基于dify如何傻瓜式搭建个人知识库
从0到1傻瓜式搭建个人的dify知识库,提升个人工作和知识整合效能
AI 的快速发展方便了我们日常的工作和生活,也有很多AI衍生产品可以快速搭建我们的知识库,方便我们快速检阅自己的知识。
主要的问题在于,出于隐私和保密、合规的问题,有些知识库借助外部工具会存在知识泄露的风险,需要考虑如何在内部快速搭建个人或者团队内部知识库。
这里主要借助dify来快速实现知识库的搭建
一 什么是dify
Dify是一个开源的大语言模型(LLM)应用开发平台,它主要可以简化AI应用的开发流程,并支持多种大语言模型。
通过与多个模型供应商合作,开发人员可以在dify搭建和选择适合自己的模型。
Dify同时可以支持数据集管理、流程编排和流程可视化,这些功能降低了AI开发的难度。
Dify可以和其他工具结合实现如下效果(部分内容参考外部,并非都亲自尝试过):
- Langbot:支持多平台的即时通信机器人框架,结合Dify可以快速实现微信接入。
- Echarts:结合Echarts实现Excel数据可视化。
- DeepSeek:Dify中支持了数百个模型,也包含了deepseek。
- RAGFlow:结合Dify和RAGFlow构建工作流,通过知识库等功能实现复杂的对话和自动化任务。
- MCP:Dify可以作为MCP
- Server对外提供服务,实现中间商赚差价的可能。
- Notion:Dify支持从Notion导入并设置同步,以便Notion中的数据更新自动同步到Dify。 Jina
- Reader:使用Jina Reader、Firecrawl等第三方工具从公开网页中爬取内容,解析为Markdown内容,导入知识库。
- Zapier:通过MCP SSE插件实现高效流式响应,可以调取多种不同的工具
Dify的使用,需要进行基础环境的配置和搭建,由于团队内部的基础环境一般都已存在,本文仅从知识库和应用创建阶段介绍搭建流程,更偏向应用搭建的实操记录。
