AI大模型介绍-BERT
BERT是由Google于2018年推出的基于Transformer架构的预训练语言模型。其核心创新在于双向编码机制,通过掩码语言模型(MLM)和下一句预测(NSP)任务进行预训练,使模型能同时利用上下文信息。BERT提供Base(12层)和Large(24层)两种版本,广泛应用于文本分类、命名实体识别、问答系统等NLP任务。模型输入包含Token、Position和Segment三种Embedd
BERT(Bidirectional Encoder Representations from Transformers)全称是“双向编码器表征法”或简单地称为“双向变换器模型”,是一种基于Transformer架构的预训练语言模型,由Google在2018年推出,代码已开源。BERT在自然语言处理(NLP)领域具有广泛的应用和出色的性能,为多种语言理解任务提供了强大的预训练模型基础。
BERT采用了双向Transformer编码器结构,这意味着在预训练阶段,模型能够同时利用输入序列的左侧和右侧上下文信息,从而更准确地理解语言的含义。
BERT在自然语言处理领域具有广泛的应用,包括:
- 文本分类:如情感分析、垃圾邮件检测、主题分类等。
- 命名实体识别:从文本中提取出具有特定意义的实体,如人名、地名、组织名等。
- 关系提取:识别文本中实体之间的关系,如从新闻文章中提取出公司和CEO之间的关系。
- 问答系统:包括阅读理解和问题回答任务,能够根据问题和文本段落提供相关的答案。
- 语义相似度计算:计算文本之间的语义相似度,帮助理解文本之间的关联和差异。
2、模型介绍
2.1、模型架构
BERT是一种基于Transformer架构的模型,且只包含Encoder模块,由多个Encoder block模块堆叠而成。其架构如下图所示。
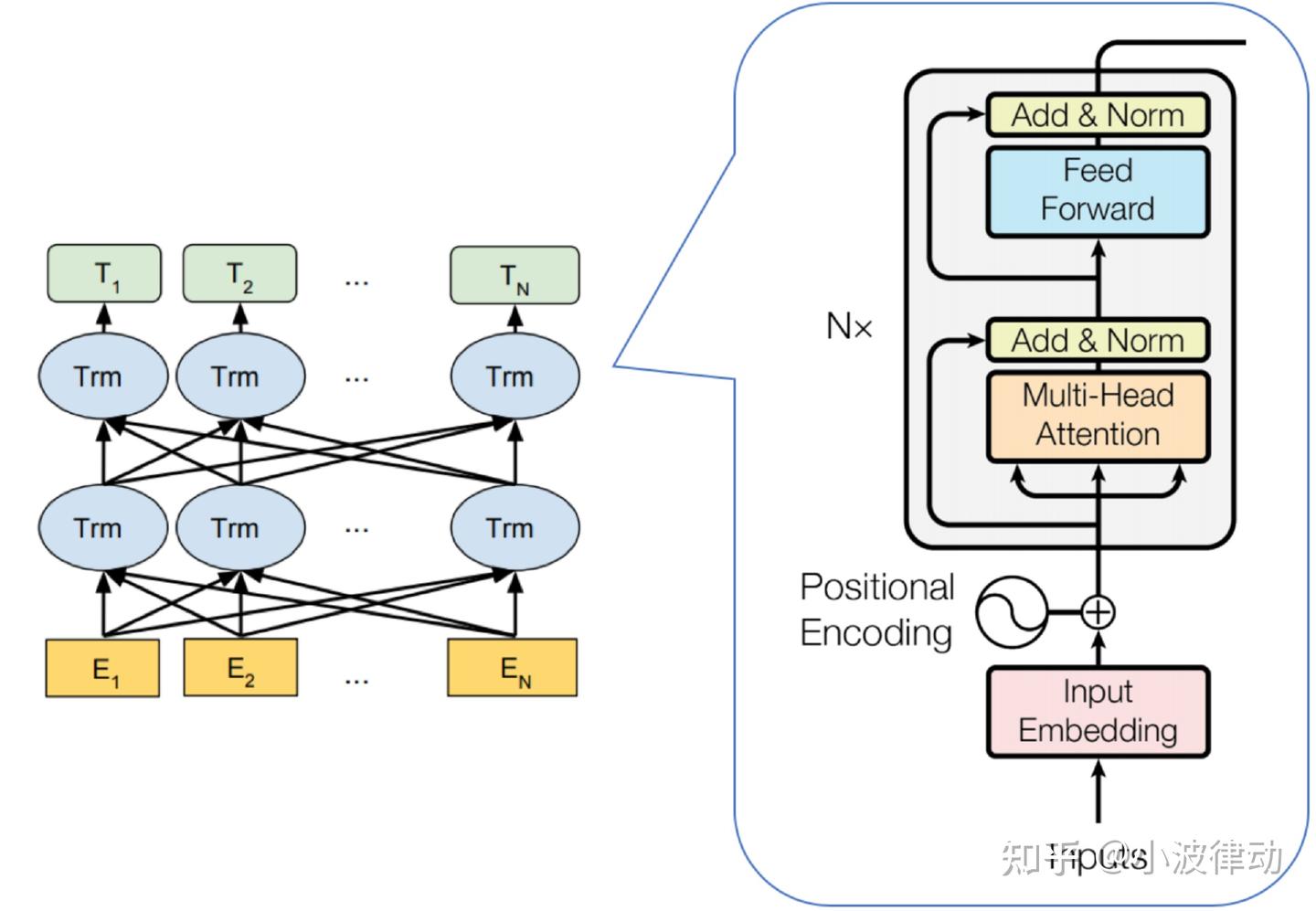
从上图左侧,我们可以看到BERT包含三种模块:
- 最底层⻩⾊标记的Embedding模块。
