动手学AI 第一部分第一节——从数据准备到模型训练的完整流程解析
本文是AI深度学习原创教程的开篇之作,系统地介绍了训练模型的完整流程。教程将分为CV、NLP、具身智能等模块展开,首节重点讲解基础核心知识。内容包括:1)数据准备阶段的数据收集、清洗和增强技术;2)模型结构选择与搭建方法;3)关键超参数(学习率、批量大小等)的设置原则;4)训练优化过程及Adam等优化器的应用。通过ResNet50微调等实例,文章以计算机视觉为例,详细解析了从数据预处理到模型训练的
从这篇文章开始,我们将由浅入深,由表及里地为大家讲解有关于AI的知识,特别是针对于深度学习的,例如CV,NLP,具身智能等各个领域。也即我的AI原创教程。
我们将我们的领域分成了若干个板块,我们打算以具体的研究方向作为划分。例如CV、具身智能模块等。
那么本节,将作为第一部分的第一节,也是整个原创教程的开始。
在第一个板块里呢,我们将会为大家带来深度学习里面非常重要的但相对来说也是比较基础的知识。
OK。那我们就开始我们本节的内容吧。
在深度学习的宏大领域中,训练模型是迈向智能应用的关键一步,它就像搭建一座高楼的基石,其重要性不言而喻。接下来,就让我们一同深入探索训练模型的奥秘以及常见步骤。
我们本节将会从宏观上来去为大家阐述,训练模型都需要经历哪些过程和步骤。
1、数据准备
训练模型的第一步是准备要训练的数据,这是整个训练过程的基础。
就如同建造房屋需要优质的建筑材料一样,高质量的数据对于训练出性能卓越的模型至关重要。在数据收集阶段,我们需要广泛地收集与研究方向相关的数据。以计算机视觉(CV)领域为例,如果要训练一个识别猫和狗的图像分类模型,就需要收集大量猫和狗的图片,这些图片的来源可以是互联网、公开数据集,甚至是自己拍摄。
我们以resnet50的微调为例,当我们想要微调或者训练这个模型的时候,我们首先需要拿到我们需要的数据:
例如下面:
那么我们在代码中,就要先把这些数据给读进来,然后进行处理。
还是以这个为例子,那么这个代码就是在进行读取数据,然后进行数据处理:
这个是在定义数据变换规则(类似于自定义数据中的自定义Dataloader)
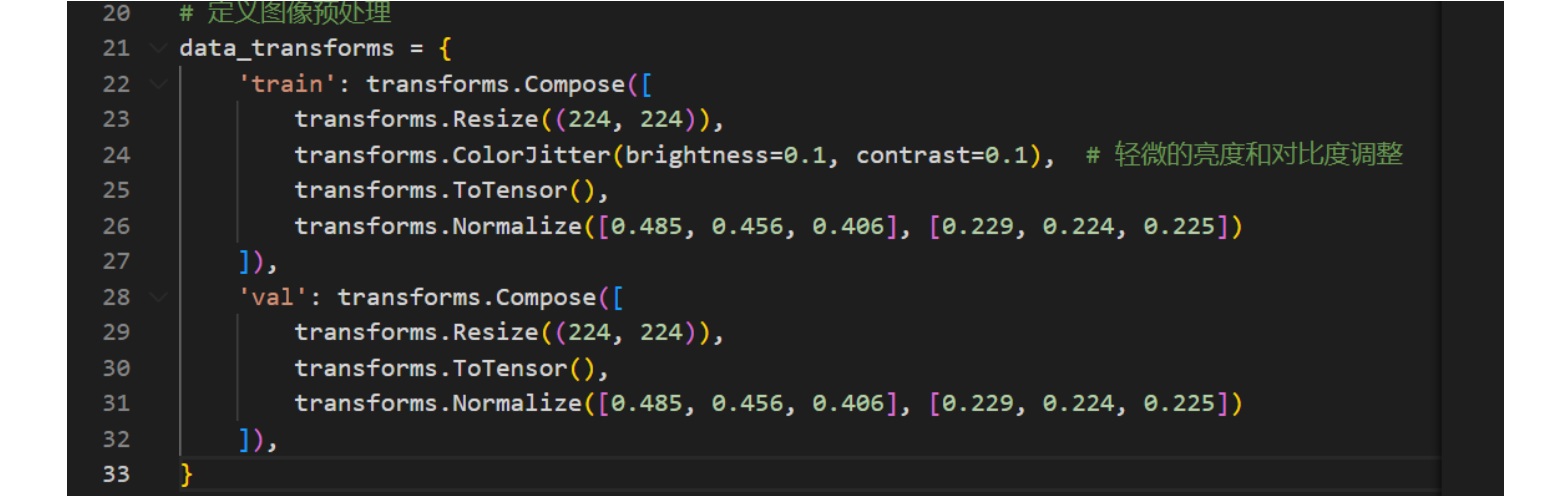
这个是在用构建的变换规则来去构建dataset,供下面的DataLoader使用:
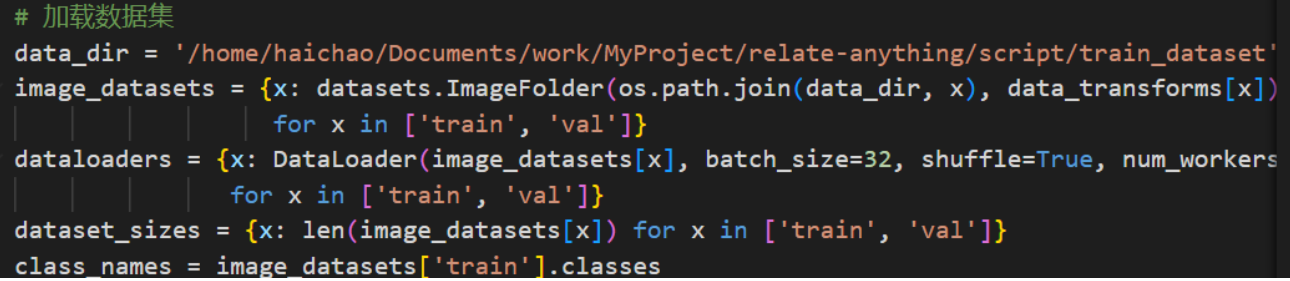
在处理数据的时候,也可能会伴随着数据清洗。数据中往往存在噪声、错误标注等问题。比如在图像数据中,可能存在模糊不清的图片,或者标注错误的类别。通过数据清洗,我们可以去除这些不良数据,提高数据的质量。
一般的处理,可以包含多种操作,如归一化、标准化等。在图像数据中,通常会将图像的像素值归一化到 0 - 1 的范围,这样可以加速模型的收敛,提高训练效率。同时,数据增强也是常用的手段,通过对图像进行旋转、缩放、裁剪等操作,扩充数据集的多样性,让模型能够学习到更多不同角度和场景下的特征,增强模型的泛化能力。
2、设置模型结构
当数据准备就绪,接下来就要选择合适的模型。深度学习领域有众多经典的模型架构,不同的模型适用于不同的任务。在 CV 领域,像卷积神经网络(CNN)就是图像识别、目标检测等任务的常用模型。对于简单的图像分类任务,LeNet 可能是一个不错的选择,它是最早的 CNN 模型之一,结构相对简单,易于理解和实现。
而对于复杂的图像任务,如识别多种不同类别的物体,ResNet 则更为合适,它通过引入残差连接解决了深度神经网络训练过程中的梯度消失问题,能够构建更深层次的网络,从而学习到更丰富的图像特征。
那么模型结构通常可以写成下面的形式:
class MyModel(nn.Module):
def __init__(self):
super(MyModel).__init__()
self.Image_encoder = nn.Sequential(
nn.Linear(6 * 128 * 128, 768),
nn.Linear(768, 128)
)
self.layers = nn.ModuleList([])
for _ in range(8):
self.layers.append(
nn.ModuleList([
MutiHeadAttention()
])
)
