重生学AI第十二集:内置数据集和DataLoader
我拿来用的是数据集:CIFAR10root:将数据集存放在哪里True: 下载的是训练数据集(训练模型使用)False: 下载的是测试数据集(测试模型是否学会,和训练集的数据不同)transform:对数据集做哪些操作target_transform :对标签做哪些操作download :若数据不存在是否从官网下载(因为这里的数据集也是可以通过第三方渠道下载后直接引用的)DataLoader简单来
1.内置数据集
今天学习Pytorch的内置数据集,这样就不用担心数据集的问题了
1.认识数据集
下载之前我们可以先去官网看看有哪些数据集,以及这些数据集的详情
1.先到官网找到Docs - Domains
2.然后网页下方会出现一堆选项,选择torchvision
3.然后一直往下,找到内置数据集
4.点开之后就是各种数据集的介绍
5.点开数据集,就有这个数据集的参数和说明
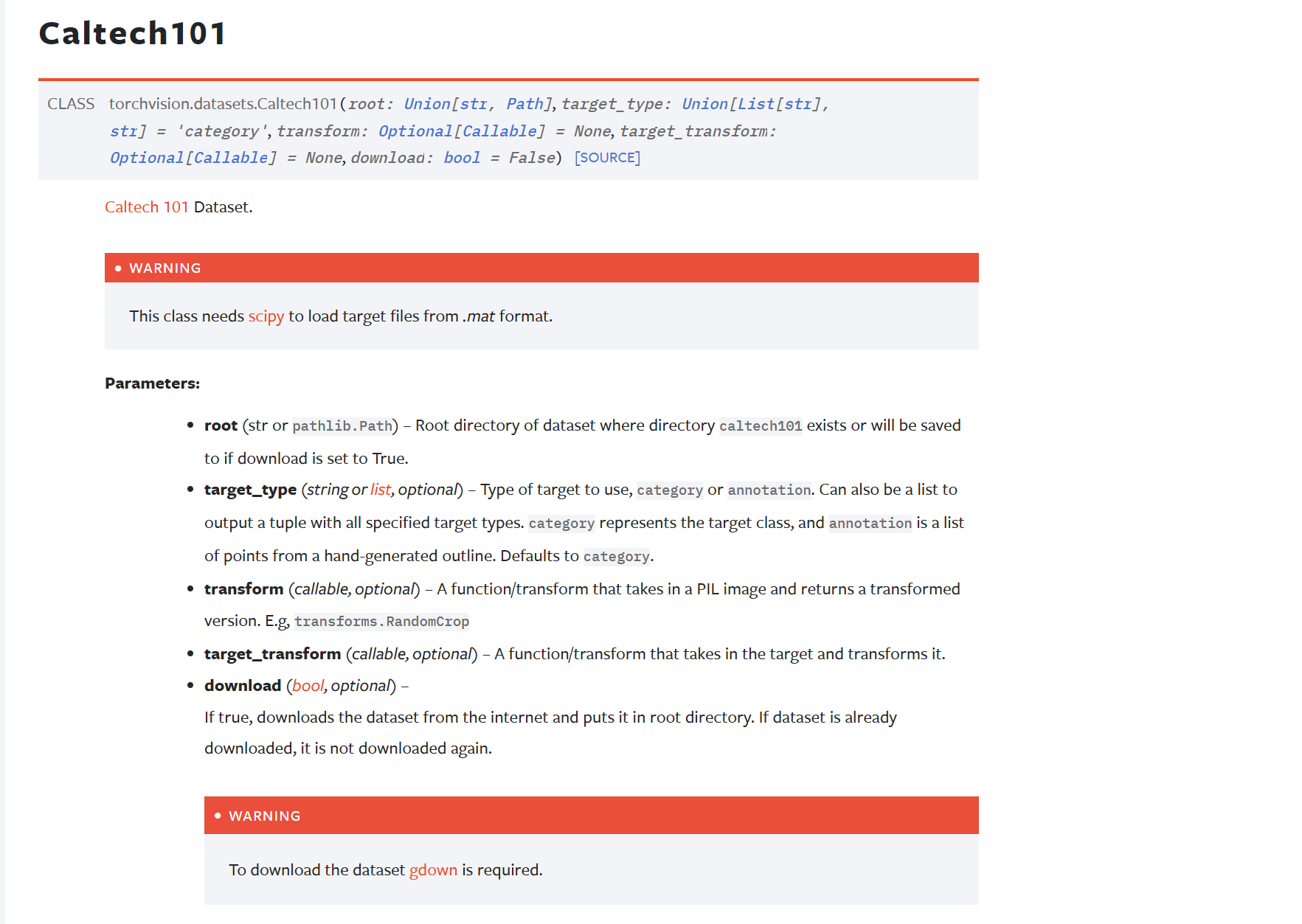
我拿来用的是数据集:CIFAR10
参数:
- root:将数据集存放在哪里
- train:True or False
- True: 下载的是训练数据集(训练模型使用)
- False: 下载的是测试数据集(测试模型是否学会,和训练集的数据不同)
- transform:对数据集做哪些操作
