langchain从入门到精通(十二)——不同记忆组件介绍
缓冲记忆组件是 LangChain 中最简单的记忆组件,绝大部分都不对数据结构和提取算法做任何处理,就是简单的原进原出,也是使用频率最高的记忆组件,在 LangChain 中封装了几种内置的缓冲记忆组件,涵盖:① ConversationBufferMemory:缓冲记忆,最简单,最数据结构和提取算法不做任何处理,将所有对话信息全部存储作为记忆。② ConversationBufferWindow
1. 缓冲记忆组件的类型
1.1 缓冲记忆组件介绍
缓冲记忆组件是 LangChain 中最简单的记忆组件,绝大部分都不对数据结构和提取算法做任何处理,就是简单的原进原出,也是使用频率最高的记忆组件,在 LangChain 中封装了几种内置的缓冲记忆组件,涵盖:
① ConversationBufferMemory:缓冲记忆,最简单,最数据结构和提取算法不做任何处理,将所有对话信息全部存储作为记忆。
② ConversationBufferWindowMemory:缓冲窗口记忆,通过设定 k 值,只保留一定数量(2*k)的对话信息作为历史。
1.2 缓冲窗口记忆示例
使用 LangChain 实现一个案例,让 LLM 应用拥有 2 轮的对话记忆,超过 2 轮的记忆全部遗忘。代码
from operator import itemgetter
import dotenv
from langchain.memory import ConversationBufferWindowMemory
from langchain_community.chat_message_histories import FileChatMessageHistory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
memory = ConversationBufferWindowMemory(
input_key="query",
return_messages=True,
k=2,
)
prompt = ChatPromptTemplate.from_messages([
("system", "你是OpenAI开发的聊天机器人,请帮助用户解决问题"),
MessagesPlaceholder("history"),
("human", "{query}")
])
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
chain = RunnablePassthrough.assign(
history=RunnableLambda(memory.load_memory_variables) | itemgetter("history")
) | prompt | llm | StrOutputParser()
while True:
query = input("Human: ")
if query == "q":
exit(0)
chain_input = {"query": query}
print("AI: ", flush=True, end="")
response = chain.stream(chain_input)
output = ""
for chunk in response:
output += chunk
print(chunk, flush=True, end="")
print("\nhistory:", memory.load_memory_variables({}))
memory.save_context(chain_input, {"output": output})
2. 摘要记忆组件的类型
2.1 摘要记忆组件的类型
在 LangChain 中使用缓冲记忆组件要不就保存所有信息(占用过多容量),要不就保留最近的记忆信息(丢失太多重要信息),那么有没有一种情况是既要又要呢?
所以折中方案就出现了——保留关键信息(重点记忆),移除冗余噪音(流水式信息)。
在 LangChain 中 摘要记忆组件 就是一种折中的方案,内置封装的 摘要记忆组件 有以下几种。
