使用来自NL2SQL数据集的可调用API进行LLM工具调用评估
本文摘要: IBM研究院团队提出了一种将自然语言转SQL(NL2SQL)数据集自动转换为自然语言转API(NL2API)数据集的新方法。研究者开发了创新的数据生成流水线,利用SQL语法构建等效的API调用序列,并应用于BIRD-SQL数据集,创建了包含2500多个API的工具集合(SLOT/SEL/REST三种形式)。实验评估了10个公开大模型的表现,发现它们在工具调用任务上完成率仅为7-47%,
Benjamin Elder ∗{ }^{*}∗
IBM研究院AI
benjamin.elder@ibm.com
Ankita Rajaram Naik
IBM研究院AI
ankita.naik@ibm.com
Danish Contractor
IBM研究院AI
danish.contractor@ibm.com
Anupama Murthi ⋆{ }^{\star}⋆
IBM研究院AI
anupama.murthi@ibm.com
Kiran Kate
IBM研究院AI
kakate@us.ibm.com
Jungkoo Kang
IBM研究院AI
Jungkoo.Kang@ibm.com
Kinjal Basu
IBM研究院AI
Kinjal.Basu@ibm.com
摘要
大型语言模型(LLMs)通常被部署为“代理”系统,可以访问与实时环境交互以完成任务的工具。在企业应用中,这些系统需要与可能极其庞大且复杂的API集合交互,通常这些API由数据库支持。为了创建具有此类特征的数据集,在本研究中我们探索了如何利用现有的自然语言到SQL查询(NL2SQL)数据集自动创建自然语言到API(NL2API)数据集。具体而言,本文描述了一种新颖的数据生成流水线,该流水线利用SQL查询的语法构造功能等价的API调用序列。我们将这一流水线应用于最大的NL2SQL数据集之一BIRD-SQL (Li et al. (2023a)),创建了一个包含超过2500个API的集合,这些API可以作为可调用工具或REST端点提供。我们将BIRD-SQL中的自然语言查询与基于此API池的真实API序列配对。我们利用这个集合研究了10个公开可用的LLMs的表现,并发现所有模型在确定正确的工具集(包括意图检测、嵌套函数调用的序列化和槽位填充任务)方面均存在困难。我们发现模型的任务完成率极低(根据数据集不同为 7−47%7-47 \%7−47%),当将模型作为与实时API环境交互的ReACT代理使用时,任务完成率仅略微提高至 50%50 \%50%。最佳任务完成率远低于有效通用工具调用代理所需的水平,表明当前最先进的工具调用LLMs仍有很大的改进空间。我们还进行了详细的消融研究,例如评估可用工具数量的影响以及工具和槽位名称模糊化的影响。我们将模型在原始SQL生成任务上的表现进行了比较,发现当前模型有时能够比API更好地利用SQL。我们释放了所有的数据和代码供进一步研究。
1 引言
基于大型语言模型(LLM)的“代理”系统旨在模仿人类的行为,如计划、推理和自我修正(Yao et al., 2023; Xu et al., 2023a)。这样的系统通常通过访问与实时环境交互以完成任务的工具进行部署,常常响应用户用自然语言表达的请求(Yoran et al., 2024; Drouin et al., 2024; Pan et al., 2024; Xie et al., 2024; Zheng et al., 2024)。
*同等贡献
工具调用能力在企业应用场景中尤为重要,因为API也是与后端系统(包括数据库)交互的首选方式。${ }^{1,2}$ 尽管LLMs在工具调用能力方面取得了快速进展,但不仅任务本身仍然具有挑战性(Yan et al., 2024),大多数现有的评估数据集和任务并未包括大规模的、由真实世界数据库支持的API(Yan et al., 2024; Zhong et al., 2025; Basu et al., 2025)。
为了促进企业工具调用领域的进一步研究,本文提出了一种方法,将现有的NL2SQL数据集(Yu et al., 2019; Li et al., 2023a; Liu et al., 2024c; Lei et al., 2025)转换为由原始数据库数据支持的一组API。此外,每个来自原始NL2SQL数据集的现有自然语言查询都与一个对应的真实API序列配对(基于创建的API)。
我们开发了三种将NL2SQL数据集转换为具有不同特征的API集合的方法。第一种集合称为'SLOT',它是一个具有一小组通用API(例如:filter、sort、aggregate)的集合,这些API通常需要多次调用并使用不同的槽位值来回答自然语言查询。第二种版本(称为'SEL')通过产生一组特定领域GET工具来增加API池的规模,每种工具都有独特的函数签名(参数值),并与通用目的API一起提供。因此,与SLOT相比,LLMs需要在SEL中选择和排序更大数量的API才能成功回答自然语言查询。最后,'REST'集合将数据表示为函数选择任务,其中大多数自然语言查询可以通过选择正确的函数并填充其参数来回答。SEL和SLOT集合呈现给LLMs的形式是Python函数,而REST集合则以路径参数填充的方式呈现为REST端点。
此外,我们所有的API都可以在测试时调用;因此,代理不仅可以规划API调用的序列,还可以与实时工具及其输出交互,尝试错误恢复,甚至在返回不正确或不完整的答案时修改计划的API序列。
贡献:总之,我们的论文做出了以下贡献:(i) 我们开发了一种新颖的数据生成流水线,允许将现有的NL2SQL任务重新用于LLM工具调用,(ii) 我们生成了三个不同版本的API - SLOT、SEL、REST,帮助我们研究工具调用的不同方面,(iii) 我们使用来自BIRD集合的11个公开可用的NL2SQL数据库(Li et al., 2023a)创建了超过2500个可调用工具,这些工具由真实数据库驱动返回响应。此外,我们的数据集包含人工制作的自然语言查询(来自源数据集)、真实API序列和最终答案。据我们所知,这是目前最大规模的公开可调用API集合,具有此类特征。(iv) 我们研究了10个LLMs以及3个ReACT代理(Yao et al., 2023)在我们结果集合上的表现,并发现模型的任务完成率极低( $7-47 \%$ - 根据数据集不同)当模型作为与实时API环境交互的ReACT代理使用时,任务完成率仅略微提高至 $50 \%$。
2 相关工作
强大LLMs的兴起导致了创建训练和评估工具调用的LLMs的数据生成流水线的发展。这些数据集通常包含API集合3{ }^{3}3,以及与真实API序列配对的查询(Qin et al., 2024; Basu et al., 2024; Pereira et al., 2024; Liu et al., 2024d)。虽然一些流水线重用了现有的数据集和查询(Peng et al., 2021; Basu et al., 2024),其他一些则利用LLMs在给定API集合的情况下生成现实的查询(Qin et al., 2024; Tang et al., 2023; Liu et al., 2024b; Pereira et al., 2024; Basu et al., 2025; Zhong et al., 2025)。
1{ }^{1}1 https://shorturl.at/bpsps
2{ }^{2}2 https://shorturl.at/daoEp
3{ }^{3}3 集合可以基于真实或合成的API
数据生成的方法也根据函数调用的性质专门化,例如,一些方法专注于涉及单次或多次调用单一函数的查询(Tang et al., 2023; Xu et al., 2023b),另一些方法则专注于需要调用多个函数,包括序列化和嵌套函数调用的查询(Liu et al., 2024b; Yan et al., 2024; Basu et al., 2025; Zhong et al., 2025)。为了评估工具调用LLMs的规划和任务解决能力,最近还开发了一些基准测试,这些测试提供了让代理与之交互的实时环境(Ruan et al., 2024; Yao et al., 2024; Cao et al., 2024; Xie et al., 2024; Zhou et al., 2024)。
-
{‘input’: ‘Among the schools with the SAT test takers of over 500, please list the schools that are magnet
-
schools or offer a magnet program.’,
‘dataset_name’: ‘california_schools’,
‘query’: 'SELECT T2.School FROM satscores AS T1 INNER JOIN schools AS T2 ON T1.cds = T2.CDSCode WHERE T2.Magnet =~ 1 AND T1.NumTstTakr > 500’,
‘gold_answer’: [‘Millikan High’, ‘Polytechnic High’, ‘Troy High’]}
列表1:原始NL2SQL实例
[{‘name’: ‘filter_data’,
