大模型应用开发工程师需要学什么
大模型,全称「大语言模型」,英文「Large Language Model」,缩写「LLM」。AI 全栈课程主要以 OpenAI 为例,少量介绍国产大模型,微调会用开源大模型。OpenAI 的接口名就叫「completion」,也证明了其只会「生成」的本质。然后用测试数据,在可以选择的模型里,做测试,找出最合适的。用人类比,训练就是学,推理就是用。很多企业将大模型和业务相结合,取得了或大或小的效果
大模型全栈知识体系

先了解个大概,后续会把这些知识全部总结出来。
大模型能干什么
大模型,全称「大语言模型」,英文「Large Language Model」,缩写「LLM」。
- 大模型就是一个函数,给输入,生成输出
- 任何可以用语言描述的问题,都可以输入文本给大模型,就能生成问题的结果文本
- 进而,任意数据,都可以输入给大模型,生成任意数据
大模型落地场景
很多企业将大模型和业务相结合,取得了或大或小的效果
- 营销
- AI 做营销创意,人再加工
- AI 批量生产营销素材
- 多语言翻译
- 客服/销售
- 全 AI,适合本来没人做,AI 来补位
- 半 AI,适合本来有人做,AI 来提效
- 办公
- 公文撰写/总结/翻译
- 知识库
- 内部客服
- 辅助决策
- 情报分析
- BI
- 产品研发
- 创意、头脑风暴
- IT 研发提效
大模型是怎么工作的
通俗原理
其实,它只是根据上文,猜下一个词(的概率)……
OpenAI 的接口名就叫「completion」,也证明了其只会「生成」的本质。
