《从零构建大模型》系列(14):词元嵌入——语言的高维密码本
本文系统阐述了神经网络中词嵌入层的核心原理与技术实现。主要内容包括:1)嵌入层将离散符号映射到连续向量空间的数学本质;2)PyTorch实现及GPT等大模型的嵌入架构剖析;3)嵌入维度选择、权重初始化、参数共享等12项关键技术;4)位置编码的演进与最新实践。文章通过可视化分析揭示了嵌入空间的语义特征,比较了不同模型的实现差异,并提供了参数配置的黄金法则。最后探讨了动态嵌入、量子化嵌入等前沿方向,为
·

目录
神经网络的语言接口:本文将揭秘词元ID如何转化为连续向量表示,开启大语言模型理解语义的关键第一步。
一、嵌入层:从离散符号到连续空间
1.1 为什么需要嵌入?
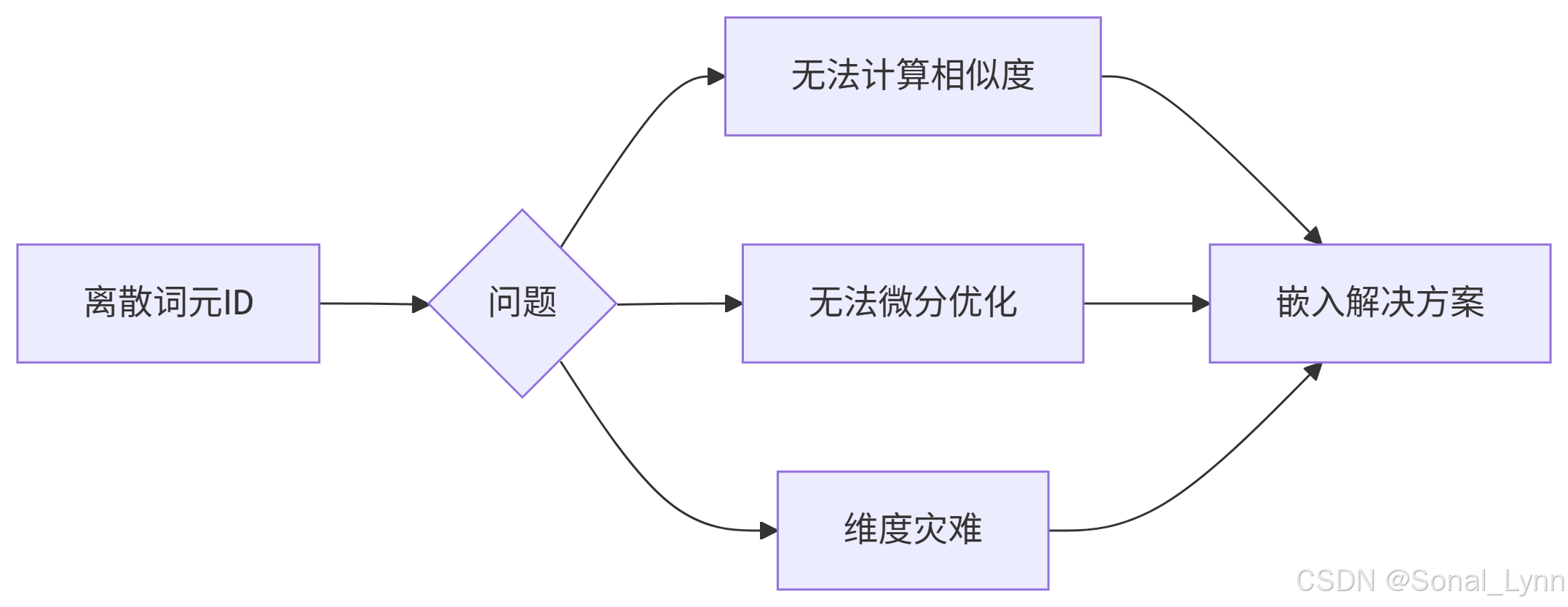
传统方法对比:
| 表示方法 | 示例 | 维度 | 可计算性 | 语义保留 |
|---|---|---|---|---|
| 独热编码 | [0,0,1,0] | 词表大小 | ✗ | ✗ |
| 整数索引 | 42 | 1 | ✗ | ✗ |
| 嵌入向量 | [0.24, -0.87, 1.32] | d_model | ✓ | ✓ |
二、嵌入层数学原理
2.1 嵌入层本质
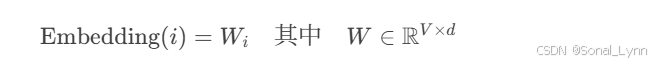
2.2 与独热编码的关系

数学等价:
![]()
三、PyTorch嵌入层实战
3.1 基础实现
import torch
import torch.nn as nn
# 设置随机种子确保可复现
torch.manual_seed(123)
# 配置参数
vocab_size = 6 # 词汇表大小
embedding_dim = 3 # 嵌入维度
input_ids = torch.tensor([2, 3, 5, 1]) # 输入词元ID
# 创建嵌入层
embedding_layer = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=embedding_dim
)
# 查看初始权重
print("嵌入层权重矩阵:")
print(embedding_layer.weight)
