Spring AI初学:人工智能概念
models人工智能模型是设计用于处理和生成信息的算法,通常模仿人类的认知功能。通过从大型数据集中学习模式和见解,这些模型可以做出预测、文本、图像或其他输出,从而增强跨行业的各种应用。有许多不同类型的AI模型,每种模型都适合特定的用例。虽然ChatGPT及其生成AI功能通过文本输入和输出吸引了用户,但许多模型和公司提供了多样化的输入和输出。在ChatGPT之前,许多人对文本到图像生成模型着迷,如M
本节介绍Spring AI使用的核心概念。我们建议仔细阅读,以了解Spring AI是如何实现的。
models
人工智能模型是设计用于处理和生成信息的算法,通常模仿人类的认知功能。通过从大型数据集中学习模式和见解,这些模型可以做出预测、文本、图像或其他输出,从而增强跨行业的各种应用。
有许多不同类型的AI模型,每种模型都适合特定的用例。虽然ChatGPT及其生成AI功能通过文本输入和输出吸引了用户,但许多模型和公司提供了多样化的输入和输出。在ChatGPT之前,许多人对文本到图像生成模型着迷,如Midjourney和Stable Diffusion。
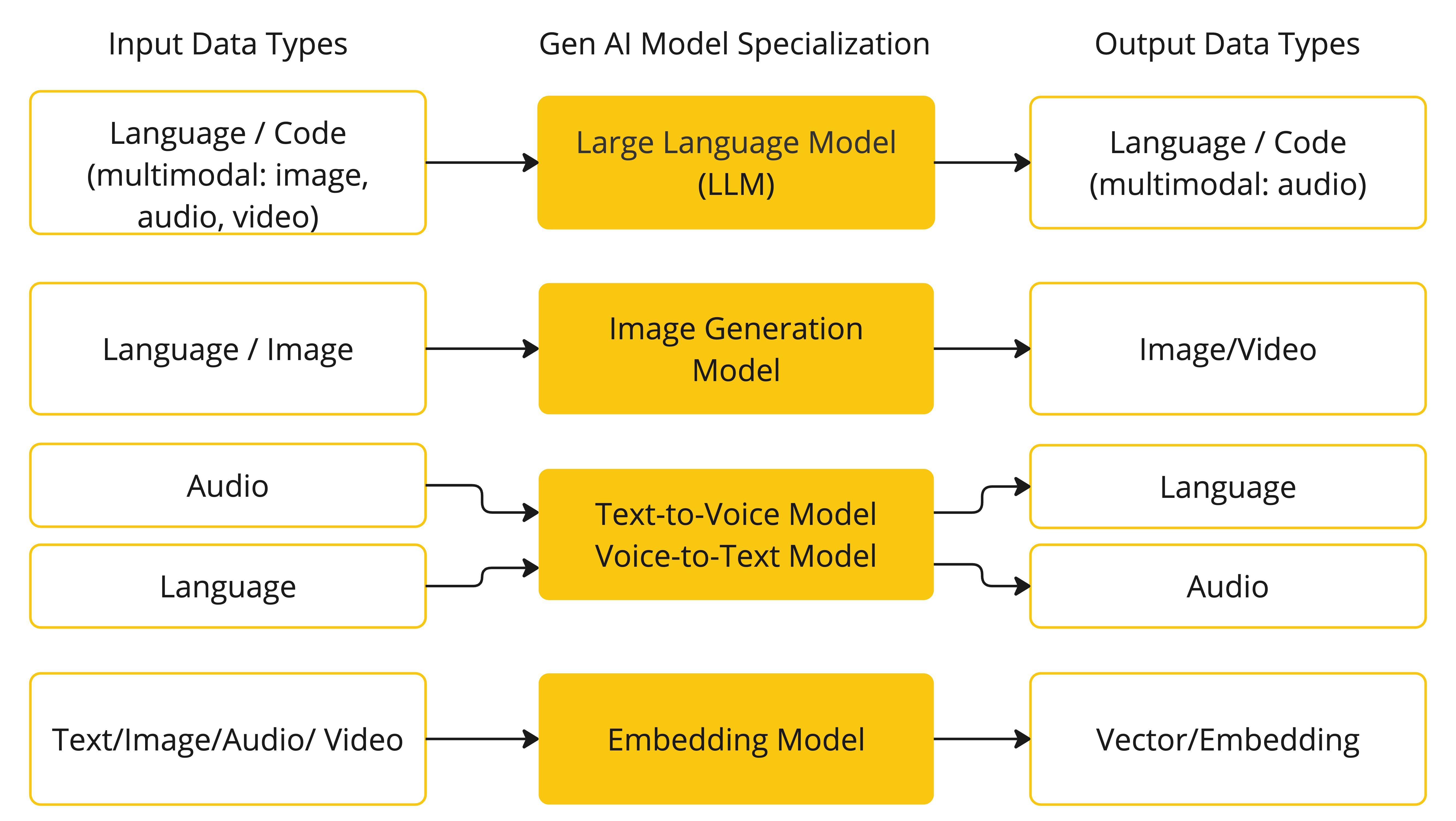
下表根据输入和输出类型对几个模型进行了分类:
Spring AI目前支持将输入和输出处理为语言、图像和音频的模型。上一个表中的最后一行接受文本作为输入并输出数字,通常被称为嵌入文本,表示AI模型中使用的内部数据结构。Spring AI支持嵌入,以实现更高级的用例。
