大模型基础学习
自己初学时的笔记,也希望其能帮助到有需要的人!
LLM的基础学习
本up主,目前研一,导师刚给我划分方向到LLM上,对于LLM也是从零开始。本人是听从B站的骆昊老师的 课程,希望能帮到有需要的人,自己也是刚刚学习,也希望有大佬也能指点。注:若有侵权,后台联系我,看到后将立刻删除!!!
1 申请API和响应状态码
1.1 申请DeepSeek-API
考虑到OpenAI API在网络访问和支付方式上对国内用户存在一定限制,为了让大家能更顺畅地学习和实践,本教程将主要基于国内的DeepSeek API进行讲解。
DeepSeek作为一款性能优异的国产大模型,是入门学习的绝佳选择。同时,所有代码示例都会附上兼容OpenAI API的版本,方便不同环境的读者参考。
- DeepSeek官网
- 创建API密钥
注意: 创建好的API密钥一定一定一定保存好,因为只显示一次!!!
1.2 状态响应码
在与LLM API打交道的过程中,我们免不了会遇到各种报错。而快速定位问题的关键,就藏在那些报错信息附带的状态响应码里。
简单来说,我们可以把这些状态码分为三大类:
- 2xx 家族 (成功通行 ✅): 比如 200 OK,恭喜你,一切顺利!
- 4xx 家族 (你的锅 😅): 这类错误通常源于我们自己的请求。比如:
- 400 Bad Request:请求的格式或内容有误。
- 401 Unauthorized:未授权
- 403 Forbidden:禁止访问
- 404 Not Found:请求的资源不存在
- 405 Method not allowed:请求方法不被允许
- 408 Request Timeout:请求超时
- 413 Payload Too Large:请求实体过大
- 429 Too many requests:请求过于频繁
- 5xx 家族 (对方的锅 🤯): 这说明是API服务提供商那边出了问题,我们能做的通常只有等待和反馈。
- 500 Internal Server Error:服务器内部错误
- 502 Bad Gateway:网关错误
2 用Python调用DeepSeek API
此处,废话不多说,直接上代码!!!(好记性不如烂笔头,多敲代码,熟练程度就会 +1 +1 +1)
对于下面代码我们参考DeepSeek官方文档
"""
用Python调用DeepSeek API
"""
# --- 1. 导入必备模块 ---
# 我们需要 'requests' 模块来向AI服务器发送网络请求,这就像是我们在浏览器地址栏输入网址并按回车。
import requests
# 我们需要 'json' 模块来将我们的Python字典数据打包成JSON格式,这是API能听懂的“普通话”。
import json
# --- 2. 准备并发送我们的请求 ---
# 使用 requests.post() 方法发送一个POST请求。POST请求通常用于向服务器提交数据,我们正是在“提交”我们的问题给AI。
resp = requests.post(
# 目标URL:这是我们AI助手的“地址”。
# 注意:这里我们使用DeepSeek的地址,OpenAI的地址已注释备用。
url='https://api.deepseek.com/chat/completions',
# url='https://api.openai.com/v1/chat/completions', # 如果用OpenAI,则替换成这个
# 请求头 (Headers):这部分信息像是我们的“身份证明”和“信件格式说明”。
headers={
# 'Authorization': 这是最重要的身份凭证,告诉服务器“我是谁”。
# 格式是 "Bearer [你的API密钥]",注意Bearer后面有个空格。
# !!!重要:千万不要将你的API密钥直接上传到GitHub等公开地方!
'Authorization': 'Bearer sk-xxxxxxxxxxx',
# 'Content-Type': 告诉服务器,我们发送给它的数据是JSON格式的。
'Content-Type': 'application/json',
# 'Accept': 接收数据也是JSON格式
'Accept': 'application/json',
},
# 请求体 (Data):这是我们请求的核心内容,也就是我们想对AI说的话和具体要求。
# 我们用 json.dumps() 将一个Python字典转换成JSON字符串。
data=json.dumps({
# 'model': 指定要使用的模型。
'model': 'deepseek-chat',
# 'model': 'gpt-4o-mini', # OpenAI的模型示例
# 'messages': 这是我们的对话历史。API通过这个列表来理解上下文。至少要包含一个'role'为'user'的消息。
'messages': [
# 'role': 'user' 代表这是用户(也就是我们)说的话。
# 'content': 存放具体的提问内容。
{'role': 'user', 'content': '今天北京天气如何?给我一些穿衣建议。'}
],
# --- 以下是控制AI输出行为的参数 ---
# 'temperature' (温度): 控制输出的创造性或随机性。
# 值越高 (如 1.0),AI回复越随机、有创意;值越低 (如 0.2),回复越确定、保守。
'temperature': 0.7,
# 'max_tokens' (最大令牌数): 限制AI生成回复的最大长度。
# 这有助于控制成本和防止生成过长的无用信息。一个汉字约等于2-3个token。
'max_tokens': 1024,
# 'stream' (流式输出): 是否像官网那样一个字一个字地返回。
# False: 等AI生成完所有内容后,一次性返回。 (代码处理简单)
# True: 陆续返回生成的内容,体验更好,但代码处理稍复杂。
'stream': False,
})
)
# --- 3. 处理AI的响应 ---
# 首先,检查HTTP状态码,这是网络通信的“回执”。状态码 200 代表“成功”,这是我们最希望看到的结果。
if resp.status_code == 200:
# 如果成功,使用 .json() 方法将返回的JSON格式内容解析成Python字典,方便我们查看。
print("请求成功,AI的回复是:")
# 通常,AI的回复内容藏在 'choices' -> [0] -> 'message' -> 'content' 这个路径里。
print(resp.json()['choices'][0]['message']['content'])
else:
# 如果不成功,打印出状态码和错误信息,帮助我们排查问题。比如 401 (认证失败), 429 (请求过于频繁) 等。
print(f"请求失败,状态码:{resp.status_code}")
print(f"错误详情:{resp.text}")
| 参数 | 含义解释 | 常用取值与建议 |
|---|---|---|
| model | 模型选择:指定想要对话的AI模型。不同模型有不同的能力、速度和成本 | DeepSeek: ‘deepseek-chat’,‘deepseek-reasoner’ OpenAI: ‘gpt-40’,'gpt-4-turbo’等 |
| messages | 对话内容:一个包含对话历史的列表,是与AI沟通的核心。每个元素都是一个字典,包含role和content | role可以是: - ‘user’ : 用户输入 -‘assistant’ : AI的回复(用于多轮对话) -‘system’ : 给AI的全局指令(如:”你是一个专业的翻译家“) |
| temperature | 创意温度计:控制输出的随机性。数据越高,回答越有创意和多样性;数值越低,回答越稳定和确定 | 范围:0.0 - 2.0 -0.2 适合代码生成、翻译、事实问答。 -0.8:适合文档创作、头脑风暴、写故事。 -默认值通常为0.7 或 1.0 |
| max_tokens | 回复长度上限:限制模型单次回复生成的最大Token数量(Token可以理解为单词或字符块) | 根据你的需要设置。比如,如果你只需要一个简短的答案,可以设为100。如果你需要一篇长文,可以设为2048或更高。注意:这会直接影响费用! |
| stream | 流式传输开关:决定是一次性接收完整回复,还是像打字机一样逐字接收。 | - False (默认): 简单,一次性获取结果。 - True: 实时性好,用户体验佳,但需要不同的代码来处理数据流。 |
| frequency_penalty | 词频惩罚:通过惩罚高频出现的词,降低模型重复相同词语的概率。 | 范围: -2.0 到 2.0。 正值会降低重复词语的概率,0代表不惩罚。如果你发现AI总说车轱辘话,可以适当调高这个值,比如0.5。 |
| presence_penalty | 话题惩罚:与上面类似,但它惩罚的是已经出现过的任意词语,鼓励模型引入新的话题和概念。 | 范围: -2.0 到 2.0。 如果你希望AI的回答更开阔,不局限于几个概念,可以调高它。 |
通过原生的requests库调用API,能让我们很好地理解其工作流程。然而,在实际开发中,为了提升效率和代码的可读性,我们通常会使用官方提供的SDK(软件开发工具包)。
对于LLM调用,openai这个Python库就是业界的标准答案。它不仅极大地简化了代码,还内置了对重试、类型提示等高级功能的支持。下面我们来看看,用openai库实现同样的功能,代码能变得多简单。
