GD32F407VE CAN通信HardFault_Handler异常
转自:https://blog.csdn.net/u013312012/article/details/82192226STM32因为结构体字节对齐导致的HardFault_Handler异常该问题遇到了好多次,前几次都因为赶,没有深究,前几天刚好空闲下来便排查了下。现象是这样的:我使用到stm32的can通信,代码本来是运行正常的。
一、他人分析
转自:https://blog.csdn.net/u013312012/article/details/82192226
STM32因为结构体字节对齐导致的HardFault_Handler异常
该问题遇到了好多次,前几次都因为赶,没有深究,前几天刚好空闲下来便排查了下。
现象是这样的:我使用到stm32的can通信,代码本来是运行正常的。后来添加了一个9字节的结构体变量,编译后下载到目标板子运行,发现只要一接收can消息,就会进入HardFault_Handler异常,在网上查找解决方法,发现进入HardFault_Handler异常有以下一些情况:
STM32出现硬件错误可能有以下原因:
数组越界操作;
(2)内存溢出,访问越界;
(3)堆栈溢出,程序跑飞;
(4)中断处理错误;
此部分原来博客地址:https://blog.csdn.net/electrocrazy/article/details/78173558
按上面说的情况一一排查,(1)(3)(4)都排除了,只剩(2)内存问题,因为赶时间同时对内存没有把握,采用了最笨的方法,把后面加的代码注释掉,编译后下载到目标板子运行,一切正常。
