ANN人工神经网络
神经网络模型是深度学习的计算模型, 仿生生物学神经元构造功能:创建自定义模型的时候自动调用操作:1.1 调用父类的__init__方法1.2 初始化隐藏层和输出层示例:self.linear1 = nn.Linear(3,3)1.3 初始化参数示例: nn.init.kaiming_normal_(self.linear1.weight)
一.神经网络的介绍和搭建
1.什么是神经网络模型?
神经网络模型是深度学习的计算模型, 仿生生物学神经元构造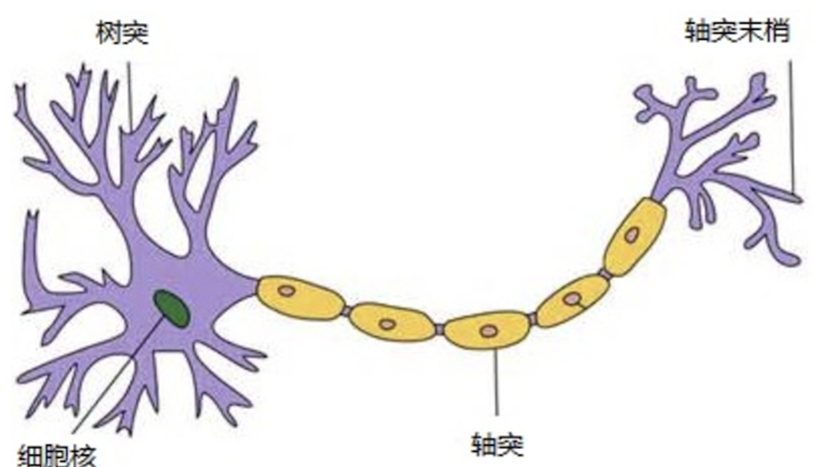
以下是相关的名词解释:

2.如何构造神经网络模型?
神经网络是由多个神经元构成,包括输入层,隐藏层,输出层。
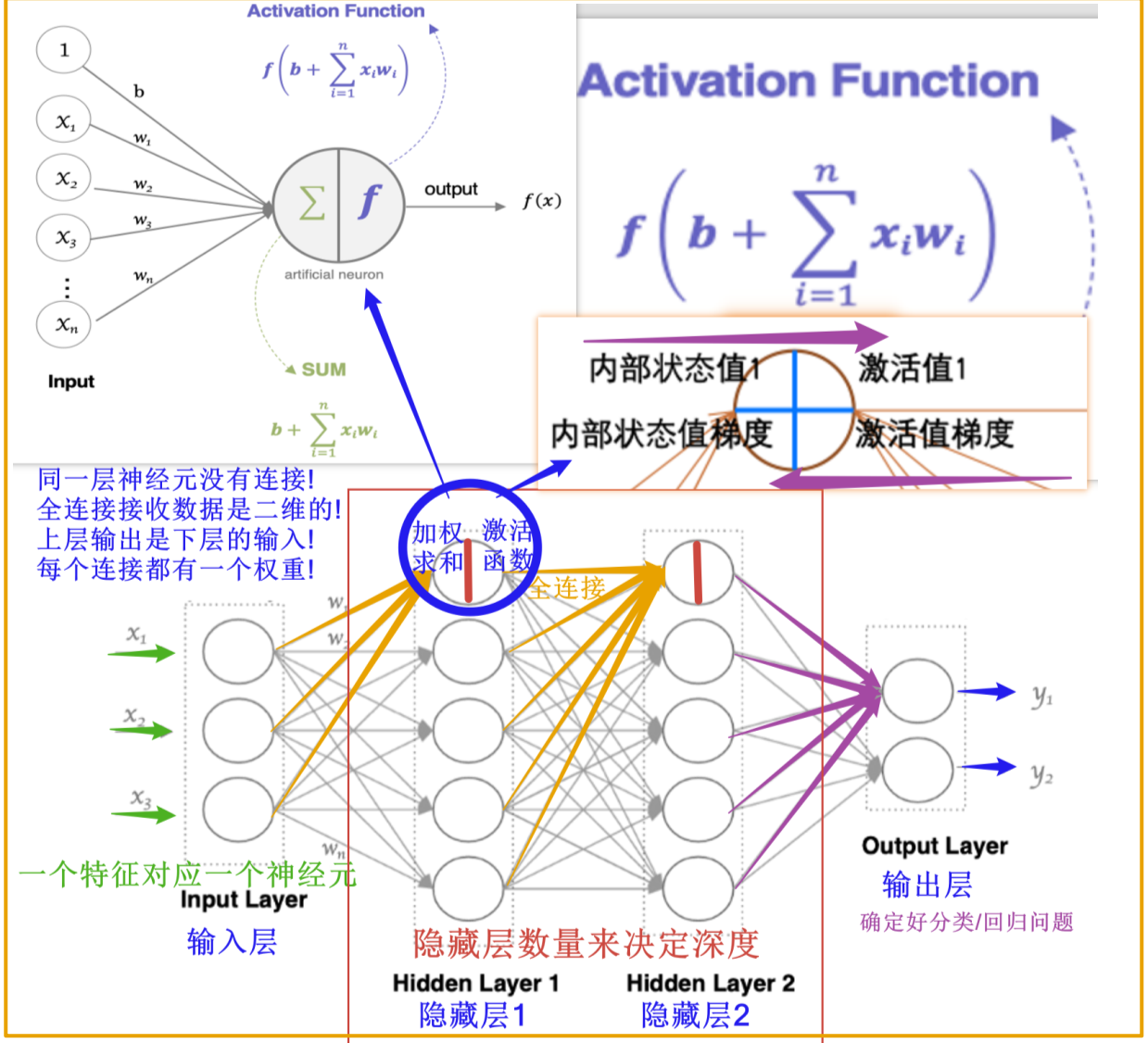
内部状态值:神经元接收到的输入、历史信息以及网络内部的权重计算结果
激活值:激活函数对内部状态值进行非线性变换后得到的结果
接下来讲解激活函数的选择:
3.激活函数
神经网络中的激活函数(Activation Function)决定了神经元的输出特性,不同的激活函数在值域、导数(梯度)、计算效率等方面有显著差异。
作用:激活函数用于对每层的输出数据进行变换, 进而为整个网络注入了非线性因素。此时, 神经网络就可以拟合各种曲线
以下是激活函数的优缺点:

4.参数初始化
1.就是对权重、偏置的初始值设定,就是参数初始化,它的作用有以下几点:
1.生成权重矩阵和偏置矩阵
2.防止梯度消失或梯度爆炸
3.打破对称性:
模型学习的方向, 学习的特征
每个神经元权重不一样, 更新时结果也不一样
2.七大初始化API
① 随机均匀初始化:uniform_()
② 随机正态分布初始化:normal_()
③ 全0初始化:zeros_()
④ 全1初始化:ones_()
⑤ 全指定值初始化:constant_()
⑥ he/kaiming初始化:
kaiming随机均匀初始化:kaiming_uniform_()
kaiming随机正态分布初始化: kaiming_normal_()
⑦ xavier初始化:
xavier随机均匀初始化:xavier_uniform_()
xavier随机正态分布初始化:xavier_normal_()
3.参数的选择
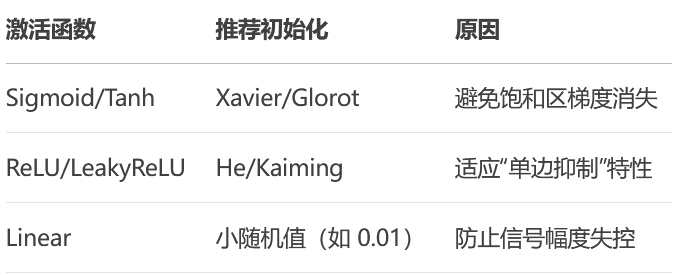
Sigmoid和Tanh选择Xavier初始化
Relu选择kaiming初始化,relu专用
4.神经网络模型搭建步骤
