Dify的知识库
Dify知识库的建立
目录
一、Dify的知识库上传步骤
1.选择数据源
2.文本分段与清洗
本质上是对数据的预处理,可以更好的服务大模型,从而为用户返回更加精准的答案。
清洗:1.去除噪声数据:非文本内容(标签、特殊符号、乱码、广告)避免污染模型训练污染结果
低价值内容:(过滤一些低价值的停用词:的,是)重复的段落无意义的占位符,可以提 升文本整体的信息密度
2.标准化格式:可以统一编码格式,统一标点符号(全角、半角)修正一些拼写的错误、 确保后续处理的一致性
结构化处理:对于非结构化文本:pdf表格、图片中的文字转化为纯文本,并提取关键字 段,像标题、摘要等
3.提升语义理解:消除歧义、清洗后的文本减少了冗余和干扰,使模型更加容易捕捉核心 的语义。
适配领域需求:对于垂直领域、如医疗、法律可以定制一些清洗的规则。保留专业术 语,去除无关的通用内容。
分段:1.适配模型的输入限制,分段后的文本能够更好的满足模型的输入要求,防止因截断而丢失 掉关键信息。
兼顾到向量化嵌入的效率:分段后的短文本生成的向量更聚焦于单一语义,可以提高相 似性检索的精准度。
