停止来回切换使用AI 工具 —— 如何构建真正为你所用的第二大脑(二)
让我们紧接着上一次未讨论完的内容继续。
让我们紧接着上一次未讨论完的内容继续。
-
启示:RAG 无处不在
完成这个项目后,我不禁思考:等等,原来如此?这就是 RAG?
它看似简单得令人意外。
但从 “匹配关键词” 到 “理解意图” 的转变,正是 RAG 的强大之处。当我在自己的系统中看到它的运作后,不禁持续思索:如果我们用作 “第二大脑” 的许多工具(如 Obsidian、Notion、Cursor),其底层都在悄然使用类 RAG 概念呢?
这个认知将我带入了一段探索之旅,彻底改变了我看待所有 AI 工具的方式。
🧠 Obsidian:结构化的思维
Obsidian 可能是最接近原始形态 “第二大脑” 的工具。它是一个本地优先、基于 Markdown 的笔记应用,具备双向链接和知识图谱。开箱即用状态下没有 AI、没有嵌入向量,只有纯粹的结构。
但当我添加插件并连接到 LLM API(大语言模型接口)后,神奇的事情发生了:我能分析写作模式、总结内容,并基于上下文拓展观点。为进一步探索,我通过 Ollama 下载了几个本地 LLM 进行实验。尽管有些插件效果参差不齐,但 Copilot 插件格外突出,它能辅助总结、改写和内容拓展。
Obsidian 界面显示 Copilot 插件聊天框,本地 LLM 帮助检索选中的相关笔记
这个写作助手不再是简单堆砌关键词,而是基于语义浮现概念、推荐措辞并提供反馈。它并未以 RAG 自居,但行为模式却如出一辙。
⚙️ 自动化 + Notion + AI
如果说有一个概念每次使用都让我觉得革命性,那就是自动化。它无处不在,贯穿教程和工作流,却从未褪去影响力 —— 尤其是与 Notion 的结构化数据库架构结合时。
我曾用 n8n 构建系统:从 Gmail 提取 AI 相关邮件,发送至 API,并将原始内容与 AI 增强内容存储在 Notion 数据库中。一旦数据入库,查询就像语义搜索一样:
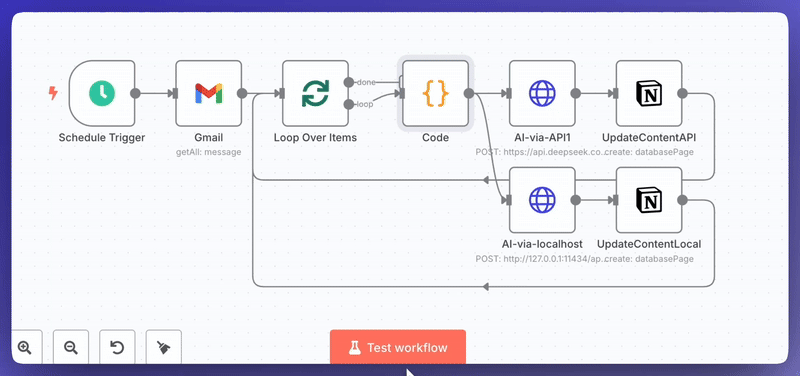
n8n 工作流截图,用于从 Gmail 检索 AI 相关邮件
我可以问:
“哪些 AI 项目涉及语音转录?”
或:
“有什么与游戏相关的内容?”
