知识图谱落地!纯本地接入大模型+RAG框架中!
本文详细介绍了如何在本地部署知识图谱,并将其接入开发环境。主要内容包括:配置本地大语言模型(LLM)和中文文本嵌入模型,连接NebulaGraph数据库并创建图空间,使用llama_index加载本地文档并构建图索引,将知识图谱数据存储到NebulaGraph中,并通过可视化工具生成HTML格式的知识图谱。此外,文章还对比了常规向量语义查询和知识图谱查询的结果,展示了知识图谱在提高回答准确性方面的
今天先进行各部分解析,然后附上了完整代码文件、环境配置以及运行操作说明,想跳过解析下文件直接跑的话,请跳转看这里:四、完整代码及操作说明
昨天在本地部署知识图谱,今天要把他接入到开发
完整代码,已上传“灵丹”资料盘,会员直接到末尾找工程师-小胖
一、任务概述总览
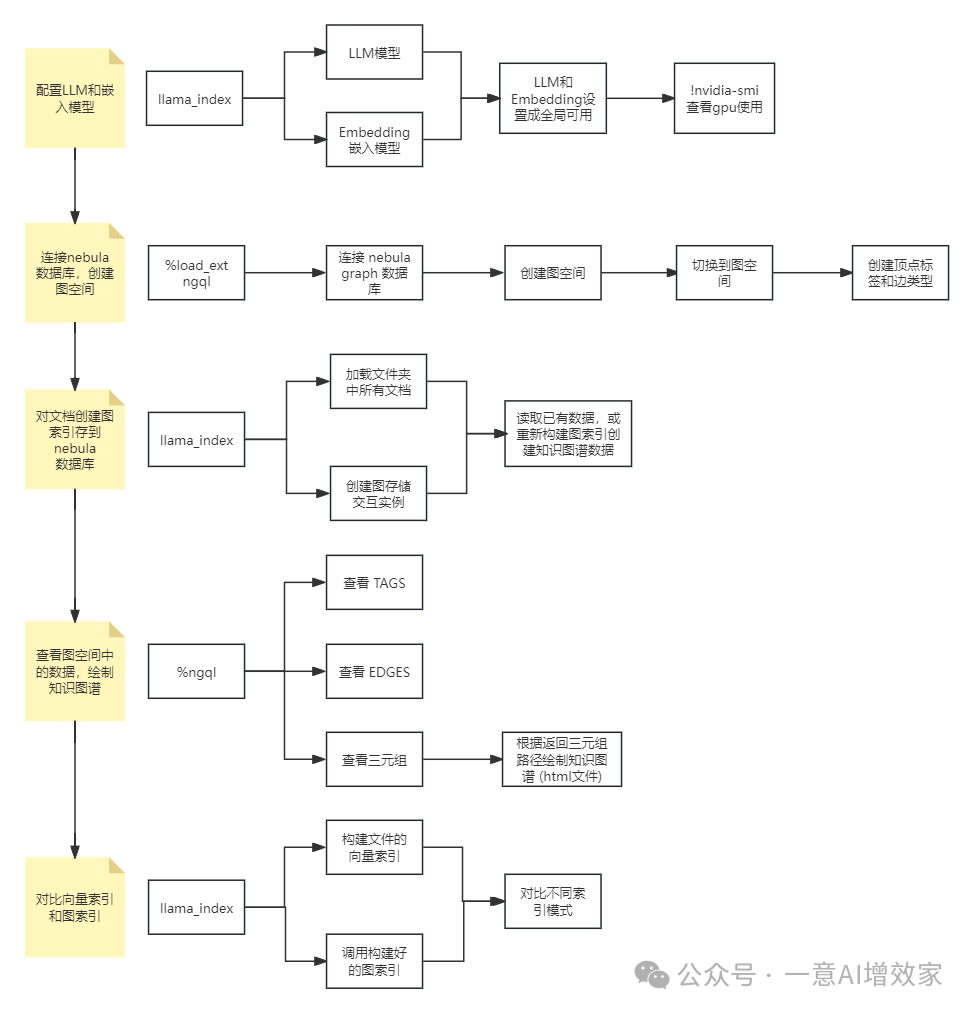
本章内容,我们主要讲述如何在本地接入大模型和文本编码模型,并利用模型对现有文件生成知识图谱数据,并将知识图谱数据接入到 RAG 框架中提高回答准确性。我们的流程如下:
-
配置本地大语言(LLM)模型和中文文本嵌入(Embedding)模型。
-
连接本地知识图谱数据库 Nebula Graph 并创建 “wukong” 图空间。
-
使用 llama_index 加载本地文件夹中的文档,构建图索引并保存到 nebula 数据库的图空间。
-
查看保存到 nebula 数据库 “wukong” 的数据,并绘制知识图谱可视化的 html 格式文件。
-
对比常规向量语义查询的结果和知识图谱的查询结果。
二、本节流程图
三、流程图+代码详细解析
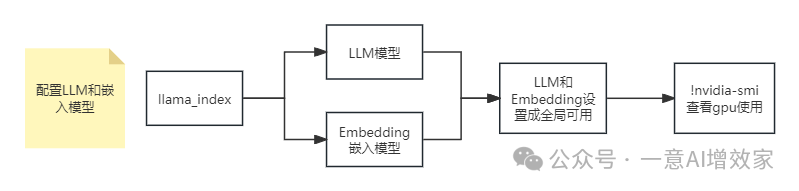
3.1 配置本地大语言(LLM)模型和嵌入(Embedding)模型
在这一部分,我们会进行本地大语言模型和中文文本嵌入模型的配置,配置好了之后就可以接入我们的RAG系统,对文档内容处理生成知识图谱数据了。
# 导入nest_asyncio模块,该模块允许在同一进程中运行多个异步事件循环。import nest_asyncio# 应用nest_asyncio,这将修补默认的asyncio事件循环策略,# 使其支持在已经运行的事件循环中再创建新的事件循环。nest_asyncio.apply()配置本地 LLM 模型:
# 从 vLLM 模块中导入 Vllm 类,vLLM 是一个高性能的推理引擎,专门用于大语言模型。from llama_index.llms.vllm import Vllm# 创建一个 Vllm 实例,初始化参数如下:llm = Vllm( # 模型路径,指定模型的具体位置。在这里,我的模型位于 /home/iip/.cache/modelscope/hub/qwen/Qwen2-7B-Instruct-GPTQ-Int4,添加你自己的位置即可 model="/home/iip/.cache/modelscope/hub/qwen/Qwen2-7B-Instruct-GPTQ-Int4", # 数据类型的设定,不同模型会有所不同。在这里,Qwen2-7B-Instruct-GPTQ-Int4 模型支持使用 float16 类型 dtype="float16", # 张量并行的大小,用于在多个 GPU 上分割模型。在这里,设置为 1,表示不在多个 GPU 上分割模型 tensor_parallel_size=1, # 温度参数,取值范围 0-1,用于控制生成文本的随机性。温度为 0 表示确定性生成,即每次生成相同的结果 temperature=0.1, # 最大生成的新标记数,用于限制生成文本的最大长度 max_new_tokens=100, # 传递给 vLLM 的额外关键字参数,用于进一步配置模型 vllm_kwargs={ # 交换空间大小,当 gpu 显存不足时,swap_space 允许将部分内存数据存储在 CPU 上,1 代表 1GB。 "swap_space": 1, # GPU 内存利用率,用于控制 GPU 内存的使用比例。在这里,设置为 0.8,尤其是在多进程或多用户环境,在此为编码模型保留一部分可用显存 "gpu_memory_utilization": 0.8, # 最大模型长度,用于限制输入序列的最大长度。