GPT等模型的不同之处在于它们的预训练性质,如GPT中的“P”所示——聊天生成预训练转换器。这种预训练功能将AI转化为一种通用的开发工具,不需要广泛的机器学习或模型训练背景。
Prompts
提示是基于语言的输入的基础,它指导人工智能模型产生特定的输出。对于熟悉ChatGPT的人来说,提示可能看起来只是在发送到API的对话框中输入的文本。然而,它所包含的远不止于此。在许多AI模型中,提示的文本不仅仅是一个简单的字符串。
ChatGPT的API在一个提示中有多个文本输入,每个文本输入都被分配一个角色。例如,有一个系统角色,它告诉模型如何表现,并为交互设置上下文。还有用户角色,通常是用户的输入。
制作有效的提示既是一门艺术,也是一门科学。ChatGPT是为人类对话而设计的。这与使用SQL之类的东西“提问”有很大的不同。一个人必须与人工智能模型进行交流,就像与另一个人交谈一样。
这种交互风格的重要性在于,“快速工程”一词已经成为一门独立的学科。越来越多的技术可以提高提示的有效性。花时间精心制作提示可以大大提高最终的输出。
分享提示已成为一种公共实践,关于这一主题正在进行积极的学术研究。最近的一篇研究论文发现,你可以使用的最有效的提示之一是“深呼吸,一步一步地做这件事”。这应该能让你明白为什么语言如此重要。我们还不完全了解如何最有效地利用这项技术的先前迭代,如ChatGPT 3.5,更不用说正在开发的新版本了。
Prompt Templates
创建有效的提示涉及建立请求的上下文,并用特定于用户输入的值替换请求的部分内容。
此过程使用传统的基于文本的模板引擎进行快速创建和管理。Spring AI为此使用了OSS库StringTemplate。
例如,考虑简单的提示模板:

在Spring AI中,提示模板可以比作Spring MVC架构中的“视图”。一个模型对象,通常是java.util。Map用于填充模板中的占位符。“渲染”字符串将成为提供给AI模型的提示内容。
发送到模型的提示的具体数据格式存在相当大的差异。最初以简单的字符串开始,提示已经演变为包括多条消息,每条消息中的每个字符串都代表模型的不同角色。
Embeddings
嵌入是捕获输入之间关系的文本、图像或视频的数字表示。
嵌入的工作原理是将文本、图像和视频转换为浮点数数组,称为向量。这些矢量旨在捕捉文本、图像和视频的含义。嵌入数组的长度称为向量的维数。
通过计算两段文本的向量表示之间的数值距离,应用程序可以确定用于生成嵌入向量的对象之间的相似性。
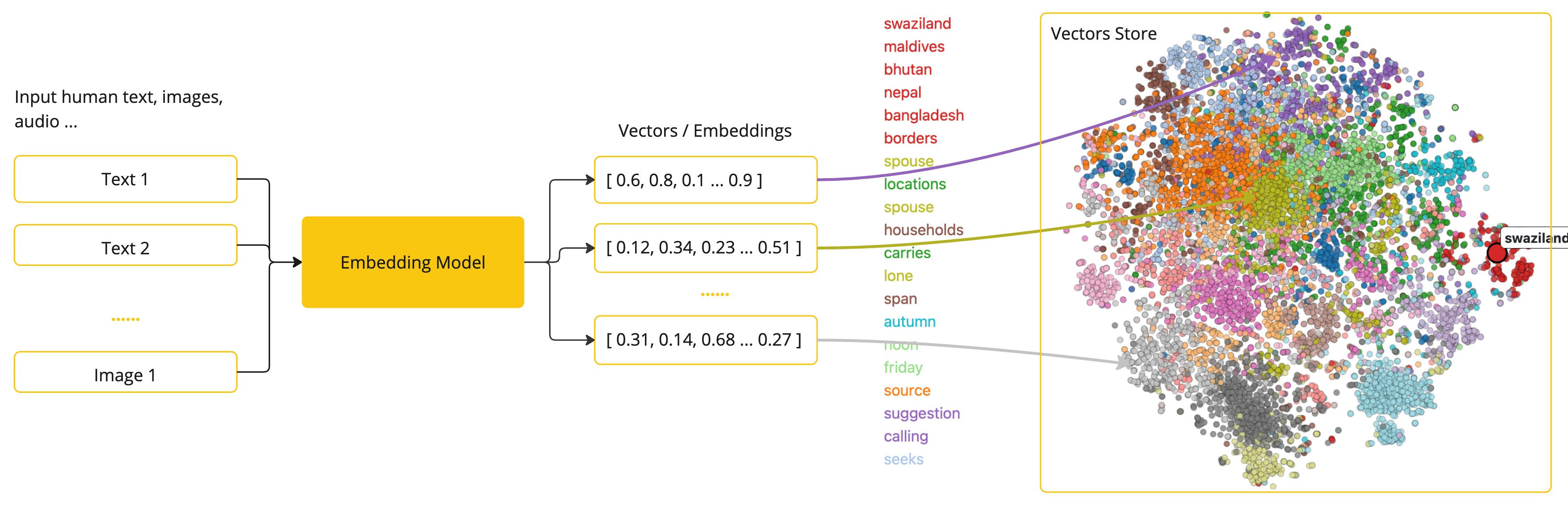
作为一名探索人工智能的Java开发人员,没有必要理解这些向量表示背后的复杂数学理论或具体实现。对它们在人工智能系统中的作用和功能有基本的了解就足够了,特别是当你将人工智能功能集成到你的应用程序中时。
嵌入在检索增强生成(RAG)模式等实际应用中尤其重要。它们能够将数据表示为语义空间中的点,语义空间类似于欧几里德几何的二维空间,但维度更高。这意味着,就像欧几里德几何中平面上的点可以根据它们的坐标接近或远离一样,在语义空间中,点的接近反映了意义的相似性。关于相似主题的句子在这个多维空间中位置更近,就像图表上彼此靠近的点一样。这种接近性有助于文本分类、语义搜索甚至产品推荐等任务,因为它允许人工智能根据其在扩展的语义环境中的“位置”来识别和分组相关概念。
Tokens
令牌是人工智能模型如何工作的构建块。在输入时,模型将单词转换为标记。在输出时,它们将标记转换回单词。