‘arguments’: {‘data_source’: ‘data_0.csv’, ‘key_name’:
~ 'schools_Magnet’,
‘value’: 1.0, ‘condition’: ‘equal_to’},
‘label’: ‘data_1.csv’},
{‘name’: ‘filter_data’,
‘arguments’: {‘data_source’: ‘data_1.csv’, ‘key_name’:
~ 'satscores_NumTstTakr’,
‘value’: 500.0, ‘condition’: ‘greater_than’},
‘label’: ‘data_2.csv’},
‘name’: ‘retrieve_data’,
‘arguments’: {‘data_source’: ‘data_2.csv’, ‘key_name’:
~ 'schools_School’,
‘distinct’: False, ‘limit’: -1),‘label’: ’
~ retrieved_json’}]
列表2:SLOT-BIRD: API序列
{‘output’: [{
^2‘name’: ‘get_schools_magnet_status_v1_bird_california_schools_schools’,
‘description’: ‘Get schools with specific magnet status and number of test takers’,
‘arguments’: {
‘magnet_status’: 1,
‘num_test_takers’: 500 },
‘path’: ‘/v1/bird/california_schools/schools_magnet_status’}]}
列表4:REST-BIRD: API端点
图1:一个样本NL2SQL实例以及SLOT-BIRD、SEL-BIRD和REST-BIRD的真实API序列。函数、槽位和槽位值描述未显示以便于展示。
我们的工作扩展了这一丰富的研究成果——我们创建了一组由NL2SQL数据集中包含的数据库支持的API,并将每个来自原始数据集的自然语言查询与基于创建的API的真实API序列配对(见图1)。我们的方法基于数据库模式和数据库列描述自动生成符合OpenAI Functions格式4{ }^{4}4的函数定义(参见附录D.1中的示例)。尽管现有的一些工作中包含了使用专有来源提供的实时API创建的查询和API(Chen et al., 2024; Qin et al., 2024; Basu et al., 2025; Yan et al., 2024; Zhong et al., 2025),但这些API通常在测试时不可用于实时代理,或者只能作为提供商托管的付费服务提供(例如:RapidAPI Hub)5{ }^{5}5。相比之下,使用我们的方法生成的API可以本地托管为端点或Python工具供LLMs(和代理)使用。此外,由于我们的API构建方法依赖于来自原始NL2SQL数据集的可执行SQL查询,我们还能够提供一个确定性和经过验证的真实最终答案,这在现有的工具调用数据集中经常缺失(Qin et al., 2024; Liu et al., 2024b)。
最近,出现了评估LLMs在数据科学任务上能力的基准测试(Jing et al., 2025)。与我们的工作不同,这些基准测试要求模型通过生成结构化查询语言或代码来解决问题(Liu et al., 2024c; Li et al., 2024)。
据我们所知,我们的工作首次展示了如何通过重新利用NL2SQL数据集来提供由真实数据支持的一组可调用API,并重用原始数据集中可用的真实自然语言查询,从而研究LLM工具调用的能力。此外,这些查询通常是复杂的,往往需要在原始SQL数据库中进行多表连接,这转化为具有复杂序列化和嵌套模式的API序列。
3 数据生成
我们使用BIRD数据集(Li et al., 2023a)dev-set中的11个数据库创建了三个不同的API集合 - SLOT、SEL和REST。
BIRD集合:BIRD是最大的真实世界数据库集合之一,配有众包的自然语言查询及其SQL语句。查询包括那些需要比较、匹配、聚合以及计数的查询。此外,查询可能还需要基于领域知识、同义词、数值等进行推理。有关查询类型分布的更多细节,请参阅(Li et al., 2023a)。BIRD集合中的每个数据集包括一个SQL数据库、一组由人工标注者创建的自然语言问题以及相应的解答问题的SQL真值。
概述:我们的每个数据生成管道生成三个产物:(i) 可用API/工具的OpenAPI规范,(ii) 可调用的API实现,以及(iii) 来自源数据集的一组自然语言(NL)问题,这些问题与真实API调用序列配对(连同槽位值)。我们确保生成的API序列的结果与原始SQL查询返回的结果相匹配,并丢弃未能通过此测试的任何样本。
图1(顶部)显示了一个NL2SQL实例的例子。我们使用总共超过2500个API的工具宇宙生成了超过1000对自然语言查询和API序列。我们在附录的表3中总结了数据集统计信息。在评估过程中,平均每次数据点分别向SLOT-BIRD、SEL-BIRD和REST-BIRD呈现7、49和125个API选项。
3.1 SLOT-BIRD(槽位填充版本)
SLOT-BIRD数据集的构建是通过将通用SQL SELECT查询分解成其组成部分,并将每一部分映射到一个API(由Python函数实现)来完成的。
函数:SQL查询中的JOIN操作由初始化步骤共同完成,该步骤在评估中以编程方式进行处理。此步骤的输出是一个单一表格,为模型/代理访问API以回答查询提供起点。这将问题集中在计划一系列数据操作和数据访问操作上,这些操作由7个API支持:aggregate_data、filter_data、group_data_by、retrieve_data、select_unique_values、sort_data和transform_data。这些函数各自处理SQL查询的一部分:WHERE、ORDERBY、COUNT等。
槽位值:SLOT-BIRD API池中的函数有两种类型的参数(槽位)需要填写。第一种与数据库模式无关,控制要执行的数据操作,例如在WHERE子句中应用的条件类型,或是否按升序或降序排序。
第二种槽位定义了哪些列用于排序和过滤等操作,以及在数据操作完成后选择哪些列。这些槽位的可能选择是分类的,对应于初始化步骤提供的连接表中的列。BIRD数据库的表中每列都有简短的描述。当必须从这组名称中选择工具参数时,OpenAI格式的工具规范包括带有允许名称及其描述的枚举。理解这些名称和描述的内容是这个数据集对于工具调用模型或代理的主要挑战。
真实API序列:在图1的列表(2)中,filter_data(第1行,第5行)和retrieve_data(第9行)是两个函数。第一次调用filter_data,需要两个槽位值——第一个(第2行)是一个特定领域的槽位schools_Magnet,第二个(第3行)是一个“控制”操作,对该槽位执行“等于”的比较。接着是另一个filter_data工具调用,最后是一个retrieve_data调用。
请注意,除了函数名和参数外,还提供了一个“标签”,给出了工具调用输出的参考。这是必要的,以便在后续步骤中提供此输出,因为模型无法正确地从一次函数调用到另一次操作大对象数据。如第4行所示,我们使用文件传递负载,并将其用作输入函数参数中的引用。模型不负责读写文件,这由我们的评估框架自动处理。对于SLOT-BIRD,除retrieve_data外的所有工具都将数据操作的结果保存到csv文件中,并将指向该文件的路径作为字符串返回。
真实序列是通过对每个NL2SQL实例解析SQL查询,使用Sqlglot Python库6{ }^{6}6并转换结果语法树中的节点为SLOT-BIRD API池中的工具来程序化构建的。真实API调用序列的输出(经过轻微的格式调整)等同于在底层数据库上执行SQL查询的结果。这个黄金答案使得可以检查模型或代理的完成率,即它们返回导致正确答案的工具调用序列的比例。
局限性:原始数据集中665个SQL查询中有665个在SLOT-BIRD当前可用工具的范围内。我们的工作仅支持“Select” SQL查询,因此“Insert”、“Create”和“Delete”查询不被支持。尚未支持的附加查询功能包括:“Select”输出的算术运算、嵌套“Select”语句、“Case”语句和日期时间运算。
3.2 SEL-BIRD(选择版本)
SEL-BIRD版本是从SLOT-BIRD派生而来的,方法是绑定每个分类函数参数的所有可能值,创建具有较少输入参数的新函数。例如,在SLOT-BIRD API池中,‘filter_data’函数的’condition’参数可以取值’equal_to’(图1 - 列表(2):第3行)或’greater_than’(图1 - 列表(2):第7行)等。在SEL-BIRD API池中,这两个操作分别有单独的函数’select_data_equal_to’(图1 - 列表(3):第1行)和’select_data_greater_than’(图1 - 列表(3):第5行),它们不需要’condition’参数。这导致了更大的数据操作工具集。