在这里,设置为 8192 "max_model_len": 8192, })配置中文文本嵌入(Embedding)模型,对于文本数据,我们如果将其编码成向量数据需要专门的嵌入模型,此处我们对文本嵌入模型进行配置,使用的是 text2vec-large-chinese 模型:
# 从 llama_index 的 embeddings 模块中导入 HuggingFaceEmbedding 类# HuggingFaceEmbedding 类用于初始化和配置 Hugging Face 的嵌入模型from llama_index.embeddings.huggingface import HuggingFaceEmbedding# 定义嵌入模型的配置参数embed_args = { # 指定使用的预训练模型名称 'model_name': 'GanymedeNil/text2vec-large-chinese', # 设置输入文本的最大长度为 512,超过这个长度的文本将会被截断。 'max_length': 512, # 设置批量嵌入的批次大小。在这里,设置为 64,即一次处理 64 个文本样本 'embed_batch_size': 64, 为了让 LLM 和 Embedding 在代码文档中的每处都可用,我们将其设置为全局可用:
from llama_index.core import Settings# 把加载的模型添加到环境设置中,定义全局模型。Settings 类用于配置全局设置,可以用来保存和管理全局变量。# 此处将刚刚设置的语言模型(LLM)和嵌入模型(Embedding Model)定义为全局可用。Settings.llm = llmSettings.embed_model = embed_model配置好模型之后,我们可以通过 !nvidia-smi 命令查看当前 gpu 的使用情况,可以看到,加载了大语言模型和文本嵌入模型之后,12G 的显存已经占用了将近 10G:
!nvidia-smi输出解释
NVIDIA-SMI 版本:显示当前 NVIDIA-SMI 的版本、驱动程序版本和 CUDA 版本。GPU 信息:Name:显示 GPU 的型号。Persistence-M:显示 GPU 的持久模式状态。Bus-Id:显示 GPU 的 PCI Bus ID。Disp.A:显示 GPU 是否被用作显示设备。Volatile Uncorr. ECC:显示易失性未校正的 ECC 错误。状态信息:Fan:显示风扇转速百分比。Temp:显示 GPU 温度。Perf:显示性能状态。Pwr:Usage/Cap:显示当前功耗和最大功耗。Memory-Usage:显示当前 GPU 内存使用情况。GPU-Util:显示 GPU 使用率。Compute M.:显示当前计算模式。MIG Mode:显示 MIG 模式状态。进程信息:列出正在使用 GPU 的进程及其占用的 GPU 内存。使用场景检查 GPU 状态:在运行深度学习模型或任何 GPU 密集型任务之前,可以使用 nvidia-smi 来检查 GPU 的状态,确保 GPU 没有被其他进程占用。监控 GPU 使用情况:在任务运行过程中,可以定期执行 nvidia-smi 命令来监控 GPU 的使用情况,确保资源得到有效利用。3.2 连接知识图谱数据库
在这一部分,我们会通过在 jupyter 中连接 nebula 数据库,并利用 nebula 的专用语言 ngql 创建新的图空间 “wukong” 来放置我们的数据。

加载 ngql 扩展,并使用 ngql 连接到 nebula graph 数据库:
# 使用 Jupyter Notebook 的魔法命令加载 ngql 扩展%load_ext ngql# 使用 ngql 魔法命令连接到 Nebula Graph 数据库# %ngql 告诉环境接下来的代码块应该被当作 NGQL 语句来执行# 指定数据库的地址、端口、用户名和密码。默认情况下,身份认证功能是关闭的,只能使用已存在的用户名(默认为root)和任意密码登录。%ngql --address 127.0.0.1 --port 9669 --user root --password nebula
Jupyter Notebook 默认只认识标准的编程语言语法(如 Python)。如果不加载扩展,它无法识别 %ngql 或者直接的 ngql 语句。
