dive_into_llms--chapter1:预训练语言模型微调与部署
DataTrainingArguments 规定了与数据处理相关的参数;ModelArguments 规定了与模型相关的参数;TrainingArguments 直接从transformers导入,规定了训练过程参数。
目录
2.2 AutoModelForSequenceClassification
2.3 由Results引发的思考:预处理函数preprocess_function
dive-into-llms/documents/chapter1 at main · Lordog/dive-into-llms · GitHub
1. 基于解耦版本定制开发
1.1 utils_data:数据加载和处理
(1)整体流程
数据加载:通过load_data函数从CSV文件中加载文本和标签数据。
数据集构建:通过自定义的MyDataset类将数据封装为PyTorch支持的Dataset对象。
文本编码:在MyDataset中,使用预训练的分词器(Tokenizer)将文本转换为模型所需的输入格式(input_ids和attention_mask)。
动态处理:根据是否为测试集决定是否包含标签,适配训练/推理场景。
(2)batch_encode_plus函数
source = self.tokenizer.batch_encode_plus(
[text], # 单个样本伪装成列表(伪批量)
max_length=self.max_length,
pad_to_max_length=True,
truncation=True,
padding="max_length",
return_tensors="pt",
)encode_plus是 batch_encode_plus 的单样本版本,直接返回形状[max_length]。
代码中选择 batch_encode_plus 的原因可能是:
代码一致性:无论处理单样本还是批量,统一使用 batch_encode_plus。
防止意外错误:某些分词器的 encode_plus 可能不返回张量(如返回列表),而 batch_encode_plus 始终返回张量。
1.2 modeling_bert:模型加载
-
模型架构:BertForSequenceClassification = BertModel + 分类头(Dropout+Linear,将BERT向量映射到分类维度)。
-
分类头:为适应特定任务新增的随机初始化层,仅在微调时训练 。
Input Text → Tokenizer → [CLS] Token → BERT Backbone → [CLS] Vector → Linear Layer → Logits
是否所有大模型微调都要在 base-model 上新增结构 ?
分类/回归任务:通常需要新增结构。
序列分类(Sequence Classification):在[CLS]向量上添加线性分类层。
问答(Question Answering):在BERT输出上添加两个线性层预测答案起止位置。
文本生成(Text Generation):在GPT等生成模型顶部保留原始语言建模头(直接输出下一个 Token 的概率)。
生成/语言模型任务:可能直接复用原始结构。
语言模型微调(Language Model Fine-tuning):直接使用预训练的语言建模头,微调目标是让模型适应领域数据。
特征提取模式(Feature Extraction):冻结模型权重,仅使用预训练模型的中间层输出作为特征(如用 BERT 提取句向量)。
1.3 main
1.3.1 from_pretrained
from transformers import AutoConfig, AutoTokenizer
config = AutoConfig.from_pretrained(args.model)
tokenizer = AutoTokenizer.from_pretrained(args.model)(1)config:加载预训练模型的配置信息(如模型结构参数),不包含模型权重。
-
AutoConfig:根据arg.model名称(bert-base-uncased)自动匹配对应配置类(BerConfig)
-
from_pretrained:从 Hugging Face 模型库或本地缓存加载配置文件(config.json)
(2)tokenizer:加载与预训练模型匹配的分词器,将文本转换为模型可处理的输入格式。
from modeling_bert import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained(args.model, config=config)(3)model:加载预训练模型的权重,并根据配置构建用于序列分类的完整模型。
属于端到端微调(End-to-End Fine-Tuning):同时更新骨干网络和新增适配层的参数。
(什么是端到端?从输入到输出的完整流程均由模型自动学习)
另外,冻结骨干网络微调(只训练分类头):
model = BertForSequenceClassification.from_pretrained(args.model, config=config)
# 冻结 BERT 参数
for param in model.bert.parameters():
param.requires_grad = False1.3.2 Trainer参数详解
class Trainer(
model: PreTrainedModel | Module = None,
args: TrainingArguments = None,
data_collator: Any | None = None, ## 批处理逻辑
train_dataset: torch.utils.data.dataset.Dataset | IterableDataset | datasets.arrow_dataset.Dataset | None = None,
eval_dataset: torch.utils.data.dataset.Dataset | Dict[str, torch.utils.data.dataset.Dataset] | datasets.arrow_dataset.Dataset | None = None, ## 验证集/测试集
processing_class: PreTrainedTokenizerBase | BaseImageProcessor | FeatureExtractionMixin | ProcessorMixin | None = None,
model_init: (() -> PreTrainedModel) | None = None,
compute_loss_func: ((...) -> Any) | None = None, ## 损失函数计算
compute_metrics: ((EvalPrediction) -> Dict) | None = None, ## 评估指标计算
callbacks: List[TrainerCallback] | None = None,
optimizers: Tuple[Optimizer | None, LambdaLR | None] = (None, None), ## 优化器
optimizer_cls_and_kwargs: Tuple[type[Optimizer], Dict[str, Any]] | None = None, ## 优化器参数
preprocess_logits_for_metrics: ((Tensor, Tensor) -> Tensor) | None = None
)(1)data_collator:将原数据样本统一为固定形状的tensor
填充(Padding):将不同长度的样本填充到相同长度。
格式转换:将 Python 对象(如列表、字典)转换为 PyTorch 张量。
生成掩码:生成 attention_mask 标识有效 token 位置。
组合批次:将多个样本合并成一个批次张量。
例如,原数据样本:
samples = [
{"input_ids": [101, 2023, 2003, 102], "labels": 0},
{"input_ids": [101, 4895, 102], "labels": 1}
]经过data_collator:
batch = {
"input_ids": tensor([
[101, 2023, 2003, 102], # 原始长度 4 → 填充到长度 4
