RAGFlow 0.18.0 实战解读:从 MCP 支持到插件配置的全流程揭秘(源码)
RAGFlow 0.18.0版本发布,主要新增了MCP功能,允许通过MCP访问知识库。其他改进包括团队协作、Agent版本管理、兼容OpenAI API模型、PDF解析增强等。文章详细介绍了如何手动开启MCP服务并应用于Cherry Studio和VSCode,同时分析了源码中的RAGFlowConnector实现。MCP作为知识库访问接口,为开发者提供了更多集成可能性,但项目目前参与者较少,部分
ragflow在0.18.0的发布的时候,已经第一时间体验了。除了之前预测的功能,就额外多加了一个MCP的功能。刚好五一假期研究了MCP。
https://github.com/infiniflow/ragflow/blob/main/docs/release_notes.md
RAGFlow 0.18.0 发布.
- 实现了 MCP Server:可以通过 MCP 访问 RAGFlow 的知识库
- 团队协作:Agent 可以被分享给其他团队成员
- Agent 版本管理:Agent 的更新会被持续记录并支持通过导出恢复至旧版本
- 新增兼容 OpenAI API 的模型供应商:Agent 支持调用与 OpenAI API 兼容的模型
- 禁用用户注册:管理员可以通过环境变量管理是否开放用户注册入口
- PDF 解析器支持 VLM 模型
- 优化回答引用:优化生成回答时候引用的精准度
- 优化对话体验:可以主动终止对话时候的流式输出
之前在深度拆解RAGFlow分片引擎!3大阶段+视觉增强,全网最硬核架构解析 通过代码梳理,已经说了3个功能
- 在naive视觉增强图表功能
agent增加团队权限功能agent添加了版本,最多保留20个
这次发布额外多了一个MCP服务的功能,前几天已经看到有相关的代码提交了。
最想看的功能是工作流重构,这次没看到,看代码提交记录,ragflow的参与者还是太少了。
启动Ragflow 中的MCP服务
默认官方是不开启mcp server的,如果我们想试用,需要自己手动将代码的注释去掉,如下图所示
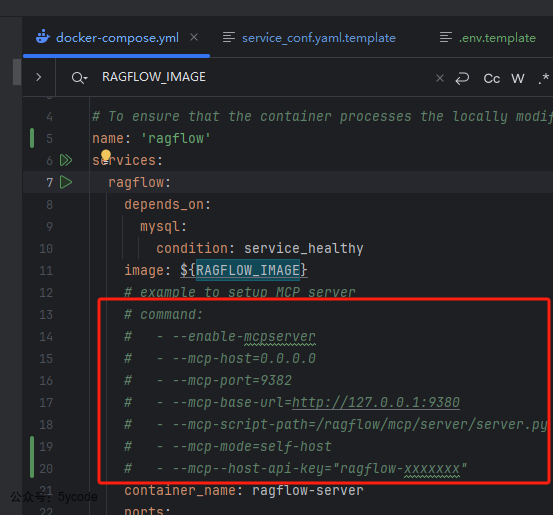
- 需要注意的是