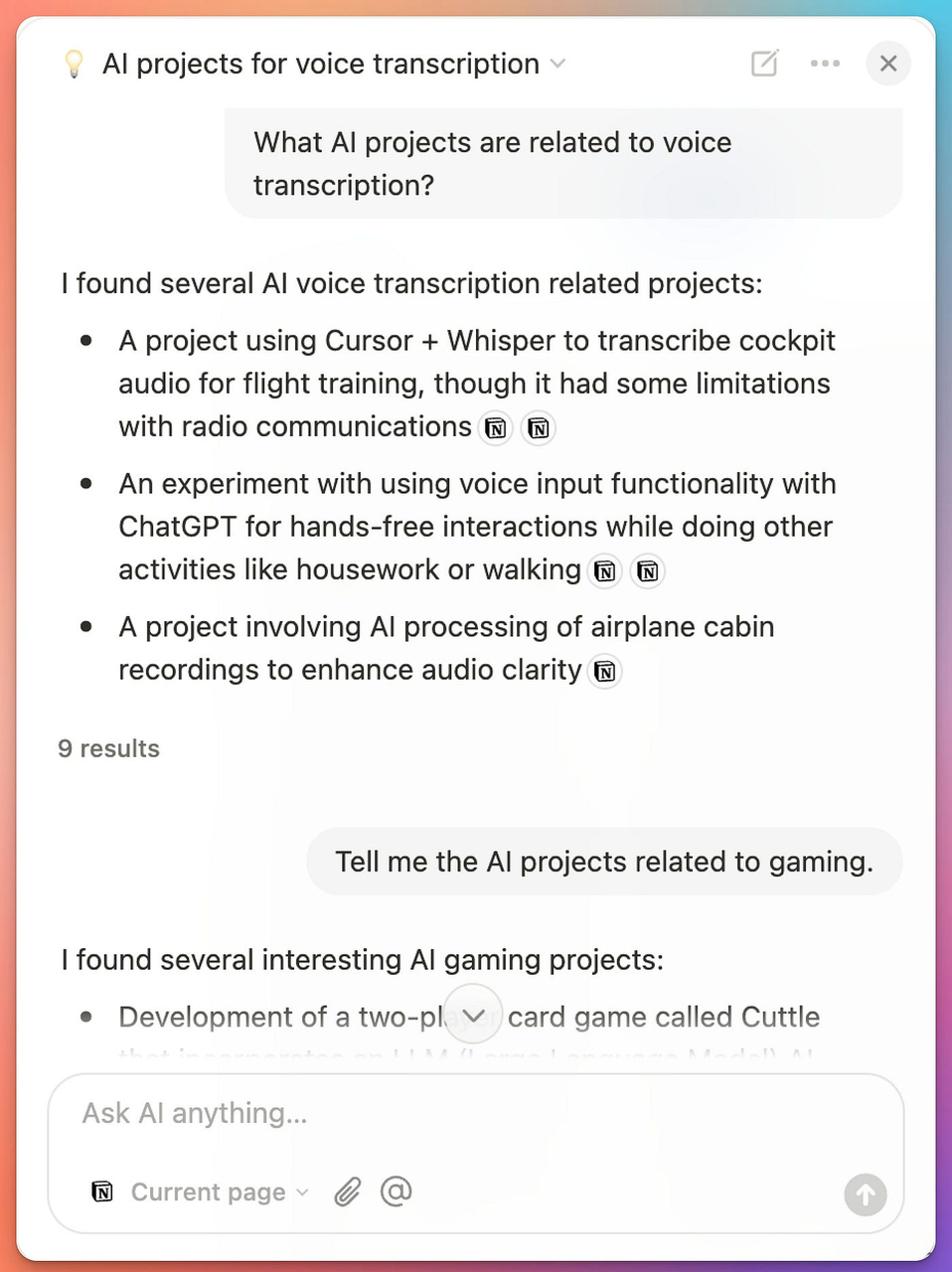
Notion AI 聊天框返回可靠答案
即使文本中没有完全匹配的词汇,结果依然相关。同样,这并非官方定义的 RAG,却完全遵循 RAG 逻辑。
💻 Cursor:我的无声第二大脑
有趣的是:如果今天要重建我的 RAG 网站并完全本地化运行,我只需打开 Cursor,指向写作文件夹,直接提问即可 —— 这正是我目前用它进行写作、编码、头脑风暴和编辑的方式。
关键在于其底层逻辑完全一致。Cursor 的工作原理是嵌入文件、运行相似度搜索,并将上下文输入语言模型,与我在项目中构建的 RAG 架构如出一辙。
有时我告诉别人如何用 Cursor 进行编辑或项目指导时,他们会用奇怪的眼神看我,但对我而言,这正是 “第二大脑” 应有的形态:
-
浮现相关洞见
-
理解任务目标
-
基于你的工作实时提供建议
换句话说,它是伪装成代码编辑器的 RAG。
🖼 超越文本:视觉 “RAG”?