3 调用OpenAI库搭建交互
由于上述代码是将API放入了代码中,这样当我们上传代码时,会将API一同上传会导致个人信息泄露。接下来我们解决这个问题
首先在代码所属文件夹下创建一个名为.env的文件,里面放入OPENAI_API_KEY=sk-xxxxxxxxxx放入你的API
from openai import OpenAI
from dotenv import load_dotenv
# 智能加载API Key
# load_dotenv() 会自动读取我们项目根目录下的 .env 文件这样,我们就不需要把敏感的API Key硬编码在代码里了!
load_dotenv(override=True)
# 初始化客户端,并指定“服务台”地址
# 注意这里的关键变化:我们传入了 base_url 来告诉openai库,我们要去的是DeepSeek的“服务台”,而不是默认的OpenAI。
# API Key会自动从环境变量中读取,非常安全和方便。
client = OpenAI(
# api_key 在.env文件中会自动读取,无需手动填写
base_url='https://api.deepseek.com/v1'
)
# 发起请求,语法更“自然”
# 直接调用 client.chat.completions.create() 方法,像填写函数参数一样传入模型、messages等信息即可。
resp = client.chat.completions.create(
model='deepseek-chat',
messages=[
{'role': 'user', 'content': '北京天气如何?'}
],
temperature=0.5,
stream=False,
)
# 精准获取回复内容
ai_message = resp.choices[0].message.content
print(ai_message)
我们尝试一下stream=True,这个时候resp返回的可是迭代器
""" 该部分只给出改变的部分,其余一致"""
resp = client.chat.completions.create(
model='deepseek-chat',
messages=[
{'role': 'user', 'content': '北京天气如何?'}
],
temperature=0.5,
stream=True,
)
# 精准获取回复内容
# 注意:print()函数会在输出内容结尾处自动添加一个换行符 \n。
# end=''的作用:在输出结尾处不加任何东西作为结尾,尤其不换行
for chunk in resp:
print(chunk.choices[0].delta.content, end='')
4 本地部署大模型
上面的均为调用API来与AI进行交互,接下来,我们尝试在本地部署大模型。
4.1 Ollama
对于本地部署大模型,自然少不了使用的大模型(需要下载到本地中),我们使用Ollama,其是一个软件并有许多开源的大模型,该软件需要下载安装到本机中。
进入Ollama网址后,点击Models就可看到许多开源的大模型。
我们可在终端处打开并检查已经下载的模型ollama list。若想要下载模型可使用ollama pull xxx(模型的名称)。
4.2 部署本地大模型
import json
import requests
resp = requests.post(
# URL指向本地主机(localhost)的11434端口,这是Ollama服务的默认地址。
# '/api/chat'是Ollama用于处理聊天请求的特定API端点。
url='http://localhost:11434/api/chat',
# 因其是本地调用大模型,所以无需进行授权'Authorization'
headers={
'Content-Type': 'application/json',
'Accept': 'application/json',
},
data = json.dumps({
# 'model'指定了我们希望Ollama使用的模型名称。这个模型必须是Ollama已经下载并可以使用的。
'model': 'qwen3',
'temperature' : 0.5,
'frequency_penalty': 0.4,
'max_tokens': 1024,
'stream': False,
'messages' : [
{'role' : 'user', 'content' : '今天北京天气如何'}
]
})
)
if resp.status_code == 200:
print(resp.json()['message']['content'])
else:
print(resp.status_code)
若跑程序时,显示无法主机连接。大概率原因是:11434该端口在被占用,只需要对其进行删除即可。打开终端:# netstat -ano | findstr :11434进行查找占用11434端口的进程ID,之后taskkill /PID <PID> /F终止该进程(替换为实际ID)。
大模型的记忆能力
在我们搭建的AI交互,均无记忆能力, 即当我们进行多轮对话时,均会忘记上一轮的会话。
当进行多轮对话时,均会调用client.chat.completions.create中的messages中输入数据,不便利并不能记住上一轮的内容。
""" common.py """
def get_content_fro_llm(client,
*, # 这是一个分隔符,它之后的所有参数都必须以关键字形式传递(例如 temperature=0.5)
system_prompt='',
few_shot_prompt=[],
user_prompt='',
model_name='gpt-4o-mini',
temperature=0.1,
top_p=0.1,
frequency_penalty=0,
max_tokens=512):
# 1. 动态构建messages列表。这是函数的核心逻辑:根据传入的提示词,智能地组装最终的messages。
messages = []
# 如果system_prompt不为空字符串,则添加到messages列表的开头。
# .strip()用于去除字符串两端的空白,防止只有空格的字符串被错误地加入。
if system_prompt.strip():
messages.append({'role': 'system', 'content': system_prompt})
# 如果few_shot_prompt列表不为空,则将其中的示例加入到messages中。
if few_shot_prompt:
messages.extend(few_shot_prompt)
# 最后,如果用户问题不为空,则将其作为最后一条user信息加入。
if user_prompt.strip():
messages.append({'role': 'user', 'content': user_prompt})
# 如果messages列表为空(例如所有prompt都未提供),可以抛出异常或返回提示
if not messages:
return "错误:没有任何有效的提示词被提供。"
# 2. 调用API并获取响应
# 使用组装好的messages和其他参数,调用我们熟悉的create方法。
response = client.chat.completions.create(
model=model_name,
temperature=temperature,
top_p=top_p,
max_tokens=max_tokens,
messages=messages,
stream=False # 在函数中通常使用非流式,方便直接返回结果
)
# 3. 解析并返回最终结果
# 将解析响应的逻辑也封装在函数内部,调用者无需关心复杂的响应结构。
return response.choices[0].message.content
开始调用上述函数进行AI交互
from dotenv import load_dotenv
from openai import OpenAI
from common import get_content_fro_llm
load_dotenv(override=True)
client = OpenAI(base_url='https://api.deepseek.com/v1')
answer1 = get_content_fro_llm(client, user_prompt='北京天气如何?', model_name='deepseek-chat')
print(answer1)
print('-' * 80)
# 但是这样操作只会让窗口越来越大,消耗大量的Toekn
answer2 = get_content_fro_llm(client, user_prompt=f'{answer1},它的面积多大', model_name='deepseek-chat')
print(answer2)
提示词
在与大语言模型(LLM)进行交互时,提示词(Prompt 的设计至关重要。根据是否为模型提供示例,我们可以将提示词策略主要分为两大类:零样本提示(Zero-Shot Prompting)和少样本提示(Few-Shot Prompting)。
- 零样本提示 (Zero-Shot Prompting)
