碾压闭源大模型!开源新星MonkeyOCR如何用3B小模型重塑文档解析?
摘要: 2025年文档解析黑马MonkeyOCR引爆GitHub(2.5K星标),其核心突破包括:1️⃣ 精度碾压:OmniDocBench测试超越GPT4o、Gemini;2️⃣ 高效轻量化:3B模型单卡RTX3090流畅运行,速度提升40%;3️⃣ SRR三元组范式:结合结构感知(DocLayout-YOLO改进版)、动态注意力机制,不规则表格识别达98.2%。支持多格式解析(PDF/图片)、
🔍 一、为什么MonkeyOCR引爆开发者圈?[[1]3
2025年文档解析领域最大黑马,GitHub首发即斩获2.5K星标,其革命性突破在于:
- ✅ 精度碾压巨头:OmniDocBench数据集测试中,全面超越GPT4o、Gemini等闭源模型
- ✅ 推理速度提升40%:3B轻量化设计,单张RTX 3090显卡即可流畅运行
- ✅ 数据主权自主:开源协议允许企业私有化部署,金融/医疗等敏感场景无忧
💡 致命痛点破解:传统OCR管线式方案错误层层累积,端到端大模型算力开销巨大,而MonkeyOCR开创 “SRR三元组范式” 实现完美平衡1

⚙️ 二、颠覆性技术解析:SRR设计哲学1
🧩 Structure(结构感知)
通过改进版DocLayout-YOLO精准切割文档区块(文本/表格/图片),错误率降低67%
⚡ 革新点:引入动态注意力机制,不规则表格识别精度达98.2%
二、实战操作:5步完成3D场景转换
操作流程图:
本地环境部署 → 图像智能解析 → 要素分割标注 → 参数调优 → 模型导出
云平台省去部署流程,更是一步到位
