首次全面复盘AI Agents记忆系统:3大类,6种操作!零基础小白看到就是赚到,建议收藏!!
记忆是AI系统的基本组成部分,尤其是对于基于LLMs的Agents。首次将记忆表示分为三类:参数化记忆、上下文结构化记忆和上下文非结构化记忆,并介绍了六种基本的记忆操作:巩固、更新、索引、遗忘、检索和压缩。盘点了几十种记忆框架、产品、应用!
前言
记忆是AI系统的基本组成部分,尤其是对于基于LLMs的Agents。首次将记忆表示分为三类:参数化记忆、上下文结构化记忆和上下文非结构化记忆,并介绍了六种基本的记忆操作:巩固、更新、索引、遗忘、检索和压缩。盘点了几十种记忆框架、产品、应用!
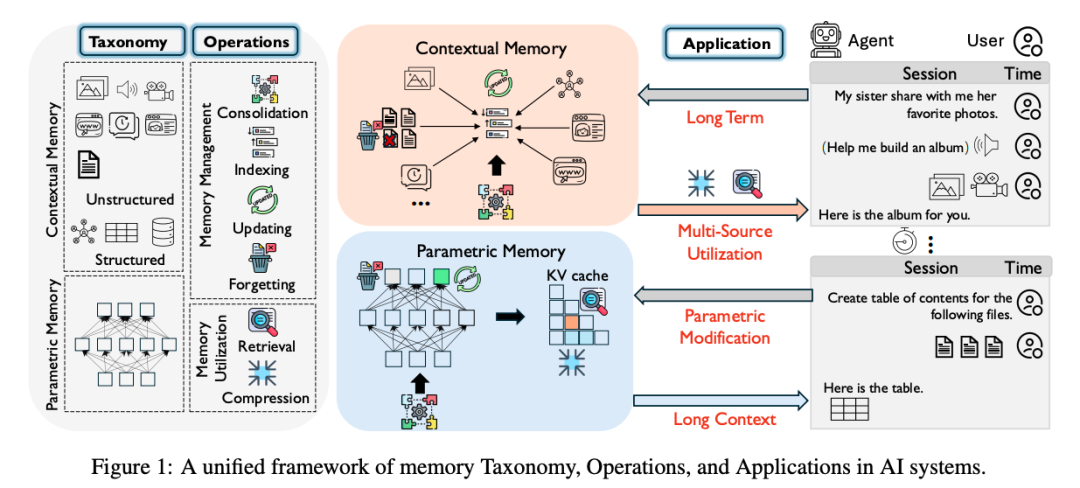
通过将这些操作系统地映射到长期记忆、长上下文记忆、参数修改和多源记忆等最相关的研究主题中,从原子操作和表示类型的视角重新审视记忆系统,为AI中与记忆相关的研究、基准数据集和工具提供了一个结构化和动态的视角。
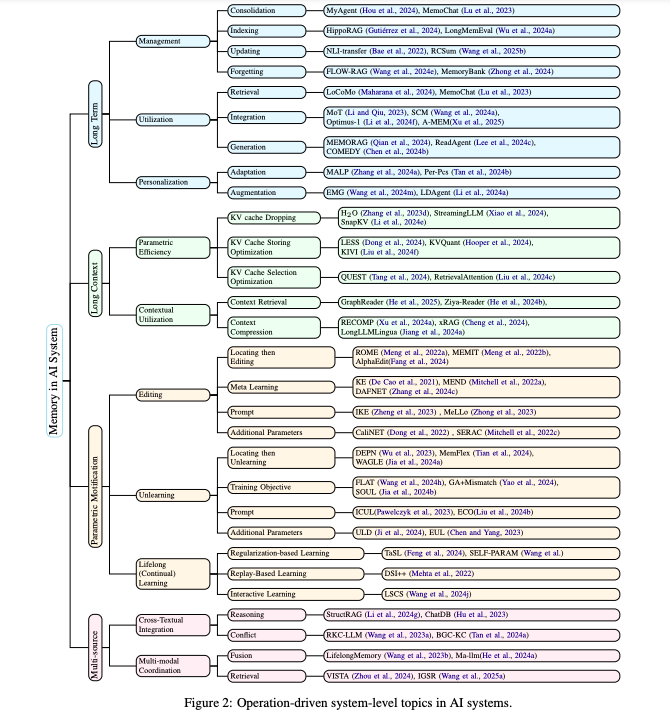
一、记忆的分类体系
详细介绍了AI系统中记忆的分类体系,将记忆分为三种主要类型:参数化记忆(Parametric Memory)、上下文结构化记忆(Contextual Structured Memory)和上下文非结构化记忆(Contextual Unstructured Memory)。以下是该部分的内容总结:
1.1 参数化记忆
-
定义:参数化记忆是指模型内部参数中隐式存储的知识。这些知识在预训练或后训练过程中获得,并在推理时通过前馈计算访问。
-
特点:
-
- 提供即时、长期且持久的记忆,能够快速检索事实和常识知识。
- 缺乏透明性,难以根据新体验或特定任务上下文选择性地更新。
-
应用场景:适用于需要快速访问固定知识的场景,例如问答系统和常识推理任务。
1.2 上下文非结构化记忆
-
定义:上下文非结构化记忆是一种显式的、模态通用的记忆系统,用于存储和检索跨异构输入(如文本、图像、音频、视频)的信息。
-
特点:
-
- 支持基于感知信号的推理,能够整合多模态上下文。
