【大模型系列】使用Hugging Face 提供的一个开源库Transformers下载模型并在本地加载运行
接上一篇,以下大概介绍通过transfers api从huggingface下载和本地运行模型的流程;
·
接上一篇 【从modelscope下载模型并使用ollama本地运行】,以下大概介绍通过transfers api从huggingface下载和本地运行模型的流程;
pytorch安装
使用Transformers库下载hugging face上模型需要用到pytorch,所有首先需要安装;安装方法:需要根据你的电脑操作系统类型和是否有gpu下载不同的module;
进入链接:链接: https://pytorch.org/get-started/locally/,根据自己的实际情况勾选,然后将安装的命令复制即可: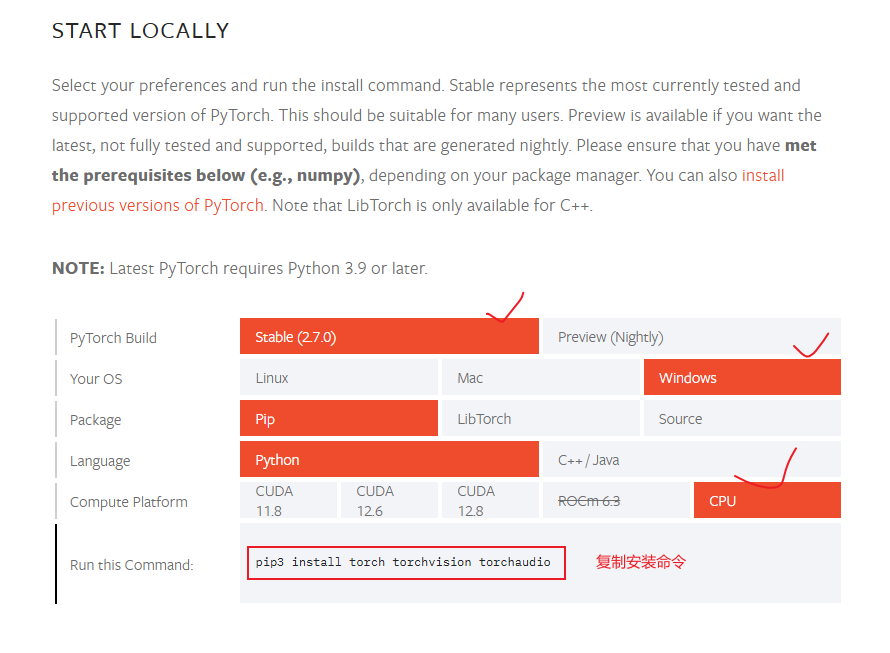
安装 transfmers
执行安装命令:
pip install transfmers
进入官网选择需要下载的模型
官网地址(这里需要梯子): https://huggingface.co/models,
- 我们搜索一个文本生成模型(uer/gpt2-chinese-cluecorpussmall)
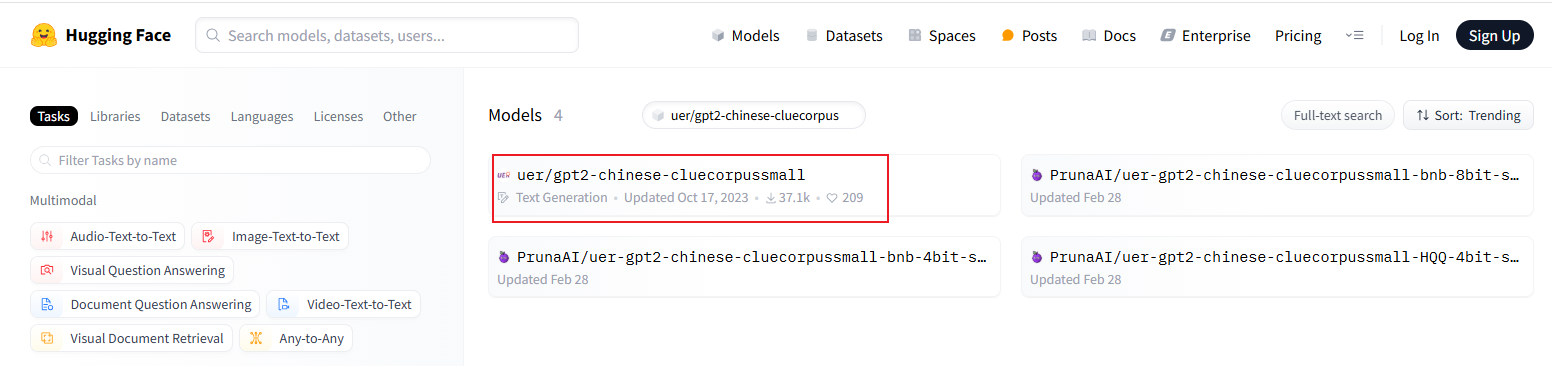
- 点击进入详情,点击复制模型ID全名
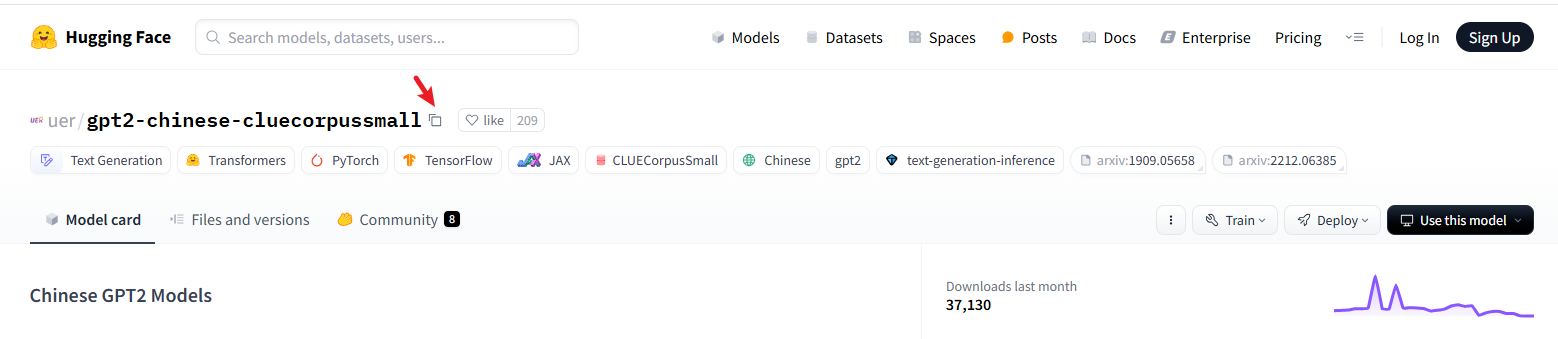
新建一个模型下载的python文件
from transformers import AutoModelForCausalLM, AutoTokenizer
"""
下载文本生成模型 uer/gpt2-chinese-cluecorpussmall
"""
model_name = "uer/gpt2-chinese-cluecorpussmall"
cache_dir = r"E:\code-ai-study-demo\ai-study-demo\f_huggingface-stu\llm"
AutoModelForCausalLM.from_pretrained(model_name, cache_dir=cache_dir)