一次无意间发现,把原来定义的出问题的变量注释掉,重新在后面的位置定义该变量,程序也能正常运行,不会进入HardFault_Handler异常 情况如下图
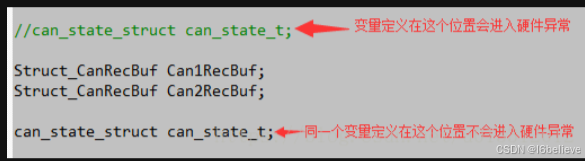
当然,问题实际上并没有解决,这只是胡乱弄暂时程序能运行,不会进入HardFault_Handler异常。接下来就继续忙别的,没有深究。
后来有同事在原来的代码上把一个32个元素的数组扩展到33个字节时,程序又出现进入HardFault_Handler异常,趁有时间开始仿真查一查,按照上面链接所说的方法,在硬件中断函数HardFault_Handler里面的while(1)处打断点
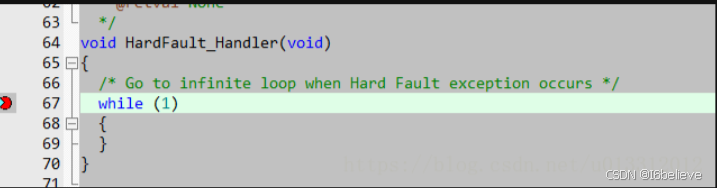
用工具发送can消息让程序进入中断,打开keil中View->Call Stack Window弹出Call Stack + Locals窗口,发现进入中断出错前调用的是_rt_memcpy_w函数,
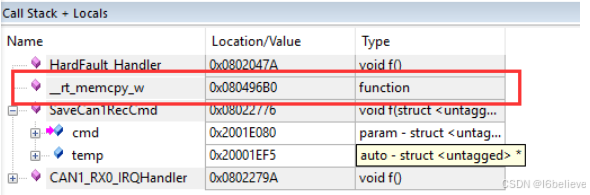
选中_rt_memcpy_w右键选择Show Caller Code,可以看到,程序是在执行这一行代码的时候进入了硬件异常

查看汇编代码
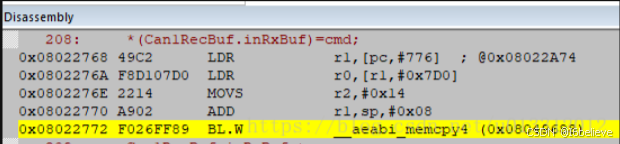
