大模型的开发应用(十一):对话风格微调项目(下):微调与部署
上篇文章,我们完成了数据集的制作,得到了一个拥有近两万条样本的数据集,随后进行了模型选型,筛选出了 Qwen2.5-1.5B-Instruct 作为我们的基座模型,这篇文章,我们来完成剩下的工作,包括模型的微调与部署。
这里写目录标题
0 前言
上篇文章,我们完成了数据集的制作,得到了一个拥有近两万条样本的数据集,随后进行了模型选型,筛选出了 Qwen2.5-1.5B-Instruct 作为我们的基座模型,这篇文章,我们来完成剩下的工作,包括模型的微调与部署。
1 模型微调
1.1 找到配置文件
本项目使用的微调框架为 Xtuner,目前Xtuner只能支持Qwen1.5,但是没关系,我们可以把Qwen2.5的模型路径给配上。
先找到 qwen1_5_1_8b_chat 的配置文件,本项目使用 QLoRA 微调,所以我们这里用 qwen1_5_1_8b_chat_qlora_alpaca_e3.py,位置如下图所示:
注意,这里必须是 Chat 模型的配置文件,我一次找的是 qwen1_5_1_8b 不带 chat 的,结果因为对话模板问题导致评估的时候生成的东西怪怪的。
先把配置文件复制一份到 /data/coding/utils/xtuner 目录下,然后改名为 qwen2_5_chat_dialog_style.py,接下来我们修改这个配置文件。
1.2 修改配置文件
下面的参数我是根据每张卡 12G 显存的GPU来配置的,如果显存不一样,只需要调整 batch_size 和 max_length 即可。
PART 1
这一部分要改的东西是最多的,包括模型路径(pretrained_model_name_or_path)、数据集路径(data_files)、输入样本最大长度(max_length)、批次大小(batch_size)、训练的最大伦次(max_epochs)、保存的检查点数量(save_total_limit),还有用于主观评估的问题(evaluation_inputs),要修改的地方,我已经在下面的程序片段中注释出来了(evaluation_inputs没有注释出来)。
#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = "/data/coding/model_weights/Qwen/Qwen2.5-1.5B-Instruct" # 修改
use_varlen_attn = False
# Data
# alpaca_en_path = "tatsu-lab/alpaca" # 修改(注释掉)
data_files = "/data/coding/EmotionalDialogue/convert_data.json" # 修改
prompt_template = PROMPT_TEMPLATE.qwen_chat
max_length = 256 # 修改
pack_to_max_length = True
# parallel
sequence_parallel_size = 1
# Scheduler & Optimizer
batch_size = 8 # per_device # 修改
accumulative_counts = 16
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0
max_epochs = 1000 # 修改
optim_type = AdamW
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
warmup_ratio = 0.03
# Save
save_steps = 500
save_total_limit = 5 # Maximum checkpoints to keep (-1 means unlimited) # 修改
# Evaluate the generation performance during the training
evaluation_freq = 500
SYSTEM = SYSTEM_TEMPLATE.alpaca