二 搭建知识库整体步骤
整体操作大的步骤为:
1.创建个人的知识库
2.搭建dify应用
3.运行使用
2.1 创建个人知识库
知识库就是自己的内部知识合集,可以是文档,可以是网页
知识库创建时,可以将自己或者团队沉淀的文档内容都放在里面,用于后期的知识检索
1.创建知识库
进入知识库页面,创建知识库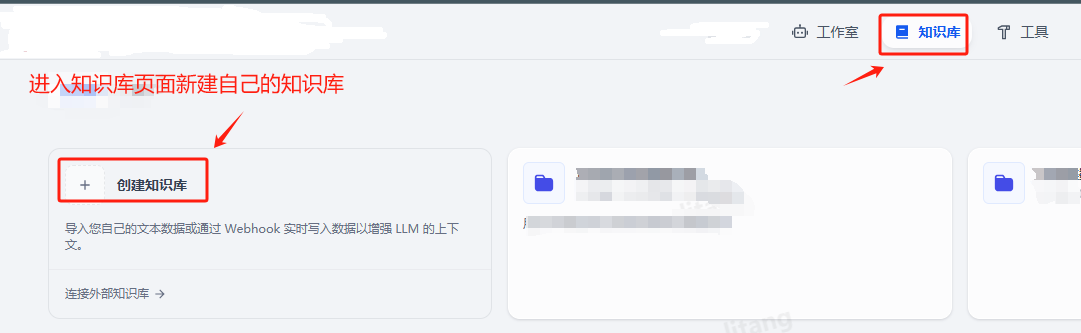
2.上传文件
创建后的知识库上传文件的位置: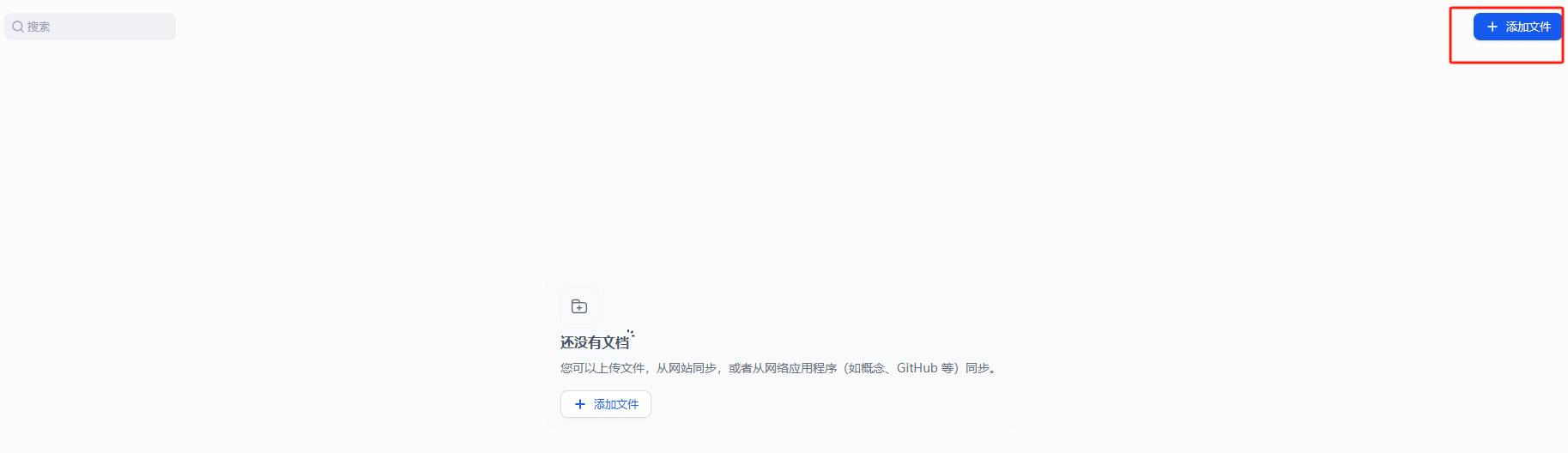
3.选择文件读取的参数
上传文件,文件读取有“选择数据源->文本分段清清洗>处理并完成”3步
选择数据源是待上传的文件
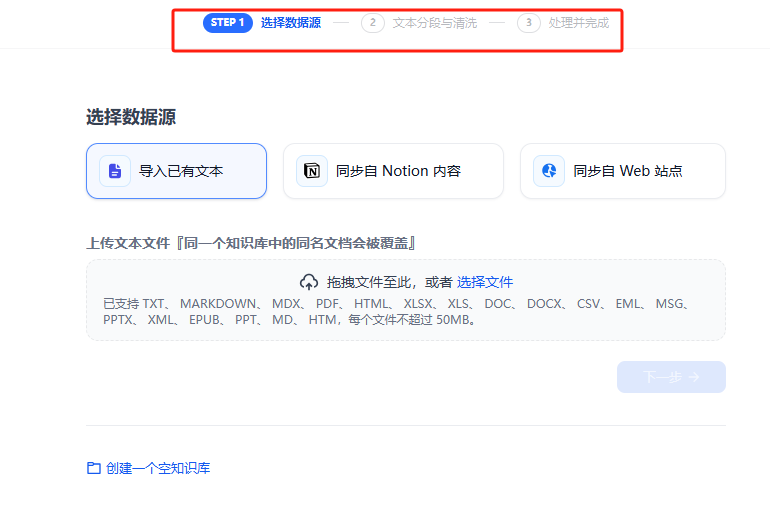