① ConversationSummaryMemory,摘要总结记忆组件,将传递的历史对话记录总结成摘要进行保存(底层使用 LLM 大语言模型进行总结),使用时填充的记忆为 摘要,并非对话数据。这种策略融合了记忆质量和容量的考量,只保留最核心的语义信息,有效减少了冗余,同时质量更高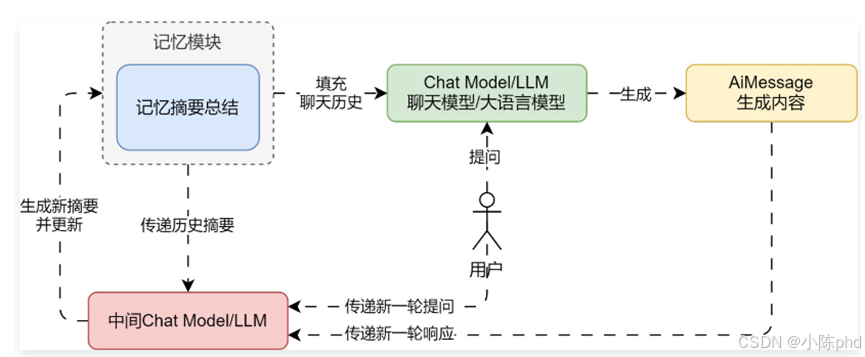
② ConversationSummaryBufferMemory,摘要缓冲混合记忆,在不超过 max_token_limit 的限制下,保存对话历史数据,对于超过的部分,进行信息的提取与总结(底层使用 LLM 大语言模型进行总结),兼顾了精确的短期记忆与模糊的长期记忆。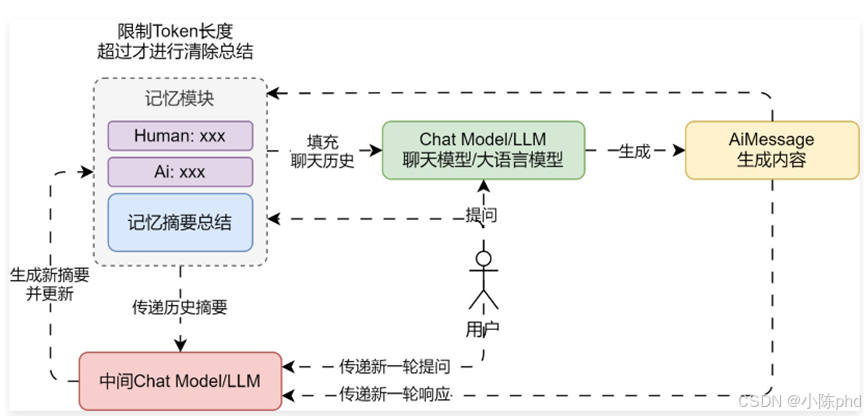
2.2 摘要缓冲混合记忆示例与注意事项
2.2.1 摘要缓冲混合记忆示例:
使用 LangChain 实现一个案例,让 LLM 应用拥有多轮对话记忆,并将历史记忆 max_token_limit 限制为 300,超过的部分进行总结产生总结记忆。代码
from operator import itemgetter
import dotenv
from langchain.memory import ConversationSummaryBufferMemory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
# 1.创建提示模板&记忆
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个强大的聊天机器人,请根据对应的上下文回复用户问题"),
MessagesPlaceholder("history"), # 需要的history其实是一个列表
("human", "{query}"),
])
memory = ConversationSummaryBufferMemory(
return_messages=True,
input_key="query",
llm=ChatOpenAI(model="gpt-3.5-turbo-16k"),
max_token_limit=300,
)
# 2.创建大语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
# 3.构建链应用
chain = RunnablePassthrough.assign(
history=RunnableLambda(memory.load_memory_variables) | itemgetter("history")
) | prompt | llm | StrOutputParser()
# 4.死循环构建对话命令行
while True:
query = input("Human: ")
if query == "q":
exit(0)
chain_input = {"query": query, "language": "中文"}
response = chain.stream(chain_input)
print("AI: ", flush=True, end="")
output = ""
for chunk in response:
output += chunk
print(chunk, flush=True, end="")
memory.save_context(chain_input, {"output": output})
print("")
print("history: ", memory.load_memory_variables({}))
2.2.2 使用注意事项
ConversationSummaryBufferMemory 会将汇总摘要的部分默认设置为 system 角色,创建系统角色信息,而其他消息则正常显示,传递的消息列表就变成:[system, system, human, ai, human, ai, human]。
但是部分聊天模型是不支持传递多个角色为 System 的消息,并且在 langchain_community 中集成的模型并没有对多个 System 进行集中合并封装(Chat Model 未更新同步),如果直接使用可能会出现报错。
而且绝大部分聊天模型在传递历史信息时,传递的信息必须是信息组,也就是 1 条 Human 消息 + 1 条 AI 消息这种格式,例如百度的文心大模型,链接:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/clntwmv7t。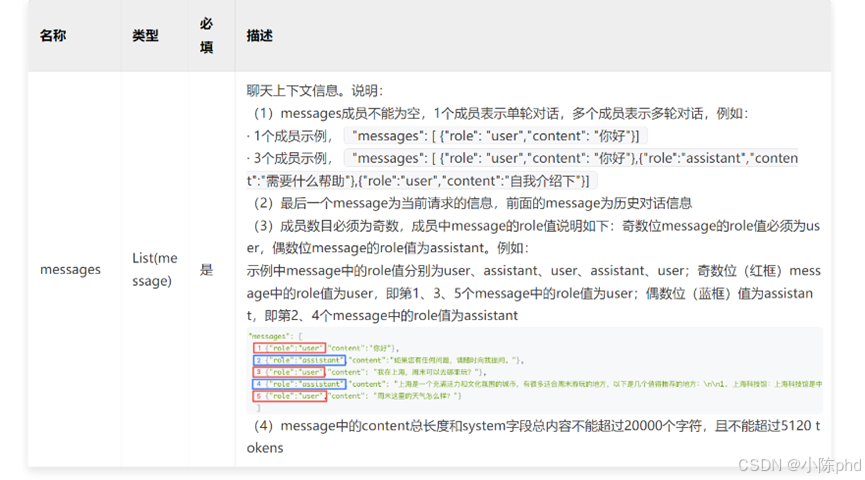
