基于cnn的通用图像分类项目——服务端部署
在这篇文章里我们实现了一套通用的图像分类技术方案。通常,我们的算法是部署在服务端的,服务端接受到客户端传来的数据,将该数据传入算法模型内,算法模型推理后,计算出结果再回传给服务端。因此在该工程的features/flask分支上,本人开发了一套基于python flask的服务端模型部署demo。可以帮助开发人员熟悉ai算法模型接入服务端的实现细节。相关工程目录如图所示,flask_client.
前言
基于cnn的通用图像分类项目-CSDN博客 ,在这篇文章里我们实现了一套通用的图像分类技术方案。
通常,我们的算法是部署在服务端的,服务端接受到客户端传来的数据,将该数据传入算法模型内,算法模型推理后,计算出结果再回传给客户端。
因此在该工程的features/flask分支上,本人开发了一套基于python flask的服务端模型部署demo。可以帮助开发人员熟悉ai算法模型接入服务端的实现细节。
相关工程目录如图所示,flask_client.py是模拟客户端的代码,flask_server.py是模拟服务端的代码。predict1.jpg是我们用来推理的图片。客户端代码会将该图片通过网络请求传到服务端,服务端再进行算法推理。
此外,为帮助对算法开发不熟悉的同学,该工程的features/flask_public对算法开发相关的代码做了删除,进行了工程解耦,有助于后端快速落地。详细可以参考文章的最后一章节。
client
这里的客户端并不是指物理意义上的客户端,也可以是另一个服务端机器。总之,flask_client.py实现的是数据的发送与算法推理结果的接收。流程图如下:
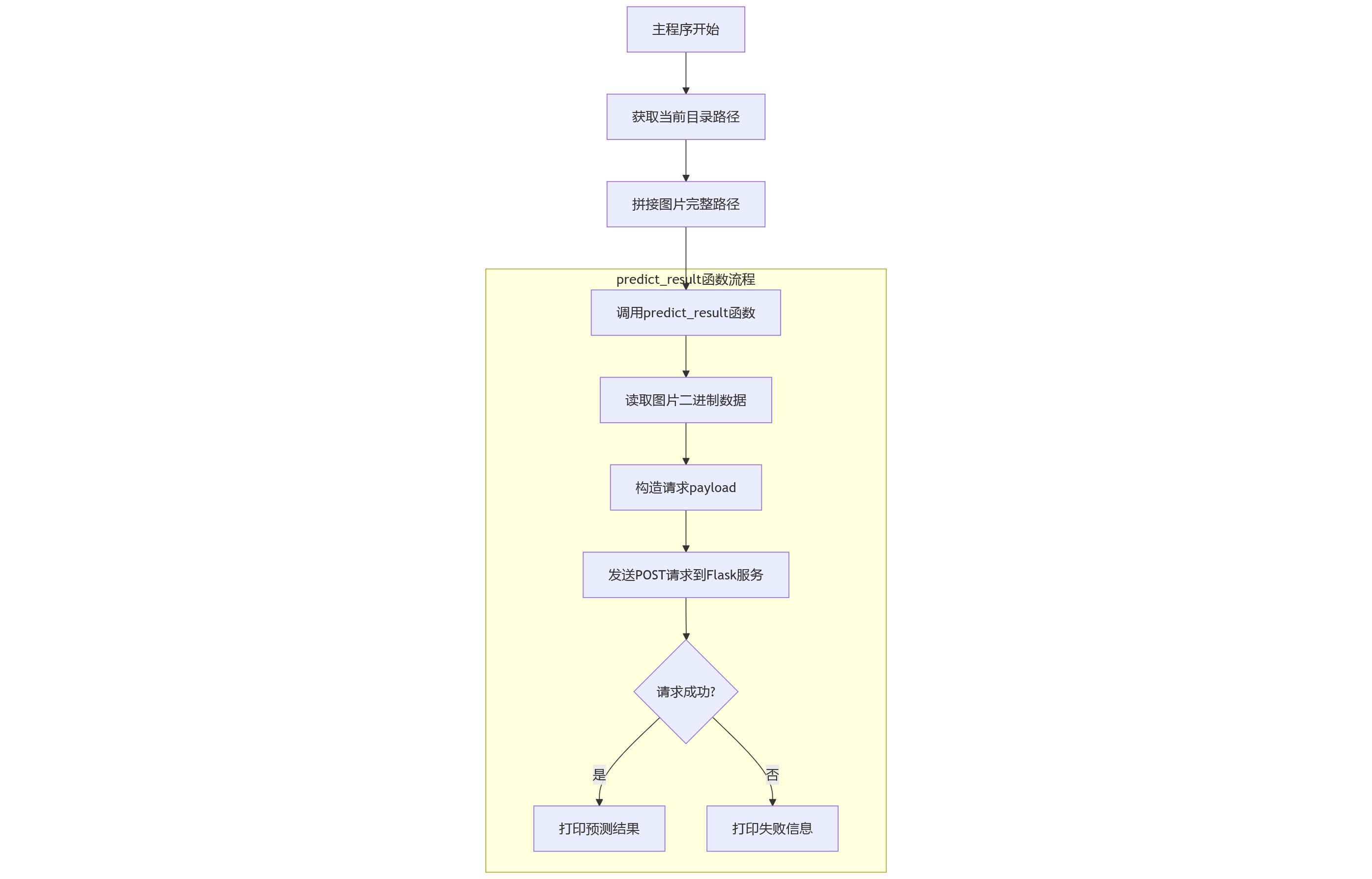
client里只有一个核心方法,用来处理图片数据的发送和请求结果的展示。
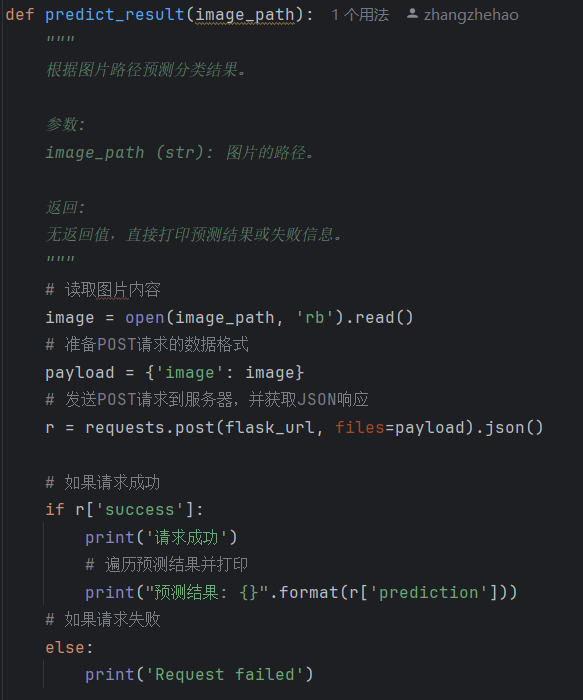
通过debug可以看到image对象包含了图像文件里面所有的像素值,image也就是图片的二进制对象。
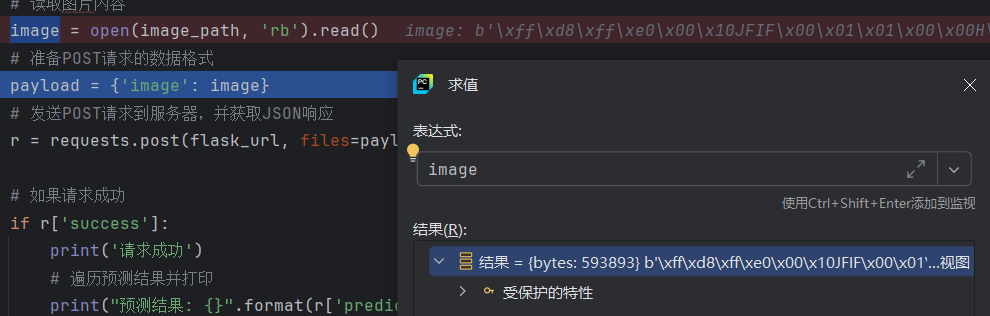 后面我们构建一个字典,将image对象作为一个value存放在字典内。再通过post请求将该字典数据发送到指定的服务器地址上。
后面我们构建一个字典,将image对象作为一个value存放在字典内。再通过post请求将该字典数据发送到指定的服务器地址上。
