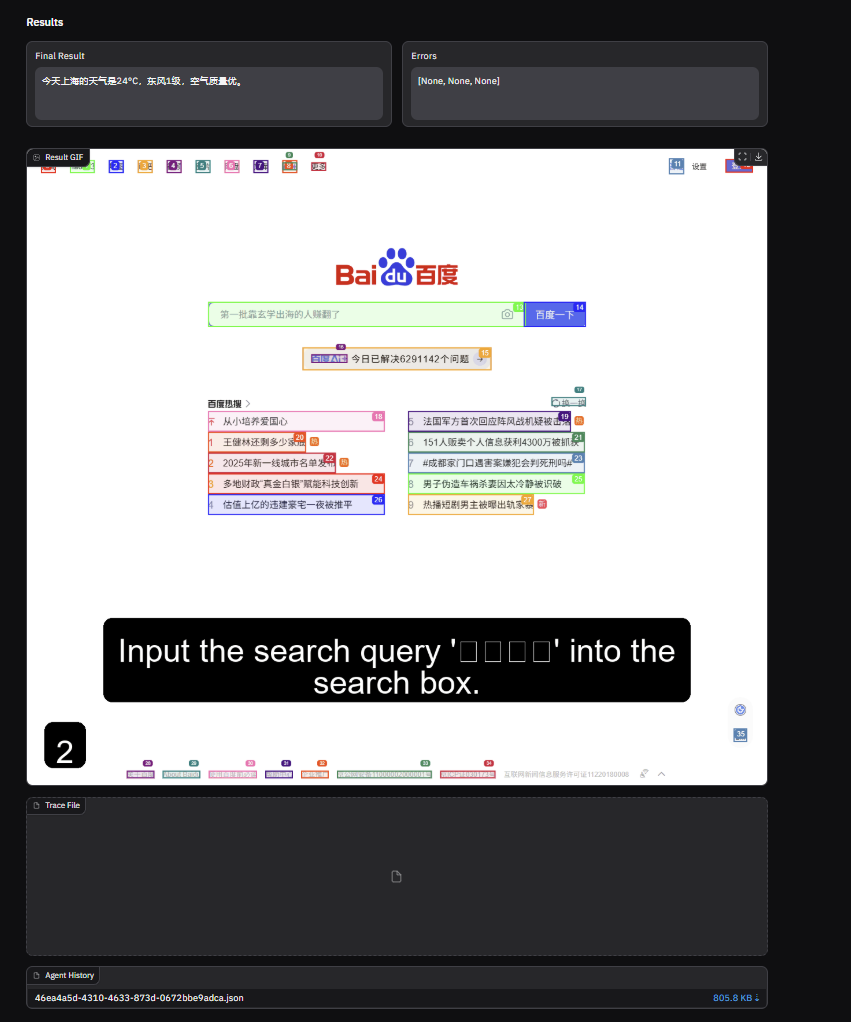
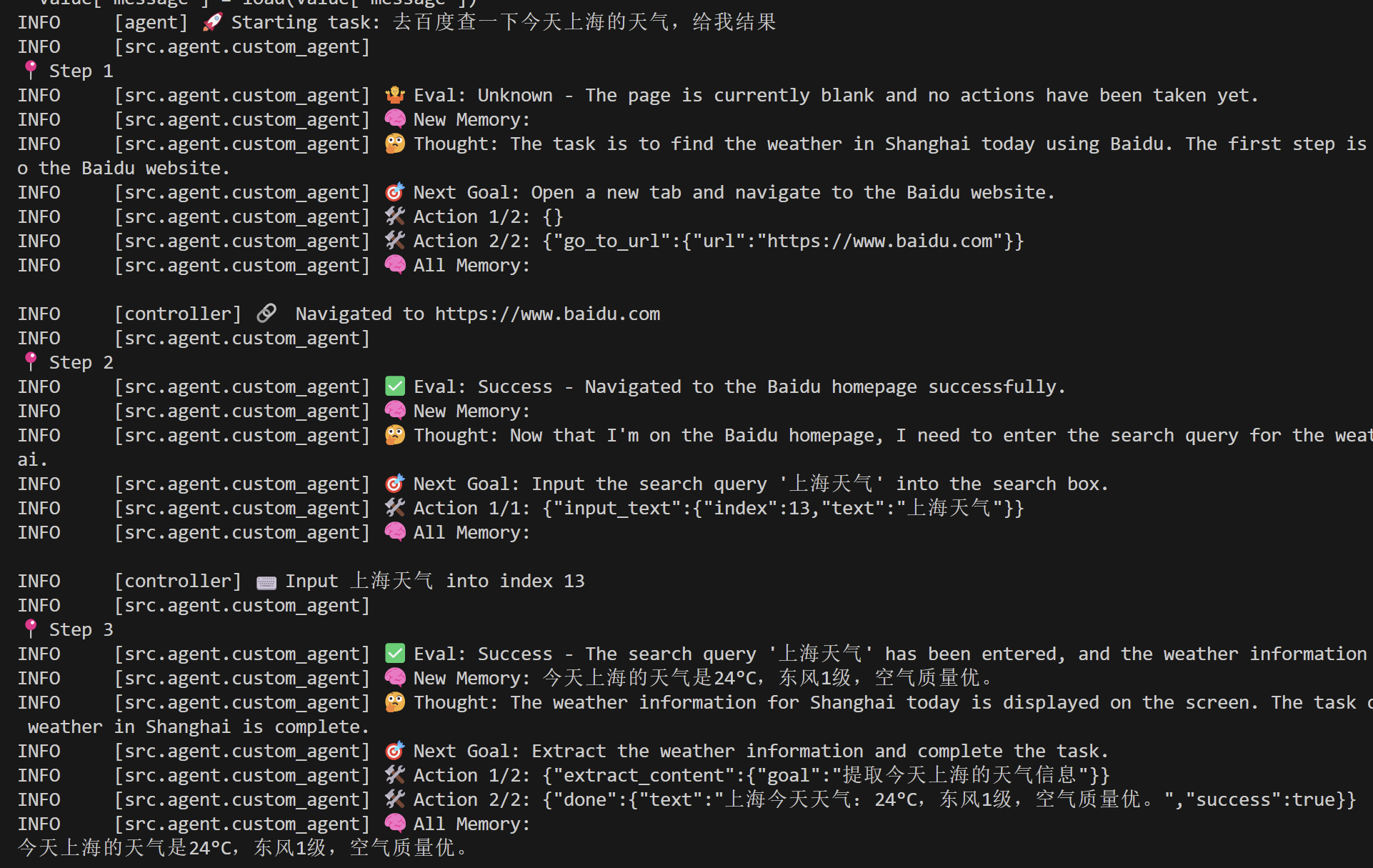
- 在Rcordings界面可以把Agent执行过程下载下来

4.4 案例二:拿书生api-key
- 在网页中输入下面这段prompt