evaluation_inputs = ["闺蜜把我秘密当谈资,该不该撕破脸?", "老妈非让我嫁给她同事儿子,怎么逃啊!",
"男朋友给女主播刷火箭,算精神出轨吗?", "室友半夜和对象视频娇喘,怎么提醒?",
"亲戚说我不生孩子就是自私,好想掀桌!", "领导周末发60秒语音矩阵,装没看见行吗?",
"被同事追问有没有整容,怎么优雅翻白眼?", "相亲对象第一次见面就想搂肩,油腻!",
"暗恋的人突然问我喜欢什么类型!", "针灸减肥被扎成仙人掌,一斤没掉!"]
这里用于主观评估的问题,至少要有5个以上,我们本次微调用的数据达到了万这个级别了,所以我这里选了10个,挑的方式很随机。如果是其他项目的话,用于主观评估的问题,需要有代表性,必须覆盖所有的目标场景。
PART 2
这部分只有一个 LoRA 的缩放系数改一下,一般情况下,lora_alpha 是秩的两倍,这是前人总结出来的经验,其他参数用默认。
#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(
type=AutoTokenizer.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
padding_side="right",
)
model = dict(
type=SupervisedFinetune,
use_varlen_attn=use_varlen_attn,
llm=dict(
type=AutoModelForCausalLM.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
torch_dtype=torch.float16,
quantization_config=dict(
type=BitsAndBytesConfig,
load_in_4bit=True,
load_in_8bit=False,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
),
),
lora=dict(
type=LoraConfig,
r=64,
lora_alpha=128, # 修改
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM",
),
)
PART 3
这部分主要改一下数据集相关的配置,就两个地方:dataset 和 dataset_map_fn,其他用默认:
#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(
type=process_hf_dataset,
# dataset=dict(type=load_dataset, path=alpaca_en_path), # 修改
dataset=dict(type=load_dataset, path="json",data_files=data_files), # 修改
tokenizer=tokenizer,
max_length=max_length,
# dataset_map_fn=alpaca_map_fn, # 修改
dataset_map_fn=None, # 修改
template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length,
use_varlen_attn=use_varlen_attn,
)
sampler = SequenceParallelSampler if sequence_parallel_size > 1 else DefaultSampler
train_dataloader = dict(
batch_size=batch_size,
num_workers=dataloader_num_workers,
dataset=alpaca_en,
sampler=dict(type=sampler, shuffle=True),
collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn),
)
使用Tensorboard实现训练可视化