- 中间层蓝⾊标记的Transformer模块。
- 最上层绿⾊标记的预微调模块。
上图右侧是Encoder block的内部模块图。图中蓝色模块被画成了两层,这表示BERT模型中堆叠了多个Transformer编码器块。每个编码器块都包含自注意力机制(Self-Attention Mechanism)和前馈神经网络(Feed-Forward Neural Network),以及层归一化(Layer Normalization)和残差连接(Residual Connections)。
BERT模型有两种规模:Base版和Large版。其中,Base版包含12层Transformer编码器,隐藏层大小为768,自注意力头数为12,总参数量约为110M;Large版则包含24层Transformer编码器,隐藏层大小为1024,自注意力头数为16,总参数量约为340M。
BASE版:L = 12,H = 768,A = 12,总参数量为 1.1 亿
LARGE版:L = 24,H = 1024,A = 16,总参数量为 3.4 亿2.2、单向编码与双向编码
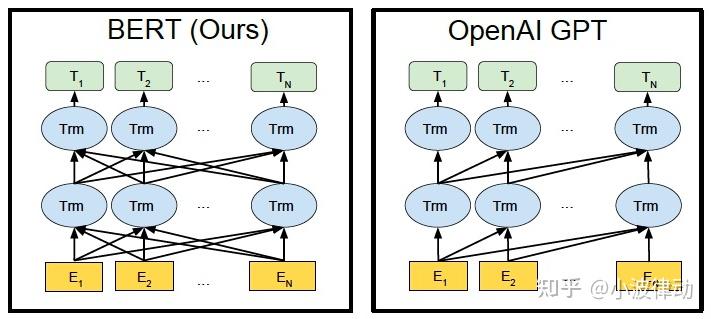
单向编码
单向编码指的是在编码过程中,模型只能利用到当前位置之前的文本信息(或只能利用到当前位置之后的文本信息,但这种情况较少见),而无法同时利用到当前位置前后的文本信息。这种编码方式使得模型在处理文本时具有一种“前瞻性”或“回顾性”,但缺乏全局的上下文理解能力。
GPT是一个典型的采用单向编码的预训练语言模型。GPT使用Transformer的解码器部分作为其主要结构,通过自回归的方式进行训练,即模型在生成下一个词时只能看到之前的词,无法看到之后的词。
双向编码
双向编码则允许模型在编码过程中同时利用到当前位置前后的文本信息,从而能够更全面地理解文本的上下文。这种编码方式使得模型在处理文本时具有更强的语义理解能力和更丰富的信息来源。