额外的特定领域函数:数据检索的工具还有更大的扩展。SEL-BIRD API池中不是采用数据表中的列名(如SLOT-BIRD API池中那样),而是为每个可能的键(例如:图1 - 列表(3):第9行)包含一个独立的“get”函数。这导致了每个实例的工具选择集发生变化,因为初始化表中的列取决于关联SQL查询中的JOINs。
3.3 REST-BIRD 版本
API设计:虽然SLOT-BIRD数据集只有少量工具和多个槽位值,SEL-BIRD数据集增加了工具的数量。在REST-BIRD数据集的版本中
6{ }^{6}6 https://github.com/tobymao/sqlglot
我们将这一概念推向极致,为NL2SQL数据集中的每个实例关联一个单一的REST端点。我们选择将此API实现为REST端点,以便能够构造出具有有意义路径参数的高度特定的API端点。例如,在图1 - 列表(4)中,原始NL查询映射到一个单一的API端点(第2行)。此数据流水线设计为仅处理GET请求,排除POST和PUT操作,类似于另外两个流水线,它不支持BIRD中的“Create”、“Insert”和“Delete”查询。
数据生成:使用此版本回答用户问题通常涉及从大量特定于相关数据库的端点中选择一个输入。为了生成这些端点,我们使用Mistal-Large 7{ }^{7}7 创建对应于源数据集中特定用户问题的端点。我们的代理数据生成流水线有四个阶段(i)代码生成代理 - 合成FastAPI服务器代码,(ii)去重代理 - 整合同能等效端点(例如,getEmployees和getAllEmployees,(iii)API执行模块,(iv)验证和过滤代理:- 确保生成的REST端点和原始SQL返回相同的结果。我们在附录E.2中包含每个子组件的详细信息以及完整的数据生成过程及局限性。
流水线末端生成基于Python的FastAPI服务器代码,可以docker化并部署为微服务。此外,我们获得了一份数据点列表(每个领域),每个数据点都与真实API及其预期响应配对。我们生成的工具是REST API,密切模拟真实的企事业单位环境。
4 实验
我们使用我们的三个数据集来回答以下研究问题:(i) 模型是否认为自动生成的API集合具有挑战性?(ii) 与相同查询的基本SQL生成任务相比,性能如何?(iii) 提供的API工具集的大小如何影响模型的功能选择性能?(iv) 模型在多大程度上依赖于函数名称的语义信号来解决任务?(v) 当模型作为可以与实时API交互的ReACT代理使用时,性能会有多大的提升?
4.1 模型和提示格式
我们实验的模型包括:Llama 3.1-8B-Instruct和Llama 3.3-70binstruct(Grattafiori等,2024年),Qwen2.5-7b-instruct和Qwen2.5-72b-instruct(Yang等,2024年),DeepSeek-v3(Liu等,2024年a),GPT4o-2024-08-06(Hurst等,2024年),Granite 3.1-8b-instruct 8{ }^{8}8,以及Hammer-7b(Lin等,2024年)和Watt-8b 9{ }^{9}9,这些都是专门的函数调用模型。
对于SLOT和SEL的所有评估,我们使用了NESTful(Basu等,2025年)中使用的类似提示格式。GPT4o限制了工具名称的长度为64个字符 10{ }^{10}10,因此我们通过两种设置来进行实验:作为’tools’11和作为提示的一部分。我们在附录F中包含所有LLM提示模板。
我们的输入数据格式化,以确保引用工具输出的结构化和可靠机制,这是工具调用的关键方面,允许后续工具调用利用前一次执行的结果。这是通过为每个工具调用分配唯一的变量名来实现的,从而确保每个工具的输出可以唯一标识和引用。这种方法特别重要,防止了同一工具的不同参数实例出现在同一个工具调用序列中时的歧义(例如,
7{ }^{7}7 https://huggingface.co/mistralai/Mistral-Large-Instruct-2411
8{ }^{8}8 https://huggingface.co/ibm-granite/granite-3.1-8b-instruct
9{ }^{9}9 https://huggingface.co/watt-ai/watt-tool-8B
10{ }^{10}10 https://community.openai.com/t/function-call-description-max-length/529902
11{ }^{11}11 https://platform.openai.com/docs/assistants/tools
| 数据集 | 模型 | 意图 | 槽位 | 完成率 | SQL完成率 | ||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | 率 | 率 | ||
| SLOT-BIRD | Llama-3.1-8B-instruct | 0.58 | 0.09 | 0.16 | 0.61 | 0.62 | 0.61 | 0.00 | 0.35 |
| Llama-3.3-70b-instruct | 0.75 | 0.22 | 0.34 | 0.65 | 0.03 | 0.05 | 0.00 | 0.45 | |
| Granite-8b-instruct | 0.63 | 0.53 | 0.58 | 0.44 | 0.41 | 0.43 | 0.00 | 0.13 | |
| Watt-tool-8b | 0.43 | 0.20 | 0.27 | 0.51 | 0.52 | 0.52 | 0.01 | - | |
| Mixtral-8x22B-instruct | 0.78 | 0.63 | 0.70 | 0.63 | 0.62 | 0.62 | 0.02 | 0.29 | |
| Hammer2.1-7b | 0.88 | 0.35 | 0.50 | 0.67 | 0.67 | 0.67 | 0.03 | - | |
| Qwen2.5-7b-instruct | 0.65 | 0.67 | 0.66 | 0.63 | 0.63 | 0.63 | 0.03 | - | |
| GPT4o-2024-08-06(Prompt) | 0.31 | 0.15 | 0.20 | 0.71 | 0.71 | 0.71 | 0.03 | 0.39 | |
| GPT4o-2024-08-06(Tools) | 0.90 | 0.52 | 0.66 | 0.43 | 0.42 | 0.42 | 0.03 | - | |
| Qwen2.5-72b-instruct | 0.80 | 0.63 | 0.71 | 0.61 | 0.61 | 0.61 | 0.06 | 0.38 | |
| DeepSeek-V3 | 0.82 | 0.54 | 0.65 | 0.67 | 0.67 | 0.67 | 0.07 | 0.40 | |
| Llama-3.1-8B-Inst | 0.11 | 0.01 | 0.02 | 0.28 | 0.26 | 0.27 | 0.0 | 0.35 | |
| Llama-3-3-70b-Inst | 0.41 | 0.11 | 0.17 | 0.25 | 0.01 | 0.02 | 0.0 | 0.45 | |
| Granite-3.1-8b-Inst | 0.05 | 0.05 | 0.05 | 0.21 | 0.18 | 0.2 | 0.0 | 0.13 | |
| GPT4o-2024-08-06(Tools) | 0.47 | 0.30 | 0.36 | 0.62 | 0.57 | 0.59 | 0.0 | - | |
| Watt-tool-8b | 0.46 | 0.1 | 0.16 | 0.43 | 0.45 | 0.44 | 0.01 | - | |
| SEL-BIRD | Hammer2.1-7b | 0.29 | 0.16 | 0.21 | 0.47 | 0.4 | 0.43 | 0.03 | - |
| Qwen2.5-7b-Inst | 0.16 | 0.29 | 0.2 | 0.39 | 0.39 | 0.39 | 0.04 | - | |
| Mixtral-8x22B-Inst | 0.6 | 0.5 | 0.55 | 0.45 | 0.44 | 0.44 | 0.04 | 0.29 | |
| DeepSeek-V3 | 0.44 | 0.28 | 0.34 | 0.45 | 0.44 | 0.44 | 0.09 | 0.40 | |
| GPT4o-2024-08-06(Prompt) | 0.42 | 0.39 | 0.4 | 0.47 | 0.46 | 0.46 | 0.09 | 0.39 | |
| Qwen2.5-72b-Inst | 0.55 | 0.48 | 0.51 | 0.46 | 0.46 | 0.46 | 0.16 | 0.38 | |
| Hammer2.1-7b | 0.70 | 0.22 | 0.34 | 0.89 | 0.86 | 0.87 | 0.17 | - | |
| Mixtral-8x22B-instruct | 0.46 | 0.39 | 0.42 | 0.78 | 0.77 | 0.77 | 0.24 | 0.22 | |
