LLM学习笔记--3.1 Encoder-only PLM
Encoder - only PLM(Pre - trained Language Model,预训练语言模型 ),指仅使用 Transformer 架构中的编码器(Encoder)部分进行预训练和下游任务适配的语言模型。在预训练阶段,模型通过对输入文本的编码学习,捕捉丰富的语言知识和上下文信息;下游任务中,直接利用编码器输出的文本表示,结合简单的任务特定层(如分类层等 )完成各类自然语言处理任务
Encoder - only PLM(Pre - trained Language Model,预训练语言模型 ),指仅使用 Transformer 架构中的编码器(Encoder)部分进行预训练和下游任务适配的语言模型。在预训练阶段,模型通过对输入文本的编码学习,捕捉丰富的语言知识和上下文信息;下游任务中,直接利用编码器输出的文本表示,结合简单的任务特定层(如分类层等 )完成各类自然语言处理任务,不依赖解码器(Decoder)进行生成式操作(与 Encoder - Decoder 架构、Decoder - only 架构区分 )。
典型的Encoder - only PLM模型由BERT(Bidirectional Encoder Representations from Transformers)、RoBERT(A Robustly Optimized BERT Pretraining Approach)、ALBERT(A Lite BERT)、XLNet等。
一、BERT
BERT( Bidirectional Encoder Representations from Transformers ),由Google团队在2018年发布的预训练语言模型,统一了多种思想,其沿承的核心思想包括:Transformer框架、预训练+微调范式。
1. 模型架构
BERT的模型架构是多层Encoder堆叠,每层包含两个关键组件:多头注意力机制、前馈神经网络。其主要结构如图所示:
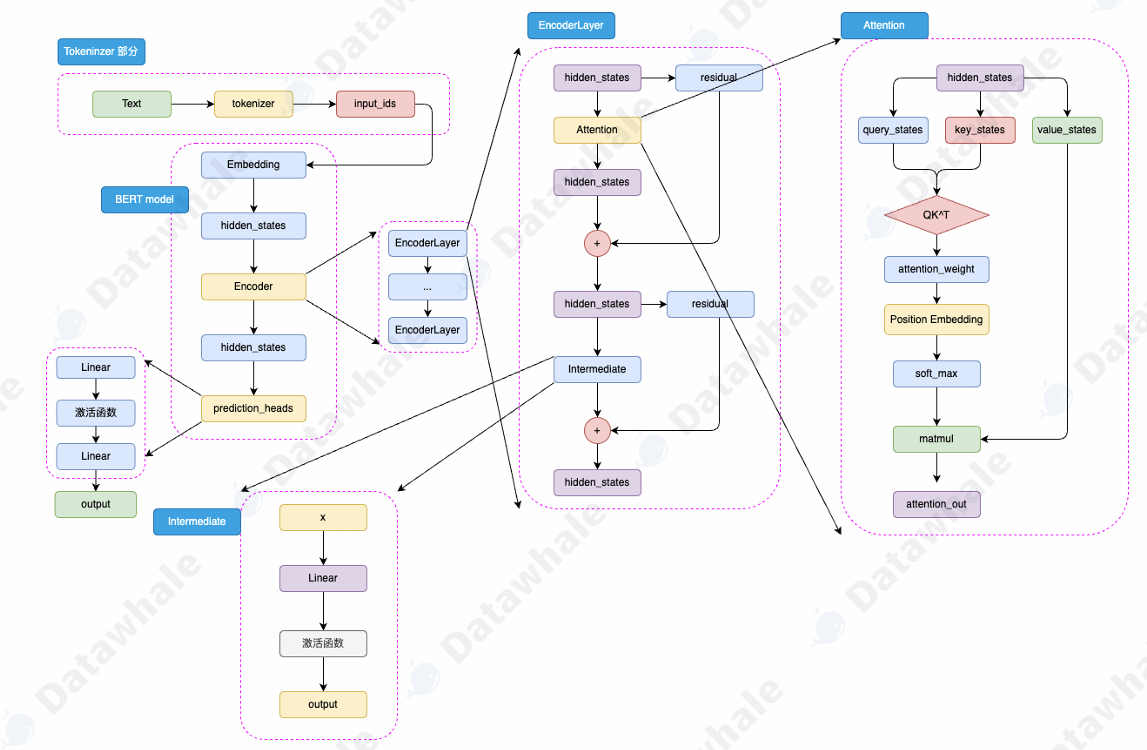
(Encoder结构细节可参考学习笔记2.2 :LLM学习笔记--2.2 Transformer架构.Encoder-Decoder-CSDN博客)
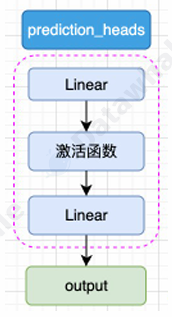
BERT是针对NLU任务的预训练模型,输入为文本序列text,输出为分类标签Lable,模型的输出层由一个分类头prediction_heads,用于将多维度的隐藏状态转换到分类维度,例如一共有两个类别,即分类维度为2,则prediction_heads的输出就是dim=2的向量。
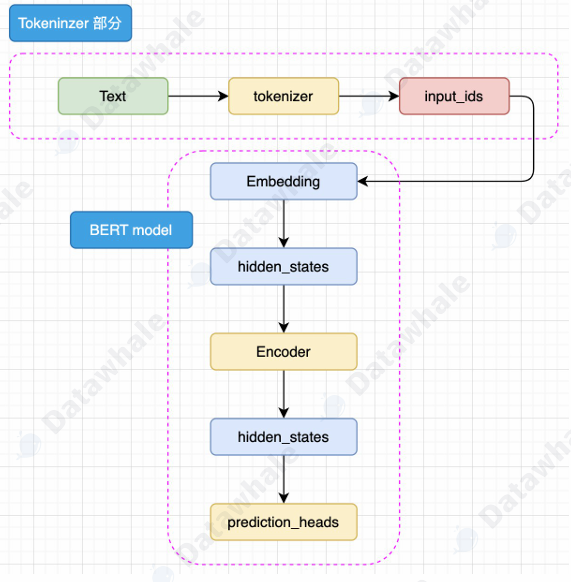
在BERT模型中,输入的文本(Text)首先通过tokenizer(分词器)转化为input_ids,然后进入Embedding层转化为特定维度的hidden_states,再经过Encoder层,这里的Encoder层是多个Encoder_Layer堆叠构成的,通过Encoder编码够的最顶层hidden_states最后经过prediction_heads得到最后的类别概率,经过Softmax输出得到计算模型预测的类别。