加载扩展 %load_ext ngql 的作用是告诉 Jupyter Notebook,接下来我要使用一个名为 ngql 的新功能,这个功能就是 %ngql 魔法命令。通俗解释魔法命令
加载扩展之后,Jupyter Notebook 就能够识别 %ngql 并正确地处理它,允许你在 Jupyter Notebook 中执行 NGQL 语句。
我们在这一步设置一个存储该项目数据的 “wukong” 图空间,如果不存在我们将会创建该空间(存在则跳过):
# 如果 "wukong" 图空间(知识图谱)不存在,则使用 ngql 魔法命令创建一个名为 "wukong" 的图空间# 指定顶点 ID (vertex ID) 的类型为长度为 256 的固定字符串# 设置分区数量为 1# 设置副本因子为 1,即只保留一个副本%ngql CREATE SPACE IF NOT EXISTS wukong(vid_type=FIXED_STRING(256), partition_num=1, replica_factor=1);-
在 NebulaGraph 中,VID(Vertex ID)是用于唯一标识图中的每个顶点(节点)的标识符。在创建图空间时,VID 的类型可以通过 vid_type 参数指定,可以是 FIXED_STRING(<N>) 或 INT64。
-
vid_type=FIXED_STRING(256):这表示每个顶点的 ID 必须是一个定长字符串,长度为 256 字节。换句话说,所有的 VID 都会被存储为 256 字节的字符串。如果插入的字符串长度不足 256 字节,系统会自动用空字节填充。如果你有一个用户的唯一标识符是 "user123",在插入时,系统会将其存储为 "user123" 后面跟着空字节,一共占用256个字节。
-
vid_type=INT64:表示图空间中的点 ID(VID)将被定义为 64 位有符号整数。如果你使用整数作为 VID,可以直接插入一个数字。
-
-
分区(Partitioning)
-
提高并发处理能力:将数据切分成多个分区可以提高系统的并发处理能力。每个分区可以独立处理请求,从而提高整体的处理速度。
-
负载均衡:分区可以帮助负载均衡,避免数据集中在一个节点上导致性能瓶颈。
-
分区是分布式系统中常用的一种技术,用于将数据切分成多个部分,并将这些部分存储在不同的节点(通常是计算机)上。分区的主要目的是:
-
-
常见的分区数量范围
-
小规模数据:如果数据量较小(例如几百万顶点和边),可以选择较少的分区数量,通常 1 到 4 个分区就足够了。
-
中等规模数据:如果数据量中等(例如几千万顶点和边),可以选择较多的分区数量,通常 4 到 16 个分区是比较常见的。
-
大规模数据:如果数据量很大(例如数亿甚至数十亿顶点和边),可以选择更多的分区数量,通常 16 到 128 个分区是比较常见的。
-
-
副本(Replication)
-
提高可靠性:通过为每个分区创建多个副本,可以确保即使某个节点发生故障,数据仍然可以被访问。
-
容错能力:当一个节点失效时,可以从其他节点的副本中恢复数据,确保系统的持续可用性。比如为每个分区创建多个副本,每个副本存储在不同的节点上,一个节点坏了依然能正常运行。
-
副本是另一种分布式系统中常用的技术,用于提高数据的可靠性和容错能力。副本的主要目的是:
-
-
常见副本选择范围:
-
对于一般的数据,通常选择 replica_factor=3 已经足够。
-
如果资源有限,可以选择较低的副本数量,如 replica_factor=2。
-
切换到新建的 “wukong” 图空间,后期便可以利用 ngql 语言来查看我们存储到 nebula 数据库中的顶点、边等数据内容:
# USE 语句用于切换到指定的图空间(知识图谱)%ngql USE wukong;
创建定点标签和边,并且暂停10s等待创建完成:
# 创建名为 'entity' 的顶点标签,如果尚不存在的话%ngql CREATE TAG IF NOT EXISTS entity(name string);# 创建名为 'relationship' 的边类型,并定义一个字符串属性 'label',如果尚不存在的话%ngql CREATE EDGE IF NOT EXISTS relationship(label string);# 等待 10 秒,用于确保数据已经被正确创建完成import timetime.sleep(10) # 暂停执行 10 秒3.3 加载本地文档,构建图索引并保存到图数据库
在这一部分,我们会加载本地的文档,并且创建一个图存储实例,这个图存储实例就是我们刚刚创建的 “wukong” 图空间,然后我们就可以通过大语言模型来利用加载的本地文档,去构建图索引数据,并且将 llama_index 会将构建的图索引数据通过刚刚建立的与数据库的连接存储到 nebula 数据库中。
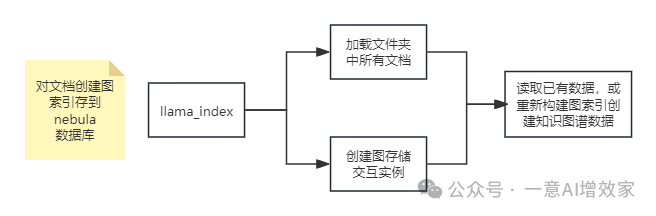
首先,我们需要先加载本地 data 文件夹中的多个 txt 文件,llama_index 将会读取这些文件,为后边处理成知识图谱做准备:
# 从 llama_index.core 模块中导入 SimpleDirectoryReader 类# SimpleDirectoryReader 用于读取目录中的文档from llama_index.core import SimpleDirectoryReader# 加载本地数据# 使用 SimpleDirectoryReader 读取指定目录中的所有文档# load_data() 方法用于加载这些文档,本案例用的 txt 文件。除此之外,还可读取 csv, docx, epub, jpeg, mp3, pdf等文件。documents = SimpleDirectoryReader("./data").load_data()设置连接 nebulagraph 的信息包括:用户名、密码、ip、图空间、关系类型、关系属性、实体标签等。并创建图存储交互实例:
from llama_index.graph_stores.nebula import NebulaGraphStore # 用于连接和操作 Nebula Graph 图数据库# 设置环境变量以存储 Nebula Graph 的认证信息# 当使用 Python 客户端工具连接到 Nebula Graph 数据库时,会使用这些信息进行身份验证os.environ["NEBULA_USER"] = "root" # Nebula Graph用户名os.environ["NEBULA_PASSWORD"] = "nebula" # Nebula Graph密码os.environ["NEBULA_ADDRESS"] = "127.0.0.1:9669" # Nebula Graph数据库的地址和端口号# 配置 Nebula Graph 知识图谱的相关信息,如图空间名称、边类型、关系属性、节点标签space_name = "wukong" # 知识图谱空间名称edge_types = ["relationship"] # 定义图中关系的类型(边)rel_prop_names = ["label"] # 关系属性名称tags = ["entity"] # 定义图中实体的标签# 创建一个 NebulaGraphStore 实例,负责与 Nebula Graph 图数据库进行交互# 创建 StorageContext 实例,用于配置图存储上下文,包括持久化存储目录和图存储实例from llama_index.core.storage.storage_context import StorageContextstorage_context = StorageContext.from_defaults( graph_store=graph_store, # 使用上面定义的 NebulaGraphStore 作为图存储实例)如果检测到本地又持久化的索引数据文件夹 “storage_graph” 就直接读取,否则加载的文件夹中的文档,并构建图索引,LLM 会自动帮我们将 txt 中的数据解析成知识图谱数据,通过图存储实例 graph_store 将解析成知识图谱存储到 nebula 数据库:
from llama_index.core.storage.storage_context import StorageContext # 存储上下文管理from llama_index.core import load_index_from_storage, SimpleDirectoryReader, KnowledgeGraphIndex # 加载索引、读取文档、知识图谱索引import loggingtry: # 尝试从持久化目录加载已存在的索引 storage_context = StorageContext.from_defaults( persist_dir="./storage_graph", # 持久化存储目录 graph_store=graph_store, # 使用前面创建的Nebula Graph存储 ) kg_index = load_index_from_storage( storage_context=storage_context, max_triplets_per_chunk=50, # 每个分块最多包含的三元组数量 space_name=space_name, edge_types=edge_types, rel_prop_names=rel_prop_names, tags=tags, verbose=True, # 输出详细信息 ) index_loaded = Trueexcept Exception as e: # 如果加载失败,打印错误并设置index_loaded为False logging.error(f"索引加载失败: {e}") index_loaded = False3.4 查看图数据库并可视化
在这一部分,我们先用 nebula 的语言 ngql 来操作数据库,查询大语言模型解析出来的知识图谱数据,看一下 LLM设置的默认提示词帮我们解析出来的 TAGS,EDGES 以及观察所有的三元组路径,并且把这些三元组绘制成可视化的图,图是 html 格式。
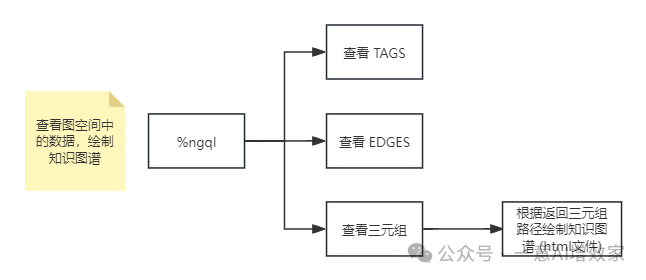
首先,我们查看利用数据库 “wukong” 图空间中的标签信息:
# 使用 ngql 魔法命令执行 NGQL 语句# SHOW TAGS 语句用于列出图空间中的所有标签(顶点类型)"""使用场景查看图空间结构:当你需要查看当前图空间中定义了哪些标签(顶点类型)时,可以使用 SHOW TAGS 命令。调试和验证:在进行图数据库的操作时,查看图空间中的标签可以帮助你验证数据结构是否符合预期。"""# 刚刚已经切换到了名为 wukong 的图空间,并且需要查看该图空间中的所有标签(顶点类型)%ngql SHOW TAGS接着,查看利用现有数据构建好数据库的边信息:
# 使用 ngql 魔法命令执行 NGQL 语句# SHOW EDGES 语句用于列出图空间中的所有边类型"""使用场景查看图空间结构:当你需要查看当前图空间中定义了哪些边类型时,可以使用 SHOW EDGES 命令。"""%ngql SHOW EDGES查看顶点与边之间的关系,并且返回顶点的 name 属性以及边的 labe 属性,让我们可以直观的看到返回的内容:
# 查询并返回图数据库中实体间的关系路径# 本查询将匹配所有从一个节点(v)出发,通过任意类型关系(r)到达另一个节点(t)的路径。# 对于每条匹配到的路径,返回源节点的名称(v.entity.name)作为`src`,# 关系的标签(r.label)作为`relation`,目标节点的名称(t.entity.name)作为`dest`。# 结果限制为最多1000条记录。%ngql MATCH p=(v)-[r]->(t) RETURN v.entity.name AS src, r.label AS relation, t.entity.name AS dest LIMIT 1000;查看完整的三元组数据包括:类型、属性 在内的完整路径:
# 查询图数据库中的路径并返回# 本查询匹配从一个节点(v)出发,通过任意类型的关系(r)到达另一个节点(t)的所有路径。# 使用`MATCH`子句定义了路径模式p=(v)-[r]->(t),其中v是起始节点,r是连接v和t的关系,t是目标节点。# `RETURN p`表示返回整个路径p,包含了起始节点、关系以及目标节点的信息。# `LIMIT 1000`限制了结果集的大小,确保最多返回1000条路径。%ngql MATCH p=(v)-[r]->(t) RETURN p LIMIT 1000;使用 ng_draw 魔法命令执行图形绘制功能,对 “wukong” 图空间中的三元组数据,生成能进行知识图谱可视化的 html 文件。