mcp--host-api-key这个变量是错误的,需要调整成mcp-host-api-key,多了一个-导致服务起不来。已经给官方提交了一个pr,合并进去了。 - 需要注意的是,这个api-key不能瞎写,取ragflow中的api key,如果不知道怎么获取,看dify外挂ragflow+QWQ,解决dify解析和检索短板
然后分别执行下面的命令
docker compose down
docker compose up -d
应用
如果不知道如何安装cline可以看上一篇。MCP不像想象的那么简单,MCP+数据库,rag之外的另一种解决方案
在Cherry Studio中应用
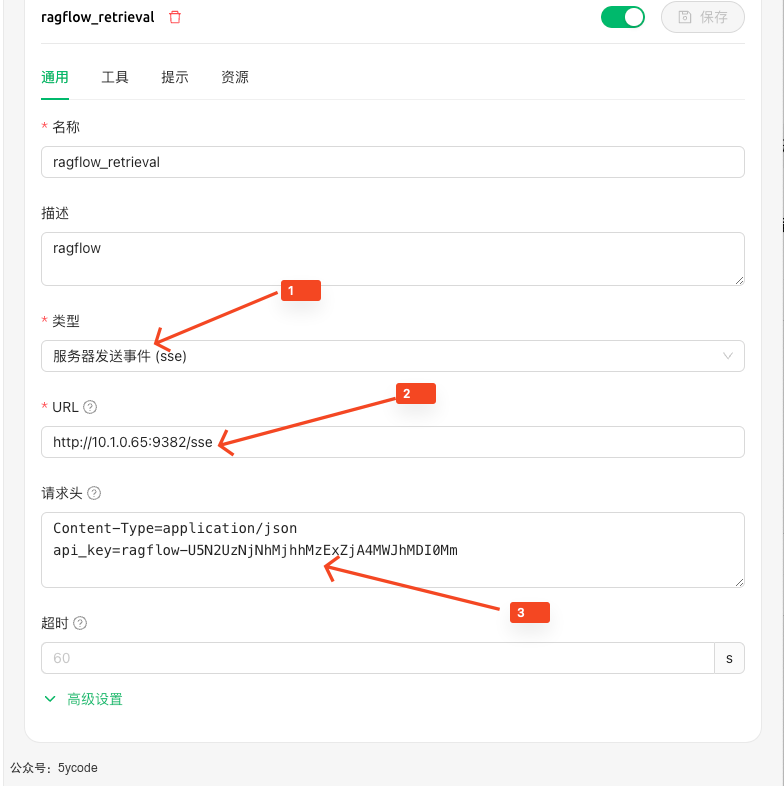
- 在
1的位置选择类型为sse - 在
2的位置填写上你的服务器ip - 在
3请求头中的api_key 填写上ragflow的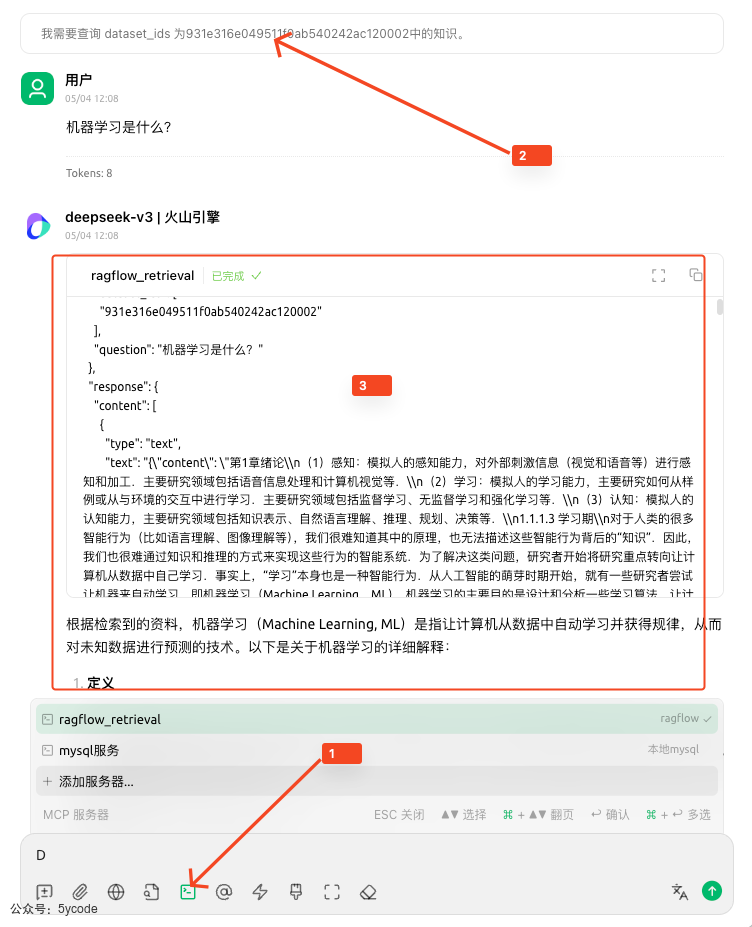
- 在聊天框
1的位置中,选择刚配置好的ragflwomcp服务 2内置提示词,让它查那个数据集(哪个知识库)- 在
3圈定的区域,可以看到检索到的内容
在Visaul Studio code中应用
在cline中添加ragflow的配置
"ragflow-remote": {
"type": "http-sse",
"url": "http://10.1.0.65:9382/sse",
"headers": {
"Content-Type": "application/json",
"api_key": "ragflow-gzY2VmNmY2MDljOTExZjA4NmJjMDI0Mm"
}
}
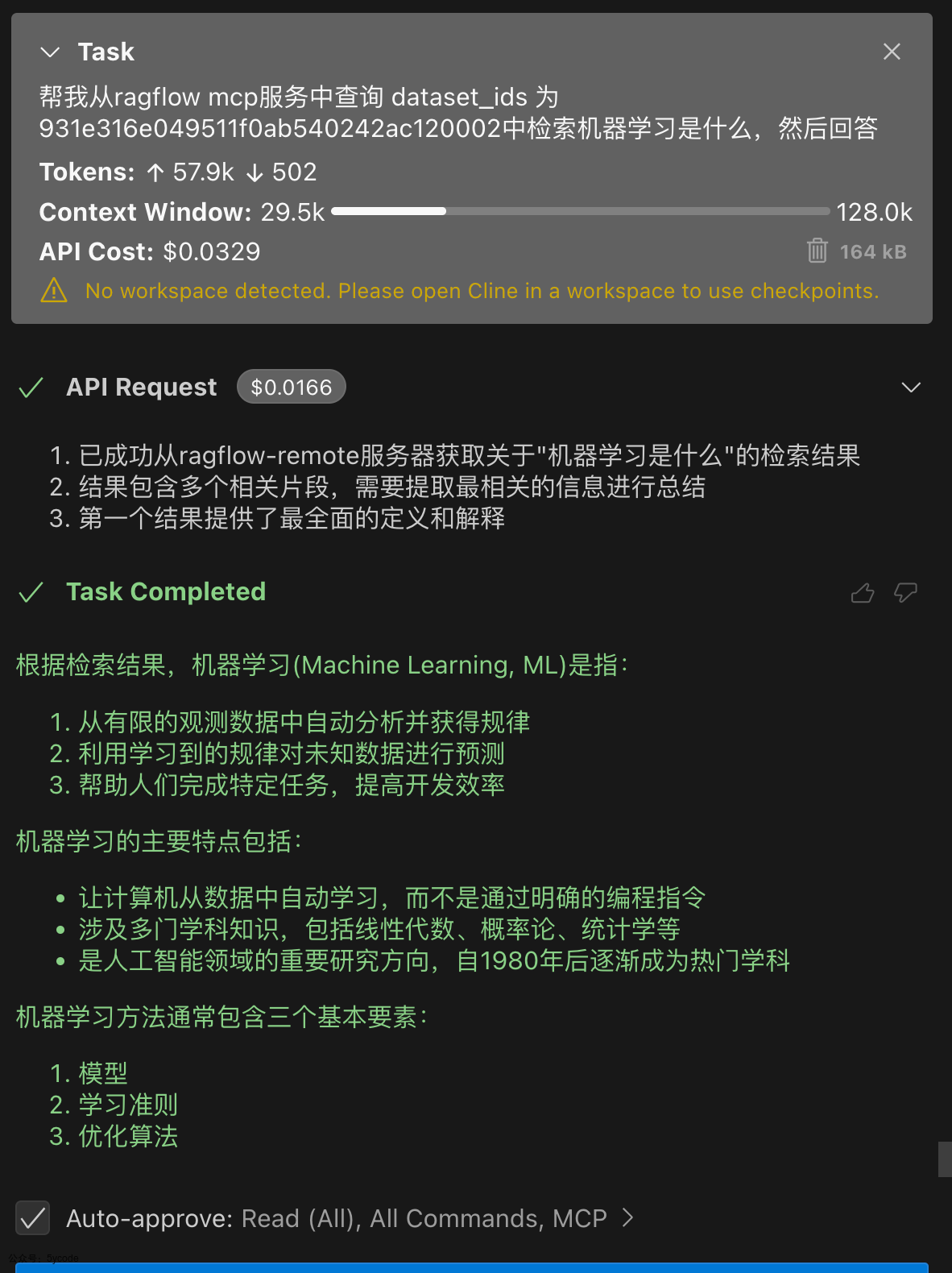
源码分析
在0.18.0版本ragflow增加了一个mcp的目录,这里有MCP的服务端和client端的代码实现。
MCP Server
在MCP Server中使用了Starlette 异步Web框架和mcp 核心库实现。
后端交互封装- RAGFlowConnector
class RAGFlowConnector:
def __init__(self, base_url: str, version="v1"):
self.base_url = base_url
self.version = version
self.api_url = f"{self.base_url}/api/{self.version}"
def bind_api_key(self, api_key: str):
self.api_key = api_key
self.authorization_header = {"Authorization": "{} {}".format("Bearer", self.api_key)}
def _post(self, path, json=None, stream=False, files=None):
if not self.api_key:
return None
res = requests.post(url=self.api_url + path, json=json, headers=self.authorization_header, stream=stream, files=files)
return res
def _get(self, path, params=None, json=None):
res = requests.get(url=self.api_url + path, params=params, headers=self.authorization_header, json=json)
return res
def list_datasets(self, page: int = 1, page_size: int = 1000, orderby: str = "create_time", desc: bool = True, id: str | None = None, name: str | None = None):
res = self._get("/datasets", {"page": page, "page_size": page_size, "orderby": orderby, "desc": desc, "id": id, "name": name})
if not res:
raise Exception([types.TextContent(type="text", text=res.get("Cannot process this operation."))])