BERT是一个典型的采用双向编码的预训练语言模型。BERT通过掩码语言模型(MLM)的方式进行训练,即随机掩盖文本中的部分词汇,然后让模型预测这些被掩盖的词汇。
举个例子:考虑一个文本序列“今天天气很好,我们决定去公园散步。”
- 在单向编码中,每个词或标记的编码仅依赖于其之前的词或标记。因此,在编码“决定”这个词时,模型只会考虑“今天”、“天气”、“很好”和“我们”这些在它之前的词。
- 在双向编码中,每个词或标记的编码都会同时考虑其前后的词或标记。因此,在编码“决定”这个词时,模型会同时考虑“今天”、“天气”、“很好”以及之后的“去公园散步”等词,从而更全面地理解整个句子的语义。
2.3、Embedding模块
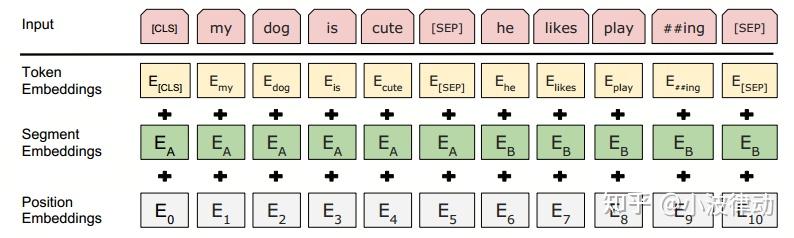
BERT的输入Embedding模块由三部分组成:
- Token Embeddings:输入文本中的每个单词或字符转换为一个固定维度的向量。Base版为768维,Large版为1024维。
- Position Embeddings:单词或字符在句子中的位置信息。BERT中的位置嵌入是可学习的,它会随着模型的训练而更新,非固定的三角函数。
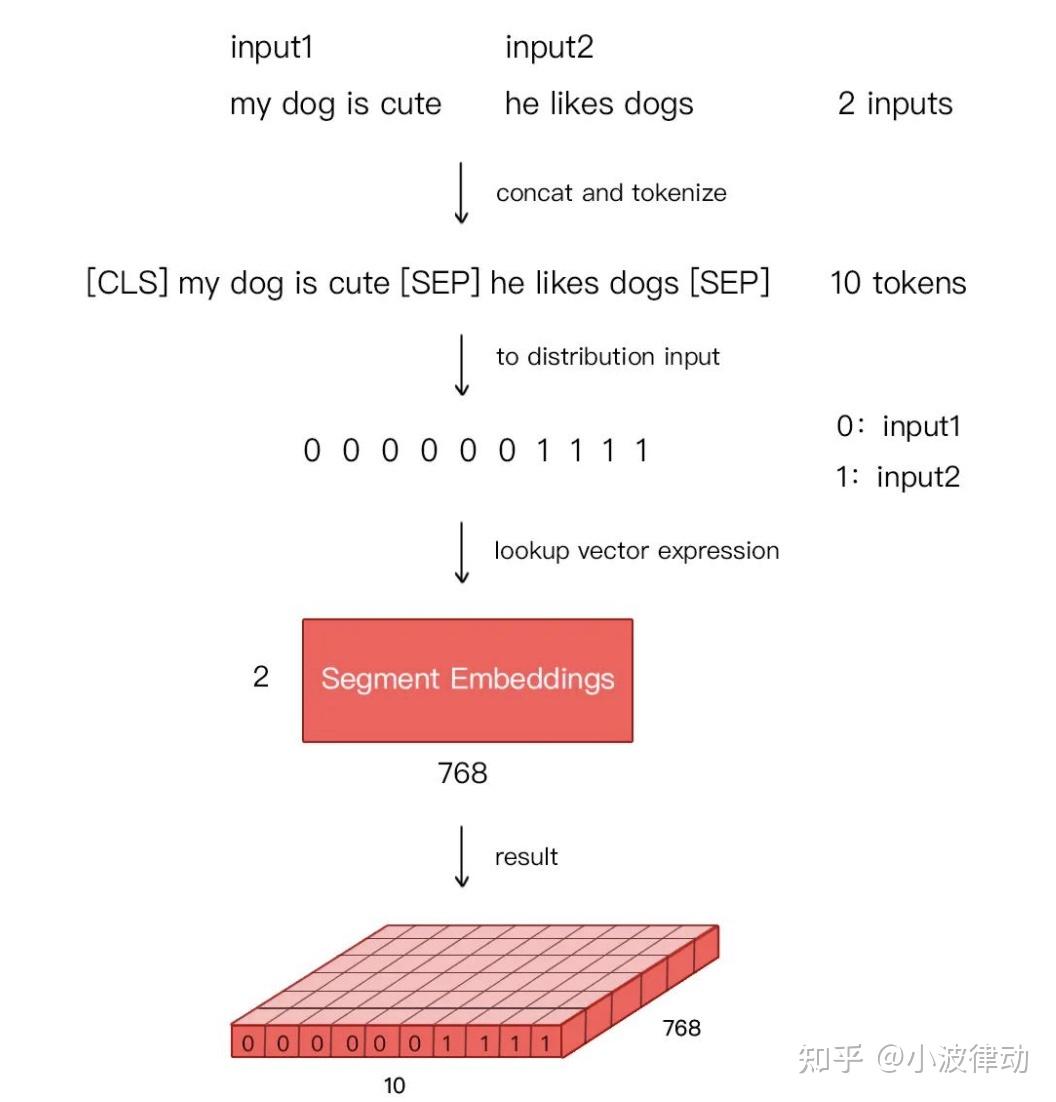
- Segment Embeddings:用于区分同一输入序列中不同句子的来源。对于多句输入,BERT会为每个句子分配一个不同的段编号,来区分它们。Segment Embeddings的取值通常是0和1,如果输入包含两个句子,通常第一个句子的token会被赋予全0的向量,第二个句子的token会被赋予全1的向量。下图是一个示例。
2.4、预训练
BERT的预训练过程主要包括两个阶段:Masked Language Model(MLM)和Next Sentence Prediction(NSP)。
1、Masked Language Model (MLM)