可以看到实际上调用的__aeabi_memcpy4这个函数,这个函数的作用跟ANSI C memcpy一样,只是这个函数要求的是指针是要4字节对齐的,打开工程的map文件,查找Can1RecBuf这个变量的指针,从下图可以看出,该指针不是四字节对齐的,所以程序进入了HardFault_Handler异常,
![]()
接下来我把之前数组扩展到36个字节,从下图可以看出,Can1RecBuf这个变量的指针已经变成4字节对齐了
![]()
编译下载后,程序正常运行。后面添加变量或是扩展数组全部四字节对齐,就不会再进入HardFault_Handler异常。
程序里有很多地方都用到了memcpy功能,在map文件查找时发现只有这个地方实际上使用的是 __aeabi_memcpy4这个函数,其他地方使用memcpy功能时使用的都是__aeabi_memcpy这个函数,(__aeabi_memcpy这个函数的作用跟ANSI C memcpy一样,只不过__aeabi_memcpy返回值为void),程序定位到使用memcp功能的变量定义处,发现,在map文件中显示调用__aeabi_memcpy函数的地方所使用的变量前面都有使用 #pragma pack(1) (#pragma pack(1)的用途可以自行百度下)让变量以一字节对齐,而在map文件中显示调用__aeabi_memcpy4这个函数的地方使用的变量前面没有全部使用#pragma pack(1)让变量以一字节对齐 ,我把原来有使用#pragma pack(1) 限定的变量前面的#pragma pack(1) 注释掉,发现原来调用_aeabi_memcpy函数的地方也变成调用_aeabi_memcpy4这个函数。定位下图代码的变量