1.自定义模型类,继承nn.module基类
2.重写两个函数:
① 重写__init__构造函数:
功能: 创建自定义模型的时候自动调用
操作:
1.1 调用父类的__init__方法
1.2 初始化隐藏层和输出层
示例: self.linear1 = nn.Linear(3,3)
1.3 初始化参数
示例: nn.init.kaiming_normal_(self.linear1.weight)
② forward前向传播函数:
功能: 调用神经网络模型对象时, 会自动执行
操作:
2.1 前向传播, 计算预测值
2.2 每一层加权求和
示例: x = self.linear1(x)
2.3 每一层激活值计算
示例: x = torch.sigmoid(x)
3.创建模型并使用模型
① model = My_Model() # 自动调用init魔法方法
② output = model(data) # 自动调用forward方法
二.损失函数
什么是损失函数?损失函数,又叫代价函数, 误差函数 ...,是衡量模型参数质量的函数。
作用:根据损失函数计算损失值, 结合反向传播算法以及梯度下降算法实现参数更新
损失函数的分类:
1.分类损失函数
① 多分类交叉熵损失函数:nn.CrossEntropyLoss(reduction='mean')
实现softmax激活值计算+损失计算:
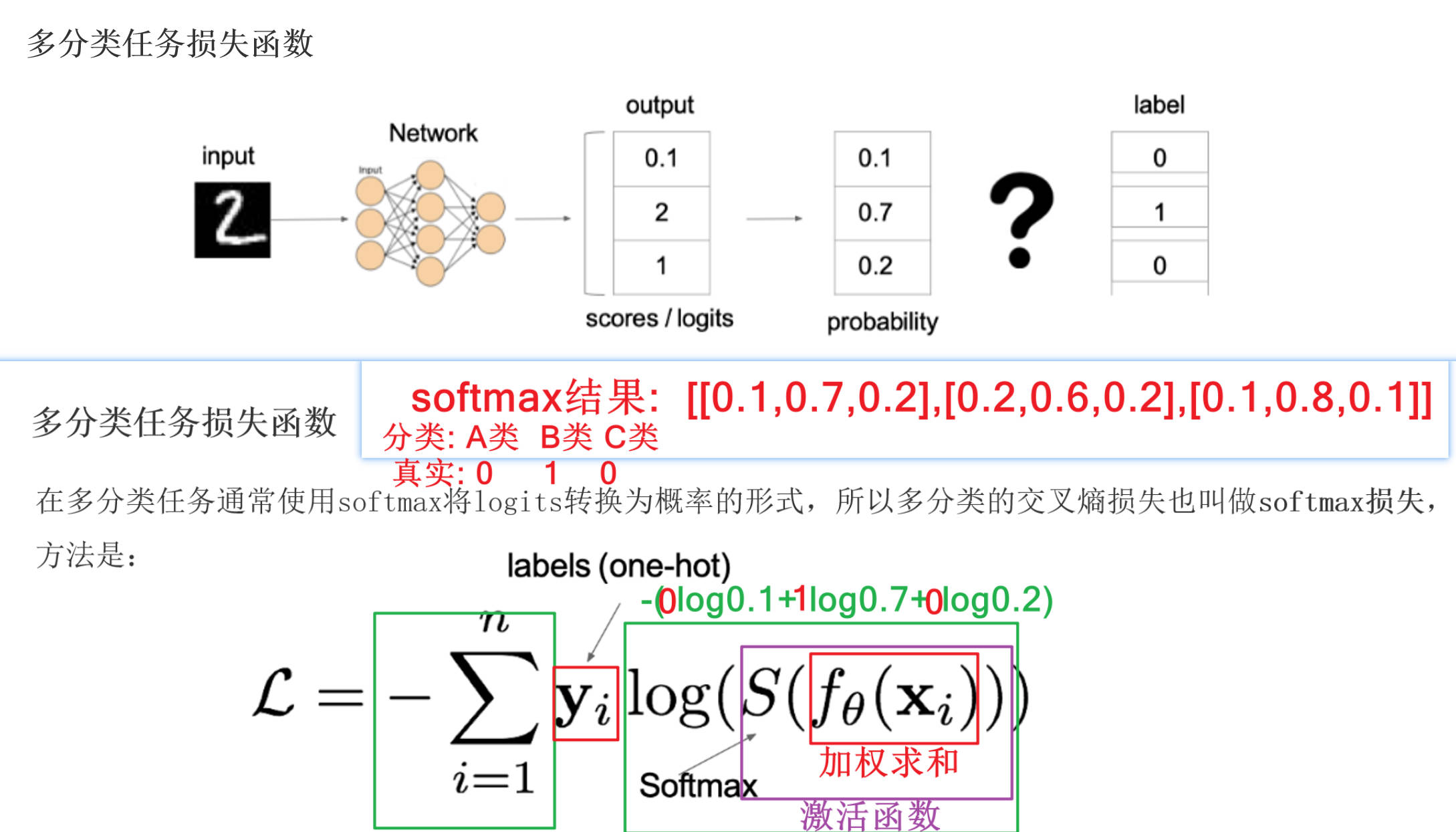
② 二分类交叉熵损失函数:nn.BCELoss(reduction='mean')
注意:多分类交叉熵损失函数可以用于二分类,但二分类不能用多分类
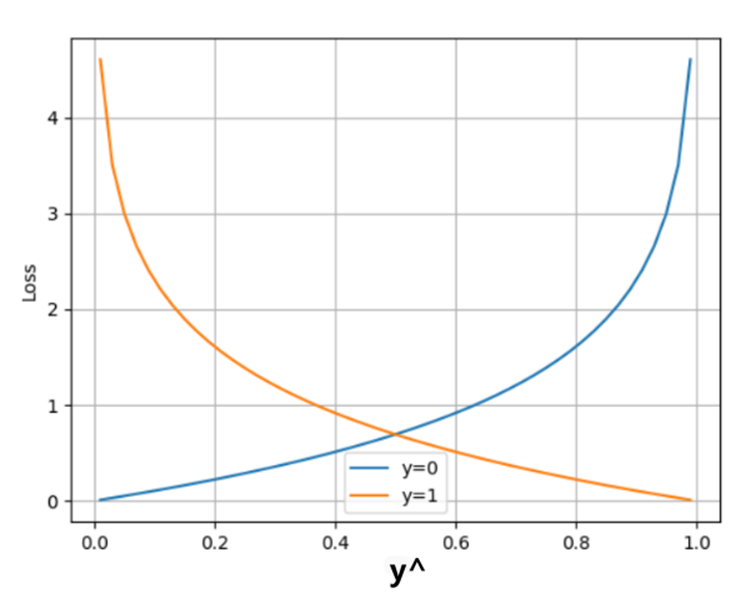
2.回归损失函数
① MAE平均绝对误差损失函数: nn.L1Loss()
特点:
计算平均绝对误差
导数为-1/1, 或者0点不可导用0代替
对异常样本效果比较好, 不会放大异常样本误差
L1 正则化, 将特征权重置为0, 特征筛选
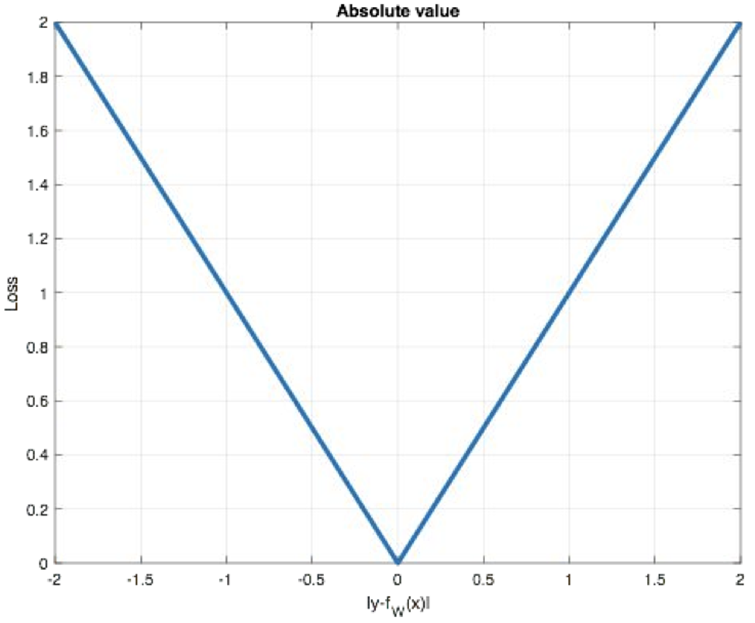
② MSE均方误差损失函数:nn.MSEloss()
特点:
计算均方误差
任意位置都有导数, loss越大导数越大, loss越小导数越小
对异常样本效果不好, 放大样本误差
L2正则化, 将特征权重接近0
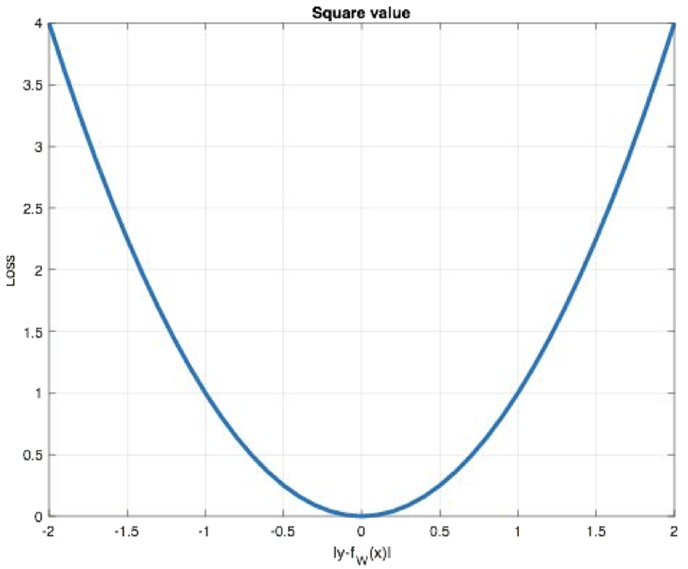
③ Smooth L1损失函数:nn.SmoothL1loss()
特点:
任意位置都有导数, [-1,1]导数减小, 小于-1或大于1导数为-1或1