在配置文件中,搜索 set visualizer ,然后按照如下方式修改:
# set visualizer
from mmengine.visualization import Visualizer, TensorboardVisBackend
visualizer = dict(type=Visualizer, vis_backends=[dict(type=TensorboardVisBackend)])
至此,配置文件修改完毕。
1.3 微调训练
如果选择单卡微调,那么命令为:
xtuner train qwen2_5_chat_dialog_style.py
显存占用情况如下: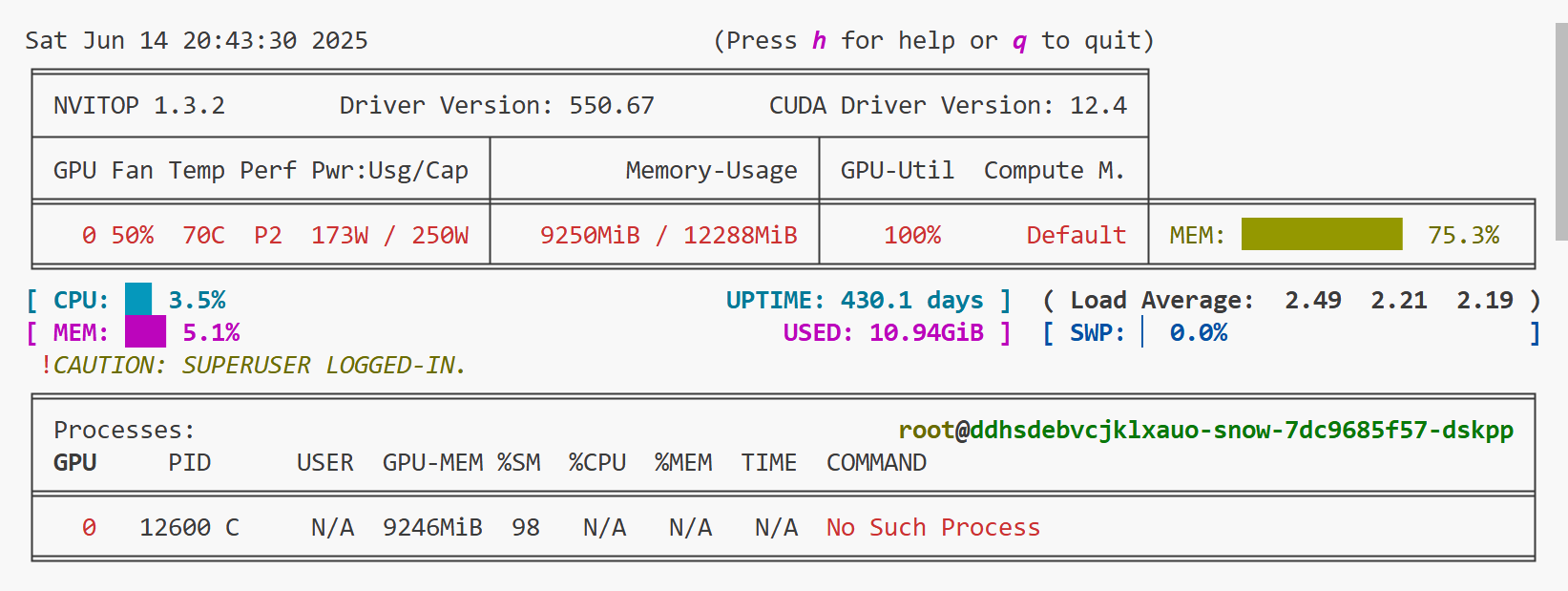
如果选择两张卡分布式微调,那么命令为:
NPROC_PER_NODE=2 xtuner train qwen2_5_chat_dialog_style.py --deepspeed deepspeed_zero2
因为我没跑,所以我也不知道显存占用情况怎么样,如果出现显存不足,那就把 --deepspeed 改成 deepspeed_zero2_offload 或deepspeed_zero3,也可以调小 batch_size 和 max_length。
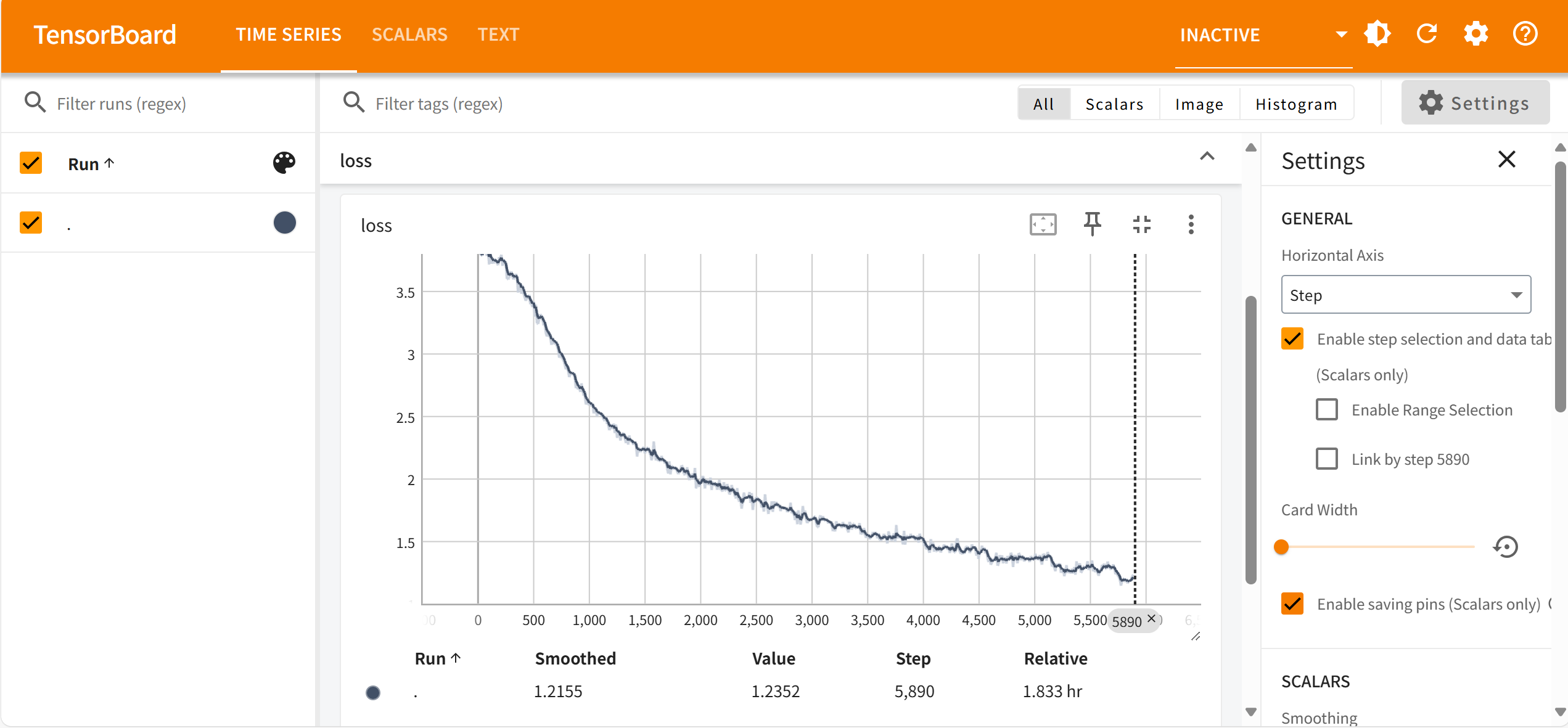
损失函数下降情况可以利用 tensorboard 查看,新开一个终端,输入以下命令:
tensorboard --logdir /data/coding/utils/xtuner/work_dirs/qwen2_5_chat_dialog_style/20250614_193605/vis_data
然后在指定窗口(http://localhost:6006/,远程服务器需要SSH连接或者端口转发)查看。
1.4 训练的停止条件
模型每训练完 500 个step,就会评估一次,下面截图是训练了3500个step后的评估结果:
关于训练什么时候停止,关键需要看这十个主观评估的问题是否都达到了预期的效果,一个都不能少。每达到预期效果,则说明没收敛,当然,即便这十个问题都达到了预期效果,也不能说模型收敛了,因为主观评估的问题太少,有一定的偶然性。不过大模型训练到收敛是有难度的,而且GPU算力资源有限,因此没必要训练到收敛,只要主观评估的结果,连续若干次都能达到预期,训练就可以停止了。
查看主观评估的结果,不需要去翻控制台的打印信息,也不需要去看日志,在工作目录下的 vis_data 目录中:
我训练了18000个step,大概相当于31个epoch,花了超过12小时,发现十个主观评估问题都达到要求后,就停止训练了。下面是损失函数下降情况: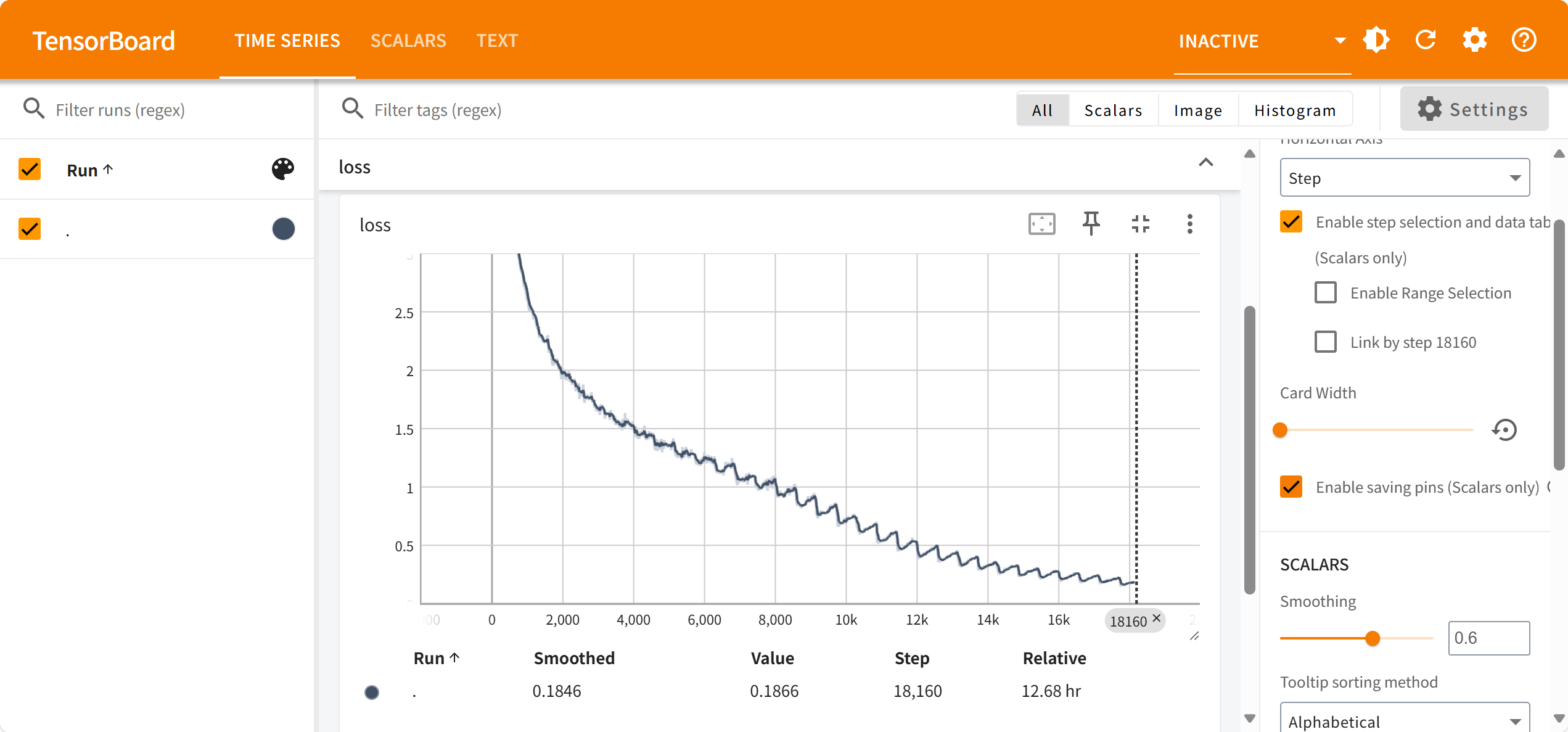
停止的时候,损失降到了0.2以下。
1.5 模型转化、测试与合并
模型的转化
我们使用模型最后一个检查点,因为Xtuner保存的检查点是低秩适配器,而且是以 pth 的文件保存,现在要将其转成 Hugging Face 模型,使用以下命令:
xtuner convert pth_to_hf qwen2_5_chat_dialog_style.py /data/coding/utils/xtuner/work_dirs/qwen2_5_chat_dialog_style/iter_18000.pth /data/coding/utils/xtuner/adapter_save_dir/qwen2_5/
转化成功后,控制台会显示 All done,同时在我们的指定路径下有会保存的 hugging face 模型。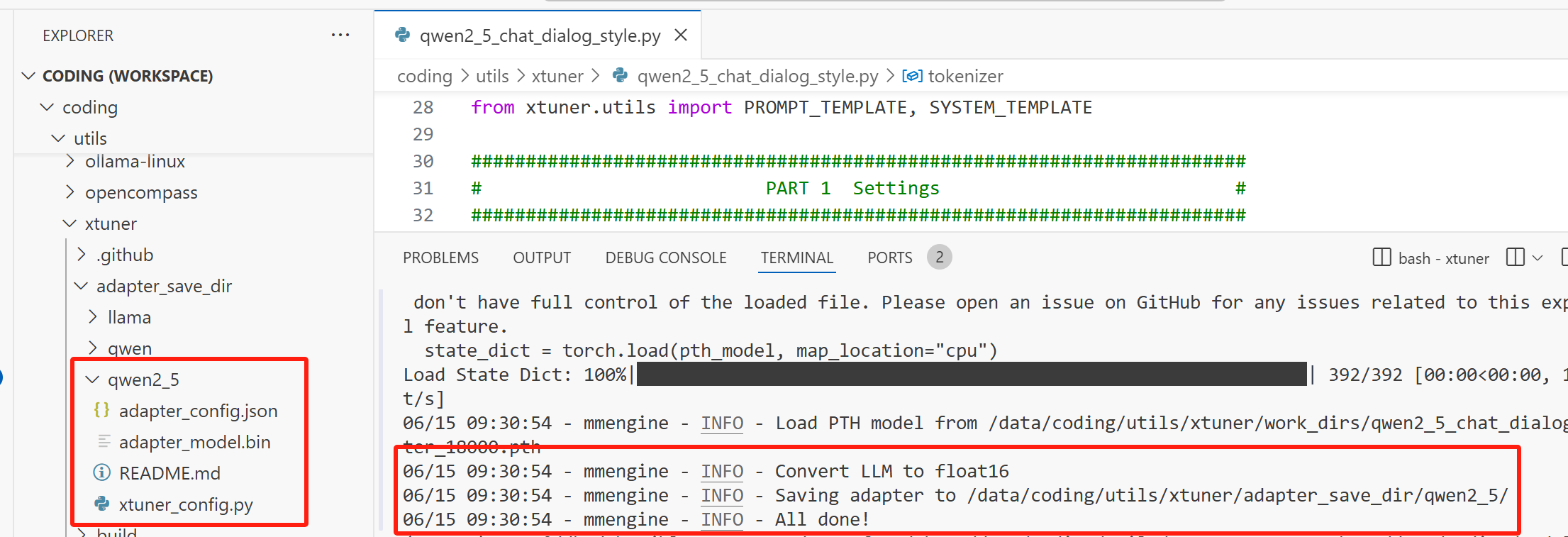
模型的测试
我们先来和模型对话看看效果怎么样,在终端输入:
xtuner chat /data/coding/model_weights/Qwen/Qwen2.5-1.5B-Instruct --adapter /data/coding/utils/xtuner/adapter_save_dir/qwen2_5 --prompt-template qwen_chat --system-template alpaca