Masked Language Model,即遮蔽语言模型,是BERT预训练的一个重要部分。在这一阶段,模型的任务是预测输入句子中被随机遮蔽(masked)掉的部分单词。
- 输入文本处理:首先,对于输入的句子,随机选择句子中15%的单词进行遮蔽。对于每个被选中的单词,有80%的概率直接用[MASK]标记替换,10%的概率用随机的一个单词替换(这有助于模型学习理解上下文的重要性,而不仅仅是依赖于[MASK]标记),剩下的10%则保持不变(这有助于模型在微调阶段更好地处理未遮蔽的单词)。
- 模型预测:模型的目标是根据上下文预测这些被遮蔽单词的原始值。这种机制促使BERT能够深入理解文本中的语义关系。
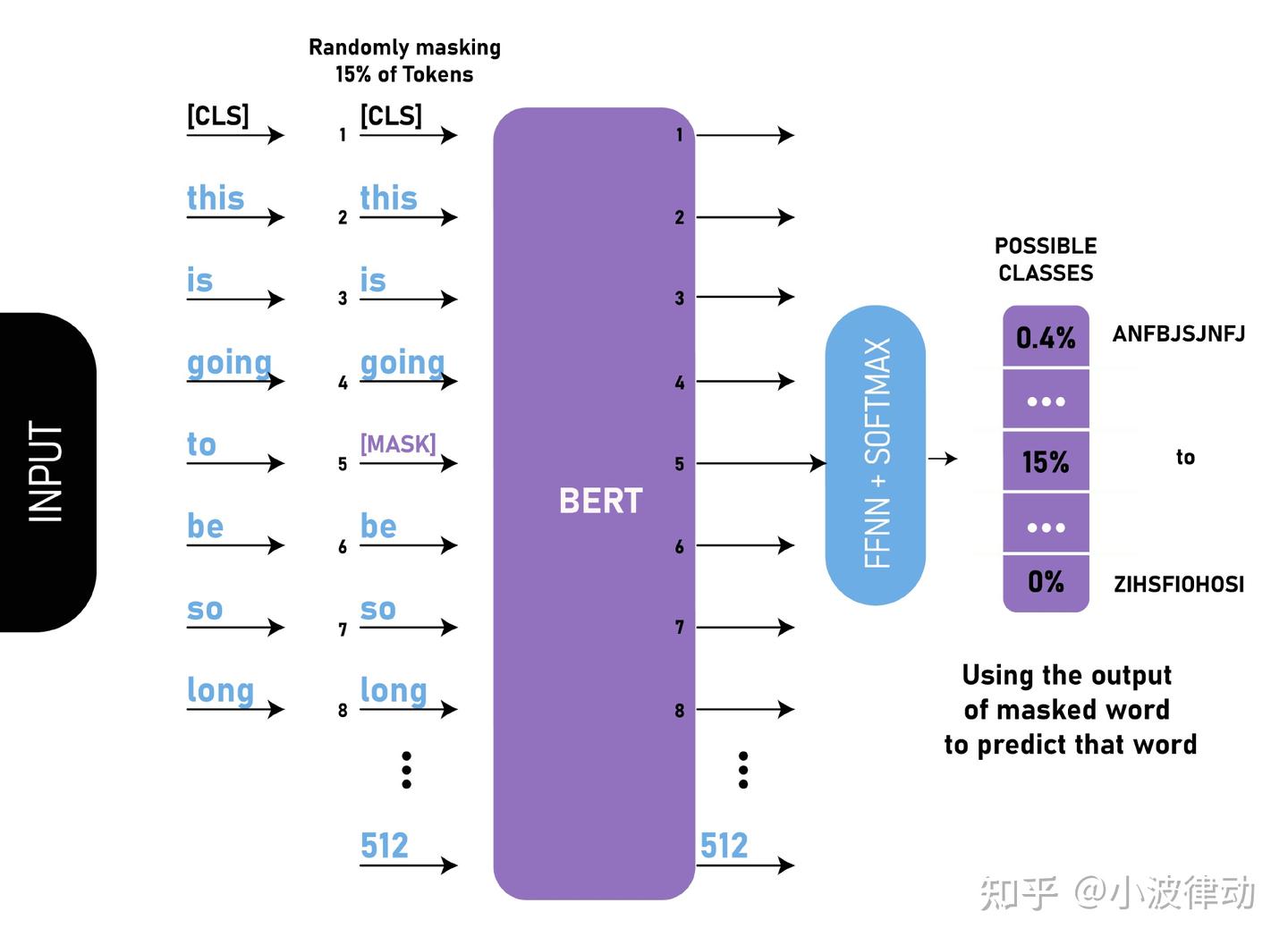
我们来看一个例子,假设有一句话:my dog is hairy
1)80%的时候是[MASK]。如,my dog is hairy——>my dog is [MASK]
2)10%的时候是随机的其他token。如,my dog is hairy——>my dog is apple
3)10%的时候是原来的token。如,my dog is hairy——>my dog is hairy
2、Next Sentence Prediction (NSP)
Next Sentence Prediction,即下一句预测,是BERT预训练的另一个重要部分,旨在提高模型对句子间关系的理解能力。
- 句子对生成:在预训练时,模型不仅接收单个句子作为输入,还接收句子对。这些句子对可能是连续的(即真实的下一句),也可能是随机组合的(即非连续的)。
- 模型预测:对于每个句子对,模型需要预测第二个句子是否是第一个句子的真实下一句。这是一个简单的二分类任务,输出是一个[0, 1]范围内的值,表示第二个句子是第一个句子真实下一句的概率。
注:在BERT的后续版本中,Next Sentence Prediction(NSP)任务被废弃了。因为研究人员发现这个任务对下游任务的性能提升有限,因此在BERT的一些后续变体中被弃用了。
2.5、微调