step1 访问https://internlm.intern-ai.org.cn/api/tokens这个网站
step2 等我大概一分钟,你在操作
step3 访问https://internlm.intern-ai.org.cn/api/tokens 获取到token 命名test123 。
step4 token结果给我。
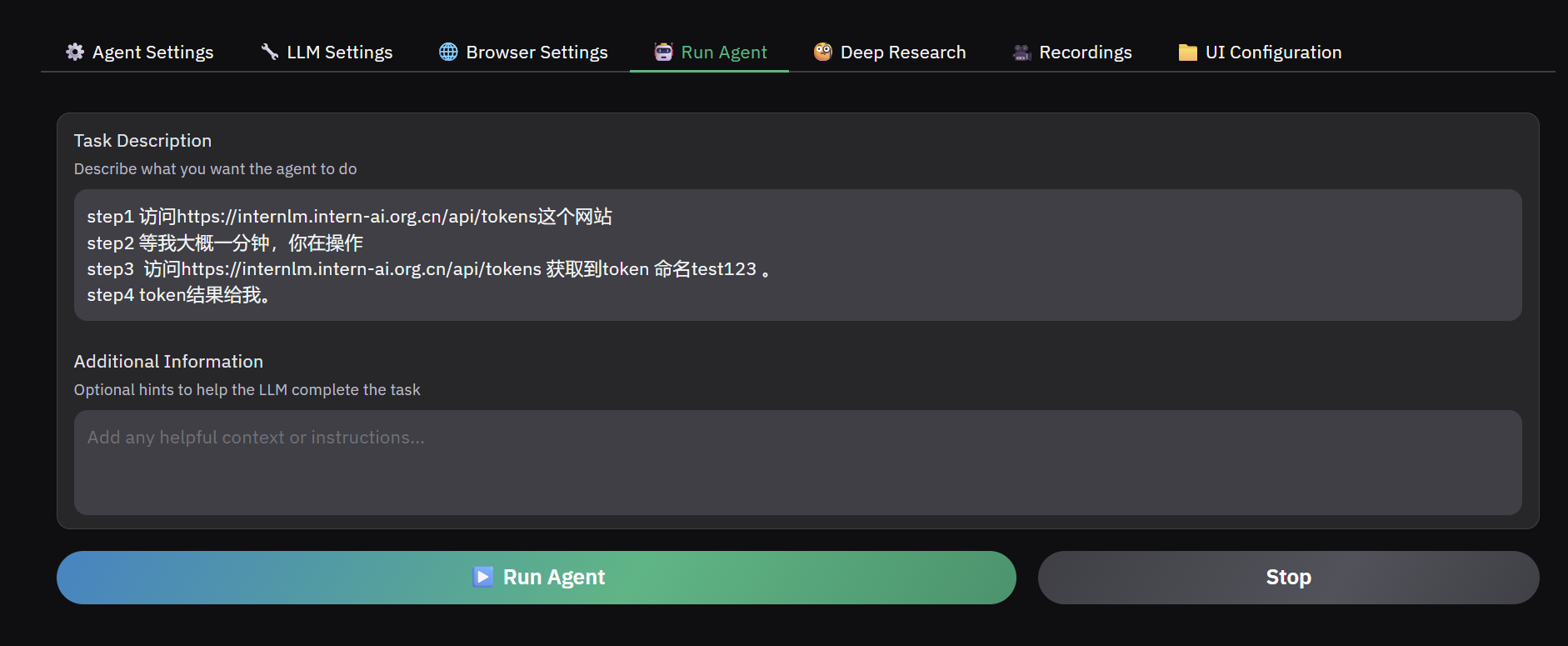
