[Seg|OVSS]FreeDA:Training-Free Open-Vocabulary Segmentation with Offline Diffusion-Augmented Prototy
提出了Freeda,一种无训练的无监督开放词汇切分方法。方法利用视觉原型和文本关键字通过扩散增强生成来离线提取,并利用推理时的局部全局相似性。在实验上,在五个不同的数据集上获得了最先进的结果。
·
1. BaseInfo
| Title | Training-Free Open-Vocabulary Segmentation with Offline Diffusion-Augmented Prototype Generation |
| Adress | https://arxiv.org/pdf/2404.06542 |
| Journal/Time | CVPR 2024 |
| Author | University of Modena and Reggio Emilia, IIT-CNR |
| Code | https://aimagelab.github.io/freeda/ |
2. Creative Q&A
大规模预训练的对像素级和单个概念的直接定位能力差,利用扩散模型在视觉上定位生成概念和局部-全局相似性的能力,将类无关区域与语义类别相匹配。
两阶段:
- 收集文本-视觉参考嵌入,从大量描述开始,利用视觉和语义上下文。
- 在测试时,这些嵌入被查询以支持视觉匹配过程,该过程通过联合考虑类无关区域和全局语义相似性来完成。
3. Concrete
- 离线阶段
利用扩散增强生成法,生成一组文本 - 视觉参考向量 。具体来说,通过大量文本描述生成合成图像及textual-visual reference vectors,这借助基于交叉注意力的定位机制实现 。
然后,使用自监督视觉主干网络 DINOV2 构建一组视觉原型(visual prototypes ),这些原型与文本向量相关联,表征合成场景中实例的上下文 。 - 推理阶段
用多模态编码器(如 CLIP )提取全局特征,同时用 DINOV2 提取局部密集特征,DINOV2 的特点是语义相关性高 。
运用超像素算法检测相关区域 。在文本 - 视觉参考嵌入集中查询输入文本类别,将每个超像素分配给在全局和局部模态间综合相似度最高的类别 。
3.1. Model
扩散部分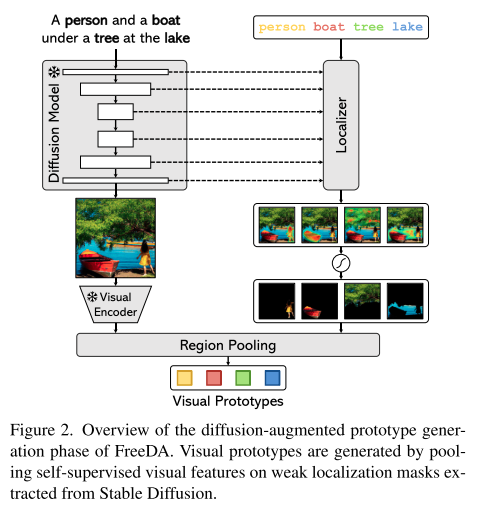
推理过程的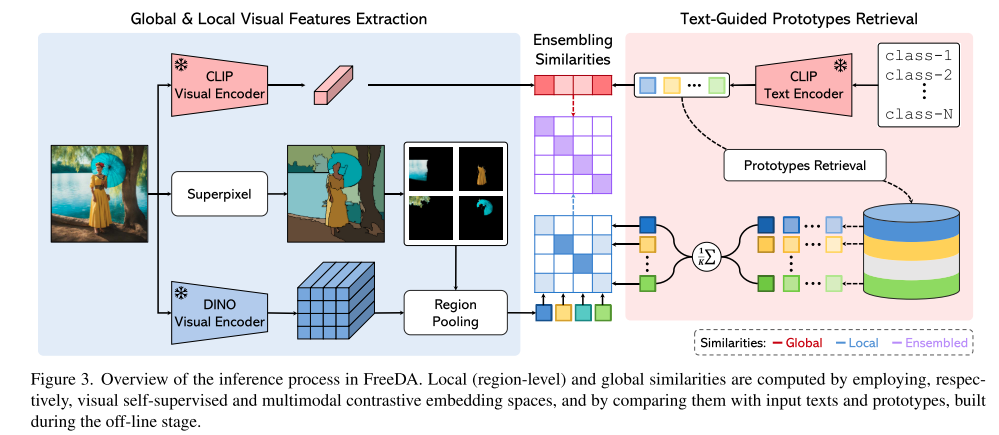
利用稳定扩散(Stable Diffusion )生成大规模真实世界场景图像,为构建语义类原型集提供基础。
为编码局部化掩码信息,采用 DINOV2 模型提取全局视觉特征,利用其语义匹配能力。
结合局部和全局相似度,利用 CLIP 模型计算输入图像与文本的全局余弦相似度,再结合局部相似度,得出多模态空间的相似度。通过加权求和结合局部和全局相似度,得到最终语义相似度,据此预测分割掩码,实现语义分割。