此处将会根据查询返回的内容进行绘图,图片会以 html 格式的文件存储:
# 绘制图数据库中实体之间的关系图# 本查询使用`ng_draw`魔法命令来可视化从一个类型为`entity`的节点出发,# 通过任意`relationship`类型的关系到达另一个类型为`entity`的节点的所有路径。# 查询将返回最多1000条这样的路径,并且这些路径将会被绘制出来。%ng_draw MATCH p=(v:entity)-[r:relationship]->(t:entity) RETURN p LIMIT 1000;3.5 对比常规向量语义查询和知识图谱查询
在这一部分,我们将会构建文本的向量索引,以及调用利用知识图谱数据构建好的图索引,对照看一下二者调用方式以及对比不同索引模式下的不同结果。
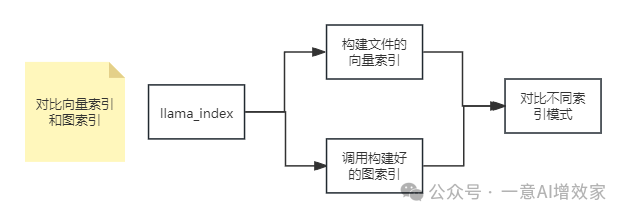
首先,从加载的文档 documents 构建向量索引:
# 导入VectorStoreIndex类,这是llama_index库中的一个核心组件,用于创建向量存储索引from llama_index.core import VectorStoreIndex# 创建一个VectorStoreIndex实例,该实例是从提供的文档集合(documents)构建的# documents 是一个包含Document对象的列表,这些对象包含了索引所需的数据vector_index = VectorStoreIndex.from_documents(documents)构建向量查询引擎,向量查询引擎会将用户的问题转换为向量,和向量索引 node 进行比对,通过计算找到相似性比较高的 node,然后把 node 向量转换为自然语言,交给 LLM 整合回答用户:
from IPython.display import Markdown, display# 创建一个查询引擎,用于执行基于向量的查询# 查询引擎可以从向量索引中检索相关信息,并提供统一的查询接口# 这样可以将查询逻辑与索引分离,提高代码的可读性和可维护性vector_query_engine = vector_index.as_query_engine()# 使用查询引擎执行一个查询:"攻杀丹药有哪些?"# 查询引擎会将用户的查询转换为向量,并计算与向量索引中向量的相似度# 返回与查询最相关的结果vector_response = vector_query_engine.query("攻杀丹药有哪些?")# 将查询结果以加粗的 Markdown 格式显示在 Jupyter Notebook 中# 这样可以以可读的格式展示查询结果,方便用户理解display(Markdown(f"<b>{vector_response}</b>"))我们将利用向量进行语义匹配找到的相似性高的内容打印出来看一下有哪些:
# 打印引用的文本块数量# len(vector_response.source_nodes) 计算引用的文本块数量print(f"引用了 {len(vector_response.source_nodes)} 个文本块。")# 提取所有引用节点的文本# 使用列表推导式遍历 source_nodes 并获取每个节点的文本source_texts = [node.node.get_text() for node in vector_response.source_nodes]我们利用知识图谱构建的图索引进行查询,看一下通过图索引查询到的结果,其中 include_text=True 意味着我们不光找出来三元组,而且将构建三元组的原始文本数据也取出来,让模型更好的理解相关内容:
# 从知识图谱索引创建查询引擎# 使用 as_query_engine 方法将 kg_index 转换为查询引擎,# include_text=True 的作用是确保查询结果不仅返回知识图中的结构化数据(如节点和它们之间的关系),还包括与这些节点相关的原始文本内容。kg_query_engine = kg_index.as_query_engine(include_text=True)# 使用查询引擎执行查询# 查询问题是 "攻杀丹药有哪些?"# kg_response 存储查询结果kg_response = kg_query_engine.query("攻杀丹药有哪些?")