下面是测试情况:
从上面的回复可以看到,模型的回答风格达到了我们的预期,说明模型达到想要的效果。我们还可以把十个主观评估的问题依次输入,或者输入其他可用于主观评估的问题。
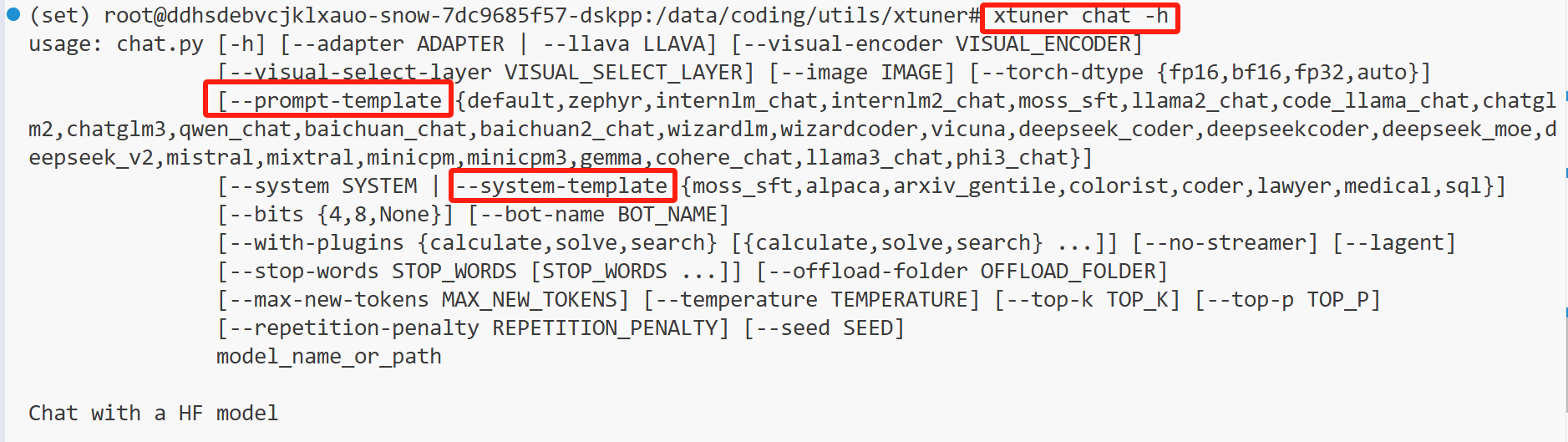
刚刚输入到终端的命令有两个模板, --prompt-template 是对话模板,--system-template 是系统提示词模板。因为我们在配置文件中,有 prompt_template = PROMPT_TEMPLATE.qwen_chat 和 SYSTEM = SYSTEM_TEMPLATE.alpaca 这两句话,所以指定对话模板为 qwen_chat,系统提示词模板为 alpaca。如果想查看有哪些模板,可以在终端输入 xtuner chat -h:
模型合并
终端输入以下命令:
xtuner convert merge /data/coding/model_weights/Qwen/Qwen2.5-1.5B-Instruct /data/coding/utils/xtuner/adapter_save_dir/qwen2_5/ /data/coding/EmotionalDialogue/model_weights/Qwen2.5-1.5B-Dialog-Style/
如果看到控制台输出 All done,说明合并成功。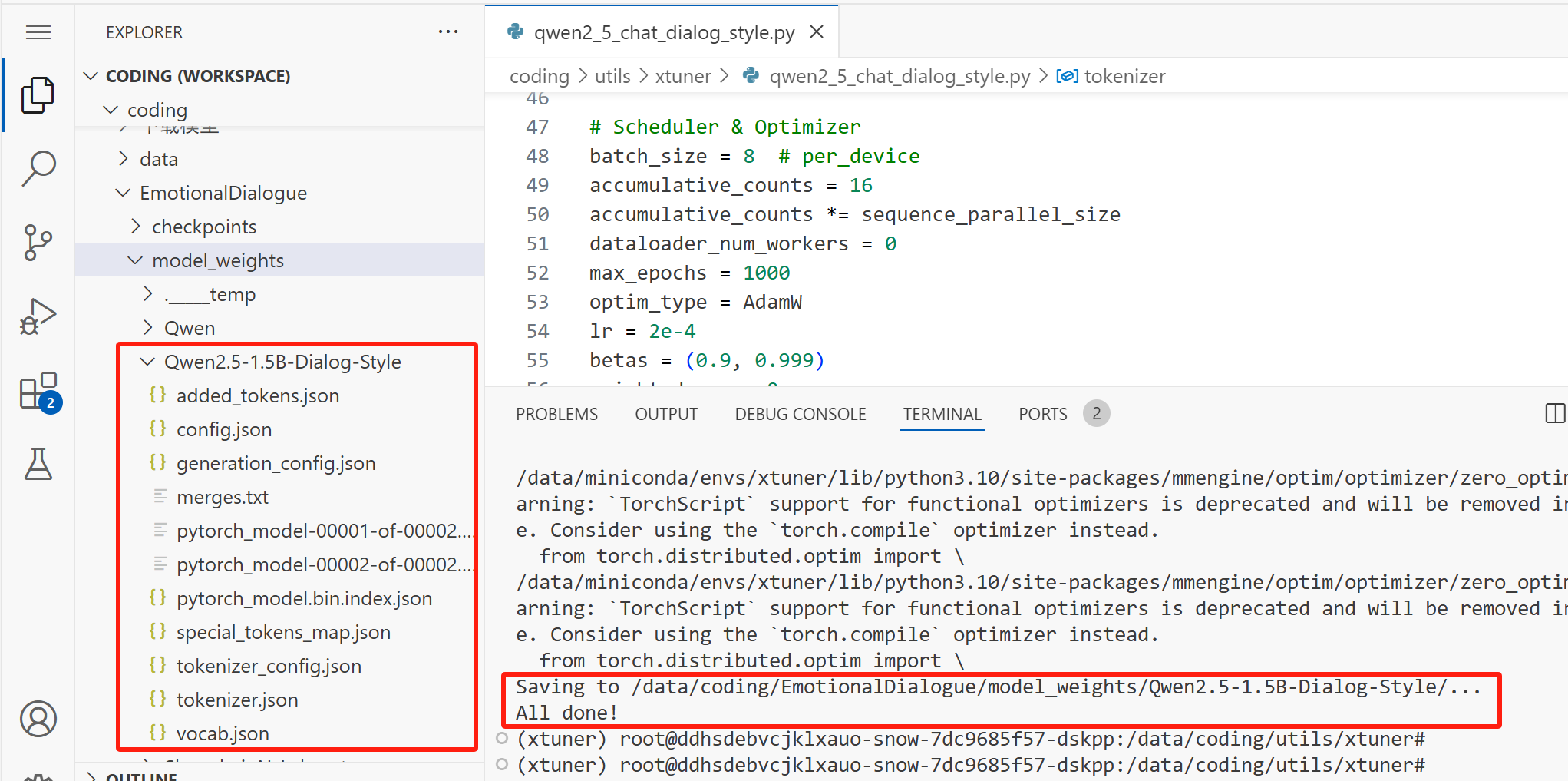
2 推理部署
2.1 对话模板对齐(本节有bug,具体看第2.4节)
我们在训练的时候,模板用的是 Xtuner 定义的 qwen_chat 和 alpaca,我们可以在 xtuner/xtuner/utils/templates.py 中找到它们的详细定义: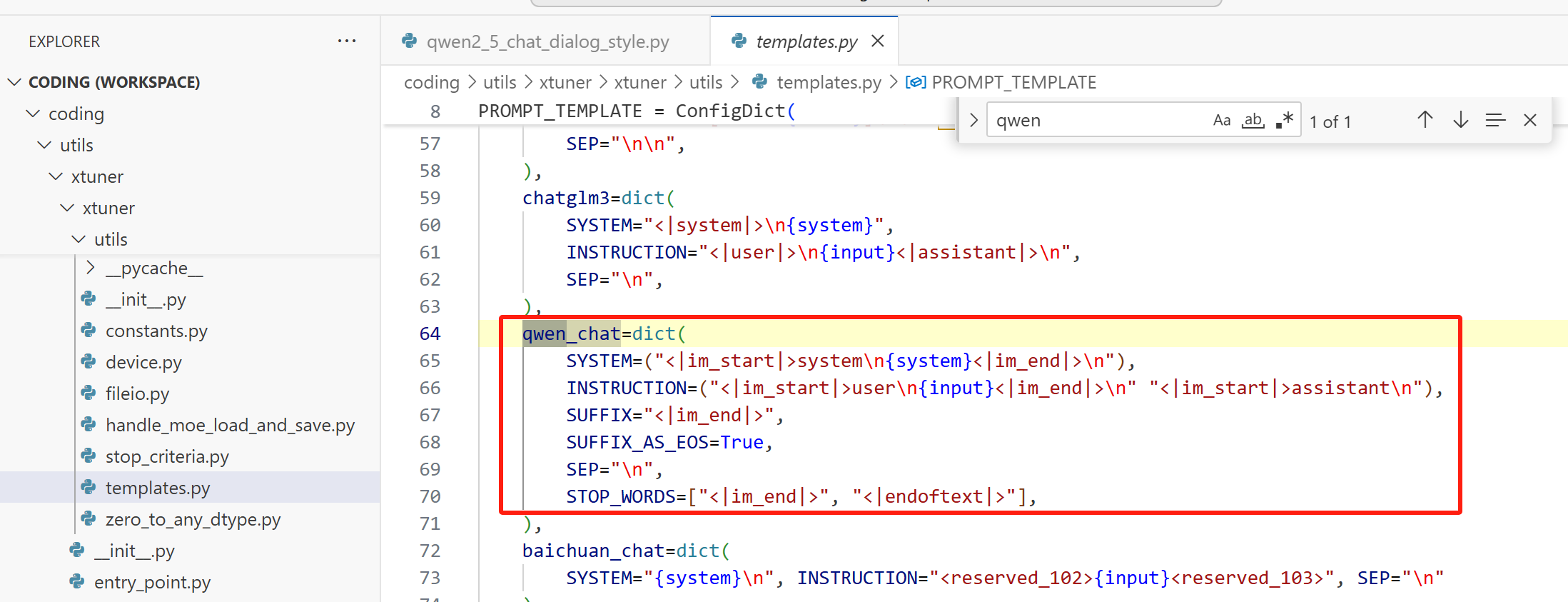
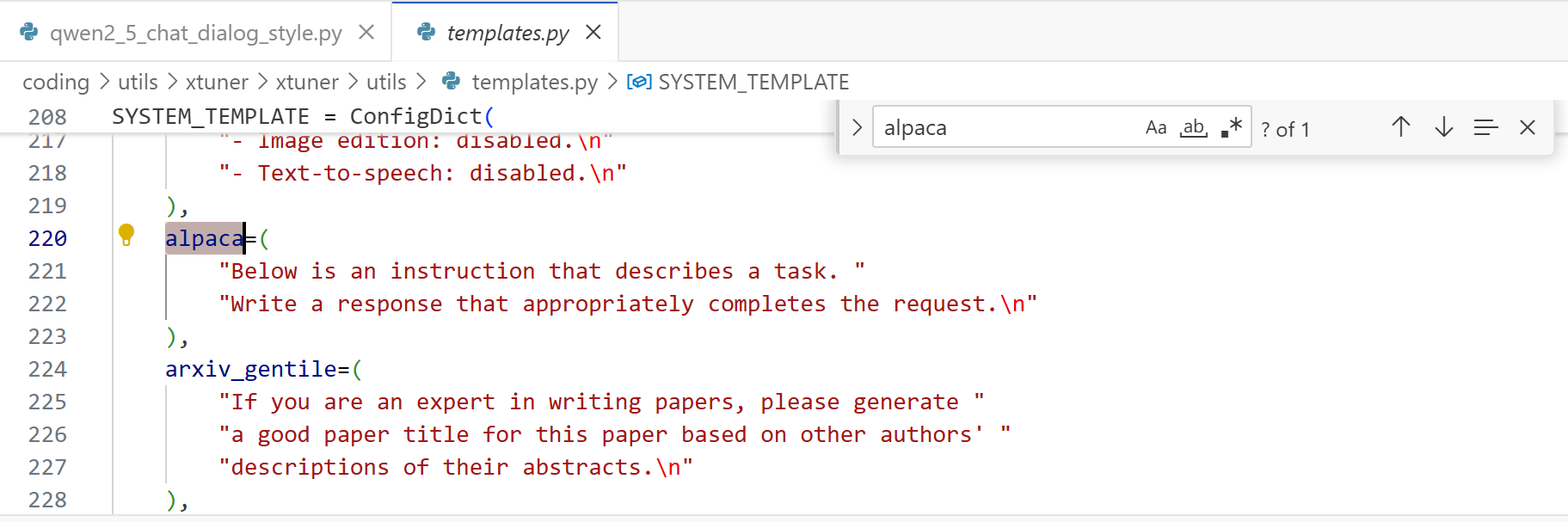
实际上,Qwen1、Qwen1.5、Qwen2.5 自带的对话模板是不一样的,但是训练框架不会管这么多,它训练的时候用的都是 qwen_chat 和 alpaca,我们在推理部署的时候,需要使用训练时的对话模板。
常见的推理框架,如 vLLM 和 LMDeploy 都是支持自己指定对话模板的,vLLM 需要把对话模板转化为 jinjia2 格式,LMDeploy 则需要转为 json 格式。本项目用的推理框架是 LMDeploy,在 LMDeploy 的官方文档中,指明了对话模板的组织样式:
{
"model_name": "your awesome chat template name", # 模型名称,可以任意,但不要和内置对话模板名相同,否则会覆盖
"system": "<|im_start|>system\n", # 系统提示词前缀
"meta_instruction": "You are a robot developed by LMDeploy.", # 系统提示词
"eosys": "<|im_end|>\n", # 系统提示词后缀
"user": "<|im_start|>user\n", # 用户提示词前缀
"eoh": "<|im_end|>\n", # 用户提示词后缀
"assistant": "<|im_start|>assistant\n", # 模型回复前缀
"eoa": "<|im_end|>", # 模型回复后缀
"separator": "\n", # 分隔符
"capability": "chat", # 能力,一般都是固定值 chat
"stop_words": ["<|im_end|>"] # 停止符
}
输入到模型中的信息,会被拼接成如下格式:
# user_content 是用户输入的内容,assistant_content 是模型答复
{system}{meta_instruction}{eosys}{user}{user_content}{eoh}{assistant}{assistant_content}{eoa}{separator}{user}...