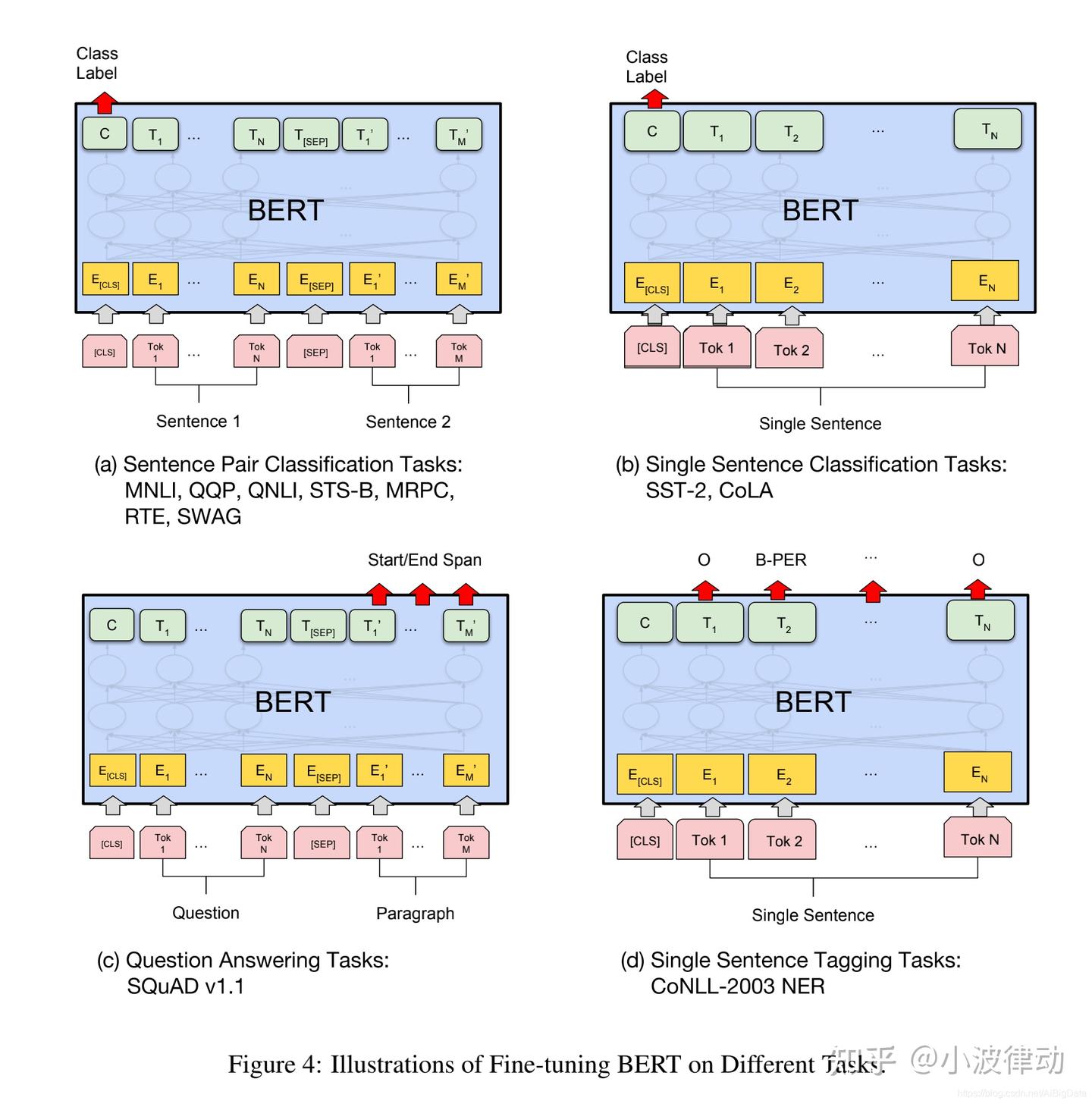
根据自然语言处理(NLP)下游任务输入和输出形式的不同,微调任务可以分为四类,分别是句对分类、单句分类、文本问答和单句标注,如下图中abcd所示。
1、句对分类
- 任务描述:句对分类任务涉及两个句子的输入,并需要模型判断这两个句子之间的关系或情感倾向等。
- 应用场景:例如,自然语言推断(NLI)任务,需要判断一个句子是否可以从另一个句子推断出来;或者语义文本相似性(STS)任务,需要评估两个句子的语义相似度。
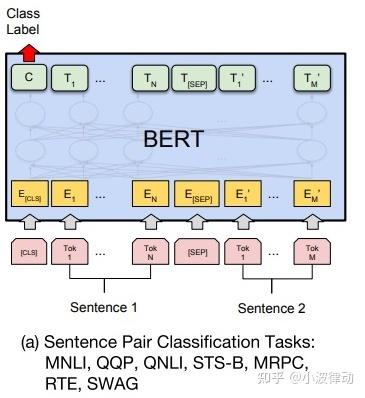
如下图所示,句对分类的处理过程为:
- 输入处理:将两个句子(句对)作为输入,在两个句子之间添加特殊的分隔符[SEP],并在开头添加开始符[CLS],在末尾添加结束符[EOS]。[CLS]标记的输出表示将被用作句对分类的输入特征。
- 模型微调:在预训练的BERT模型基础上,添加一个全连接层作为输出层,用于句对分类任务。
- 特征提取:利用BERT编码器提取的句对表示,结合注意力机制等技术,捕捉两个句子之间的关系和交互信息,用于句对分类。
举例说明:下面有两个句子,我们要判断句子2是否是句子1的合理后续,即句子间的逻辑关系,如蕴含、中立、矛盾等。在这个例子中,可以视为一个蕴含关系,因为好天气通常适合户外运动。
句子1: "今天的天气真好。"
句子2: "适合去户外运动。"BERT处理:将两个句子用[SEP]分隔,并在开头添加[CLS]标记,然后输入到BERT模型中。模型输出[CLS]标记的表示,用于句对关系的分类。
[CLS] 今天的天气真好。 [SEP] 适合去户外运动。 [SEP]模型输出标签:entailment(蕴含)
注:实际的模型输出是一个概率分布,如[0.85, 0.1, 0.05],分别对应蕴含、中立、矛盾的概率,这里为了简化只给出了最可能的标签。
2、单句分类
- 任务描述:单句分类任务是将单个句子作为输入,并输出该句子的类别或情感倾向。