res = res.json()
if res.get("code") == 0:
result_list = []
for data in res["data"]:
d = {"description": data["description"], "id": data["id"]}
result_list.append(json.dumps(d, ensure_ascii=False))
return "\n".join(result_list)
return ""
def retrieval(
self, dataset_ids, document_ids=None, question="", page=1, page_size=30, similarity_threshold=0.2, vector_similarity_weight=0.3, top_k=1024, rerank_id: str | None = None, keyword: bool = False
):
if document_ids is None:
document_ids = []
data_json = {
"page": page,
"page_size": page_size,
"similarity_threshold": similarity_threshold,
"vector_similarity_weight": vector_similarity_weight,
"top_k": top_k,
"rerank_id": rerank_id,
"keyword": keyword,
"question": question,
"dataset_ids": dataset_ids,
"document_ids": document_ids,
}
# Send a POST request to the backend service (using requests library as an example, actual implementation may vary)
res = self._post("/retrieval", json=data_json)
if not res:
raise Exception([types.TextContent(type="text", text=res.get("Cannot process this operation."))])
res = res.json()
if res.get("code") == 0:
chunks = []
for chunk_data in res["data"].get("chunks"):
chunks.append(json.dumps(chunk_data, ensure_ascii=False))
return [types.TextContent(type="text", text="\n".join(chunks))]
raise Exception([types.TextContent(type="text", text=res.get("message"))])
在这里是封装了调用ragflow的接口,可以看成是一个业务连接器,这里和mcp没有任何关系,只是把要调用的接口进行了封装。
bind_api_key这里只是构建了一个鉴权的authorization_header_get/_post在调用ragflow的时候,将构建的 authorization_header 传递给后端- 业务方法:
list_datasets: 获取可用数据集列表并返回格式化字符串retrieval: ragflow的检索方法封装
需要注意的是,RAGFlowConnector实例 是全局唯一,在mcp服务启动的时候,构建好了,不要把一些动态变量内置进去,需要在调用的时候动态设置。
MCP 生命周期管理
class RAGFlowCtx:
def __init__(self, connector: RAGFlowConnector):
self.conn = connector
@asynccontextmanager
async def server_lifespan(server: Server) -> AsyncIterator[dict]:
ctx = RAGFlowCtx(RAGFlowConnector(base_url=BASE_URL))
try:
yield {"ragflow_ctx": ctx}
finally:
pass
app = Server("ragflow-server", lifespan=server_lifespan)
sse = SseServerTransport("/messages/")
- server_lifespan: 异步上下文管理器,在Server启动的时候,把Ragflow的连接器实例放入到上下文中
- app 在内存中创建一个
MCP Server的实例对象,这个时候并没有启动,没有绑定到任何网络端口上
tools列表
@app.list_tools()
async def list_tools() -> list[types.Tool]:
ctx = app.request_context
ragflow_ctx = ctx.lifespan_context["ragflow_ctx"]
connector = ragflow_ctx.conn
if MODE == LaunchMode.HOST:
api_key = ctx.session._init_options.capabilities.experimental["headers"]["api_key"]
if not api_key:
raise ValueError("RAGFlow API_KEY is required.")