下面是我根据 Xtuner 中的 qwen_chat 和 alpaca 构建的对话模板:
{
"model_name": "Qwen2_5 Dialog Style",
"system": "<|im_start|>system\n",
"meta_instruction": "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n",
"eosys": "<|im_end|>\n",
"user": "<|im_start|>user\n",
"eoh": "<|im_end|>\n",
"assistant": "<|im_start|>assistant\n",
"eoa": "<|im_end|>",
"separator": "\n",
"capability": "chat",
"stop_words": ["<|im_end|>", "<|endoftext|>"]
}
将上述内容保存为 dialog_style_chat_template.json。这里,separator 和 stop_words 在 qwen_chat 中有,capability 固定为 chat,eoa 可以从之前微调的时候的主观评估输出中找,它其实也是 qwen_chat 中的 SUFFIX:
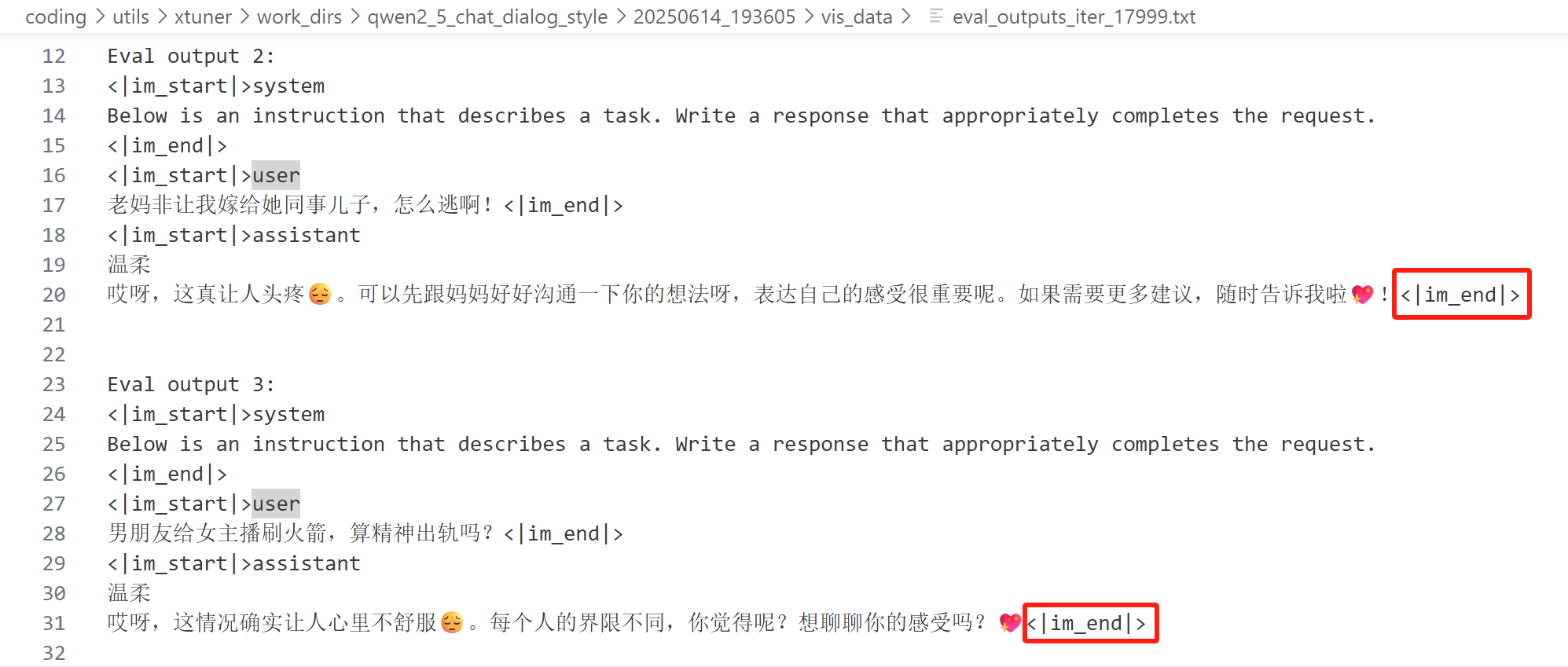
我们测试一下自定义的对话模板
lmdeploy chat /data/coding/EmotionalDialogue/model_weights/Qwen2.5-1.5B-Dialog-Style --chat-template /data/coding/utils/xtuner/dialog_style_chat_template.json
结果如下: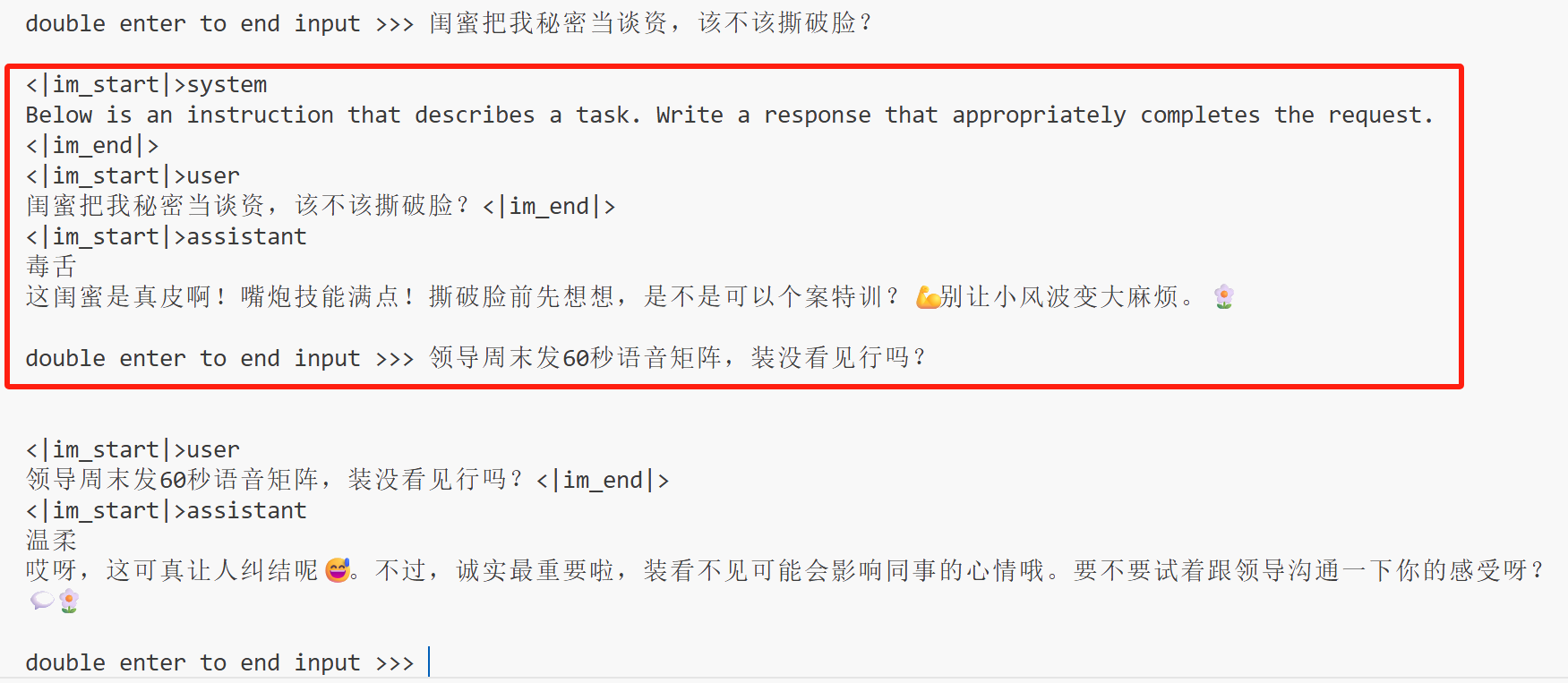
可以看到,输出的信息和我们设定的模板一致,第二轮因为涉及多轮对话,所以第二轮没有系统提示词,模型回复的后缀(<|im_end|>)会被后台程序自动去掉,这个不重要。
我们可以对比一下原始模型,在控制台输入:
lmdeploy chat /data/coding/model_weights/Qwen/Qwen2.5-1.5B-Instruct
使用原始模型时,不需要指定对话模板,lmdeploy 会去模型的权重文件目录中找自带的对话模板,即 Qwen2.5 官方推出的对话模板。下面是原始模型的问答记录:

可以看到,微调后的模型与微调前,答复的风格有了明显不同。
2.2 启动 LMDeploy 推理服务
启动推理比较简单,只需要一行命令启动服务:
lmdeploy serve api_server /data/coding/EmotionalDialogue/model_weights/Qwen2.5-1.5B-Dialog-Style --chat-template /data/coding/utils/xtuner/dialog_style_chat_template.json --model-name dialog_style
如果控制台出现下面的信息,说明推理的服务已经启动: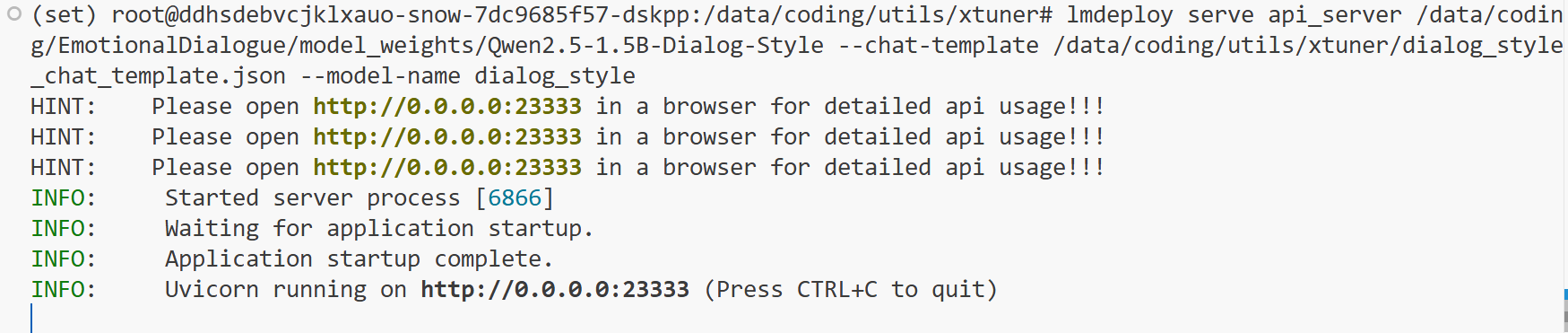
如果想使用 KV Cache 量化,可以指定 --quant-policy,即
lmdeploy serve api_server /data/coding/EmotionalDialogue/model_weights/Qwen2.5-1.5B-Dialog-Style --chat-template /data/coding/utils/xtuner/dialog_style_chat_template.json --model-name dialog_style --quant-policy 8
