SCHEMA-R1:一种用于文本到SQL任务中模式链接的推理训练方法
本文提出Schema-R1模型,通过强化学习提升文本到SQL任务中的模式链接推理能力。针对现有监督微调方法过度优化真实结果而牺牲推理能力的问题,作者设计了三阶段训练框架:1)利用商业大模型生成高质量推理样本;2)进行监督微调实现冷启动;3)基于规则的强化学习训练优化推理路径。实验表明,该方法在Spider-dev数据集上的表列过滤准确率比现有方法提升10%。创新点在于将强化学习引入模式链接任务,有
Wuzhenghong Wen, Su Pan, Yuwei Sun
南京邮电大学物联网学院 南京
中国
{Wuzhenghong Wen, Su Pan, yuwei Sun}2022070804@njupt.edu.cn
摘要
模式链接是文本到SQL任务中的关键步骤,旨在根据给定的问题准确预测SQL查询所需的表名和列名。然而,当前用于模式链接模型的微调方法采用死记硬背的学习范式,过度优化真实模式链接结果,而牺牲了推理能力。这一局限性源于难以获取高质量的下游任务推理样本。为了解决这个问题,我们提出了Schema-R1,这是一种使用强化学习进行训练的推理模式链接模型。具体来说,Schema-R1包括三个关键步骤:构建小批量高质量推理样本、冷启动初始化的监督微调以及基于规则的强化学习训练。最终结果显示,我们的方法有效提升了模式链接模型的推理能力,在过滤准确性方面比现有方法提高了10%。我们的代码可在https://github.com/hongWin/Schema-R1/获得。
关键词 文本到SQL ⋅\cdot⋅ 推理模型 ⋅\cdot⋅ 微调
1 引言
文本到SQL是一项自然语言处理(NLP)任务,它将自然语言问题转换为结构化查询语言(SQL)。这一过程明确或隐含地涉及:模式链接、SQL生成、编码增强和自我修正 [1, 2]。模式链接是文本到SQL中的关键步骤,系统在此筛选与用户自然语言问题最相关的数据库表和列,以支持精确的SQL生成 [3]。
根据现有研究,为了实现文本到SQL的目标,模式链接任务可以隐含地融入文本到SQL的推理过程中 [4, 5, 6, 7],或者可以通过额外的模式链接生成模型显式构建 [8, 9, 10, 11]。然而,虽然将模式链接隐式集成到SQL生成中可以确保推理的一致性,但它使错误模式链接的有效监督信号的构建变得复杂,从而使得纠正变得困难。因此,将模式链接从SQL生成中分离出来并采用流水线方法增强了可解释性,并促进了文本到SQL任务中的错误修正。[8, 9, 10] 利用提示工程技术,将商业大型语言模型(LLM)作为模式链接模型来预测潜在的数据库表和列。尽管这些商业模型受益于广泛的知识库和强大的训练数据,但在处理具有复杂结构和严格隐私要求的大规模数据库时,它们的应用往往遇到显著限制。因此,为了在保持强大适应性的同时确保数据隐私,开源LLM正逐渐成为垂直领域中的关键合作者 [12]。监督微调(SFT)已成为赋予这些开源模型专门领域知识的主要方法。[13, 11, 14, 15, 16] 使用监督微调(SFT)在开源LLM上训练特定的模式链接模型用于文本到SQL任务。训练流程如图1所示:如图1所示,直接使用监督微调(SFT)构建目标导向的模式链接模型会导致教科书式的训练方式。这导致模型在监督目标上过拟合,而在推理期间失去其固有的推理能力。然而,构建基于思维链(CoT)[17] 的微调监督目标受到有限的高质量CoT样本可用性的限制 [18]。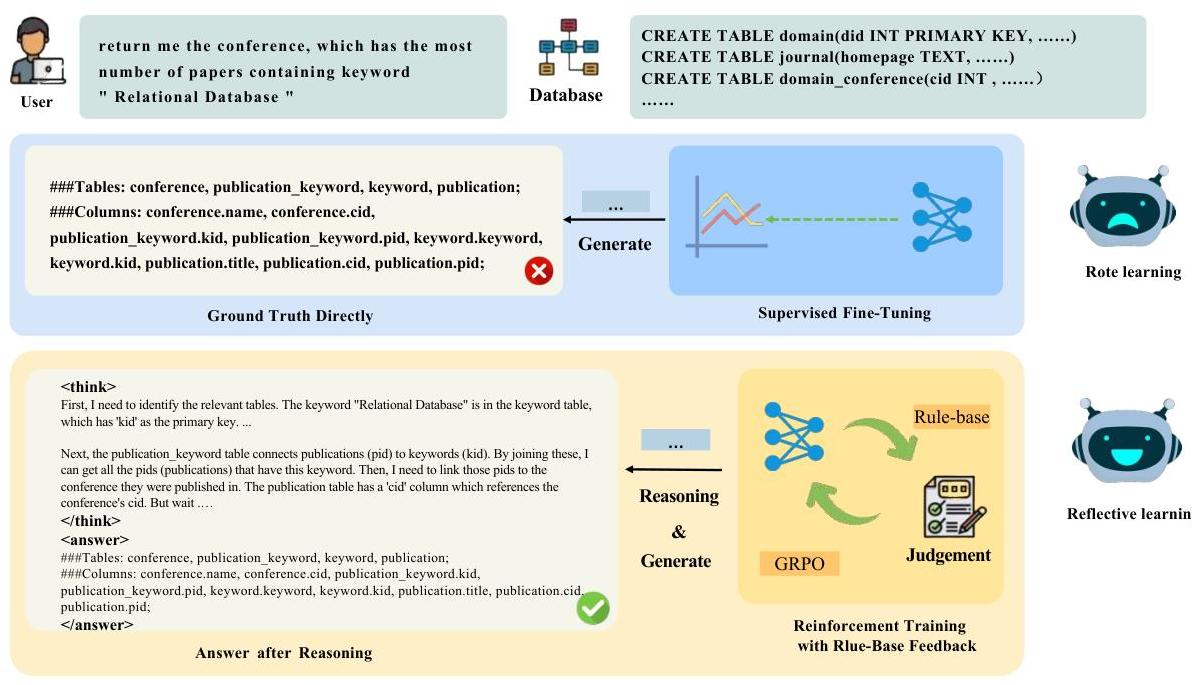
图1:SFT和推理RL在模式链接下游任务调优中的差异
用于推理训练的强化学习(RL)在自生成推理和对各种LLM应用中的下游任务稳健适应方面展示了卓越的能力。如在推理强化学习[19, 20, 21]中的实施,这种方法生成多个推理路径,并采用群体优化策略来增强高奖励轨迹,同时抑制低奖励轨迹。与仅优化单一目标的监督微调(SFT)相比,用于推理训练的RL在下游任务训练中表现出更强的鲁棒性。
为了开发一个具有强大推理能力的模式链接模型,我们提出了Schema-R1,这是一种实现三阶段训练框架的新方法:*基于提示的知识增强:我们首先设计了一组提示模板,利用商业LLM根据真实的模式链接信息生成连贯的推理信息,有效弥补了缺失的推理信息。*监督微调用于冷启动:然后仔细选择一小部分数据集样本,构建SFT任务,每个训练实例包含问题、数据库模式、推理信息和真实的模式链接信息,使模型能够学习适当的输出模式。*用于推理训练的强化学习(RL):我们以SFT后的模型作为参考,采用GPRO动态捕捉训练过程中的表和列预测准确性,建立相应的奖励信号。这引导模型逐步偏好更高奖励的推理路径,同时提升其推理能力。实验结果表明,在Spider-dev数据集中,我们的方法在表和列的过滤准确性方面均比最先进的基于微调的模式链接方法提高了至少10%。总之,我们的贡献可以概括如下。