- 核心思想:直接向模型提出任务请求,不提供任何解题范例。
零样本提示完全依赖模型自身强大的预训练知识和泛化能力来理解并执行指令。我们相信模型已经“见过”足够多的信息,能够直接领会我们的意图。 - 实例
# 直接下达指令 将下面的文本翻译成法语: "Hello, how are you?"
- 核心思想:直接向模型提出任务请求,不提供任何解题范例。
- 少样本提示 (Few-Shot Prompting)
- 核心思想:在提出最终任务前,先给模型提供一或多个“问题-答案”的完整范例,引导其学习您期望的输出格式、风格或逻辑。
少样本提示通过“现场教学”的方式,为模型设置了清晰的上下文和行为模式。这使得模型能更精确地模仿范例,处理更复杂或更具特定格式要求的任务。 - 实例
# 提供一个范例,然后提出新问题 将英文翻译成法语。 英文: "sea otter" 法语: "loutre de mer" 英文: "Hello, how are you?" 法语:
- 核心思想:在提出最终任务前,先给模型提供一或多个“问题-答案”的完整范例,引导其学习您期望的输出格式、风格或逻辑。
LangChain和LangSmith
- LangChain 是一个帮你快速、高效地将大语言模型(LLM)与外部数据和工具组合起来,以构建强大 AI 应用的开源开发框架。
- LangSmith 是一个让你能够调试、评估和监控你的 AI 应用内部运作过程的可观测性平台,是 LangChain 的“最佳拍档”。
现如今,LangChain的框架是比较常用的。对于LangChain的使用可参考官方文档。当然啦,这是全英文的,易读性一般般,介绍一个全中文的网址。
下面的代码需要去LangSmith官方网址申请API密钥。并将申请API密钥放入.env文件中:LANGCHAIN_API_KEY=lsv2-xxxxxxxxxx。
LangChain核心组件之一:LLM缓存
"""
本示例将演示 LangChain 的核心组件之一:LLM 缓存(Cache)。
缓存的目的是:当遇到完全相同的请求时,直接返回之前缓存的结果,而不是再次调用大语言模型(LLM)的 API。这能显著地:
1. 降低 API 调用成本。
2. 加快响应速度。
"""
from dotenv import load_dotenv
from langchain.globals import set_llm_cache
from langchain_community.cache import SQLiteCache
from langchain_core.caches import InMemoryCache
from langchain_openai import ChatOpenAI
load_dotenv(override=True)
"""
开启缓存存储:LangChain 允许我们设置一个全局缓存。
一旦设置,任何通过 LangChain 框架发出的 LLM 请求都会自动应用这个缓存机制。
注意:后面的设置会覆盖前面的设置。
"""
# 这是一个内存缓存的例子(本代码中它被下一行覆盖了,仅作演示)。
# InMemoryCache 将所有缓存项存储在程序的内存中。
# - 优点:读写速度极快。
# - 缺点:当程序结束时,所有缓存内容都会丢失。
# maxsize=32 表示最多缓存32个不同的请求。
# set_llm_cache(InMemoryCache(maxsize=32))
# SQLiteCache 将缓存内容写入一个本地的数据库文件(在这里是 'cache.db')。
# - 优点:数据持久化。即使关闭并重启程序,之前的缓存依然有效。
# - 缺点:相比内存缓存,有轻微的磁盘I/O开销,但通常可以忽略不计。
# 这是推荐用于本地开发和测试的方式。
set_llm_cache(SQLiteCache(database_path='cache.db'))
# --- 初始化大语言模型 (LLM) ---
# 创建一个 ChatOpenAI 的实例。
llm = ChatOpenAI(
base_url = 'https://api.deepseek.com/v1',
model = 'deepseek-chat',
temperature = 0.3,
frequency_penalty = 0.5,
)
# --- 演示缓存效果 ---
# 第一次调用:
print('第一次调用(将请求API)...')
# 使用 .invoke() 方法向 LLM 发送请求。
# 由于这是第一次用 "请介绍一下辽宁" 这个提示词,缓存中没有记录。
# LangChain 会正常地向 DeepSeek API 发送网络请求。
# 收到回复后,LangChain 会自动将【提示词】和【回复内容】作为一个键值对,存入我们设置的 'cache.db' 文件中。
resp = llm.invoke("请介绍一下辽宁")
# 打印从 API 获取的实时回复。
print(resp.content)
print('-' * 80)
# 第二次调用:
print('第二次调用(将从缓存读取)...')
# 再次使用完全相同的提示词 "请介绍一下辽宁" 来调用 .invoke()。
# 这次,LangChain 在发送请求前,会先检查缓存('cache.db' 文件)。
# 它发现这个提示词已经存在于缓存中,于是它会**直接从缓存中取出对应的回复,而根本不会向 DeepSeek API 发送任何网络请求**。
# 如果您开启了 LangSmith,您会在 LangSmith 的追踪记录中看到这次调用的标签是 "CacheHit"。
resp = llm.invoke("请介绍一下辽宁")
print(resp.content)

LangChain核心 – 缓存(Cache) vs 记忆(Memory)
"""
本示例将同时演示 LangChain 的两大核心组件:
1. 缓存 (Cache): 用于存储并复用对【完全相同】请求的 LLM 响应,以节省成本和时间。
2. 记忆 (Memory): 用于在【一次连续对话中】存储上下文信息,让 LLM 能够理解前后文关联。
"""
from dotenv import load_dotenv
from langchain.globals import set_llm_cache
from langchain_community.cache import SQLiteCache
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
from langchain_openai import ChatOpenAI
load_dotenv(override=True)
# 设置全局 LLM 缓存。我们将使用 SQLiteCache,它会将缓存结果持久化保存在 'cache.db' 文件中。
# 这意味着,即使程序重启,只要输入完全一样,缓存依然有效。
set_llm_cache(SQLiteCache(database_path='cache.db'))
# --- 初始化大语言模型 (LLM) ---
llm = ChatOpenAI(
base_url = 'https://api.deepseek.com/v1',
model = 'deepseek-chat',
temperature = 0.3,
frequency_penalty = 0.5
)
# --- 演示“记忆 (Memory)”组件 ---
# 创建一个 ConversationBufferMemory 实例。
# 把它想象成一个专门为“当前这次对话”服务的短期记事本。
# return_messages=True 是一个推荐的设置,让记忆以更结构化的消息对象形式存储。
memory = ConversationBufferMemory(return_messages=True)
# 使用 .save_context() 方法,我们可以手动向“记事本”中预先写入一些对话内容。
# 这就像是在与 AI 对话前,先给它一些背景设定。
memory.save_context({'input':'你好呀'}, {'output' : '你好呀,研究生!!!'})
memory.save_context({'input':'我的研究方向是LLM'},{'output':'哇!很不错的研究方向'})
# 使用 .load_memory_variables({}) 查看一下当前“记事本”里都记了些什么。输出会是一个包含所有历史对话的格式化字符串。
print("--- 预设的记忆内容 ---")
print(memory.load_memory_variables({}))
print("-" * 25)
# 将 LLM 和 Memory 组装成一个“对话链 (ConversationChain)”。这个链会自动处理记忆的加载和保存。
chain = ConversationChain(llm=llm, memory=memory, verbose=True) # verbose=True能看到链的思考过程
# 测试一下记忆的效果。
# 当我们问“你知道我的学历吗?”,链会自动将历史对话(其中提到了“研究生”)
# 和新问题一起发送给 LLM,因此 LLM 能够根据上下文回答。
print("--- 测试记忆效果 ---")
response = chain.invoke('你知道我的学历吗?')
print("AI的回复:", response['response']) # response 是一个字典,答案在 'response' 键中
print("-" * 25)
# --- 演示“缓存 (Cache)”与“记忆 (Memory)”的协同工作 ---
# 第一次调用:
print('--- 演示缓存与记忆的协同 ---')
print('第一次调用(将请求API)...')