略深一点的通俗原理
训练和推理是大模型工作的两个核心过程。
用人类比,训练就是学,推理就是用。学以致用,如是也。
用不严密但通俗的语言描述原理:
- 大模型阅读了人类说过的所有的话。这就是「机器学习」
- 训练过程会把不同 token 同时出现的概率存入「神经网络」文件。保存的数据就是「参数」,也叫「权重」
- 我们给推理程序若干 token,程序会加载大模型权重,算出概率最高的下一个 token 是什么
- 用生成的 token,再加上上文,就能继续生成下一个 token。以此类推,生成更多文字
Token 是什么?
- 可能是一个英文单词,也可能是半个,三分之一个
- 可能是一个中文词,或者一个汉字,也可能是半个汉字,甚至三分之一个汉字
- 大模型在开训前,需要先训练一个 tokenizer 模型。它能把所有的文本,切成 token
再深一点点
- 这套生成机制的内核叫「Transformer 架构」
- Transformer 是目前人工智能领域最广泛流行的架构,被用在各个领域
- Transformer 仍是主流,但并不是最先进的
| 架构 | 设计者 | 特点 | 链接 |
|---|---|---|---|
| Transformer | 最流行,几乎所有大模型都用它 | OpenAI 的代码 | |
| RWKV | PENG Bo | 可并行训练,推理性能极佳,适合在端侧使用 | 官网、RWKV 5 训练代码 |
| Mamba | CMU & Princeton | 性能更佳,尤其适合长文本生成 | GitHub |