所以在使用 ConversationSummaryMemory 这种类型的记忆组件时,需要检查对应的模型传递的 messages 的规则,以及 LangChain 是否对特定的模型封装进行了更新。
除此之外,在某些极端的场合下,例如第一条提问回复内容比较短,第二条提问内容比较长,ConversationSummaryMemory 执行两次 Token 长度计算,如果不异步执行任务,对话速度会变得非常慢。
摘要更新 逻辑代码
# langchain/memory/summary_buffer.py
def prune(self) -> None:
"""Prune buffer if it exceeds max token limit"""
buffer = self.chat_memory.messages
curr_buffer_length = self.llm.get_num_tokens_from_messages(buffer)
if curr_buffer_length > self.max_token_limit:
pruned_memory = []
while curr_buffer_length > self.max_token_limit:
pruned_memory.append(buffer.pop(0))
curr_buffer_length = self.llm.get_num_tokens_from_messages(buffer)
self.moving_summary_buffer = self.predict_new_summary(
pruned_memory, self.moving_summary_buffer
)
3. 实体记忆组件介绍
3.1 介绍
实体记忆指的是跟踪对话中提到的实体,并且在对话中记住关于特定实体的既定事实,它提取关于实体的信息(使用LLM),并随着时间的推移建立对该实体的知识(使用LLM),一般使用实体记忆来存储和查询对话中引用的各种信息,比如人物、地点、事件等。
在 LangChain 内部封装了一个实体记忆类 ConversationEntityMemory,这个类可以从对话历史中提取实体并生成描述(简单来讲,就是提取关键词+对应的描述),不过 ConversationEntityMemory 预设的 Prompt 过于笨重,而且极度消耗 Token,并且对大模型的要求极高,所以实用度并不高。
例如有以下 3 段对话信息
Human: 你好,我是慕小课。我最近正在学习LangChain。
AI: 你好,慕小课!很高兴认识你。LangChain 是一个非常有趣的项目,它专注于构建和连接语言模型。你最近在学习 LangChain 的过程中有没有遇到什么问题或难点呢?或者有没有什么特别感兴趣的功能或主题?我很乐意帮忙解释或提供相关信息!
Human: 我最喜欢的编程语言是 Python。
AI: Python 是一门非常受欢迎且功能强大的编程语言,特别适合数据科学、人工智能、Web 开发等领域。它的语法简洁明了,非常适合初学者,同时也有丰富的库和框架支持高级开发。\n\n既然你喜欢 Python,并且正在学习 LangChain,你可能会发现 Python 在处理自然语言处理(NLP)任务时非常有用。LangChain 结合了语言模型和链式处理的概念,可以帮助你更好地构建复杂的 NLP 应用。\n\n你对 Python 的哪些方面最感兴趣?是数据处理、机器学习、Web 开发,还是其他领域?或者你在学习 LangChain 时有没有遇到具体的问题?我可以根据你的兴趣和需求提供更详细的帮助。
Human: 我住在广州
AI: 广州是一个非常美丽和繁华的城市,拥有丰富的历史和文化。作为中国的第三大城市,广州不仅是一个重要的经济中心,也是一个充满活力的科技和创新之地。\n\n既然你住在广州,你可能会对一些本地的科技社区和活动感兴趣。广州有许多科技公司和初创企业,定期举办各种技术交流会和黑客马拉松。如果你对 Python 和 LangChain 感兴趣,参加这些活动可能会对你有很大帮助。\n\n另外,广州的美食也是非常有名的,不知道你有没有特别喜欢的广州菜呢?如果你有任何关于广州生活或学习编程的问题,随时告诉我,我很乐意帮忙!