- 根据时间范围,进一步分为短期记忆(如当前对话会话上下文)和长期记忆(如跨会话对话记录和个人持久知识)。
-
应用场景:适用于需要处理多模态输入和动态上下文的任务,例如多模态对话系统和视觉问答系统。
1.3 上下文结构化记忆
-
定义:上下文结构化记忆是指以预定义的、可解释的格式或模式(如知识图谱、关系表、本体论)组织的显式记忆,这些记忆可以根据请求进行查询。
-
特点:
-
- 支持符号推理和精确查询,通常与预训练语言模型的关联能力相辅相成。
- 可以是短期的(在推理时构建用于局部推理)或长期的(跨会话存储策划知识)。
-
应用场景:适用于需要精确知识检索和推理的任务,例如知识图谱问答和复杂事件推理任务。
二、记忆6种操作
详细介绍了AI系统中记忆操作的分类和功能。这些操作被分为两大类:记忆管理(Memory Management)和记忆利用(Memory Utilization)。
2.1 记忆管理
记忆管理涉及如何存储、维护和修剪记忆,以支持记忆在与外部环境交互过程中的有效使用。记忆管理包括以下四种核心操作:
-
Consolidation(巩固):
-
- 定义:将短期经验转化为持久记忆,例如将对话历史编码为模型参数、知识图谱或知识库。
- 功能:支持持续学习、个性化、外部记忆库构建和知识图谱构建。
- 应用场景:在多轮对话系统中,将对话历史整合到持久记忆中,以便在未来的对话中使用。
-
Indexing(索引):
-
- 定义:构建辅助代码(如实体、属性或基于内容的表示),以便高效检索存储的记忆。
- 功能:支持可扩展的检索,包括符号、神经和混合记忆系统。
- 应用场景:在大规模记忆库中,通过索引快速定位和检索相关信息。
-
Updating(更新):
-
- 定义:重新激活现有记忆表示并对其进行临时修改。
- 功能:支持持续适应,同时保持记忆一致性。例如,通过定位和编辑机制修改模型参数,或通过总结、修剪或精炼来更新上下文记忆。
- 应用场景:在对话系统中,根据用户反馈动态更新记忆内容。
-
Forgetting(遗忘):
-
- 定义:有选择性地抑制可能过时、无关或有害的记忆内容。
- 功能:通过遗忘技术(如修改模型参数以擦除特定知识)或基于时间的删除和语义过滤来丢弃不再相关的内容。