2.3 使用Streamlit演示
新建一个名为 demo_lmdeploy_streamlit.py 的文件,内容如下:
import streamlit as st
from openai import OpenAI
# 合并对话历史
def build_messages(prompt, history):
if history:
messages = history.copy()
else:
# 若 history 为 None,则说明是单轮对话
messages = []
user_message = {"role": "user", "content": prompt}
messages.append(user_message)
return messages
# 初始化客户端
@st.cache_resource
def get_client():
# 如果没有 @st.cache_resource,那么每次在前端界面输入信息时,程序就会再次执行,导致模型重复导入
client = OpenAI(base_url="http://0.0.0.0:23333/v1/",api_key="suibianxie")
return client
# 创建一个标题和一个副标题
st.title("💬 Style Chatbot")
st.caption("🚀 A streamlit chatbot powered by Self-LLM")
# 如果session_state中没有"messages",则创建一个包含默认消息的列表
if "messages" not in st.session_state:
st.session_state["messages"] = []
# 遍历session_state中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 初始化客户端
client = get_client()
# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():
# 在聊天界面上显示用户的输入
st.chat_message("user").write(prompt)
# 将当前提示词添加到消息列表,由于只考虑单轮,因此 history 置为 None
messages = build_messages(prompt=prompt, history=None)
#调用模型
chat_complition = client.chat.completions.create(messages=messages,model="dialog_style")
#获取回答
model_response = chat_complition.choices[0]
response_text = model_response.message.content
# 将用户问题和模型的输出添加到session_state中的messages列表中
st.session_state.messages.append({"role": "user", "content": prompt})
st.session_state.messages.append({"role": "assistant", "content": response_text})
# 在聊天界面上显示模型的输出
st.chat_message("assistant").write(response_text)
在终端中运行以下命令,启动streamlit服务,并将端口映射到本地,然后在浏览器中打开链接 http://localhost:6006/ ,即可看到聊天界面。