2.提升语义的相关性,避免信息的稀释。将内容按主题和段落拆成段落或章节。确保每个 分段聚焦单一语义,便于后续检索时精准匹配用户的问题。
3.优化检索的性能,通过减少冗余计算,根据需求选择单个召回或者是多段合并。从而可 以比较好的平衡精度与覆盖面。
索引方式
本质:设置数据结构,方便后续检索更加精准
嵌入模型索引:支持语义级别的检索
嵌入模型本质:将离散的文本信息转换为数字向量 使用会消耗token(bge-m3)(reddit 社区进行参考要选择什么嵌入模型比较好)
关键字索引
检索相关
向量检索:语义相似度检索
全文检索:关键词检索
混合索引:向量检索和全文检索结合
根据具体场景进行选择
3.处理并完成
二、Dify知识库建立的具体操作
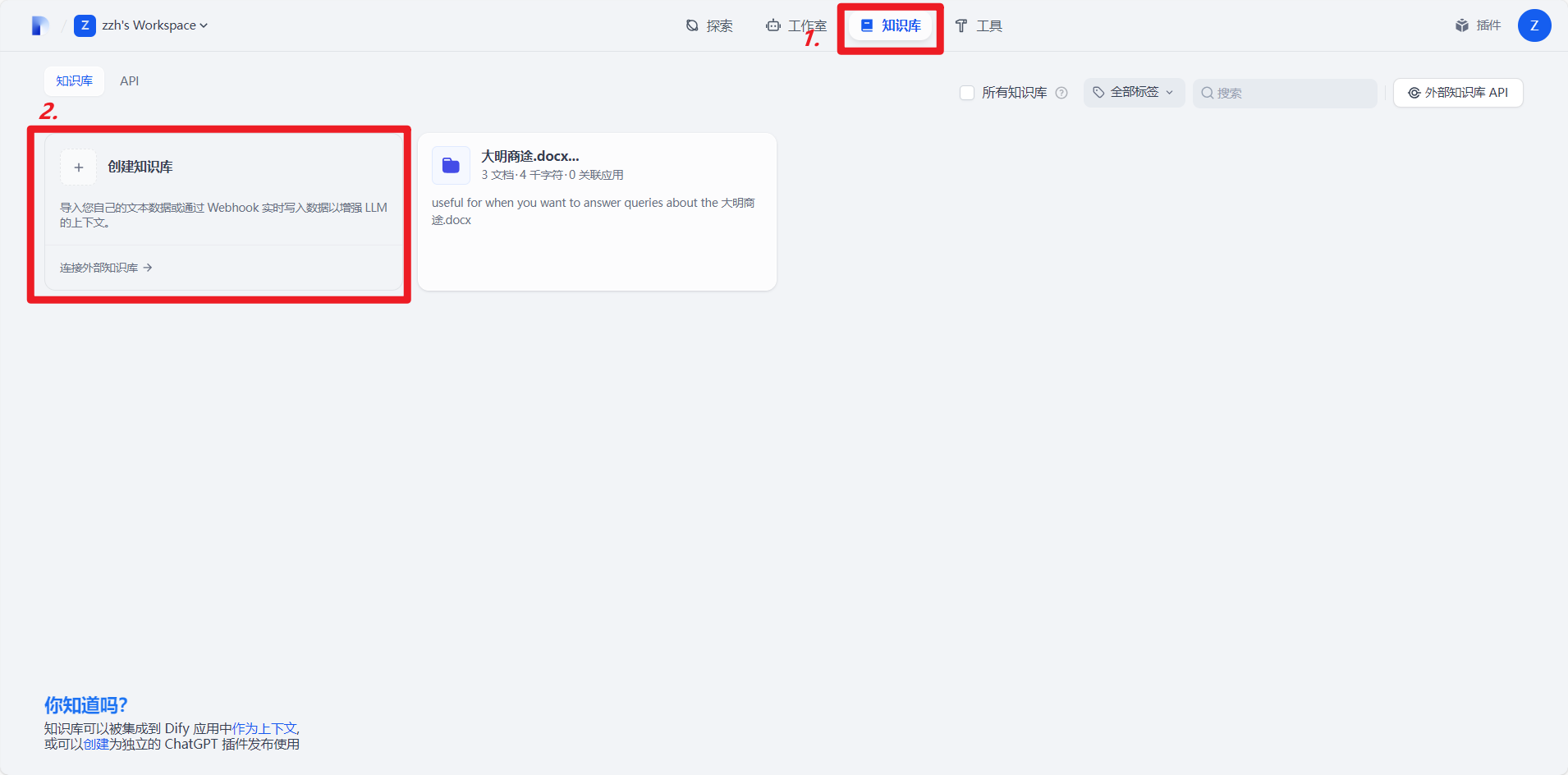
1.打开创建知识库界面
2.上传文件到知识库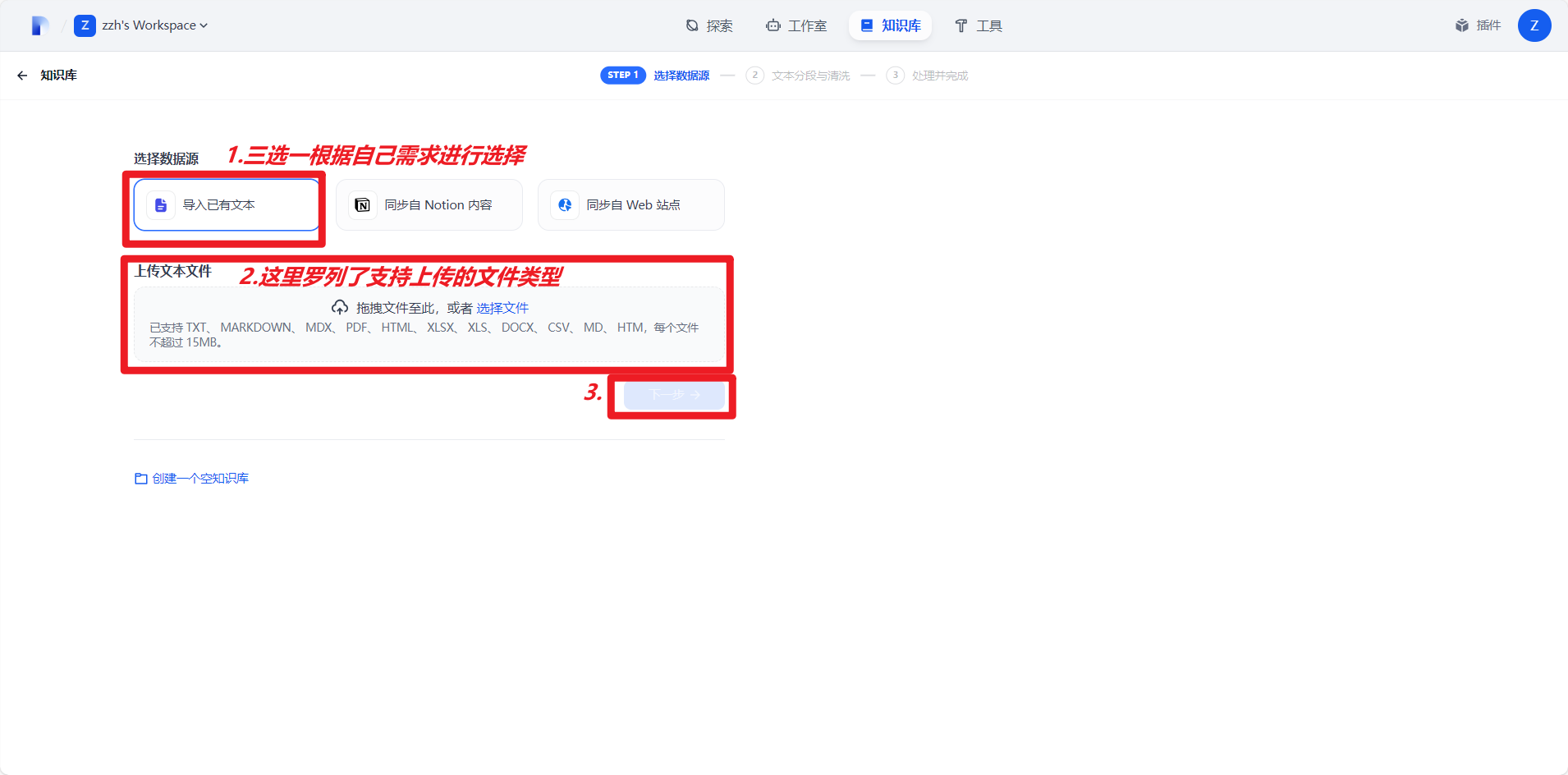
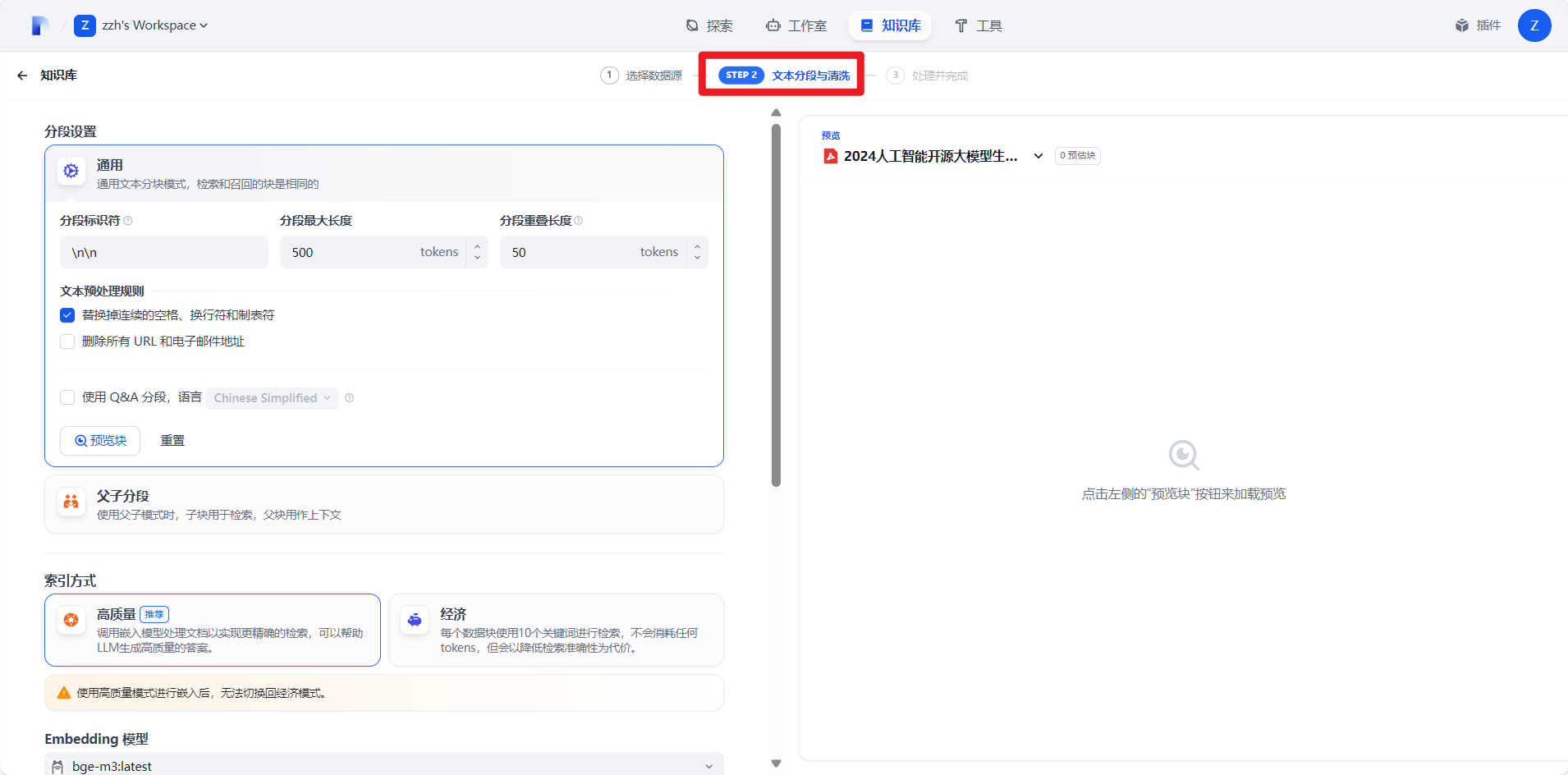
3.分段与清洗
这部分每项设置大概说明在上面都进行了讲述,可以自己根据需求进行设置。这里我们直接使用默认的即可。下拉点击保存并处理按钮即可。