接下来给出模型架构中各部分的具体结构实现:
- prediction_heads
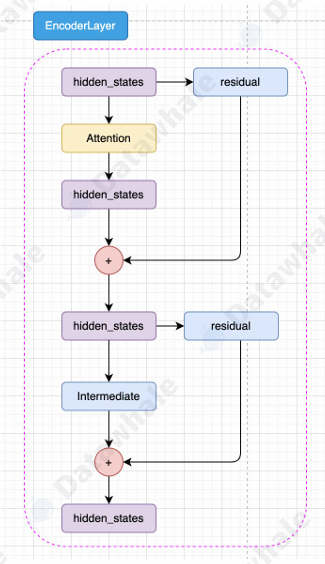
- Encoder_Layer
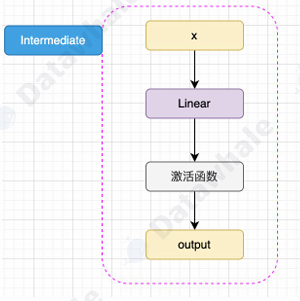
- Intermediate
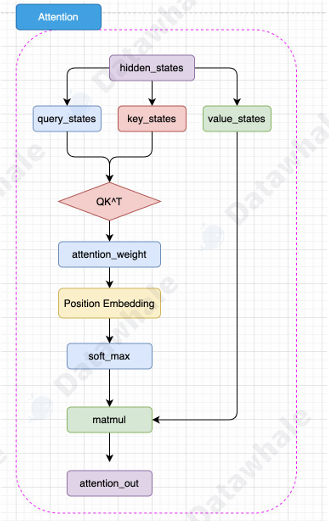
- Attention
2. 预训练任务--MLM+NSP
首先解释MLM和NSP是什么,掩码语言建模(Masked Language Modeling, MLM),下一句预测(Next Sentence Prediction, NSP)。
MLM是为了弥补传统单向语言模型只能利用单侧语境的不足,借助双向语境学习更全面的语义表示,为下游任务储备丰富词汇语义知识。在具体进⾏ MLM 训练时,会随机选择训练语料中 15% 的 token ⽤于遮蔽,按规则替换:80% 替换为特殊标记 [MASK] ,10% 替换为随机词,10% 保持原词不变。例如句子 “猫在追老鼠” ,可能处理为 “猫在追 [MASK]”“[MASK] 在追 老鼠”“猫在 [MASK] 老鼠” 等情况。
让模型根据上下文预测被掩码(或替换、原词)位置的正确词汇,迫使模型学习词与词、词与上下文的语义关联,掌握词汇在不同语境下的含义和用法,像模型需理解 “追” 这个动作的主体、对象常见搭配,从而精准预测 “老鼠” 。
NSP帮助模型掌握文本段落层面的语义逻辑,提升对文本整体的理解能力。其核心思路是要求模型对两个句子的上下文关系进行判断,给模型输入句子对(Sentence A 和 Sentence B ),50% 概率 Sentence B 是 Sentence A 在原始文本中真实的下一句(标记为 IsNext ),50% 概率是从语料库随机选的无关句子(标记为 NotNext )。比如从新闻中取 “科技公司发布新产品”(Sentence A )和 “新产品受用户欢迎”(Sentence B ,IsNext ),或和 “体育赛事精彩回顾”(Sentence B ,NotNext )组成样本。
让模型判断 Sentence B 是否是 Sentence A 的真实下一句,使模型学习句子间的逻辑连贯性、语义关联性,理解文本的篇章结构,比如识别因果、顺承等句子关系。
3. 下游任务微调
完成预训练后,针对每一个下游任务,只需要使用一定量的全监督人工标注数据,对预训练的BERT在该任务上进行微调即可。所谓微调,是在特定的任务、更少的训练数据、更小的batch_size上进行训练,对参数的更新幅度更小。
微调训练过程包括数据准备和参数更新两部分:
- 数据准备:收集下游任务的标注数据,按任务需求格式化(如分类任务需文本 - 标签对,问答任务需问题 - 上下文 - 答案对 ),并进行分词、编码(用 BERT 分词器转换为模型可识别的 token 序列 )、填充 / 截断(保证输入长度统一 )等预处理。
- 参数更新:用下游任务的标注数据,以预训练好的 BERT 参数为初始值,定义损失函数(如分类用交叉熵损失 ),通过优化器(如 AdamW )反向传播更新模型参数(包括 BERT 主体和新增输出层参数 ),使模型在下游任务上的预测结果与标注标签尽可能接近,学习到任务特定的语义模式。