对异常样本效果好, 不会产生梯度爆炸, 不容易跳过最低点
特殊的huber loss,固定了超参数:(图解)
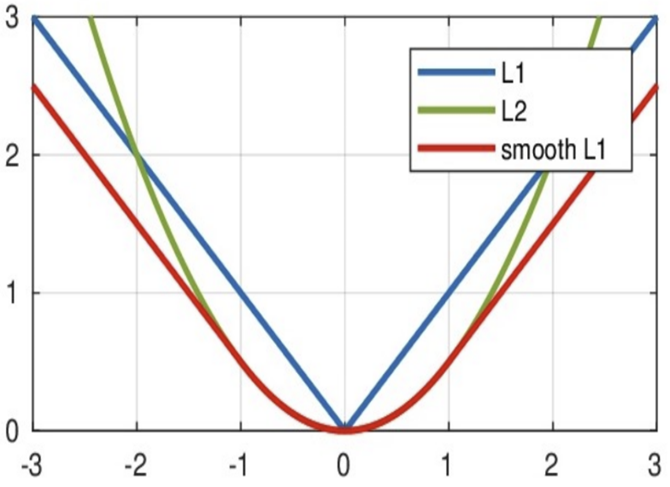
三. 网络模型优化方法
优化模型离不开更新权重,可以从下图权重更新公式发现有两个优化方向

先讲解一下梯度下降的公式和概念
公式 :w1 = w0 - lr*grad
参数解释:
w0是上一版模型的参数
lr是学习率,已知
grad是梯度,反向传播计算得到
1.梯度下降法三大概念:
① epoch:
训练次数/轮次
② batch_size:
每次迭代需要的样本数
③ iteration:
每次训练需要迭代多少次
样本数/batch_size[+1, 不能整除需要加1]
2.正向传播和反向传播(图解)
正向传播算法: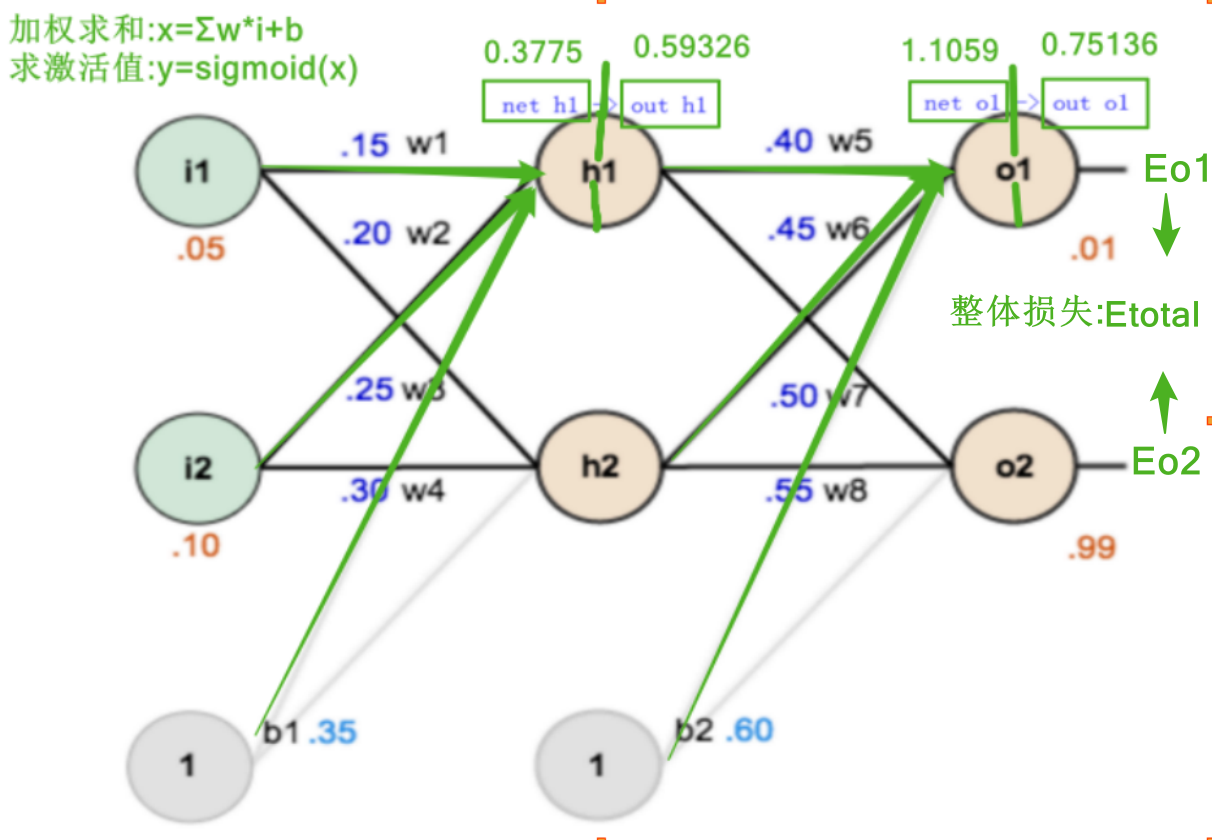
反向传播算法: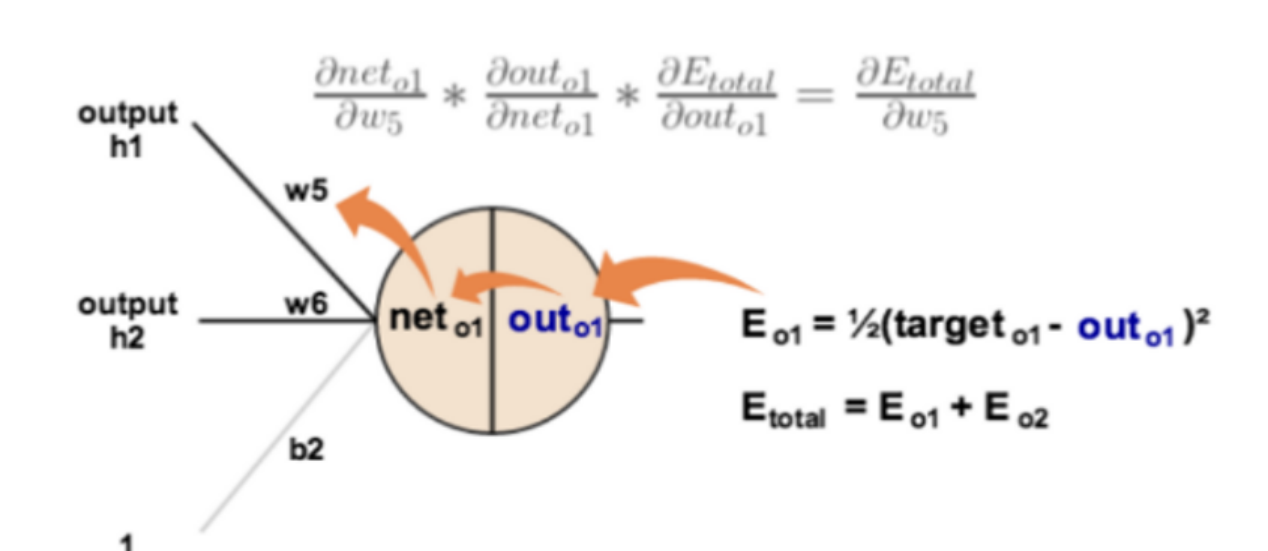
梯度下降的两种方式
从下图中可以看出,权重可以从学习率和梯度的角度优化
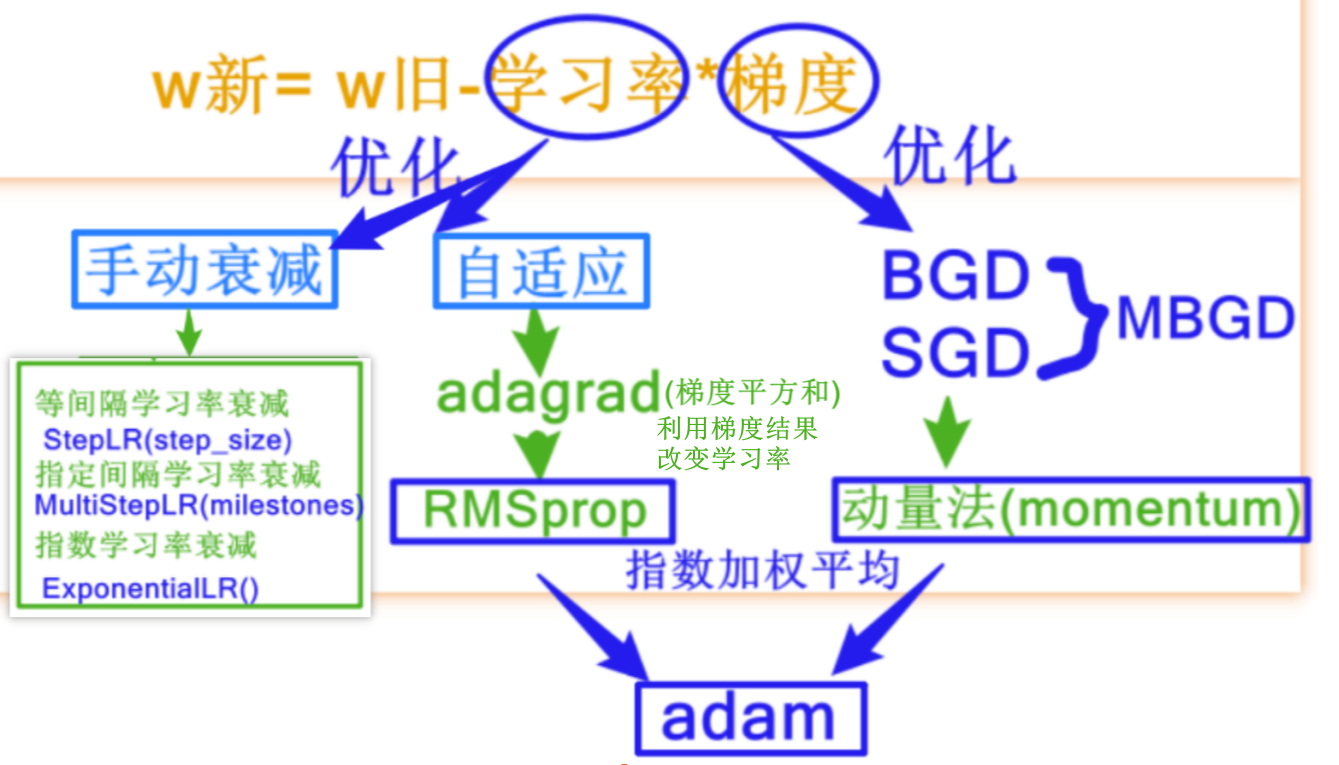
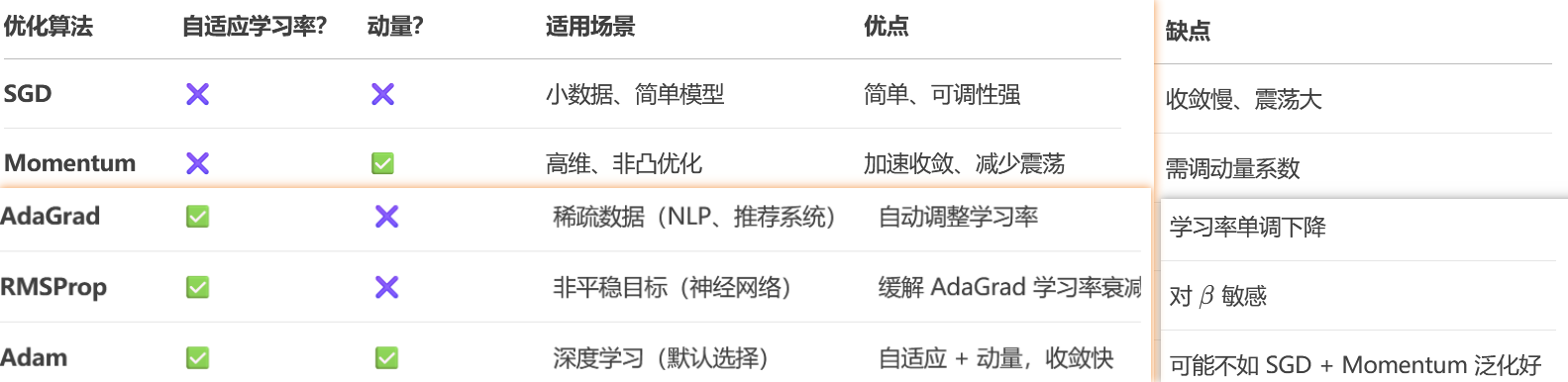
1.站在梯度的角度
① BGD(准确但是慢)
② SGD(快但是不稳定):MBGD(快稳定)
③ momentum动量法:当前梯度是指数移动加权平均梯度
St=(1-β)*Gt + β*St-1
结合当前梯度*系数+历史加权平均梯度
当前梯度为0, St = 0.1*0 + 0.9*St-1 != 0
W0 = W1 - lr*St
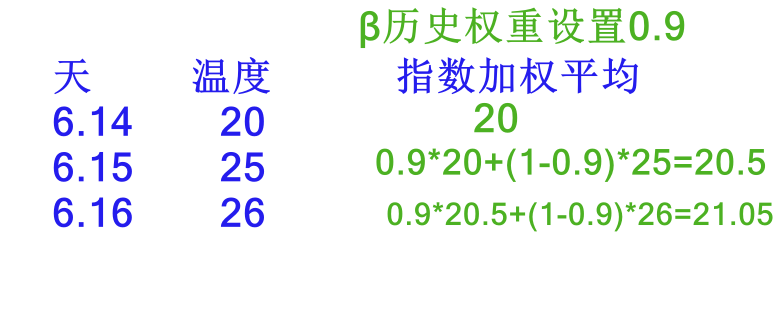
指数加权平均思想:动量法使用了此思想
公式:

举例:
2.站在学习率的角度
2.1 自适应
① adagrad
Ⅰ自动调整学习率, 初始训练时学习率大, 后期训练学习率小
Ⅱ 新学习率=原始学习率 / 历史梯度平方:
初始训练累加梯度小, 分母小, 新的学习率大
后期训练累加梯度大, 分母大, 新的学习率小
Ⅲ 适用于高维稀疏数据或文本数据
② RMSprop
Ⅰ自动调整学习率, 初始训练时学习率大, 后期训练学习率小
Ⅱ 新学习率=原始学习率 / 历史指数加权平均梯度平方:
初始训练累加梯度小, 分母小, 新的学习率大
后期训练累加梯度大, 分母大, 新的学习率小
Ⅲ 避免adagrad优化方法的学习率下降过快, 导致模型震荡