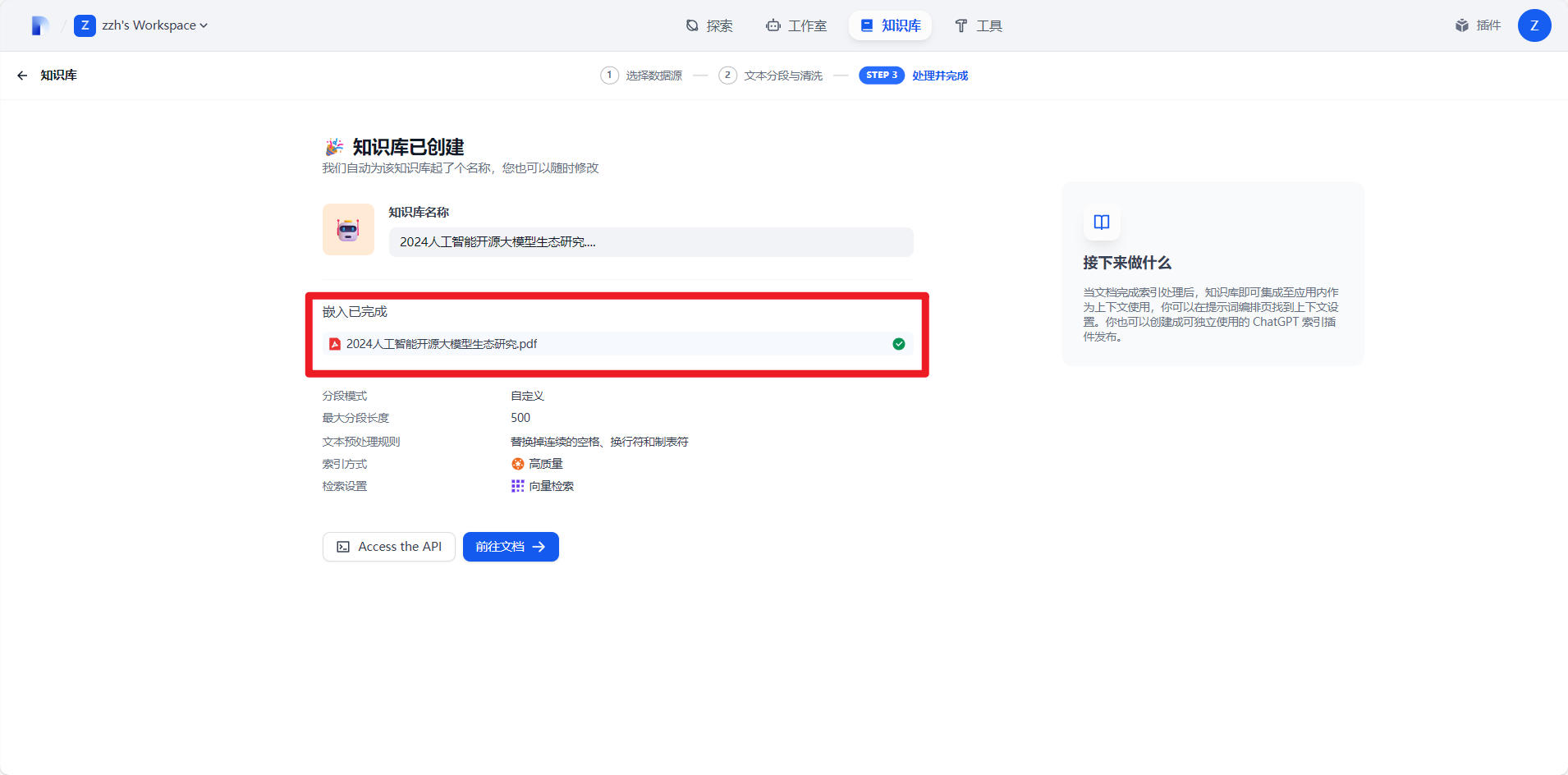
 4.这里要出现嵌入已完成即文件右侧出现绿色√说明上传成功了
4.这里要出现嵌入已完成即文件右侧出现绿色√说明上传成功了
 5.此时我们返回工作室界面
5.此时我们返回工作室界面
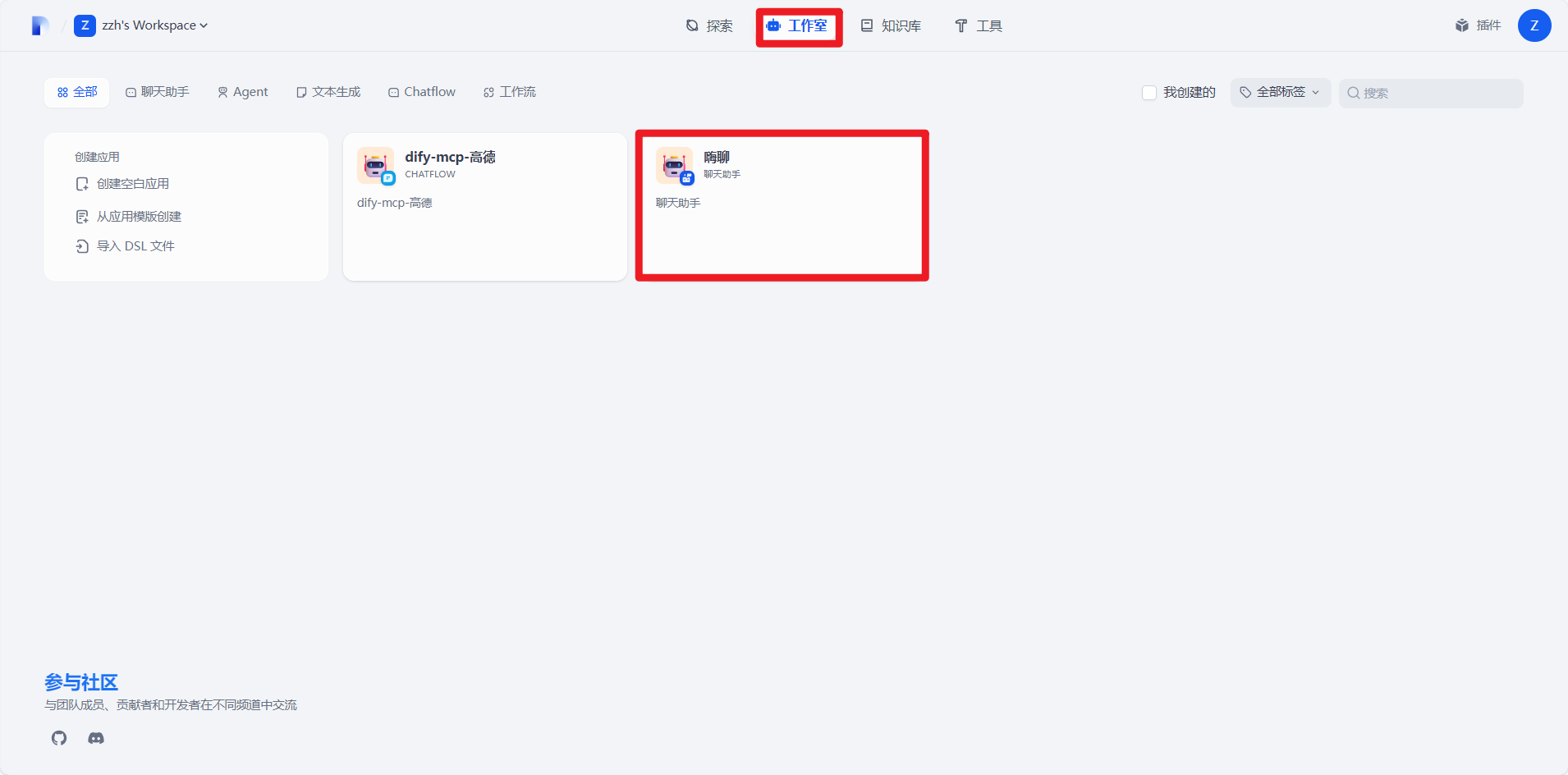 6.对于已经存在的应用我们双击即可跳转到配置界面,如果没有新建应用点击创建空白应用直接进行配置即可。然后在编排界面点击添加知识库即可让自己新建的应用关联自己的知识库。