# 显示查询结果# 使用 Markdown 格式展示查询结果display(Markdown(f"<b>{kg_response}</b>"))现在我们利用向量索引的常规 RAG 和利用知识图谱构建的图索引,分别找到的结果放到 dataframe 中进行对比,看一下二者的差异:
import pandas as pd# 定义查询问题query_question = "攻杀丹药有哪些??"# 常规查询引擎的查询质量vector_query_engine = vector_index.as_query_engine()vector_response = vector_query_engine.query(query_question)vector_results = str(vector_response)# 知识图谱的查询质量kg_query_engine = kg_index.as_query_engine(include_text=True)kg_response = kg_query_engine.query(query_question)kg_results = str(kg_response)现在,我们更进一步,不仅查看常规的 RAG 回答和知识图谱回答,还看一下他们的数据来源于哪一个节点,一起放到 dataframe 中进行更详细的对比:
import pandas as pd# 定义查询问题query_question = "攻杀丹药有哪些?"# 常规查询引擎的质量vector_query_engine = vector_index.as_query_engine()vector_response = vector_query_engine.query(query_question)vector_results = str(vector_response)# 获取常规查询引擎的引用数据vector_sources = []vector_source_texts = []if hasattr(vector_response, 'source_nodes'): # 如果查询结果包含来源节点,则提取其文本 vector_sources = [node.node.get_text() for node in vector_response.source_nodes] vector_source_texts = ', '.join(vector_sources)else: # 如果查询结果不包含来源节点,则设置默认提示 vector_source_texts = '无法获取来源'# 接入知识图谱的查询结果kg_query_engine = kg_index.as_query_engine(include_text=True)kg_response = kg_query_engine.query(query_question)kg_results = str(kg_response)# 获取知识图谱查询引擎的节点信息kg_retriever = kg_index.as_retriever(include_text=True)kg_nodes = kg_retriever.retrieve(query_question)kg_node_texts = ', '.join([node.text for node in kg_nodes])# 创建DataFrame进行对比comparison_df = pd.DataFrame({ '查询问题': [query_question, query_question], '常规RAG回答': [vector_results, vector_source_texts], '知识图谱回答': [kg_results, kg_node_texts]})四、完整代码及操作说明
-
文件放置结构如下:
.├── .env├── data│ ├── 九叶灵芝草(上品).txt│ ├── 交梨(上品).txt│ └── ...├── requirements.txt├── environment.yml├── wukong_api.ipynb└── wukong_local_model.ipynb
我们过去,用知识图谱+多智能体,交付项目!
这也是2025年,一意为会员交付的价值项目之一!
在开始之前,我们要把这个课程的基底,给所有会员补齐!
让你跟上大进度!
才有今天内容!