| DeepSeek-V3 | 0.65 | 0.50 | 0.57 | 0.77 | 0.74 | 0.76 | 0.31 | 0.29 | |
| Llama-3.1-8B-instruct | 0.22 | 0.57 | 0.31 | 0.76 | 0.76 | 0.76 | 0.32 | 0.24 | |
| REST-BIRD | Granite-8b-instruct | 0.45 | 0.58 | 0.50 | 0.77 | 0.76 | 0.77 | 0.34 | 0.09 |
| Qwen2.5-7b-instruct | 0.53 | 0.52 | 0.53 | 0.80 | 0.80 | 0.80 | 0.37 | - | |
| GPT4o-2024-08-06(Prompt) | 0.82 | 0.54 | 0.65 | 0.79 | 0.79 | 0.79 | 0.38 | 0.29 | |
| Llama-3.3-70b-instruct | 0.57 | 0.67 | 0.61 | 0.76 | 0.76 | 0.76 | 0.42 | 0.35 | |
| Watt-tool-8b | 0.60 | 0.64 | 0.62 | 0.78 | 0.76 | 0.77 | 0.43 | - | |
| Qwen2.5-72b-instruct | 0.66 | 0.65 | 0.66 | 0.82 | 0.82 | 0.82 | 0.47 | 0.27 |
表1:跨数据集和模型的直接调用性能,显示了意图和槽位预测的精确度§、召回率®和F1分数,以及完成率。SQL Compl. Rate是指当支持SQL生成的模型直接用来查询数据库时的任务完成率。
并行工具调用)。通过每个工具调用的唯一标识符,我们促进了清晰高效的工具链式调用,确保正确解决工具之间的依赖关系。所有模型都需要遵循提示中包含的指定格式(附录F)。
输出解析:尽管指示使用JSON输出格式,模型通常未能做到这一点,导致指令对齐失败。为了处理模型返回的替代格式,我们按照附录H中描述的方法为每个模型创建了自定义输出解析器。
ReACT代理:将所有模型作为ReACT代理进行实验会因TAO循环变得非常昂贵,因此我们从实验中选择4个模型作为ReACT代理。我们选择了Mixtral-8x22B-instruct,这是一个令人惊讶地在我们的数据上表现不佳的大混合专家模型,并希望看到当它作为代理使用时性能的变化。此外,我们选择了LLama 3.3-70B-instruct、Qwen2.5-72b-instruct和GPT4o模型,因为它们相对广泛使用。我们配置我们的ReACT代理有一个固定的思考-行动-观察(TAO)循环预算为10步,即代理需要在10个TAO步骤内完成任务。
从表2可以看出,代理的任务完成率在SLOT-BIRD和SEL-BIRD数据集上不超过15%和17%,但在REST-BIRD数据集上性能更高(GPT4o达到50%的完成率)。此外,代理几乎从不在REST-BIRD数据集上耗尽TAO循环预算或重复相同的步骤,但在SLOT-BIRD和SEL-BIRD数据集上面临这两个问题。
4.3.1 工具调用中模糊化的影响
我们再次强调我们工作的重大贡献:生成大量由数据库支持的可调用API集合的能力。我们利用这一方面来调查模型在非信息性函数名称提供无洞察力的预期用途时,能在多大程度上依赖函数描述和其他元数据完成任务。为此,我们通过为前缀“func”分配一个唯一的整数来混淆每个API(Paul等人,2025年)。不出所料,混淆函数名称的模型在所有数据集上的性能都较低(附录图3),REST-BIRD数据集性能略有下降,但SLOT-BIRD和SEL-BIRD数据集上的任务完成率接近零,出现严重故障。
4.3.2 可用工具数量的影响
对于REST-BIRD数据集,由于我们集合中的每个查询都映射到单个意图,我们通过调整候选集中可用API的数量来进行实验。我们调整
宇宙(候选集大小)为完整原始集的10%、25%、50%和75%,同时确保始终存在真实意图。随着选择意图数量的减少,代理选择正确意图的能力确实提高了(附录图4)。有趣的是,即使在小规模的宇宙大小下,基于GPT4-o的最佳表现ReACT代理的任务完成率也只有71%。
5 结论
在本文中,我们演示了如何将现有的NL2SQL数据集转换为可调用API的集合,以评估LLMs。我们开发了三种不同风格的API,它们具有逐步增加的具体性(SLOT、SEL和REST),并展示了当前最先进的LLMs在正确回应用户请求方面的困难。我们的方法是可扩展的,很容易扩展以支持更多的数据集(和SQL查询模式)。随着越来越多的企业采用LLMs,模型暴露于这类环境中可能遇到的API模式是很重要的。我们的自动化数据生成方法不仅有助于评估模型,还可以用于创建训练数据——这是我们留给未来的工作方向。此外,我们希望将我们的方法扩展到更多的SQL查询操作,并支持创建与GraphQL兼容的API。
致谢
我们要感谢同事Ibrahim Abdelaziz和Saurabh Goyal的努力。
参考文献
Kinjal Basu, Ibrahim Abdelaziz, Subhajit Chaudhury, Soham Dan, Maxwell Crouse, Asim Munawar, Vernon Austel, Sadhana Kumaravel, Vinod Muthusamy, Pavan Kapanipathi, 和 Luis Lastras。2024。API-BLEND:培训和基准测试API LLMs的综合语料库。在计算语言学协会第62届年会论文集(第1卷:长篇论文),页码12859-12870,泰国曼谷。计算语言学协会。
Kinjal Basu, Ibrahim Abdelaziz, Kiran Kate, Mayank Agarwal, Maxwell Crouse, Yara Rizk, Kelsey Bradford, Asim Munawar, Sadhana Kumaravel, Saurabh Goyal, Xin Wang, Luis A. Lastras, 和 Pavan Kapanipathi。2025。Nestful:评估LLMs在API调用嵌套序列上的基准测试。预印本,arXiv:2409.03797。
Ruisheng Cao, Fangyu Lei, Haoyuan Wu, Jixuan Chen, Yeqiao Fu, Hongcheng Gao, Xinzhuang Xiong, Hanchong Zhang, Yuchen Mao, Wenjing Hu, Tianbao Xie, Hongshen Xu, Danyang Zhang, Sida Wang, Ruoxi Sun, Pengcheng Yin, Caiming Xiong, Ansong Ni, Qian Liu, Victor Zhong, Lu Chen, Kai Yu, 和 Tao Yu。2024。Spider2-v:多模态代理离自动化数据科学和工程工作流程有多远?预印本,arXiv:2407.10956。
Wei Chen, Zhiyuan Li, 和 Mingyuan Ma。2024。Octopus:软件API函数调用的设备上语言模型。预印本,arXiv:2404.01549。
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, 和 Alexandre Lacoste。2024。Workarena:网络代理在解决常识工作任务方面的能力如何?在机器学习国际会议第41届会议论文集,页码11642-11662。
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, 等人。2024。Llama 3系列模型。arXiv预印本arXiv:2407.21783。
Han Han, Tong Zhu, Xiang Zhang, Mengsong Wu, Hao Xiong, 和 Wenliang Chen。2024。Nestools:评估大型语言模型嵌套工具学习能力的数据集。arXiv预印本arXiv:2410.11805。
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, 等人。2024。Gpt-4o系统卡。arXiv预印本arXiv:2410.21276。
Liqiang Jing, Zhehui Huang, Xiaoyang Wang, Wenlin Yao, Wenhao Yu, Kaixin Ma, Hongming Zhang, Xinya Du, 和 Dong Yu。2025。DSBench:数据科学代理距离成为数据科学专家有多远?在第十三届学习表示国际会议上。
Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, Hongjin SU, ZHAOQING SUO, Hongcheng Gao, Wenjing Hu, Pengcheng Yin, Victor Zhong, Caiming Xiong, Ruoxi Sun, Qian Liu, Sida Wang, 和 Tao Yu。2025。Spider 2.0:评估语言模型在实际企业文本到SQL工作流中的表现。在第十三届学习表示国际会议上。