- 应用场景:如情感分析(判断文本是正面、负面还是中性)、垃圾邮件检测(判断邮件是否为垃圾邮件)等。
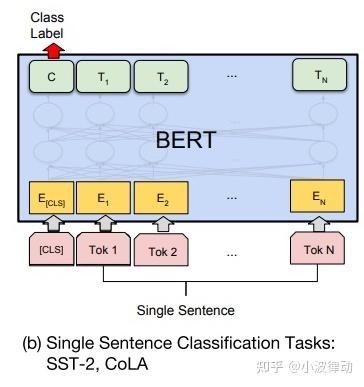
如下图所示,单句分类的处理过程为:
- 输入处理:将单个句子作为输入,添加开始符[CLS]。
- 模型微调:与句对分类类似,在预训练的BERT模型基础上添加一个全连接层作为输出层,用于单句分类任务。通过微调整个模型来优化分类性能。
- 特征提取:利用BERT编码器提取的单个句子表示,捕捉句子中的语义信息,用于单句分类。
举例说明:下面的句子,我们将句子分类为正面情感或负面情感。在这个例子中,句子表达的是正面情感。
句子: "这部电影非常精彩!"BERT处理:将句子作为输入,添加[CLS]标记,然后输入到BERT模型中。模型输出一个或多个类别的概率分布,选择概率最高的类别作为分类结果。
[CLS] 这部电影非常精彩!输出概率分布:[0.95, 0.05],其中第一个值对应正面情感的概率,第二个值对应负面情感的概率。
3、文本问答
- 任务描述:文本问答任务涉及一个问题和一段文本(如文章或段落),模型需要从文本中找出问题的答案。
- 应用场景:如机器阅读理解(MRC),自动问答系统(FAQ)等。
如下图所示,文本回答的处理过程为:
- 输入处理:将问题和相关文档或段落作为输入,使用特殊的分隔符[SEP]将问题和文档分隔开。
- 答案抽取:BERT模型通过编码器部分提取问题和文档的表示,然后可以结合指针网络等机制来定位答案在文档中的位置。在某些情况下,可能需要在BERT模型的基础上添加额外的层(如两个指针层)来指示答案的起始和结束位置。
- 微调任务:针对问答任务进行微调,优化模型在定位答案位置方面的性能。
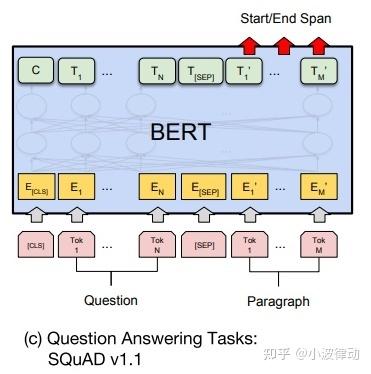
举例说明:下方的问题,我们从文档中找出问题的答案。在这个例子中,答案是"北京不是省份"。
问题: "北京是中国的哪个省份?"