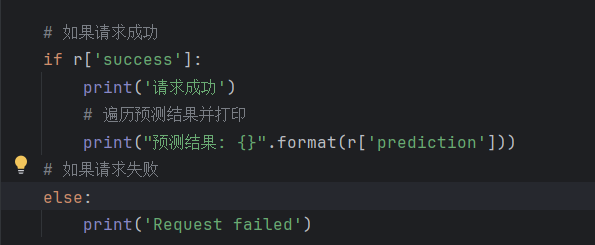
请求成功后会根据约定好的json字段,将预测结果打印出来。
server
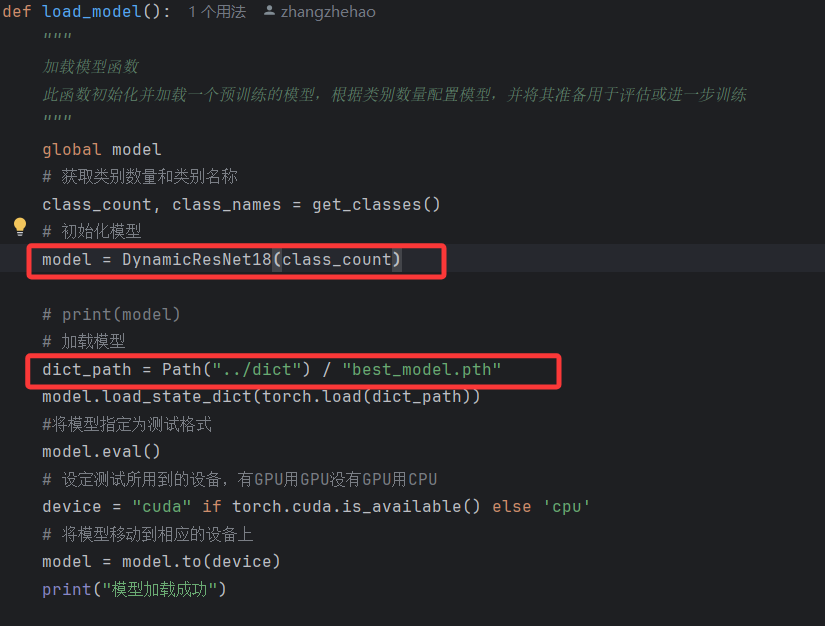
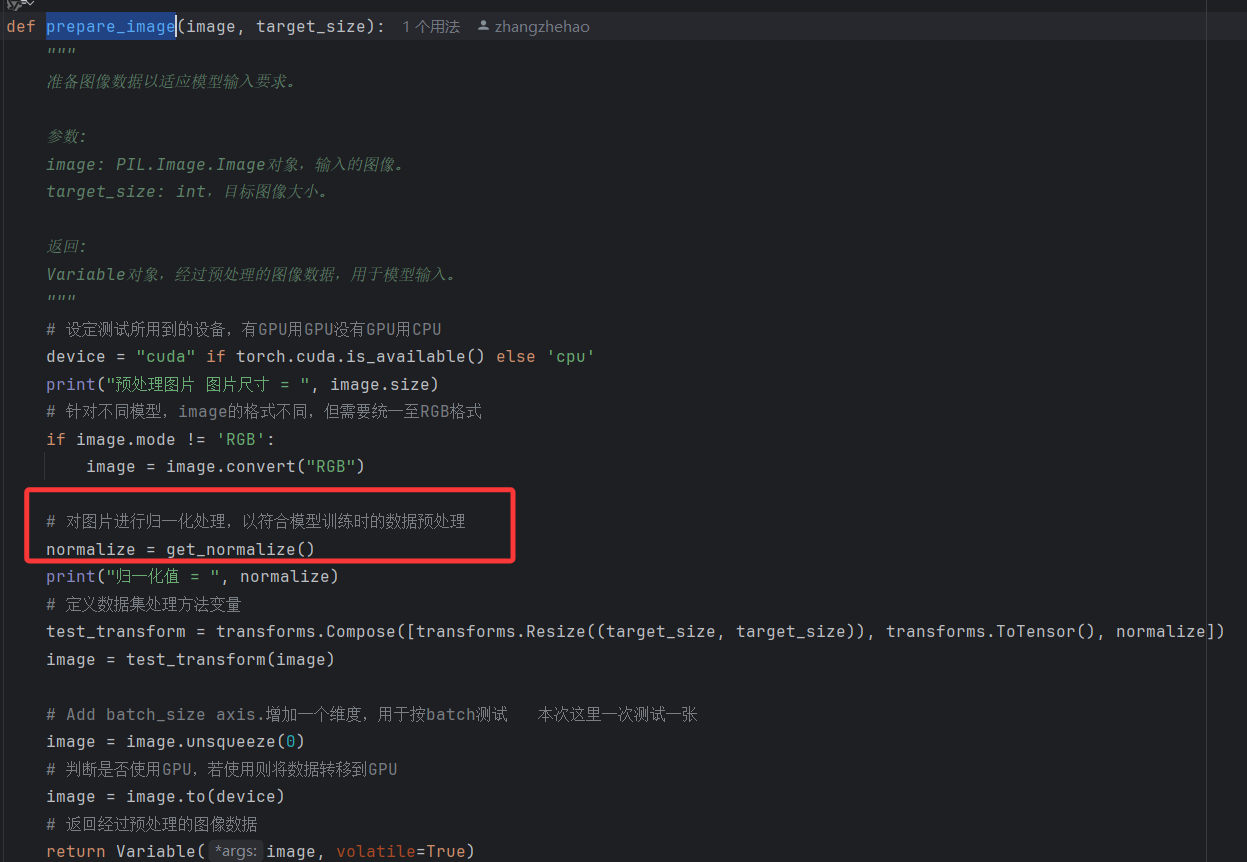
flask_server.py核心实现了三个方法,分别是模型加载,图片预处理,请求处理。其中图片预处理基本不需要调整。
flask_server.py的工作流程图如下所示:
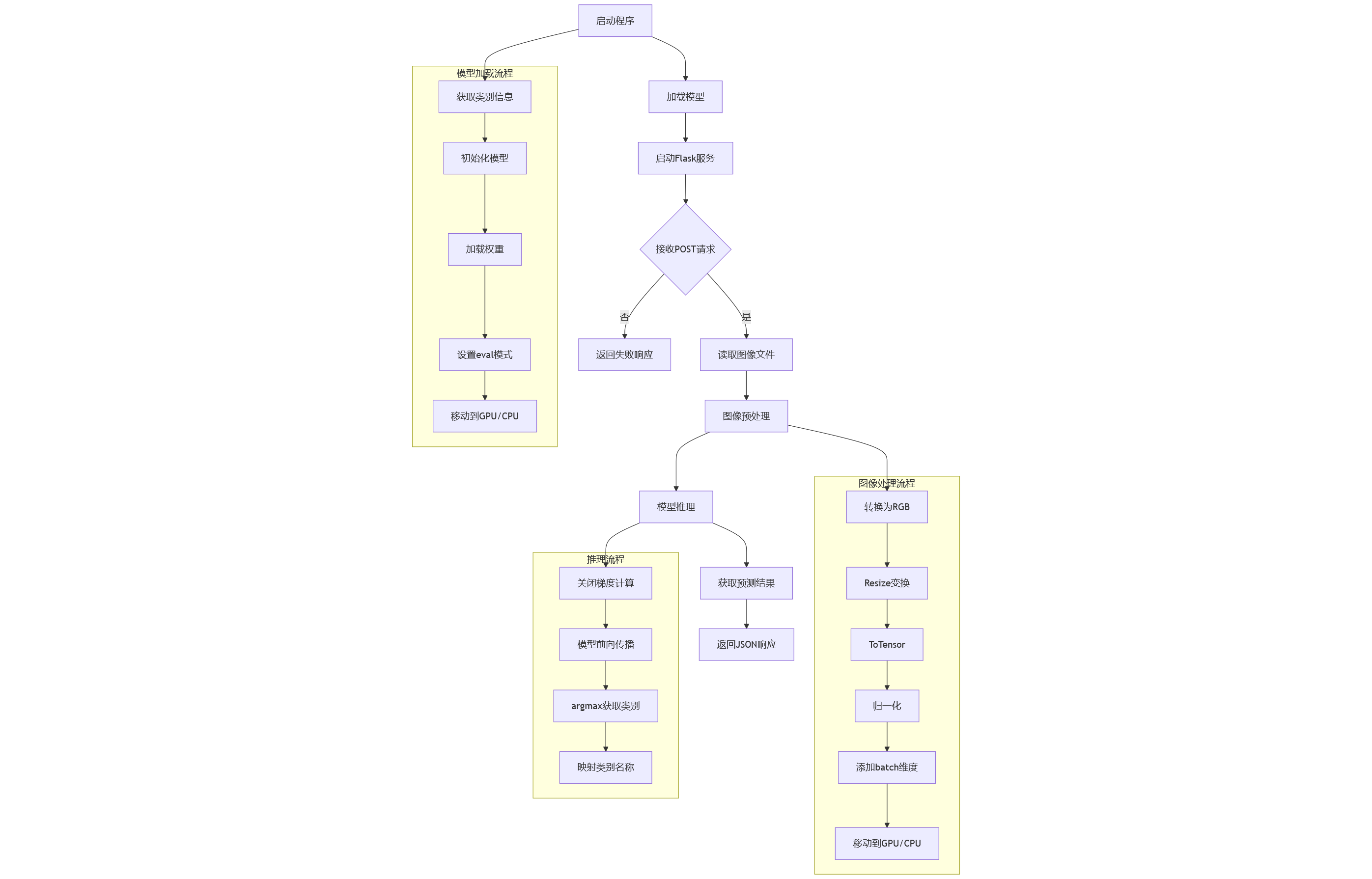
首先是在启动程序时先加载模型,ai模型的本质就是网络结构源码+模型参数。
当收到客户端的请求时,先将传来的图片进行预处理。这里注意,在归一化处理流程中,归一化需要的mean和std值需要与训练阶段的值相同,效果才最好。