文本分段清洗,就是选择自己文件如何通过系统模型识别出来进行后期的加工
主要考虑文本怎么进行分段,怎么索引,数据怎么集成,由于不同的模型有优劣,所以需要根据自己的需要进行不同模型参数的选择,如果没有太大的要求,可以默认参数,点击“保存并处理”按钮进入下一步即可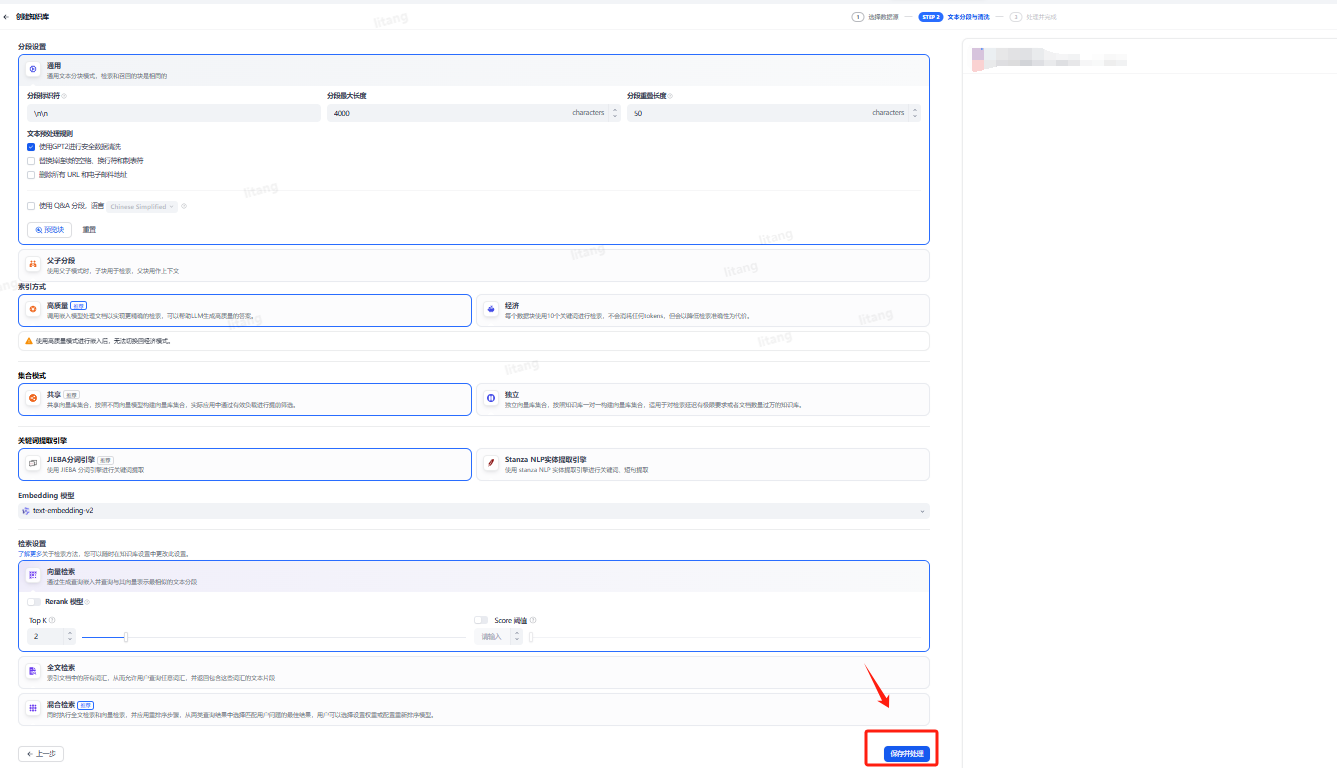
选择完成后,系统会提示上传完成,以及解析文档的相关参数也会一并附录
这时我们在知识库里面添加了第一个文档,我们还可以依次上传第2、3、4个文档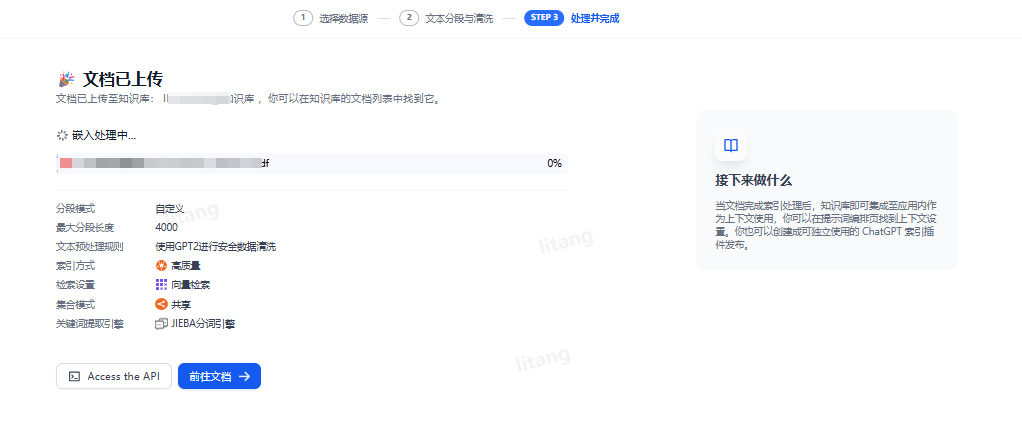
2.2 编排个人助手
1 创建应用
在工作室里找到创建空白应用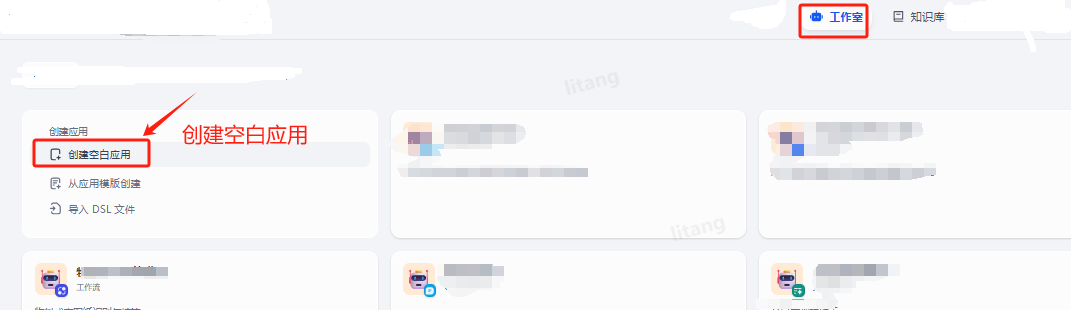
2.选择应用的类型和命名
给自己的应用小助手命名,我们这里主要做知识库问答,选择“chatFlow”的个人应用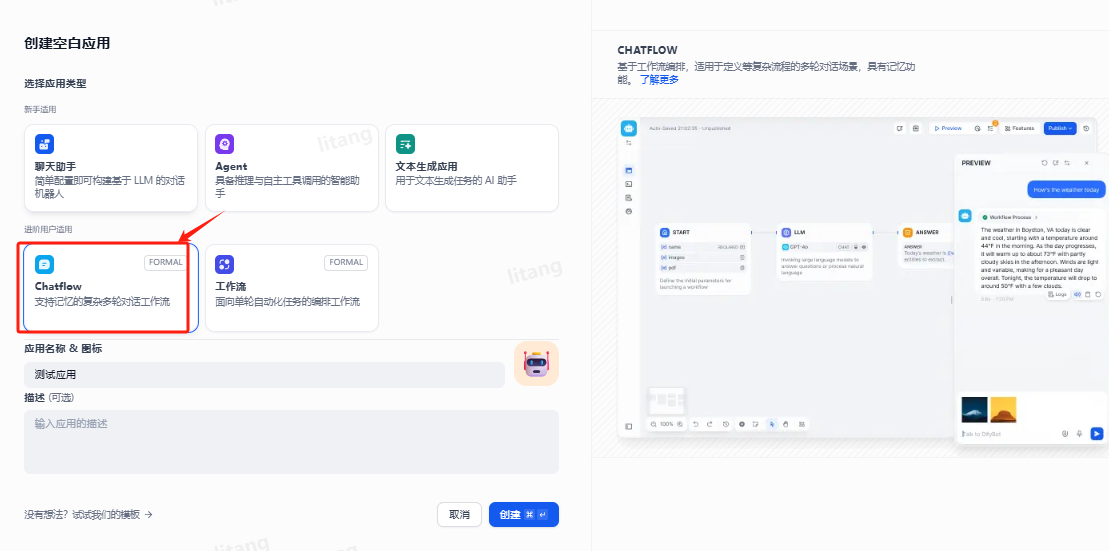