| Test-Time Training (TTT) | Stanford, UC San Diego, UC Berkeley & Meta AI | 速度更快,长上下文更佳 | GitHub |
目前只有 transformer 被证明了符合 scaling-law。
大模型应用技术架构
大模型应用技术特点:门槛低,天花板高。
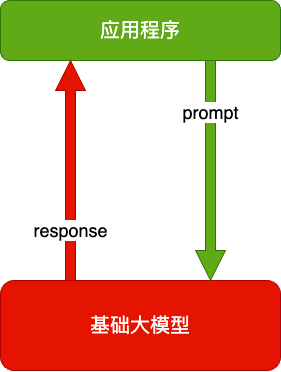
纯 Prompt
- Prompt 是操作大模型的唯一接口
- 当人看:你说一句,ta 回一句,你再说一句,ta 再回一句……
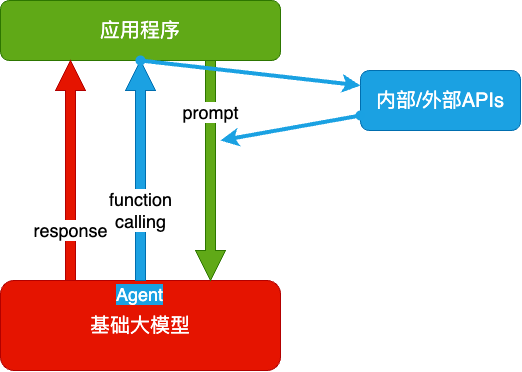
Agent + Function Calling
- Agent:AI 主动提要求
- Function Calling:AI 要求执行某个函数
- 当人看:你问 ta「我明天去杭州出差,要带伞吗?」,ta 让你先看天气预报,你看了告诉 ta,ta 再告诉你要不要带伞
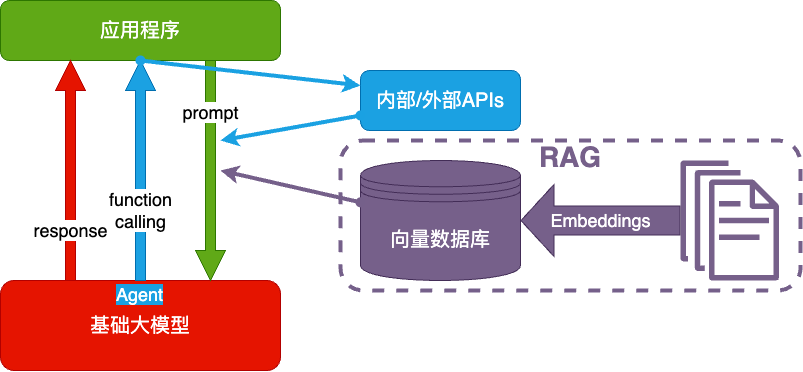
RAG(Retrieval-Augmented Generation)
- Embeddings:把文字转换为更易于相似度计算的编码。这种编码叫向量
- 向量数据库:把向量存起来,方便查找
- 向量搜索:根据输入向量,找到最相似的向量
- 当人看:考试答题时,到书上找相关内容,再结合题目组成答案,然后,就都忘了
Fine-tuning(精调/微调)