所以在代码里我们会对训练集的图片完整计算一次mean和std值,是为了简化使用者的操作。但是需要注意,完整计算需要耗费一定时间,在实际的工程中,算法工程师会提供一组定值(训练集的值),来节省预处理速度。
当收到网络请求时,server会依次进行图像读取->图像预处理->模型推理->数据组装与返回。其中模型推理代码与上一篇文章中的推理环节完全相同,这里不加赘述。
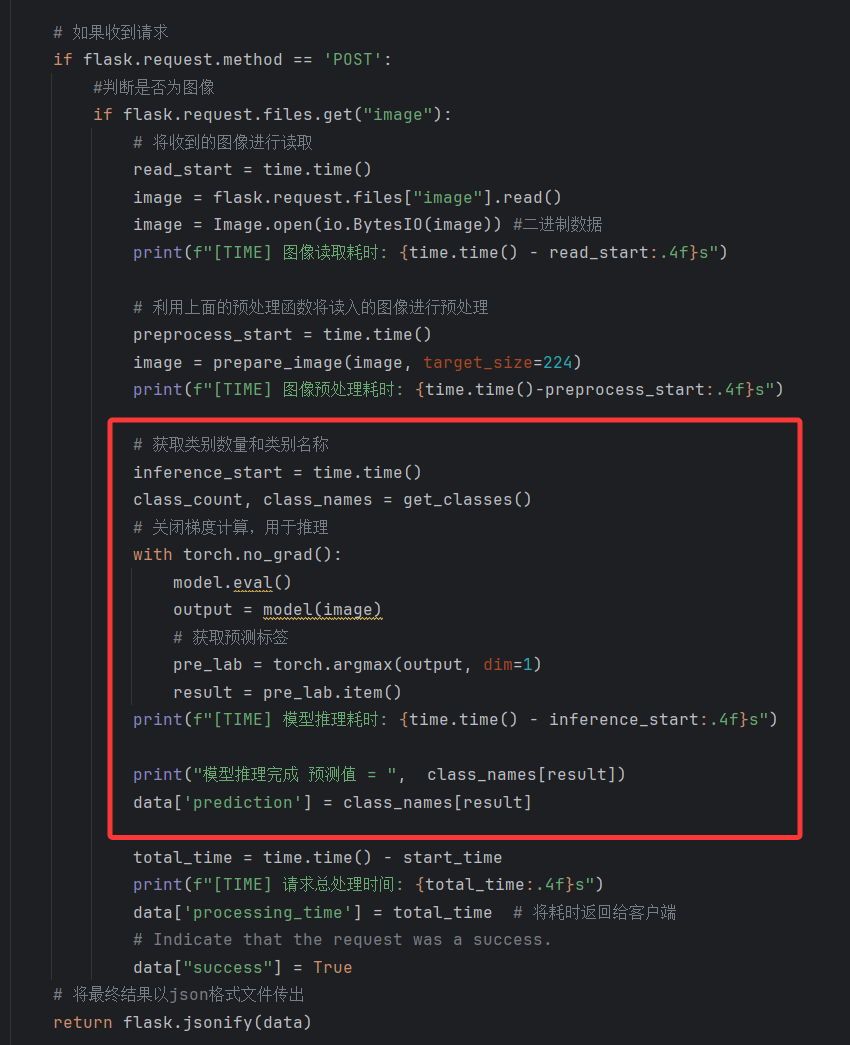
运行
首先运行server,启动flask服务;再运行client,发送请求。
运行sever,输出日志如下,可见模型已经加载成功。
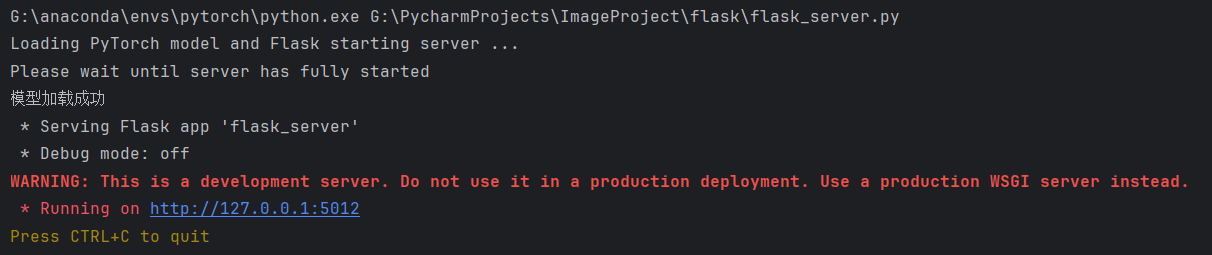