Jinyang Li, Binyuan Hui, GE QU, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin Chang, Fei Huang, Reynold Cheng, 和 Yongbin Li。2023a。LLM能否已经作为数据库接口?大规模数据库为基础的文本到SQL的BIg基准测试。第三十七届神经信息处理系统大会数据集和基准测试轨道。
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, 和 Yongbin Li。2023b。Api-bank:工具增强LLMs的全面基准测试。arXiv预印本arXiv:2304.08244。
Ziming Li, Qianbo Zang, David Ma, Jiawei Guo, Tuney Zheng, Minghao Liu, Xinyao Niu, Yue Wang, Jian Yang, Jiaheng Liu, Wanjun Zhong, Wangchunshu Zhou, Wenhao Huang, 和 Ge Zhang。2024。Autokaggle:自主数据科学竞赛的多智能体框架。预印本,arXiv:2410.20424。
Qiqiang Lin, Muning Wen, Qiuying Peng, Guanyu Nie, Junwei Liao, Jun Wang, Xiaoyun Mo, Jiamu Zhou, Cheng Cheng, Yin Zhao, 等人。2024。Hammer:通过函数屏蔽实现在设备上的稳健函数调用。arXiv预印本arXiv:2410.04587。
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, 等人。2024a。Deepseek-v3技术报告。arXiv预印本arXiv:2412.19437。
Weiwen Liu, Xu Huang, Xingshan Zeng, Xinlong Hao, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Zhengying Liu, Yuanqing Yu, 等人。2024b。Toolace:赢得LLM函数调用点。arXiv预印本arXiv:2409.00920。
Xinyu Liu, Shuyu Shen, Boyan Li, Peixian Ma, Runzhi Jiang, Yuxin Zhang, Ju Fan, Guoliang Li, Nan Tang, Yuyu Luo。2024c。关于使用大型语言模型的NL2SQL调查:我们在哪里,我们将去往何方?arXiv预印本arXiv:2408.05109。
Zuxin Liu, Thai Quoc Hoang, Jianguo Zhang, Ming Zhu, Tian Lan, Shirley Kokane, Juntao Tan, Weiran Yao, Zhiwei Liu, Yihao Feng, Rithesh R N, Liangwei Yang, Silvio Savarese, Juan Carlos Niebles, Huan Wang, Shelby Heinecke, 和 Caiming Xiong。2024d。APIGen:生成可验证和多样化函数调用数据集的自动化管道。在第三十八届神经信息处理系统大会数据集和基准测试轨道上。
Yichen Pan, Dehan Kong, Sida Zhou, Cheng Cui, Yifei Leng, Bing Jiang, Hangyu Liu, Yanyi Shang, Shuyan Zhou, Tongshuang Wu, 等人。2024。Webcanvas:在线环境中网络代理的基准测试。在ICML 2024的Agentic Markets Workshop上。
Indraneil Paul, Haoyi Yang, Goran Glavaš, Kristian Kersting, 和 Iryna Gurevych。2025。Obscuracoder:通过模糊编码实现高效代码LM预训练。在第十三届学习表示国际会议上。
Yun Peng, Shuqing Li, Wenwei Gu, Yichen Li, Wenxuan Wang, Cuiyun Gao, 和 Michael Lyu。2021。重新审视、基准测试和探索API推荐:我们离目标有多远?预印本,arXiv:2112.12653。
André Pereira, Bruno Lima, João Pascoal Faria。2024。Apitestgenie:通过生成式人工智能自动化API测试生成。arXiv预印本arXiv:2409.03838。
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, dahai li, Zhiyuan Liu, 和 Maosong Sun。2024。ToolLLM:促使大型语言模型掌握16000+真实世界API。在第十二届学习表示国际会议上。
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J Maddison, 和 Tatsunori Hashimoto。2024。识别lm代理的风险与lm仿真沙箱。在第十二届学习表示国际会议上。
Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, 和 Le Sun。2023。Toolalpaca:使用3000个模拟案例的语言模型工具学习。预印本,arXiv:2306.05301。
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, 和 Tao Yu。2024。OSWorld:在真实计算机环境中评估开放式任务的多模态代理。预印本,arXiv:2404.07972。
Binfeng Xu, Zhiyuan Peng, Bowen Lei, Subhabrata Mukherjee, Yuchen Liu, 和 Dongkuan Xu。2023a。Rewoo:解耦推理与观测以实现高效的增强语言模型。预印本,arXiv:2305.18323。
Qiantong Xu, Fenglu Hong, Bo Li, Changran Hu, Zhengyu Chen, 和 Jian Zhang。2023b。开源大型语言模型的工具操作能力。预印本,arXiv:2305.16504。
Fanjia Yan, Huanzhi Mao, Charlie Cheng-Jie Ji, Tianjun Zhang, Shishir G. Patil, Ion Stoica, 和 Joseph E. Gonzalez。2024。伯克利函数调用排行榜。https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html.
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, 等人。2024。Qwen2.5技术报告。arXiv预印本arXiv:2412.15115。
Shunyu Yao, Noah Shinn, Pedram Razavi, Karthik Narasimhan。2024。t-bench:真实领域中工具-代理-用户互动的基准测试。预印本,arXiv:2406.12045。
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, Yuan Cao。2023。React:语言模型中的推理与动作协同。在第十一届学习表示国际会议上。
Ori Yoran, Samuel Joseph Amouyal, Chaitanya Malaviya, Ben Bogin, Ofir Press, Jonathan Berant。2024。Assistantbench:网络代理能否解决现实且耗时的任务?预印本,arXiv:2407.15711。
Tao Yu, Rui Zhang, Michihiro Yasunaga, Yi Chern Tan, Xi Victoria Lin, Suyi Li, Heyang Er, Irene Li, Bo Pang, Tao Chen, Emily Ji, Shreya Dixit, David Proctor, Sungrok Shim, Jonathan Kraft, Vincent Zhang, Caiming Xiong, Richard Socher, Dragomir Radev。2019。SParC:上下文中的跨域语义解析。在计算语言学协会第57届年会论文集,Florence, Italy。Association for Computational Linguistics.
Boyuan Zheng, Boyu Gou, Scott Salisbury, Zheng Du, Huan Sun, Yu Su。2024。WebOlympus:活网站上网络代理的开放平台。EMNLP 2024系统演示文集,Miami, Florida, USA。Association for Computational Linguistics.
