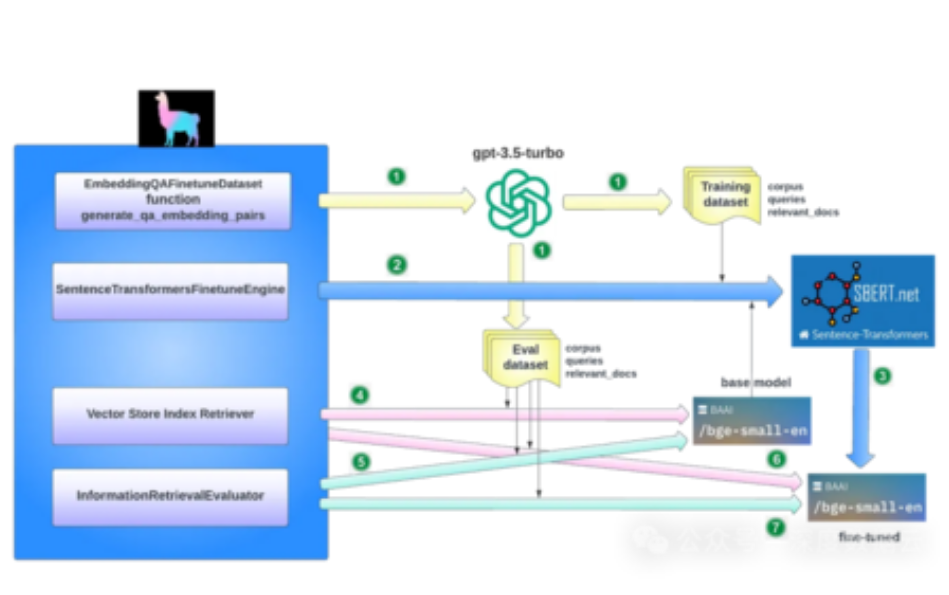
大模型微调与部署终极指南:从LoRA到GGUF的工业级实践
量化训练:启用`load_in_4bit=True`,配合`gradient_checkpointing`降低显存占用。- 推荐24G显存以上GPU(如A100),多卡分布式训练需配置`accelerate`。- Bitsandbytes:4-bit量化训练库,显存占用降低3倍。- 训练阶段:Loss曲线、参数更新幅度(通过`wandb`可视化)。- 部署:通过多Lora合并,单卡支持5个子业务线
一、环境配置与工具链
1. 核心工具
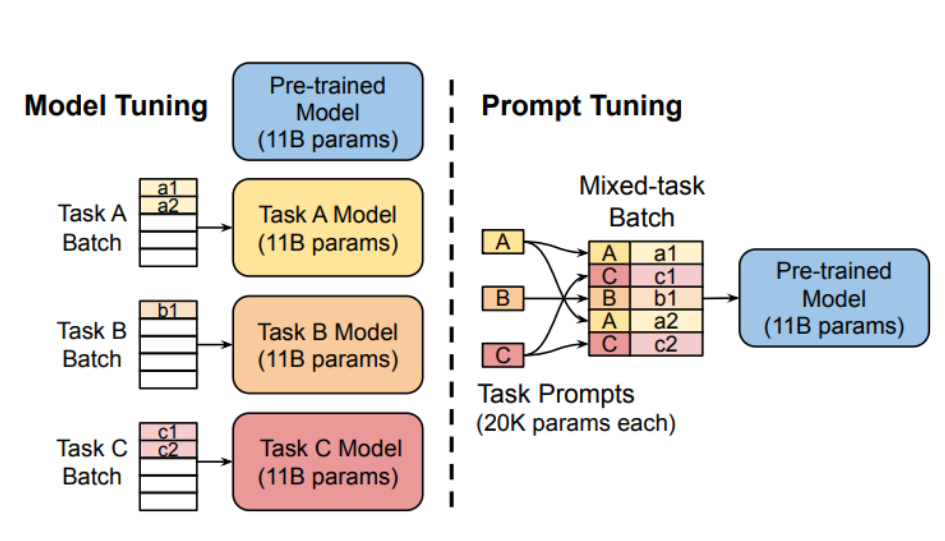
- PEFT:用于LoRA/QLoRA微调的轻量化框架,支持参数高效适配。
- Bitsandbytes:4-bit量化训练库,显存占用降低3倍。
- Unsloth:加速训练的优化工具,支持动态张量核心计算。
- VLLM:高性能推理引擎,支持批量生成和低延迟响应。
2. 硬件要求
- 推荐24G显存以上GPU(如A100),多卡分布式训练需配置`accelerate`。
- 本地部署可使用Ollama容器化工具,支持多模型快速加载。
二、微调全流程设计
1. 数据准备与预处理
- 数据来源:优先使用领域定制数据集(如Hugging Face中文对话数据集),混合通用语料提升泛化性。
- 模板设计:
```python template = f"用户:{user_input}\n助手:{assistant_response}" ``` ``` 确保对话轮次清晰,标注意图标签(如情感、实体)。- 数据增强:通过同义词替换、句式变换生成多样化样本,提升模型鲁棒性。
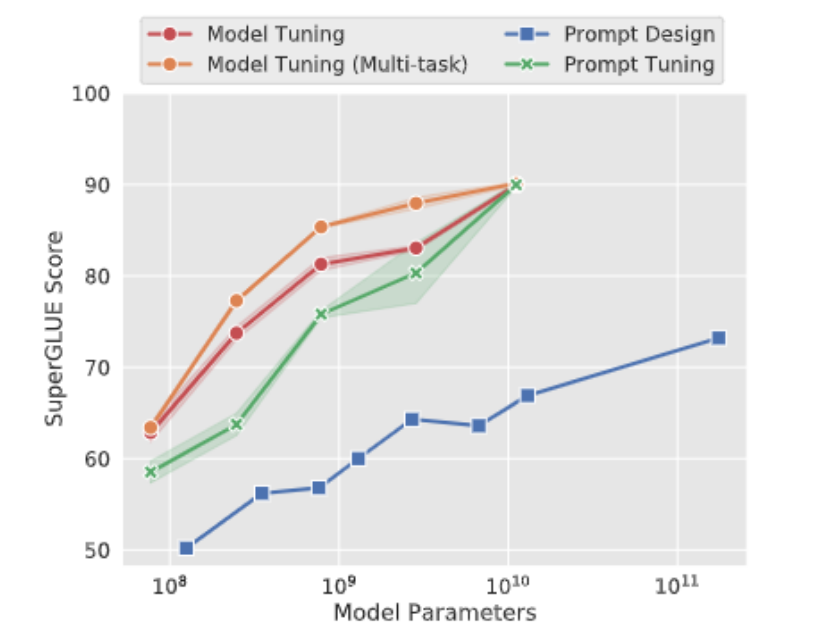
2. LoRA/QLoRA微调策略
- 参数配置:
- LoRA秩值(r):推荐64-128,平衡精度与显存。
- 学习率:法律/代码任务设为2e-5,情感任务可调至5e-5。
- 量化训练:启用`load_in_4bit=True`,配合`gradient_checkpointing`降低显存占用。
3. 多任务适配与模型合并
- 多Lora部署:
- 合并多个业务场景的Lora Adapter,单卡支持多模型推理。
- 动态加载逻辑:通过API参数指定激活的Lora模块,避免显存冲突。
三、GGUF格式转换与部署
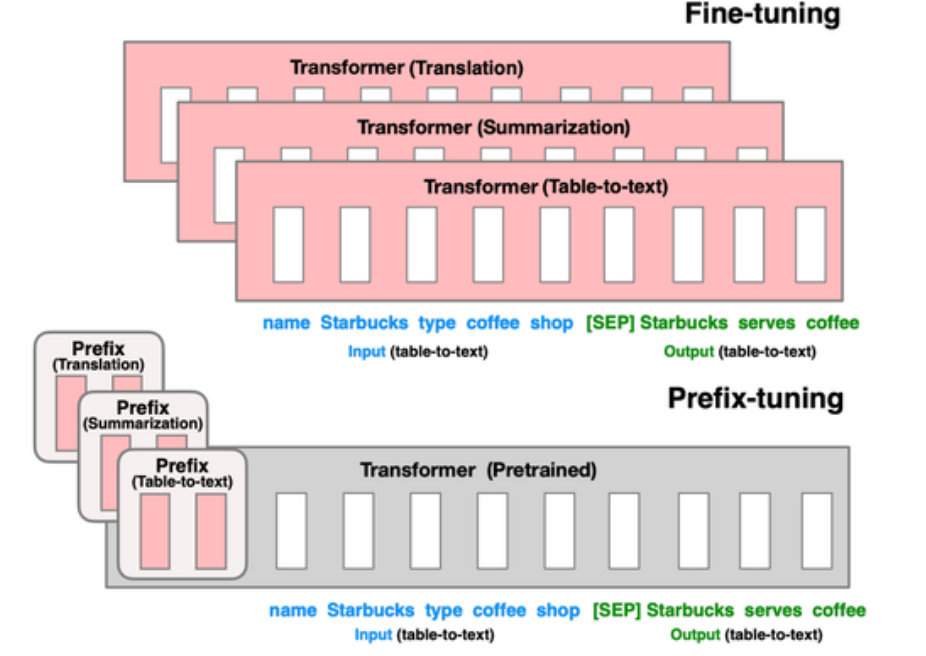
1. 模型格式转换
- 转换命令:
```bash python convert-h5-to-gguf.py --model model_path --output gguf_model_name ``` ``` 支持f16、q4_0、q8_0等量化模式,量化后模型体积缩小75%。2. 工业级部署方案
- Ollama容器化:
```bash ollama build -t custom_model ./Dockerfile ollama run custom_model "生成一段科技新闻" ``` ```支持热更新,冷启动时间<2秒。
- 服务化架构:
前端通过REST API调用,后端采用Kubernetes动态扩缩容。
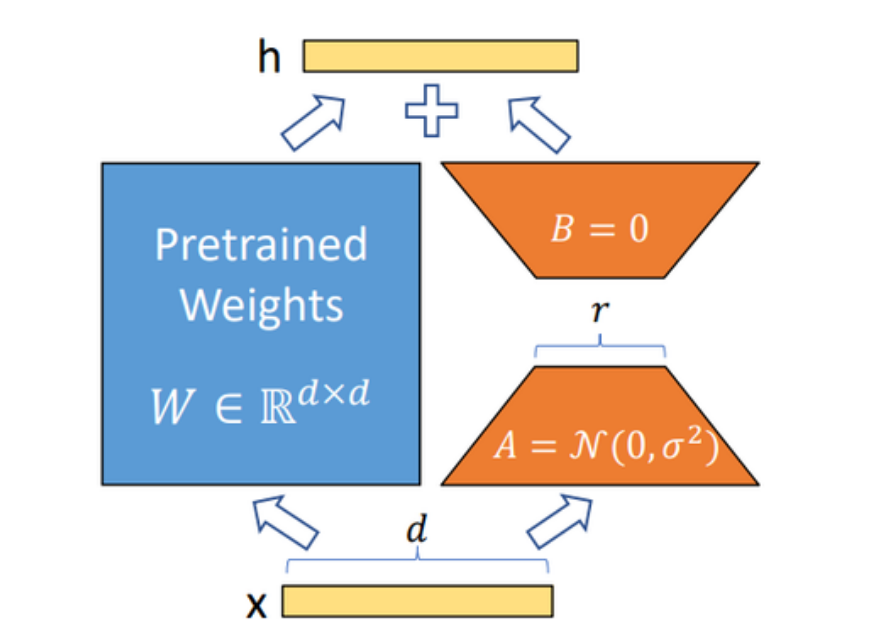
四、性能优化与监控
1. 显存优化技巧
- 启用`torch.compile`加速PyTorch 2.0推理。
- 分块加载模型权重,避免OOM错误。
2. 监控指标
- 训练阶段:Loss曲线、参数更新幅度(通过`wandb`可视化)。
- 推理阶段:延迟(P99<500ms)、吞吐量(QPS>1000)。
五、工业级实践案例
1. 金融知识库问答系统
- 数据:合并10万条财报文本+对话日志,采用RAG架构。
- 部署:通过多Lora合并,单卡支持5个子业务线,成本降低60%。
2. 多语言客服机器人
- 微调策略:中文LoRA+英文QLoRA混合训练,支持中英混合输入。
- 量化部署:q4_0模型在Edge TPU上实现本地化推理。
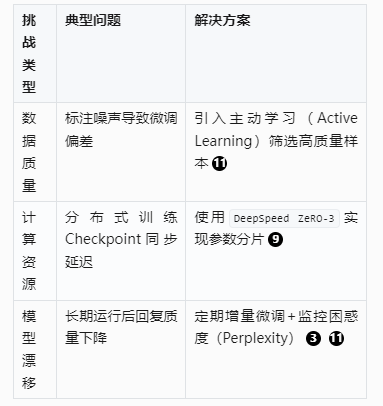
六、挑战与解决方案
附录:完整代码示例与参数调优手册可参考下方二维码内容


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 5
5 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)