*弱推理模型初始化:通过在有限样本上的提示工程,我们结合监督微调(SFT)使用商业LLM开发了一个具有基本推理能力的初步模式链接模型,该模型严格遵循指令约束。
*Schema-R1:高级推理模型:我们提出了Schema-R1,这是一种强大的推理增强型模式链接模型,通过少量样本进行冷启动微调,并通过我们新颖的推理RL框架进行自我优化,以改进CoT。
2 相关工作
模式链接模型早期关于模式链接模型的研究主要集中在开发基于编码器-解码器的架构。例如,[22]使用编码器对问题和目标数据库进行编码,目的是训练模型捕捉不同问题中表格和列的相关性。同时,[23]利用多个解码器同时解决文本到SQL的各种子任务。与这些方法不同,[24, 25]编码模式图以表示数据库内的连接信息,然后使用解码器推断潜在的模式信息。随着商业和开源LLM在推理和知识能力方面的不断增强,越来越多的研究利用提示工程来增强这些模型的推理能力,并将其应用于模式链接任务。[26]探索了GPT-4在零样本方法下的模式链接模型性能,而[8]采用了N样本方法。[9, 27]使用多个提示生成模式链接信息,然后聚合多个推理路径得出最终答案。同样,[10]利用自生成的CoT推理来提高获得最佳模式链接结果的概率。与这些方法相反,[28, 29]首先生成SQL查询,然后反向推断模式链接信息。
尽管商业LLM在各种开源任务中表现出色,但当应用于私有数据库或高度专业化的领域时,通常需要使用开源模型进行监督微调(SFT)。一些研究利用SFT将自然语言问题和数据库模式映射到目标表和列。[13, 11, 14, 15, 16]为此开发了端到端的监督微调方法,而[30]引入了一个两阶段的流水线,首先识别相关表,然后再预测列。[31]采取了更直接的方法,将表预测任务制定为微调目标。然而,当前用于模式链接的监督微调方法经常面临一个关键限制:训练数据中缺乏高质量的推理信息,常常导致过程变成死记硬背,而非真正的模式理解。
用于推理的RL 关于LLM推理的研究已经取得了显著进展,从基于线性提示的因果增强[17]发展到启发式推理搜索方法[32, 33],最近又发展到结合RL训练的CoT提示这一流行方法[19]。GRPO[19]代表了这一方向的重要进展。为了解决GRPO中的训练不稳定问题,后续的工作[20, 21]提出了各种改进和优化方案。此外,研究人员[34, 35, 36]还探索了通过RL训练将推理规则注入模型。RL在推理中的应用在专业领域显示出特别强劲的势头,包括:数学[37, 38]、奖励模型[39, 40]、金融应用[41]。同时,[42, 43]成功将基于RL的推理方法应用于文本到SQL任务中的表预测任务。与[42, 43]不同,Schema R1展示了通过不仅进行表预测,还进行列预测的改进能力。
3 预备知识
3.1 模式链接任务中的监督微调
按照[11]的监督微调任务设计方法,模式链接任务的微调目标可以定义为:
minimizeθ1N∑i=1NLoss((ti∗,ci∗),LLMS(qi,Si;θ)) \operatorname{minimize}_{\theta} \quad \frac{1}{N}\sum_{i=1}^{N}\operatorname{Loss}\left(\left(t_{i}^{*},c_{i}^{*}\right), \operatorname{LLM}_{S}\left(q_{i},S_{i} ; \theta\right)\right) minimizeθN1i=1∑NLoss((ti∗,ci∗),LLMS(qi,Si;θ))
方程(1)使模式链接LLM LLMSL L M_{S}LLMS 能够预测与SQL查询需求qiq_{i}qi相匹配的表t∗it^{*}{ }_{i}t∗i和列c∗ic^{*}{ }_{i}c∗i,给出总数据库描述SiS_{i}Si。θ\thetaθ表示所有参与训练的参数,Loss是交叉熵损失。
3.2 用于推理的RL
作为最具影响力的推理RL算法之一,GRPO有效地利用了强化学习中固有的探索与利用的权衡。为了优化GPU效率,它消除了对价值模型评估单个采样轨迹优势的需求。相反,它计算同一问题实例下一组采样轨迹的奖励,然后从这些奖励中导出它们的相对优势。GRPO的优化目标可以正式表达为:
JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold (O∣q)]1G∑i=1G1∣oi∣∑t=1∣oi∣{min[πθ(oi,t∣q,oi,<t)πθold (oi,t∣q,oi,<t)A^i,t,clip(πθ(oi,t∣q,oi,<t)πθold (oi,t∣q,oi,<t),1−ε,1+ε)A^i,t]−βDKL[πθ∥πref]} \begin{aligned} \mathcal{J}_{G R P O}(\theta)= & \mathbb{E}\left[q \sim P(Q),\left\{o_{i}\right\}_{i=1}^{G} \sim \pi_{\theta_{\text {old }}}(O \mid q)\right] \\ & \frac{1}{G} \sum_{i=1}^{G} \frac{1}{\left|o_{i}\right|} \sum_{t=1}^{\left|o_{i}\right|} \left\{\min \left[\frac{\pi_{\theta}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta_{\text {old }}}\left(o_{i, t} \mid q, o_{i,<t}\right)} \hat{A}_{i, t}, \operatorname{clip}\left(\frac{\pi_{\theta}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta_{\text {old }}}\left(o_{i, t} \mid q, o_{i,<t}\right)}, 1-\varepsilon, 1+\varepsilon\right) \hat{A}_{i, t}\right]-\beta \mathbb{D}_{K L}\left[\pi_{\theta} \| \pi_{r e f}\right]\right\} \end{aligned} JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold (O∣q)]G1i=1∑G∣oi∣1t=1∑∣oi∣{min[πθold (oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold (oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ε,1+ε)A^i,t]−βDKL[πθ∥πref]}
如方程(2)所示,q∼P(Q)q \sim P(Q)q∼P(Q) : 表示从问题分布P(Q)\mathrm{P}(\mathrm{Q})P(Q)中采样的输入问题。GGG是组大小,表示为同一问题生成的不同候选回答的数量。πθ\pi_{\theta}πθ表示当前策略模型,其参数θ\thetaθ通过优化目标函数进行更新,而πθold \pi_{\theta_{\text {old }}}πθold 表示旧的策略模型,其参数固定,用于生成训练样本。A^i,t\hat{A}_{i, t}A^i,t是组内的相对优势值,通过归一化奖励计算,这是与PPO[44]相比的最大区别。
4 提出的方法
4.1 冷启动准备
在我们的研究中,为了增强GRPO的答案生成与人类偏好的一致性并加速收敛,我们采用监督微调以确保模型遵守特定的输出格式。然而,由于传统的模式链接模型通常依赖于对答案的死记硬背,我们开发了一种面向推理的微调方法。
为了实现这一点,我们首先通过从Spider数据集中提取200个样本来整理高质量的推理信息。这些样本被构造成包含问题、数据库模式和目标表/列的提示模板。目标是指导商业LLM(具体来说,我们选择了DeepSeek-R1)使用真实模式链接作为监督来重建缺失的推理过程。提示模板的具体构造在附录A中提供。在上述小型数据集的基础上,我们将监督微调目标公式化如方程(3)所示。
minimizeθ1N∑i=1NLoss((ti∗,ci∗,CoTi),LLMS(q,S,D;θ)) \underset{\theta}{\operatorname{minimize}} \quad \frac{1}{N} \sum_{i=1}^{N} \operatorname{Loss}\left(\left(t_{i}^{*}, c_{i}^{*}, C o T_{i}\right), \operatorname{LLM}_{S}(q, S, D ; \theta)\right) θminimizeN1i=1∑NLoss((ti∗,ci∗,CoTi),LLMS(q,S,D;θ))
如方程(3)所指定,CoTiC o T_{i}CoTi表示与给定问题对应的地面真值CoT。通过我们的监督微调方法,该模型生成的响应可靠地遵循我们期望的格式:在…标签内封装推理过程,在…标签内封装模式链接输出。这种结构化输出使得后续的推理RL阶段能够精确地从…段中提取监督信号,同时训练在…组件中展示的推理能力。
4.2 推理RL的规则基础
适当奖励目标的设计对于指导RL模型的最终学习结果至关重要。由于GRPO是一种结果监督的RL算法,我们基于…标签内的输出建立基于规则的评分机制。在Schema-R1训练中,我们实现了由三个不同组件组成的综合奖励系统。
格式奖励 尽管模型通过冷启动初始化获得了基本的指令跟随能力,但RL训练倾向于激发其在训练过程中的探索行为。这鼓励了更多创造性回应,但也可能导致模型偏离我们期望的输出格式,导致回应不匹配。为了在创造性探索和格式合规之间保持平衡,我们实施了一种基于规则的机制,持续加强目标回应范式。我们的奖励的具体配置如下:
Rf={1, 格式成功 0, 格式失败 R_{f}= \begin{cases}1, & \text { 格式成功 } \\ 0, & \text { 格式失败 }\end{cases} Rf={1,0, 格式成功 格式失败
Rc=bool( count ("### table:" )==1)+bool( count ("### columns:" )==1) R_{c}=\operatorname{bool}(\text { count }(" \# \# \# \text { table:" })==1)+\operatorname{bool}(\text { count }(" \# \# \# \text { columns:" })==1) Rc=bool( count ("### table:" )==1)+bool( count ("### columns:" )==1)
格式奖励包括两个组成部分:方程(4)确保采样响应正确地将答案封闭在…标签中,将推理封闭在…标签中,而方程(5)指导模型将表预测放在文本"###table:“之后,将列预测放在文本”###column:"之后,其中count表示字符串频率函数。
推理长度奖励 过长的推理过程会增加推理和训练时间,但可能不会提高性能[45, 46],而不足的推理会阻碍完整的问题解决。因此,我们设定了一个最优推理长度基准,构造如下:
Rl={0, len response < Lower Length 1, Lower Length <= len response < Upper Length 0, Upper Length <= len response R_{l}= \begin{cases}0, & \text { len }_{\text {response }}<\text { Lower Length } \\ 1, & \text { Lower Length }<=\text { len }_{\text {response }}<\text { Upper Length } \\ 0, & \text { Upper Length }<=\text { len }_{\text {response }} \end{cases} Rl=⎩
⎨
⎧0,1,0, len response < Lower Length Lower Length <= len response < Upper Length Upper Length <= len response
如方程(6)所示,len_{response}表示响应的总标记数,而Lower Length和Upper Length分别表示期望响应长度的下限和上限。
模式链接奖励 对于模式链接任务,其目标是确定预测的表和列是否准确匹配地面真值,我们采用了[11]的评估方法。具体而言,我们利用过滤准确性度量(filter acc)来配置特定任务的奖励和惩罚。
Rst=Rtmax/len(ti∗)∗len(ti−ti′)−Ptmax/len(ti′)∗len(ti−ti′)R_{st} = R_{tmax}/len(t_{i}*)*len(t_{i} - t_{i}') - P_{tmax}/len(t_{i}')*len(t_{i} - t_{i}')Rst=Rtmax/len(ti∗)∗len(ti−ti′)−Ptmax/len(ti′)∗len(ti−ti′)
Rsc=Rcmax/len(ci∗)∗len(ci−ci′)−Pcmax/len(ci′)∗len(ci−ci′)R_{sc} = R_{cmax}/len(c_{i}*)*len(c_{i} - c_{i}') - P_{cmax}/len(c_{i}')*len(c_{i} - c_{i}')Rsc=Rcmax/len(ci∗)∗len(ci−ci′)−Pcmax/len(ci′)∗len(ci−ci′)
在方程(7)中,tit_{i}ti表示预测的表集合,而tit_{i}ti表示地面真值表集合。由此我们可以得到正确预测的表集合(ti−ti′t_{i} - t_{i}'ti−ti′)和错误预测的集合(ti−ti′t_{i} - t_{i}'ti−ti′)。我们定义了表预测的最大可得奖励RtmaxR_{tmax}Rtmax和最大惩罚PtmaxP_{tmax}Ptmax。因此,每个正确预测项的平均奖励计算为Ptmax/len(ti′)P_{tmax}/len(t_{i}')Ptmax/len(ti′),每个错误预测项的平均惩罚计算为Ptmax/len(ti′)P_{tmax}/len(t_{i}')Ptmax/len(ti′)。表预测RstR_{st}Rst的最终奖励则是总奖励Rtmax/len(ti∗)∗len(ti−ti′)R_{tmax}/len(t_{i}*)*len(t_{i} - t_{i}')Rtmax/len(ti∗)∗len(ti−ti′)与惩罚Ptmax/len(ti′)∗len(ti−ti′)P_{tmax}/len(t_{i}')*len(t_{i} - t_{i}')Ptmax/len(ti′)∗len(ti−ti′)之间的差值。类似地,列预测RscR_{sc}Rsc的奖励可以按方程(8)的方式公式化。在模式链接任务中,准确的表预测对于确保后续步骤中的列预测正确至关重要。为了反映这一点重要性,我们设置Rtmax>RcmaxR_{tmax} > R_{cmax}Rtmax>Rcmax和Ptmax>PcmaxP_{tmax} > P_{cmax}Ptmax>Pcmax。模式链接的整体奖励因此表示为:Rs=Rst+RscR_{s} = R_{st} + R_{sc}Rs=Rst+Rsc。