# 我们问了一个全新的问题:“介绍一下北京的历史”。
# 1. **记忆组件工作**:链会把之前的对话历史和这个问题一起打包。
# 2. **缓存组件检查**:LangChain 检查缓存中是否有这个【打包后的完整提示】。因为是第一次问,所以缓存未命中。
# 3. **LLM 调用**:请求被发送到 DeepSeek API。
# 4. **缓存组件保存**:API 的回复被返回,同时缓存系统会将【打包后的完整提示】和【回复】存入 'cache.db'。
# 5. **记忆组件更新**:这次的问答也被加入到对话记忆中。
result = chain.invoke('介绍一下北京的历史')
print("AI的回复:", result['response'])
print('-' * 80)
# 第二次调用,这是一个有关联但不同的问题。
print('第二次调用(利用记忆,但缓存未命中)...')
# 我们问了一个相关问题:“其占地面积多大”。
# 1. **记忆组件工作**:链会把【所有】历史对话(包括上一轮关于北京历史的问答)和新问题打包。
# 打包后的提示会是类似:“...介绍一下北京的历史...AI:...其占地面积多大”。
# 2. **缓存组件检查**:LangChain 检查缓存。由于这次打包后的提示与上一次【完全不同】,所以**缓存再次未命中**。
# 3. **LLM 调用**:请求再次被发送到 DeepSeek API。LLM 因为看到了完整的历史记录,所以知道“其”指的是北京。
# 4. **缓存组件保存**:新的提示和回复被存入缓存。
# 5. **记忆组件更新**:这轮问答也被加入记忆。
result = chain.invoke('其占地面积多大')
print("AI的回复:", result['response'])
LangChain进阶版 – 让非OpenAI模型(如DeepSeek)支持Token计数与高级记忆功能
"""
问题背景:
LangChain 中的一些高级记忆组件(如 ConversationSummaryBufferMemory, ConversationTokenBufferMemory)
需要计算对话历史的 Token 数量,来决定何时进行总结或截断。
然而,LangChain 的内置 Token 计算器(tiktoken)只认识 OpenAI 的模型。
当我们使用像 DeepSeek 这样的第三方模型时,程序会因无法计算 Token 而报错。
解决方案:
本示例将演示如何通过“继承”和“重写”的方式,创建一个自定义的 ChatDeepSeek 类,
让它学会使用 DeepSeek 官方的分词器(Tokenizer)来计算 Token,从而解锁所有高级记忆功能。
"""
from langchain_openai import ChatOpenAI
from langchain.globals import set_llm_cache
from langchain_community.cache import SQLiteCache
from langchain.memory import (
ConversationSummaryBufferMemory,
ConversationBufferMemory,
ConversationBufferWindowMemory,
ConversationTokenBufferMemory
)
from langchain.chains import ConversationChain
from langchain_core.messages import BaseMessage
from dotenv import load_dotenv
from deepseek_tokenizer import Tokenizer # 导入 DeepSeek 官方的分词器
# --- 创建自定义的 ChatDeepSeek 类 ---
# 我们创建一个新类 ChatDeepSeek,让它继承自 LangChain 官方的 ChatOpenAI 类。
# 继承意味着它自动拥有 ChatOpenAI 的所有功能,我们只需要对需要的部分进行修改。
class ChatDeepSeek(ChatOpenAI):
"""一个支持 DeepSeek Token 计算的自定义 LLM 类"""
# 定义一个类级别的属性 `tokenizer`。
# 我们在这里直接加载 DeepSeek 官方推荐的分词器模型。
# 这确保了所有 ChatDeepSeek 实例共享同一个分词器,避免重复加载。
tokenizer: Tokenizer = Tokenizer.from_pretrained('deepseek-ai/deepseek-coder-33b-instruct')
# 这是关键:我们重写(override)父类 ChatOpenAI 中的 get_num_tokens_from_messages 方法。
# 原来的方法遇到不认识的模型会报错,我们在这里实现自己的逻辑。
def get_num_tokens_from_messages(self, messages: list[BaseMessage]) -> int:
"""使用 DeepSeek 官方分词器来精确计算 Token 数量"""
num_tokens = 0
# 遍历传入的消息列表
for message in messages:
# 对每条消息的内容进行编码(即分词),然后计算其长度。
# 这就是这条消息所占的 Token 数量。
num_tokens += len(self.tokenizer.encode(message.content))
return num_tokens
# --- 环境设置与模型初始化 ---
load_dotenv(override=True)
# 设置全局 SQLite 缓存,用于持久化存储 LLM 的响应
set_llm_cache(SQLiteCache(database_path='cache.db'))
# 初始化 LLM。注意:我们现在使用的是自己创建的 ChatDeepSeek 类!
# 因为它继承自 ChatOpenAI,所以所有的参数(base_url, model 等)都完全兼容。
llm = ChatDeepSeek(
base_url='https://api.deepseek.com/v1',
model='deepseek-chat',
temperature=0.3,
frequency_penalty=0.5
)
# --- 选择并配置记忆 (Memory) 组件 ---
# LangChain 提供了多种记忆类型,以适应不同的对话场景。
# 您可以取消下面不同行的注释,来体验它们的差异。
# 4.1 基础记忆 (无限容量)
# 这是最基础的记忆类型,它会无限制地存储所有对话历史。
# 优点:信息最全。缺点:随着对话变长,发送给 LLM 的 Token 会越来越多,成本和延迟增加,最终可能超出模型上下文窗口。
memory = ConversationBufferMemory(return_messages=True)