print(f"形状: {embedding_layer.weight.shape}")
# 获取嵌入向量
embeddings = embedding_layer(input_ids)
print("\n输入词元ID的嵌入向量:")
print(embeddings)输出分析:
嵌入层权重矩阵:
Parameter containing:
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)
形状: torch.Size([6, 3])
输入词元ID的嵌入向量:
tensor([[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-2.8400, -0.7849, -1.4096],
[ 0.9178, 1.5810, 1.3010]], grad_fn=<EmbeddingBackward0>)3.2 权重初始化策略
| 初始化方法 | 公式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 均匀分布 | 简单 | 可能梯度消失 | 小型模型 | |
| 正态分布 | 标准 | 需调整方差 | GPT系列 | |
| Xavier | 保持方差 | 假设线性 | Transformer | |
| Kaiming | 适合ReLU | 需调整 | ResNet |
自定义初始化:
# Xavier初始化嵌入层
def init_embedding(module):
if isinstance(module, nn.Embedding):
nn.init.xavier_uniform_(module.weight)
# 填充词元初始化为零
if module.padding_idx is not None:
nn.init.zeros_(module.weight[module.padding_idx])
embedding_layer.apply(init_embedding)四、嵌入层可视化:理解高维空间
4.1 降维可视化技术
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
# 选择示例词元
words = ["king", "queen", "man", "woman", "computer", "data", "algorithm"]
word_ids = [tokenizer.encode(word)[0] for word in words]
# 获取嵌入向量
embeddings = embedding_layer(torch.tensor(word_ids)).detach().numpy()
# t-SNE降维
tsne = TSNE(n_components=2, perplexity=2, random_state=42)
reduced_emb = tsne.fit_transform(embeddings)
# 可视化
plt.figure(figsize=(10, 8))
for i, word in enumerate(words):
plt.scatter(reduced_emb[i, 0], reduced_emb[i, 1], marker='o')
plt.text(reduced_emb[i, 0]+0.1, reduced_emb[i, 1]+0.1, word, fontsize=12)
plt.title('词元嵌入空间可视化 (t-SNE降维)')
plt.xlabel('维度1')
plt.ylabel('维度2')
plt.grid(alpha=0.2)
plt.savefig('embedding_visualization.png', dpi=300)4.2 语义关系探索
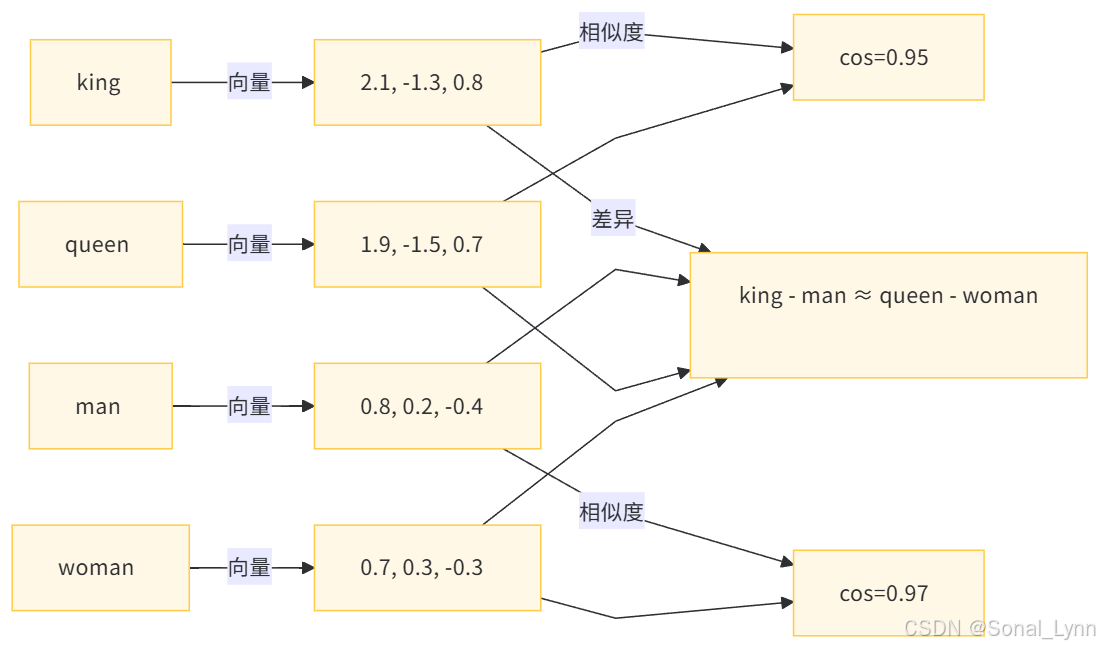
五、GPT嵌入层架构剖析
5.1 现代大语言模型嵌入层
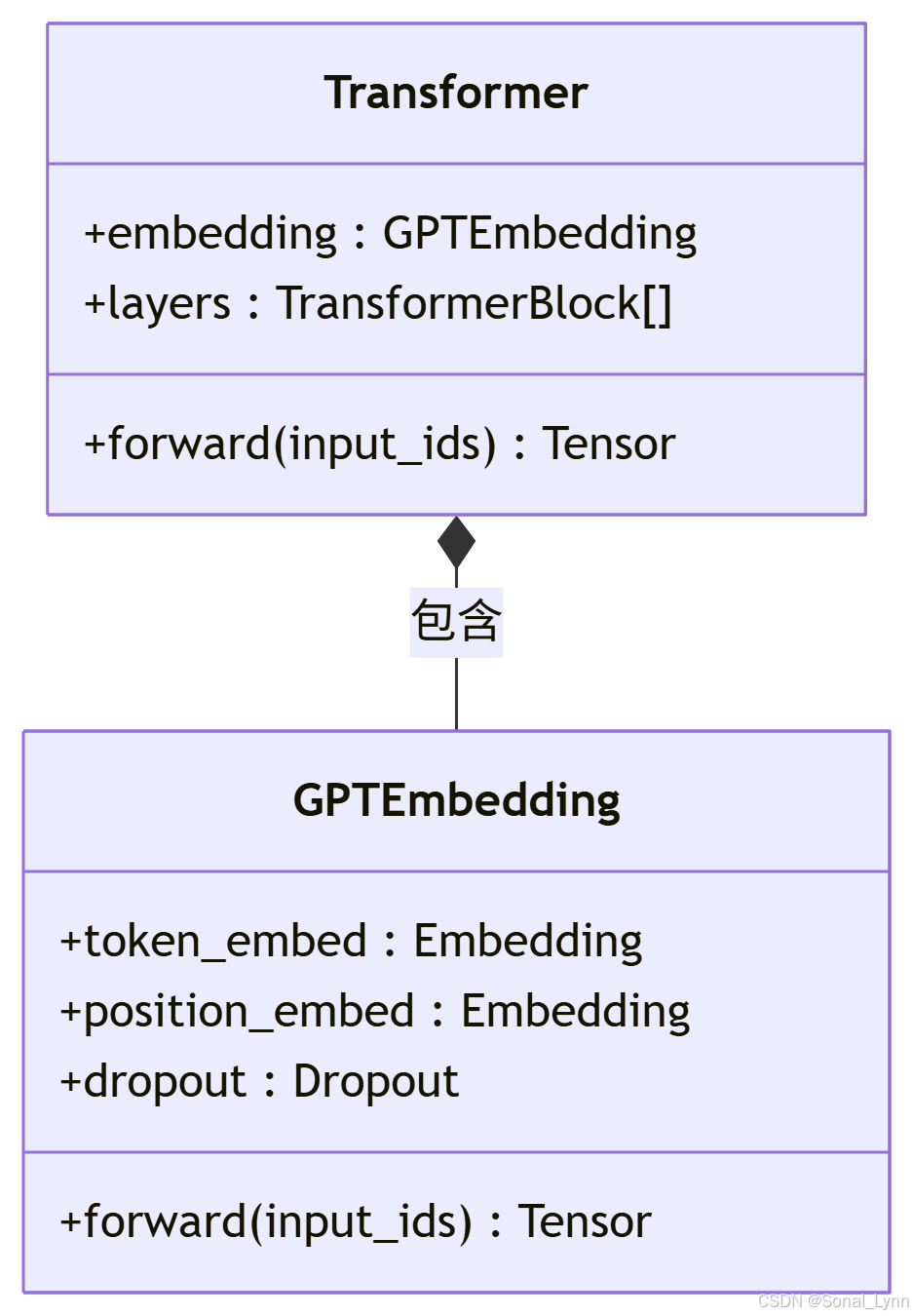
5.2 完整实现
class GPTEmbeddings(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.token_embed = nn.Embedding(
config.vocab_size,
config.hidden_size
)
self.position_embed = nn.Embedding(
config.max_position_embeddings,