- 当ai打开这个网页的时候,需要在一分钟内登陆一下
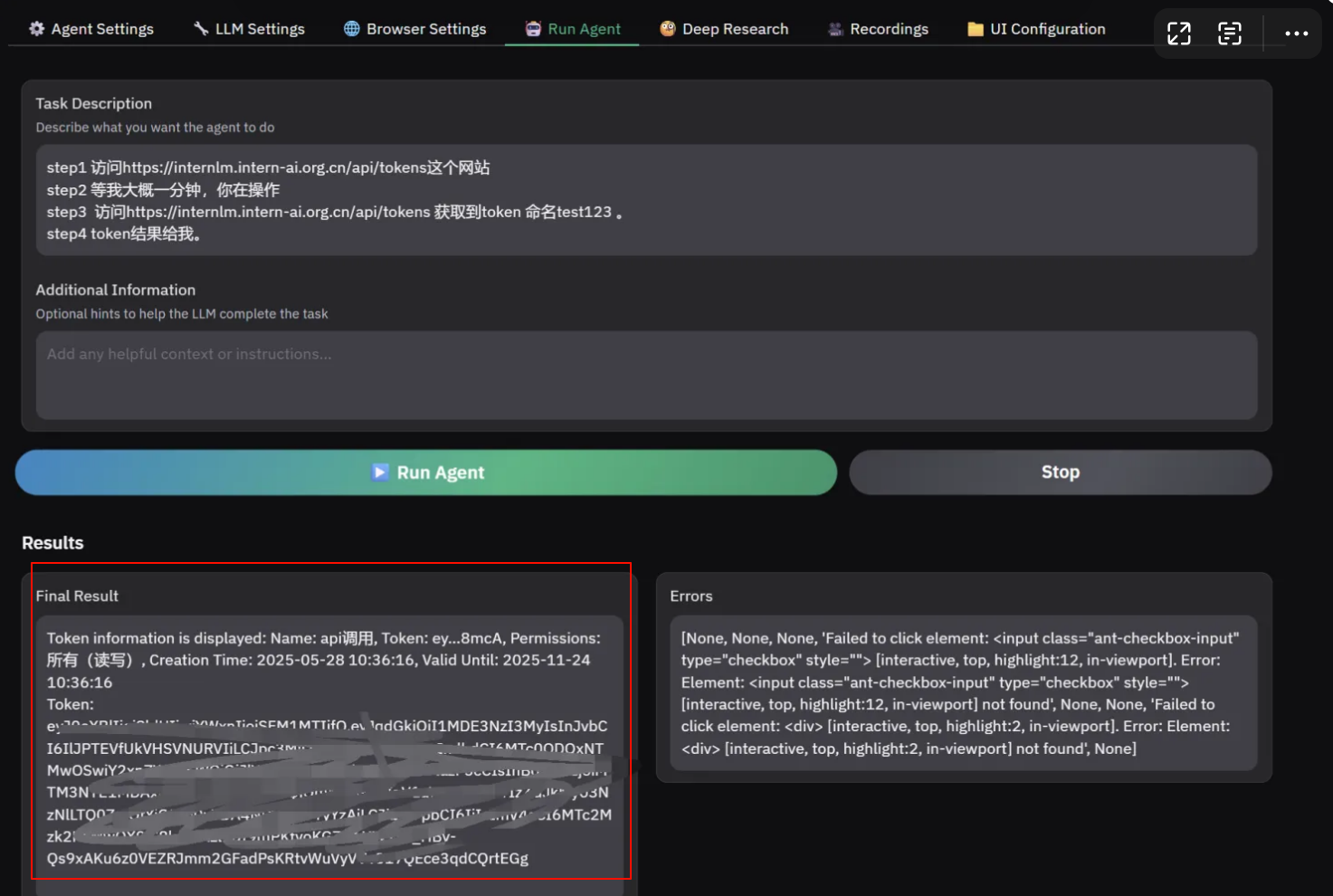
- 然后等待输出结果即可


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

{kind=link}
所有评论(0)