5 实验
5.1 设置
基准测试 我们在Spider数据集上使用Schema-R1进行了训练。按照[11]中概述的方法,我们通过从SQL查询中提取地面真值表和列来构建模式链接任务。经过验证后,我们总共编译了8529个训练样本,其中前200个样本保留用于创建CoT监督微调数据,剩余的8329个样本用于GRPO训练。对于验证,我们采用相同的方法从Spider-dev集合中提取地面真值表和列。我们使用的评估指标如下。精确匹配(EM):衡量预测内容是否完全与地面真值一致。
过滤准确性(FilterdAcc):量化预测与地面真值之间的重叠程度,数值越高表示覆盖的正确内容越多。
召回率(Rec):评估模型在完整性方面的预测质量。
训练设置 我们的实验基于Qwen2.5-0.5B和Qwen2.5-1.5B基础模型。在冷启动SFT期间,我们采用了保守学习率为5e-5的全参数微调,并将训练限制为3个epoch以减轻过拟合。对于GRPO训练阶段,我们采用了一种采样策略,每查询生成10个响应,保持学习率为2e-05,设置训练批次大小为10。0.5B模型在三块A100-40G GPU上训练,而1.5B模型则使用三块A100-80G GPU。VLLM用于加速推理,温度设置为1。
5.2 主要结果
| 表格预测 | |||
|---|---|---|---|
| 方法 | EM | FilteredAcc | Rec |
| Qwen2.5-0.5B (DTS-SQL) | 54.28 | 64.24 | 74.07 |
| Qwen2.5-1.5B (DTS-SQL) | 64.84 | 75.0 | 83.03 |
| Qwen2.5-0.5B (Cold-start) | 29.98 | 53.78 | 65.02 |
| Qwen2.5-1.5B (Cold-start) | 56.67 | 70.41 | 79.06 |
| Qwen2.5-0.5B (Schema-R1) | 55.38 | 75.60 | 85.34 |
| Qwen2.5-1.5B (Schema-R1) | 73.21 | 89.94 | 94.40 |
表1:不同模型在表格预测任务中的表格预测性能。
表2:不同方法在列预测任务中的表格预测性能。
| 列预测 | |||
|---|---|---|---|
| 方法 | EM | FilteredAcc | Rec |
| Qwen2.5-0.5B (DTS-SQL) | 19.32 | 29.98 | 48.64 |
| Qwen2.5-1.5B (DTS-SQL) | 31.17 | 42.43 | 59.41 |
| Qwen2.5-0.5B (Cold-start) | 4.8 | 15.14 | 31.71 |
| Qwen2.5-1.5B (Cold-start) | 19.42 | 35.05 | 54.52 |
| Qwen2.5-0.5B (Schema-R1) | 13.24 | 44.02 | 64.86 |
| Qwen2.5-1.5B (Schema-R1) | 38.24 | 68.82 | 81.85 |
RL训练相较于SFT展现出更优越的结果。表1和表2展示了监督微调(SFT)与推理RL在我们的验证集上的对比分析。在单数据集配置中,0.5B模型在表格和列预测方面都实现了比仅依赖SFT的DTS-SQL更高的过滤准确性。特别是,1.5B模型在所有评估指标上均显著优于DTS-SQL,表格和列预测的所有指标均有显著改善。这些结果表明,更大的模型能更有效地从推理训练中受益,突出了我们方法的可扩展性优势。
推理密集型任务从推理-表格中受益更多。实验结果揭示了一个重要发现:尽管在有限的高质量CoT样本下训练的表现不如全面的监督微调(如与Cold-start和DTS-SQL的比较所示),但两阶段方法证明非常有效。初始的小样本集微调随后进行基于GRPO的推理训练,使模型能够自主优化其推理能力。这种方法不仅补偿了小样本训练的局限性,而且最终通过内部化和优化所获得的推理模式超越了传统SFT方法的性能。
训练进度显示奖励和性能的一致改进。图2显示了训练迭代中奖励分数、响应长度和评估指标的进展。值得注意的是,冷启动SFTed模型在训练期间显示出稳定的奖励分数改进,与无SFT基线的糟糕表现和频繁的指令跟踪失败形成鲜明对比,特别是在0.5B模型中。这一有力证据表明,精确的意图识别使强化学习能够系统地优化模型输出的质量和任务执行的效果。