AutoTokenizer.from_pretrained(model_name, cache_dir=cache_dir)
print("下载完毕")
该代码执行完毕后,模型文件就会下载到cache_dir中,模型文件的目录结构:
| 名称 | 说明 |
|---|---|
| config.json | 模型说明信息 |
| pytorch_model.bin | 模型文件 |
| special_tokens_map.json | 模型特殊字符标记说明 |
| tokenizer_config.json | 分词器说明 |
| vocab.txt | 模型支持的词库说明 |
使用hugging face提供的api运行本地模型
复制以下代码后运行即可
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
"""
通过 transformers api 加载本地模型进行文本生成
"""
# 设置具体包含 config.json 的目录
model_dir = r"E:\code-ai-study-demo\ai-study-demo\f_huggingface-stu\llm\models--uer--gpt2-chinese-cluecorpussmall\snapshots\c2c0249d8a2731f269414cc3b22dff021f8e07a3"
# 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained(model_dir)
tokenizer = AutoTokenizer.from_pretrained(model_dir)
# 使用加载的模型和分词器创建生成文本的 pipeline
generator = pipeline("text-generation", model=model, tokenizer=tokenizer, device="cpu")
# 生成文本
output = generator(
"你好,我是一款语言模型,", # 生成文本的输入种子文本(prompt)。模型会根据这个初始文本,生成后续的文本