借助预训练阶段学习的通用语言知识,只需少量下游任务标注数据,就能快速训练出高性能模型,大幅降低任务定制模型的成本和难度,且模型在多个任务上泛化性好,能适配不同场景需求。
二、RoBERTa
RoBERTa是由Facebook发布的、在BERT模型基础上进行了优化的预训练模型,在模型架构、预训练策略、数据处理等方面进行了系统性改进,以下是核心优化点的深度解析:
1. 预训练任务优化:去掉NSP,强化MLM
在BERT模型中,NSP任务被质疑过于简单,且可能让模型更关注主题相关性而不是语义连贯性,对下游任务帮助有限。在RoBERTa模型中,完全移除NSP,仅保留MLM任务,专注于提升模型对词级和句级语义的捕捉能力。移除 NSP 后模型在 SQuAD 等问答任务、MNLI 等自然语言推理任务上性能显著提升,证明 NSP 并非必要。
BERT模型使用一次性掩码(静态掩码),同一数据在多轮训练中掩码位置固定。RoBERTa模型使用动态掩码,每次训练时动态生成掩码,即同一文本在不同轮次训练中掩码的位置不同,增强了训练数据的多样性。这种做法避免了模型“记忆”掩码位置,能够使模型真正学习上下文语义。
2.数据与训练策略优化:更大的数据,更长的训练
RoBERTa模型使用了庞大的数据量,高达160G,十倍于BERT模型。增大了batch_size,同时训练过程中全部在512长度长进行训练。这样可以充分利用长文本语境,提升模型对长距离依赖的捕捉能力。
3.词表优化:更大的BPE词表
BPE(Byte Pair Encoding,字节对编码)是Transformer中Tokenizer的编码策略,RoBERTa选择了50K大小的词表来优化模型的编码能力,相比于BERT的30k词表大小,增加了近一倍的数据量。
三、ALBERT
RoBERTa模型是从增大模型规模的方向来优化BERT,而ALBERT模型则是从减小模型的方向来优化。BERT 虽强,但参数量大(如 BERT - Large 有 3.4 亿参数 ),训练和部署成本高,限制在资源有限场景的应用,ALBERT的目标就是让模型更小、更快,既压缩参数量,又不损失性能。
1. 分解 Embedding 参数
在BRET中,Embedding 层的参数矩阵维度大小为,在隐藏层的维度发生改变时,总体维度变化明显,这将极大的增加计算开销。
ALBERT模型将词嵌入矩阵分解为两个小矩阵,解绑 E 和 H,让隐藏层 H 可灵活增大(捕捉更复杂语义 ),同时大幅减少词嵌入参数量。
2.跨层参数共享
分析BERT的各层参数可以得出一个结论,各层参数出现高度一致的情况,这说明在原模型中有大量的参数是重复的,占用空间且占用算力。ALBERT提出让各个Encoder层共享模型参数,以此达到减少模型参数量的目的。在具体实现上,其实就是 ALBERT 仅初始化了⼀个 Encoder 层。
这个优化虽然直观减小了参数量,但是在训练速度以及训练效果上并没有突出的表现。
3.SOP预训练任务
ALBERT改进NSP任务,增加其难度,正例同样由两个连续句⼦组成,负例是将这两个的顺序反过来。这种改进要求模型不仅要拟合两个句子的关系,还要分析清楚句子之间顺序关系。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)