文档: "北京是中国的首都,位于华北地区,不是省份。"BERT处理:将问题和文档分别作为输入,然后输入到BERT模型中。模型输出包括两个指针,用于指示答案在文档中的位置。
问题:[CLS] 北京是中国的哪个省份? [SEP]
文档:[CLS] 北京是中国的首都,位于华北地区,不是省份。 [SEP]模型输出:
- 起始索引:(在文档中的位置,假设从0开始) 23
- 结束索引:(同样,假设从0开始) 25
注:这里的索引只是示意性的,实际输出可能依赖于文档的预处理和编码方式。
4、单句标注
- 任务描述:单句标注任务是对句子中的每个词或子词进行标注,如命名实体识别(NER)、词性标注(POS Tagging)等。
- 应用场景:在信息抽取、文本分析等领域有广泛应用。
如下图所示,单句标注的处理过程为:
- 输入处理:将单个句子作为输入,不需要特殊的分隔符,但可能需要对句子进行分词处理以符合BERT的输入要求。
- 序列标注:将单句标注视为序列标注任务,其中句子中的每个单词或子词都被分配一个标签。BERT模型通过编码器部分提取句子的表示,然后结合序列标注层(如CRF层或softmax层)来为每个单词或子词分配标签。
- 微调模型:在BERT模型的基础上添加一个序列标注层,并通过微调来优化标注性能。微调过程中,模型会学习如何将句子的表示映射到对应的标签序列上。
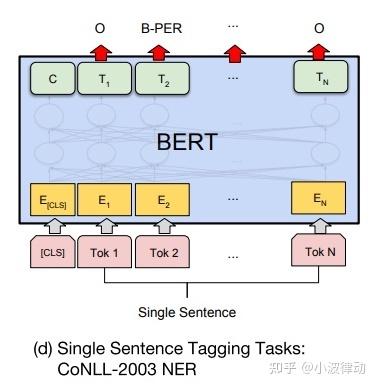
举例说明:下方的句子,我们对句子中的实体进行标注,如公司名称、地点等。在这个例子中,"苹果公司"应被标注为公司名称,"美国加利福尼亚州库比蒂诺"应被标注为地点。
句子: "苹果公司是一家总部位于美国加利福尼亚州库比蒂诺的科技公司。"BERT处理:将句子作为输入,并添加特定的标记。然后,使用BERT的编码器部分提取句子的表示,并结合序列标注层(如CRF或softmax层)来为每个单词或子词分配标签。最后,根据标签确定实体的类型和边界。
[CLS] 苹果公司是一家总部位于美国加利福尼亚州库比蒂诺的科技公司。对句子分词:
苹果公司 是 一家 总部 位于 美国 加利福尼亚州 库比蒂诺 的 科技 公司 。模型输出(假设为BIO标注方案):
- 苹果公司:B-ORG, I-ORG
- 美国:B-LOC
- 加利福尼亚州库比蒂诺:B-LOC
- 科技公司:B-ORG
注:BIO标注方案中,B表示实体的开始,I表示实体的内部,O表示非实体部分。此外,B和I后面通常会跟随一个表示实体类型的标签,如B-PER(人名)、B-LOC(地名)、B-ORG (机构)等。
2.6、模型测评
BERT在11个不同类型的NLP任务中均表现出了卓越的性能。
1、(GLUE)通用语言理解评估基准集合,包括以下几个主要任务类别:
- 单句任务:这类任务主要关注单个句子的语言特性。例如,CoLA(语言可接受性任务)和SST-2(句子情感分类任务)就是典型的单句任务。
- 相似性和释义任务:这类任务要求评估两个文本之间的相似度或释义关系。MRPC(微软研究段落相关性任务)、STS-B(语义文本相似性基准任务)和QQP(Quora问题对任务)都属于这一类别。
- 自然语言推理任务:这类任务旨在评估模型对自然语言文本之间逻辑关系的推理能力。MNLI(多类型自然语言推理任务)、QNLI(问题自然语言推理任务)、RTE(识别文本蕴含任务)和WNLI(Winograd自然语言推理任务)是自然语言推理任务的代表。
