Kaggle竞赛题思路解析1:Binary Prediction with a Rainfall Dataset
Kaggle赛题思路
目标:预测一年中每天的降雨量
提交结果将根据预测概率与实际目标之间的ROC曲线下面积(AUC)进行评估
提交文件
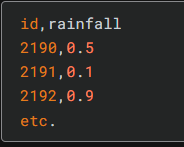
对于测试集中每个 ID,你必须预测该目标降雨的概率。文件应包含表头,并具有以下格式:
数据集说明
本次比赛所使用的数据集(包括训练集和测试集)是由一个深度学习模型生成的,该模型是基于 “使用机器学习进行降雨预测” 数据集进行训练的。
特征的分布与原始数据集非常接近,但并不完全相同。
你可以自由使用原始数据集来参与本次比赛,既可以用来探索它与当前数据之间的差异,也可以尝试将其整合进训练过程中,以观察是否能够提升模型的性能。
文件说明
-
train.csv:训练数据集,
rainfall是一个二元目标变量(表示是否下雨)。 -
test.csv:测试数据集,你的目标是为每一行预测下雨的概率。
-
sample_submission.csv:一个格式正确的示例提交文件,可作为参考模板
🧠 一、明确问题与数据结构
🎯 比赛目标:
预测每日是否降雨(二分类,目标为 rainfall 的概率),使用 AUC(ROC曲线下的面积) 作为评估指标。
🗃 数据结构:
-
训练集:6 年,共 2190 行(365 天 × 6)
-
测试集:2 年,共 730 行
-
原始数据集仅有 1 年,比赛数据为合成的
🧩 时间序列判断:
虽然官方未明确声明是时间序列,但以下现象暗示我们应按时间序列处理:
-
测试集为后两年
-
公私榜单为时间后段与前段切分
-
id大小等于样本在时间上的顺序 -
多个提交显示 shift、diff 特征对模型提升明显
🏗 二、数据准备与特征工程
🔢 1. 数值型特征筛选:
排除 id 和 target 后的数值列作为基础特征集
num_cols = df.select_dtypes(include=[np.number]).columns.tolist() num_cols = [c for c in num_cols if c not in ['id', 'target']]
🧪 2. 特征工程模块
| 方法 | 作用 | 示例 |
|---|---|---|
| 交互特征 | 模拟变量乘积关系 | temp * humidity |
| 比例特征 | 模拟相对比值关系 | dewpoint / mintemp |
| 对数特征 | 减少偏态分布 | log(pressure) |
| 分箱特征 | 捕捉非线性区间趋势 | humidity → 5分位分箱 |
| 时间序列特征 | 模拟前后天趋势 | temp.shift(1)、temp.diff(1) |
| 周期性特征 | 年度循环模拟 | sin(2πday/365) |
代码结构已实现:
-
每类特征构建函数(如
create_interaction_features(df, num_cols)) -
分别生成新列,并与原始特征拼接
🧹 三、特征选择(防止维度爆炸)
from sklearn.feature_selection import SelectKBest, f_classif X_selected = SelectKBest(f_classif, k=50).fit_transform(X, y)
✅ 建议:
| 方法 | 说明 |
|---|---|
| SelectKBest | 快速选出最具线性相关性特征 |
| RFE(递归) | 尽管精度高,但计算量大,适合后期稳定精调 |
| 基于模型的选择 | 可用 XGBoost/LGBM 的 feature_importances_ 排序 |
🔁 四、交叉验证策略:GroupKFold 或 PurgedCV
推荐用法:
groups = train['id'] // 365 GroupKFold(n_splits=6).split(X, y, groups)
✅ 避免未来信息泄露,模拟时间“先训练、后预测”流程。
🤖 五、模型选择与训练
建议模型对比:
| 模型 | 特点 | 是否推荐 |
|---|---|---|
| LogisticRegression | 快速、可解释、适合 baseline | ✅ |
| RidgeClassifier | 更抗多重共线性 | ✅ |
| XGBoost | 强大的非线性拟合能力 | ✅ |
| TabPFN | 表格型神经网络,适合小数据 | ✅(可集成) |
| SVC(RAPIDS) | GPU 加速,高精度但慢 | 可选 |
代码片段:
!uv pip install --system --quiet scikit-learn==1.5.2 tabpfn
import numpy as np
import pandas as pd
from sklearn.model_selection import StratifiedKFold, cross_val_score
from tabpfn import TabPFNClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from catboost import CatBoostClassifier
X = pd.read_csv('/kaggle/input/playground-series-s5e3/train.csv', index_col='id')
y = X.pop('rainfall')
kfold = StratifiedKFold(10, shuffle=True, random_state=0)
models ={
'tabpfn': TabPFNClassifier(random_state=0),
'xgboost': XGBClassifier(n_jobs=4, random_state=0),
'lightgbm': LGBMClassifier(n_jobs=4, random_state=0, verbose=-1),
'catboost': CatBoostClassifier(thread_count=4, random_state=0,
verbose=0, task_type='GPU')
}
for m in models:
model = models[m]
%time scores = cross_val_score(model, X, y, cv=kfold, n_jobs=1, scoring='roc_auc')
print(F'{m}: {scores.mean():.5f} ± {scores.std():.5f}')
欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)