在英语中,一个标记大约相当于一个单词的75%。作为参考,莎士比亚的完整作品总计约90万字,翻译成约120万个代币。

也许更重要的是代币=金钱。在托管AI模型的背景下,您的费用由使用的代币数量决定。输入和输出都有助于整体令牌计数。
此外,模型受令牌限制,这限制了单个API调用中处理的文本量。这个阈值通常被称为“上下文窗口”。该模型不处理任何超过此限制的文本。
例如,ChatGPT3有4K令牌限制,而GPT4提供了不同的选项,如8K、16K和32K。Anthropic的Claude AI模型具有100K令牌限制,Meta最近的研究得出了1M令牌限制模型。
要使用GPT4总结莎士比亚的作品集,您需要设计软件工程策略来分割数据,并在模型的上下文窗口限制内呈现数据。Spring AI项目可以帮助你完成这项任务。
Structured Output
人工智能模型的输出传统上以java.lang.String的形式到达,即使您要求以JSON格式回复。它可能是正确的JSON,但它不是JSON数据结构。它只是一个字符串。此外,在提示中要求“for JSON”并不是100%准确的。
这种复杂性导致了一个专门领域的出现,该领域涉及创建提示以产生预期的输出,然后将生成的简单字符串转换为可用于应用程序集成的数据结构。
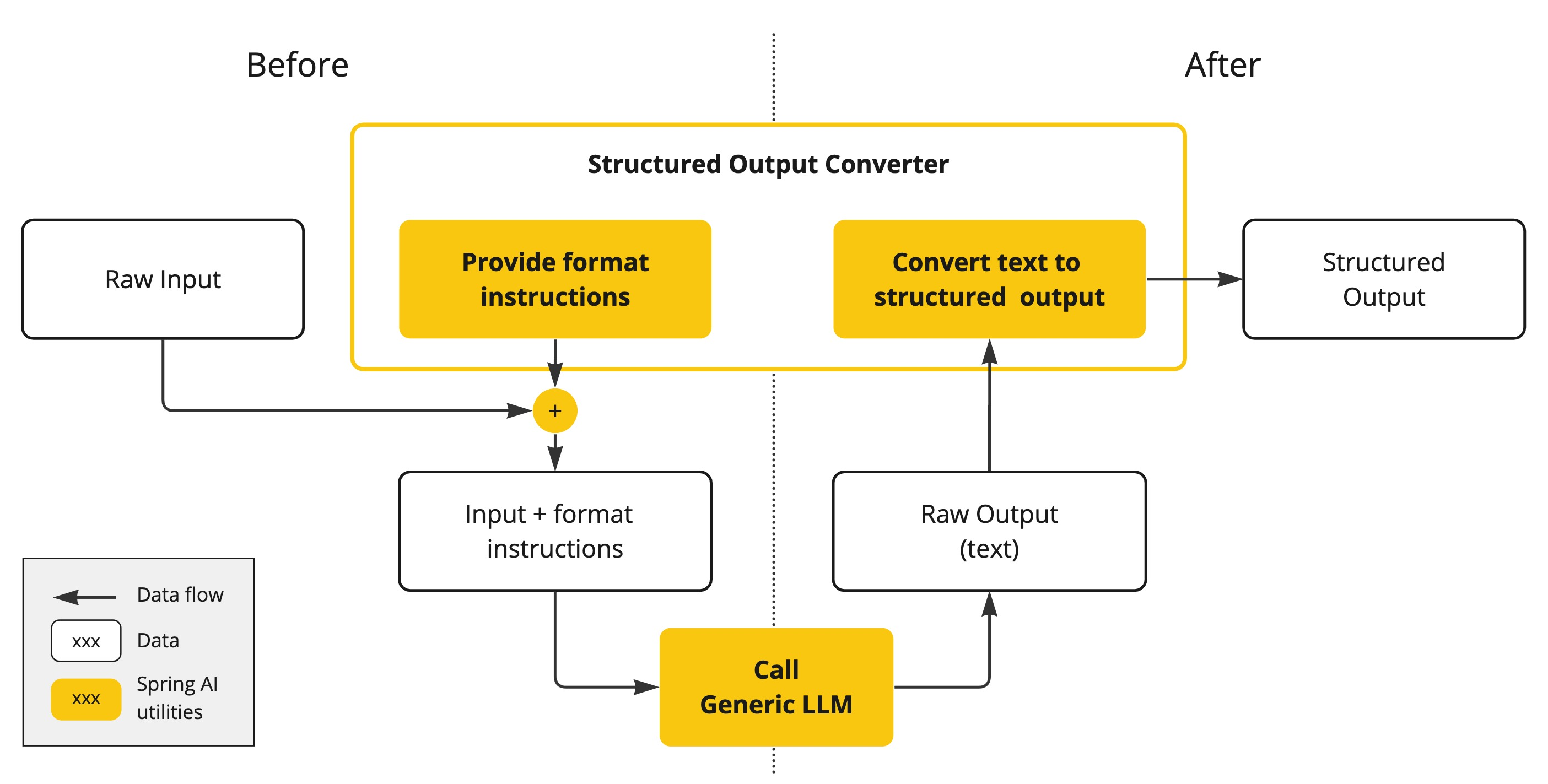
结构化输出转换采用精心制作的提示,通常需要与模型进行多次交互才能实现所需的格式。
Bringing Your Data & APIs to the AI Model
你如何为人工智能模型配备尚未训练过的信息?