- 应用场景:在处理敏感信息时,确保隐私和安全,同时减少记忆干扰。
2.2 记忆利用
记忆利用涉及在推理过程中检索和使用存储的记忆,以支持下游任务(如响应生成、视觉定位或意图预测)。记忆利用包括以下两种操作:
-
Retrieval(检索):
-
- 定义:根据输入识别并访问相关记忆内容。
- 功能:支持从多个来源(如多模态输入、跨会话记忆)检索信息。
- 应用场景:在问答系统中,根据问题检索相关的知识库内容;在多轮对话中,检索与当前对话相关的上下文信息。
-
Compression(压缩):
-
- 定义:在保持关键信息的同时减少记忆大小,以便在有限的上下文窗口中高效使用。
- 功能:通过预输入压缩(如对长上下文输入进行评分、过滤或总结)或后检索压缩(如在模型推理前对检索到的内容进行压缩)来优化上下文使用。
- 应用场景:在处理长文本输入时,通过压缩减少计算负担,同时保留关键信息。
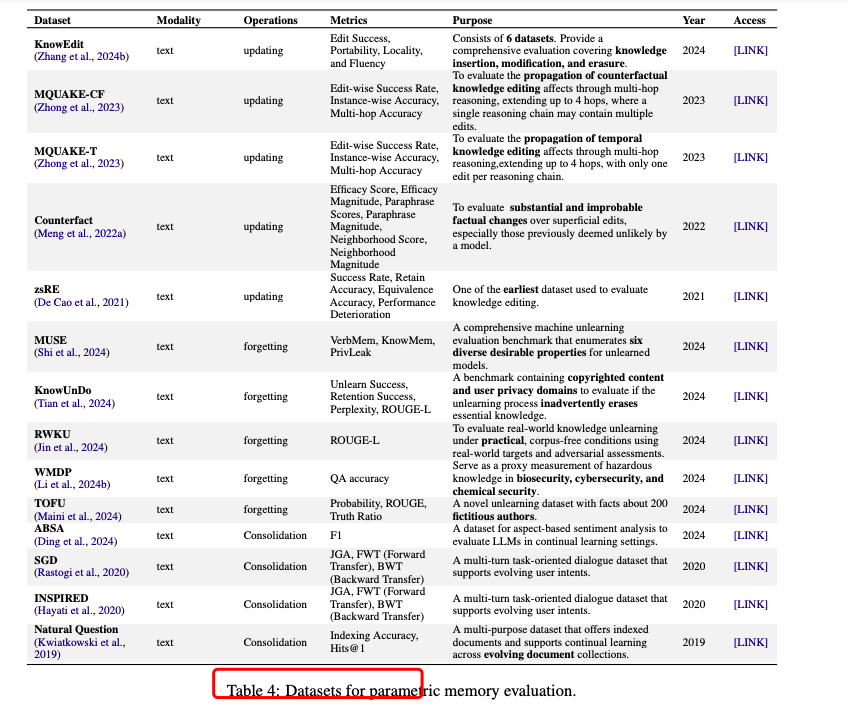
三、从记忆操作到系统级主题
探讨了如何将前面介绍的记忆操作(巩固、索引、更新、遗忘、检索、压缩)应用于实际的系统级研究主题。这些主题涵盖了长期记忆、长上下文记忆、参数化记忆修改和多源记忆等多个方面。
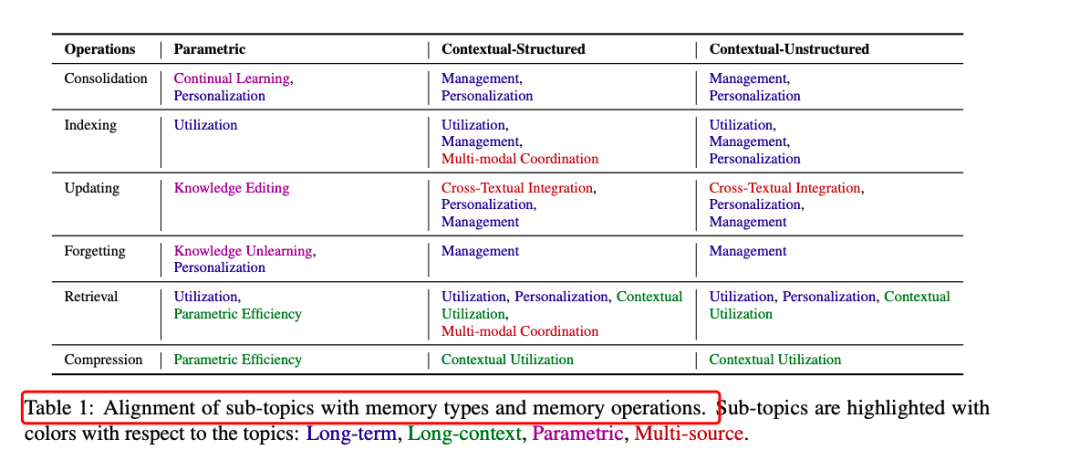
3.1 长期记忆
长期记忆是指通过与环境的交互而持久存储的信息,支持跨会话的复杂任务和个性化交互。
-
管理(Management):
-
- 巩固(Consolidation):将短期记忆转化为长期记忆,例如通过对话历史的总结或编码。
- 索引(Indexing):构建记忆索引以支持高效检索,例如通过知识图谱或时间线索引。
- 更新(Updating):根据新信息更新长期记忆,例如通过对话历史的动态编辑。
- 遗忘(Forgetting):有选择性地移除过时或不相关的记忆,例如通过时间衰减或用户反馈。
-
利用(Utilization):
-
- 检索(Retrieval):根据当前输入和上下文检索相关记忆,例如通过多跳图检索或基于事件的检索。
- 整合(Integration):将检索到的记忆与模型上下文结合,支持连贯的推理和决策。