max_length=50, # 指定生成文本的最大长度。这里的 50 表示生成的文本最多包含 50 个标记(tokens)
num_return_sequences=1, # 参数指定返回多少个独立生成的文本序列。值为 1 表示只生成并返回一段文本。
truncation=True, # 该参数决定是否截断输入文本以适应模型的最大输入长度。如果 True,超出模型最大输入长度的部分将被截断;如果 False,模型可能无法处理过长的输入,可能会报错。
temperature=0.3, # 该参数控制生成文本的随机性。值越低,生成的文本越保守(倾向于选择概率较高的词);值越高,生成的文本越多样(倾向于选择更多不同的词)。0.7 是一个较为常见的设置,既保留了部分随机性,又不至于太混乱。
top_k=50, # 该参数限制模型在每一步生成时仅从概率最高的 k 个词中选择下一个词。这里 top_k=50 表示模型在生成每个词时只考虑概率最高的前 50 个候选词,从而减少生成不太可能的词的概率。
top_p=0.9, # 该参数(又称为核采样)进一步限制模型生成时的词汇选择范围。它会选择一组累积概率达到 p 的词汇,模型只会从这个概率集合中采样。top_p=0.9 意味着模型会在可能性最强的 90% 的词中选择下一个词,进一步增加生成的质量。
clean_up_tokenization_spaces=True, # 该参数控制生成的文本中是否清理分词时引入的空格。如果设置为 True,生成的文本会清除多余的空格;如果为 False,则保留原样。默认值即将改变为 False,因为它能更好地保留原始文本的格式。
)
print(output)
输出如下:

生成的内容可以通过generator方法参数调整,选择适合业务场景的模型也是一个重要的前提;
注意,这里下载的是一个gtp模型即文本生成模型,所有输出为文本是对上面query的续写;
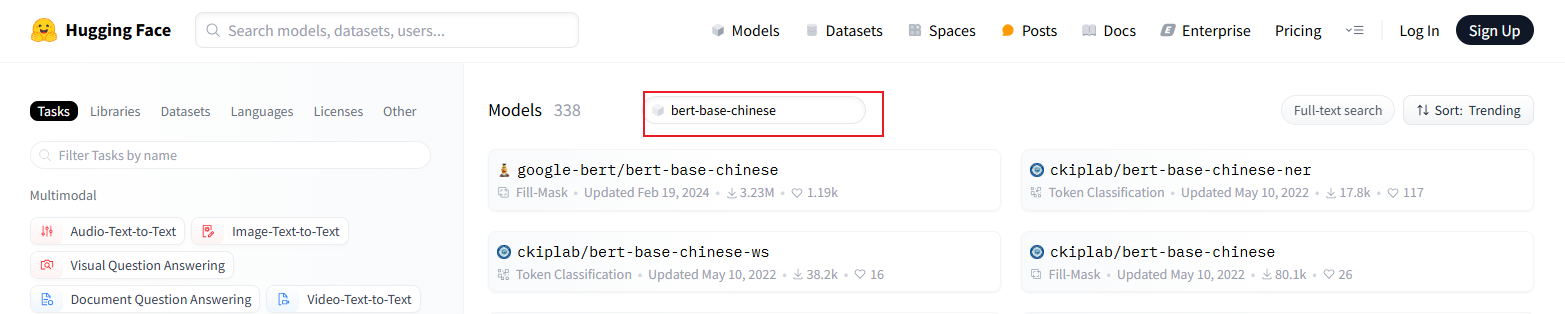
如果需要下载分类模型,可以搜索带bert关键字的模型
over~~

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)