提取出来的实体信息:
{
‘慕小课’: ‘慕小课最近正在学习LangChain。’,
‘LangChain’: ‘LangChain 是一个专注于构建和连接语言模型的项目。’,
‘Python’: ‘Python 是一门非常受欢迎且功能强大的编程语言,特别适合数据科学、人工智能、Web 开发等领域。’,
‘广州’: ‘广州是中国的第三大城市,不仅是一个重要的经济中心,也是一个充满活力的科技和创新之地,拥有丰富的历史和文化。’
}
3.2 实体记忆组件示例
import dotenv
from langchain.chains.conversation.base import ConversationChain
from langchain.memory import ConversationEntityMemory
from langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
llm = ChatOpenAI(model="gpt-4o", temperature=0)
chain = ConversationChain(
llm=llm,
prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE,
memory=ConversationEntityMemory(llm=llm),
)
print(chain.invoke({"input": "你好,我是慕小课。我最近正在学习LangChain。"}))
print(chain.invoke({"input": "我最喜欢的编程语言是 Python。"}))
print(chain.invoke({"input": "我住在广州"}))
# 查询实体中的对话
res = chain.memory.entity_store.store
print(res)
输出:
{'input': '你好,我是慕小课。我最近正在学习LangChain。', 'history': '', 'entities': {'慕小课': '', 'LangChain': ''}, 'response': '你好,慕小课!很高兴认识你。LangChain 是一个非常有趣的项目,它专注于构建和连接语言模型。你最近在学习 LangChain 的过程中有没有遇到什么问题或难点呢?或者有没有什么特别感兴趣的功能或主题?我很乐意帮忙解释或提供相关信息!'}
{'input': '我最喜欢的编程语言是 Python。', 'history': 'Human: 你好,我是慕小课。我最近正在学习LangChain。\nAI: 你好,慕小课!很高兴认识你。LangChain 是一个非常有趣的项目,它专注于构建和连接语言模型。你最近在学习 LangChain 的过程中有没有遇到什么问题或难点呢?或者有没有什么特别感兴趣的功能或主题?我很乐意帮忙解释或提供相关信息!', 'entities': {'Python': ''}, 'response': 'Python 是一门非常受欢迎且功能强大的编程语言,特别适合数据科学、人工智能、Web 开发等领域。它的语法简洁明了,非常适合初学者,同时也有丰富的库和框架支持高级开发。\n\n既然你喜欢 Python,并且正在学习 LangChain,你可能会发现 Python 在处理自然语言处理(NLP)任务时非常有用。LangChain 结合了语言模型和链式处理的概念,可以帮助你更好地构建复杂的 NLP 应用。\n\n你对 Python 的哪些方面最感兴趣?是数据处理、机器学习、Web 开发,还是其他领域?或者你在学习 LangChain 时有没有遇到具体的问题?我可以根据你的兴趣和需求提供更详细的帮助。'}
{'input': '我住在广州', 'history': 'Human: 你好,我是慕小课。我最近正在学习LangChain。\nAI: 你好,慕小课!很高兴认识你。LangChain 是一个非常有趣的项目,它专注于构建和连接语言模型。你最近在学习 LangChain 的过程中有没有遇到什么问题或难点呢?或者有没有什么特别感兴趣的功能或主题?我很乐意帮忙解释或提供相关信息!\nHuman: 我最喜欢的编程语言是 Python。\nAI: Python 是一门非常受欢迎且功能强大的编程语言,特别适合数据科学、人工智能、Web 开发等领域。它的语法简洁明了,非常适合初学者,同时也有丰富的库和框架支持高级开发。\n\n既然你喜欢 Python,并且正在学习 LangChain,你可能会发现 Python 在处理自然语言处理(NLP)任务时非常有用。LangChain 结合了语言模型和链式处理的概念,可以帮助你更好地构建复杂的 NLP 应用。\n\n你对 Python 的哪些方面最感兴趣?是数据处理、机器学习、Web 开发,还是其他领域?或者你在学习 LangChain 时有没有遇到具体的问题?我可以根据你的兴趣和需求提供更详细的帮助。', 'entities': {'广州': ''}, 'response': '广州是一个非常美丽和繁华的城市,拥有丰富的历史和文化。作为中国的第三大城市,广州不仅是一个重要的经济中心,也是一个充满活力的科技和创新之地。\n\n既然你住在广州,你可能会对一些本地的科技社区和活动感兴趣。广州有许多科技公司和初创企业,定期举办各种技术交流会和黑客马拉松。如果你对 Python 和 LangChain 感兴趣,参加这些活动可能会对你有很大帮助。\n\n另外,广州的美食也是非常有名的,不知道你有没有特别喜欢的广州菜呢?如果你有任何关于广州生活或学习编程的问题,随时告诉我,我很乐意帮忙!'}