Ⅳ 适用于高维稀疏数据或文本数据
③ adam
adam是momentum+rmsprop的结合,一般优先选择
优化器核心对比:

2.2手动指定
① 等间隔学习率衰减
训练次数(步长)相等, 学习率随着训练次数减小
lr = lr * gamma
api:
scheduer = optim.lr_scheduler.StepLR(optimizer=optimizer, step_size=50, gamma=0.5)
scheduer.step()
② 指定间隔学习率衰减
自定义训练次数(步长), 学习率随着训练次数减小
lr = lr * gamma
api:
optim.lr_scheduler.MultiStepLR(optimizer=optimizer, milestones=[50, 100, 160], gamma=0.5, last_epoch=-1)
③ 指数学习率衰减
按指数减小, 前期减小快, 后期减小慢
api:
lr = lr*gamma**epoch
optim.lr_scheduler.ExponentialLR(optimizer=optimizer, gamma=0.9)
正则化(解决过拟合问题)
什么是正则化?正则化是一种解决过拟合提高模型泛化能力的策略,泛化能力是指:模型在测试样本/新样本效果要好
策略分为三种:
1.范数正则化:
L1正则化
L2正则化:torch.optim.SGD(weight_decay=)
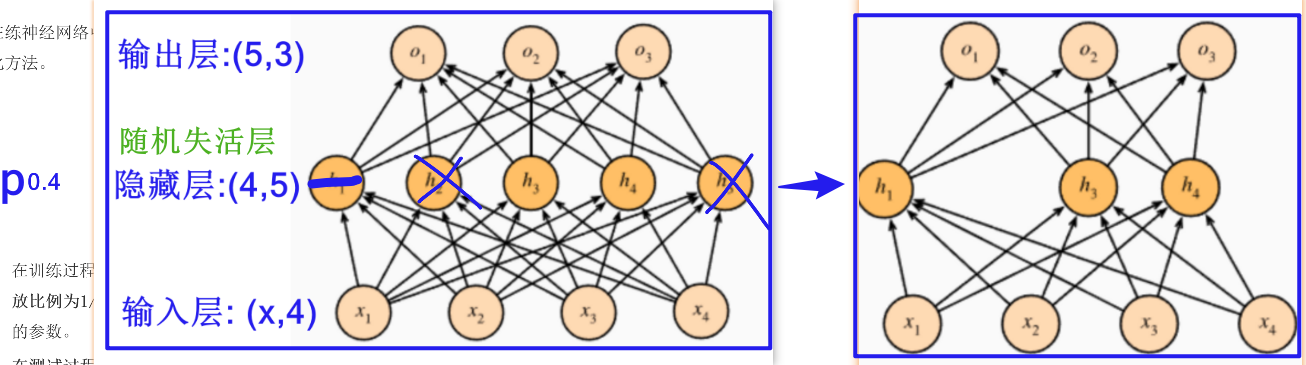
2.随机失活正则化
在激活函数后添加一个随即失活层
dropout层特点:
① 以指定p概率让神经元随机失活
② 每批次训练时失活的神经元不是固定, 得到不同的子网络, 防止预测结果过分依赖某些神经元
③ 注意点:
在激活层后使用
未失活的神经元输出除以(1-p)
dropout在测试集上不生效
④ 模型状态切换
训练模式 model.train()
测试模式 model.eval()
⑤ API:nn.Dropout(p=0.4)
3.批量归一化正则化
3.1批量归一化是对线性结果进行标准化处理,根据每批样本的均值和标准差计算标准化的值
3.2 作用:
Ⅰ 正则化:不同批次样本的均值和标准差不一样, 有可能会引入噪声样本, 降低训练模型效果
Ⅱ 加快模型收敛速度:
数据分布均匀, 落入不同激活函数要求的范围内
sigmoid/tanh激活函数->数据分布在0附近,导数最大
3.3 注意点:
在激活层前使用(卷积层后/线性层后)
多数在计算机视觉领域使用