- 生成(Generation):基于整合的记忆生成响应,例如通过多跳推理或反馈引导的生成。
-
个性化(Personalization):
-
- 模型级适应(Model-Level Adaptation):通过微调或轻量级更新将用户偏好编码到模型参数中。
- 记忆级增强(Memory-Level Augmentation):在推理时从外部记忆中检索用户特定信息以增强个性化。
3.2 长上下文记忆
长上下文记忆涉及处理和利用大量的上下文信息,以支持长文本理解和生成。
-
参数化效率(Parametric Efficiency):
-
- KV缓存丢弃(KV Cache Dropping):通过静态或动态方式丢弃不必要的KV缓存,以减少内存需求。
- KV缓存存储优化(KV Cache Storing Optimization):通过量化或低秩表示压缩KV缓存,以减少内存占用。
- KV缓存选择(KV Cache Selection):通过查询感知的方式选择性加载KV缓存,以加速推理。
-
上下文利用(Contextual Utilization):
-
- 上下文检索(Context Retrieval):通过图结构或片段级选择方法,从大量上下文中检索关键信息。
- 上下文压缩(Context Compression):通过软提示压缩或硬提示压缩,减少上下文长度,提高推理效率。
3.3 参数化记忆修改
参数化记忆修改涉及对模型内部参数的动态调整,以适应新的知识或任务需求。
-
编辑(Editing):
-
- 定位-编辑方法(Locating-then-Editing):通过归因或追踪找到存储知识的位置,然后直接修改。
- 元学习(Meta Learning):通过编辑网络预测目标权重变化,实现快速和稳健的修正。
- 提示方法(Prompt-based Methods):通过精心设计的提示间接引导输出。
- 附加参数方法(Additional-parameter Methods):通过添加外部参数模块调整行为,而不修改模型权重。
-
遗忘(Unlearning):
-
- 定位-遗忘方法(Locating-then-Unlearning):找到负责特定记忆的参数,然后应用目标更新或禁用。