发现变量cmd的结构体前面没有使用#pragma pack(1) 限定,加上之后重新编译程序,可以看到,复制函数已经有__aeabi_memcpy4变成了__aeabi_memcpy

总结上面的所说,要使程序不进入HardFault_Handler异常,目前我发现的有两种做法:
1、在定义全局变量的时候全部使用4字节对齐,这样会浪费一些内存空间;
2、在声明结构体的时在结构体的前面加上#pragma pack(1)让其以一字节对齐,这样在使用memcpy的时候就不会调用__aeabi_memcpy4这个函数,而是使用__aeabi_memcpy这个函数
二、个人分析

结合他人分享内容,分析数据对齐方式,发现在945行,结束了1字节对齐,can通信数据定义在1403行,不是以4字节对齐导致。注释掉777行和945行之后,硬件错误故障消除。

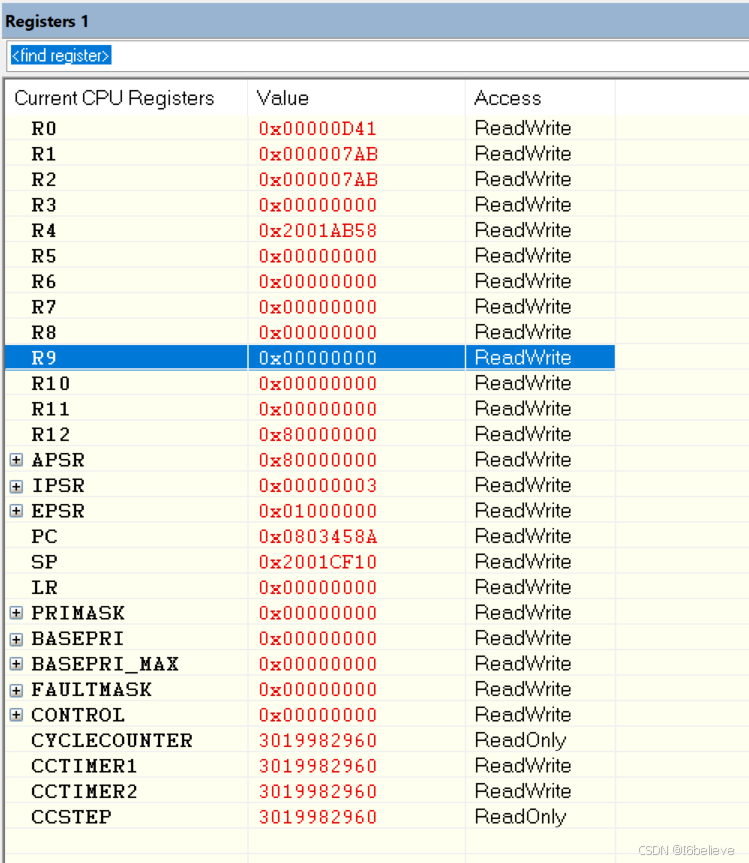
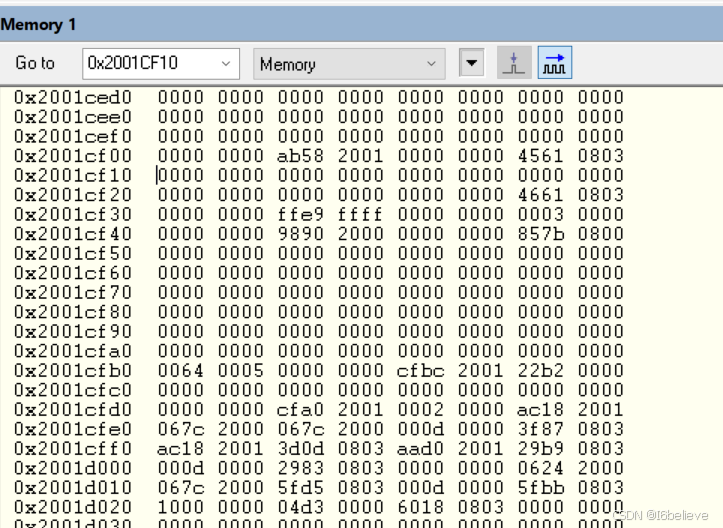
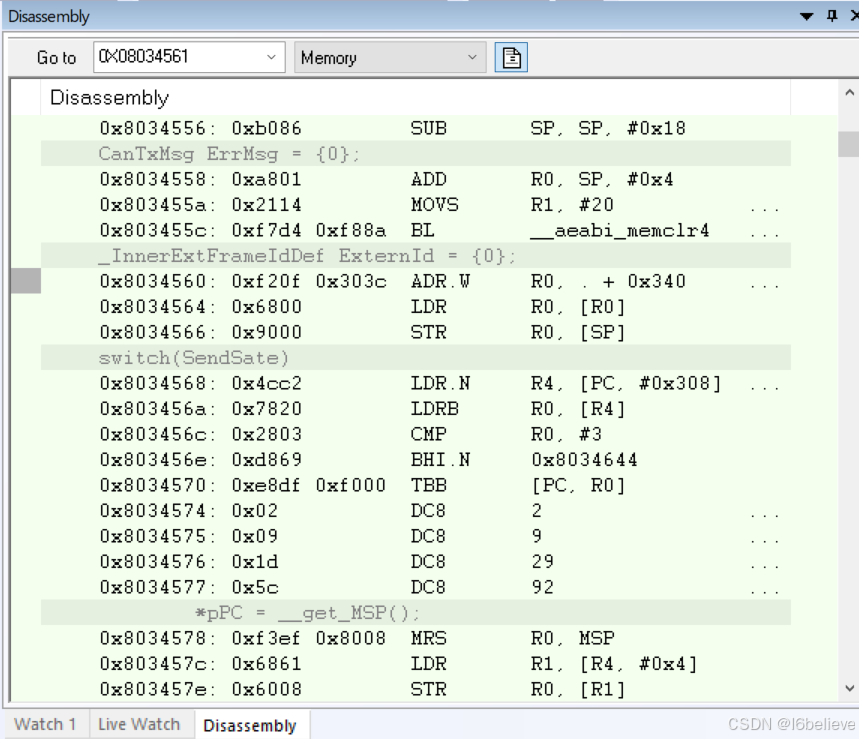
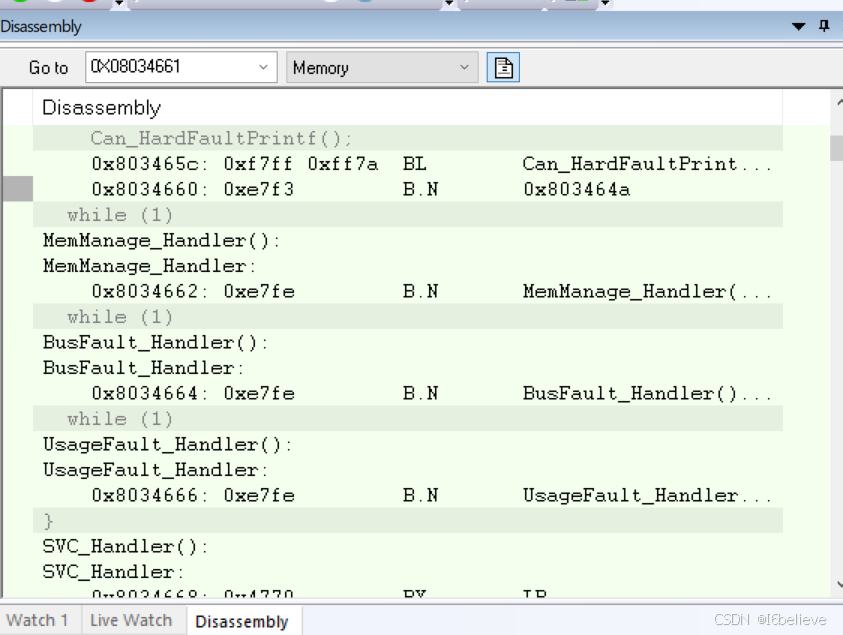
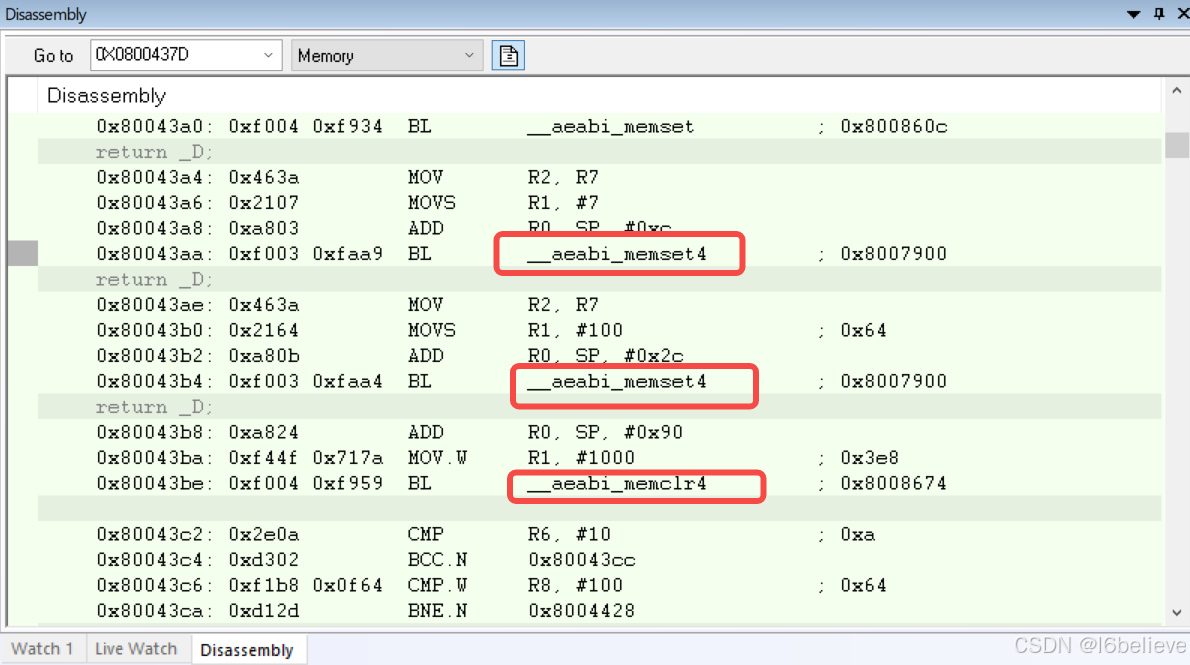
三、__aeabi_memcpy __aeabi_memcpy4 __aeabi_memcpy8区别
armcc解决方式如下
How do the ARM Compilers handle memcpy()?