可以引入γ和β可学习参数, 不同层的样本分布在不同范围内(不同层使用的激活函数不同); 可以补回标准化丢失的信号
3.4 API
nn.BatchNorm1d()
nn.BatchNorm2d()
nn.BatchNorm3d()
相关分类:

以下是一个小案例,手机分类价格预测,其中20个特征列,一个标签,2000个样本
# TODO 导包
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader, TensorDataset
import torch
import time
# 优化: 导入标准化包,提前对数据做标准化处理
from sklearn.preprocessing import StandardScaler
# TODO 1.自定义函数,做数据加载和处理
def get_data_loader(batch_size):
# 1.加载数据
data = pd.read_csv('data/手机价格预测.csv')
# 2.了解数据
print(data.shape)
# print(data.columns)
# print(data.head())
# data.info()
# 3.处理数据
# 3.1获取特征值x和目标值y
x, y = data.iloc[:, :-1], data.iloc[:, -1]
# 3.2为了后续用于张量,提前做类型转换:特征值转浮点,目标值转整型
x = x.astype(np.float32)
y = y.astype(np.int64)
# 3.3 数据集划分
x_train, x_valid, y_train, y_valid = train_test_split(x, y, train_size=0.8, random_state=88)
# TODO StandardScaler添加数据标准化处理
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_valid = scaler.transform(x_valid)
# 3.4 构建数据集,最终为训练集dataloader和测试集dataloader
# 先把numpy数据集转换成张量,然后封装成张量数据集
train_dataset = TensorDataset(torch.from_numpy(x_train), torch.from_numpy(y_train.values))