- target_transform :对标签做哪些操作
- download :若数据不存在是否从官网下载(因为这里的数据集也是可以通过第三方渠道下载后直接引用的)
2.下载数据集
直接在Pycharm里面下载就可以了
#下载训练集
train_set = torchvision.datasets.CIFAR10(
root="./dataset",
train=True,
download=True
)
# 下载测试集
test_set = torchvision.datasets.CIFAR10(
root="./dataset",
train=False,
download=True
)下载是个缓慢的过程

下载完成
3.查看数据集数据
这个时候可以看一下数据集中的数据

数据分两部分,逗号前面是图片数据,后面是标签的下标,通过classes属性可以查看标签集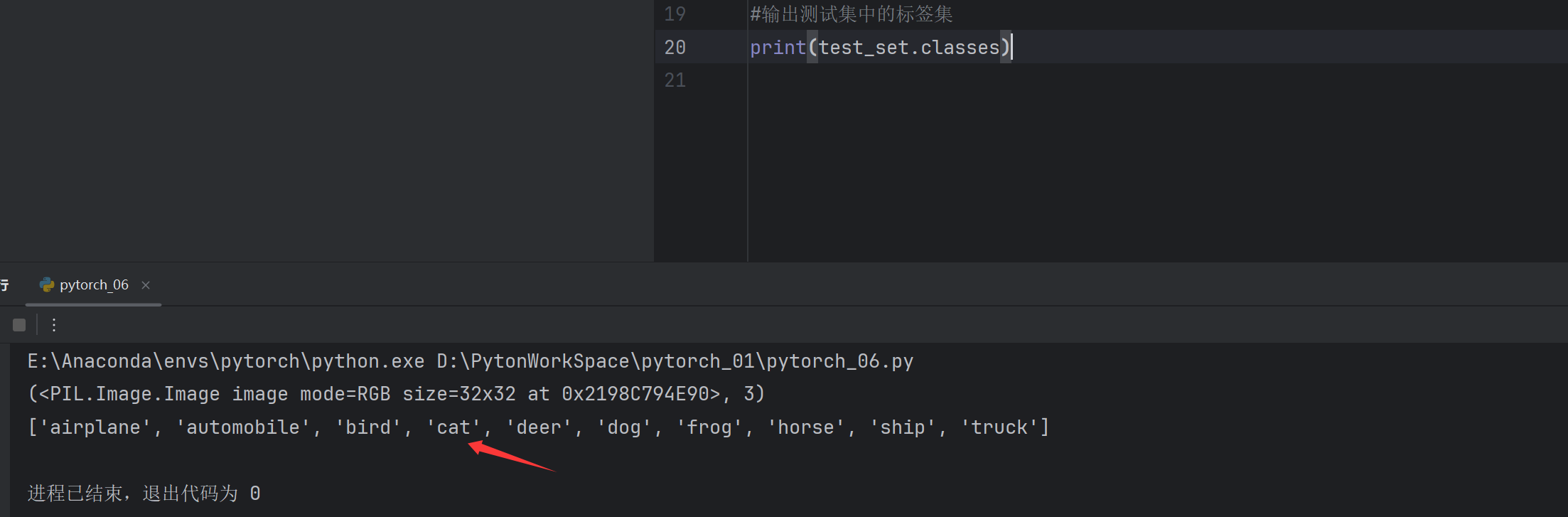
3对应的是猫,可以用img.show()看看是不是一只猫
img,target=test_set[0]
img.show()但是图片太小了,看不清楚,不过从轮廓上能模糊的感觉到是一只猫

看下一张

标签是8,对应ship,这张就很明显了,是一只船

4.写入tensorboard
接下来把数据集的数据写入到tensorboard
1.先创建一个transform