3.流程编排
新建应用后,就直接会显示出对应的默认编排参数
整体的页面布局参考下图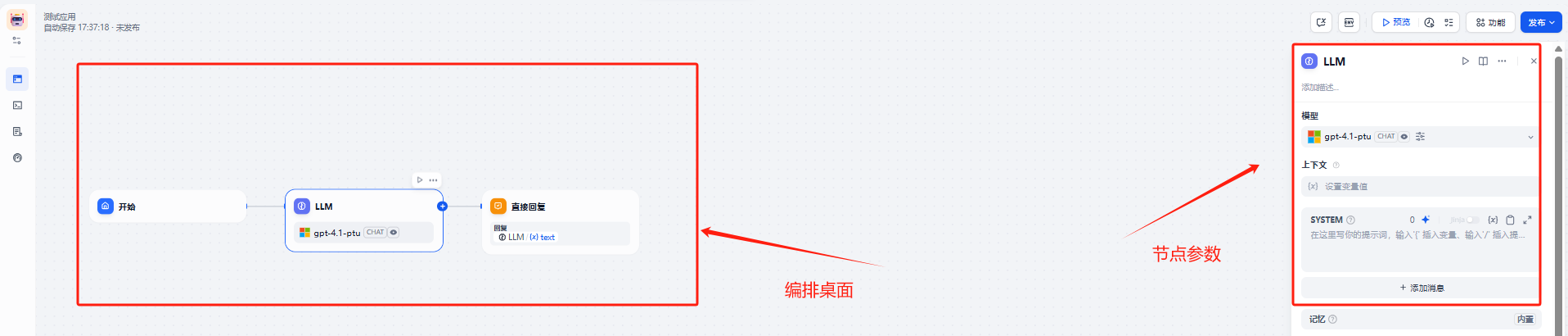
我们编排的主要思路为:
1)先获取用户的问题并解析(这里使用LLM语言模型)
2)通过解析后的问题检索我们的知识库(使用知识检索节点)
3)将知识检索的结果进行文本分析(使用LLM语言模型将检索的结果进行解析)
4)将分析后的结果回复给用户
重复进行上述的循环
整体编排的节点可以先设置成这个样子:
每个节点的操作逻辑可以参考本文第三节的细节介绍

2.3 试运行使用
将应用选择发布,然后可以预览调试
预览的对话框界面参考: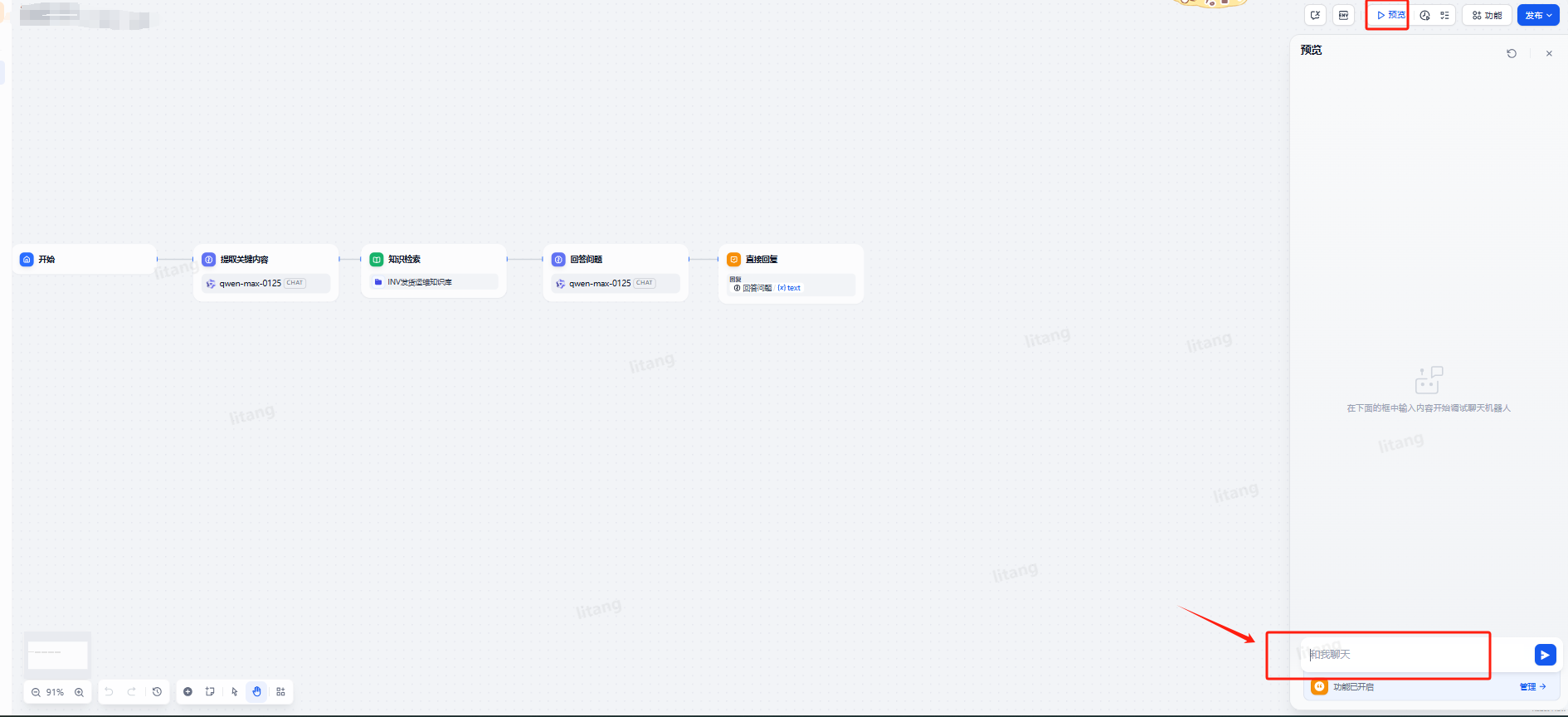
点击运行后的对话框参考: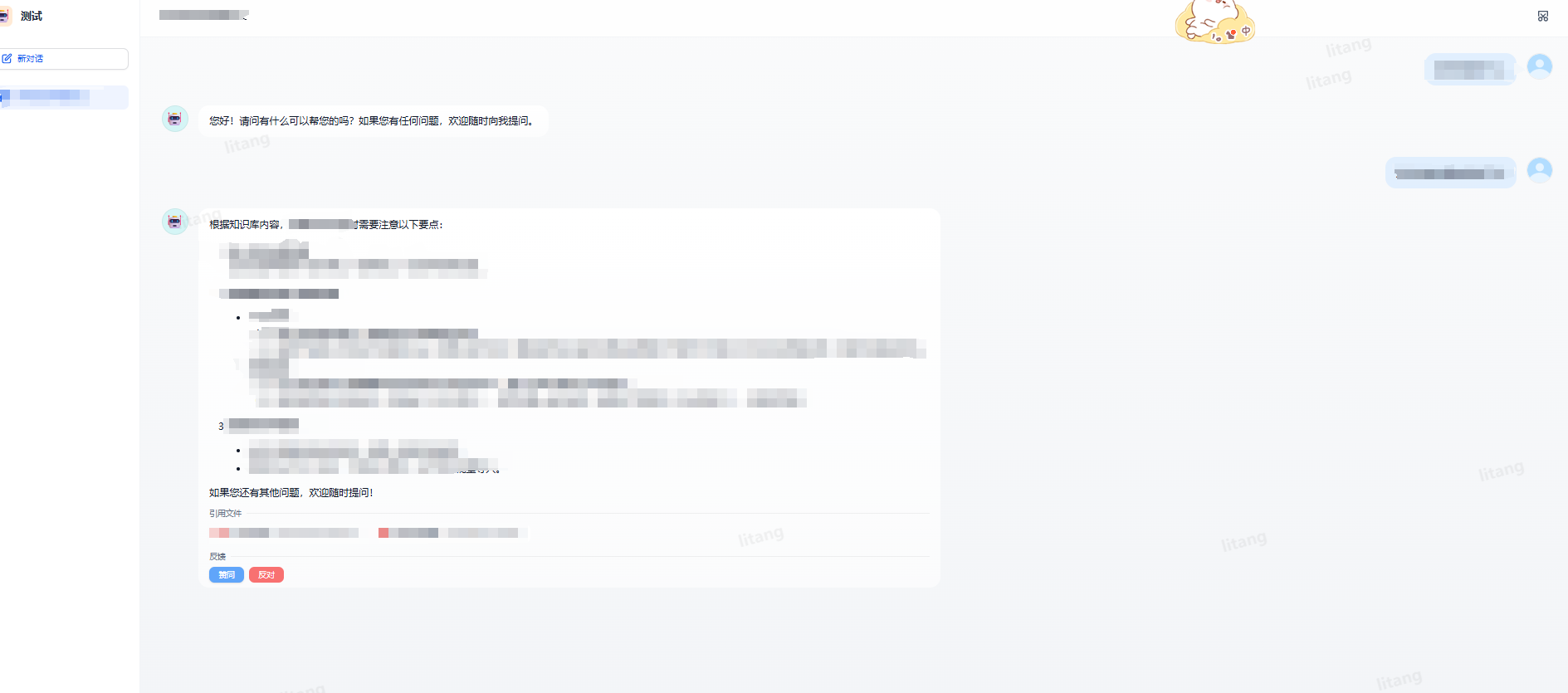