valid_dataset = TensorDataset(torch.from_numpy(x_valid), torch.from_numpy(y_valid.values))
# 再把张量数据集封装成数据加载器,并且设置批量大小和是否打乱数据
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
valid_dataloader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=False)
# 4.返回结果: 数据加载器,数据集长度,输入特征维度,输出特征维度
return train_dataloader, valid_dataloader, x_train.shape[1], len(y.unique())
# TODO 2.自定义类,构建神经网络模型
class PhonePriceModel(torch.nn.Module):
# 重写__init__方法和forward方法
def __init__(self, input_num, output_num):
# 调用父类的构造方法
super().__init__()
# 定义网络结构
self.linear1 = torch.nn.Linear(input_num, 128)
self.linear2 = torch.nn.Linear(128, 256)
# TODO 优化3: 增加网络深度
self.linear3 = torch.nn.Linear(256, 256)
self.out = torch.nn.Linear(256, output_num)
# 重写forward方法
def forward(self, x):
# 加权求和->激活函数(默认隐藏层都用relu作为激活函数)
x = torch.relu(self.linear1(x))
x = torch.relu(self.linear2(x))
# TODO 优化3: 增加网络深度,后添加计算
x = torch.relu(self.linear3(x))
# 输出层(注意:后续使用交叉熵损失函数,它已经自带了softmax()操作,此处只需要做加权求和操作)
x = self.out(x)
# 返回最后的加权求和结果,不是预测值
return x
# TODO 3.模型训练
def train_model(train_dataloader, model, epochs):
# 1.获取数据(此处参数已经传入)
# 2.获取模型(此处参数已经传入)
# 3.创建损失函数对象
loss_fn = torch.nn.CrossEntropyLoss()