#创建transform转换tensor数据
tsfm_to_tensor= torchvision.transforms.ToTensor()
2.将transform加入到测试集的参数里
# 下载测试集
test_set = torchvision.datasets.CIFAR10(
root="./dataset",
train=False,
#加入transform转换tensor操作
transform=tsfm_to_tensor,
download=True
)3.循环写入tensorboard
writer = SummaryWriter("tb_test_set")
#写入数据集的前十张图片
for i in range(10):
img,label = test_set[i]
writer.add_image("test_set", img, i)
writer.close()4.打开tensorboard
因为tensorboard的文件夹换名字了,所以打开tensorboard的命令也要换一下

5.写入成功
不同的数据集需要的参数可能也会不同,用之前可以先问问AI,关于这个数据集的详情和示例,方便我们学习
6.第三方下载
对了,如果因网速问题,下载数据集太慢的话,可以按住ctrl键,进入数据集函数的内部查看URL链接,复制到迅雷下载
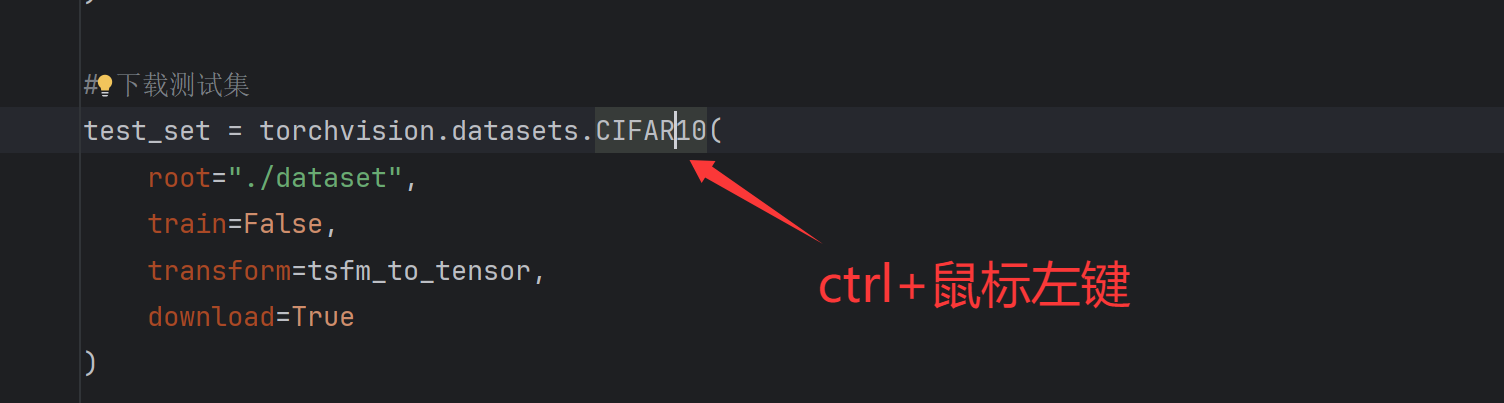