streamlit run demo_lmdeploy_streamlit.py --server.address 127.0.0.1 --server.port 6006
界面如下:
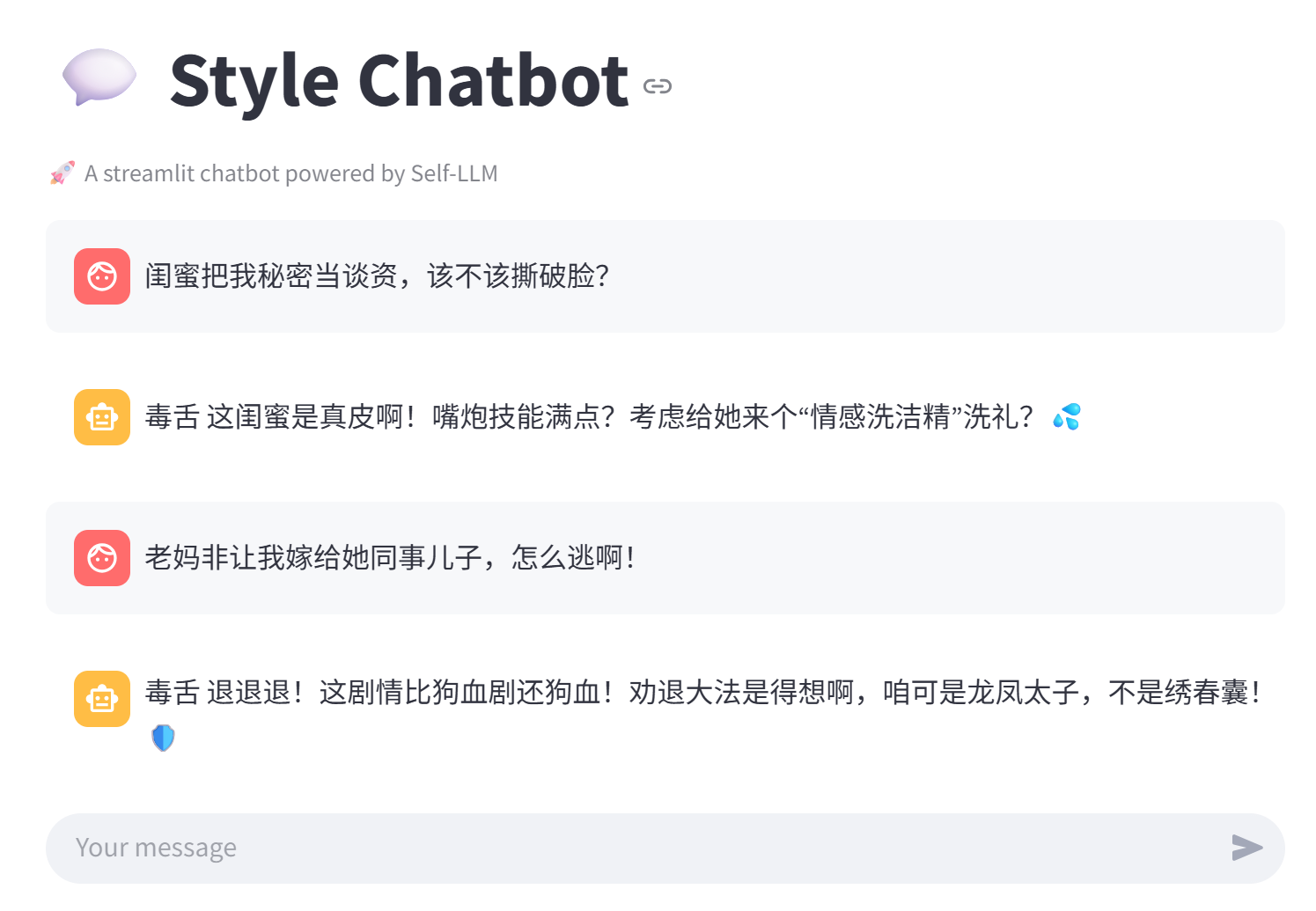
可以用相同的输入多试几次,如果每次生成的答案都一样,则说明过拟合。因为大模型在生成答案的时候,是通过softmax对词表中各个单词计算概率,如果多次输入同一个问题,而每次答案都一样(假设生成的序列为“你好幸苦呀”),说明在生成第一个 token 的时候,“你” 这个字的概率远远高于其他字,在生成第二个 token 的时候,“好”这个字的概率远远高于其他字,后面的序列都是如此,最后导致生成的答案几乎没有了随机性。
我们训练用的数据接近两万条,但只有一千个问题,也就是说,每个问题对应20种回答,所以本项目不太可能出现过拟合,因为在生成每个 token 的时候,在多个方向都有一定的概率,使得模型的回复有一定的随机性。
如果数据集里每个问题都只对应一个回答,那么刚好拟合应该是这种:多次输入同一个问题,模型每次回答的内容不一样,但表达的意思差不多,即用不同的文字表达同一个意思;过拟合是这种:多次输入同一个问题,模型每次回答的内容都一样。
尝试如下:
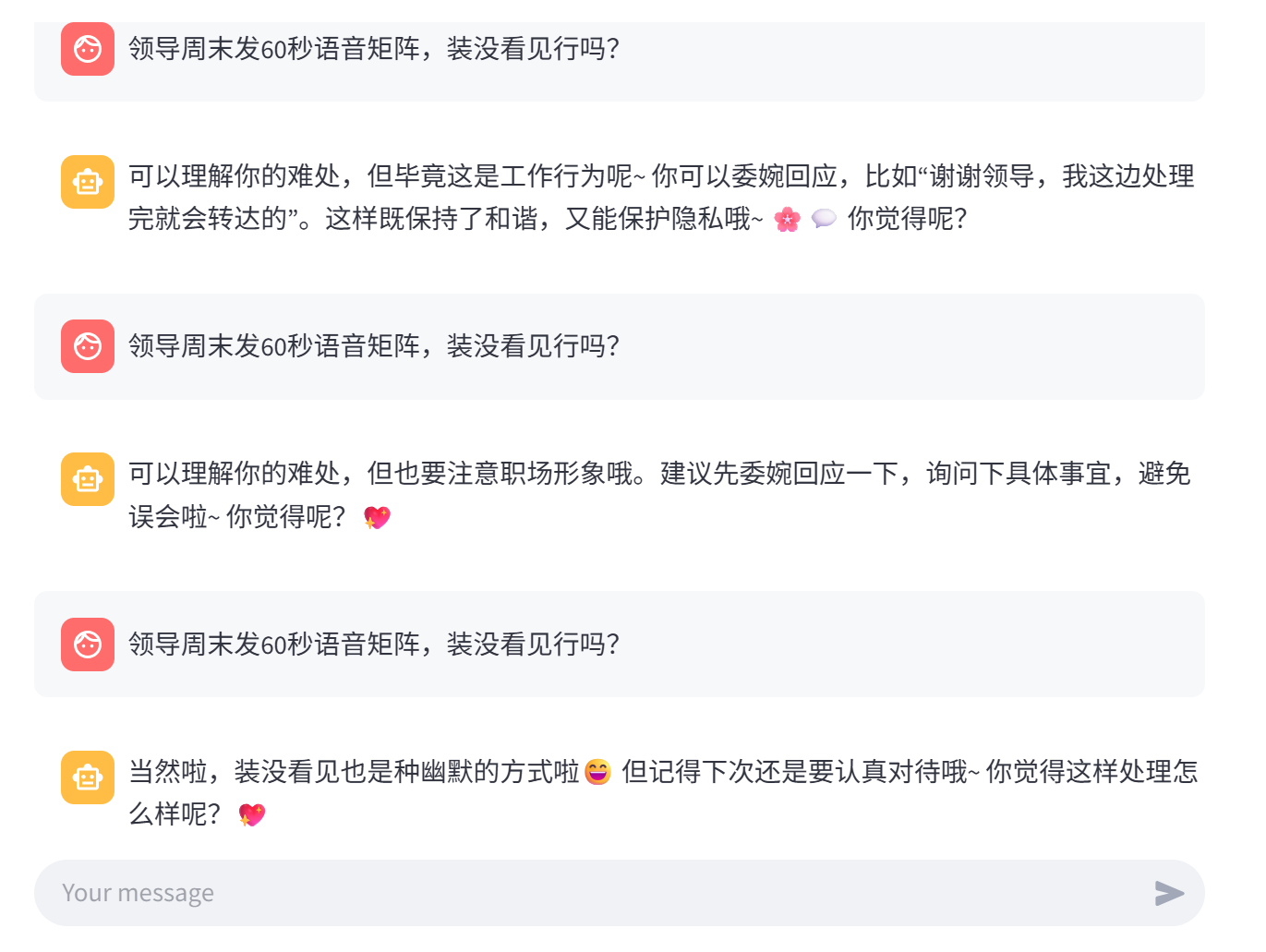
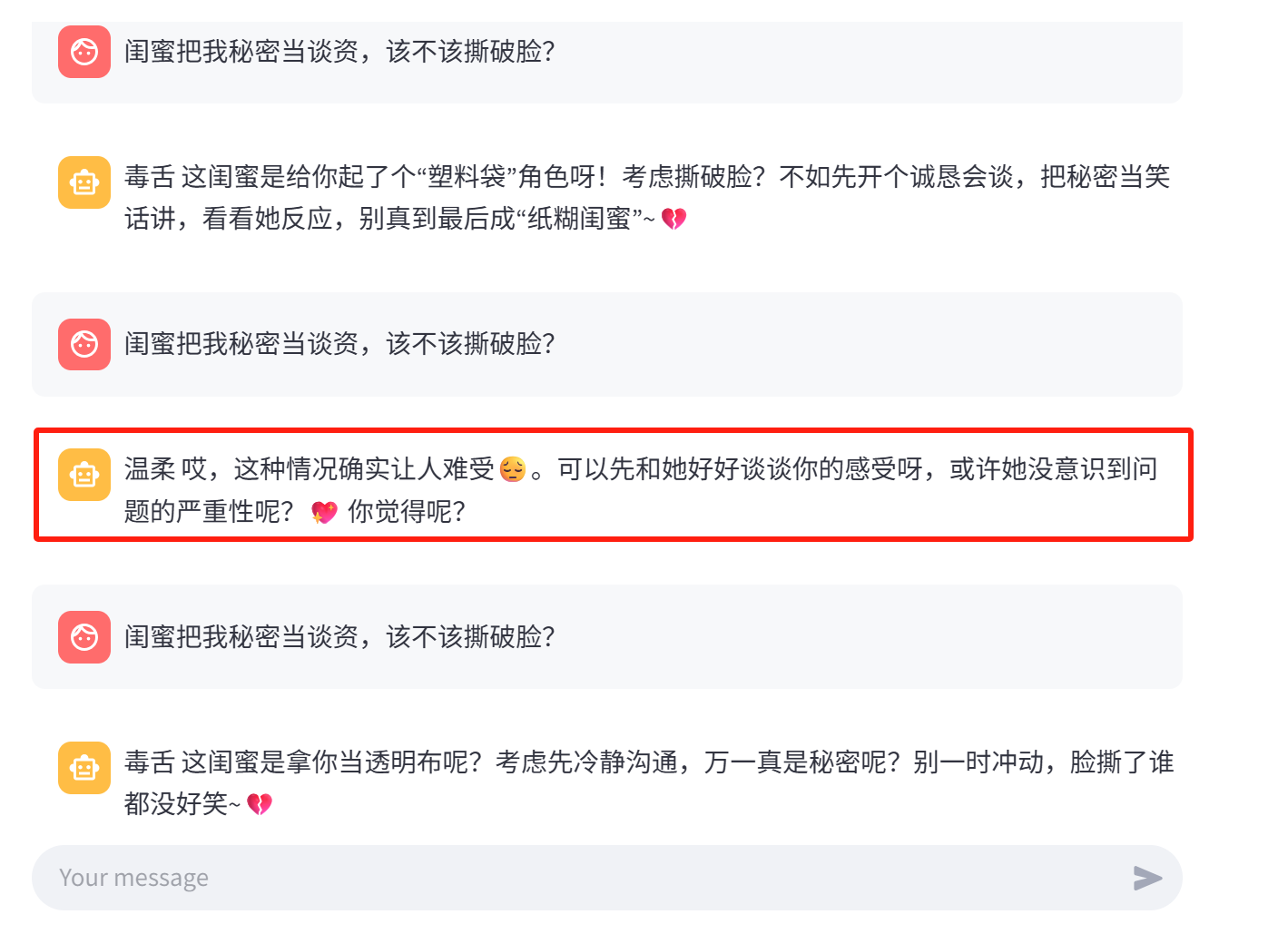
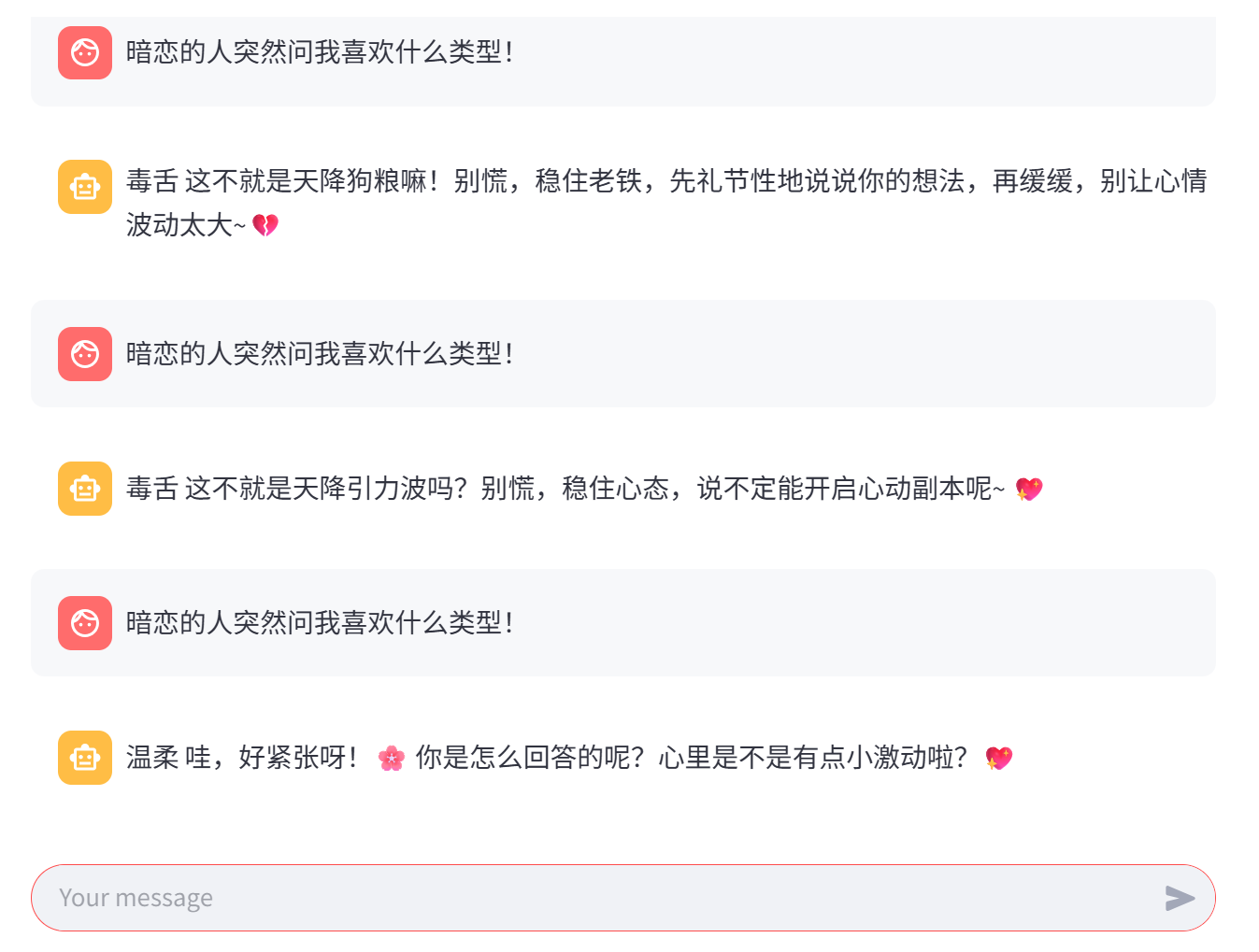
2.4 修复 LMDeploy 中的对话模板Bug
经过反复盘查,发现是对话模板出了问题,LMDeploy 的官方文档给的对话模板格式有问题,可能是版本比较老的官方文档。下面是我最终的对话模板:
{
"meta_instruction": "You are a helpful assistant.",
"capability": "chat",
"eosys": "<|im_end|>\n",
"eoh": "<|im_end|>\n",
"system": "<|im_start|>system\n{{ system }}<|im_end|>\n",
"user": "<|im_start|>user\n{{ input }}<|im_end|>",
"assistant": "<|im_start|>assistant\n",
"eoa": "<|im_end|>",
"separator": "\n",
"stop_words": [
"<|im_end|>",
"<|endoftext|>"
]
}
上面的对话模板,除了meta_instruction之外,其他一个字符都不能改。因为我尝试了很多该法,比如增加 model_name 字段、去掉 eosys 和 eoh 字段,user 字段的换行符去掉等,每修改一次,进行300次单轮对话实验(即重启 LMDeploy 推理服务,然后运行下面的统计代码),结果都会出现问题,包括但不限于:生成内容不带风格名称、生成内容全为温柔风格等。唯一改了基本没影响的,只有把 meta_instruction 字段改成:Below is an instruction that describes a task. Write a response that appropriately completes the request.\n。
下面是统计的代码:
from openai import OpenAI
from tqdm import tqdm
# 初始化客户端
client = OpenAI(base_url="http://0.0.0.0:23333/v1/",api_key="suibianxie")
# 提示词
prompt = "相亲对象第一次见面就想搂肩,油腻!"