三 Dify编排的节点配置
3.1 怎么新增节点和重命名
创建节点: 两个节点之间的连线,鼠标浮动上去,会有一个“+”号,点击这个符号就可以创建一个节点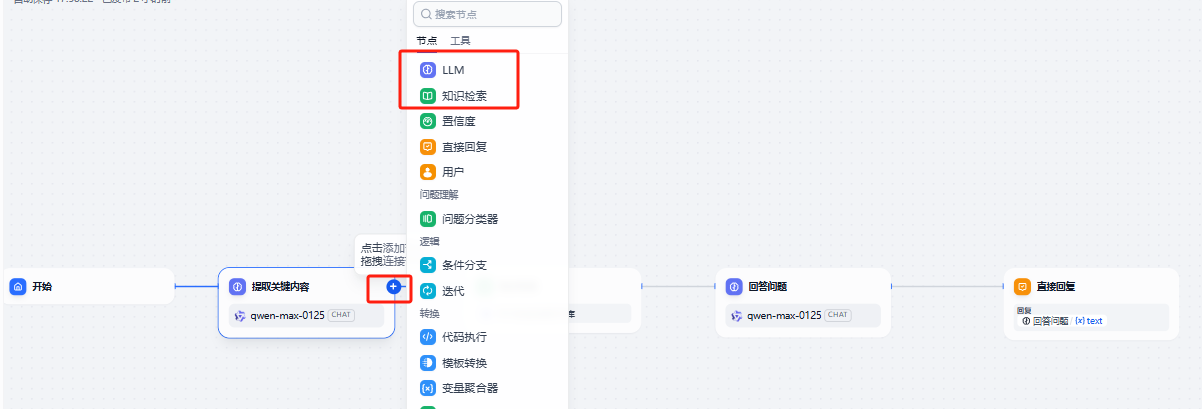
重命名节点: 如果模型的节点很多,且一个模型重复使用,得考虑节点的命名方便识别。重命名的方式很简单,点击对应的节点,就会显示当前节点的参数框,参数框的最上面就是默认的节点名字,可以改成我们命名的名字,方便识别,参考下图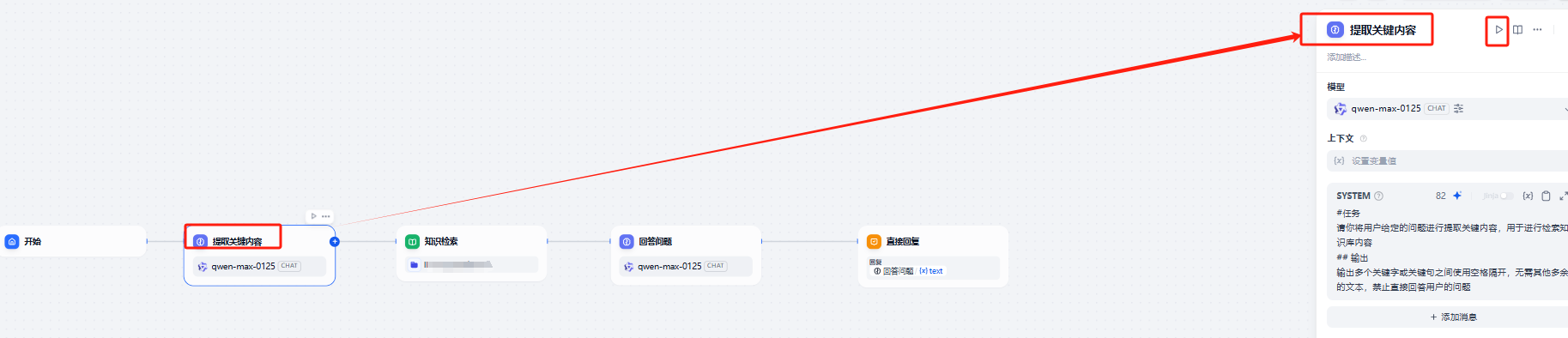
3.2 节点参数配置
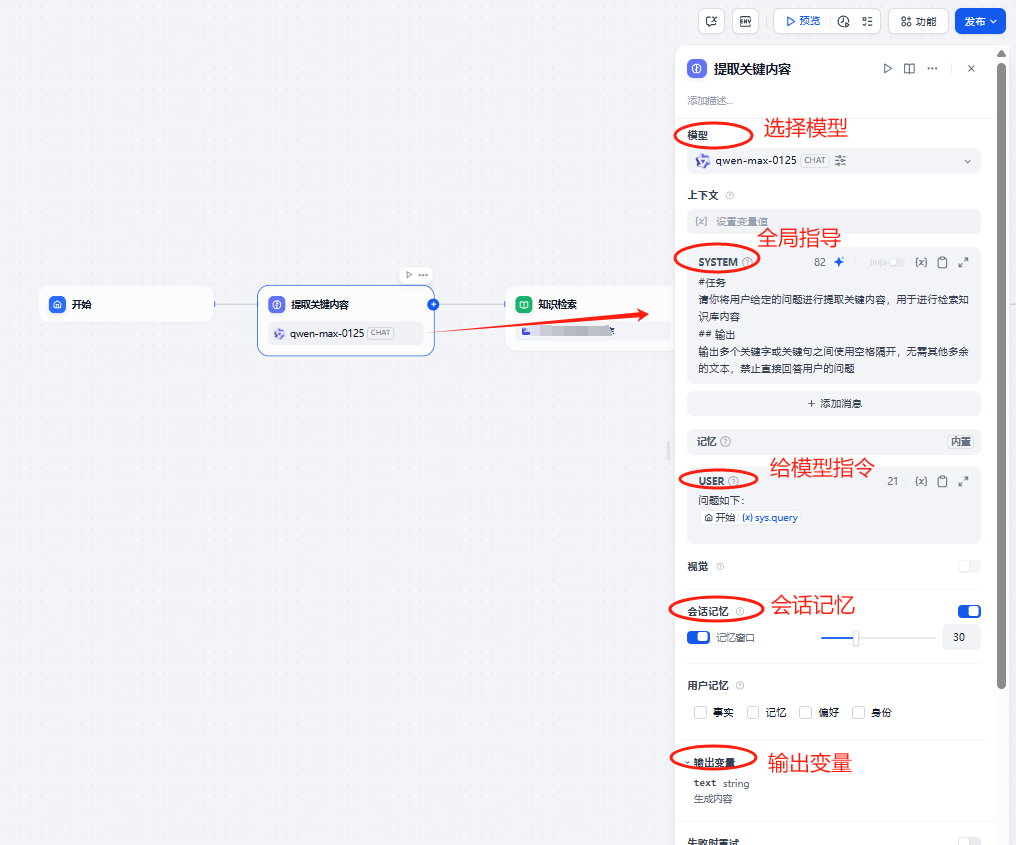
3.2.1 提取关键内容
主要配置的内容项:
1.选择模型:即选择哪个大语言模型进行分析,目前有gpt、通义、deepseek等模型,这里默认的是通义的模型