# 4.2 窗口记忆 (固定轮数)
# 只保留最近的 k 轮对话。例如 k=3,它会记住最近的3次提问和3次回答。
# 优点:简单高效,能有效控制 Token 数量。缺点:会“忘记”早期的重要信息。
# memory = ConversationBufferWindowMemory(k=3, return_messages=True)
# 4.3 摘要缓冲记忆 (自动总结,需要Token计算)
# 它有一个 Token 数量的上限。当对话历史超过这个上限时,它会自动调用 LLM 将【最早期】的对话内容进行总结,
# 然后用这个简短的总结替换掉原来的详细对话,从而“压缩”记忆。
# 优点:既能保留长期记忆的精华,又能控制 Token 数量。
# 缺点:需要额外的一次 LLM 调用来进行总结,会产生少量额外成本。
# 注意:这个记忆类型必须依赖我们实现的 get_num_tokens_from_messages 方法才能工作!
# memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=1000, return_messages=True)
# 4.4 Token缓冲记忆 (固定Token数,需要Token计算)
# 与窗口记忆类似,但它不是按“轮数”截断,而是按“Token数”截断。
# 它会一直保留最近的对话,直到总 Token 数超过 max_token_limit,然后开始丢弃最早的消息。
# 优点:能比窗口记忆更精确地控制上下文长度。
# 注意:这个记忆类型也必须依赖我们实现的 get_num_tokens_from_messages 方法!
# memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=2048, return_messages=True)
# --- 演示与测试 ---
memory.save_context({'input': '我叫小强'}, {'output': '你好,小强'})
memory.save_context({'input': '我现在是一名研究生,研究方向是人工智能和自然语言处理,最近在学习 LangChain 框架。'},
{'output': '很棒的方向!LangChain 是一个强大的工具,祝你学习顺利!'})
memory.save_context({'input': '我感觉有点难,特别是关于 Agent 和 Tool 的部分。'},
{'output': '别担心,这是正常的。多看文档,多动手实践,你会掌握它的。'})
memory.save_context({'input': '我还很胖'}, {'output': '没事的,你在坚持锻炼,逐渐会强壮的!!!'})
# 打印初始记忆内容
print('-------当前记忆中的内容----------')
print(memory.load_memory_variables({}))
print('-' * 80)
# 创建对话链,将 LLM 和 Memory 组装起来
chain = ConversationChain(llm=llm, memory=memory, verbose=True)
# 进行多轮对话测试
result = chain.invoke('介绍一下辽宁省沈阳市')
print("AI 回复:", result['response'])
print('-' * 80)
# 提出一个依赖上一轮对话的问题
result = chain.invoke('其历史是如何的') # LLM 应该知道 "其" 指的是沈阳
print("AI 回复:", result['response'])
print('-' * 80)
# 提出一个依赖最早期预设记忆的问题
result = chain.invoke('你知道我是干什么的吗?') # LLM 应该能从记忆中找到“研究生”这个信息
print("AI 回复:", result['response'])
print('-' * 80)
# 打印最终的、包含所有对话的记忆内容
print('-------最终记忆中的内容----------')
print(memory.load_memory_variables({}))
| 记忆类型 | 工作原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| ConversationBufferMemory | 存储全部对话历史 | 信息最完整,不会遗忘 | Token 数量会无限增长,最终可能超限 | 短对话、或需要完整上下文的场景 |
| ConversationBufferWindowMemory | 只保留最近的 k 轮对话 | 简单、高效,严格控制上下文长度 | 会“硬性”遗忘早期重要信息 | 闲聊机器人、客服等关注近期对话的场景 |
| ConversationTokenBufferMemory | 保留最近的对话,直到总 Token 数超限 | 能比窗口记忆更精确地控制 Token 数量 | 同样会“硬性”遗忘早期信息 | 对 Token 成本和上下文窗口有严格限制的场景 |
| ConversationSummaryBufferMemory | 对话超长时,自动总结早期内容 | 两全其美:既保留长期记忆的精华,又控制了 Token 数量 | 需要额外调用LLM进行总结,有少量延迟和成本 | 长对话、需要记住早期关键信息(如用户身份、核心目标)的场景 |
链路 + 输出解析器
"""
本示例将演示 LangChain 的两大基石:
1. 提示词模板 (PromptTemplate): 如何创建可复用的、带有变量的指令。
2. 链 (Chain): 如何使用 LCEL (LangChain Expression Language) 的管道符 `|`,
将提示词模板和语言模型(LLM)优雅地连接起来,形成一个强大的工作流。
"""
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv(override=True)
llm = ChatOpenAI(
base_url='https://api.deepseek.com/v1',
model='deepseek-chat',
temperature=0.3,
frequency_penalty=0.5
)
# --- 创建提示词模板 (Prompt Template) ---
# 使用 ChatPromptTemplate.from_messages 工厂方法来创建一个模板。
# 这种方法允许我们以一种结构化的、类似真实对话的方式定义提示。
prompt = ChatPromptTemplate.from_messages([
# 第一个元组代表“系统消息 (system message)”。
# 系统消息用于给 AI 设定一个整体的角色、背景或高级指令。
# 这里的 {target} 是一个占位符,我们之后可以动态地填入具体的目标语言。
('system', '你是一个专业的翻译助手,请将我提供的内容翻译为{target},只输出翻译的内容。'),
# 第二个元组代表“用户消息 (human message)”。
# 这通常是用户提出的具体问题或需要处理的内容。
# 这里的 {sentence} 是另一个占位符,之后我们会填入用户想要翻译的句子。
('human', '我要翻译的内容是:{sentence}')
])
# --- 构建链 (Chain) 并执行 ---
# 使用 LangChain 表达式语言 (LCEL) 的管道符 `|` 来构建一个链。
# 这行代码的含义非常直观:将 `prompt` 的输出“管道连接”到 `llm` 的输入。
# `chain` 现在是一个可执行的对象,封装了“填充提示 -> 调用LLM”的完整流程。
chain = prompt | llm
targets = ['日语', '法语', '德语', '俄语', '韩语']
sentence = input('请输入需要翻译的内容:')
for target in targets:
resp = chain.invoke({
'target': target, # 将当前循环的语言(如'日语')填充到 {target}
'sentence': sentence # 将用户输入的句子填充到 {sentence}
})
# `resp` 是一个 AIMessage 对象,我们需要通过 .content 属性来获取其纯文本内容。
print(f"翻译成 {target}: {resp.content}")
高级输出解析器
"""
本示例在之前的基础上,引入了一个新的核心组件:输出解析器 (Output Parser)。
我们将看到如何使用它来确保 LLM 的输出是我们期望的 Python 列表格式,而不是一个难以处理的普通字符串。
"""
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import CommaSeparatedListOutputParser
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv(override=True)
# 创建一个 CommaSeparatedListOutputParser 的实例。
# 这个 `parser` 对象有两个核心功能:
# 1. 提供“格式化指令”,告诉 LLM 应该如何输出。
# 2. 解析 LLM 返回的字符串,将其转换为 Python 列表。
parser = CommaSeparatedListOutputParser()
# 打印出由解析器自动生成的“格式化指令”。
# 这行代码会输出一段明确的英文提示,例如:"Your response should be a list of comma separated values, eg: `foo, bar, baz`"
# 这段指令是让 LLM 理解我们期望格式的关键。
print("解析器提供的格式化指令:", parser.get_format_instructions())
llm = ChatOpenAI(
base_url='https://api.deepseek.com/v1',
model='deepseek-chat',
temperature=0.3,
frequency_penalty=0.5
)
# --- 创建包含“格式化指令”的提示词模板 ---
# 创建一个聊天提示词模板。
prompt = ChatPromptTemplate.from_messages([
# 系统消息:这里的关键变化是,我们不再硬编码指令,
# 而是直接将 `parser.get_format_instructions()` 的返回值作为系统消息。
# 这样,我们就把“如何格式化输出”的要求,动态地注入到了给 LLM 的指令中。
('system', parser.get_format_instructions()),
# 用户消息:提出具体的需求,这部分保持不变。
('human', '请帮我生成{subject}的{num}个十六进制表示的随机颜色')
])
# --- 构建并执行一个“三段式”链 ---
# 这里的链结构发生了变化,变成了三段式: prompt | llm | parser
# 这是理解数据在 LangChain 中完整流转过程的关键:
# 1. (输入) -> prompt: 输入的字典被 `prompt` 用来填充占位符,生成一个完整的、包含格式化指令的提示。
# 2. prompt -> llm: `prompt` 的输出(一个格式化的提示)被发送给 `llm`。
# 3. llm -> parser: `llm` 返回一个 AIMessage 对象(其内容是模型生成的、逗号分隔的字符串),这个对象接着被传递给 `parser`。
# 4. parser -> (最终输出): `parser` 接收到 AIMessage,提取其内容,并将其解析成一个真正的 Python 列表。
chain = prompt | llm | parser
# 调用链的 .invoke() 方法来执行整个三段式流程。
colors = chain.invoke({'subject': '彩虹色', 'num': 8})
# 打印链的最终输出结果。
# 因为链的最后一环是 `parser`,所以 `colors` 变量的类型不再是字符串或 AIMessage,而是经过解析器处理后的 Python 列表。
# 例如:['#FF0000', '#FFA500', '#FFFF00', '#008000', '#0000FF', '#4B0082', '#EE82EE', '#C0C0C0']
print("解析后的颜色列表:", colors)
# 打印 `colors` 变量的类型,以验证其是否为我们期望的列表类型。
# 输出将会是:<class 'list'>
print("结果的数据类型:", type(colors))
自定义解析器
from typing import List
from dotenv import load_dotenv
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
# --- 使用 Pydantic 定义我们的目标数据结构 (Schema) ---
# 这是本示例最核心的一步。我们不再满足于简单的列表,而是要定义一个复杂的、包含多种数据类型的对象。
# 我们创建一个名为 BookInfo 的类,并让它继承自 pydantic.BaseModel。
# 这个类就像一个“数据合同”,精确地描述了我们希望从 LLM 得到的数据的结构和类型。
class BookInfo(BaseModel):
# 定义一个名为 title 的字段,类型为字符串 (str)。
# Field(...) 用于提供额外信息,这些信息会被解析器自动用来构建给 LLM 的指令:
# - description: 这段描述会告诉 LLM 这个字段代表什么。
# - examples: 这些例子会给 LLM 提供具体的输出示范,帮助它更好地理解。
title: str = Field(description='书籍名称', examples=['《三国演义》', '《水浒传》'])
# 定义一个名为 author 的字段,同样带有描述和示例。
author: str = Field(description='作者', examples=['罗贯中', '施耐庵'])
# 定义一个名为 types 的字段,类型为字符串列表 (List[str])。
# 这清晰地告诉 LLM,我们期望这个字段的值是一个包含多个字符串的数组/列表。
types: List[str] = Field(description='类型', examples=[['历史', '小说'], ['动作']])
# --- 环境设置与 Pydantic 解析器初始化 ---
load_dotenv(override=True)
# 创建一个 PydanticOutputParser 的实例。
# 关键步骤:通过 `pydantic_object=BookInfo` 这个参数,我们将解析器与我们上面定义的 BookInfo 类进行了绑定。
# 从现在起,这个 `parser` 的所有工作都将围绕着如何生成和解析一个符合 BookInfo 结构的对象。
parser = PydanticOutputParser(pydantic_object=BookInfo)
# --- 初始化 LLM 和提示词模板 (与之前类似) ---
llm = ChatOpenAI(...)