下载完直接复制到项目路径下
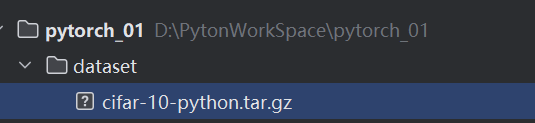
运行代码

很丝滑,可以用,不用再下载了
2.DataLoader
1.简介:
DataLoader简单来说就是一个加载器,他能够按照你的要求将数据加载到模型里
参数:
- dataset:数据集,就像前面的test_set,当然也可以是自定义的数据集
- batch_size:每次加载的样本数量
- shuffle:是否打乱顺序(如果一个数据集我们要加载两遍,第二遍是否按照相同的顺序)
- num_workers:子进程数,windows一般为0,不用改
- drop_last:假设一共有82张图,每次加载9张,最后1张是否需要加载
2.代码实现:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision.utils import make_grid
#创建测试数据集
test_set = torchvision.datasets.CIFAR10(root="dataset", train=False, transform=torchvision.transforms.ToTensor())
#创建测试数据加载器
test_loader = DataLoader(dataset=test_set, batch_size=36, shuffle=True, num_workers=0,drop_last=False)
writer = SummaryWriter("logs")
index = 0
#循环写入tensorboard
for data in test_loader:
imgs, labels = data
#把36张图片进行拼接,每行显示6张
img_grid = make_grid(imgs, nrow=6)
writer.add_image("test_img", img_grid, index)
index += 1
writer.close()网页展示:
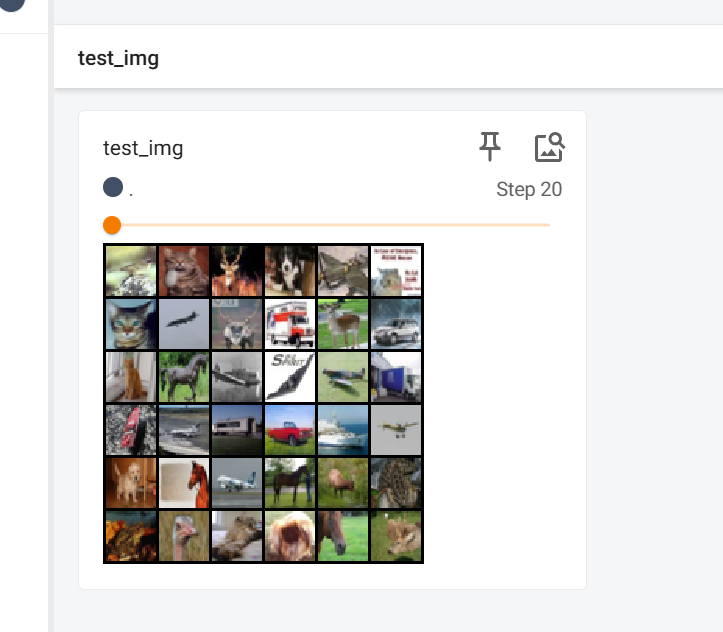
最后的图片不足36张,也展示了出来
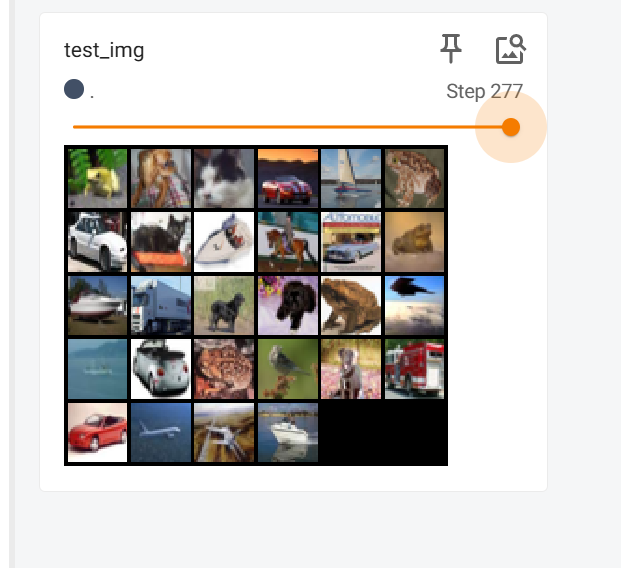
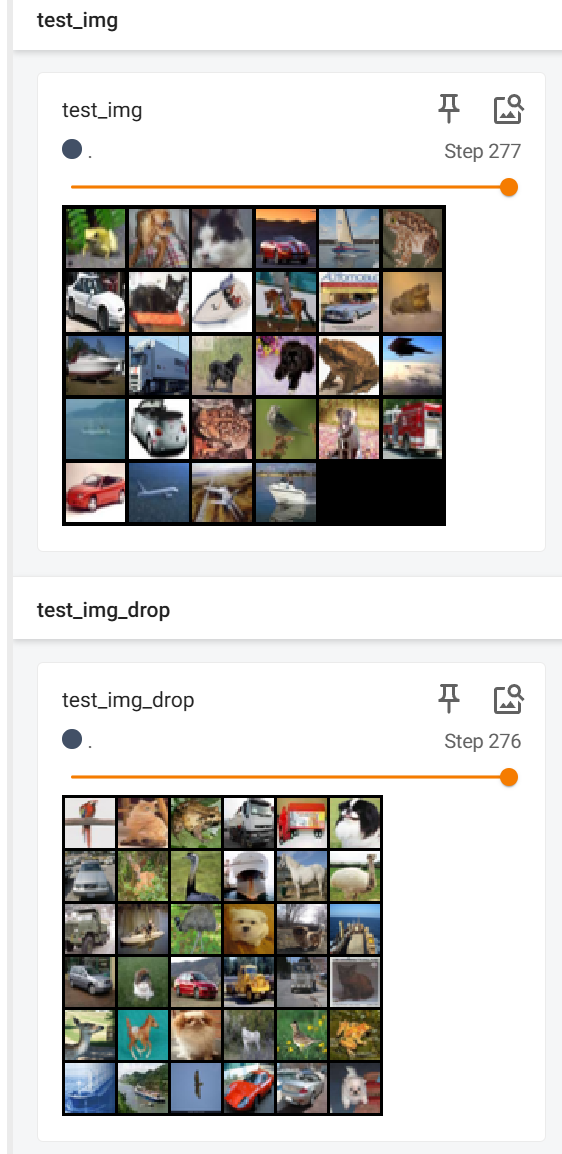
3.drop_last
把drop_last改成True试一下
步数变少了,最后一步显示的变成了36张图片
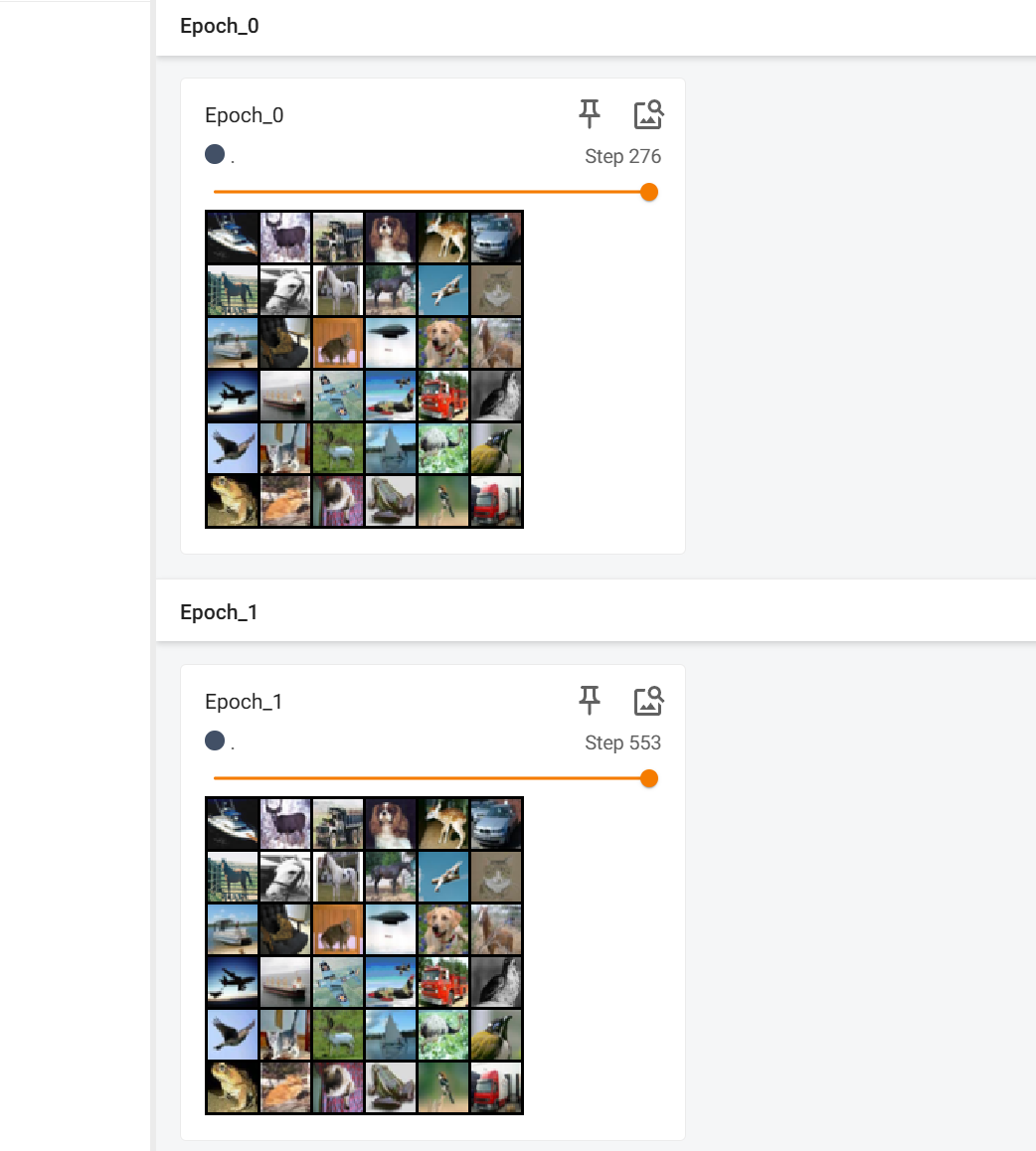
4.shuffle
把shuffle改成False,意味着运行两遍不打乱顺序,运行两遍试一下
#创建测试数据加载器