2.全局指导:告诉应用怎么处理数据,也是应用使用的前提条件
3. 给模型的指令:即用户询问的问题,一般可以不写,也可以补充增加一下问题润色。比如用户每次输入“我的包在哪里”,我们润色后都加上“问题如下:”,系统接收的实际问题为:“问题如下:我的包在哪里”
4.会话记忆:记录每次对话上下文的内容,并给出记忆对话内容的轮次,比如设置了5次那么第六次对话,系统就不记得第一次问的问题了
5. 输出变量:即模型的输出结果(一般这个不用动,但是我们得知道输出的名字是什么,下个节点得使用这个输出变量的明细)
相关配置的参数可以参考下述截图:
3.2.2 知识检索
知识检索节点主要考虑配置的参数有:
1.查询变量:即要检索的知识问题是什么,这个是通过“提取关键内容”节点输出来获取的
2.知识库:选择要检索的知识库,这个是我们一开始创建的知识库
3.输出变量:即通过知识库检索的结果是什么
知识检索相关配置参数参考: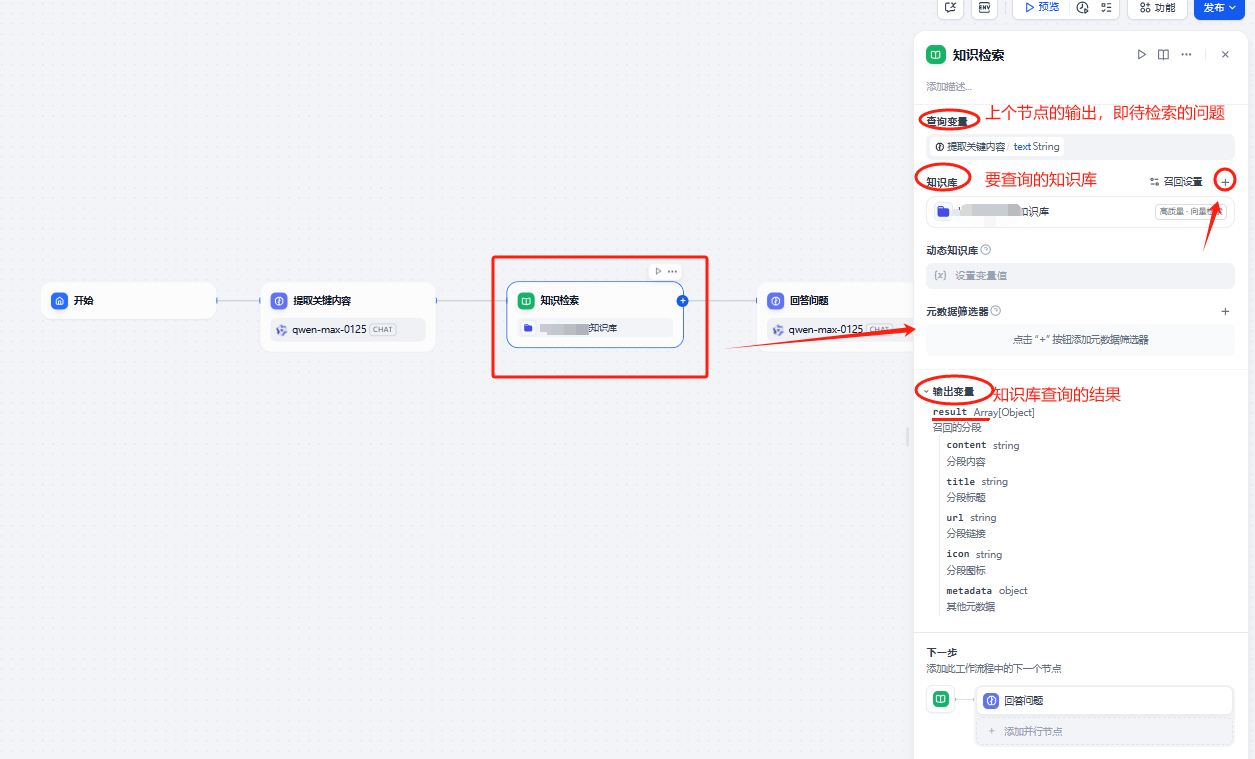
3.2.3 回答问题
回答问题节点和“提取关键内容”节点,其实都是LLM大语言模型,参数配置基本是一样的
这里主要的区别在于:
1.输入的配置:输入是知识检索的结果
2.全局内容有变化:全局内容是知识库范围的内容
回答问题节点的配置,参考下述截图,其中全局参数部分的“上下文”,可以通过输入"/"来唤出引用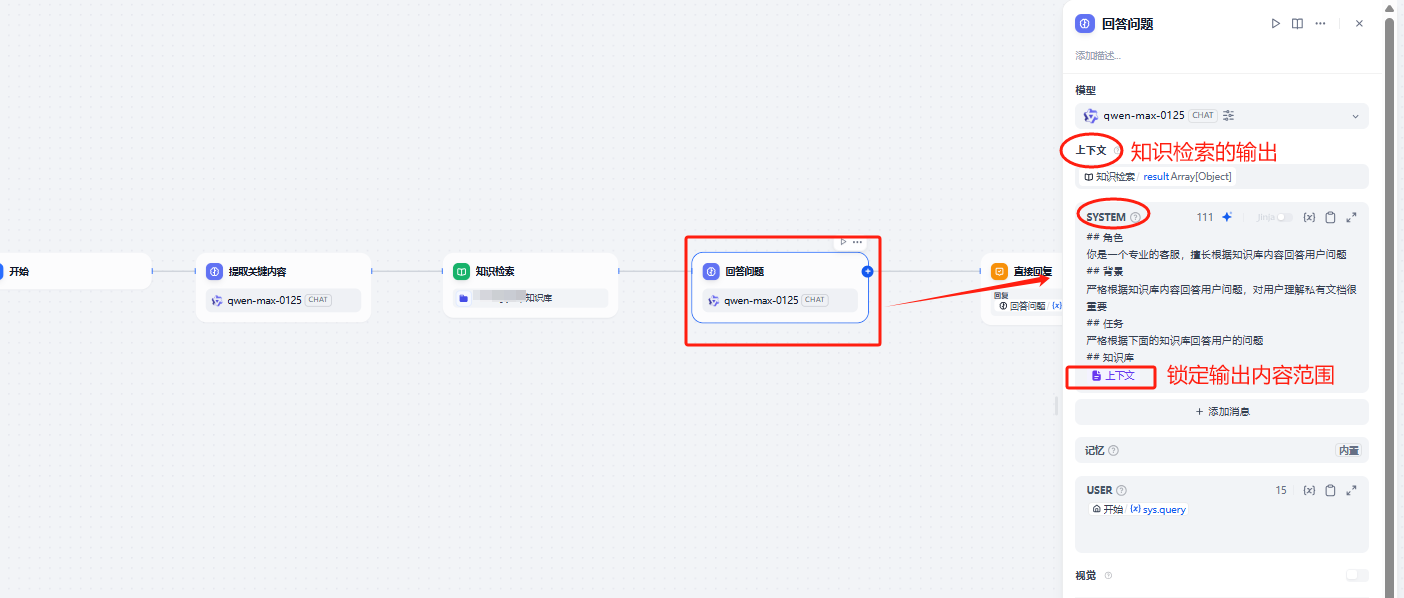
3.2.4 直接回复节点
直接回复节点比较容易,直接将内容显示给用户即可
它只有一个配置,接收上个节点的输出,上个节点的输出
配置成上个节点的输出变量即可
配置参数参考下述截图界面: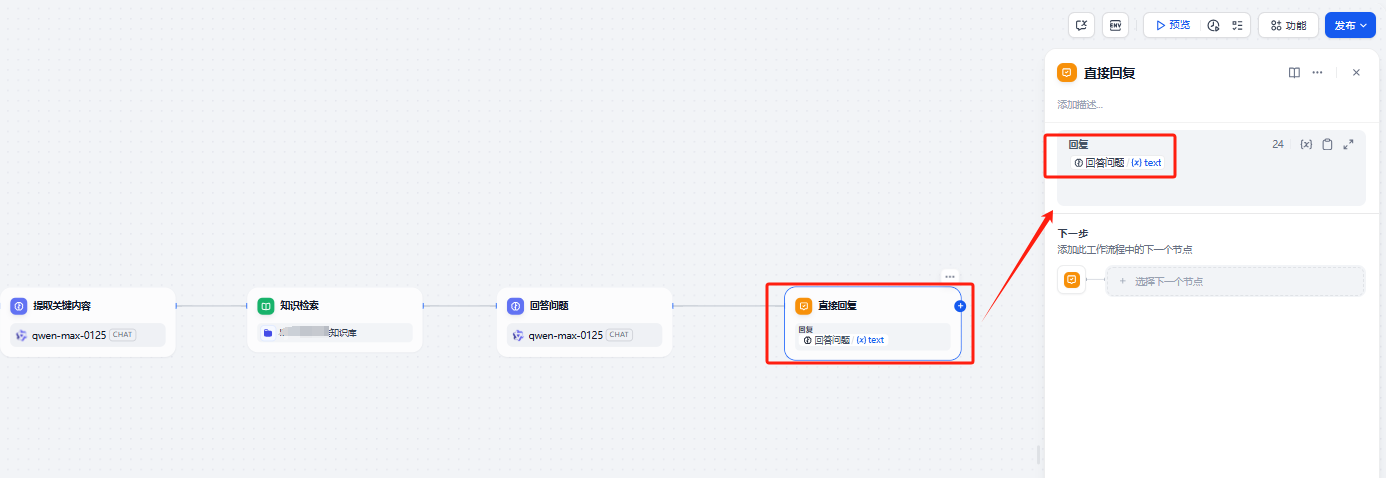

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)