请注意,GPT 3.5/4.0数据集仅持续到2021年9月。因此,该模型表示,它不知道在该日期之后需要知识的问题的答案。一个有趣的细节是,这个数据集大约是650GB。
有三种技术可以定制AI模型以整合您的数据:
微调:这种传统的机器学习技术涉及定制模型并改变其内部权重。然而,对于机器学习专家来说,这是一个具有挑战性的过程,对于GPT等模型来说,由于其规模,这是非常耗费资源的。此外,某些型号可能不提供此选项。
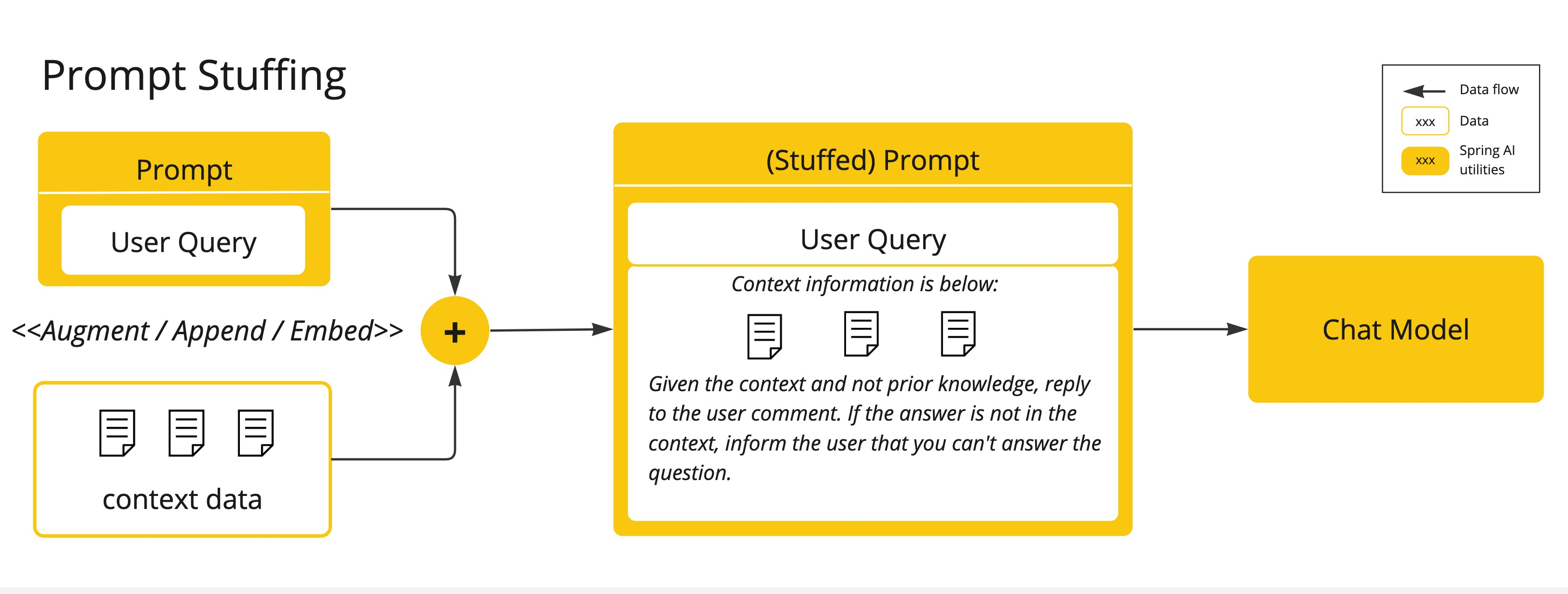
提示填充:一种更实用的替代方案是将数据嵌入提供给模型的提示中。鉴于模型的令牌限制,需要在模型的上下文窗口中呈现相关数据的技术。这种方法通俗地称为“填充提示”。Spring AI库帮助您实现基于“填充提示“技术的解决方案,也称为检索增强生成(RAG)。
工具调用:此技术允许注册将大型语言模型连接到外部系统API的工具(用户定义的服务)。Spring AI大大简化了您需要编写的支持工具调用的代码。
Retrieval Augmented Generation