在反思文本场景后,我开始思考图像:这让我回想起一个项目 —— 在一个充满未标记、随机命名图片的巨大文件夹中搜索。没有标签或文件名,但输入查询就能立即找到所需内容。

ImageFinder 应用截图,支持基于内容而非文件名搜索图片
其底层使用了:
-
OpenAI 的 CLIP 模型,将图像和文本嵌入同一向量空间
-
余弦相似度,用于匹配文本提示与视觉内容
-
本地处理,无需外部数据库或 LLM
需要明确的是,这并非完整的 RAG,缺少上下文增强和生成步骤,但无疑属于类 RAG。即便不符合定义,它也源自相同的思维框架。
⚡ 你已在使用的实时 RAG
当看到 RAG 概念在文本和图像中都能奏效后,我开始注意到日常工具中的类似应用 —— 即使它们并未宣扬这一点:
-
Unsplash:搜索 “cozy winter cabin”(舒适的冬日小屋),即使文件名不匹配也能精准返回结果。这不是关键词搜索,而是使用了类似 CLIP 的图文嵌入。
-
NotebookLM:谷歌的 AI 笔记工具。上传文档后,它通过检索相关内容并生成回答 —— 这正是 RAG 的实际应用。
-
Spotify 搜索也开始有 RAG 感:输入 “lo-fi beats for focus”(专注用低保真节拍),它不仅匹配流派,更在理解氛围、上下文和意图。
这些工具可能不会标榜自己是 RAG,但底层都在做同一件事:检索→理解→响应。
所以是的,RAG 是技术性的,但它早已成为你日常生活的一部分。
-
策略性转变:选择适合你的正确第二大脑
当我意识到所有这些工具共享相同的底层逻辑时,终于明白为何自己一直在它们之间跳转 —— 我曾将它们视为“不同物种”,实则它们是“同一类动物的不同品种”。
不再对比功能列表后,我开始思考正确的问题:
-
这个工具最擅长检索什么类型的内容? Cursor 擅长处理代码和项目文件,NotebookLM 适合文档与研究,Obsidian 则在互联笔记中创造奇迹。
-
它如何理解上下文? 有些工具优先考虑近期交互,另一些侧重相似度权重,还有些会纳入你的行为模式。
-
哪种响应风格匹配我的思维? 我需要对话式的来回交互、快速的上下文建议,还是结构化分析?
这些工具并非真正在竞争,而是针对不同思维类型做了优化。一旦理解它们的 RAG 基因,你就能将其与实际工作流匹配,而非追逐最新功能。
反切换框架
以下三步法最终让我停止不断切换工具:
步骤 1:绘制你的思维模式
在选择任何工具前,花一周时间记录你何时以及为何寻求 AI 帮助。注意:
-
写作时需要快速答案吗?(检索导向)
-
正在头脑风暴并连接想法吗?(探索导向)
-
处理结构化数据和文档吗?(组织导向)
大多数人在某一领域最强,先识别自己的类型。
不要猜测,切实记录一周:“周二下午 2 点:需要帮助向客户解释复杂概念(检索导向)” 或 “周四上午 10 点:卡在项目方向上,需要探索可能性(探索导向)。”
步骤 2:选择基础工具
根据你的主导模式,选择唯一主要工具:
-
检索导向:从 Cursor 或 NotebookLM 开始 —— 它们擅长从现有工作中查找和呈现相关上下文。
-
探索导向:带 AI 插件的 Obsidian 为连接想法和发现新洞见提供最佳思考场域。
-
组织导向:Notion AI 无缝处理结构化内容和工作流,尤其与自动化结合时。
关键在于:抵制优化的冲动。基础工具无需在所有方面完美,只需在你的主导思维模式上表现卓越。
步骤 3:构建 RAG 思维模式
现在你已理解这些工具的真正运作方式(它们都在执行 “检索→理解→响应”),可以更有意地使用它们:
-
向工具输入真实工作内容,而非随机提示。 上传文档、连接项目、导入笔记 —— 当工具理解你的特定上下文时,魔法才会发生。
-
提出基于历史上下文的问题。 不要每次都重新开始,参考之前的对话,在已有洞见上拓展,创建思维脉络。
-
让工具建议你可能忽略的连接。 利用它们的模式识别能力,呈现想法、项目或研究之间的关联。
-
将工具输出视为思考伙伴,而非最终答案。 最佳交互发生在你与工具协作时,而不仅是消费其输出。
深度原则
魔力不在工具本身,而在于创建随时间变得更智能的一致上下文。每一次对话、每一份添加的文档、每一个提出的问题,都在构建对工作和思维模式更丰富的理解。
这就是频繁切换工具适得其反的原因:每次切换都会丢失累积的上下文,本质上是在每个新工具中重新开始,从未让任何系统真正理解你的工作。
现在轮到你开始
今晚就选择基础工具。根据主导思维模式,选一个工具并承诺至少使用 30 天。
明天,花 10 分钟向它输入实际在做的内容:当前项目、笔记文件夹、或正在困扰你的文档。问一个关于工作的真实问题 —— 不是测试问题,而是你真正想探索的内容。
就是这样:无需复杂设置,无需完美系统。只有一个工具、一个上下文、一个问题。
最重要的不是使用哪个工具,而是问:
“我需要在什么方面获得帮助?”
“最舒适、无摩擦的实现方式是什么?”
当你承诺深度而非广度时,切换行为就会停止。这些工具并非在争夺你的注意力,而是来支持你的思考方式、创作方式和工作意愿。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)