6 结论
本文针对文本到SQL系统中的模式链接这一关键挑战,提出了Schema-R1,这是一种显著提高准确性和适应性的强大推理增强模型。通过将模式链接从SQL生成中解耦并通过自我改进的推理增强,Schema-R1为更准确、更适应性强且注重隐私的数据库交互系统铺平了道路。
局限性 尽管我们的Schema-R1在较小的模型中已显示出成功,但由于计算资源的限制,尚未能在更大的模型中进行测试。未来的工作将涉及在更大规模的模型上验证Schema-R1。
文本到SQL作为一个自然语言到SQL的任务,提出了一个挑战:即使解耦了模式链接,使其预测与最终的SQL保持一致仍然不是一件容易的事。为了解决这个问题,我们将研究自我修正模型,以确保模式链接和SQL生成之间的一致性。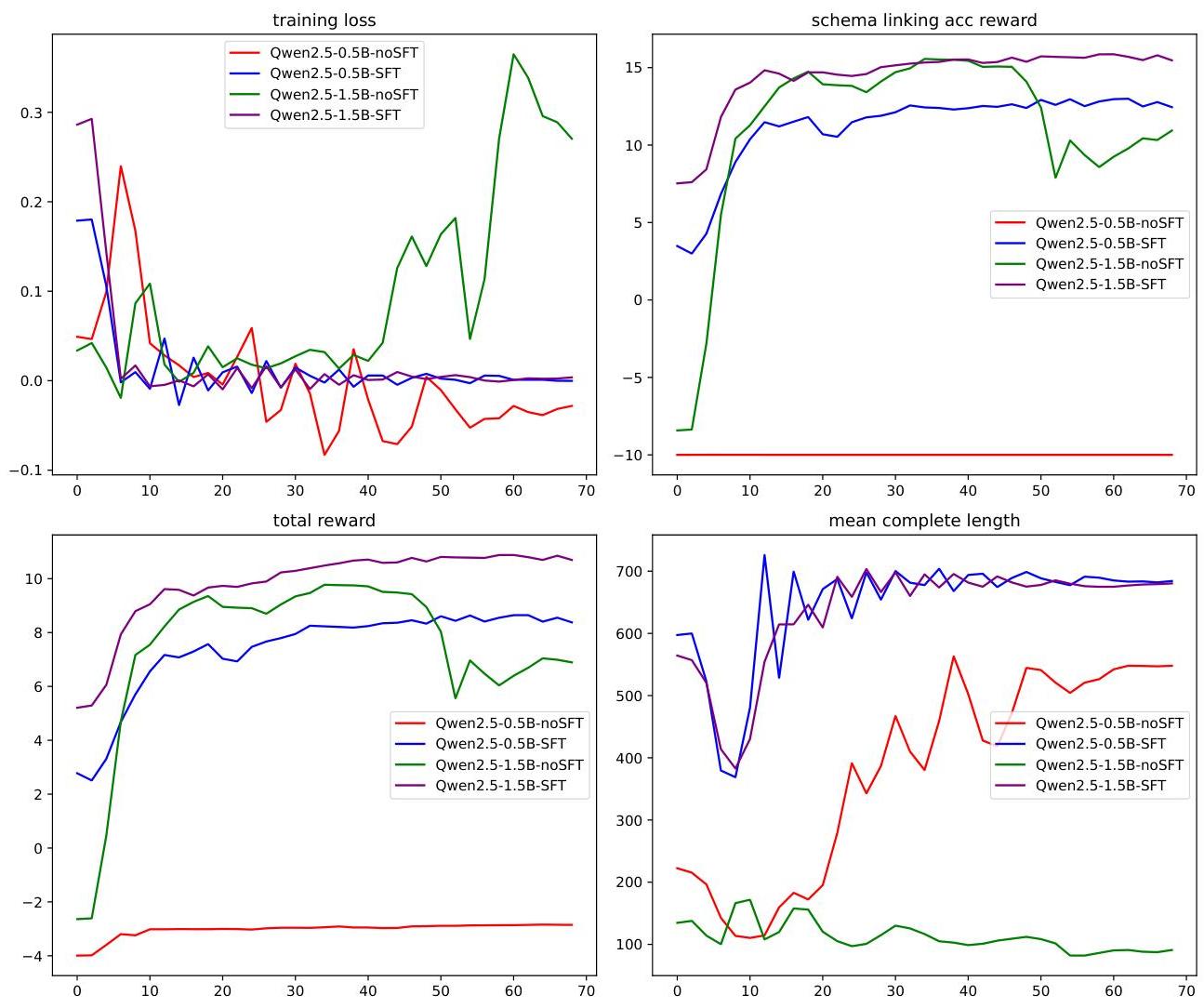
图2:schema-R1在不同基础模型上的训练过程
参考文献
[1] Liang Shi, Zhengju Tang, Nan Zhang, Xiaotong Zhang, 和 Zhi Yang. 大型语言模型在文本到SQL任务中的应用综述. ACM Computing Surveys, 2024.
[2] Peixian Ma, Xialie Zhuang, Chengjin Xu, Xuhui Jiang, Ran Chen, 和 Jian Guo. Sql-r1: 通过强化学习训练自然语言到SQL的推理模型. arXiv预印本 arXiv:2504.08600, 2025.
[3] Wenqiang Lei, Weixin Wang, Zhixin Ma, Tian Gan, Wei Lu, Min-Yen Kan, 和 Tat-Seng Chua. 重新审视模式链接在文本到SQL中的作用. 在 Bonnie Webber, Trevor Cohn, Yulan He, 和 Yang Liu 编辑的《2020年自然语言处理实证方法会议论文集》(EMNLP),第6943-6954页,线上,2020年11月。计算语言学协会.
[4] Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, 和 Jingren Zhou. 借助大型语言模型的文本到SQL:基准评估. Proc. VLDB Endow., 17(5):1132-1145, 2024年1月.
[5] Siqiao Xue, Danrui Qi, Caigao Jiang, Fangyin Cheng, Keting Chen, Zhiping Zhang, Hongyang Zhang, Ganglin Wei, Wang Zhao, Fan Zhou, Hong Yi, Shaodong Liu, Hongjun Yang, 和 Faqiang Chen. 展示db-gpt:借助大型语言模型的下一代数据交互系统. 17(12), 2024.
[6] Xiaojun Chen, Tianle Wang, Tianhao Qiu, Jianbin Qin, 和 Min Yang. Open-sql框架:在开源大型语言模型上增强文本到SQL. arXiv预印本 arXiv:2405.06674, 2024.
[7] Yuankai Fan, Zhenying He, Tonghui Ren, Can Huang, Yinan Jing, Kai Zhang, 和 X. Sean Wang. Metasql:自然语言到SQL翻译的生成-排序框架. 在2024 IEEE第40届国际数据工程会议(ICDE),第1765-1778页,2024.
[8] Mohammadreza Pourreza 和 Davood Rafiei. Din-sql:分解上下文学习的文本到SQL与自我修正. 第37届神经信息处理系统大会论文集, NIPS '23, Red Hook, NY, USA, 2023. Curran Associates Inc.
[9] Dongjun Lee, Choongwon Park, Jaehyuk Kim, 和 Heesoo Park. MCS-SQL:利用多提示和多选选择进行文本到SQL生成. 在 Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, 和 Steven Schockaert 编辑的第31届国际计算语言学会议论文集中,第337-353页,阿布扎比,阿联酋,2025年1月。计算语言学协会.
[10] Hanchong Zhang, Ruisheng Cao, Lu Chen, Hongshen Xu, 和 Kai Yu. Act-sql:利用自动生成的思维链进行文本到SQL的上下文学习. In EMNLP (Findings), 2023.