当人看:努力学习考试内容,长期记住,活学活用。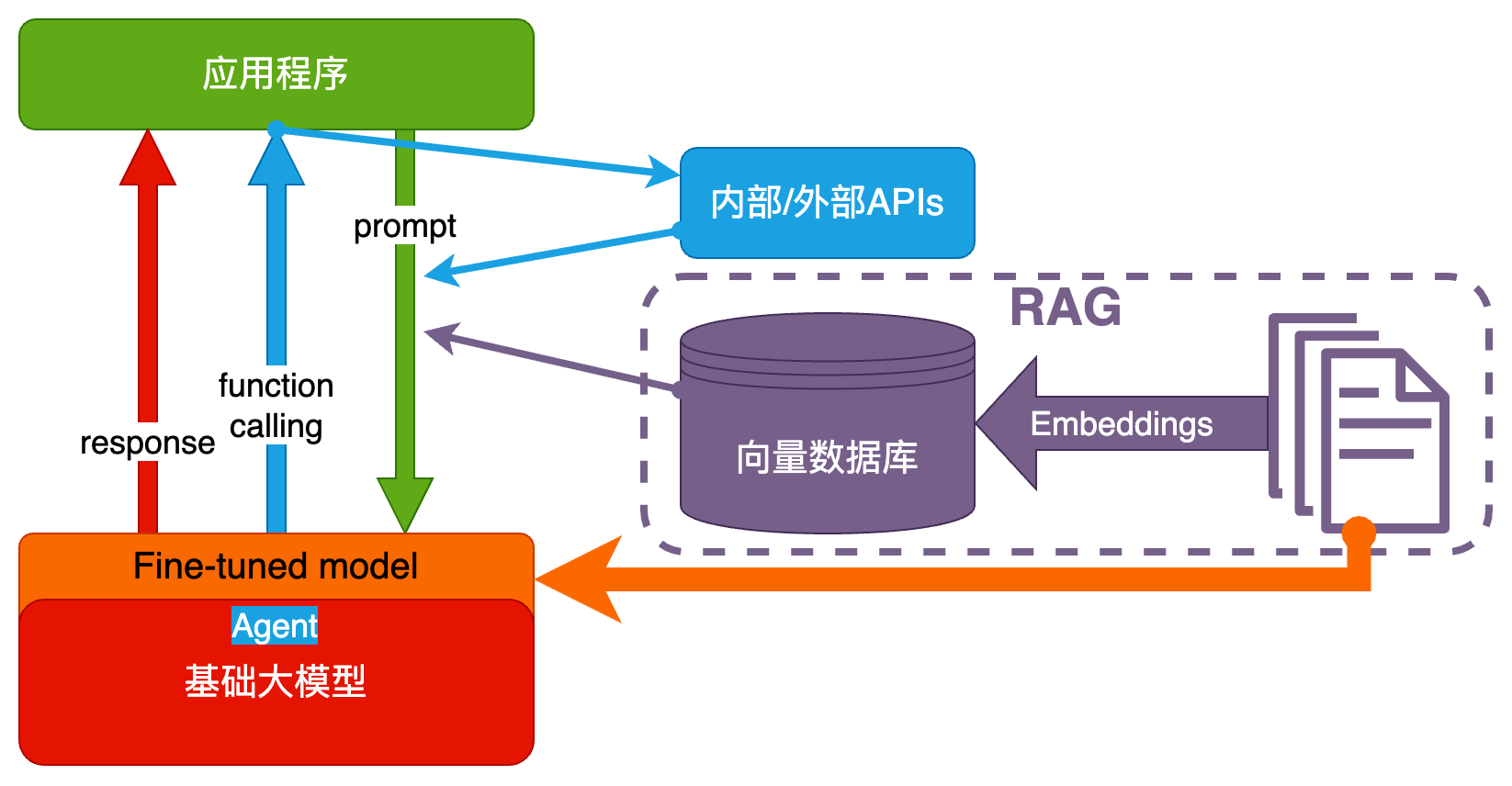
如何选择技术路线
面对一个需求,如何开始,如何选择技术方案?下面是个不严谨但常用思路。
其中最容易被忽略的,是准备测试数据
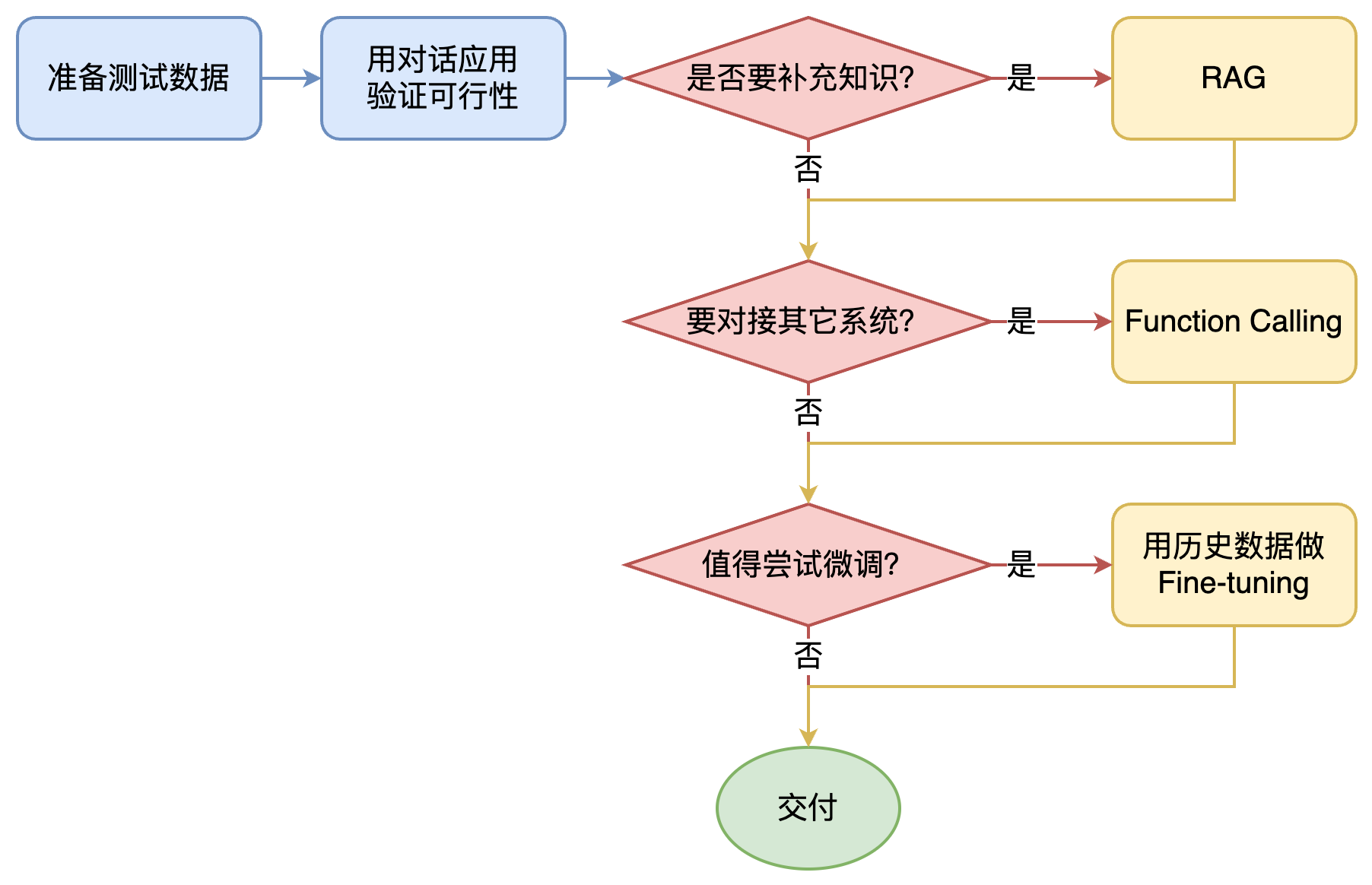
值得尝试 Fine-tuning 的情况:
- 提高模型输出的稳定性
- 用户量大,降低推理成本的意义很大
- 提高大模型的生成速度
- 需要私有部署
如何选择基础模型
凡是问「哪个大模型最好?」的,都是不懂的。
不妨反问:「有无论做什么,都表现最好的员工吗?」
基础模型选型,合规和安全是首要考量因素。
| 需求 | 国外闭源大模型 | 国产闭源大模型 | 开源大模型 |
|---|---|---|---|
| 国内 2C | 🛑 | ✅ | ✅ |
| 国内 2G | 🛑 | ✅ | ✅ |
| 国内 2B | ✅ | ✅ | ✅ |
| 出海 | ✅ | ✅ | ✅ |
| 数据安全特别重要 | 🛑 | 🛑 | ✅ |
然后用测试数据,在可以选择的模型里,做测试,找出最合适的。
AI 全栈课程主要以 OpenAI 为例,少量介绍国产大模型,微调会用开源大模型。因为:
- OpenAI 最流行,即便国内也是如此
- OpenAI 最先进
- 其它模型都在追赶和模仿 OpenAI
- 学会 OpenAI,其它模型触类旁通
- 反之,不一定

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)