6.对于已经存在的应用我们双击即可跳转到配置界面,如果没有新建应用点击创建空白应用直接进行配置即可。然后在编排界面点击添加知识库即可让自己新建的应用关联自己的知识库。
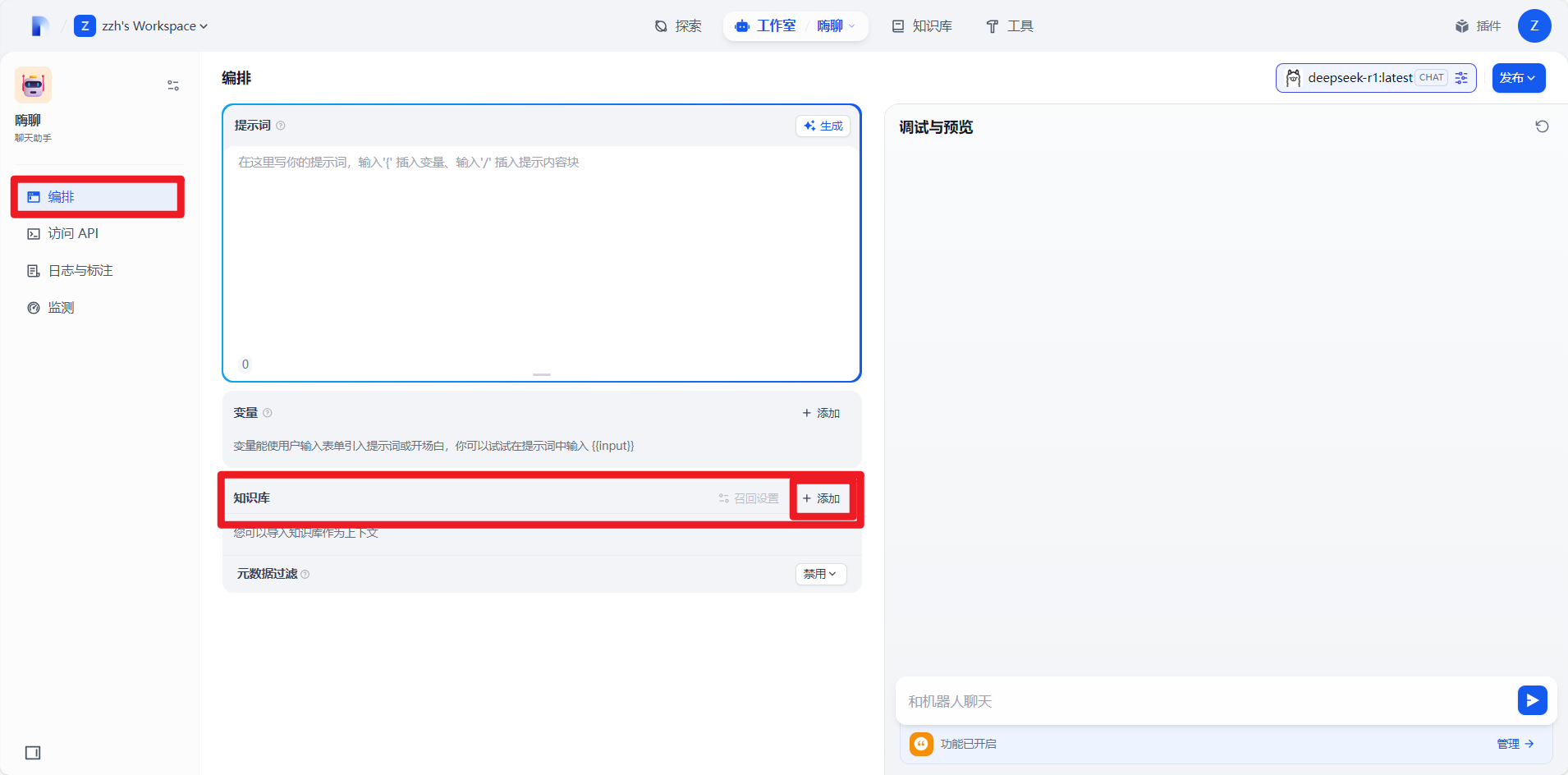 然后点击右上角发布更新或者发布即可。
然后点击右上角发布更新或者发布即可。
tip:dify的意思是do it for you,你知道吗ღ( ´・ᴗ・` )

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)