如何快速、免费搭建一个独属自己的个人知识库?(框架、要点)看完这一篇你就懂了!!
AI大模型层出不穷,不知大家使用的感受怎么样。作为码字一员,最大的感受是,AI大模型正在批量制造垃圾,反过来垃圾又在污染AI语料库,如此反复。“如果数据源、参考源是垃圾,得到的也只能是垃圾。”那么,如何控制数据源、参考源?
前言
AI大模型层出不穷,不知大家使用的感受怎么样。
作为码字一员,最大的感受是,AI大模型正在批量制造垃圾,反过来垃圾又在污染AI语料库,如此反复。
“如果数据源、参考源是垃圾,得到的也只能是垃圾。”
那么,如何控制数据源、参考源?
一个独立于公域的私域库,在这个信息爆炸、信息筛选成本越来越高的时代就显得尤为重要。
有能力、有预算的企业、个人,已经着手搭建公司、个人知识库;对于个人来说,如果只是轻度使用,该怎么快速、轻便构建属于自己的知识库呢?
本篇结合笔者使用几个月的经历,给大家做一个分享。
先看看效果:
- 查产品获批:

- 查财报信息:

- 查物价信息:

本篇分以下几部分简单介绍:
(1)工具、(2)框架搭建、(3)标签体系、(4)正式搭建、(5)使用注意事项
01 工具
腾讯ima。

ima具体使用方式不再赘述,很好上手。
笔者总结其优势:
-
免费,界面清爽,无广;
-
整合deepseek模型(比原生deepseek快、稳定,不会崩溃);
-
30G存储空间(可作为网盘使用);
-
小程序、手机、PC、平板,无缝跨平台使用(可当文件传输助手);
-
一键导入微信公众号文章(腾讯同体系优势);
-
支持线上笔记功能(当跨平台笔记本用);
-
个人知识库、共享知识库隔离(个人库自己使用;共享库可以团体、部门、公司使用);
-
还在不断迭代更新(功能陆续开发中)。
有朋友应该已经使用过ima,可能感受不佳。一方面可以继续看看下面内容,看看笔者的建议是否有帮助;另一方面,调整预期,对于一个免费工具,当一个跨平台的网盘、收藏夹、笔记本、检索工具,也未尝不可。
02 框架搭建
有了工具,并不意味着把电脑中的所有内容喂给它,它就能按指令输出。
为了让它发挥最大的效能,笔者建议和房屋收纳、电脑文件夹整理一样,首先想想这个知识库用来干什么,然后根据目的,搭建一个知识库框架、统一命名体系、标签体系、文件权重,然后将文件分门别类。这样在后期可以更方便检索,更准确输出。
比如,笔者想搭建一个面向测序行业的共同知识库,如何操作呢?
基因江湖公众号主要面向于测序行业,测序上中下游全产业链中的企业、行业人都是观察对象,那么该知识库的重点在于众多资料的有序归整。
为此,笔者搭建了如下框架,可供借鉴:
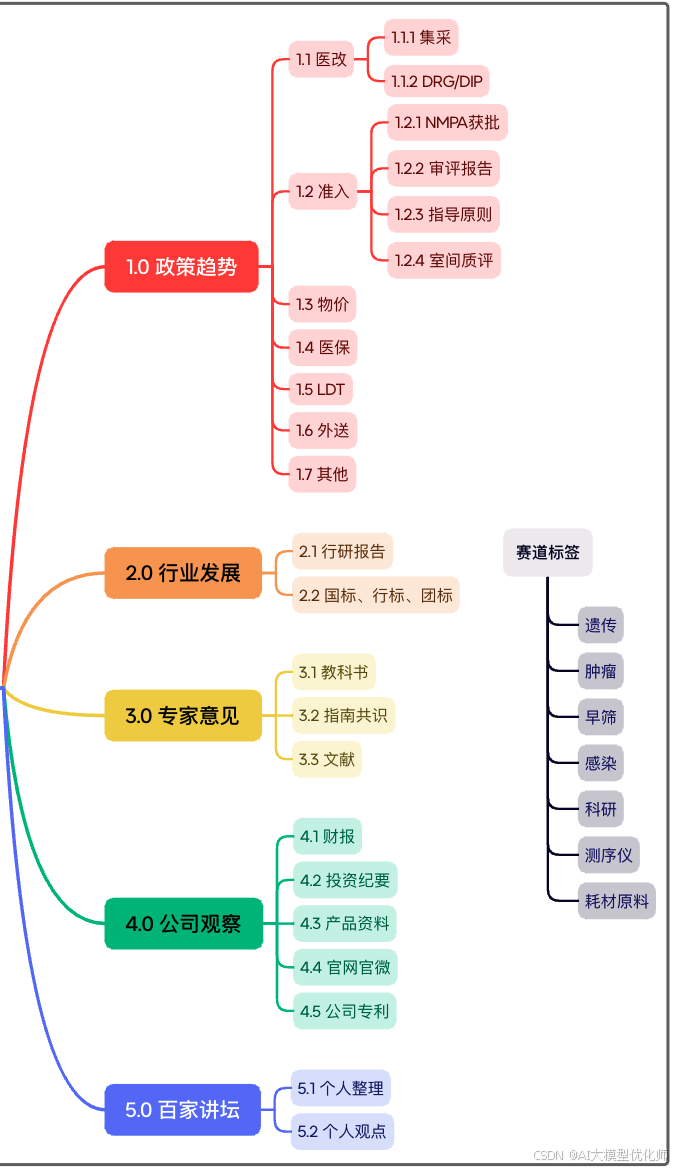
整个框架由大到小,共分为5个模块,依次为:政策趋势、行业发展、专家意见、公司观察、百家讲坛。
相应地,笔者在PC端也建立了一个ima本地文件夹,在批量上传之前,先按上述框架整理所需要的资料。文件夹命名与上述框架保持一致。
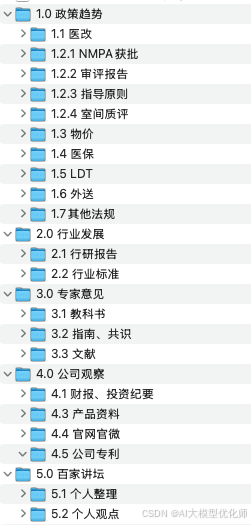
本地与线上统一数据、统一逻辑,双重保险,也方便维护。
03 标签体系
在ima工具中,笔者认为最重要的是“标签”体系。
文件上传后,要及时设定文件标签,如下:

如果不设定标签,在AI工具使用过程中经常发生的事情是,它会遍历所有文件、参考很多无用信息。
所以,如果想指定某类文件进行定向分析,建立标签系统尤为重要;同时,标签也有助于我们进行文件检索、进行批量操作。
比如本文之前案例:

在执行任务时,定义检索范围为“财报”,AI只会在标签为“财报”的文件中检索、输出。
建立文件标签时,经常发生的事情是“临时随意设定”,比如一份财报,标签可能随手设定为“财报”、“年报”、“年度报告”、“X公司年报”等等,这样的标签设定毫无意义,只会让标签体系越来越混乱。
那如何构建呢?
可以先一套分类逻辑为主,穷尽;然后再用另一套分类逻辑作为补充。
如细分领域是一套标签体系、公司名称是一套标签体系、文件置信权重也是一套标签体系。按自己使用习惯来设定。
注意同一文件的标签不宜过多(一般不超过3个),否则会增加每次文件导入的工作量。
笔者目前的做法,标签命名体系与上文中(2)知识体系框架中最后一个词条一致:
“物价、医保、财报、行研、文献、指南…”
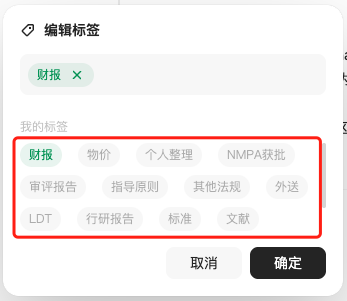
统一命名体系,方便后续定向分析、检索和批量操作。
04 正式搭建
按上文,设定了知识库框架和标签体系,剩下的就是文件批量上传、导入。
此处有3个关键点:
(1)宁缺毋滥:私域库设定的最初目的,就是人为筛选精要资料进行投喂,得到相对于公域更准确的结果;也可以通过标签体系对每一份文件置信程度进行赋分;
(2)统一文件命名规则:同一类型文件尽量按同一规则进行命名,如下:
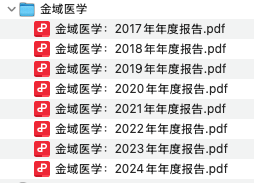
(3)定期维护,实时更新:建议先本地库,再线上库。
05 注意事项
(1)善用标签:指定标签对某一类资料进行分析;
(2)多次尝试:执行任务时输入的提示词,可以反复尝试,其中关键词尽量与文件中关键词统一;执行效果较好的关键词,建议保存,以后可以直接复制、执行;
(3)结果错误、缺漏:尽管已经人为控制了数据源,但AI在执行任务时仍会经常出错,尤其是对多文件、表格数据、表头不一等数据的汇总处理。同一指令多次执行,每次输出不尽相同。
对于复杂任务,建议进行任务拆解。重要的数据,建议根据AI的参考资料,进行溯源核对,不建议直接使用。
(4)建议使用DeepSeek R1模型:ima默认为腾讯旗下混元模型,可以在执行任务时选择DeepSeek R1模型;也可在设置中修改默认模型为DeepSeek R1模型。

以上,是笔者基于ima工具搭建个人知识库、行业知识库的个人体会。目前笔者对该工具的评价,能胜任一般性的信息检索,但对复杂任务处理不足。可用作信息提示、任务粗处理、临时查询等。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 12
12 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)