hive插入数据报错IOException(Unable toclosefile becausethe last blockdoes nothave enough number of replicas
Job Submission failed with exception 'java.io.IOException(Unable to close file because the last block BP-1696380843-192.168.139.128-1747021700060:blk_1073742200_1376 does not have enough number of rep
Hive插入数据翻车实录:你的HDFS副本在“罢工”?
作者:一个被BUG折磨到秃头的IT老司机
关键词:Hive、HDFS、副本不足、程序员崩溃瞬间
前言:当Hive告诉你“备胎不够”时
某个月黑风高的夜晚,你正优雅地敲下一条神圣的INSERT INTO语句,准备把熬夜写的20GB数据灌进Hive表里。突然!屏幕上蹦出一串报错,其中“Unable to close file because the last block does not have enough replicas”尤为亮眼,仿佛HDFS在对你冷笑:“兄弟,你的备胎不够啊!”
(程序员崩溃.jpg)
别慌!今天就让本老司机带你飙车,看透这个“副本不足”的真相,顺便教你如何优雅地让HDFS闭嘴!
一、副本不足?你的“备胎”不够啊!
1.1 HDFS的“备胎”哲学
在HDFS的世界里,每个数据块(Block)都要有至少3个“备胎”(默认副本数dfs.replication=3)。这就像你同时找三个朋友帮你保管同一份重要文件——万一某位朋友(DataNode)突然失联(宕机、断网、硬盘爆炸),其他两位还能顶上。
1.2 翻车现场还原
当你用Hive插入数据时,HDFS会:
-
把数据切成块(Block)
-
给每个块找“备胎”(副本)
-
凑齐备胎后,优雅地关闭文件(
closeFile)
但如果某个块的备胎数量不足(比如只找到1个备胎,而默认要3个),HDFS就会傲娇地抛出错误:“这届DataNode不行!”
二、翻车原因大起底:谁动了我的备胎?
2.1 备胎候选人(DataNode)集体跑路
-
DataNode宕机:某个节点突然躺平(比如被运维小哥误拔电源)。
-
磁盘爆炸:DataNode的硬盘塞满了小姐姐的4K视频(误)。
-
网络抽风:DataNode和NameNode玩起了“你画我猜”(网络中断)。
诊断方法:
hdfs dfsadmin -report 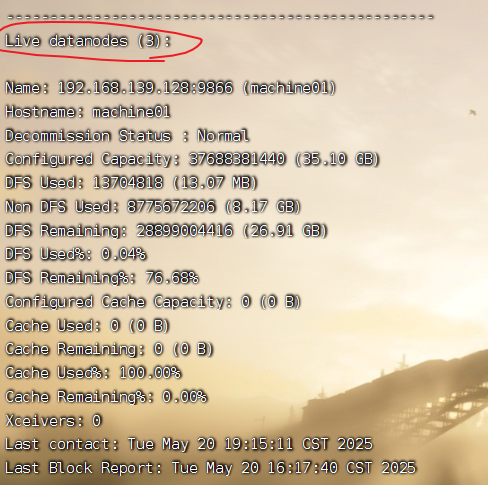
正常来说在Live datanodes后可以看到数量,且这个数量应与集群数量一致
若显示Dead datanodes则说明datanode挂掉了(诶,你好像有点似了耶ಠಿ_ಠ)
如果看到 Live datanodes 数量不足,请立刻拨打DataNode的心理咨询热线(重启服务)!
2.2 你要的备胎太多,但候选人太少
经典场景:
-
你设置了
dfs.replication=3,但整个集群只有2个DataNode。 -
就像你想找三个备胎,但通讯录里只有两个单身好友——HDFS表示:“臣妾做不到啊!”
解决方案:
-- 临时降低备胎需求(Hive会话中执行)
SET dfs.replication=1;(友情提示:测试环境可用,生产环境慎用!)(~ ̄(OO) ̄)ブ
终极奥义:修改HDFS“择偶标准”:
修改hdfs-site.xml,降低副本数要求:
<property>
<name>dfs.replication</name>
<value>2</value> <!-- 根据实际DataNode数量调整 -->
</property>(修改后记得重启HDFS,否则NameNode会继续装死( ̄m ̄))
2.3 备胎质量不过关
-
副本复制超时:DataNode在摸鱼(集群负载过高)。
-
块损坏:某个备胎偷偷篡改了你的文件(物理存储故障)。
急救措施:
hdfs fsck /path/to/file -blocks -locations # 检查哪个备胎不靠谱
hdfs debug recoverLease -path /path/to/file -retries 3 # 强制让HDFS重新找备胎2.4 HDFS配置的失误
我们在从IT“小登”转变为IT“老登”的过程中,老师经常会让我们去搭建伪分布式与全分布式,我们在伪分布式搭建时有这么一个步骤:namenode格式化:
hdfs namenode -format格式化其实就是在hadoop文件夹内创建了一系列的文件夹:logs tmp。
而在全分布式搭建时有这么一个步骤:删除 主机下的 hadoop 下的 logs 以及 tmp 文件。
rm -rf /opt/installs/hadoop/logs /opt/installs/hadoop/tmp不明白具体操作的可以移步我的另一篇博客哦 谢啦!!☆⌒(*^-゜)v深入剖析Hadoop之HDFS的安装,HDFS中的Shell命令与分布式的搭建_hdfs搭建-CSDN博客
可千万不要觉得删文件这个步骤不重要,已经有好多学弟学妹向我咨询这个问题了,我在解决的时候一问:AUV!您猜怎么着,人家根本没删!
我们在伪分布式格式化之后没有删除logs和tmp目录。格式化NameNode会生成新的集群ID,但原有的数据目录如果没被清除,可能会有残留。比如,tmp目录下的数据可能包含旧的fsimage和edits文件,这些属于之前的集群。而logs目录下的日志文件可能与新集群的ID不一致,导致DataNode无法正确注册。NameNode 或 DataNode 启动失败,提示元数据损坏。
所以同学们,我们只需要关闭hdfs,并从“删除logs和tmp文件夹”开始重新搭建hdfs全分布式就可以了哦 !Ψ( ̄∀ ̄)Ψ
三、防翻车秘籍:做一个备胎管理大师
-
日常监控:
-
用Ambari或Cloudera Manager盯紧DataNode状态。
-
定期执行
hdfs fsck /检查文件健康度。
-
-
备胎冗余策略:
-
副本数 ≤ 可用DataNode数量
-
生产环境建议至少3个DataNode
-
-
定期维护:
-
清理DataNode的垃圾数据
-
及时更换故障硬盘
-
四、结语:程序员の觉悟
程序员日常:不是在写BUG,就是在改BUG的路上。但只要你掌握了HDFS的“备胎管理艺术”,就能优雅地对报错说:“你过来啊!”

温馨提示:如果以上方法均无效,请尝试重启电脑、换键盘、烧香拜佛,或者@你的运维小哥。
点赞、收藏、关注三连,下次不迷路!
(毕竟,谁也不知道下一个BUG会从哪里冒出来🙃)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)