prompt = ChatPromptTemplate.from_messages([
('system', '{instruction}'),
('human', '书籍介绍如下所示:\n{introduction}')
])
# --- 构建链并执行 ---
# 链的结构仍然是三段式: prompt | llm | parser
chain = prompt | llm | parser
# 从用户处获取需要解析的书籍介绍文本。
introduction = input('请输入书籍介绍:')
result = chain.invoke({
# 'instruction' 字段的值,我们动态地传入 `parser.get_format_instructions()`。
# 这个方法是 PydanticOutputParser 的“魔法”所在:它会自动检查我们绑定的 BookInfo 类,读取所有字段(title, author, types)、
# 它们的类型(str, List[str])、以及我们用 Field 提供的所有描述和示例,然后自动生成一个非常详细、包含 JSON Schema 的指令字符串。
# 这个复杂的指令会被填充到提示模板的 {instruction} 位置,精确地告诉 LLM 如何构建一个符合我们要求的 JSON 对象。
'instruction': parser.get_format_instructions(),
# 'introduction' 字段则填充用户输入的文本。
'introduction': introduction
})
# 打印链的最终输出结果。
# `result` 已经不是一个简单的字符串或字典了。
# `parser` 在接收到 LLM 返回的 JSON 格式字符串后,会做两件事:
# 1. **验证 (Validate)**: 检查返回的 JSON 是否完全符合 BookInfo 类的结构和类型要求。
# 2. **转换 (Parse)**: 如果验证通过,它会将 JSON 转换为一个真正的、活生生的 BookInfo Python 对象实例。
print("解析后的对象:", result)
# 打印 `result` 变量的类型。
# 输出将会是 <class '__main__.BookInfo'>,而不是 <class 'dict'> 或 <class 'str'>。
# 这证明我们得到了一个我们自己定义的类的实例。
print("结果的数据类型:", type(result))
# 因为 result 是一个 BookInfo 对象,我们可以像操作普通 Python 对象一样方便地访问它的属性。
# 这就是 PydanticOutputParser 带来的最大便利。
print(f"书名: {result.title}")
print(f"作者: {result.author}")
print(f"类型: {result.types}")
RAG - 检索增强生成
RAG的步骤如下: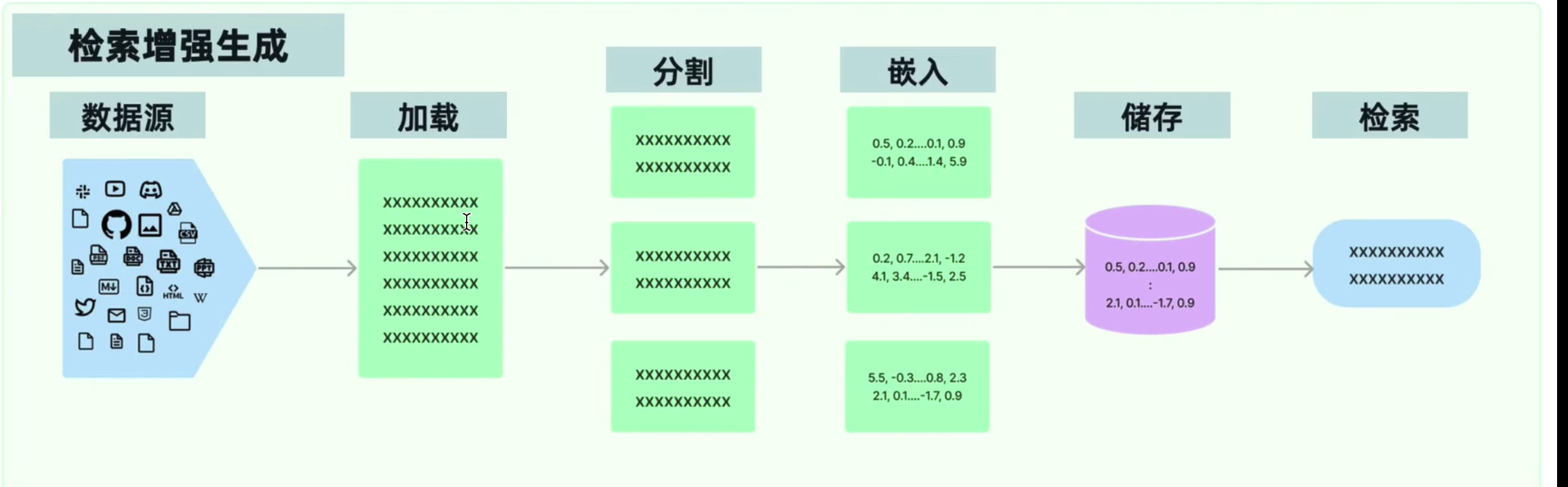
1. 加载外部文档
from dotenv import load_dotenv
from langchain_community.document_loaders import TextLoader, PyPDFLoader, WikipediaLoader
from langchain_community.utilities import GoogleSerperAPIWrapper
# --- 场景一:读取本地的TXT文件 ---
# 1. 初始化TextLoader,并指定要加载的本地文件名。
# TextLoader专门用于处理纯文本(.txt)文件。
loader = TextLoader('异世之全能死神.txt')
# 2. 调用.load()方法,该方法会读取整个文件内容,并将其封装成一个包含一个或多个Document对象的列表。
docs = loader.load()
# 3. 遍历这个列表(通常对于TXT文件,列表中只有一个Document)。
for doc in docs:
# 打印Document对象的核心属性`.page_content`,即文件的文本内容。
print(doc.page_content)
# --- 场景二:读取本地的PDF文件 ---
# 1. 初始化PyPDFLoader,指向本地的PDF文件名。
# PyPDFLoader能够解析PDF格式,并提取其中的文本。
loader = PyPDFLoader('SAGIN_database.pdf')
# 2. 再次调用.load()方法。对于PDF,此方法通常会将每一页的内容都解析成一个独立的Document对象,并放入一个列表中。
docs = loader.load()
# 3. 使用enumerate遍历列表,这样可以同时获得索引(i)和Document对象(doc)。
for i, doc in enumerate(docs):
# 使用f-string和字符串的.center()方法,打印出一个美观的页码标题。
print(f'Page {i+1}'.center(80, '-'))
# 打印当前页的文本内容。
print(doc.page_content)
# --- 场景三:从在线维基百科加载内容 ---
# 1. 初始化WikipediaLoader,这是一个能直接从维基百科API获取数据的加载器。
# - query: 指定要搜索的维基百科词条。
# - load_max_docs: 限制加载的相关文章数量,这里只取最相关的一篇。
# - doc_content_chars_max: 限制从每篇文章中提取的字符数,防止内容过长。
loader = WikipediaLoader(query='艾伦 图灵', load_max_docs = 1, doc_content_chars_max=2000)
# 2. 调用.load()方法,它会连接维基百科服务器,获取数据并封装成Document对象。
docs = loader.load()
# 3. 遍历并打印加载到的文章内容。
for i, doc in enumerate(docs):
print(f'Page {i+1}'.center(80, '-'))
print(doc.page_content)
# --- 场景四:进行实时在线搜索 ---
# 1. load_dotenv()会查找项目目录下的.env文件,并加载其中的环境变量。
# 这是为了安全地使用API Key,而无需将其硬编码在代码中。
# (需要你在.env文件中预先设置好`SERPER_API_KEY="你的密钥"`)
load_dotenv(override=True)
# 2. 初始化GoogleSerperAPIWrapper,这是一个LangChain工具,封装了对Google Serper搜索API的调用。
# 它会自动在环境变量中寻找`SERPER_API_KEY`。
wrapper = GoogleSerperAPIWrapper()
# 3. 调用.run()方法,并传入你的搜索查询。
# 该方法会执行一次实时搜索,并返回一个经过处理的、简洁的文本摘要结果。
result = wrapper.run(query='沈阳')
print(result)
2. 加载 + 切割 + 嵌入
from langchain_community.document_loaders import TextLoader
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# --- 步骤一:加载文档 ---
# 和之前一样,我们先加载一篇长文本文档。
loader = TextLoader('异世之全能死神.txt')
docs = loader.load()
# --- 步骤二:分割文档(Splitting) ---
# 这是将长文本“化整为零”的关键一步。我们初始化一个“递归字符文本分割器”。
splitter = RecursiveCharacterTextSplitter(