config.hidden_size
)
self.dropout = nn.Dropout(config.emb_dropout_prob)
# 初始化权重
self.apply(self._init_weights)
def _init_weights(self, module):
"""专用初始化策略"""
if isinstance(module, nn.Embedding):
# 与GPT-3一致的初始化
nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.padding_idx is not None:
nn.init.zeros_(module.weight[module.padding_idx])
def forward(self, input_ids):
# 词元嵌入
token_embeds = self.token_embed(input_ids)
# 位置嵌入
seq_length = input_ids.size(1)
position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device)
position_embeds = self.position_embed(position_ids)
# 组合嵌入
embeddings = token_embeds + position_embeds
return self.dropout(embeddings)
# 配置示例
class GPTConfig:
vocab_size = 50257
hidden_size = 768
max_position_embeddings = 1024
emb_dropout_prob = 0.1
# 使用示例
config = GPTConfig()
embedding_layer = GPTEmbeddings(config)
input_ids = torch.randint(0, config.vocab_size, (2, 64)) # 2个样本,长度64
embeddings = embedding_layer(input_ids)
print(f"嵌入张量形状: {embeddings.shape}") # torch.Size([2, 64, 768])六、嵌入维度:模型性能的关键因素
6.1 维度选择影响
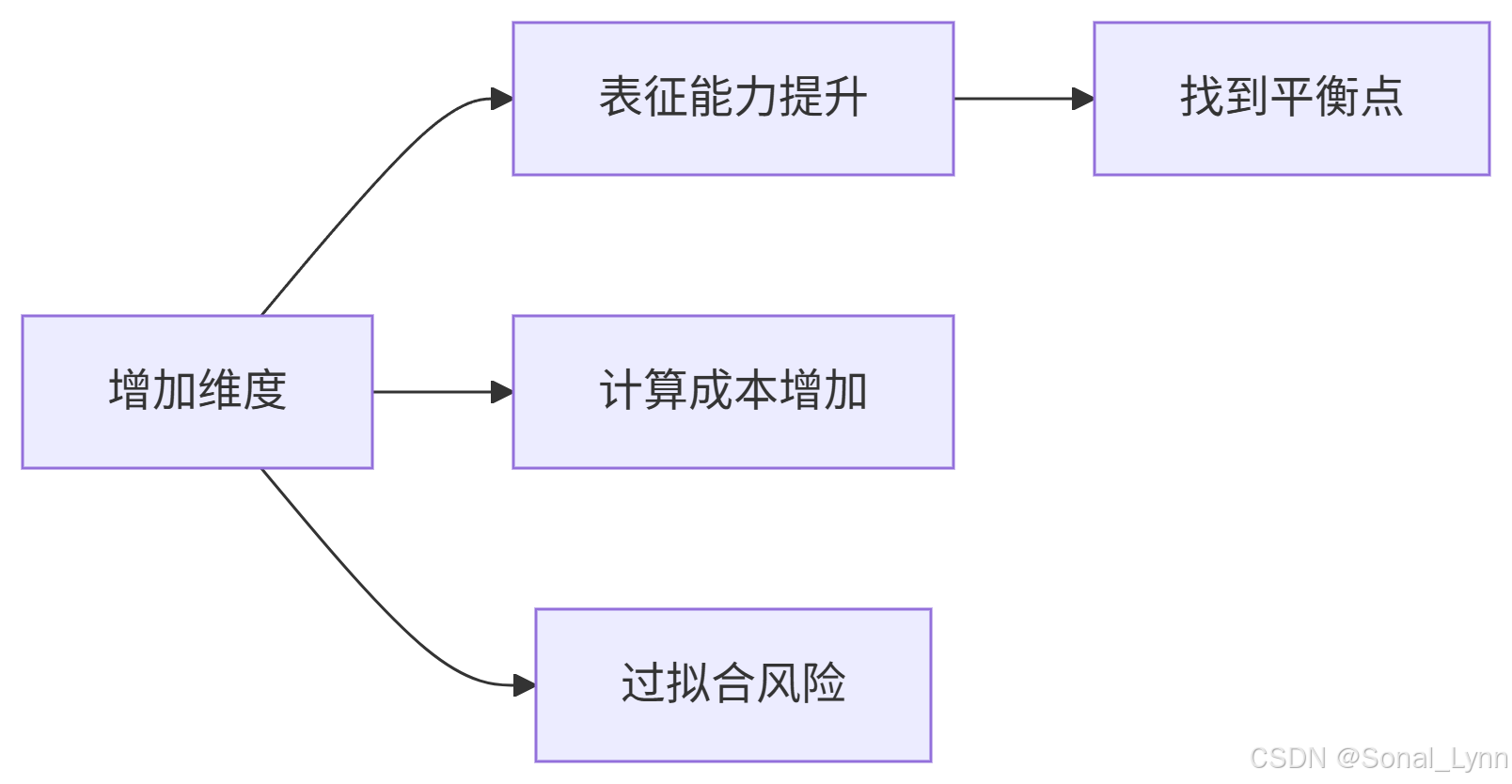
6.2 主流模型配置
| 模型 | 嵌入维度 | 层数 | 总参数量 | 性能表现 |
|---|---|---|---|---|
| GPT-1 | 768 | 12 | 117M | 基础 |
| GPT-2 | 1280 | 48 | 1.5B | 显著提升 |
| GPT-3 | 12288 | 96 | 175B | 突破性 |
| LLaMA-7B | 4096 | 32 | 6.7B | 高效平衡 |
| Mistral-8x7B | 4096 | 32 | 42B | MoE架构 |
七、高级嵌入技术
7.1 参数共享
# 嵌入层与输出层共享权重
class GPTWithSharedEmbedding(nn.Module):
def __init__(self, config):
super().__init__()
self.embedding = GPTEmbeddings(config)
self.transformer = TransformerBlocks(config)
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
# 权重共享
self.lm_head.weight = self.embedding.token_embed.weight
def forward(self, input_ids):
x = self.embedding(input_ids)
x = self.transformer(x)
return self.lm_head(x)7.2 因子化嵌入
# 大型词汇表的优化技术
class FactorizedEmbedding(nn.Module):
def __init__(self, vocab_size, hidden_size, factor_size=128):
super().__init__()
self.factor_embed = nn.Embedding(vocab_size, factor_size)
