【AI4TCM】基于GraphRAG技术赋能的大语言模型系统OpenTCM
OpenTCM通过。
摘要
OpenTCM系统通过构建中医知识图谱(含68本妇科典籍的370万古汉字提炼出的4.8万实体和15.2万关系)与GraphRAG技术结合,解决了中医古籍语义解析和复杂概念建模的难题;该系统无需模型微调即可实现高精度药物检索(专家评分4.5/5)和诊断问答(评分3.8/5),知识图谱构建精度达98.55%,为中医智能化提供了高效可靠的新范式。

一、背景:当古老中医遇见人工智能
传统中医(TCM)拥有数千年历史,其典籍蕴含丰富的诊疗智慧,如《黄帝内经》《伤寒杂病论》等。然而,这些古籍以文言文写成,术语晦涩(如“气滞血瘀”),知识体系复杂(药物、症状、方剂关联紧密),现代医师学习和应用难度大。尽管AI技术(如ChatGPT)已在现代医学中广泛应用,但直接用于中医面临严重挑战:误读古籍语义、忽略经典文献、开方“幻觉”风险(生成错误药方)。
香港中文大学团队开发的 OpenTCM 系统,首次将大语言模型(LLM)与中医知识图谱深度融合,构建了一个“免训练”的智能辅助平台。它从68本妇科古籍(370万古汉字)中提炼出4.8万条实体(药物、症状等)和15.2万条关系,通过创新的 GraphRAG 技术,实现高精度药物检索(专家评分4.5/5)和诊断问答(准确率75.1%),为中医数字化开辟新路径。
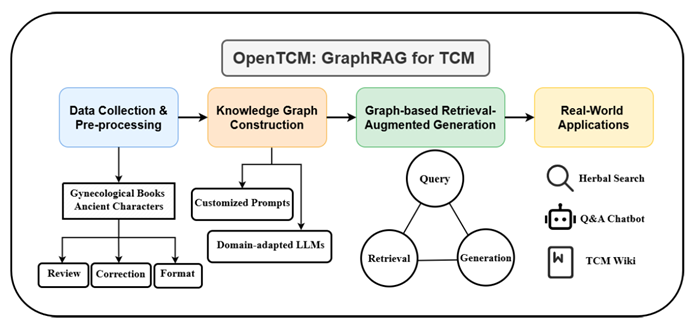
二、核心难题:中医知识现代化的三座大山
论文指出,中医AI化需攻克三大难关:
- 古籍语义鸿沟
古籍文言文与现代汉语差异巨大(如“当归”在古方中称“乾归”),且一词多义(“表证”既可指症状也可指病理阶段),通用AI模型无法准确解析。
- 知识关联复杂性
中医强调“辨证论治”,需综合症状、体质、药物相互作用(如“十八反十九畏”)等多维关系。现有系统多孤立处理信息,忽视整体关联。
- 结构化知识缺失
经典TCM文献缺乏数字化知识图谱(类似“中医版百科关联网络”),导致AI依赖“死记硬背”而非逻辑推理,易产生误导性结论。
例如,若问“产后头痛如何用药?”,通用AI可能机械推荐“川芎”,但忽略患者是否伴有“血虚”或“瘀血”,导致药不对症。
三、破解之道:OpenTCM的三步革新
Step 1:构建中医“知识互联网”
团队在中医专家协助下,从 68本妇科典籍(涵盖产科、妇科、不孕症)中提取370万字符原始文本,并创新设计 定制化提示词(Prompt) 指导AI解析:
- 角色定义:要求AI扮演“中医数据处理专家”,专注提取古籍关键信息;
- 结构化输出:强制生成标准化JSON数据,包含药物、症状、方剂等4类表结构(如“药物-方剂关联表”需注明剂量与炮制法);
- 示例学习:提供古文范例及对应输出格式,让AI“照葫芦画瓢”。
最终建成含 4.8万实体+15.2万关系 的知识图谱,精度高达 98.55%。例如,将“当归补血汤”拆解为:
成分(当归、黄芪)→ 功效(补气生血)→ 适用症状(产后血虚发热)→ 禁忌(阴虚火旺者忌用)
Step 2:知识图谱 + GraphRAG = 中医“最强大脑”
传统AI检索如同“关键词匹配”(输入“头痛”即搜所有含“头痛”的文本),而 GraphRAG 的核心突破是“关系推理”:
- 多跳检索:沿知识图谱路径自动关联多层信息。
用户问“月经不调伴腹痛该用什么药?”
→ 系统检索路径:腹痛 → 关联证型“气滞血瘀” → 推荐方剂“桃红四物汤” → 解析成分(桃仁、红花、当归等)
- 降幻觉设计:答案严格限定在图谱关联范围内,避免编造不存在的关系。
- 免训练部署:直接调用开源模型(如DeepSeek、Kimi),节省百万元级算力成本。
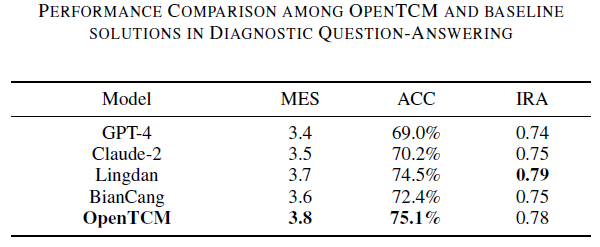
Step 3:双场景验证,效果碾压现有方案
系统在两类任务中完胜通用AI(如GPT-4)和中医专用模型(如BianCang、Lingdan):
|
任务类型 |
OpenTCM表现 |
对比模型最佳表现 |
|
药物知识检索 |
专家评分4.5/5,准确率89.6% |
评分3.2,准确率72% |
|
诊断问答 |
专家评分3.8/5,准确率75.1% |
评分3.0,准确率68% |
典型案例:
问:“气虚湿重如何调理?”
OpenTCM输出:
①推荐方剂“参苓白术散”(含人参、茯苓等);
②解释逻辑:气虚→脾失健运→生湿→需健脾化湿;
③警示“忌生冷油腻”。
——专家评价:“贴合经典理论,无冗余信息。”