[11] Mohammadreza Pourreza 和 Davood Rafiei. DTS-SQL:使用小型大型语言模型的分解文本到SQL. 在 Yaser Al-Onaizan, Mohit Bansal, 和 Yun-Nung Chen 编辑的《计算语言学协会论文集:EMNLP 2024》,第8212-8220页,美国佛罗里达州迈阿密,2024年11月。计算语言学协会.
[12] Gang Sun, Ran Shen, Liangfeng Jin, Yifan Wang, Shiyu Xu, Jinpeng Chen, 和 Weihao Jiang. 在电网领域使用大型语言模型进行指令调整的文本到SQL. 在2023年第4届控制、机器人和智能系统国际会议上,第59-63页,2023.
[13] Satya Krishna Gorti, Ilan Gofman, Zhaoyan Liu, Jiapeng Wu, NoÄGl Vouitsis, Guangwei Yu, Jesse C Cresswell, 和 Rasa Hosseinzadeh. Msc-sql:用于文本到SQL翻译的多样本批判小型语言模型. arXiv预印本 arXiv:2410.12916, 2024.
[14] Lixia Wu, Peng Li, Junhong Lou, 和 Lei Fu. Datagpt-sql-7b:一个开源的文本到SQL语言模型. arXiv预印本 arXiv:2409.15985, 2024.
[15] Haoyang Li, Jing Zhang, Hanbing Liu, Ju Fan, Xiaokang Zhang, Jun Zhu, Renjie Wei, Hongyan Pan, Cuiping Li, 和 Hong Chen. Codes:构建用于文本到SQL的开源语言模型. 计算机管理学报, 2(3):1-28, 2024.
[16] Hongwei Yuan, Xiu Tang, Ke Chen, Lidan Shou, Gang Chen, 和 Huan Li. Cogsql:增强大型语言模型在文本到SQL翻译中的认知框架. AAAI人工智能会议论文集, 39(24):25778-25786, 2025年4月.
[17] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, 等. 思维链提示促使大型语言模型进行推理. 神经信息处理系统进展, 35:24824-24837, 2022.
[18] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, 等. Deepseek-r1:通过强化学习激励LLMs的推理能力. arXiv预印本 arXiv:2501.12948, 2025.
[19] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, 等. Deepseekmath:推动开放语言模型数学推理的极限. arXiv预印本 arXiv:2402.03300, 2024.
[20] Jian Hu. Reinforce++:一种简单高效的大语言模型对齐方法. arXiv预印本 arXiv:2501.03262, 2025.
[21] Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, 等. Dapo:一个大规模的开源LLM强化学习系统. arXiv预印本 arXiv:2503.14476, 2025.
[22] Haoyang Li, Jing Zhang, Cuiping Li, 和 Hong Chen. Resdsql:解耦模式链接和骨架解析用于文本到SQL. 第三十七届人工智能协会会议暨第三十五届创新人工智能应用会议及第十三届人工智能教育进步研讨会论文集, AAAI’23/IAAI’23/EAAI’23. AAAI Press, 2023.
[23] Han Fu, Chang Liu, Bin Wu, Feifei Li, Jian Tan, 和 Jianling Sun. Catsql:迈向现实世界自然语言到 SQL 应用程序. Proceedings of the VLDB Endowment, 16(6):1534-1547, 2023.
[24] Bailin Wang, Richard Shin, Xiaodong Liu, Oleksandr Polozov, 和 Matthew Richardson. RAT-SQL:关系感知的模式编码和链接用于文本到SQL解析器. 在 Dan Jurafsky, Joyce Chai, Natalie Schluter, 和 Joel Tetreault 编辑的《计算语言学协会第58届年会论文集》,第7567-7578页,在线,2020年7月。计算语言学协会.
[25] Ruisheng Cao, Lu Chen, Zhi Chen, Yanbin Zhao, Su Zhu, 和 Kai Yu. LGESQL:混合局部和非局部关系的线图增强文本到SQL模型. 在 Chengqing Zong, Fei Xia, Wenjie Li, 和 Roberto Navigli 编辑的《计算语言学协会第59届年会暨第11届国际自然语言处理联合会议论文集(第一卷:长篇论文)》,第2541-2555页,在线,2021年8月。计算语言学协会.
[26] Xuemei Dong, Chao Zhang, Yuhang Ge, Yuren Mao, Yunjun Gao, Jinshu Lin, Dongfang Lou, 等. C3:使用ChatGPT进行零样本文本到SQL. arXiv预印本 arXiv:2307.07306, 2023.
[27] Zhao Tan, Xiping Liu, Qing Shu, Xi Li, Changxuan Wan, Dexi Liu, Qizhi Wan, 和 Guoqiong Liao. 通过定制提示增强大型语言模型的文本到SQL能力. 在 Nicoletta Calzolari, Min-Yen Kan, Veronique Hoste, Alessandro Lenci, Sakriani Sakti, 和 Nianwen Xue 编辑的《2024年计算语言学、语言资源和评估联合国际会议论文集(LREC-COLING 2024)》,第6091-6109页,意大利都灵,2024年5月。ELRA and ICCL.
[28] Zhishuai Li, Xiang Wang, Jingjing Zhao, Sun Yang, Guoqing Du, Xiaoru Hu, Bin Zhang, Yuxiao Ye, Ziyue Li, Rui Zhao, 等. Pet-sql:通过跨一致性提示增强的两轮文本到SQL细化. arXiv预印本 arXiv:2403.09732, 2024.