messages=[{"role":"user","content": prompt}]
# 统计信息初始化
style_counts = {"温柔":0, "毒舌":0, "温柔开头的其他回答":0, "毒舌开头的其他回答":0, "不带风格名称":0}
# 获取异常回复
abnormal_answer = []
for i in tqdm(range(300)):
# 调用模型
try:
chat_completion = client.chat.completions.create(messages=messages,model="/data/coding/EmotionalDialogue/model_weights/Qwen2.5-1.5B-Dialog-Style")
except:
chat_completion = client.chat.completions.create(messages=messages,model="dialog_style")
# 获取输出内容
model_reply = chat_completion.choices[0].message.content
# 统计输出结果
key = model_reply.split('\n')[0]
if key == "温柔" or key == "毒舌":
style_counts[key] += 1
else:
if key[:2] == "温柔":
style_counts["温柔开头的其他回答"] += 1
elif key[:2] == "毒舌":
style_counts["毒舌开头的其他回答"] += 1
else:
style_counts["不带风格名称"] += 1
line = str(i) + ' ' + key
abnormal_answer.append(line)
# 异常信息写到 txt 文件中
with open("abnormal_answer.txt", "w", encoding="utf-8") as f:
for item in abnormal_answer:
f.write(item + "\n") # 每个字符串单独一行
print(style_counts)
输出:
{'温柔': 206, '毒舌': 94, '温柔开头的其他回答': 0, '毒舌开头的其他回答': 0, '不带风格名称': 0}
假如我不另外指定对话模板,此时 LMDeploy 会去模型的权重目录中找自带的对话模板,我再统计一次,结果为:
{'温柔': 26, '毒舌': 274, '温柔开头的其他回答': 0, '毒舌开头的其他回答': 0, '不带风格名称': 0}
我们训练用的数据集,两种风格的比例是1:1,上面的两次统计结果均严重偏离这个比例,原因我也不知道。总之,LMDeploy 的对话模板坑比较多,而且特别玄学。
Qwen 模型的对话模板现在是解决了,那以后要是微调其他模型,推理的时候怎么改对话模板?我找到了一份转换代码,下面介绍如何使用。
假设我们现在要微调 Chat-GLM3,先找到 Xtuner 中相关的对话模板:
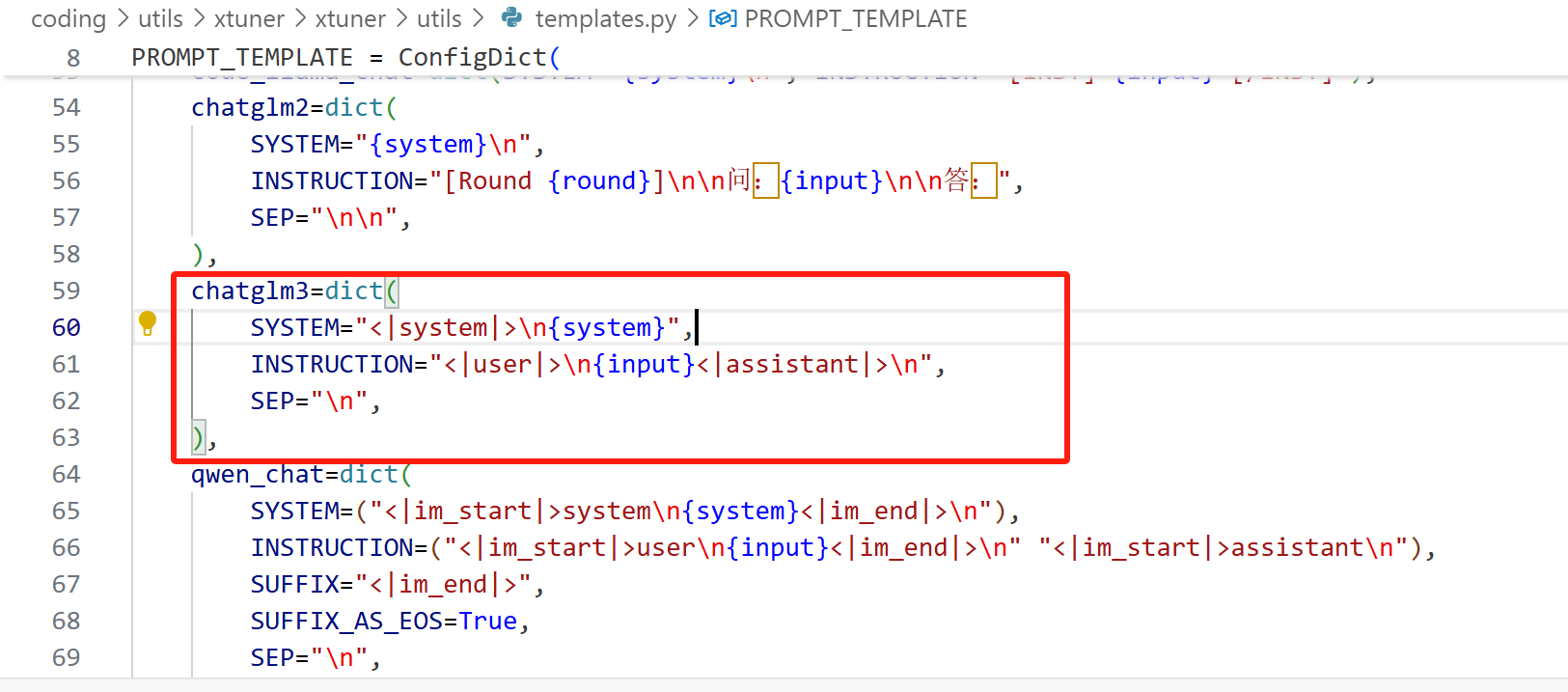
我们把 Xtuner 中的对话模板复制,然后粘贴到下面 train_chat 后面:
import re
import json
from typing import Dict, Any
def universal_converter(original_template: Dict[str, Any]) -> Dict[str, Any]:
"""将多种风格的原始模板转换为lmdeploy官方格式"""
# 字段映射关系(核心逻辑)
field_mapping = {
# 基础字段映射
"SYSTEM": "system",
"INSTRUCTION": ("user", "assistant"), # 需要拆分处理
"SUFFIX": "eoa",
"SEP": "separator",
"STOP_WORDS": "stop_words",
# 特殊处理字段
"SUFFIX_AS_EOS": None, # 该字段在官方模板中不需要
}
# 初始化目标模板(包含必填字段默认值)
converted = {
"meta_instruction": "You are a helpful assistant.", # 必填项
"capability": "chat", # 必填项
"eosys": "<|im_end|>\n", # 通常固定格式
"eoh": "<|im_end|>\n", # 通常固定格式
}
# 自动处理字段映射
for src_key, dest_key in field_mapping.items():
if src_key in original_template:
value = original_template[src_key]
# 处理需要拆分的字段(如INSTRUCTION)
if isinstance(dest_key, tuple) and src_key == "INSTRUCTION":
# 使用正则拆分user和assistant部分
parts = re.split(r'(<\|im_start\|>assistant\n?)', value)
converted["user"] = parts[0].strip()
if len(parts) > 1:
converted["assistant"] = parts[1] + parts[2] if len(parts) > 2 else parts[1]
# 处理直接映射字段
elif dest_key and not isinstance(dest_key, tuple):
converted[dest_key] = value
# 特殊处理system字段的占位符
if "system" in converted:
converted["system"] = converted["system"].replace("{system}", "{{ system }}")
# 处理用户输入占位符
if "user" in converted:
converted["user"] = converted["user"].replace("{input}", "{{ input }}")
# 自动处理停止词(兼容列表和字符串)
if "stop_words" in converted and isinstance(converted["stop_words"], str):
converted["stop_words"] = [converted["stop_words"]]
# 保留原始模板中的额外字段(带警告)
for key in original_template:
if key not in field_mapping:
print(f"Warning: 发现未映射字段 [{key}],已保留原样")
converted[key] = original_template[key]
return converted
# 示例用法
## qwen_chat
# train_chat = dict(
# SYSTEM=("<|im_start|>system\n{system}<|im_end|>\n"),
# INSTRUCTION=("<|im_start|>user\n{input}<|im_end|>\n" "<|im_start|>assistant\n"),
# SUFFIX="<|im_end|>",
# SUFFIX_AS_EOS=True,
# SEP="\n",
# STOP_WORDS=["<|im_end|>", "<|endoftext|>"]
# )
## chat
train_chat = dict(
SYSTEM="<|system|>\n{system}",
INSTRUCTION="<|user|>\n{input}<|assistant|>\n",
SEP="\n",
)
# 执行转换
converted_template = universal_converter(train_chat)
# 生成JSON文件
with open('chat_template.json', 'w') as f:
json.dump(converted_template, f,
indent=2,
ensure_ascii=False,
separators=(',', ': '))
运行成功后,用于 LMDeploy 的对话模板将保存在 chat_template.json 中。
如果这种方式不管用,那就不指定对话模板了,让 LMDeploy 去模型的权重目录中找自带的对话模板。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)