整个系列,我们会花一周跟完,内容如下:

我们由浅至深,啃下RAG+KG搭建,最后,我们动手做一个属于自己的应用,会教你他背后是如何做到的,你最终做出来的成果,是这样的:
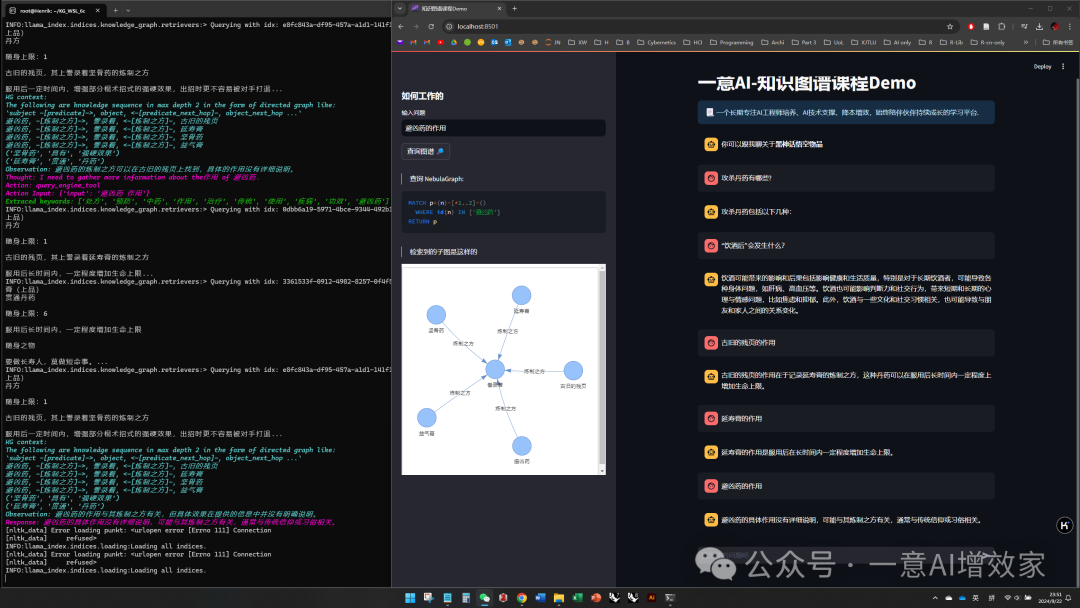
找工程师吧!
一、大模型风口已至:月薪30K+的AI岗正在批量诞生
2025年大模型应用呈现爆发式增长,根据工信部最新数据:
国内大模型相关岗位缺口达47万
初级工程师平均薪资28K
70%企业存在"能用模型不会调优"的痛点
真实案例:某二本机械专业学员,通过4个月系统学习,成功拿到某AI医疗公司大模型优化岗offer,薪资直接翻3倍!

二、如何学习大模型 AI ?
🔥AI取代的不是人类,而是不会用AI的人!麦肯锡最新报告显示:掌握AI工具的从业者生产效率提升47%,薪资溢价达34%!🚀
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
1️⃣ 提示词工程:把ChatGPT从玩具变成生产工具
2️⃣ RAG系统:让大模型精准输出行业知识
3️⃣ 智能体开发:用AutoGPT打造24小时数字员工
📦熬了三个大夜整理的《AI进化工具包》送你:
✔️ 大厂内部LLM落地手册(含58个真实案例)
✔️ 提示词设计模板库(覆盖12大应用场景)
✔️ 私藏学习路径图(0基础到项目实战仅需90天)





第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
* 大模型 AI 能干什么?
* 大模型是怎样获得「智能」的?
* 用好 AI 的核心心法
* 大模型应用业务架构
* 大模型应用技术架构
* 代码示例:向 GPT-3.5 灌入新知识
* 提示工程的意义和核心思想
* Prompt 典型构成
* 指令调优方法论
* 思维链和思维树
* Prompt 攻击和防范
* …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
* 为什么要做 RAG
* 搭建一个简单的 ChatPDF
* 检索的基础概念
* 什么是向量表示(Embeddings)
* 向量数据库与向量检索
* 基于向量检索的 RAG
* 搭建 RAG 系统的扩展知识
* 混合检索与 RAG-Fusion 简介
* 向量模型本地部署
* …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
* 为什么要做 RAG
* 什么是模型
* 什么是模型训练
* 求解器 & 损失函数简介
* 小实验2:手写一个简单的神经网络并训练它
* 什么是训练/预训练/微调/轻量化微调
* Transformer结构简介
* 轻量化微调
* 实验数据集的构建
* …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
* 硬件选型
* 带你了解全球大模型
* 使用国产大模型服务
* 搭建 OpenAI 代理
* 热身:基于阿里云 PAI 部署 Stable Diffusion
* 在本地计算机运行大模型
* 大模型的私有化部署
* 基于 vLLM 部署大模型
* 案例:如何优雅地在阿里云私有部署开源大模型
* 部署一套开源 LLM 项目
* 内容安全
* 互联网信息服务算法备案
* …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 17
17 0
0- 0



 已为社区贡献269条内容
已为社区贡献269条内容

所有评论(0)