else:
api_key = HOST_API_KEY
connector.bind_api_key(api_key)
dataset_description = connector.list_datasets()
return [
types.Tool(
name="ragflow_retrieval",
description="Retrieve relevant chunks from the RAGFlow retrieve interface based on the question, using the specified dataset_ids and optionally document_ids. Below is the list of all available datasets, including their descriptions and IDs. If you're unsure which datasets are relevant to the question, simply pass all dataset IDs to the function." + dataset_description,
inputSchema={
"type": "object",
"properties": {"dataset_ids": {"type": "array", "items": {"type": "string"}}, "document_ids": {"type": "array", "items": {"type": "string"}}, "question": {"type": "string"}},
"required": ["dataset_ids", "question"],
},
),
]
在这里的逻辑
- 使用@app.list_tools():装饰器注册
tools/list - 从
request_context.lifespan_context获取注入的RAGFlowCtx - 这里并没有做鉴权,只是把api_key透传给了ragflow,让ragflow判断用户是否有权限
- 先去ragflow中查询了该数据集中的文档
- 然后通过types.Tool 构建了一个对外的工具的元数据定义
- 从properties属性中可以看出来,只暴露了3个属性,还没有暴露
top_k - 这个格式完全遵循MCP协议,详见上一篇
- 从properties属性中可以看出来,只暴露了3个属性,还没有暴露
工具调用 call_tool
@app.call_tool()
async def call_tool(name: str, arguments: dict) -> list[types.TextContent | types.ImageContent | types.EmbeddedResource]:
ctx = app.request_context
ragflow_ctx = ctx.lifespan_context["ragflow_ctx"]
connector = ragflow_ctx.conn
if MODE == LaunchMode.HOST:
api_key = ctx.session._init_options.capabilities.experimental["headers"]["api_key"]
if not api_key:
raise ValueError("RAGFlow API_KEY is required.")
else:
api_key = HOST_API_KEY
connector.bind_api_key(api_key)
if name == "ragflow_retrieval":
document_ids = arguments.get("document_ids", [])
return connector.retrieval(dataset_ids=arguments["dataset_ids"], document_ids=document_ids, question=arguments["question"])
raise ValueError(f"Tool not found: {name}")
- 通过
@app.call_tool()装饰器注册tools/call方法 - 和tools的流程差不多,只不过这块的代码是,调用接口执行检索逻辑
- 需要注意的是,这里通过name限定了工具名称,多个工具的时候,叠加即可。
鉴权中间件
class AuthMiddleware(BaseHTTPMiddleware):
async def dispatch(self, request, call_next):
if request.url.path.startswith("/sse") or request.url.path.startswith("/messages"):
api_key = request.headers.get("api_key")
if not api_key:
return JSONResponse({"error": "Missing unauthorization header"}, status_code=401)
return await call_next(request)
middleware = None
if MODE == LaunchMode.HOST:
middleware = [Middleware(AuthMiddleware)]
- 这里构建了一个
鉴权中间件,用于starlette_app应用中 - 拦截
/sse 与 /messages路径,验证 api_key HTTP Header- 这里只是判断了是否存在,并未真正的鉴权
- 如果我们做,可以在这里获取用户的
access_token来识别用户,然后用于鉴权用户有无对应Tool的权限,通过指定用户获取对应的权限的数据。
ragflow这么做,是因为它的应用已经具备了完整了权限了,是先有了具体的业务功能。如果我们也是这样的场景,可以直接复用。如果我们没有业务功能,可以自定义扩展。
应用与启动
async def handle_sse(request):