# separators: 定义了分割文本时使用的“断句符”列表,它会按顺序尝试。
# 优先尝试用段落("\n\n")分割,如果切分后的块仍然过长,它会退一步,尝试用句子("\n", "。", "!", "?")分割,以此类推。
# 这确保了我们的文本块尽可能保持语义完整。
separators=["\n\n", "\n", "。", "!", "?", ".", "!", "?", ",", ",", " ", ""],
# chunk_size: 定义了每个文本块的目标大小(以字符为单位)。
# 这个值的设定需要权衡,太小可能丢失上下文,太大可能超出模型限制。1000是一个常用的值。
chunk_size=1000,
# chunk_overlap: 定义了相邻文本块之间的重叠字符数。
# 这非常重要!它可以防止在块的边界处切断一个完整的句子或思想,
# 就像我们看书翻页时,会下意识地回顾上一页的最后一句来连接上下文。
chunk_overlap=100,
)
# .split_documents()方法会接收一个Document列表,并根据我们设置的规则,将它们分割成更多个、更小的Document对象。
texts = splitter.split_documents(docs)
# 我们可以打印一下分割后的块数,看看一本小说被分成了多少部分。
print(f"文档被分成了 {len(texts)} 个文本块。")
# --- 步骤三:文本嵌入(Embedding) ---
# 这是将文本“翻译”成计算机语言(数字)的关键一步。
# 我们初始化一个HuggingFace的嵌入模型。
em_model = HuggingFaceEmbeddings(
# model_name: 指定要从Hugging Face Hub使用的模型。
# 'bert-base-chinese' 是一个经典的、效果不错的中文BERT模型。
# 首次运行时,LangChain会自动从网络下载该模型到本地缓存。
model_name='bert-base-chinese'
)
# 【嵌入操作演示】
# 为了直观地看到嵌入是什么样子的,我们先用几个简单的词来做个示范。
# .embed_documents()方法接收一个字符串列表,并为每个字符串生成一个向量。
embedded_vectors = em_model.embed_documents(['猫', '狗', '大炮'])
# 打印结果,你会看到一个列表,其中包含3个子列表。
# 每个子列表就是对应词语的“语义向量”,它是一长串的数字。
# 对于'bert-base-chinese',每个向量的长度是768。
print(embedded_vectors)
print(f"每个向量的维度是: {len(embedded_vectors[0])}")
# 真正的应用中,我们会对分割后的所有文本块进行嵌入:
# all_vectors = em_model.embed_documents([t.page_content for t in texts])
# 这一步通常会比较耗时,因为它需要用模型对大量文本进行计算。
3. 完整版RAG
import pickle # Python内置的序列化库,FAISS在保存/加载时会用到
from langchain.chains.conversational_retrieval.base import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
# --- 步骤1 & 2:加载与分割文档 ---
# 这两步我们已经很熟悉了,是所有知识库应用的数据准备阶段。
loader = TextLoader('异世之全能死神.txt')
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", "!", "?", ".", "!", "?", ",", ",", " ", ""],
chunk_size=1000,
chunk_overlap=100,
)
texts = splitter.split_documents(docs)
# --- 步骤3:定义词嵌入模型 ---
# 我们选择一个中文嵌入模型,它将负责把所有文本块“翻译”成向量。
em_model = HuggingFaceEmbeddings(model_name='bert-base-chinese')
# --- 步骤4:创建并持久化向量数据库 ---
# 这是将我们的知识“固化”下来,以便未来快速检索的关键。
# !!!注意:以下创建和保存数据库的代码,在第一次成功运行后,就可以注释掉了。
# 1. 创建向量数据库:使用FAISS.from_documents(),它接收文本块和嵌入模型,在内存中完成“文本 -> 向量 -> 索引”的全过程。
db = FAISS.from_documents(texts, em_model)
# 2. 保存到本地:将构建好的向量索引保存到磁盘,方便未来直接加载使用,避免了每次都要重新计算昂贵的嵌入过程。
db.save_local('faiss_index')
# 在后续运行中,我们直接从本地加载已构建好的索引。
db = FAISS.load_local(
'faiss_index',
embeddings=em_model,
# 这是一个安全设置,因为pickle可能加载恶意代码。对于我们自己创建的文件,设为True是安全的。
allow_dangerous_deserialization=True
)
# --- 步骤5:创建检索器(Retriever) ---
# 向量数据库本身只负责存储,而“检索器”则负责根据用户问题,从数据库中提取最相关的文档。
# 它就像一个高效的图书管理员。
retriever = db.as_retriever()
# 我们可以单独测试一下检索器,看看它对于一个问题,会返回哪些相关的原文片段。
print("--- 单独测试检索器 ---")
print(retriever.invoke('异世之全能死神的主人公'))
print("-" * 20)
# --- 步骤6:创建大语言模型(LLM) ---
# 这是我们系统的“大脑”,负责根据检索到的信息和用户问题,生成最终的自然语言回答。
load_dotenv(override=True)
llm = ChatOpenAI(
base_url='https://api.deepseek.com/v1',
model='deepseek-chat',
temperature=0.3
)
# --- 步骤7:创建对话记忆(Memory) ---
# 为了让机器人能够理解上下文,我们需要一个“记忆”组件。
# 如果没有记忆,你问完“主角是谁”,再问“他多大了”,机器人会一头雾水。
memory = ConversationBufferMemory(
memory_key='chat_history', # 告诉Chain,对话历史存储在这个键下。
input_key='question', # 告诉Chain,用户的提问会存放在这个键下。
output_key='answer', # 告诉Chain,LLM的回答会存放在这个键下。
return_messages=True # 设置为True,记忆会以消息对象列表的形式返回,这与LLM的输入格式匹配。
)
# --- 步骤8:创建对话检索链(The Grand Finale!) ---
# 这是我们的“总指挥”,它将所有组件(LLM, Retriever, Memory)串联起来协同工作。
chain = ConversationalRetrievalChain.from_llm(
llm=llm, # 指定“大脑”
retriever=retriever, # 指定“图书管理员”
memory=memory, # 指定“短期记忆”
return_source_documents=True # 设为True,我们能看到回答是基于哪些原文生成的,非常便于调试。
)
# --- 步骤9:开始对话! ---
print("\n--- 开始与小说问答机器人对话 ---")
# 第一次提问
result1 = chain.invoke({'question': '异世之全能死神的主人公是谁?'})
print(f"回答1: {result1['answer']}")