# 4.创建优化器对象
# optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
# TODO 优化5: SGD-> Adam, 同时调整学习率
optimizer = torch.optim.Adam(model.parameters(), betas=(0.9, 0.999),lr=0.0001)
# 5.循环训练模型
# TODO 如果后续使用了随机失活dropout,此处模型就需要切换到训练模式
model.train()
# 外层循环轮次,内层循环批次
for epoch in range(epochs):
# 定义初始参数
total_loss, batch_cnt, start = 0.0, 0, time.time()
for batch_x, batch_y in train_dataloader:
# 正(前)向传播:从输入到输出: 预测值和损失值
# 模型预测(此处拿到了加权求和结果)
y = model(batch_x) # 底层自动调用了forward
# 损失计算 (此处先底层调用了softmax获取预测值,然后计算损失值)
loss = loss_fn(y, batch_y)
# 累加损失值和批次数
total_loss += loss.item()
batch_cnt += 1
# 反向传播:从输出到输入: 梯度计算和参数更新
# 梯度清零!!!
optimizer.zero_grad()
# 梯度计算
loss.backward()
# 参数更新
optimizer.step()
# 走到此处,说明一轮结束: 累加损失和批次数用于计算每轮损失值.
epoch_loss = total_loss / batch_cnt
print(f"第{epoch + 1}轮,运行时间{time.time() - start:.2f}秒,损失值为:{epoch_loss:.2f}")
# 6.保存训练好的模型参数字典
torch.save(model.state_dict(), 'model/手机价格分类预测.pth')
# TODO 4.模型评估
def eval_model(valid_dataloader, input_num, output_num):
# 1.获取数据(此处参数已经传入)
# 2.创建新模型对象,加载训练好的参数字典,用于评估
model = PhonePriceModel(input_num, output_num)