test_loader = DataLoader(dataset=test_set, batch_size=36, shuffle=False, num_workers=0,drop_last=True)
writer = SummaryWriter("logs")
index = 0
for epoch in range(2):
#循环写入tensorboard
for data in test_loader:
imgs, labels = data
img_grid = make_grid(imgs, nrow=6) # 每行显示6张
writer.add_image("Epoch_{}".format(epoch), img_grid, index)
index += 1
writer.close()也比较容易能看出来图片的位置都没有改变
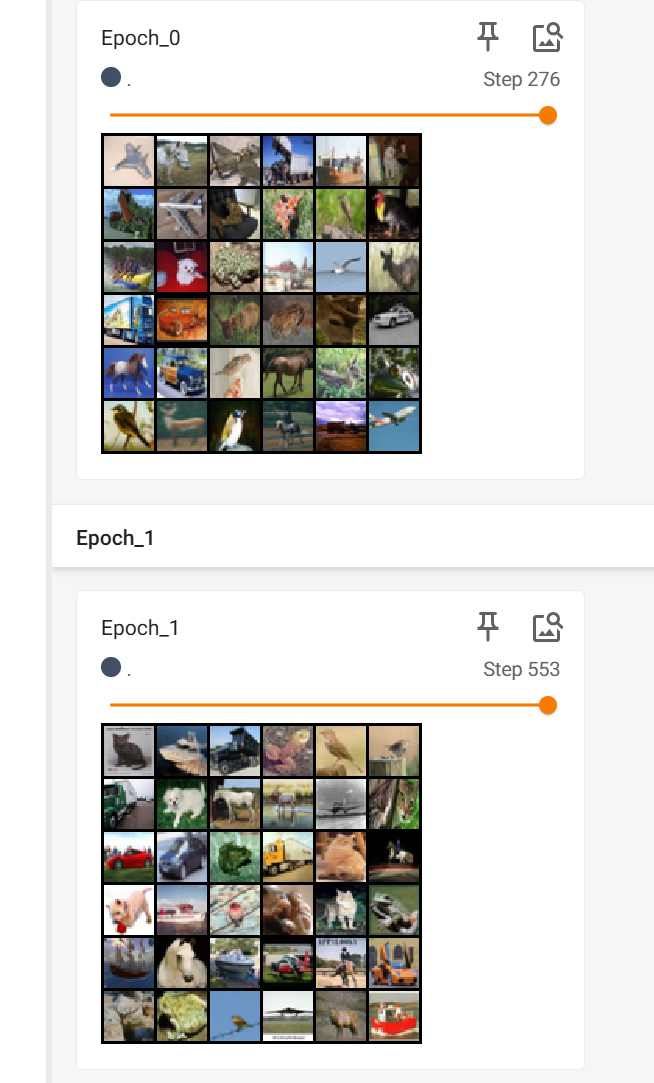
再改成True运行一下
#创建测试数据加载器
test_loader = DataLoader(dataset=test_set, batch_size=36, shuffle=True, num_workers=0,drop_last=True)
writer = SummaryWriter("logs")
index = 0很明显,顺序已经被打乱了
又是充实的一天,拜拜


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)