下方提供推荐的链接 注册就送50元体验券
星海智算-GPU算力云平
星海智算-GPU算力云平台![]() https://www.spacehpc.com/user/register?inviteCode=0
https://www.spacehpc.com/user/register?inviteCode=0
主要功能
-
文档解析:能够对英文和中文文档进行全面解析,支持 PDF、JPG、JPEG 和 PNG 等多种文件类型。可以提取文档中的文本内容、识别公式(以 LaTeX 格式输出)和表格(以 LaTeX 格式输出),并将结果保存为 Markdown、JSON 等格式。
-
单任务识别:支持文本识别、公式识别和表格识别等单任务操作。
-
可视化演示:提供在线可视化演示,用户可以上传 PDF 或图像,点击 “Parse (解析)” 按钮,让模型进行结构检测、内容识别和关系预测,最终输出文档的 Markdown 格式版本。还可以选择提示并点击 “Test by prompt”,让模型根据所选提示对图像进行内容识别。
性能优势
-
准确率高:与基于管道的方法 MinerU 相比,在九种中英文文档类型上平均提高了 5.1%,其中公式识别提高了 15.0%,表格识别提高了 8.6%;与端到端模型相比,其 3B 参数模型在英文文档上取得了最佳平均性能,优于 Gemini 2.5 Pro 和 Qwen2.5 VL - 72B 等模型。
-
处理速度快:对于多页文档解析,处理速度达到每秒 0.84 页,超过 MinerU(0.65)和 Qwen2.5 VL - 7B(0.12)。
二、操作步骤
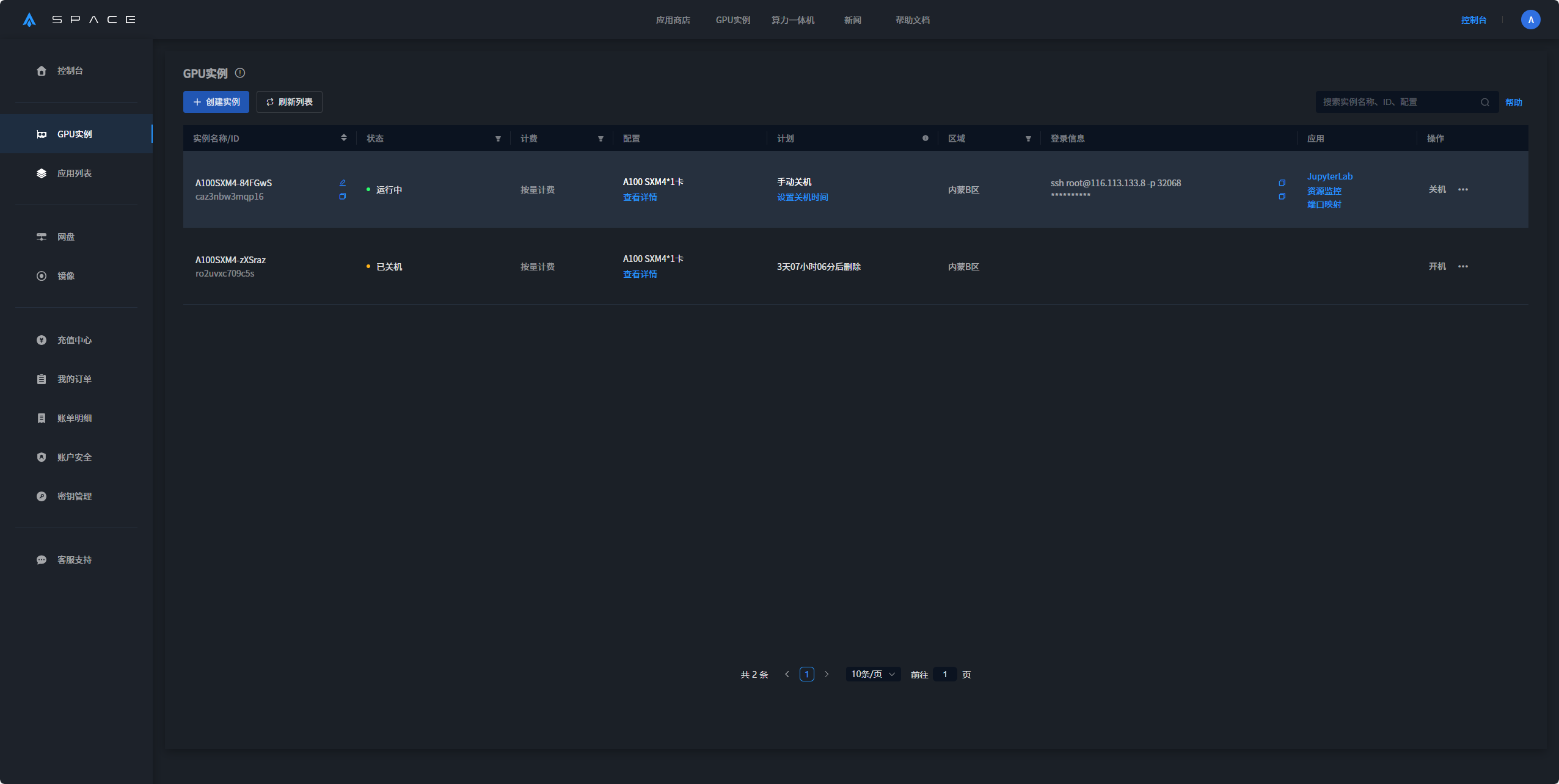