四、技术点睛:为什么OpenTCM更懂中医?
1.中文优化LLM:DeepSeek & Kimi
实验证明,使用专攻中文的模型是关键:
- 古籍解析精度:中文LLM(DeepSeek) > 通用LLM(GPT-4)近20%
- 原因:DeepSeek/Kimi在训练中纳入更多文言文语料,理解“通假字”“典故”等特殊表达。
2.提示词工程:让AI“学规矩”
团队设计了一套中医专属指令:
- 错误案例:通用Prompt让AI将“白芍”(药物)误标为“地名”;
- 解决方案:在Prompt中明确定义“所有药材名需标记为‘ingredient’”。
3.知识图谱:中医关系的“超脑地图”
图谱包含10类关键关系,例如:
- 药物互斥:“甘草反甘遂”(配伍禁忌);
- 症状关联:“经期腹痛”常与“血块紫暗”共存(提示血瘀证);
- 方剂派生:“四物汤”是“桃红四物汤”的基础方。

五、未来:OpenTCM的进击之路
尽管当前成果显著,团队指出三大发展方向:
- 知识扩容
扩展至儿科、内科等全科典籍,纳入罕见病和医案,构建亿级实体图谱。 - 多模态融合
增加药材图像识别(如区分“生地黄”与“熟地黄”),辅助线下药房应用。
- 临床落地
开发患者版/医师版界面,并接入居家养老、临床辅助诊断等场景。
挑战:古籍中模糊表述(如“少许”“适量”)的量化处理,仍需中医专家介入。
六、结语:古老智慧的“数字新生”
OpenTCM通过 “知识图谱+GraphRAG” 双引擎,首次实现:
✅ 高精度古籍解析(误差<1.5%)
✅ 免训练高效部署(节省千亿参数微调成本)
✅ 可解释的诊断推理(如图4的辨证逻辑链)
团队已开源项目(https://github.com/XY1123-TCM/OpenTCM),未来将推动中医从“经验传承”走向“数据智能”,让AI真正成为老中医的“超级助手”,而非替代者。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 18
18 0
0- 0



 已为社区贡献278条内容
已为社区贡献278条内容

所有评论(0)