# 建立双向流
async with sse.connect_sse(request.scope, request.receive, request._send) as streams:
# 将http header 注入到initialization_options
await app.run(streams[0], streams[1], app.create_initialization_options(experimental_capabilities={"headers": dict(request.headers)}))
# 封装一个starlette 应用,里面有两条路由
starlette_app = Starlette(
debug=True,
routes=[
# 用于握手与消息流
Route("/sse", endpoint=handle_sse),
# 用于SSE客户端推送消息
Mount("/messages/", app=sse.handle_post_message),
],
# 应用鉴权中间件
middleware=middleware,
)
if __name__ == "__main__":
# 加载环境变量
load_dotenv()
# 解析命令行参数
parser = argparse.ArgumentParser(description="RAGFlow MCP Server")
BASE_URL = os.environ.get("RAGFLOW_MCP_BASE_URL", args.base_url)
HOST = os.environ.get("RAGFLOW_MCP_HOST", args.host)
PORT = os.environ.get("RAGFLOW_MCP_PORT", args.port)
MODE = os.environ.get("RAGFLOW_MCP_LAUNCH_MODE", args.mode)
HOST_API_KEY = os.environ.get("RAGFLOW_MCP_HOST_API_KEY", args.api_key)
uvicorn.run(starlette_app, host=HOST, port=int(PORT),
)
在这段代码里,starlette_app 封装成了一个starlette 应用,里面有两条路由
/sse用于握手和消息流,每当客户端发起一次初始化请求时,就会调用handle_sse 方sse.connect_sse异步完成SSE通道的握手,并返回一对流对象- streams[0] 读取客户端发来的消息
- streams[1] 往客户端推送服务器事件
/messages/用于向SSE客户端推送消息
在启动时候,如果环境变量有配置,优先与命令行传递的参数,这块需要注意下。
整个流程如下:
后记
- ragflow暴露出来的mcp服务,我们可以直接配置到应用客户端
- 我们可以同时应用数据库+ragflow的MCP ,通过关键词+向量化混合检索。通过自然语言组织业务流程。解决向量不准确的问题。
- 需要注意的是
mysql_mcp_server是 本地服务,一般我们本地是没法连接生产环境的数据库的。也是为安全起见。mysql_mcp_server的使用要和应用服务器部署在一起。 - 当然也有其他的解决方案,
dify通过插件化解决了。相当于在dify的中安装了mysql_mcp_server
系列文章
dify相关
DeepSeek+dify 本地知识库:真的太香了
Deepseek+Dify本地知识库相关问题汇总
dify的sandbox机制,安全隔离限制
DeepSeek+dify 本地知识库:高级应用Agent+工作流
DeepSeek+dify知识库,查询数据库的两种方式(api+直连)
DeepSeek+dify 工作流应用,自然语言查询数据库信息并展示
聊聊dify权限验证的三种方案及实现
dify1.0.0版本升级及新功能预览
Dify 1.1.0史诗级更新!新增"灵魂功能"元数据,实测竟藏致命Bug?手把手教你避坑
【避坑血泪史】80次调试!我用Dify爬虫搭建个人知识库全记录
手撕Dify1.x插件报错!从配置到网络到Pip镜像,一条龙排雷实录
dify1.2.0升级,全新循环节点优化,长文写作案例
dify1.x无网环境安装插件
dify项目结构说明与win11本地部署
Dify 深度拆解(二):后端架构设计与启动流程全景图
dify应用:另类的关键词检索
10分钟搞定企业级登录!Dify无缝集成LDAP实战指南](https://mp.weixin.qq.com/s/qKT80Z9giIB6fZUfW0ZsJQ)
ragflow相关
DeepSeek+ragflow构建企业知识库:突然觉的dify不香了(1)
DeepSeek+ragflow构建企业知识库之工作流,突然觉的dify又香了
DeepSeek+ragflow构建企业知识库:高级应用篇,越折腾越觉得ragflow好玩
RAGFlow爬虫组件使用及ragflow vs dify 组件设计对比
从8550秒到608秒!RAGFlow最新版本让知识图谱生成效率狂飙,终于不用通宵等结果了
以为发现的ragflow的宝藏接口,其实是一个天坑、Chrome/Selenium版本地狱
NLTK三重降噪内幕!RAGFlow检索强悍竟是靠这三板斧
从代码逆向RAGFlow架构:藏在18张表里的AI知识库设计哲学
解剖RAGFlow!全网最硬核源码架构解析
深度拆解RAGFlow分片引擎!3大阶段+视觉增强,全网最硬核架构解析
深度拆解RAGFlow分片引擎之切片实现
RAGFlow核心引擎DeepDoc之PDF解析大起底:黑客级PDF解析术与致命漏洞
RAGFlow 0.18.0 实战解读:从 MCP 支持到插件配置的全流程揭秘
ragflow 0.19.0 图文混排功能支持
mcp
MCP不像想象的那么简单,MCP+数据库,rag之外的另一种解决方案
上线3周:告警减少70%!AI巡检分级报告实战(一)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 10
10 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)