Lucen Zhong, Zhengxiao Du, Xiaohan Zhang, Haiyi Hu, Jie Tang。2025。Complexfuncbench:长上下文中多步骤受限函数调用的探索。预印本,arXiv:2501.10132。
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, Graham Neubig。2024。Webarena:建立自治代理的真实网络环境。预印本,arXiv:2307.13854。
A 概述
我们在B节中包含数据集统计信息,并在C.1节中研究混淆对ReACT代理的影响,以及C.2节中宇宙大小的影响。我们在D节中描述API生成管道生成的工件,并在E节中包含更多关于数据生成管道的详细信息。我们在F节中包含所有LLM提示模板,在G节中包含代理提示模板。最后,我们在H.1.1节中包含关于输出解析和如何进行错误分析的更多细节。
B 数据集统计信息
| API 基准测试 | #样本数 | #工具数 | 平均API序列长度 | 平均#槽位数 | 是否人工生成? | 是否真实世界? | 是否可调用? |
|---|---|---|---|---|---|---|---|
| NESTOOLS (Han et al., 2024) | 1000 | 3,034 | 3.04 | 2.24 | 否 | 否 | 是 |
| NextFul (Basu et al., 2025) | 1861 | 921 | 4.40 | 否 | 否 | 是 | |
| ToolBench (Qin et al., 2024) | 126486 | 16464 | - | 1.01 | 否 | 是 | 是* |
| API-Bank (Li et al., 2023b) | 485 | 73 | 1.53 | 1.97 | 否 | 否 | 是 |
| SLOT-BIRD | 665 | 7 | 2.7 | 3.29 | 是 | 是 | 是 |
| SEL-BIRD | 651 | 1256 | 2.9 | 0.05 | 是 | 是 | 是 |
| REST-BIRD | 1267 | 1250 | 1 | 1.38 | 是 | 是 | 是 |
表3:数据集统计信息。* 执行API需要RapidAPI密钥
C 附加实验
C.1 混淆的影响
C.1.1 数据构建
如正文所述,我们的目标是研究函数描述和函数名称的影响。为此,我们对API和槽位名称进行混淆,用诸如FUNC_0、FUNC_1… FUNC_N和ARG_1、ARG_2… ARG_N之类的占位符替换它们。下面是一个示例,显示了一个API名称和参数被混淆的情况,混淆后的工具名称和槽位将传递给代理。
“get_free_meal_count_ratio_v1_bird_california_schools_get”: {
“name”: “get_free_meal_count_ratio_v1_bird_california_schools_get”,
“description”: “获取特定县的免费餐食比例”,
“arguments”: {
“county_name”: {
“type”: “string”,
“description”: “县名”,
“title”: “县名”,
“name”: “ARG_1”
}
},
“path”: “/v1/bird/california_schools/free_meal_count_ratio”
}
“FUNC_0”: {
“name”: “FUNC_0”,
“description”: “获取特定县的免费餐食比例”,
“arguments”: {
“ARG_1”: {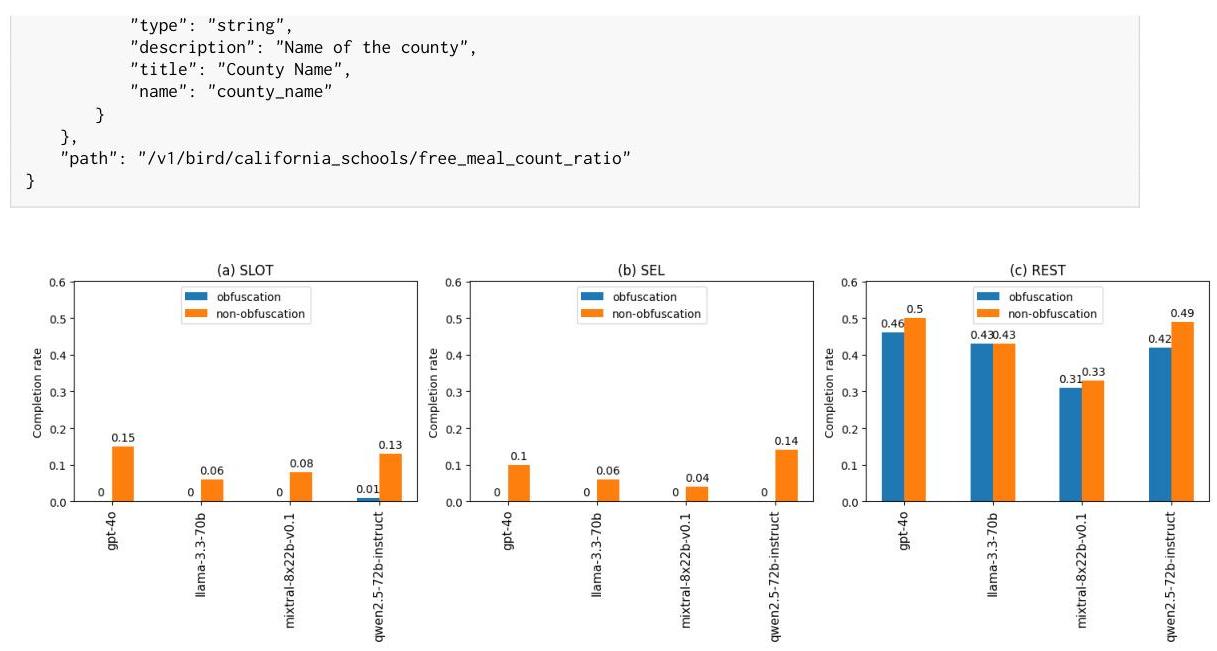
图3:混淆对完成率的影响
C.1.2 结果
我们再次强调我们工作的一个重要贡献:生成大量可调用API的能力。我们利用这一方面来研究模型在面对没有提供预期用途的非信息性函数名称时,能够在多大程度上依赖函数描述和其他元数据来完成任务。为此,我们通过为前缀"func"分配唯一的整数来混淆每个API(Paul et al., 2025)。毫不奇怪,使用混淆函数名称的模型在所有数据集上的表现都较低(附录图3),在REST-BIRD数据集上性能略有下降,而在SLOT-BIRD和SEL-BIRD数据集上出现严重失败。这一结果突出了使用特定领域词汇构造工具的重要性,以增强代理提高工具调用性能的能力。
| 数据集 | 10%\mathbf{1 0 \%}10% | 25%\mathbf{2 5 \%}25% | 50%\mathbf{5 0 \%}50% | 75%\mathbf{7 5 \%}75% | 100%\mathbf{1 0 0 \%}100% |
|---|---|---|---|---|---|
| 公式1 | 12 | 31 | 63 | 94 | 126 |
| 卡牌游戏 | 15 | 38 | 77 | 115 | 154 |
| 超级英雄 | 10 | 27 | 54 | 81 | 109 |
| 代码库社区 | 15 | 39 | 78 | 117 | 156 |
| 血栓形成预测 | 13 | 33 | 67 | 101 | 135 |
| 毒理学 | 9 | 23 | 47 | 71 | 95 |
| 金融学 | 9 | 22 | 45 | 68 | 91 |
| 加州学校 | 7 | 18 | 37 | 56 | 75 |
| 学生俱乐部 | 13 | 32 | 65 | 97 | 130 |
| 欧洲足球2 | 11 | 29 | 59 | 88 | 118 |
| 借记卡特化 | 6 | 15 | 30 | 45 | 61 |
表4:数据集间的工具分布百分比
C.2 可用工具数量的影响
如正文所述,我们还研究了提供给代理的工具数量变化的影响。REST数据集包含一个大的API宇宙,在某些情况下,超过100个工具传给了模型——使选择任务更具挑战性。
C.2.1 数据构建
为了研究工具集大小的影响,我们引入了一种尽力筛选机制。在总共有N个工具的情况下,我们将候选集减少到原始大小的10%,25%,50%或75%,以模拟不同的工具可用级别。
我们采用一种尽力筛选机制,总是包含真实工具,并补充N-1个额外的(随机)工具,得到一个包含N个工具的集合,然后将其提供给模型。
对于这次实验,我们使用了REACT代理和前面章节中描述的提示。
下表显示了数据集和分布列表。
C.2.2 结果
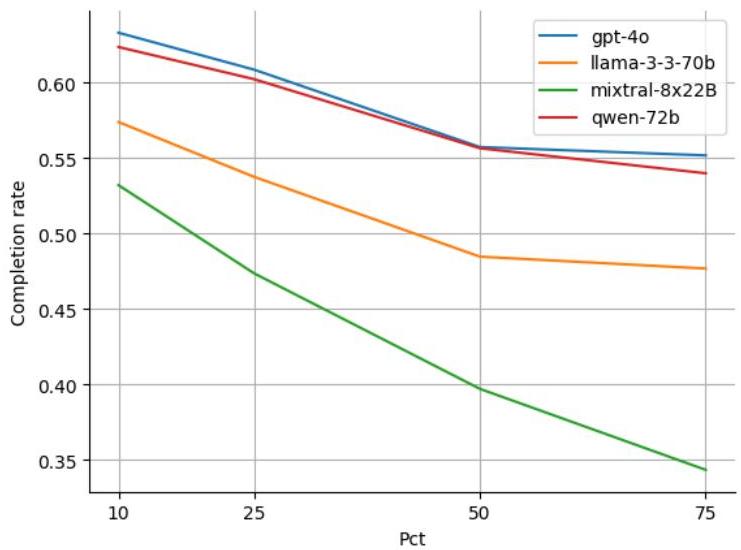
图4:可用工具数量(宇宙的百分比)对完成率的影响
我们再次强调我们工作的一个重要贡献:生成大量可调用API的能力。我们利用这一方面来研究模型在面对提供无信息的函数名称时,能够在多大程度上依赖函数描述和其他元数据来完成任务。为此,我们通过为前缀"func"分配一个唯一整数来混淆每个API(Paul等人,2025)。我们像之前一样使用三个ReACT代理进行评估,因为它们能够基于观察结果(反馈)探索环境。不出所料,使用混淆函数名称的模型在所有数据集上的表现都较低(附录图3),在REST-BIRD数据集上的性能略有下降,但在SLOT-BIRD和SEL-BIRD数据集上出现严重失败。这一结果突显了使用特定领域词汇构建工具的重要性,以增强代理提高工具调用性能的能力。
D 工件
每个数据生成管道生成以下三个工件:
- OpenAPI工具/API规格说明:这些规格说明包括调用工具所需的名称和参数,以及理解工具的目的和行为所需的语义内容描述。
-
- 可调用的API/函数实现:SLOT-BIRD和SEL-BIRD工具以Python函数的形式提供,可以以编程方式调用或绑定到函数调用LLM。REST-BIRD API以FastAPI服务器中的端点形式提供,并使用Docker容器化以便于部署。
-
- 评估集:自然语言、工具/API序列对组成的评估集可用于基准测试工具调用LLM或代理。
D.1 OpenAPI 函数/工具
OpenAPI工具/API规范包括意图(API)名称、描述以及输入和输出参数。对于每个参数,提供名称、描述和数据类型。还提供了每个规范中所需输入参数的子集。对于工具调用LLM或代理的实验,可以在模型提示中提供这些规范。模型必须理解这些规范才能成功调用工具。
以下是每个数据生成管道中的一些示例工具规范。
SLOT-BIRD:SLOT-BIRD数据集中的’sort_data’工具包含一个必需的’key_name’参数,该参数的值来自特定领域的枚举。可能的值和描述作为工具规范的一部分提供。
{
‘name’: ‘sort_data’,