运行client,查看server的输出日志,可以看到主要的耗时是归一化数据计算,当该数据提供的是固定值时,该耗时可以忽略不计。
 一共耗时11秒,预处理花费了10.8秒(可优化为近似为0),模型推理仅使用了0.15秒,能够满足服务端耗时要求。(运行机器显卡为rtx 4070)
一共耗时11秒,预处理花费了10.8秒(可优化为近似为0),模型推理仅使用了0.15秒,能够满足服务端耗时要求。(运行机器显卡为rtx 4070)
再看client的输出日志,已经打印出来了预测值。

精简server工程
切换到 features/flask_public 分支,可以看到工程目录极大简化:
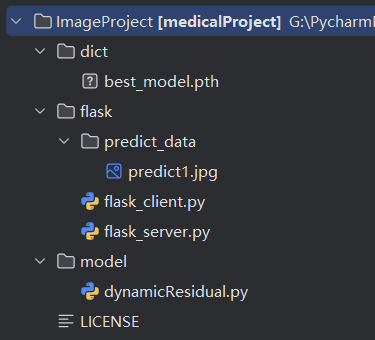
dict:存放模型网络参数文件。
flask:服务端与客户端demo。
model:存放模型网络结构文件。
dict和model文件夹下的内容由算法工程师提供,此外,在实际上线前,算法工程师还会提供一些额外参数:

归一化参数需要和训练的数据集相同,所以需要算法工程师提供一组定值。每次更新模型时,如果训练集数据有更新,则需要提供一组新的常量。
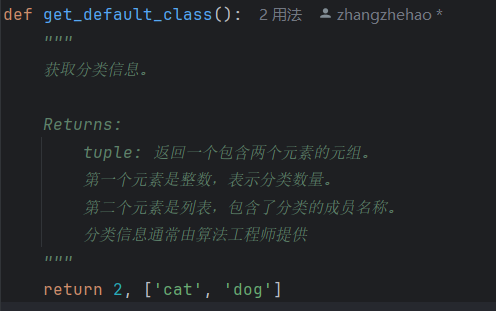
分类模型的分类数量和分类名称通常需要算法工程师提供,注意分类名称的顺序不可以调整。
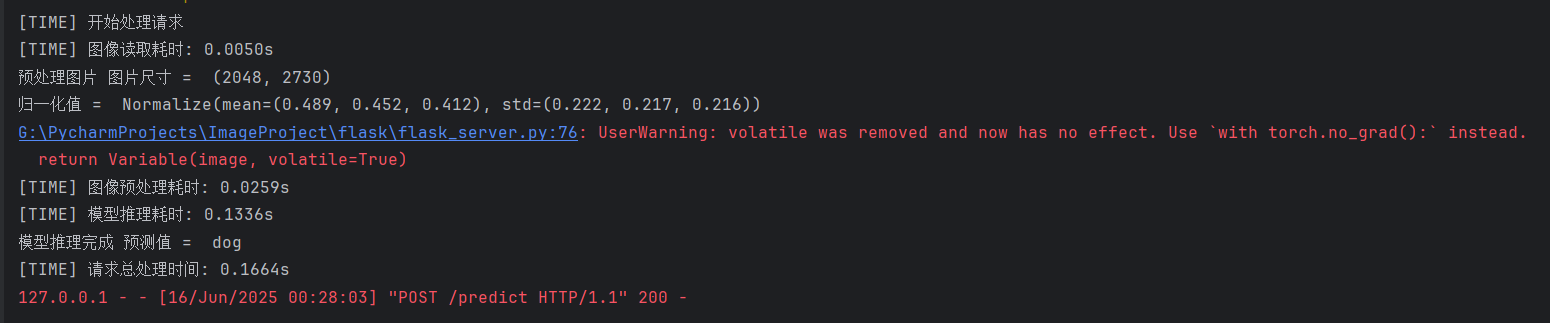
运行代码,可以看到总耗时只有0.1664s,原因是归一化的数值不需要重新计算,节省了绝大多数时间。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)