{'慕小课': '慕小课最近正在学习LangChain。', 'LangChain': 'LangChain 是一个专注于构建和连接语言模型的项目。', 'Python': 'Python 是一门非常受欢迎且功能强大的编程语言,特别适合数据科学、人工智能、Web 开发等领域。', '广州': '广州是中国的第三大城市,不仅是一个重要的经济中心,也是一个充满活力的科技和创新之地,拥有丰富的历史和文化。'}
4. 记忆组件的持久化
4.1 介绍
在 LangChain 中记忆组件本身没有持久化功能,但是可以通过 chat_memory 来将对话信息历史持久化,通过额外的数据库来存储汇总信息、摘要等技巧,从而实现记忆的持久化。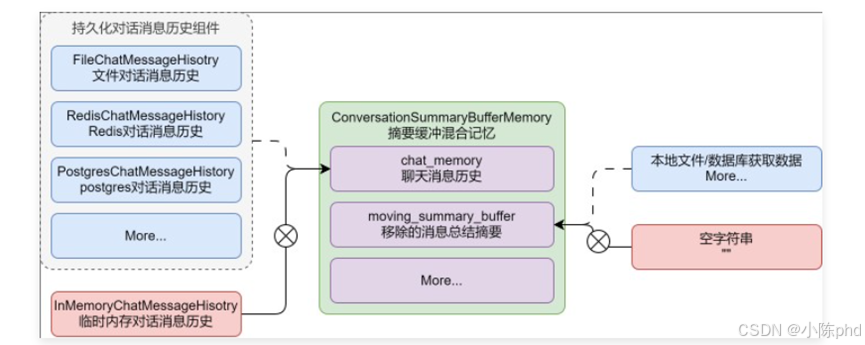
以 ConversationSummaryBufferMemory 为例,如果想要持久化,可以使用带有持久化功能的 chat_memory,并且利用外部的文件或者数据库管理 moving_summary_buffer 字段数据,从而实现整个记忆组件的持久化。
在 LangChain 中,集成接入的第三方对话消息历史有近 50+ 个,涵盖了:Postgres、Redis、Kafka、MongoDB、SQLite 等,并且 ChatMessageHistory 可以完美接入到 Runnable 可运行协议的链条。
LangChain 第三方记忆组件官网:https://python.langchain.com/v0.2/docs/integrations/memory/
4.2 实现有记忆功能的聊天机器人API
在 Flask 中,每一个请求结束后,所执行的线程/协程会被释放,所以没法像命令行聊天机器人一样,将记忆内容存储到临时内存中,所以需要一种中介来存储相应的对话历史,这个中介可以是文件,也可以是数据库,甚至是另外的程序。
为了降低学习难度,我们先将基础的聊天机器人通过本地文件的方式来存储最近 3 轮对话信息,实现 3 轮内记忆,下一阶段掌握 RAG、工具回调后,再将聊天机器人的数据统一使用 Postgres 进行管理(涵盖配置、聊天历史、对话信息等)。
更新后的聊天机器人的运行流程图如下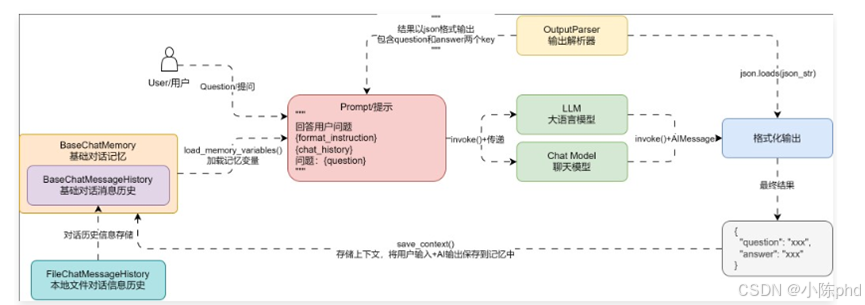
def debug(self, app_id: UUID):
# 1.提取从接口中获取的输入
req = CompletionReq()
if not req.validate():
return validate_error_json(req.errors)
# 2.创建prompt与memory
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个强大的聊天机器人,能根据用户的提问回复对应的问题"),
MessagesPlaceholder("history"),
("human", "{query}"),
])
memory = ConversationBufferWindowMemory(
k=3,
input_key="query",
output_key="output",
return_messages=True,
chat_memory=FileChatMessageHistory("./storage/memory/chat_history.txt"),
)
# 3.构建llm应用
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
# 4.创建链应用
chain = RunnablePassthrough.assign(
history=RunnableLambda(memory.load_memory_variables) | itemgetter("history")
) | prompt | llm | StrOutputParser()
# 5.调用链生成内容
chain_input = {"query": req.query.data}
content = chain.invoke(chain_input)
# 6.存储链状态
memory.save_context(chain_input, {"output": content})
return success_json({"content": content})

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)