self.transform = nn.Linear(factor_size, hidden_size)
def forward(self, input_ids):
factors = self.factor_embed(input_ids)
return self.transform(factors)7.3 自适应嵌入
# 根据词频调整嵌入维度
class AdaptiveEmbedding(nn.Module):
def __init__(self, vocab, cutoffs, dims):
super().__init__()
self.embeddings = nn.ModuleList()
for i in range(len(cutoffs)-1):
low, high = cutoffs[i], cutoffs[i+1]
emb_dim = dims[i]
self.embeddings.append(nn.Embedding(high-low, emb_dim))
def forward(self, input_ids):
outputs = []
for id_val in input_ids.view(-1):
for i, emb in enumerate(self.embeddings):
if cutoffs[i] <= id_val < cutoffs[i+1]:
outputs.append(emb(torch.tensor([id_val - cutoffs[i]])))
break
return torch.stack(outputs).view(*input_ids.shape, -1)八、嵌入层训练动态
8.1 训练过程可视化
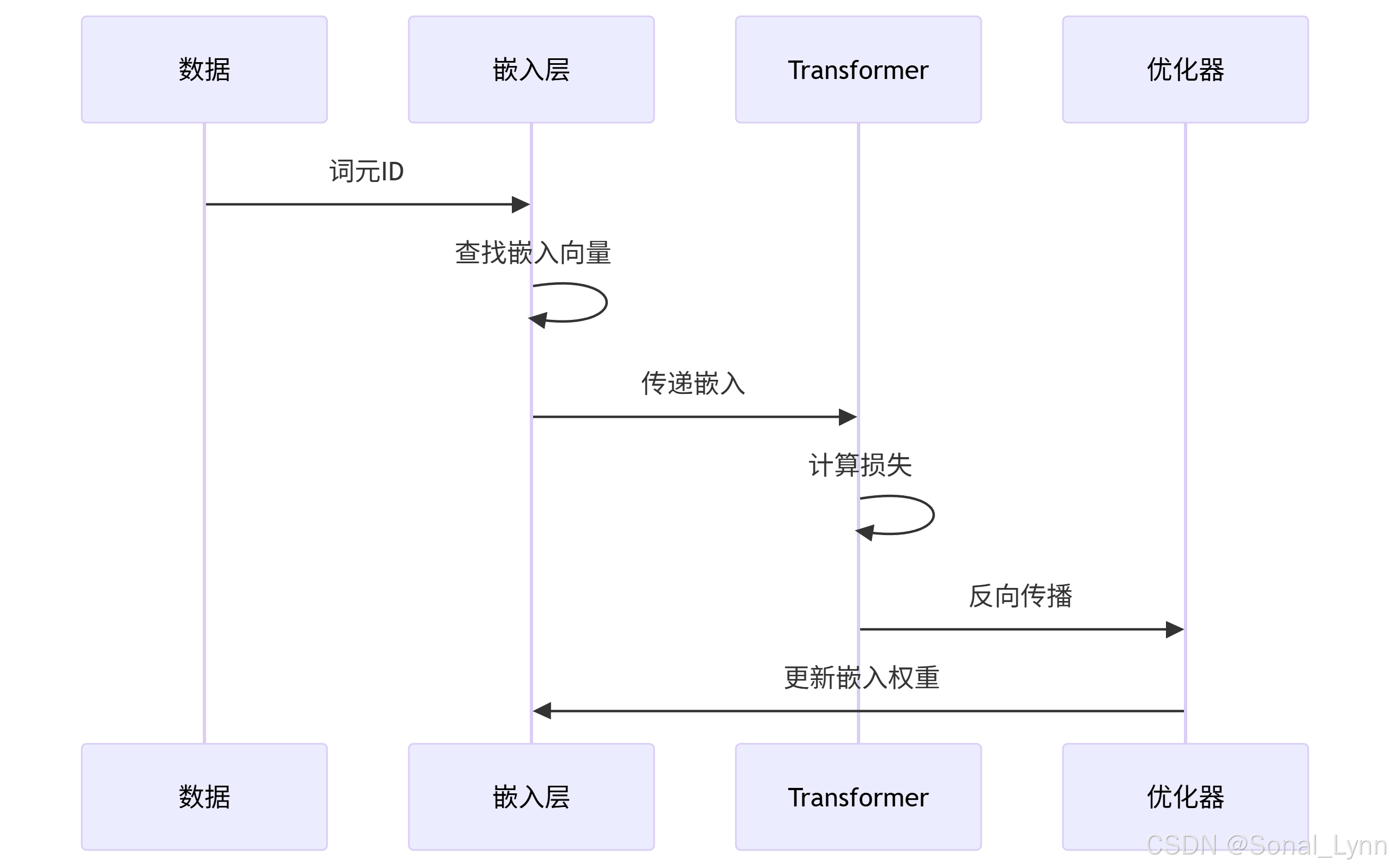
8.2 嵌入权重演变
# 记录嵌入权重变化
def track_embedding_evolution(model, word, tokenizer, num_epochs=10):
word_id = tokenizer.encode(word)[0]
embeddings = []
for epoch in range(num_epochs):