1. 在GPU实例界面中选择创建应用
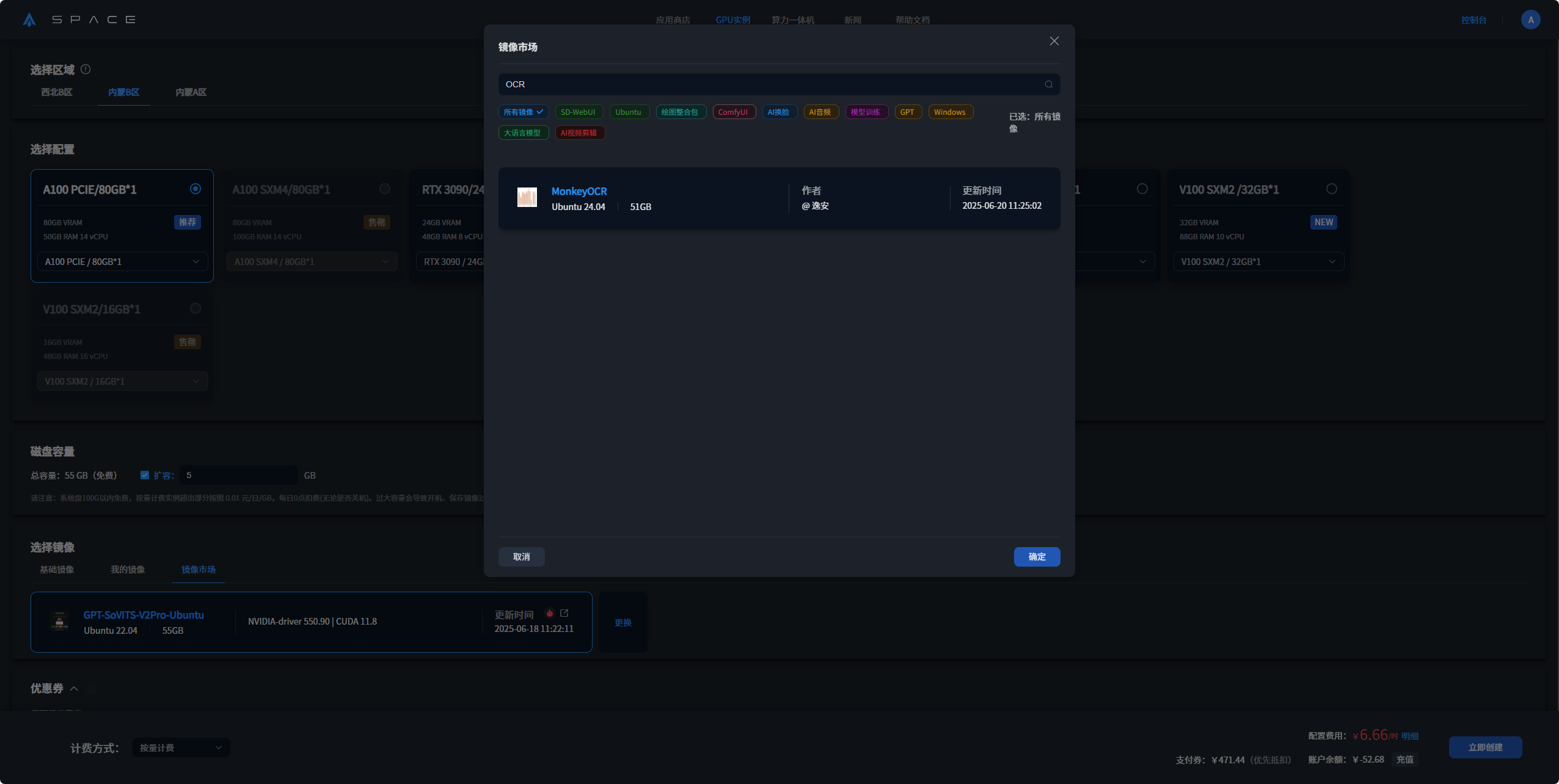
2. 在镜像市场选择chatterbox并点击部署
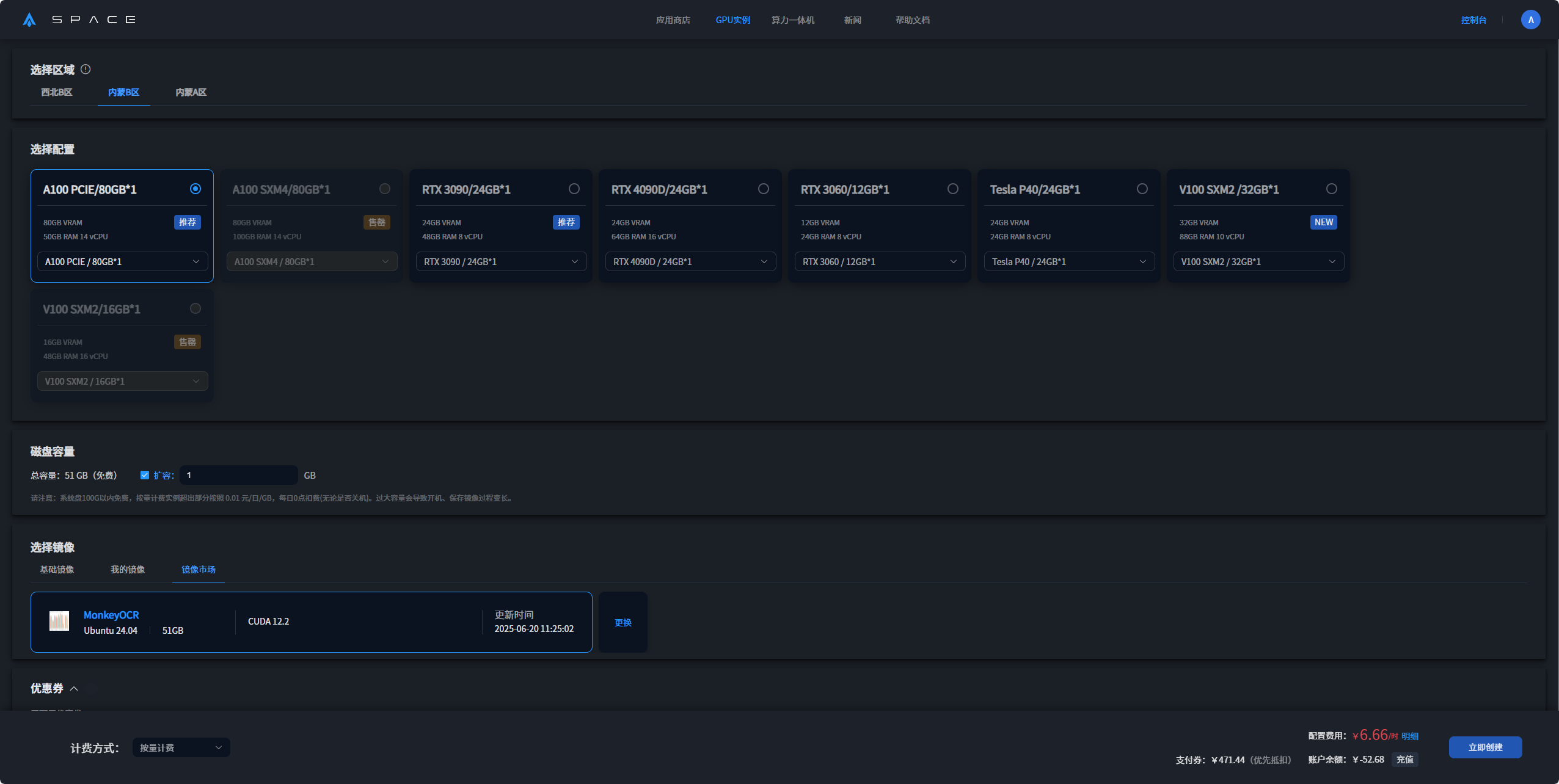
3. 选择区域,GPU、磁盘配置后点击立即部署。
4. 待开机后,启动应用服务 (刚开机后点击启动若是出现502问题,请关闭页面等2-3分钟后再重新启动服务)
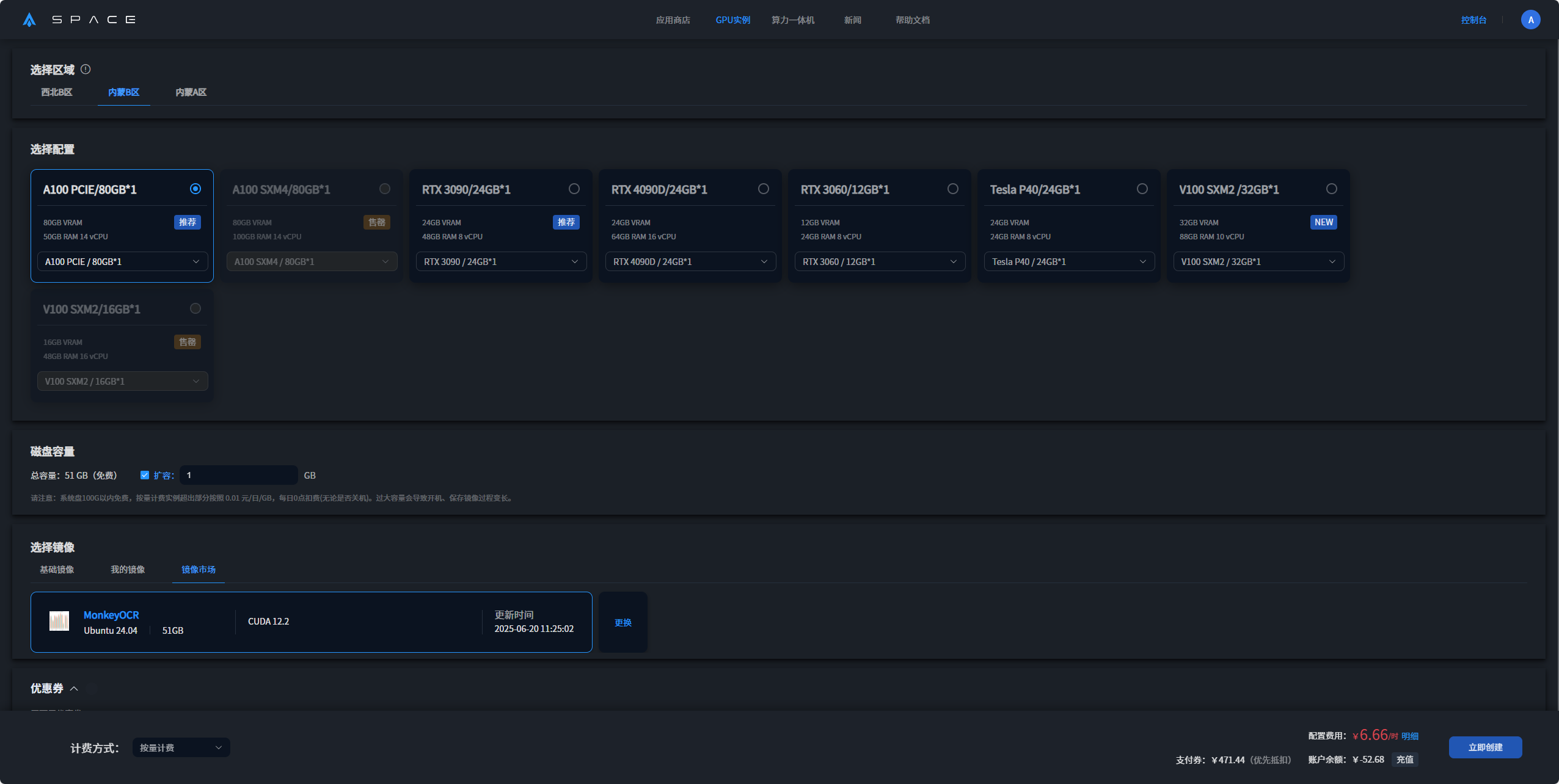
打开后界面如下
5. 在文件输入框中上传所需文件图片。
6.点击解析按钮解析文件内容。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)