‘description’: “根据所选键='key_name’的值对数据进行排序。如果输入数据是类列表,则返回排序后的列表。如果输入数据是表格,则返回按列’key_name’的值排序的表格。如果数据是分组表格,则按’key_name’的值对分组进行排序。”,
‘parameters’: {
‘properties’: {
‘data_source’: {
‘description’: ‘CSV格式的数据文件位置。’, ‘schema’: {‘type’: ‘string’}
},
‘key_name’: {
‘description’: “要排序的键名:\n* ‘member_member_id’ - 成员的唯一ID\n*‘member_first_name’ - 成员的名字\n*‘member_last_name’ - 成员的姓氏\n*‘member_email’ - 成员的电子邮件\n*‘member_position’ - 成员在俱乐部中的职位\n*‘member_t-shirt_size’ - 成员想要的T恤尺码\n*‘member_phone’ - 联系成员的最佳电话号码\n*‘member_zip’ - 成员家乡的邮政编码\n*‘member_link_to_major’ - 成员专业的唯一标识符。参考专业表\n*‘major_major_id’ - 每个专业的唯一标识符\n*‘major_major_name’ - 专业名称\n*‘major_department’ - 提供该专业的部门名称\n*‘major_college’ - 提供该专业的学院名称”,
‘schema’: {‘type’: ‘string’, ‘enum’: [‘member_member_id’, ‘member_first_name’, ‘member_last_name’, ‘member_email’, ‘member_position’, ‘member_t-shirt_size’, ‘member_phone’, ‘member_zip’, ‘member_link_to_major’, ‘major_major_id’, ‘major_major_name’, ‘major_department’, ‘major_college’]}
},
'ascending': {
'description': '是否按升序排序',
'schema': ('type': 'boolean'))),
'required': ['data_source', 'key_name', 'ascending'],
'type': 'object'),
'output_parameters': {
'properties': {
'output_0': {
'description': '包含按选定键排序数据的CSV文件的路径', 'type': 'string'
}
}
}
}
SEL-BIRD:SEL-BIRD数据集中的’sort_data_ascending’工具相当于SLOT-BIRD中的’sort_data’工具,'ascending’参数固定为True。还有一个对应的’sort_data_descending’工具。
{
‘name’: ‘sort_data_ascending’,
‘description’: “根据所选键='key_name’的值对数据进行排序。如果输入数据是类列表,则返回排序后的列表。如果输入数据是表格,则返回按列’key_name’的值排序的表格。如果数据是分组表格,则按’key_name’的值对分组进行排序。”,
‘parameters’: {
‘properties’: {
‘data_source’: {
‘description’: ‘CSV格式的数据文件位置。’, ‘schema’: (‘type’: ‘string’)
},
‘key_name’: {
‘description’: “要排序的键名:\n* ‘member_member_id’ - 成员的唯一ID\n* ‘member_first_name’ - 成员的名字\n* ‘member_last_name’ - 成员的姓氏\n* ‘member_email’ - 成员的电子邮件\n* ‘member_position’ - 成员在俱乐部中的职位\n* ‘member_t-shirt_size’ - 成员想要的T恤尺码\n* ‘member_phone’ - 联系成员的最佳电话\n* ‘member_zip’ - 成员家乡的邮政编码\n* ‘member_link_to_major’ - 成员专业的唯一标识符。参考Major表\n* ‘major_major_id’ - 每个专业的唯一标识符\n* ‘major_major_name’ - 专业名称\n* ‘major_department’ - 提供该专业的部门名称\n* ‘major_college’ - 提供该专业的学院名称”,
‘schema’: (‘type’: ‘string’, ‘enum’: [‘member_member_id’, ‘member_first_name’, ‘member_last_name’, ‘member_email’, ‘member_position’, ‘member_t_shirt_size’, ‘member_phone’, ‘member_zip’, ‘member_link_to_major’, ‘major_major_id’, ‘major_major_name’, ‘major_department’, ‘major_college’])
},
‘required’: [‘data_source’, ‘key_name’, ‘ascending’], ‘type’: ‘object’},
‘output_parameters’: {
‘properties’: {
‘output_0’: {‘description’: ‘包含按选定键排序数据的CSV文件路径’, ‘type’: ‘string’}
}
}
}
REST-BIRD:以下是使用REST-BIRD管道生成的工具示例。
“tools”: [
{
“name”: "get_free_meal_count_ratio_v1_bird_california_schools
",
“description”: “获取特定县的免费餐食比例”
",
“arguments”: {
“county_name”: {
“type”: “string”,
“description”: “县名”,
“title”: “县名”
}
},
“path”: “/v1/bird/california_schools/free_meal_count_ratio”
},
{
“name”: “get_free_meal_count_ratio_educational_option_v1_bird
“,
“description”: “获取特定教育选项类型的免费餐食比例”,
“arguments”: {
“educational_option_type”: {
“type”: “string”,
“description”: “教育选项类型”,
“title”: “教育选项类型”
}
},
“path”: “/v1/bird/california_schools/
free_meal_count_ratio_educational_option”
},
{
“name”: "
get_zip_codes_v1_bird_california_schools_zip_codes_get”,
“description”: “获取特定地区名称和特许学校状态的邮政编码”,
“arguments”: {
“district_name”: {
“type”: “string”,
“description”: “地区的名称”,
“title”: “地区名称”
},
“charter_school”: {
“type”: “integer”,
“description”: “特许学校的状况(1表示是,0表示否)”,
“title”: “特许学校”
}
},
“path”: “/v1/bird/california_schools/zip_codes”
},
{
“name”: "
get_mail_street_highest_frpm_v1_bird_california_schools”,
“description”: “获取最高FRPM计数(K-12)的邮件街道”,
“arguments”: {},
“path”: “/v1/bird/california_schools/mail_street_highest_frpm”
}
D.2 评估数据集
我们的数据处理管道还将为我们提供一个评估集(JSON格式)或测试集将包含以下内容:
- 话语:自然语言话语(来自BIRD-SQL数据集)
-