model.load_state_dict(torch.load('model/手机价格分类预测.pth'))
# 3.定义变量,记录: 预测正确的样本数.
correct = 0
# TODO 如果后续使用了随机失活dropout,此处模型就需要切换到测试模式
model.eval()
# 4.具体的 每批评估 过程.
for batch_x, batch_y in valid_dataloader:
# 4.1 模型预测(此处拿到的是加权求和结果)
y = model(batch_x)
# 4.2 获取预测结果
y_pred = torch.argmax(y, dim=1)
# 4.3 获取预测正确的个数
correct += (y_pred == batch_y).sum()
# 5.求预测精度
print(f'Acc: {(correct / len(valid_dataloader.dataset)):.4f}')
# 程序的主入口
if __name__ == '__main__':
# 1.自定义函数,做数据加载和处理
# 设置batch_size大小并传参给get_data_loader()函数
# TODO 优化1: 调整batch_size大小
batch_size = 16
# TODO 优化2: tandardScaler提前对数据做标准化处理
train_dataloader, valid_dataloader, input_num, output_num = get_data_loader(batch_size)
# 2.自定义类,构建神经网络模型
# TODO 优化3: 增加网络深度
model = PhonePriceModel(input_num, output_num)
# 3.模型训练(正向/反向传播)
# TODO 优化4: 调整训练轮次
epochs = 100
# TODO 优化5: SGD-> Adam,同时调整学习率
train_model(train_dataloader, model, epochs)
# 4.模型评估
eval_model(valid_dataloader, input_num, output_num)
通过网盘分享的文件:手机价格预测.csv
链接: https://pan.baidu.com/s/1eHYF3NXeDAf8u1Gq1jbI5w?pwd=micx 提取码: micx 复制这段内容后打开百度网盘手机App,操作更方便哦

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)