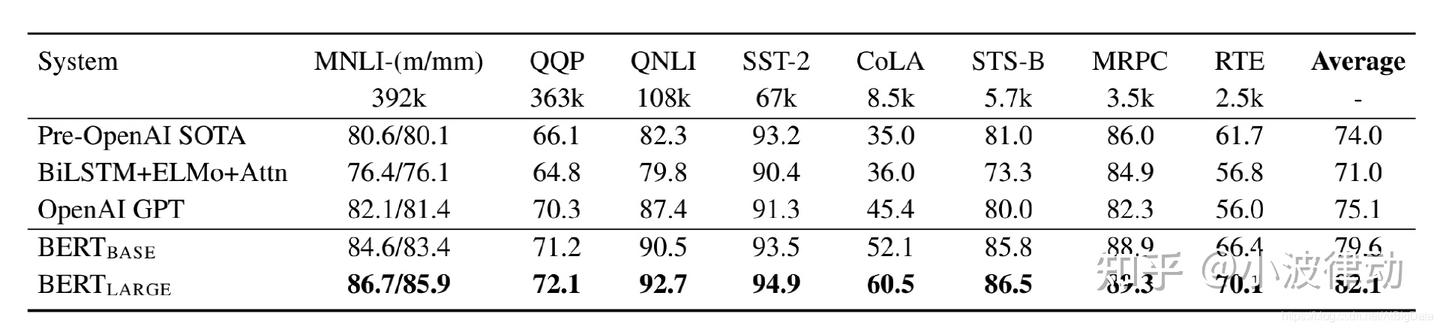
从上图可以看出:BASE版和LARGE版都获得了较高的分数,比其他模型得分高许多。
2、SQuAD v1.1,斯坦福问答数据集收集了100k众包问答对。
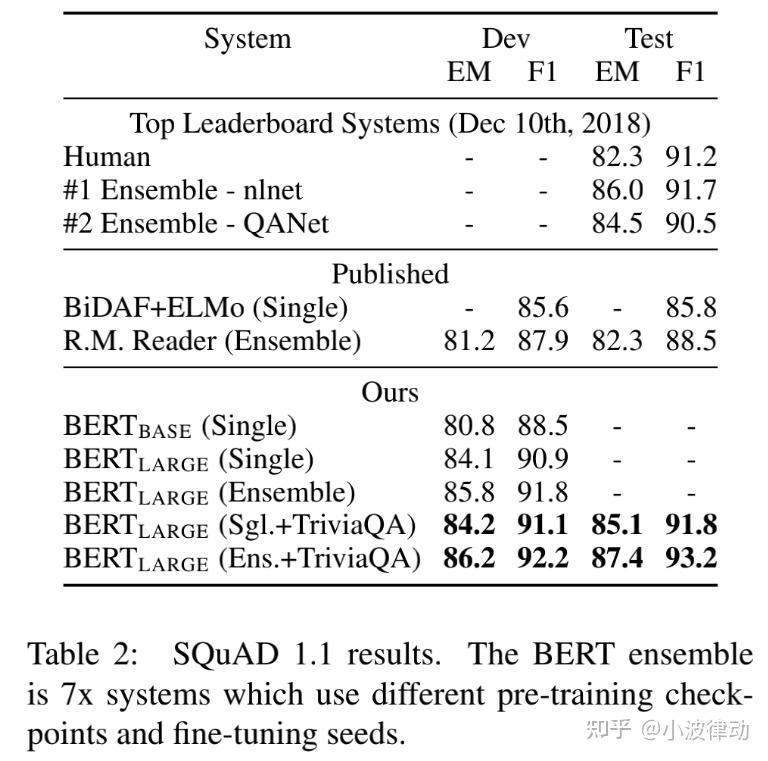
3、SQuAD v2.0,SQuAD2.0任务延伸了SQuAD1.1问题定义通过考虑在提供段落中没有短回答的存在,使得问题更加符合实际情况。
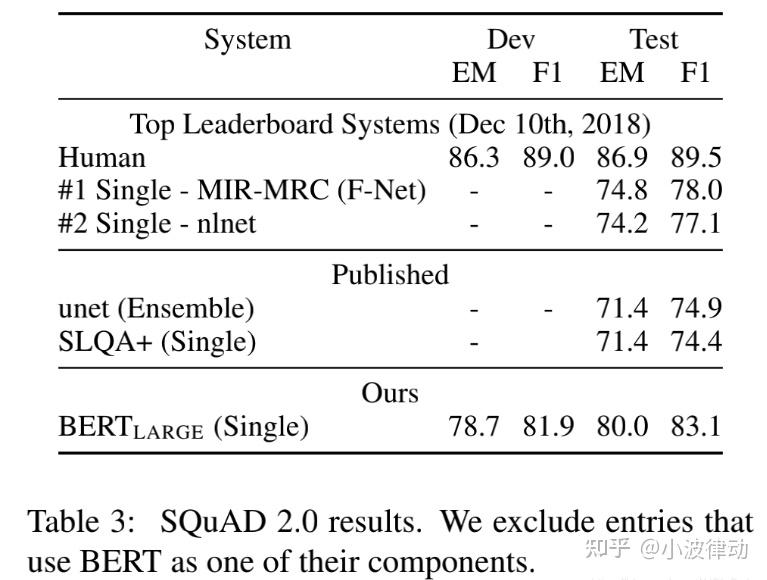
4、SWAG,对抗生成数据集包含11.3万完整样本句子对来评估理性常识推理。

3、模型应用
BERT是一个开源大模型,开源链接:https://github.com/google-research/bert。你可以将代码下载到本地,私有化部署。BERT毕竟是大模型,对硬件环境的要求还是比较高的。但官方没有给出详细的硬件要求,我们只能说需要尽可能高的硬件运行环境。
使用方法:
1、进一步训练BERT模型。
BERT是一个预训练模型,提供了丰富的语言表示能力,用户可以根据自己的任务需求对模型进行进一步的训练。下载BERT的源码后,可以对其进行微调以适应你的特定任务。
2、将BERT部署到本地使用,调用BERT接口使用BERT模型的能力。
许多组织和企业会选择将BERT模型或其变种部署到云服务器上,对外提供BERT模型的API接口。用户可以通过HTTP请求等方式与这些接口交互,以获取BERT模型的预测结果或语言表示能力。
实际项目:
BERT已经被广泛应用于各种实际项目中。以下是一些BERT在实际项目中的应用示例:
- 智能客服:许多企业利用BERT构建智能客服系统,以自动回答用户的问题。这些系统能够准确理解用户的问题,并提供相关的答案或解决方案。
- 搜索引擎:搜索引擎公司也利用BERT改进其搜索结果的相关性。通过BERT对查询和文档进行语义理解,搜索引擎能够更准确地返回用户所需的信息。
- 情感分析:在电商、社交媒体等领域,情感分析是一个重要的应用。利用BERT进行情感分析,可以自动判断用户对产品或服务的评价,为企业提供客户反馈洞察。
- 命名实体识别:在医疗、金融等领域,命名实体识别是一个关键任务。通过BERT进行命名实体识别,可以自动从文本中提取出关键信息,如疾病名称、药物名称、金融术语等。
4、总结
本文介绍了大模型BERT,这是一个重要的大模型,在NLP领域取得了显著的成果,成为了自然语言处理领域的重要里程碑。其双向Transformer编码器结构、预训练与微调的学习模式以及掩码语言模型(MLM)等预训练任务,都为后续的大模型发展提供了重要的参考。许多新大模型都参考了BERT大模型,因此全面学习BERT大模型对理解大模型设计及应用具有非常重要的意义。
5、参考文档
《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》原文或译文

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 40
40 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)