一种名为检索增强生成(RAG)的技术已经出现,以解决将相关数据整合到提示中以获得准确AI模型响应的挑战。
该方法涉及批处理风格的编程模型,其中作业从文档中读取非结构化数据,对其进行转换,然后将其写入向量数据库。在较高的层次上,这是一个ETL(提取、转换和加载)管道。矢量数据库用于RAG技术的检索部分。
作为将非结构化数据加载到矢量数据库的一部分,最重要的转换之一是将原始文档拆分为更小的部分。将原始文档分割成小块的过程有两个重要步骤:
将文档拆分为多个部分,同时保留内容的语义边界。例如,对于包含段落和表格的文档,应避免将文档拆分到段落或表格的中间。对于代码,请避免在方法实现的中间拆分代码。
将文档的各个部分进一步拆分为大小仅占AI模型令牌限制一小部分的部分。
RAG的下一阶段是处理用户输入。当用户的问题需要人工智能模型回答时,该问题和所有“类似”的文档片段都会被放置在发送给人工智能模型的提示中。这就是使用矢量数据库的原因。它非常善于找到类似的内容。
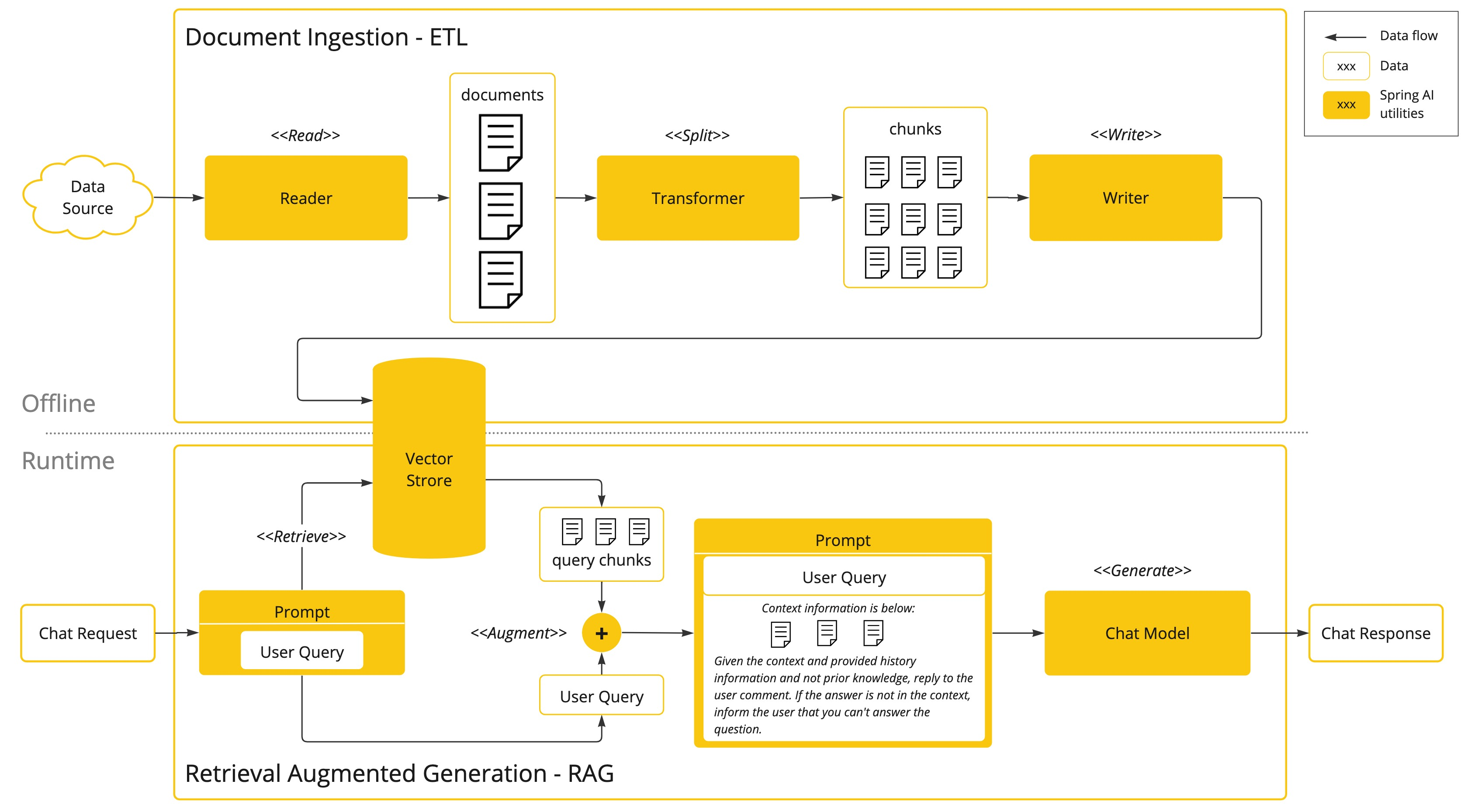