- 扩散增强原型生成(Diffusion - Augmented Prototype Generation )
核心目标:构建能代表不同语义类别的视觉原型,像 “人”“船” 等类别,得有对应的视觉特征表示。
文本引导图像生成,弱定位对象掩码,提取视觉特征,生成视觉原型。 - 无训练掩码预测(Training - Free Mask Prediction )
检索原型:把输入文本类别编码,和训练时的文本模板对比,用余弦相似度从原型数据库找最像的 K 个视觉原型。
结合局部和全局相似度:CLIP 视觉编码器提取图像全局特征,和文本特征计算全局余弦相似度,衡量图像整体和文本语义的匹配程度。DINO 视觉编码器结合超像素分割,提取局部密集特征,经区域池化处理,计算局部相似度,关注图像局部区域和语义的关联。
3.2. Training
| 类别 | 详情 |
|---|---|
| 文本输入来源 | COCO Captions数据集,使用每张图像对应的全部5条字幕 |
| 扩散模型 | Stable Diffusion v2.1 ,扩散步数50 ,阈值 γ\gammaγ 为0.45 ,标量权重 α\alphaα 为0.9 |
| 自监督视觉主干网络 | DINOV2 ,在LVD - 142M数据集预训练,使用ViT - B/14和ViT/L - 14版本,输入图像尺寸518×518 ,生成密集特征尺寸37×37 |
| 多模态编码器 | CLIP ,采用原始OpenAI权重,ViT - B/16和ViT - L/14架构,用于键嵌入和全局相似度计算 |
| 超像素提取算法 | Felzenszwalb算法 |
| 原型检索 | 通过faiss库基于余弦相似度构建高效检索索引,检索原型数量 KKK 为350(所有数据集) |
| 相似度融合权重 | β\betaβ 为0.8(除Pascal VOC ,其 β\betaβ 为0.7 ) |
3.2.1. Resource
3.2.2 Dataset
| 数据集名称 | 语义类别数量 | 验证集图像数量 |
|---|---|---|
| Pascal VOC 2012 | 20 | 1,449 |
| Pascal Context | 59 | 5,104 |
| COCO Stuff | 171 | 5,000 |
| Cityscapes | 19 | 2,000 |
| ADE20K | 150 | 500 |
3.3. Eval
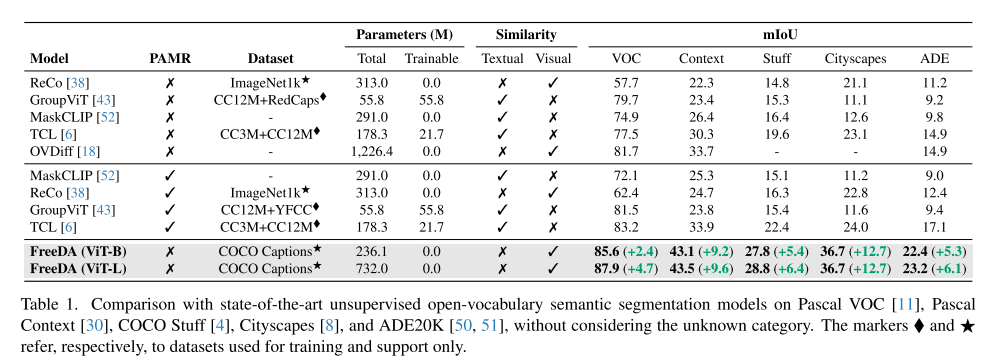
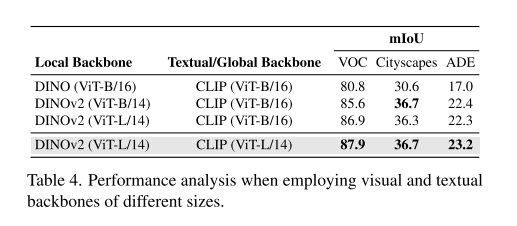
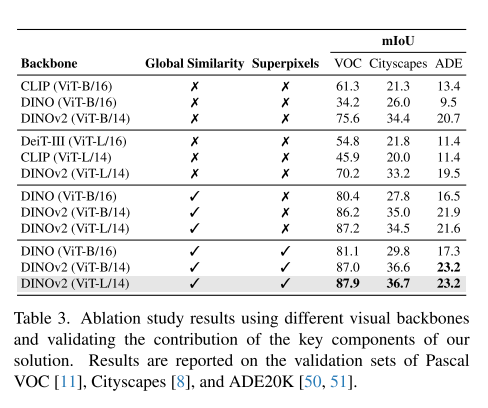
3.4. Ablation
4. Reference
5. Additional
有支撑材料
实验还是挺充分的。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)