def forward(self, agent_view, eye_in_hand, extra_state, init_state, actions_truth):
# 加噪声, image condition
# b, t, c = actions_truth.shape
#
# noise = np.random.normal(loc=0, scale=1, size=(t, c))
# noise = noise.reshape(b, -1)
# print(noise.shape)
# action = actions_truth + noise
# # 两个图像拼在一起,在C维度上合并,然后经过编码,得到(b, t, c, h, w);再经过decoder变换
# image = np.concatenate(agent_view, eye_in_hand, dim=2)
# image = rearrange(image, 'b t c h w -> b t (c h w)')
#
# ee_state = extra_state['ee_states']
# gripper_state = extra_state['gripper_states']
# img = self.Image_encoder(image)
# # img = rearrange(img, 'b t (c h w) -> b t c h w', c=3, h=h, w=w)
# task_dict = get_task_bert_embs()
# task_emb = task_dict[0]
#
#
#
# x = np.concatenate(actions_truth, img)
# # x.reshape()
#
# for attn in self.layers:
return actions_truth
它往往都是继承nn.Module,然后里面至少会有__ init __ 函数和 __ forward __ 函数。
一个是初始化的时候用的,一个是调用该类的时候,会调用forward函数。
3、超参数设置
选定模型后,就需要设置超参数。超参数是在模型训练之前手动设置的参数,它们对模型的性能有着重要影响。
常见的超参数包括学习率、批量大小、迭代次数等。
**学习率决定了模型在训练过程中参数更新的步长。**如果学习率设置过大,模型可能会在训练过程中无法收敛,甚至发散;如果学习率设置过小,模型的训练速度会非常缓慢,需要更多的训练时间。通常可以通过试验不同的学习率值,观察模型在验证集上的性能表现,来选择一个合适的学习率。
**批量大小指的是每次训练时输入模型的数据样本数量。**较大的批量大小可以加快训练速度,但可能会占用更多的内存,并且可能导致模型在训练过程中陷入局部最优解;较小的批量大小可以使模型更充分地学习每个样本的特征,但训练速度会相对较慢。迭代次数则决定了模型对整个训练数据集进行训练的轮数。
一般来说,随着迭代次数的增加,模型在训练集上的损失会逐渐减小,但当迭代次数过多时,可能会出现过拟合现象,即模型在训练集上表现良好,但在测试集上性能大幅下降。因此,需要在训练过程中监控模型在验证集上的性能,选择一个合适的迭代次数,以平衡模型的准确性和泛化能力。
4、模型训练与优化
**一切准备就绪后,就可以开始模型的训练了。**在训练过程中,模型会根据输入的数据和设置的超参数,通过前向传播计算预测结果,然后根据预测结果与真实标签之间的差异,使用反向传播算法计算梯度,更新模型的参数。这个过程会不断重复,直到模型收敛或者达到预设的训练条件。
为了加速模型的训练和提高模型的性能,通常会使用优化器。常见的优化器有随机梯度下降(SGD)、Adagrad、Adadelta、Adam 等。SGD 是最基本的优化器,它每次随机选择一个小批量的数据样本计算梯度并更新参数。Adam 优化器则结合了 Adagrad 和 RMSProp 的优点,能够自适应地调整学习率,在许多任务中表现出良好的性能。在训练过程中,可以根据模型的特点和训练情况选择合适的优化器。
例如,这就是Adam优化器:

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 18
18 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)