# 训练模型...
emb = model.embedding.token_embed.weight[word_id].detach().cpu().numpy()
embeddings.append(emb)
# 可视化
plt.figure(figsize=(12, 6))
for dim in range(embeddings[0].shape[0]):
dim_vals = [emb[dim] for emb in embeddings]
plt.plot(dim_vals, label=f'Dim {dim+1}')
plt.title(f'"{word}"嵌入向量在训练中的演变')
plt.xlabel('训练周期')
plt.ylabel('嵌入值')
plt.legend()
plt.grid(alpha=0.3)
plt.savefig(f'{word}_embedding_evolution.png', dpi=300)九、位置编码:嵌入的关键补充
9.1 为什么需要位置信息?
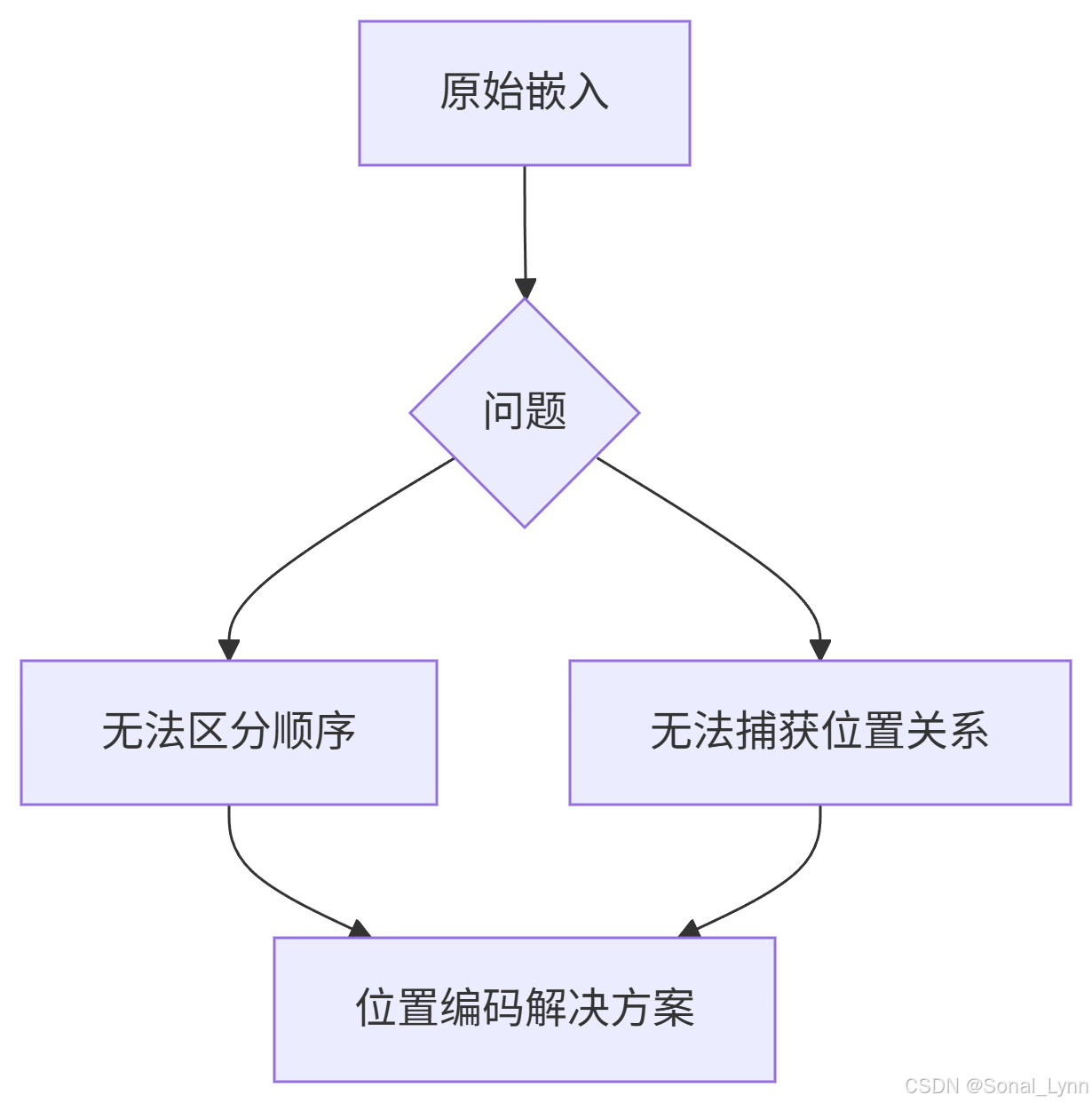 9.2 正弦位置编码
9.2 正弦位置编码
class SinusoidalPositionEmbedding(nn.Module):
def __init__(self, max_len, d_model):
super().__init__()
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(max_len, d_model)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:x.size(1)]GPT位置编码创新:
| 模型 | 位置编码方案 | 特点 | 最大长度 |
|---|---|---|---|
| GPT-1 | 可学习位置嵌入 | 简单直接 | 512 |
| GPT-2 | 可学习位置嵌入 | 更长上下文 | 1024 |
| GPT-3 | 旋转位置编码 | 更好的长程依赖 | 2048 |
| LLaMA | RoPE | 相对位置编码 | 4096 |
十、嵌入层最佳实践
10.1 配置黄金法则
| 参数 | 推荐值 | 说明 |
|---|---|---|
| 嵌入维度 | 768-4096 | 平衡性能与效率 |