ETL管道提供了有关编排从数据源提取数据并将其存储在结构化向量存储中的流程的更多信息,确保数据在传递给AI模型时以最佳格式进行检索。
ChatClient-RAG解释了如何使用问答顾问在您的应用程序中启用RAG功能。
Tool Calling
大型语言模型(LLM)在训练后被冻结,导致知识陈旧,无法访问或修改外部数据。
工具调用机制解决了这些缺点。它允许您将自己的服务注册为将大型语言模型连接到外部系统API的工具。这些系统可以为LLM提供实时数据,并代表它们执行数据处理操作。
Spring AI大大简化了您需要编写的支持工具调用的代码。它为您处理工具调用对话。您可以将工具作为@tool注释方法提供,并在提示选项中提供,使其可用于模型。此外,您可以在单个提示中定义和引用多个工具。
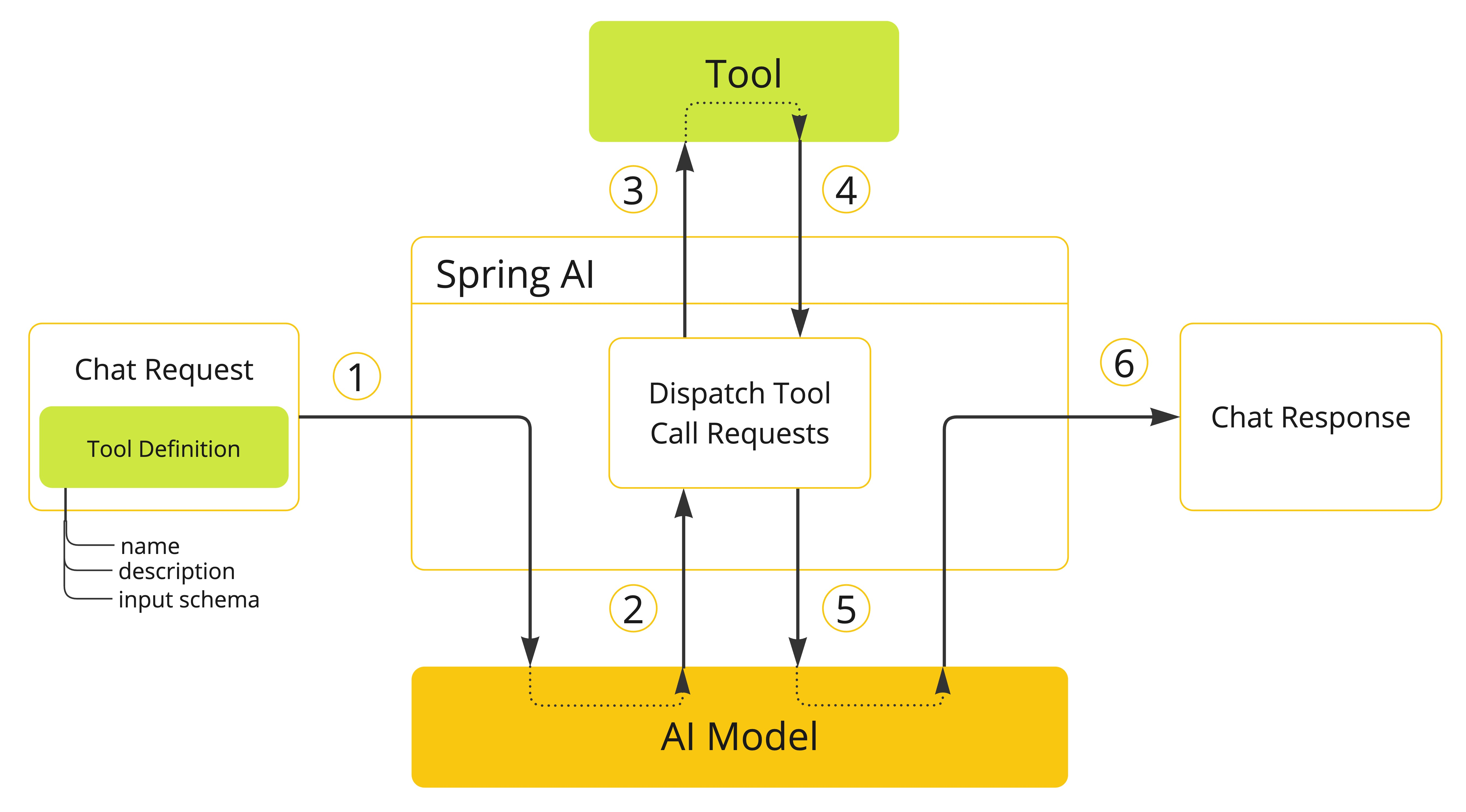
当我们想为模型提供一个工具时,我们会在聊天请求中包含它的定义。每个工具定义包括输入参数的名称、描述和模式。
当模型决定调用工具时,它会发送一个响应,其中包含工具名称和根据定义的模式建模的输入参数。
应用程序负责使用工具名称识别并使用提供的输入参数执行工具。
工具调用的结果由应用程序处理。
应用程序将工具调用结果发送回模型。
该模型使用工具调用结果作为附加上下文生成最终响应。
有关如何将此功能用于不同AI模型的更多信息,请参阅工具调用文档。
Evaluating AI responses
有效评估人工智能系统响应用户请求的输出对于确保最终应用程序的准确性和有用性非常重要。一些新兴技术使预训练模型本身能够用于此目的。
此评估过程涉及分析生成的响应是否与用户的意图和查询的上下文一致。相关性、连贯性和事实正确性等指标用于衡量人工智能生成的响应的质量。
一种方法涉及呈现用户的请求和AI模型对模型的响应,查询响应是否与提供的数据一致。
此外,利用矢量数据库中存储的信息作为补充数据可以增强评估过程,有助于确定响应相关性。
Spring AI项目提供了一个Evaluator API,目前可以访问评估模型响应的基本策略。有关更多信息,请参阅评估测试文档。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)