- 训练目标方法(Training Objective-based Methods):通过修改训练损失函数或优化策略,显式鼓励遗忘。
-
持续学习(Continual Learning):
-
- 正则化方法(Regularization-based Methods):通过约束重要权重的更新,保留关键参数记忆。
- 重放方法(Replay-based Methods):通过重新引入过去样本强化记忆,特别适合在训练中整合检索到的外部知识。
3.4 多源记忆
多源记忆涉及整合来自不同来源(如文本、知识图谱、多模态输入)的信息,以支持更丰富的推理和决策。
-
跨文本整合(Cross-textual Integration):
-
- 推理(Reasoning):整合多格式记忆以生成一致的响应,例如通过动态整合领域特定的参数化记忆。
- 冲突解决(Conflict Resolution):识别和处理来自不同记忆源的矛盾信息,例如通过信任校准和来源归因。
-
多模态协调(Multi-modal Coordination):
-
- 融合(Fusion):对齐跨模态信息,例如通过统一语义投影或长期跨模态记忆整合。
- 检索(Retrieval):跨模态检索存储的知识,例如通过基于嵌入的相似性计算。
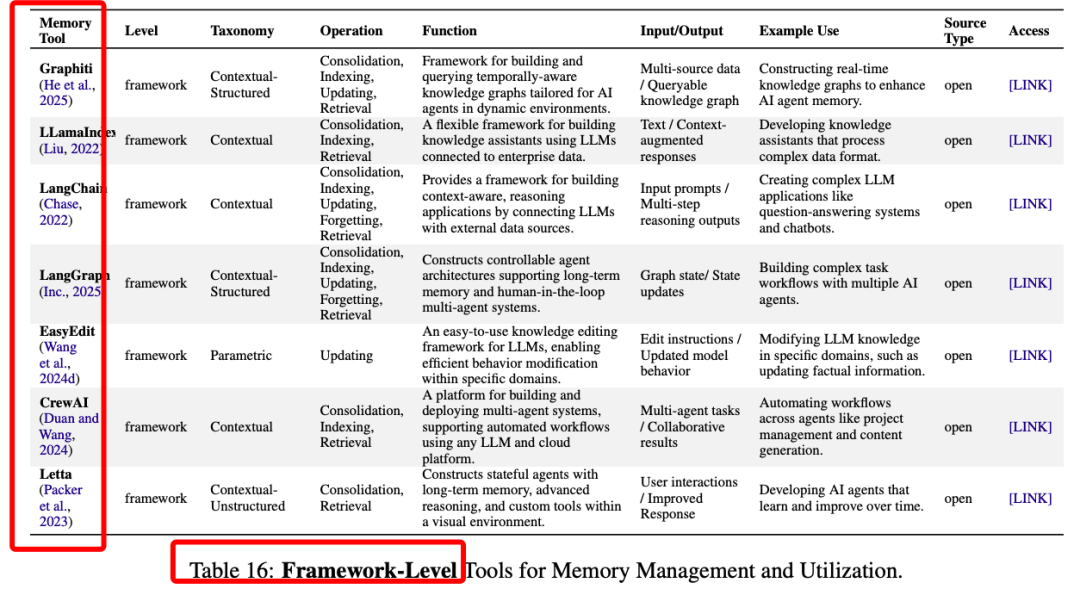
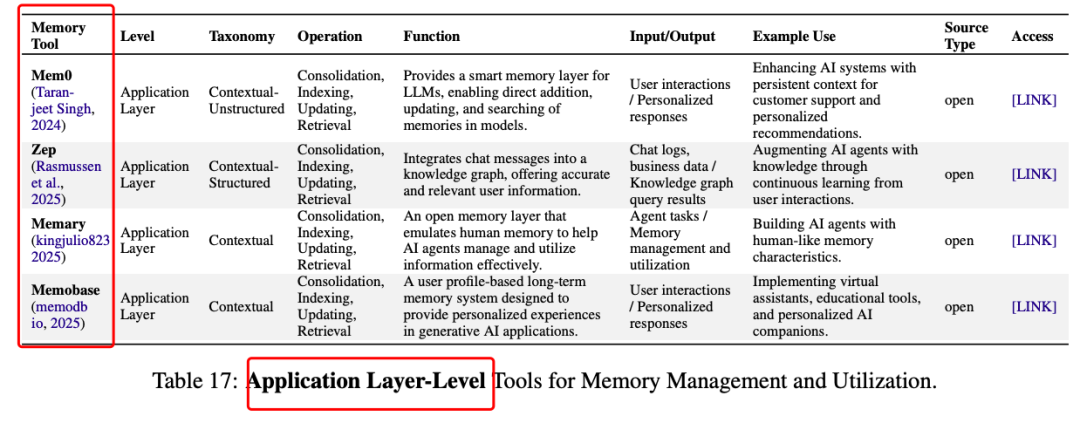
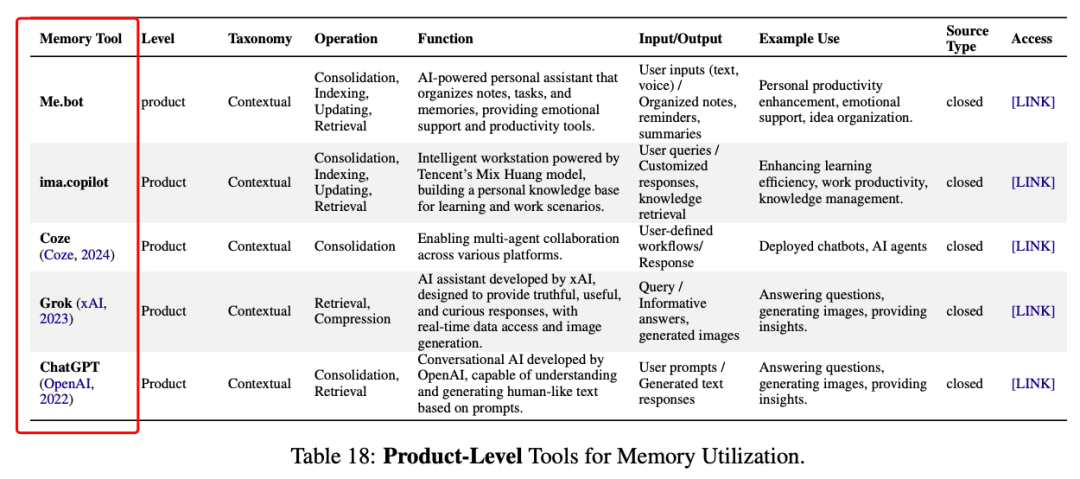
https://arxiv.org/pdf/2505.00675Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directionshttps://knowledge-representation.org/j.z.pan/
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 19
19 0
0- 0



 已为社区贡献110条内容
已为社区贡献110条内容

所有评论(0)