| 初始化 | N(0, 0.02) | GPT系列验证 |
| Dropout | 0.1 | 防止过拟合 |
| 权重共享 | 开启 | 减少参数+提升一致性 |
| 位置编码 | 旋转位置编码 | 最新最佳实践 |
10.2 常见陷阱及规避

十一、前沿研究与发展
11.1 新型嵌入技术
-
动态嵌入:
# 上下文相关的动态嵌入 context_emb = model.context_encoder(context_text) word_emb = base_emb + context_emb -
量子化嵌入:
# 1-bit量化嵌入 quant_emb = torch.sign(original_emb) -
跨模态对齐:
# 文本-图像联合嵌入 text_emb = text_encoder("一只猫") image_emb = image_encoder(cat_image) loss = contrastive_loss(text_emb, image_emb)
11.2 开放挑战
-
多语言嵌入:统一跨语言表示
-
增量学习:动态扩展词汇表
-
可解释性:理解嵌入空间语义
-
隐私保护:防止嵌入泄漏敏感信息
十二、学习资源宝库
12.1 推荐工具
| 类型 | 工具名 | 特点 |
|---|---|---|
| 可视化 | TensorBoard Projector | 交互式嵌入探索 |
| 词向量 | Gensim | Word2Vec/FastText |
| 大模型嵌入 | HuggingFace Transformers | 预训练嵌入 |
| 降维 | UMAP | 高质量可视化 |
12.2 必读论文
-
Efficient Estimation of Word Representations in Vector Space (Word2Vec)
-
Attention Is All You Need (Transformer位置编码)
-
RoFormer: Enhanced Transformer with Rotary Position Embedding (旋转位置编码)
实践项目:
结语:词元嵌入是连接离散符号与神经连续空间的魔法桥梁。掌握这一技术,您将打开大语言模型理解人类语言的大门!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)