# 第二次提问,这个问题依赖于第一次提问的上下文(“他”指代主角)
# 因为有Memory的存在,Chain能够理解这个指代关系。
result2 = chain.invoke({'question': '他最后和谁在一起了?'})
print(f"回答2: {result2['answer']}")
# 打印最后一次交互的完整结果,深入了解Chain的内部工作。
# 你会看到'question', 'chat_history', 'answer', 'source_documents'等所有信息。
print("\n--- 最后一次交互的完整结果 ---")
print(result2)
4. 进阶版RAG – 用语义相似度实现智能文本分块
传统的文本分块方法(如按固定字符数切割)可能会粗暴地将一个完整的语义单元切断。
本示例将介绍一种更智能的方法:基于相邻句子间语义相似度的“断点检测法”。
核心思想:
当两个相邻句子之间的语义相似度突然大幅下降时,说明这里可能是一个话题的转折点,因此是一个理想的“断点”或“切分点”。
def compute_breakpoints(similarities, method="percentile", threshold=90):
"""
根据句子间的语义相似度,计算文本分块的“断点”。
断点是那些相似度特别低的位置,通常意味着话题的转换。
# --- 步骤 1: 根据选择的方法,计算出一个动态的“相似度阈值” ---
# 我们的目标是找到一个“门槛”,任何低于这个门槛的相似度都被认为是“异常低”。
if method == "percentile":
# 百分位法 (Percentile Method)
# 这种方法非常直观。例如,threshold=10 意味着:我们将所有的相似度分数从小到大排序,取排在后10%位置的那个分数作为阈值。这样,只有最不相似的10%的连接点才会被识别为断点。
threshold_value = np.percentile(similarities, 10) # 找出最低的10%作为断点
elif method == "standard_deviation":
# 标准差法 (Standard Deviation Method)
# 这种方法适用于数据大致呈正态分布的情况。它计算所有相似度的平均值(mean)和标准差(std_dev)。
mean = np.mean(similarities)
std_dev = np.std(similarities)
# 阈值被设定为“平均值减去 N 倍的标准差”。
# 这里的 `threshold` 就扮演了 N 的角色。例如 threshold=1.5 意味着,任何比“平均值低1.5个标准差”的相似度点,都被认为是异常的低点。
threshold_value = mean - (threshold * std_dev)
elif method == "interquartile":
# 四分位距法 (Interquartile Range, IQR Method)
# 这是一种对异常值不敏感的、非常稳健的统计方法。
# 1. 计算出第一四分位数(Q1, 25%位置)和第三四分位数(Q3, 75%位置)。
q1, q3 = np.percentile(similarities, [25, 75])
# 2. 计算四分位距 IQR = Q3 - Q1。
iqr = q3 - q1
# 3. 根据统计学上常用的异常值检测规则,将阈值设定为 Q1 - 1.5 * IQR。
# 任何低于这个“下限”的点都被认为是异常的低点。
threshold_value = q1 - 1.5 * iqr
else:
# 如果传入了不支持的方法名,则抛出错误。
raise ValueError("Invalid method. Choose 'percentile', 'standard_deviation', or 'interquartile'.")
# --- 步骤 2: 找出所有低于阈值的点 ---
# 遍历 `similarities` 列表,使用列表推导式高效地找出所有满足条件的索引。
# `enumerate(similarities)` 会同时返回每个元素的索引 `i` 和值 `sim`。
# `if sim < threshold_value` 是判断条件:如果当前相似度分数低于我们计算出的阈值,那么它的索引 `i` 就是一个“断点”。
return [i for i, sim in enumerate(similarities) if sim < threshold_value]
ReAct 框架
LLMs 以交错的方式 生成推理轨迹和任务特定操作。
生成推理轨迹 使模型能够诱导、跟踪和更新操作计划,甚至处理异常情况。 操作步骤 允许与外部源(如知识库或环境)进行交互并且收集信息。
ReAct 是一个将推理和行为与 LLMs 相结合通用的范例。ReAct 提示 LLMs 为任务生成口头推理轨迹和操作。这使得系统执行动态推理来创建、维护和调整操作计划,同时还支持与外部环境(例如,Wikipedia)的交互,以将额外信息合并到推理中。
from langchain_openai import ChatOpenAI
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from dotenv import load_dotenv
load_dotenv(override=True)
llm = ChatOpenAI(
base_url='https://api.deepseek.com/v1',
model_name="deepseek-chat",
temperature=0
)
# 为 Agent 准备“工具箱”
# 'google-serper' - 搜索工具
# 'llm-math' - 数学计算工具
tools = load_tools(["google-serper", "llm-math"], llm=llm)
# “组装”和“激活”我们 Agent
# initialize_agent 函数就像一个“Agent 工厂”,它接收我们提供的零件(工具、大脑),并按照指定的“设计图纸”(agent 类型)来组装出一个完整的、可以工作的 Agent。
# tools:告诉 Agent:“这是你的工具箱,你可以根据需要使用里面的任何工具。”
# agent="zero-shot-react-description" -- 这是“设计图纸”,指定了我们要创建的 Agent 的类型和工作方式。这个名字可以拆解为:
# zero-shot (零样本): 意味着我们不需要给 Agent 提供任何如何使用工具的范例。它需要依靠 LLM 自身的推理能力,以及工具的描述,来决定何时、如何使用工具。
# ReAct: 这是这个 Agent 遵循的核心思想框架,是 Reasoning (推理) 和 Acting (行动) 的缩写。ReAct 框架的工作流程是一个循环:
# 1. Thought (思考): LLM 首先会思考它需要做什么来回答问题。
# 2. Action (行动): 基于思考,LLM 决定使用哪个工具,以及该工具的输入是什么。
# 3. Observation (观察): 执行工具后,得到一个结果(比如搜索结果或计算结果),这个结果被称为“观察”。
# 4. Thought (再次思考): LLM 观察到结果后,会再次思考:“这个结果足够回答问题了吗?如果不够,我的下一步行动应该是什么?”
# 5. 这个循环会一直持续,直到 LLM 认为它已经收集到足够的信息,可以给出最终答案为止。
# description: 指的是 Agent 在决定使用哪个工具时,会依赖我们在工具中提供的描述(description)。每个工具都有一个描述,比如“用于进行网络搜索”或“用于进行数学计算”。
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
result = agent.invoke({"input": "奥利维亚·王尔德的男朋友是谁?他现在的年龄的0.23次方是多少?"})
print(result)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)