Applies to: ARM Developer Suite (ADS), RealView Developer Kit (RVDK) for OKI, RealView Developer Kit (RVDK) for ST, RealView Development Suite (RVDS)
Answer
In many cases, when compiling calls to memcpy(), the ARM C compiler will generate calls to specialized, optimised, library functions instead. Since RVCT 2.1, these specialized functions are part of the ABI for the ARM architecture (AEABI), and include:
__aeabi_memcpy
This function is the same as ANSI C memcpy, except that the return value is void.
__aeabi_memcpy4
This function is the same as __aeabi_memcpy; but may assume the pointers are 4-byte aligned.
__aeabi_memcpy8
This function is the same as __aeabi_memcpy but may assume the pointers are 8-byte aligned
The linker will select the optimal versions of these functions to use depending on the selected target processor and build options. In many cases when unaligned accesses are permitted, the 3 variants may map to the same function. As memcpy is typically heavily used and performance critical, ARM versions of these functions are always selected, unless the target processor does not support the ARM instruction set (for example, the Cortex-M3 processor). The linker will provide a state-change as required (for example an inline veneer or a BLX instruction as the function call).
A further optimization may take place if the compiler can determine that you require a copy of a small number of bytes (typically <= 64) which is a multiple of four (e.g. 36 bytes). In this case, rather than calling a function the compiler will generate multiple LDM/STM instructions to perform the copy.
Due to these optimizations, you must take care when copying data using unaligned pointers. The ARM compiler assumes that all pointers are naturally-aligned (i.e. int* is word-aligned, short* is halfword-aligned, etc.). You need to either explicitly tell the compiler when you are using unaligned pointers by using the __packed keyword (described in the compiler guide), or create a temporary char* pointer to access the address. For example:
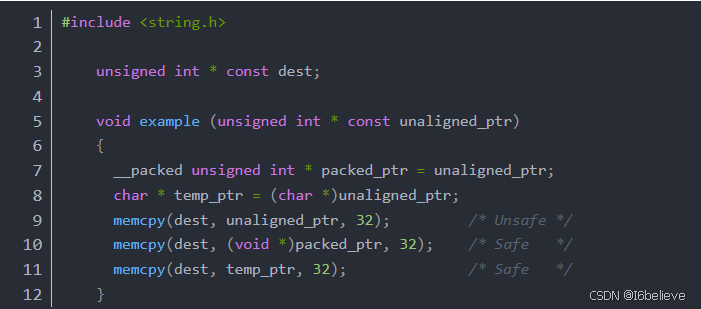
In both of the safe cases the compiler will generate code (or call functions) that work regardless of the pointer alignment. In the unsafe case the compiler is likely to perform the copy using LDM and STM instructions, which do not work if the pointers are unaligned, even on processors that support unaligned accesses.
In a similar way, calls to memmove() and memset() may result in calls to optimized versions which assume 4 or 8 byte alignment, or generate instructions inline. Calls to memset() with zero as the initializing value result in a call to an optimised memclr().
If you wish to provide your own implementations of these functions, you must also provide implementations of the __aeabi* versions. These optimised functions are described further in the Run-time ABI for the ARM Architecture, part of the AEABI, which can be found at http://www.arm.com/products/DevTools/ABI.html.
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/weixin_41572450/article/details/124275549

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)