如何激发出大模型的推理能力?详解两种思维链(CoT)技术
今天的大模型分为推理模型和非推理模型,且推理模型的回答质量往往好于非推理模型。我们来回顾一下大模型的推理能力到底是怎么激发出来的?今天的大模型能力非常强都具备推理能力,我们得回到gpt3时代(2020年),大模型还没有太多推理能力的时代。
今天的大模型分为推理模型和非推理模型,且推理模型的回答质量往往好于非推理模型。我们来回顾一下大模型的推理能力到底是怎么激发出来的?
今天的大模型能力非常强都具备推理能力,我们得回到gpt3时代(2020年),大模型还没有太多推理能力的时代。
GPT3的问题
结合少样本示例的GPT3虽已展示强大能力,但对于复杂问题还力不从心,如图1左边示例所示:
在让gpt3回答问题前,先给一个回答示例:问:罗杰又5个网站…A:答案是11.(为什么要在输入中给出回答示例?因为这样的话gpt3的性能会大幅提高。示例也可以去掉只是性能会降低)
再给出自己的问题:食堂有23个苹果…他们现在有多少
最后gpt3回答27,答案错误。
这样的表现和GPT3的强大文本理解能力是不匹配的,GPT3像一个强大的文本生成器却不具备逻辑思考能力,问题出在哪里,如何激发出它应该具备的推理能力?
思维链提示(CoT)
也许GPT3只是还还不理解提问者的问题,它可能认为这是一个文本续写问题而不是数学推理问题。如果能提示清楚让它知道这是个数学推理问题,需要推理解决,相信GPT3就能回答对。

如何激发出大模型的推理能力?思维链提示CoT(《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》 ) 就回答了这一问题,而且解决方法很简单:只需在模型输入中明确加入思维链(推理过程)提示,如图1右边所示,相比原始输入,在给出答案示例前增加了推理过程:“A:罗杰一开始有5个球…6个网球…答案是11”,而不是仅仅是只给出“答案是11”这个答案。
这个加入推理过程提示的方法就是原始CoT的核心了,虽然简单却实实在在可以提高大模型的性能。
研究者在数学,常识和符号推理方面做了实验,以此证明CoT的有效性。
研究者使用如下提示词,再不同数据集上进行实验:

数学推理

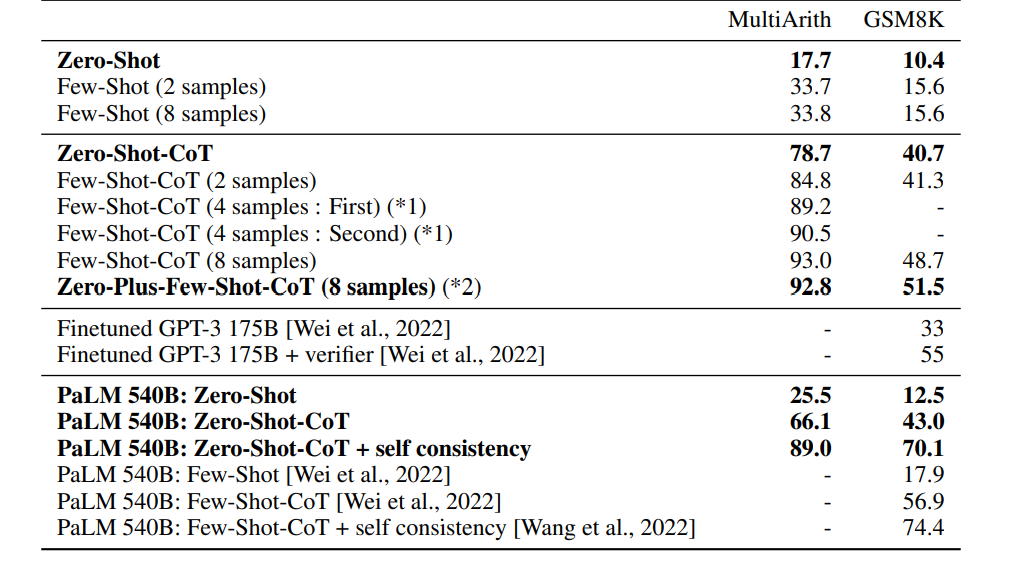
在GSM8K数据集上,CoT结合参数最大的GPT3和PALM后的提升非常大,对于另外两个数据集由于数据集较简单/不太适用多步推理,提升不明显。
常识推理

CoT在常识推理数据集总体提升较为明显(10%以上)。
符号推理

CoT在符号推理数据集总体提升非常明显。
总之,大模型结合思维链提示后在推理任务上取得了明显进步,也就不会像开头一样把简单推理任务做错了。
零样本思维链提示
少样本思维链提示虽在推理问题上性能优秀,但需提供少样本示例,实际使用有些不便,毕竟我们只是想输入问题让模型回答而不是输入问题+示例再让模型回答。
零样本思维链《Large Language Models are Zero-Shot Reasoners》的提出让提示更加简洁,不需要示例,只需在输入问题后加 “Let’s think step by step”,如下图d所示。

零样本思维链(Zero-shot-Cot)将回答过程拆解成两步:
- 推理提取,如下图左侧所示,通过 “Let’s think step by step”让大模型输出推理过程。
- 答案提取,如下图又侧所示,通过结合上步的推理过程,让大模型生成答案。

这一过程也和如今的推理模型(openai o系列,deepseek r1)的两阶段回答一致,先输出思考过程再输出答案。虽然略显冗余,但这样能避免思考/推理过程与答案的相互干扰。
零样本思维链(Zero-shot-Cot)大幅提高了GPT3和其他早期大模型(PaLM)在推理任务上的表现:

后续
CoT技术开启了提高大模型推理能力的路线,它为训练原生推理模型指明了方向。研究者们开始利用CoT生成海量的"问题+推理过程"数据,并用这些"高质量教材"去微调模型。这正是今天我们看到的推理模型(如O系列)能力强大的核心秘密之一: 它们已经系统性地学习了如何思考而无需再去提示它们。
启示
- 前文所述的两种CoT技术都比较简单(只是在问题上增加提示词即可不需要动模型),却也在当时效果显著,这也启发我们大模型时代机遇万千,也许只需一个好的提示词,就能激发出大模型意想不到的潜能。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)