[29] Sun Yang, Qiong Su, Zhishuai Li, Ziyue Li, Hangyu Mao, Chenxi Liu, 和 Rui Zhao. SQL-to-schema 增强文本到SQL中的模式链接. 在 Christine Strauss, Toshiyuki Amagasa, Giuseppe Manco, Gabriele Kotsis, A. Min Tjoa, 和 Ismail Khalil 编辑的《数据库和专家系统应用》,第139-145页,瑞士,2024. Springer Nature Switzerland.
[30] Ran Shen, Gang Sun, Hao Shen, Yiling Li, Liangfeng Jin, 和 Han Jiang. SP-SQL:基于逐步解析的文本到SQL生成框架. 在 2023 年第七届机器视觉与信息技术国际会议 (CMVIT) 上,第 115-122 页。IEEE,2023.
[31] Xiaokang Zhang, Sijia Luo, Bohan Zhang, Zeyao Ma, Jing Zhang, Yang Li, Guanlin Li, Zijun Yao, Kangli Xu, Jinchang Zhou, 等. TableLLM:在实际办公场景中启用LLM进行表格数据操作. arXiv预印本 arXiv:2403.19318, 2024.
[32] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, 和 Karthik Narasimhan. 思维树:使用大型语言模型进行深思熟虑的问题解决. 神经信息处理系统进展, 36:11809-11822, 2023.
[33] Bowen Jin, Chulin Xie, Jiawei Zhang, Kashob Kumar Roy, Yu Zhang, Zheng Li, Ruirui Li, Xianfeng Tang, Suhang Wang, Yu Meng, 和 Jiawei Han. 图思维链:通过在图上推理增强大型语言模型. 在 Lun-Wei Ku, Andre Martins, 和 Vivek Srikumar 编辑的《计算语言学协会论文集:ACL 2024》,第163-184页,泰国曼谷,2024年8月。计算语言学协会.
[34] Gongfan Fang, Xinyin Ma, 和 Xinchao Wang. Thinkless:LLM 学习何时思考. arXiv 预印本 arXiv:2505.13379, 2025.
[35] Lingjie Jiang, Xun Wu, Shaohan Huang, Qingxiu Dong, Zewen Chi, Li Dong, Xingxing Zhang, Tengchao Lv, Lei Cui, 和 Furu Wei. 仅在需要时思考:使用大型混合推理模型. arXiv 预印本 arXiv:2505.14631, 2025.
[36] Wenjie Ma, Jingxuan He, Charlie Snell, Tyler Griggs, Sewon Min, 和 Matei Zaharia. 不思考也能有效推理的模型. arXiv 预印本 arXiv:2504.09858, 2025.
[37] Zihan Liu, Yang Chen, Mohammad Shoeybi, Bryan Catanzaro, 和 Wei Ping. AceMath:通过后训练和奖励建模推进前沿数学推理. arXiv 预印本, 2024.
[38] Liang Wen, Yunke Cai, Fenrui Xiao, Xin He, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Lifu Tang, Xiaowei Lv, 等. Light-R1:从头开始的课程SFT、DPO和RL进行长CoT及其他. arXiv 预印本 arXiv:2503.10460, 2025.
[39] Xiusi Chen, Gaotang Li, Ziqi Wang, Bowen Jin, Cheng Qian, Yu Wang, Hongru Wang, Yu Zhang, Denghui Zhang, Tong Zhang, 等. RM-R1:将奖励建模视为推理. arXiv 预印本 arXiv:2505.02387, 2025.
[40] Zijun Liu, Peiyi Wang, Runxin Xu, Shirong Ma, Chong Ruan, Peng Li, Yang Liu, 和 Yu Wu. 一般奖励建模的推理时缩放. arXiv 预印本 arXiv:2504.02495, 2025.
[41] Zhaowei Liu, Xin Guo, Fangqi Lou, Lingfeng Zeng, Jinyi Niu, Zixuan Wang, Jiajie Xu, Weige Cai, Ziwei Yang, Xueqian Zhao, 等. Fin-R1:通过强化学习进行金融推理的大型语言模型. arXiv 预印本 arXiv:2503.16252, 2025.
[42] Zheyuan Yang, Lyuhao Chen, Arman Cohan, 和 Yilun Zhao. Table-R1:表格推理的推理时缩放. arXiv 预印本 arXiv:2505.23621, 2025.
[43] Fangyu Lei, Jinxiang Meng, Yiming Huang, Tinghong Chen, Yun Zhang, Shizhu He, Jun Zhao, 和 Kang Liu. Reasoning-Table:探索用于表格推理的强化学习. arXiv 预印本 arXiv:2506.01710, 2025.
[44] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, 和 Oleg Klimov. 近端策略优化算法. arXiv 预印本 arXiv:1707.06347, 2017.
[45] Pranjal Aggarwal 和 Sean Welleck. L1:通过强化学习控制推理模型思考的时间. arXiv 预印本 arXiv:2503.04697, 2025.
[46] Bairu Hou, Yang Zhang, Jiabao Ji, Yujian Liu, Kaizhi Qian, Jacob Andreas, 和 Shiyu Chang. Thinkprune:通过强化学习修剪LLM的长链思维. arXiv 预印本 arXiv:2504.01296, 2025.
A 提示构造
CoT生成提示模板
:
您的任务是将用户在…中的问题与提供的数据库信息…以及真实的模式链接信息…结合起来,然后补充…中的推理信息。您的回复必须严格遵守以下模板:
(如何到达…中的内容)
Related_Tables:Book, Student;
Related_Columns:Book.id,Book.nums;
:
How many book all student have? \n\nCreate Table
Book (id, name, student_id);\nCreate Table Student (id,name);\n
图3:CoT生成的提示模板
参考论文:https://arxiv.org/pdf/2506.11986

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 19
19 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)