- SQL查询:来自BIRD-SQL数据集的SQL查询
-
- 黄金答案:通过在BIRD SQL数据库上执行SQL查询获得的真实答案
-
- 输出:包含API(以OpenAI函数格式)的字典,这些API将导致黄金答案
-
- 执行API后的输出:执行API后的输出将具有与黄金答案相同的数据,但可能格式不同
在我们的评估中,我们使用通过我们的数据生成管道生成的评估集对各种模型进行基准测试。
有关评估集的更多详细信息,请参见图1。
- 执行API后的输出:执行API后的输出将具有与黄金答案相同的数据,但可能格式不同
D.3 可调用的API(Python代码或微服务)
除了上述组件,我们的数据生成管道还会生成可调用的代码。
从REST-BIRD管道,我们获得了FastAPI服务器,它被容器化并部署为微服务。
从SEQ-BIRD和SEL-BIRD管道,我们收到一套Python工具。这些工具可以通过安装随附的invocable-api代码库(随本提交一起提供)作为Python库调用。
E 数据生成管道
BIRD SQL数据集提供了丰富结构化信息源,可用于构建高质量的以API为中心的数据集。具体来说,它包括以下组件:
- 自然语言输入语句(问题)
-
- 对应的SELECT-SQL查询,这些查询可以产生正确的答案
-
- 真实世界数据库
-
- 详细的数据库模式,包括表名、列名和描述
-
- 真实答案(通过执行相关的SQL查询可以获得)
我们从BIRD SQL数据集中获得了以下信息
- 真实答案(通过执行相关的SQL查询可以获得)
{
“query”: “SELECT ‘Free Meal Count (K-12)’ / ‘Enrollment (K-12)’ FROM From WHERE ‘County Name’ = ‘Alameda’”
“-- ORDER BY (CAST(‘Free Meal Count (K-12)’ AS REAL) / ‘Enrollment (K-12)’) DESC LIMIT 1”,
“input”: “加州阿勒米达县学校中K-12学生的最高免费餐食比例是多少?”,
“dataset_name”: “california_schools”,
“gold_answer”: [
[
1.0
]
1,
}
在这项工作中,我们使用开发集,其中包括总共11个领域。BIRD-SQL数据集仅包含SELECT语句,不包括UPDATE或INSERT查询。因此,我们的工具主要作为数据检索器,有效地充当getter。
- 加州学校
-
- 卡牌游戏
-
- 代码库社区
-
- 借记卡专业化
-
- 欧洲足球
-
- 金融
-
- 一级方程式赛车
-
- 学生俱乐部
-
- 超级英雄
-
- 血栓形成预测
-
- 毒理学
E.1 SLOT-BIRD和SEL-BIRD数据生成管道
SLOT-BIRD和SEL-BIRD数据集是通过首先编写一组Python工具来构建的,这些工具可以执行SQL SELECT查询各部分的相同数据操作。然后使用Sqlglot Python库解析每个SQL查询为抽象语法树。数据生成管道按以下顺序处理解析后的查询组件:
- JOIN语句
-
- WHERE语句
-
- GROUPBY语句
-
- ORDERBY语句
-
- SELECT语句
-
- AGGREGATE语句
JOIN语句 这些语句被合并为一个步骤,由’initialize_active_data’函数执行。这个函数未包含在提供给模型和代理的工具规范中,因为其所需参数的复杂性。相反,它在实验脚本中作为设置或数据处理步骤被调用。此函数的输出是其余工具调用将操作的单个表。它被保存到临时csv文件中,该文件在模型提示中被指向。
WHERE语句 当前只要求AND连接,就支持任意数量的WHERE语句。WHERE语句可以执行的条件是:‘equal_to’、‘not_equal_to’、‘greater_than’、‘less_than’、‘greater_than_equal_to’、‘less_than_equal_to’、‘contains’和’like’。BETWEEN条件和OR连接的子句将在未来版本中包含。
GROUPBY语句 支持GROUPBY语句,并带有一个参数控制聚合类型。
SELECT语句 在SLOT-BIRD和SEL-BIRD中,SELECT语句的处理方式不同。在SLOT-BIRD中,'retrieve_data’函数执行此任务,返回提供表的部分列。此函数还包括可选参数:'distinct’控制是否只返回列中的不同元素列表,'limit’截断返回结果。
在SEL-BIRD中,每列用于创建唯一的’get_table_and_column_name’函数,该函数仅返回该列。因此在此版本中,选择N列需要N次工具调用而不是一次。没有提供distinct和limit参数,而是由必须应用于’get’输出的单独函数处理。
- AGGREGATE语句
一个典型的例子如下:
-
{‘query’: "SELECT T2.major_name FROM member AS T1 INNER JOIN major AS T2 ON T1.link_to_major = T2.major_id WHERE
-
T1.first_name = ‘Angela’ AND T1.last_name = ‘Sanders’",
‘input’: “安吉拉·桑德斯的专业是什么?”,
‘gold_answer’: ‘Business’,
‘output’: [{‘name’: ‘filter_data’,
‘arguments’: {‘data_source’: ‘startingtablevarstarting_table_varstartingtablevar’,
‘key_name’: ‘member_first_name’,
‘value’: ‘Angela’,
‘condition’: ‘equal_to’),
‘label’: ‘FILTERED_DF_0’),
{‘name’: ‘filter_data’,
‘arguments’: {‘data_source’: ‘FILTEREDDF0FILTERED_DF_0FILTEREDDF0’,
‘key_name’: ‘member_last_name’,
‘value’: ‘Sanders’,
‘condition’: ‘equal_to’),
‘label’: ‘FILTERED_DF_1’),
{‘name’: ‘retrieve_data’,
‘arguments’: {‘data_source’: ‘FILTEREDDF1FILTERED_DF_1FILTEREDDF1’,
‘key_name’: ‘major_major_name’,
‘distinct’: False,
‘limit’: -1},
‘label’: ‘SELECT_COL_0’}],
{‘dataset_name’: ‘student_club’,
‘sample_id’: 0,
‘initialization_step’: {‘name’: ‘initialize_active_data’,
‘arguments’: {‘condition_sequence’: [[‘T1.link_to_major’,
‘T2.major_id’,
‘INNER’]},
‘alias_to_table_dict’: {‘T1’: {‘original_table_name’: ‘member’,
‘modified_table_name’: ‘member’},
‘T2’: {‘original_table_name’: ‘major’, ‘modified_table_name’: ‘major’}},
‘database_path’: ‘/home/belder/invocable-api-hub/invocable_api_hub/driver/…/…/db/cache/student_club.sqlite’},
~}
‘label’: ‘starting_table_var’]}
以下示例异常困难,因为为了正确选择序列中的初始工具,模型不仅需要理解’Player_Attributes_date’列的内容,还需要检查内容以确定需要从每个单元格中的字符串值中选择子字符串。从提供的描述中看不出来:
{‘key_name’: ‘Player_Attributes_date’, ‘description’
参考论文:https://arxiv.org/pdf/2506.11266

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 19
19 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)