[101, 4895, 102, 0] # 原始长度 3 → 填充 0
]),
"attention_mask": tensor([
[1, 1, 1, 1],
[1, 1, 1, 0]
]),
"labels": tensor([0, 1])
}(2)processing_class:
-
NLP: 传入tokenizer以动态分词(需配合未分词的数据集使用)。
-
多模态: 传入processor处理图文数据。
(3)callbacks:自定义训练过程回调函数。
内置回调:EarlyStoppingCallback(早停)、PrinterCallback(控制台日志打印)
(4)preprocess_logits_for_metrics:当评估指标的计算逻辑与模型输出的logits形式不匹配时,在计算评估指标前进行预处理。
常见场景:
多标签分类(Multi-label Classification):需通过 sigmoid 转换为概率
生成任务(Text Generation):logits包含填充符(pad token)的预测,需过滤
掩码语言模型(Masked LM):只需计算被掩码位置的预测结果
2. 基于集成版本微调
2.1 参数
(1)参数定义
DataTrainingArguments 规定了与数据处理相关的参数;ModelArguments 规定了与模型相关的参数;TrainingArguments 直接从transformers导入,规定了训练过程参数。
(2)参数传递
代码使用HfArgumentParser解析三个独立的参数类
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()运行时必须通过命令行显式传递:
python LLM_dive_into_llms/chapter1/TextClassification/run_classification.py \
--model_name_or_path LLM_dive_into_llms/chapter1/TextClassification/bert-base-uncased \
--train_file LLM_dive_into_llms/chapter1/TextClassification/data/train.csv \
--validation_file LLM_dive_into_llms/chapter1/TextClassification/data/val.csv \
--test_file LLM_dive_into_llms/chapter1/TextClassification/data/test.csv \
--shuffle_train_dataset \
--metric_name accuracy \
--text_column_name "text" \
--text_column_delimiter "\n" \
--label_column_name "target" \
--do_train \
--do_eval \
--do_predict \
--max_seq_length 512 \
--per_device_train_batch_size 32 \
--output_dir LLM_dive_into_llms/chapter1/TextClassification/experiments/2.2 AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
ignore_mismatched_sizes=model_args.ignore_mismatched_sizes,
)(1)自动适配:根据配置文件动态选择适合的模型架构(如BERT、RoBERTa、DistilBERT等)
# 同一段代码可加载任意支持的模型架构
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased") # → BertForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("roberta-base") # → RobertaForSequenceClassification(2)自动生成标准分类头(基于config.num_labels),相当于base-model+适配层。
|
任务类型 |
AutoModel类 |
适配层作用 |
|---|---|---|
|
文本分类 |
|
添加全连接分类层 |
|
问答任务 |
|
添加起始/结束位置预测层 |
|
序列标注 |
|
每个Token添加分类层 |
|
掩码语言建模 |
|
添加词汇表预测层 |
|
文本生成 |
|
添加自回归语言模型头 |
|
多选任务 |
|
添加选项得分计算层 |
2.3 由Results引发的思考:预处理函数preprocess_function
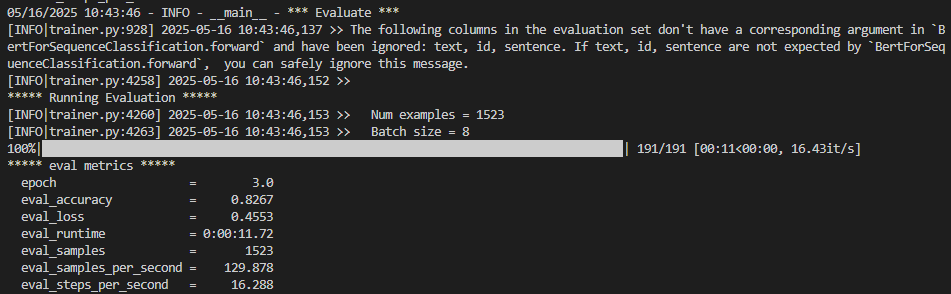
(1)“The following columns in the evaluation set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: text, id, sentence. If text, id, sentence are not expected by `BertForSequenceClassification.forward`, you can safely ignore this message.” 说明什么?
evaluate dataset中包含 text/id/sentence 列,但BertForSequenceClassification模型的forward方法不需要这些列作为输入,Hugging Face 的Trainer在自动处理数据时,会过滤掉模型不需要的列,因此这些列不会被送入模型,所有必要信息已编码在input_ids和label中。
原始验证集
│
├── id → 被忽略(仅用于数据跟踪)
├── text → 通过tokenizer转换为input_ids
└── target → 映射为label(数值标签)
│
└── 模型输入
├── input_ids → 来自text的编码
└── attention_mask → 来自text的编码
│
└── 模型输出
└── 预测结果 → 与label对比计算指标(2)preprocess_function
def preprocess_function(examples):
## 1.多文本列拼接
if data_args.text_column_names is not None:
text_column_names = data_args.text_column_names.split(",")
# join together text columns into "sentence" column
examples["sentence"] = examples[text_column_names[0]]
for column in text_column_names[1:]:
for i in range(len(examples[column])):
examples["sentence"][i] += data_args.text_column_delimiter + examples[column][i]
## 2.调用分词器
result = tokenizer(examples["sentence"], padding=padding, max_length=max_seq_length, truncation=True)
## 3.标签格式转换
if label_to_id is not None and "label" in examples:
if is_multi_label:
result["label"] = [multi_labels_to_ids(l) for l in examples["label"]]
else:
result["label"] = [(label_to_id[str(l)] if l != -1 else -1) for l in examples["label"]]
return resultTokenizer 会自动生成三个核心字段:
- input_ids:文本的数字编码
- attention_mask:标识有效token位置
- token_type_ids(optional):区分句子的标记

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)